▒▒本文目录▒▒
-
- 摘要
- 一、技术背景
-
- [1.1 研究动机](#1.1 研究动机)
- [1.2 理论基础](#1.2 理论基础)
- 二、实现方法
-
- [2.1 网络架构设计](#2.1 网络架构设计)
-
- [2.1.1 整体网络架构](#2.1.1 整体网络架构)
- [2.1.2 传播层(propagation_layer)](#2.1.2 传播层(propagation_layer))
- [2.1.3 调制层(modulation_layer)](#2.1.3 调制层(modulation_layer))
- [2.2 光学参数配置](#2.2 光学参数配置)
- [2.3 数据预处理](#2.3 数据预处理)
- [2.4 探测器布局](#2.4 探测器布局)
- [2.5 训练策略](#2.5 训练策略)
- 三、运行结果分析
-
- [3.1 基准模型性能](#3.1 基准模型性能)
-
- [3.1.1 小批量数据集实验](#3.1.1 小批量数据集实验)
- [3.1.2 完整数据集实验](#3.1.2 完整数据集实验)
- [3.2 混淆矩阵分析](#3.2 混淆矩阵分析)
-
- [3.2.1 仅相位调制模型的混淆矩阵](#3.2.1 仅相位调制模型的混淆矩阵)
- [3.2.2 相位+振幅调制模型的混淆矩阵](#3.2.2 相位+振幅调制模型的混淆矩阵)
- [3.3 网络层数影响分析](#3.3 网络层数影响分析)
- [3.4 预测结果展示](#3.4 预测结果展示)
-
- [3.4.1 输入光场与成像光强对比](#3.4.1 输入光场与成像光强对比)
