单向循环链表
循环链表(Circular Linked List)是另一种形式的链式存储结构。其特点是表中最后一个节点的指针域指向头节点,整个链表形成一个环。
当链表遍历时,判别当前指针p是否指向表尾结点的终止条件不同。在单链表中,判别条件为 p!=NULL或 p->next!=NULL ,而循环单链表的判别条件为p!=L 或 p->next!=L。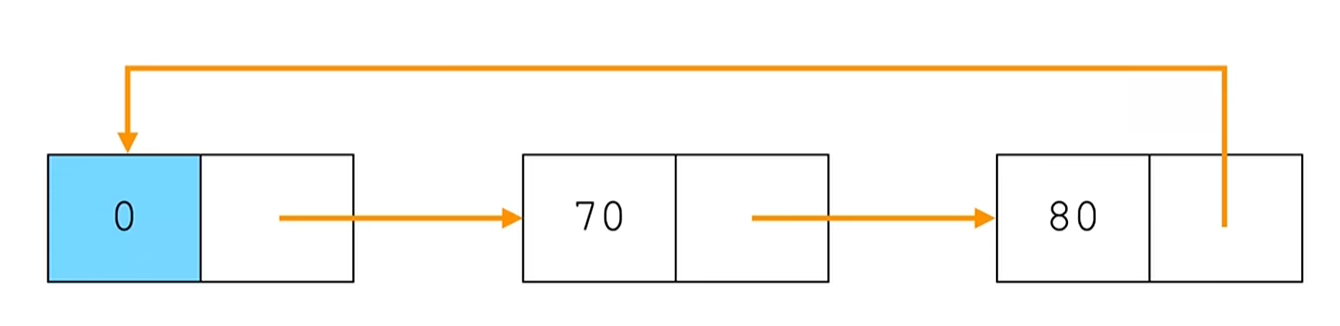
1. 核心区别:为什么不能用 NULL?
- 普通单链表 :尾节点的
next指针是NULL,遍历到p == NULL或p->next == NULL就知道到表尾了。 - 循环单链表 :尾节点的
next指针直接指向头节点L,整个链表是一个闭环,没有NULL指针,所以不能用NULL作为终止标志。
2. 两个判别条件的含义
假设头指针是 L,当前遍历指针是 p:
条件 1:p != L
- 适用场景:从
L->next(第一个数据节点)开始遍历 - 逻辑:当
p再次回到头节点L时,说明已经绕了一圈,遍历结束 - 遍历顺序:
0 → 70 → 80,当p回到L(头节点)时停止。
cpp
p = L->next; // 从第一个数据节点开始
while (p != L) {
// 处理 p 节点
p = p->next;
}条件 2:p->next != L
- 适用场景:从
L或某个节点开始,要遍历到尾节点 - 逻辑:当
p->next == L时,说明p就是尾节点
cpp
p = L;
while (p->next != L) {
p = p->next;
}
// 循环结束时,p 指向尾节点(80)这样可以直接定位到尾节点,方便在尾部插入等操作。
3. 直观类比
把循环链表想象成环形跑道:
- 头节点
L是「起点 / 终点」 - 普通单链表是「直跑道」,跑到尽头就是
NULL - 循环单链表是「环形跑道」,永远跑不到
NULL,只能用「回到起点」作为结束信号
4. 易错点提醒
- ❌ 不要写成
p != NULL:循环链表没有NULL,会导致死循环 - ✅ 必须用
p == L或p->next == L作为终止判断
一句话总结
循环单链表没有 NULL 终点,所以用「回到头节点 L」作为遍历结束的标志:
- 遍历所有数据节点 →
p != L - 找到尾节点 →
p->next != L
完整 C 语言代码:循环单链表遍历(含两种判别条件)
下面的代码,包含创建循环单链表 、遍历所有节点 、定位尾节点三个核心功能,带你直观理解两种判别条件的用法。
cpp
#include <stdio.h>
#include <stdlib.h>
// 定义循环单链表节点结构
typedef struct Node {
int data; // 数据域
struct Node *next; // 指针域
} Node, *CircularLinkList;
// 1. 初始化循环单链表(带头节点)
CircularLinkList InitList() {
// 创建头节点
CircularLinkList L = (Node *)malloc(sizeof(Node));
if (L == NULL) {
printf("内存分配失败!\n");
exit(1);
}
L->next = L; // 循环链表:头节点的next指向自己(空表)
return L;
}
// 2. 尾插法添加节点(构建有数据的循环链表)
void AddNode(CircularLinkList L, int data) {
// 创建新节点
