原来我的jetpack版本较低,可以直接从jetson zoo中找到对应本版编译好的ort:
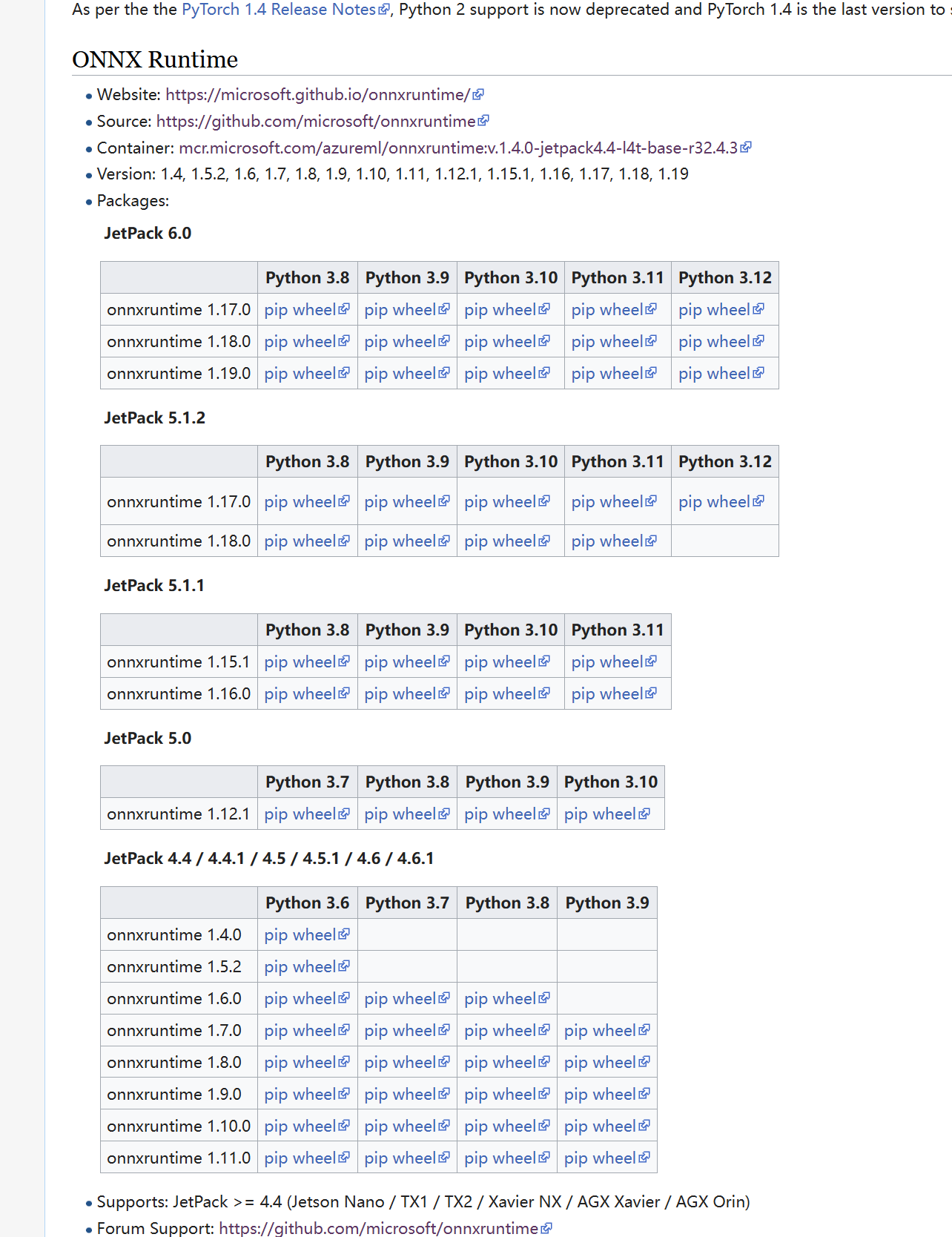
但是最高也只支持到jetpack6.0。而我今天的设备是jetpack 6.2.1(L4T 36.4.4),一开始我的思路是在官网中寻找这个版本对应的ort,发现根本没有类似jetson zoo这样的,已经编译好的whl文件,直接下载后pip install即可安装完成那么简单。
所以只能换个思路,自己手动编译ORT。首先找到onnxruntime官网,里面每个版本都发布在上面。根据nvidia官方文档查看jetpack版本对应的onnxruntime版本,JetPack 6.x 支持 ONNX Runtime 1.17.x,根据我JetPack 6.2.1(L4T 36.4.4)应该对应的是 ONNX Runtime 1.17.1。
在官网中找到1.17.1版本的release,下载Source code (zip) 或者 Source code (tar.gz)
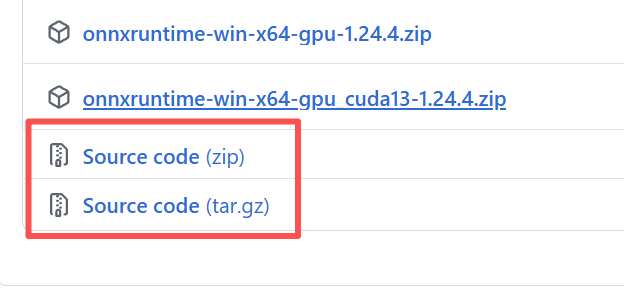
推荐是下载tar.gz,然后开始编译:
🟩步骤 1:安装依赖
bash
sudo apt update
sudo apt install -y build-essential python3-dev python3-pip git cmake ninja-build🟩 步骤 2:安装 protobuf(JetPack 6.x 必须)
bash
sudo apt install -y protobuf-compiler libprotobuf-dev🟩 步骤 3:下载 ONNX Runtime 1.17.1 源码
bash
wget https://github.com/microsoft/onnxruntime/archive/refs/tags/v1.17.1.tar.gz
tar -xvf v1.17.1.tar.gz
cd onnxruntime-1.17.1🟩 步骤 4:开始编译(JetPack 6.x 专用命令)
首先构建 ONNX Runtime(含 CUDA + TensorRT):
bash
./build.sh --config Release \
--update --build \
--parallel \
--use_cuda \
--cuda_home /usr/local/cuda \
--cudnn_home /usr/lib/aarch64-linux-gnu \
--use_tensorrt \
--tensorrt_home /usr/lib/aarch64-linux-gnu \
--skip_tests解释:
--use_cuda → 启用 CUDA EP
--use_tensorrt → 启用 TensorRT EP
--skip_tests → 避免 Jetson 上跑测试太慢
--parallel → 多核编译时间比较久大约需要 30--60 分钟。