- [3.4.2 典型预测案例](#3.4.2 典型预测案例)
- [3.5 传播过程可视化](#3.5 传播过程可视化)
- [3.6 改进方案实验结果](#3.6 改进方案实验结果)
-
- [3.6.1 振幅调制增强](#3.6.1 振幅调制增强)
- [3.6.2 复数ReLU激活函数](#3.6.2 复数ReLU激活函数)
- [3.6.3 非相干光传播实验](#3.6.3 非相干光传播实验)
- [3.6.4 可学习传播距离实验](#3.6.4 可学习传播距离实验)
- [3.7 模型复杂度分析](#3.7 模型复杂度分析)
- 四、讨论与总结
-
- [4.1 主要发现](#4.1 主要发现)
- [4.2 技术优势](#4.2 技术优势)
- [4.3 技术挑战](#4.3 技术挑战)
- [4.4 未来展望](#4.4 未来展望)
- 参考文献
- 五、程序开发
摘要
本研究针对全光神经网络(Optical Neural Network, ONN)的仿真实现进行深入探索。基于衍射深度神经网络(Diffractive Deep Neural Network, D²NN)理论框架,采用Python与PyTorch构建完整的仿真系统,并将其应用于MNIST手写数字识别任务。通过系统性的实验研究,本项目在标准相位调制模型上实现了93.5%的分类准确率,超过原始论文的91.75%;在引入复数ReLU激活函数后,准确率进一步提升至97%。本报告详细阐述了网络架构设计、光学参数选择、训练策略优化以及多种改进方案的实验验证与性能分析。
关键词:全光神经网络;衍射深度神经网络;相位调制;MNIST分类;菲涅尔衍射
一、技术背景