Node *newNode = (Node *)malloc(sizeof(Node));
newNode->data = data;
// 找到尾节点(用判别条件:p->next != L)
Node *p = L;
while (p->next != L) { // 核心:尾节点的next指向头节点L
p = p->next;
}
// 插入新节点,维持循环结构
newNode->next = L; // 新节点的next指向头节点
p->next = newNode; // 原尾节点指向新节点
}
// 3. 遍历所有数据节点(用判别条件:p != L)
void TraverseList(CircularLinkList L) {
if (L->next == L) { // 空表判断
printf("链表为空!\n");
return;
}
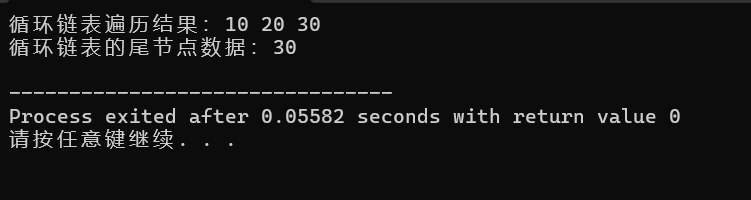
printf("循环链表遍历结果:");
Node *p = L->next; // 从第一个数据节点开始
while (p != L) { // 核心:遍历到回到头节点L为止
printf("%d ", p->data);
p = p->next;
}
printf("\n");
}
// 4. 定位并打印尾节点(验证 p->next == L)
void FindTailNode(CircularLinkList L) {
if (L->next == L) {
printf("链表为空,无尾节点!\n");
return;
}
Node *p = L;
while (p->next != L) { // 找到尾节点(尾节点的next是L)
p = p->next;
}
printf("循环链表的尾节点数据:%d\n", p->data);
}
int main() {
// 步骤1:初始化循环链表
CircularLinkList L = InitList();
// 步骤2:添加节点(数据:10、20、30)
AddNode(L, 10);
AddNode(L, 20);
AddNode(L, 30);
// 步骤3:遍历所有节点(验证 p != L)
TraverseList(L);
// 步骤4:定位尾节点(验证 p->next == L)
FindTailNode(L);
return 0;
}代码关键解释
-
初始化逻辑 :空的循环单链表,头节点
L的next直接指向自己(L->next = L),这是循环链表的基础特征。 -
添加节点(尾插法):
- 用
p->next != L找到尾节点:因为尾节点是最后一个节点,它的next必须指向头节点L,所以当p->next == L时,p就是尾节点。 - 新节点插入后,要保证
newNode->next = L,维持 "循环" 特性。
- 用
-
遍历节点:
- 从
L->next(第一个数据节点)开始,用p != L作为终止条件:只要p没回到头节点,就继续遍历,避免死循环。
- 从
-
运行结果 :
❌ 易错点演示(千万别这么写)
如果把遍历的终止条件写成 p != NULL,会触发死循环:
cpp
// 错误示例(仅演示,不要运行!)
Node *p = L->next;
while (p != NULL) { // 循环链表没有NULL,会无限循环
printf("%d ", p->data);
p = p->next;
}总结
- 循环单链表无
NULL指针,核心判别依据是「是否回到头节点L」。 p != L用于遍历所有数据节点(从第一个数据节点开始)。p->next != L用于定位尾节点(从任意节点开始找尾)。