其次构建 Python wheel:
bash
python3 tools/ci_build/build.py \
--config Release \
--build_dir build \
--parallel \
--skip_tests \
--use_cuda \
--cuda_home /usr/local/cuda \
--cudnn_home /usr/lib/aarch64-linux-gnu \
--use_tensorrt \
--tensorrt_home /usr/lib/aarch64-linux-gnu \
--build_wheel🟩 步骤 5:找到生成的 whl 文件
编译完成后,whl 会在路径:
bash
build/Linux/Release/dist/文件名类似:
bash
onnxruntime_gpu-1.17.1-cp310-cp310-linux_aarch64.whl🟩 步骤 6:安装 whl
bash
pip install build/Linux/Release/dist/onnxruntime_gpu-1.17.1-cp310-cp310-linux_aarch64.whl🟦 五、验证 TensorRT + CUDA 是否启用成功
python
import onnxruntime as ort
print(ort.get_available_providers())你应该看到:
python
['TensorrtExecutionProvider', 'CUDAExecutionProvider', 'CPUExecutionProvider']但是上面只是理想的状态:其实大部分时间都会花在以下步骤------问题的出现、排查与解决:
问题1:fatal: 不是 git 仓库 (或者任何父目录) .git
在编译源码的时候出现如图报错:
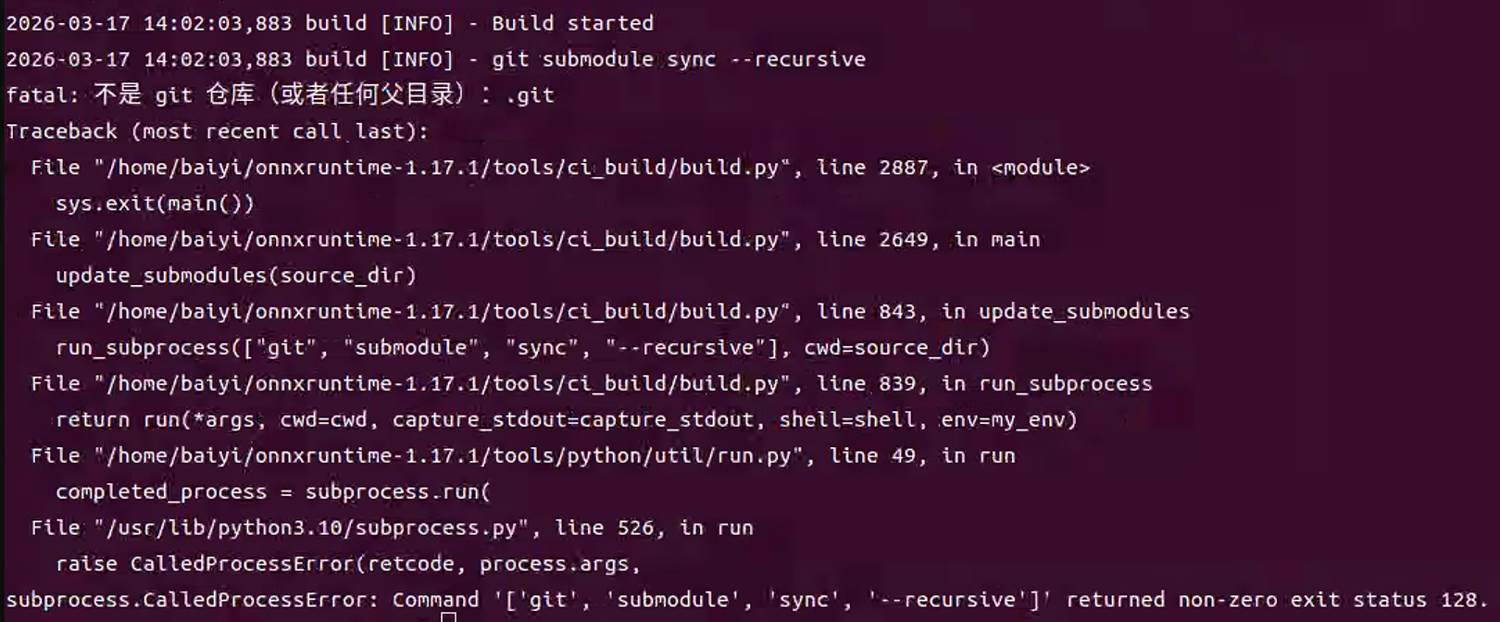
是因为 GitHub 的 Source code 压缩包不包含 .git 和 submodules。
ONNX Runtime 的源码依赖大量 Git submodules(protobuf、flatbuffers、onnx、mimalloc、re2...),如果没有 submodules,编译一定失败。
解决:
删除当前的 onnxruntime-1.17.1 文件夹:
bash
rm -rf onnxruntime-1.17.1使用 git clone 下载完整仓库(包含 submodules):
bash
git clone --recursive https://github.com/microsoft/onnxruntime.git -b v1.17.1然后再继续构建 C++ 与 构建 Python wheel 命令的执行。
问题2:git总是失败或者时间很长
①若是报错:
bash
fatal: 无法访问 'https://github.com/microsoft/onnxruntime.git/':HTTP/2 stream 1 was not closed cleanly before end of the underlying stream'... ...