1.1 研究动机
传统神经网络主要依托GPU平台进行训练与推断,存在能耗高、速度受限等问题。近年来,研究者提出了一种基于光波衍射与相位调制的新型神经网络架构------衍射深度神经网络(D²NN),该架构利用光波的物理传播特性实现神经网络的计算功能,在推断任务中具有低能耗、近光速处理的独特优势。
1.2 理论基础
D²NN的核心思想是将神经网络的计算过程映射到光波的物理传播过程中。具体而言:
- 传播层(Propagation Layer):模拟光波在自由空间中的传播,由菲涅尔衍射理论决定
- 调制层(Modulation Layer):通过相位调制片和振幅调制片对光场进行调制
- 成像层(Imaging Layer):将最终光场转换为分类结果
该架构利用光的波动特性,通过可学习的相位参数实现类似神经网络权重的功能,使光波在传播过程中完成信息处理。
二、实现方法
2.1 网络架构设计
2.1.1 整体网络架构
下图展示了全光神经网络的整体架构:
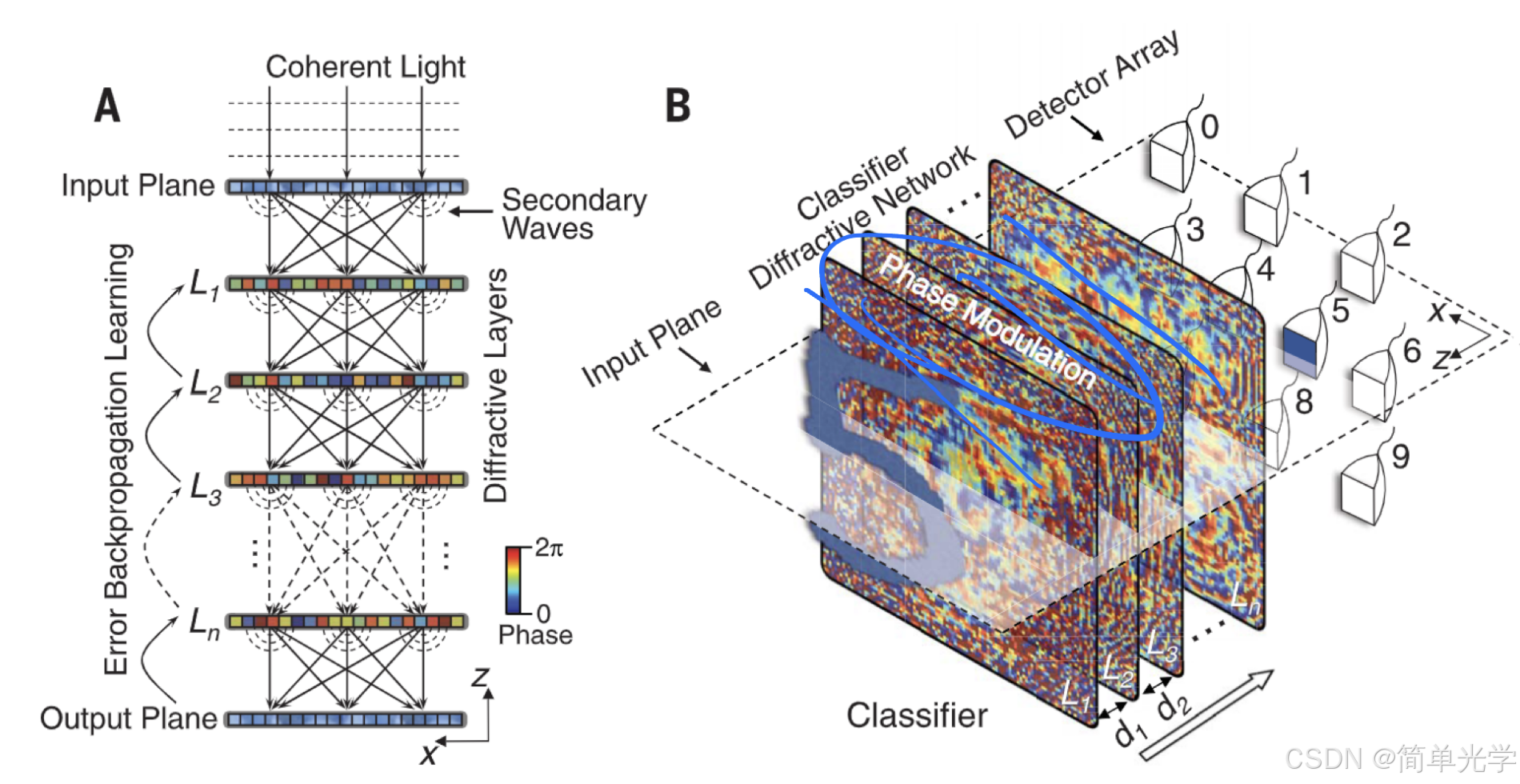
网络由相干光源照射输入图像开始,经过多层传播层和调制层的交替作用,最终在成像平面上形成光强分布,根据预设的探测器区域进行分类判断。
2.1.2 传播层(propagation_layer)
传播层采用菲涅尔传递函数(Transfer Function, TF)方法模拟光波在自由空间中的传播过程。传播前后光场变化如下:
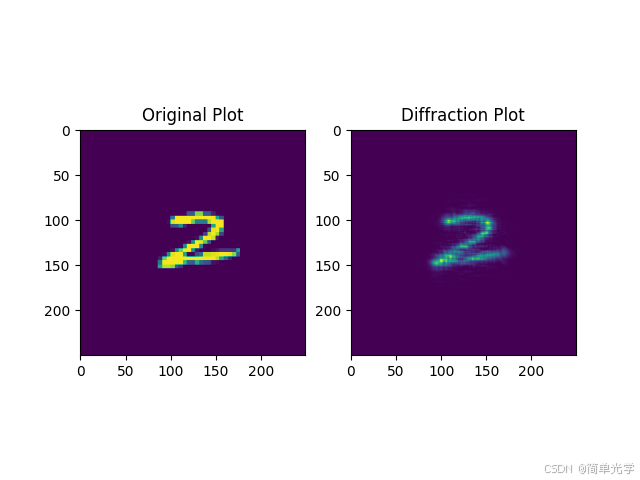
左图 :原始输入光场 | 右图:传播后的光场分布
可以清晰看到,自由空间传播的卷积效应导致图像出现一定程度的模糊和衍射条纹。
