1 简介
卷积神经网络中,滑动窗口卷积是其特征提取的核心操作。传统卷积依靠多层嵌套循环,逐行、逐列滑动卷积核,与局部感受野内的特征元素依次完成乘加运算。再结合激活函数的非线性运算,以一种简洁的方式,诠释着自己对于这个世界的独特理解。
这种朴素的串行遍历思想,完全贴合卷积的数学定义与直观理解,但却忽略了现代计算机体系结构的底层特性:CPU、GPU 均以矩阵运算、批量计算、高速缓存、SIMD / 并行计算为性能优势,嵌套循环的零散访存、频繁的内存跳转、碎片化计算,会造成计算资源利用率低下、缓存命中率不足,成为卷积推理与训练阶段的性能瓶颈。
在实际的GPU计算中,并不会直接用硬件实现滑的硬件操作,有以下原因:
- 传统滑动窗口卷积访存冗余严重,感受野重叠带来大量重复读取,GPU 缓存利用率低、带宽浪费大。
- 多层嵌套循环逻辑零散、分支复杂,不符合 GPU 大规模规整并行的计算范式,易造成线程束分化。
GPU 张量核、加速单元均原生面向标准矩阵乘法设计,不规则的滑窗乘加无法直接硬件映射,专用算力难以利用。 - 滑窗计算访存开销远大于计算量,算力闲置严重;且卷积参数多变,不利于硬件统一优化与算子调度。
因此,在很多GPU平台上,并非直接将卷积计算送到Tensor core进行推理,而是先经过img2col算法进行预处理,变成传统意义上的矩阵乘法。
2 算法基本原理
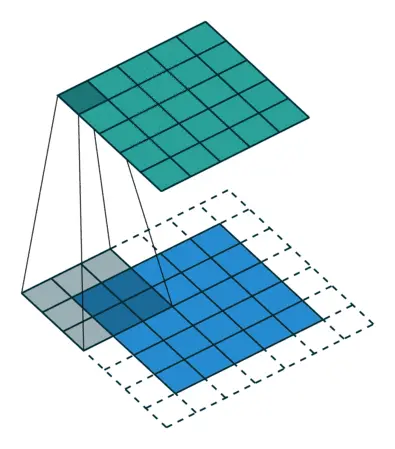
假有33 3输入的特征图,当前阶段只有一个2*2,步长为1的卷积操作,如下图所示:
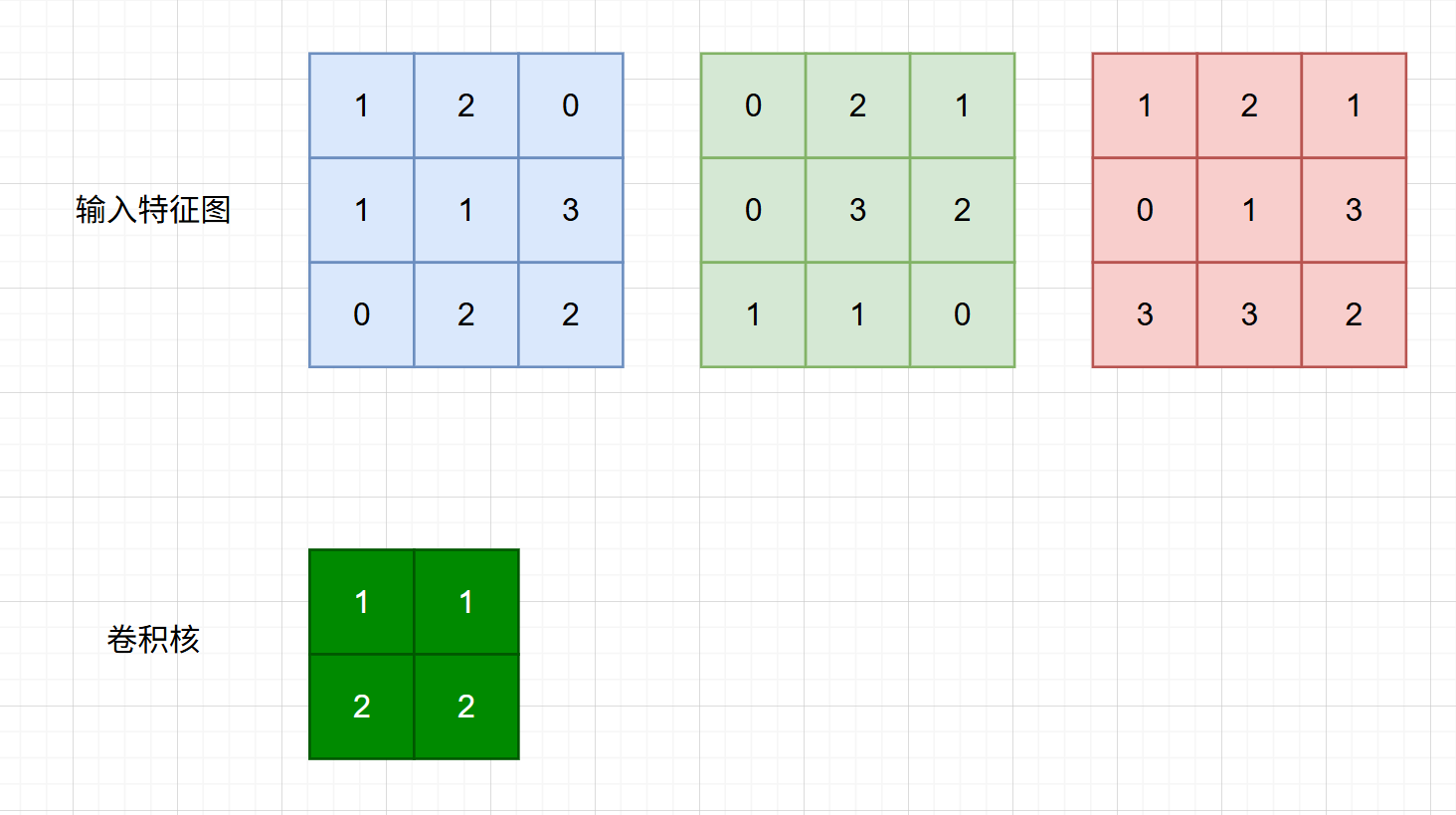