如果第一种方案没能解决,你会跟我一样中间还有无数种各种各样不同的报错,根本原因还是国内网络不稳定git拉取也不稳定。直接看终极解决方案就行。
... ...
②根本原因国内网络不稳定
解决:
①强制 Git 使用 HTTP/1.1(避免 HTTP/2 问题)
bash
git config --global http.version HTTP/1.1
git config --global http.postBuffer 524288000
git config --global http.maxRequests 100然后继续git
②直接开VPN挂梯子
注意vpn内核要使用arm64架构的,而非常规的amd64架构。
开完之后拉取速度从之前的十几K到目前的几十M。
问题3:CMake 版本太低
报错:
bash
CMake Error at CMakeLists.txt:5 (cmake_minimum_required):
CMake 3.26 or higher is required. You are running version 3.22.1
-- Configuring incomplete, errors occurred!
... ...
... ...
File "/usr/lib/python3.10/subprocess.py", line 526, in run
raise CalledProcessError(retcode, process.args,
subprocess.CalledProcessError: Command '['/usr/bin/cmake', '/home/baiyi/onnxruntime/cmake' ... ...etPack 6.2.1 自带的 CMake 版本太低(3.22.1),而 ONNX Runtime 1.17.1 要求 CMake ≥ 3.26
解决:
从 CMake 官网下载二进制包cmake-3.27.x-linux-aarch64.tar.gz
然后:
bash
tar -xvf cmake-3.27.*-linux-aarch64.tar.gz
sudo mv cmake-3.27.*-linux-aarch64 /opt/cmake
sudo ln -sf /opt/cmake/bin/* /usr/local/bin/验证:
bash
cmake --version然后继续构建 ONNX Runtime 和 wheel。
问题4:构建onnxruntime时自动下载 Eigen出问题
报错:
bash
CMake Error at eigen-subbuild/eigen-populate-prefix/src/eigen-populate-stamp/download-eigen-populate.cmake:170 (message):
Each download failed!