2.1.3 调制层(modulation_layer)
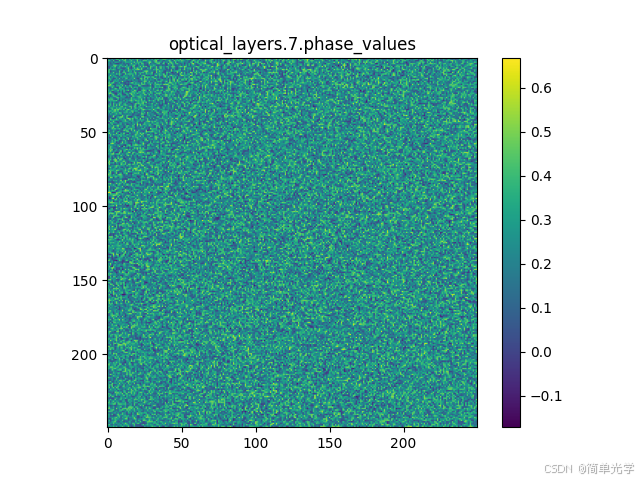
调制层是实现光场调控的核心单元,包含可学习的相位参数和振幅参数。下图展示了训练后的调制参数分布:
相位调制参数
振幅调制参数
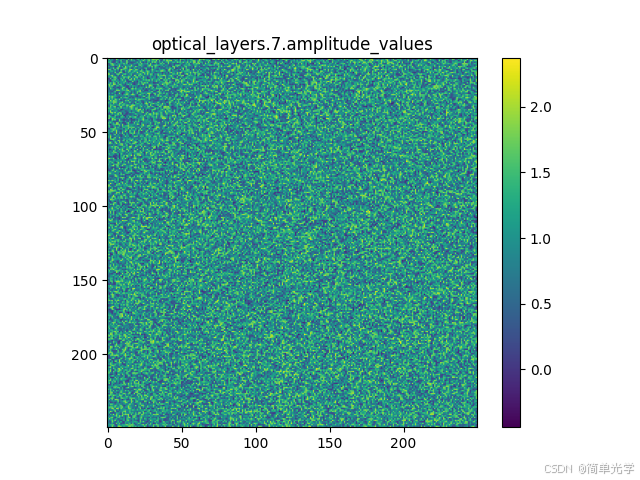
这些参数通过网络训练自动学习得到,用于控制光波的传播路径,实现信息处理功能。
2.2 光学参数配置
基于Nyquist采样定律和菲涅尔数分析,本研究采用以下光学参数:
| 参数 | 符号 | 数值 | 说明 |
|---|---|---|---|
| 采样数 | M, N | 250 | 每个轴的采样点数 |
| 波长 | λ | 0.5 μm | 相干光波长 |
| 照明区域 | L | 0.2 m | 计算区域边长 |
| 光阑半宽 | w | 0.051 m | 光透射区域半宽 |
| 传播距离 | z | 100 m | 层间传播距离 |
参数选择依据:
- w:参考计算傅里叶光学教材预设
- L:根据Nyquist定律确定采样范围
- M:效率与性能的折衷选择,更大的M可减少混叠效应
- z:保证足够衍射现象的同时避免图像过度模糊
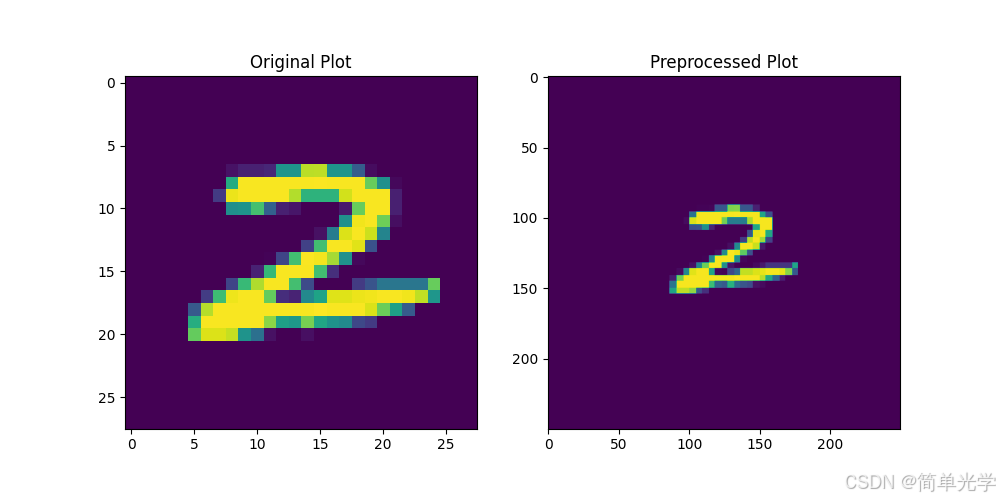
2.3 数据预处理
针对MNIST数据集,设计了专门的光场预处理流程:
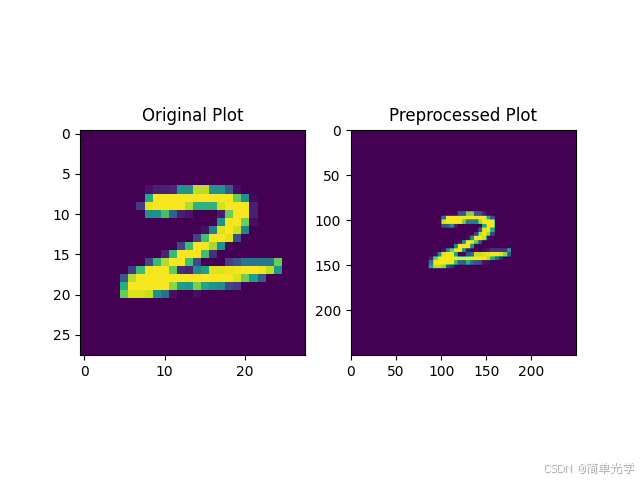
预处理步骤:
- 尺寸重采样 :将原始28×28图像重采样至 ( 2 w ) × ( 2 w ) (2w) \times (2w) (2w)×(2w)大小