先将标准卷积计算过程中的每次滑窗区域掩码的矩阵展平得到一个个行向量,然后将其组合成一个矩阵,具体流程如下(仅展开第一个矩阵,其他依次类推):
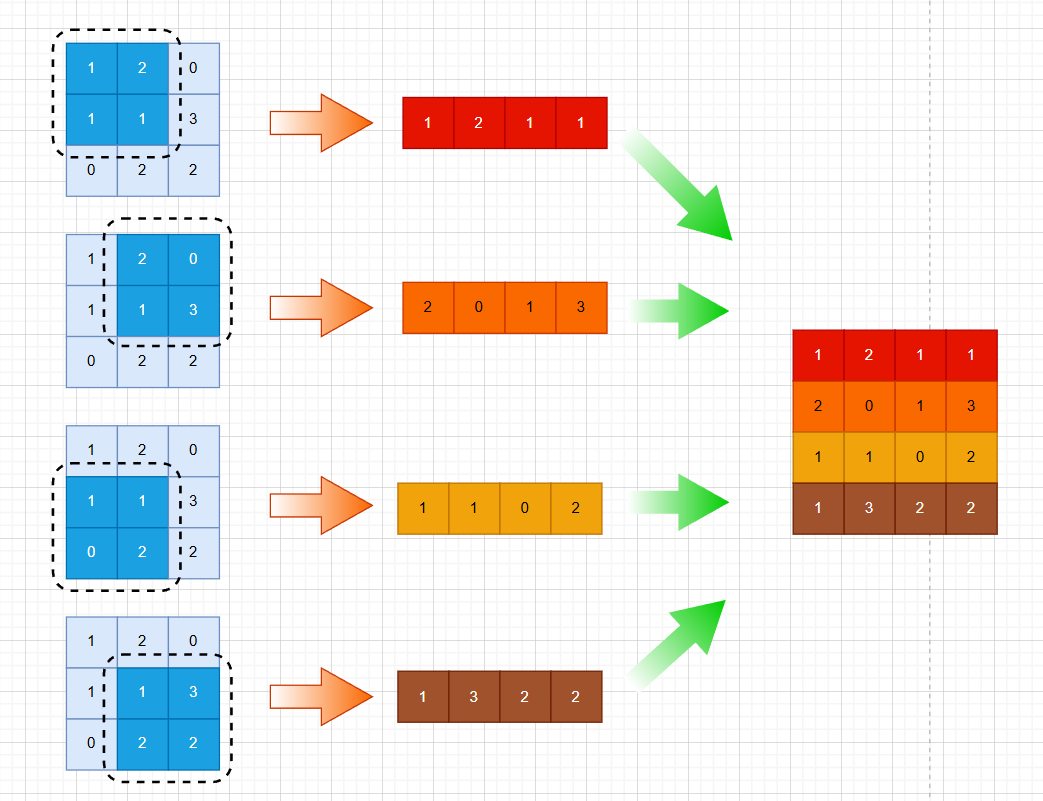
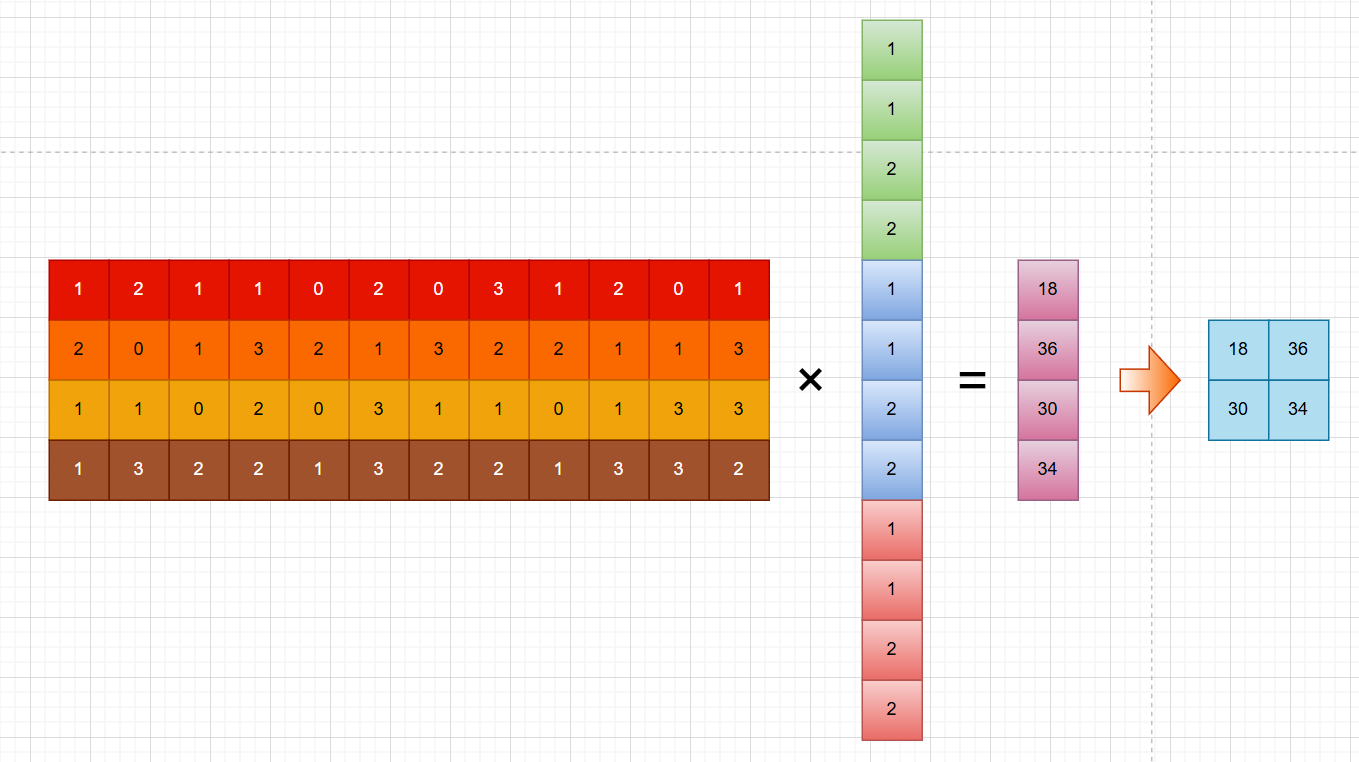
最终,将3个矩阵全部展平,得到如下的12 * 4矩阵:
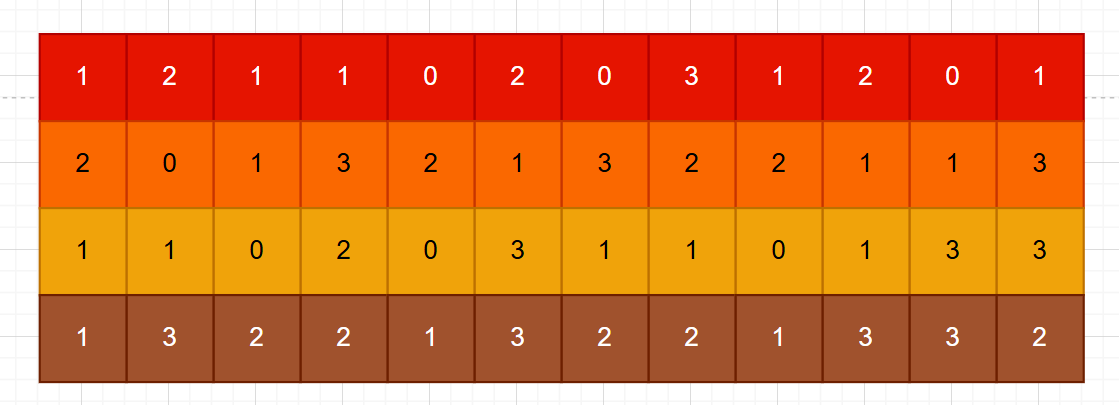
同时将卷积核展平,再复制2分,得到1 * 12的列向量,再与上述的矩阵相乘,得到最终结果:
3 总结
本文讲解了 img2col 算法的核心原理,其核心思想是将卷积神经网络的滑动窗口运算,通过数据重排展开为标准矩阵乘法。借助高度优化的 GEMM 运算,替代低效的多层嵌套循环卷积,大幅提升计算并行度,贴合现代处理器的并行计算架构。
目前,CPU、嵌入式边缘设备仍大量使用 img2col 及其改进方案,该方法实现简单、通用性强,适配无专用张量核心的硬件平台,兼容性极好。
img2col 核心优势:逻辑直观、易于实现,充分利用成熟的矩阵运算库,大幅提升卷积计算效率;主要弊端:滑窗展开存在大量数据冗余,显存与内存占用高,额外的数据排布拷贝会增加访存开销。
在高端 GPU 与工业级推理场景下,原生 img2col 已不再是最优方案。Winograd 快速卷积、算子融合等技术不断迭代,形成合力,共同推进模型的部署进程。
后续文章将聚焦 TensorRT 推理引擎,深入解析工业级卷积优化、算子调度、硬件适配等底层优化逻辑,带你理解高性能部署的核心思路。
3 参考文献
- 《端侧模型部署》葳葳 东南大学出版社
- 阿里云【AI系统】Im2Col 算法