ubuntu03-17 16:00:55
gmake[2]: *** [CMakeFiles/eigen-populate.dir/build.make:100:eigen-populate-prefix/src/eigen-populate-stamp/eigen-populate-download] 错误 1
gmake[1]: *** [CMakeFiles/Makefile2:83:CMakeFiles/eigen-populate.dir/all] 错误 2
gmake: *** [Makefile:91:all] 错误 2
CMake Error at /opt/cmake/share/cmake-3.27/Modules/FetchContent.cmake:1662 (message):
Build step for eigen failed: 2
Call Stack (most recent call first):
/opt/cmake/share/cmake-3.27/Modules/FetchContent.cmake:1802:EVAL:2 (__FetchContent_directPopulate)
/opt/cmake/share/cmake-3.27/Modules/FetchContent.cmake:1802 (cmake_language)
external/eigen.cmake:12 (FetchContent_Populate)
external/onnxruntime_external_deps.cmake:462 (include)
CMakeLists.txt:575 (include)
-- Configuring incomplete, errors occurred!
subprocess.CalledProcessError: Command '['/usr/local/bin/cmake', '/home/baiyi/onnxruntime/cmake' ... ...核心在于:
bash
Each download failed!
Build step for eigen failed我的网络无法访问 Eigen 的官方源
解决:
手动下载 Eigen 并放到 ORT 的 external 目录
bash
onnxruntime/cmake/external/eigenORT 会从这里查找 Eigen,可以手动下载 Eigen,然后放进去。
首先从官网的release中找到3.4.0版本,下载tar.gz源码压缩包。
进行解压:
bash
tar -xvf eigen-3.4.0.tar.gz得到的eigen-3.4.0/目录放到 ORT 的 external 目录底下:
bash
mv eigen-3.4.0 onnxruntime/cmake/external/eigen然后继续构建onnxruntime。
但是再次运行可能还是会报同样的错,因为放进去的 Eigen 目录没有被 ORT 识别到,ONNX Runtime 的 CMake 脚本不会自动检测手动放的 Eigen,它仍然会执行 FetchContent,从网络下载。所以必须让 ORT 强制使用本地 Eigen,而不是联网下载。
修改文件:
bash
onnxruntime/cmake/external/eigen.cmake将这段代码:
bash
FetchContent_Declare(
eigen
URL https://gitlab.com/libeigen/eigen/-/archive/3.4.0/eigen-3.4.0.tar.gz
)替换为:
bash
FetchContent_Declare(
eigen
SOURCE_DIR ${CMAKE_CURRENT_LIST_DIR}/eigen
)这一步是要告诉CMake,不要下载 Eigen,直接用我本地的 eigen 目录。
然后删除 CMake 缓存,否则 CMake 会继续使用旧的下载配置:
bash
rm -rf build
rm -rf eigen-subbuild
rm -rf eigen-src重新进行./build.sh
问题5:ORT 1.17.1 的 CUDA RNN 模块与 cuDNN 9 不兼容
报错:
bash
/home/baiyi/onnxruntime/onnxruntime/core/providers/cuda/rnn/cudnn_rnn_base.cc:31:36: error: 'cudnnGetRNNLinLayerMatrixParams' was not declared in this scope
31 | cudnnGetRNNLinLayerMatrixParams(handle, rnn_desc, pseudo_layer, x_desc, w_desc, reorganized_w_data, lin_layer_id, filter_desc, (void**)&mem_offset);
| ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
/home/baiyi/onnxruntime/onnxruntime/core/providers/cuda/rnn/cudnn_rnn_base.cc:33:34: error: 'cudnnGetRNNLinLayerBiasParams' was not declared in this scope
33 | cudnnGetRNNLinLayerBiasParams(handle, rnn_desc, pseudo_layer, x_desc, w_desc, reorganized_w_data, lin_layer_id, filter_desc, (void**)&mem_offset);
| ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
gmake[2]: *** [CMakeFiles/onnxruntime_providers_cuda.dir/build.make:776:CMakeFiles/onnxruntime_providers_cuda.dir/home/baiyi/onnxruntime/onnxruntime/core/providers/cuda/rnn/cudnn_rnn_base.cc.o] 错误 1
gmake[1]: *** [CMakeFiles/Makefile2:2099:CMakeFiles/onnxruntime_providers_cuda.dir/all] 错误 2
gmake[1]: *** 正在等待未完成的任务....cuDNN 9 已经完全移除了 RNN API(包括 cudnnGetRNNLinLayerMatrixParams / BiasParams),但 ONNX Runtime 1.17.1 仍然在尝试编译基于 cuDNN RNN 的 CUDA RNN Kernel。