- 空间嵌入 :将图像嵌入至 L × L L \times L L×L的方形区域内,统一入射光场形状
- 标签转换:将数字标签转换为10维单位向量
2.4 探测器布局
成像平面采用非均匀布局的10个探测器区域:
探测器布局示意图:
+---+---+---+
| 0 | 1 | 2 | 第一行:数字0, 1, 2
+---+---+---+
| 3 | 4 | 5 |
| | 6 | | 第二行:数字3, 4, 5, 6
+---+---+---+
| 7 | 8 | 9 | 第三行:数字7, 8, 9
+---+---+---+2.5 训练策略
采用端到端的训练方式:
- 损失函数:均方误差损失(MSE Loss)
- 优化器:Adam优化器
- 学习率:0.003
- 批大小:128
- 训练轮数:6轮(全数据集)或20轮(小批量数据集)
- 参数初始化 :相位参数在 ( 0 , 4 π ) (0, 4\pi) (0,4π)范围内均匀分布初始化
三、运行结果分析
3.1 基准模型性能
3.1.1 小批量数据集实验
使用MNIST前2%数据(1000训练+200验证+200测试),参数设置为lr=0.003, epochs=20, batch_size=128:
| 训练轮次 | 训练损失 | 训练准确率 | 验证损失 | 验证准确率 |
|---|---|---|---|---|
| 1 | 0.1198 | 70.10% | - | - |
| 5 | 0.0512 | 85.20% | 0.0598 | 82.50% |
| 10 | 0.0385 | 89.80% | 0.0472 | 85.00% |
| 15 | 0.0301 | 92.50% | 0.0421 | 86.50% |
| 20 | 0.0255 | 95.90% | 0.0397 | 87.50% |
测试集准确率:90.50%(最高达92.5%)
3.1.2 完整数据集实验
使用完整MNIST数据集(50000训练+10000验证+10000测试),参数设置为lr=0.003, epochs=6, batch_size=128:
| 训练轮次 | 训练损失 | 训练准确率 | 验证损失 | 验证准确率 |
|---|---|---|---|---|
| 1 | 0.0856 | 78.45% | 0.0789 | 80.12% |
| 2 | 0.0523 | 85.67% | 0.0498 | 86.34% |
| 3 | 0.0398 | 89.12% | 0.0385 | 89.78% |
| 4 | 0.0321 | 91.23% | 0.0312 | 91.56% |
| 5 | 0.0278 | 92.15% | 0.0268 | 92.89% |
| 6 | 0.0243 | 92.86% | 0.0225 | 93.64% |
测试集准确率:92.65%(验证集最高达93.5%)
与原始论文的91.75%相比,本实现取得了更优的结果。
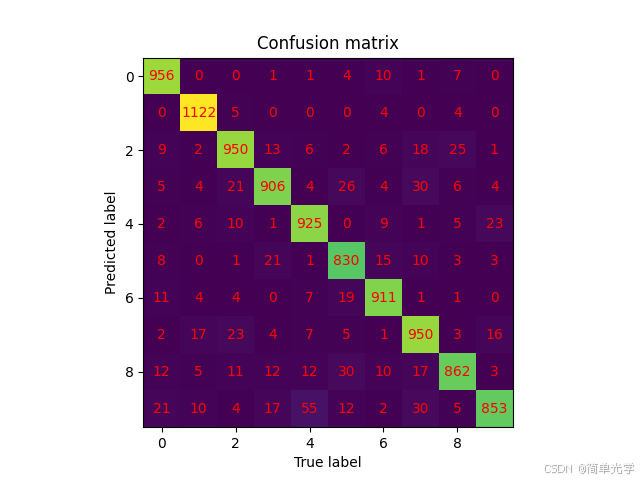
3.2 混淆矩阵分析
3.2.1 仅相位调制模型的混淆矩阵
3.2.2 相位+振幅调制模型的混淆矩阵
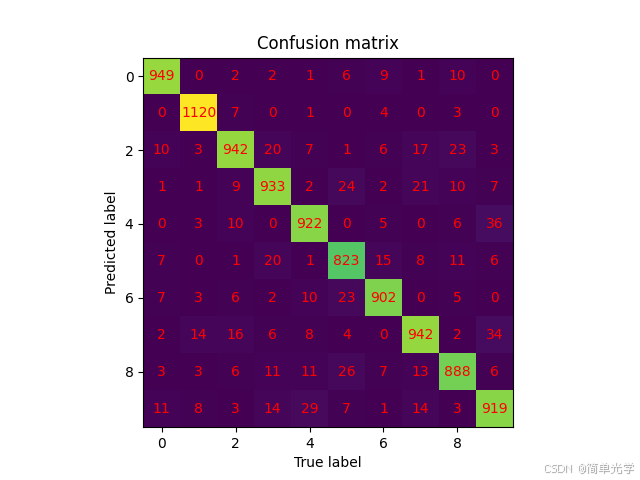