报错正是 cuDNN 9 删除的 API:
bash
cudnnGetRNNLinLayerMatrixParams
cudnnGetRNNLinLayerBiasParams这些 API 在 cuDNN 8.x 存在,但在 cuDNN 9.x 被 NVIDIA 官方彻底移除。
这就意味着,ORT 1.17.1 无法在 JetPack 6.x(cuDNN 9)上直接编译 CUDA EP,必须要使用使用 ONNX Runtime 1.18。
解决:
删除旧目录:
bash
rm -rf onnxruntime重新 clone ORT 1.18(支持 cuDNN 9)
bash
git clone --recursive https://github.com/microsoft/onnxruntime.git -b v1.18.0然后进行解压、编译、构建wheel重复一开始的步骤顺序。
问题6:error: identifier "FLT_MAX" is undefined
报错:
bash
/home/baiyi/onnxruntime/onnxruntime/contrib_ops/cuda/moe/ft_moe/moe_kernel.cu(68): error: identifier "FLT_MAX" is undefined
float threadData(-FLT_MAX);
1 error detected in the compilation of "/home/baiyi/onnxruntime/onnxruntime/contrib_ops/cuda/moe/ft_moe/moe_kernel.cu".
gmake[2]: *** [CMakeFiles/onnxruntime_providers_cuda.dir/build.make:6984:CMakeFiles/onnxruntime_providers_cuda.dir/home/baiyi/onnxruntime/onnxruntime/contrib_ops/cuda/moe/ft_moe/moe_kernel.cu.o] 错误 2
gmake[2]: *** 正在等待未完成的任务....
gmake[1]: *** [CMakeFiles/Makefile2:2099:CMakeFiles/onnxruntime_providers_cuda.dir/all] 错误 2
gmake: *** [Makefile:146:all] 错误 2
Traceback (most recent call last):
... ...
... ...
File "/usr/lib/python3.10/subprocess.py", line 526, in run
raise CalledProcessError(retcode, process.args,
subprocess.CalledProcessError: Command '['/usr/local/bin/cmake', '--build', '/home/baiyi/onnxruntime/build/Linux/Release', '--config', 'Release', '--', '-j8']' returned non-zero exit status 2.错误来自于:
bash
onnxruntime/contrib_ops/cuda/moe/ft_moe/moe_kernel.cu这是 ONNX Runtime 1.18.0 的已知 BUG,官方 issue 已确认并给出修复方法:
缺少 头文件导致 FLT_MAX 未定义。
FLT_MAX 定义在 中,而不是 <float.h> 或 CUDA 的头文件里。
ORT 1.18.0 的这个文件漏掉了 include,导致 NVCC 无法找到 FLT_MAX。
解决:
编辑文件:
bash
onnxruntime/onnxruntime/contrib_ops/cuda/moe/ft_moe/moe_kernel.cu在文件开头添加:
cpp
#include <cfloat>修改后必须清理缓存并重新构建:
bash
rm -rf build
rm -rf CMakeCache.txt然后重新编译和构建。
问题7:TypeError: canonicalize_version() got an unexpected keyword argument 'strip_trailing_zero'
在构建wheel时报错:
bash
File "/usr/local/lib/python3.10/dist-packages/setuptools/_core_metadata.py", line 293, in _distribution_fullname
canonicalize_version(version, strip_trailing_zero=False),
TypeError: canonicalize_version() got an unexpected keyword argument 'strip_trailing_zero'
... ...
File "/usr/lib/python3.10/subprocess.py", line 526, in run
raise CalledProcessError(retcode, process.args,
subprocess.CalledProcessError: Command '['/usr/bin/python3', '/home/baiyi/onnxruntime/setup.py', 'bdist_wheel', '--wheel_name_suffix=gpu']' returned non-zero exit status 1.setuptools 版本过新,而 ONNX Runtime 1.18.0 的 setup.py 使用的是 旧 API,两者不兼容,需要把 setuptools 降级到 ORT 兼容的版本。
解决:
降级 setuptools 到 65.x(官方兼容版本)
bash
pip install "setuptools==65.5.1" --force-reinstall然后重新运行 build.py。
最后构建完成之后开始pip install,发现wheel文件不在/Linux/Release/dist/里面,使用find . -name "*.whl"找一下whl文件所在位置然后进行pip install,然后验证 CUDA / TensorRT 是否启用:
python
import onnxruntime as ort
print(ort.get_available_providers())