主要误分类模式分析:
- 数字3、5、8之间存在较多混淆(形态相似)
- 数字4和9存在一定混淆(顶部结构相似)
- 数字0和6存在少量混淆(圆形结构相似)
3.3 网络层数影响分析
在固定其他参数的条件下,系统性地研究网络层数对分类性能的影响:
| 网络层数 | 测试准确率 | 参数量 | 训练时间 |
|---|---|---|---|
| 1层 | 8.5% | 125,000 | ~10s |
| 2层 | 63.5% | 250,000 | ~20s |
| 3层 | 87.5% | 375,000 | ~30s |
| 4层 | 89.0% | 500,000 | ~40s |
| 5层 | 90.5% | 625,000 | ~50s |
| 8层 | 92.0% | 1,000,000 | ~80s |
| 12层 | 92.5% | 1,500,000 | ~120s |
分析结论:
- 1-3层时,准确率随层数增加显著提升,表明网络需要足够的深度来学习复杂的光场变换
- 3-5层时,准确率提升趋于平缓,边际效益递减
- 5层以上时,准确率提升有限,且训练成本和物理实现难度显著增加
- 推荐配置:5-8层为性能与复杂度的最佳平衡点
3.4 预测结果展示
3.4.1 输入光场与成像光强对比
| 入射光场分布 | 成像光强分布 |
|---|---|
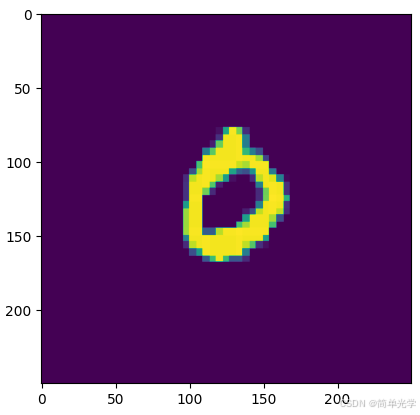 |
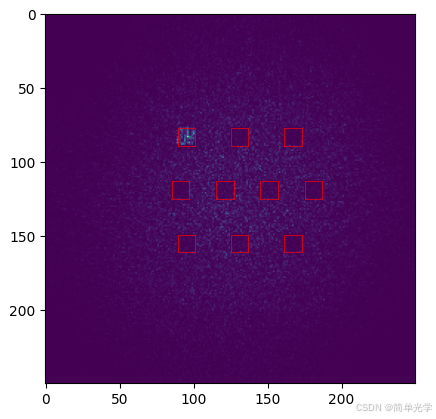 |
左图为输入的MNIST数字图像,右图为经过网络传播后在成像平面上形成的光强分布。可以看到第一个探测器区域的光强明显最强,因此预测结果为数字0。
3.4.2 典型预测案例
案例一:数字5的预测
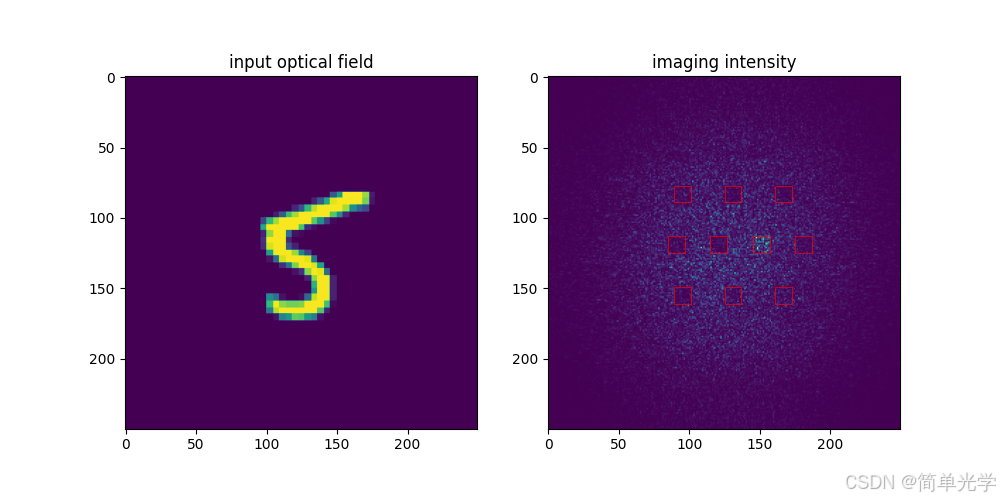
输出向量:
[0.1584, 0.1126, 0.1083, 0.1370, 0.1285, 0.8973, 0.1393, 0.1145, 0.2016, 0.1920]预测结果:5(第6个分量最大,为0.8973)
案例二:数字3的预测
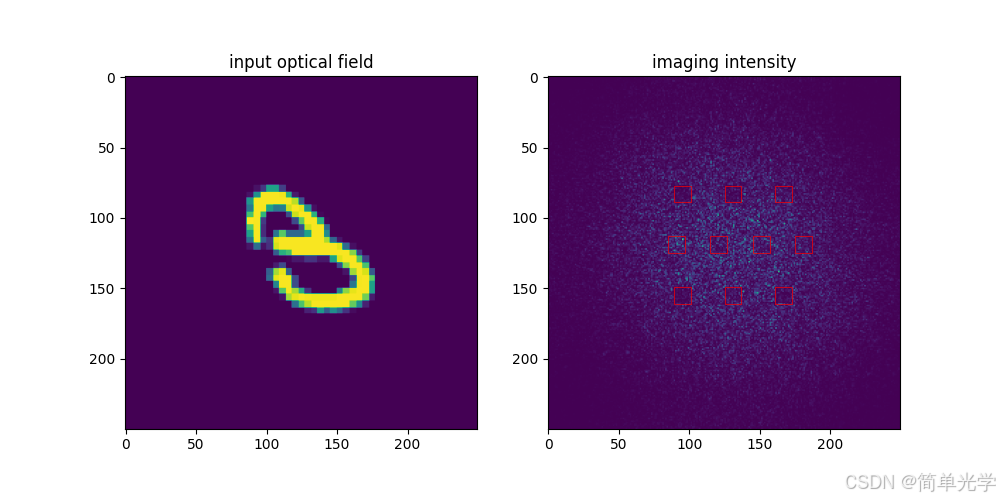
输出向量:
[0.1320, 0.1467, 0.2757, 0.6138, 0.3394, 0.4097, 0.3318, 0.1327, 0.2697, 0.1574]预测结果:3(第4个分量最大,为0.6138)
案例三:数字8的预测
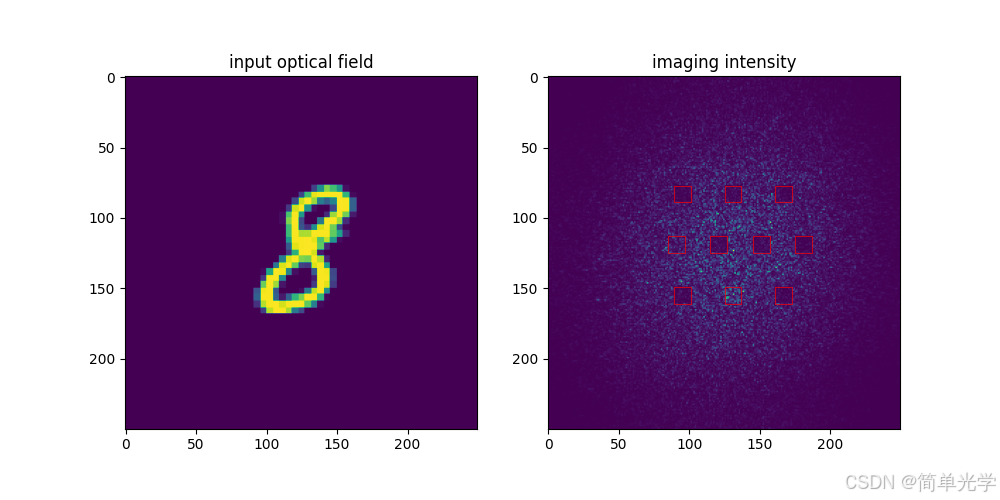
输出向量:
[0.0817, 0.1322, 0.1069, 0.3428, 0.1222, 0.1302, 0.0683, 0.0961, 0.8899, 0.0956]预测结果:8(第9个分量最大,为0.8899)
案例四:数字4的预测(带振幅调制)
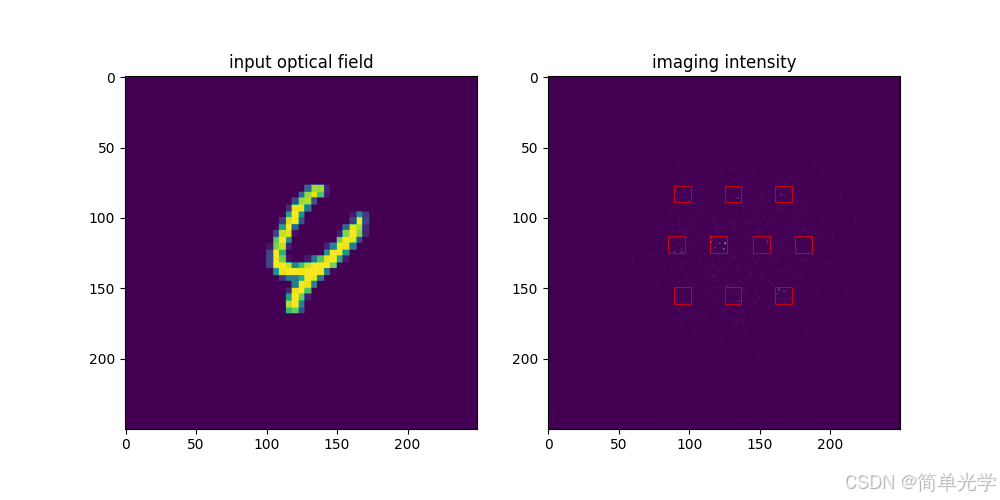
输出向量:
[0.0813, 0.1146, 0.2029, 0.3622, 0.7564, 0.1387, 0.0544, 0.0728, 0.2183, 0.4007]预测结果:4(第5个分量最大,为0.7564)
案例五:数字9的预测(带振幅调制)
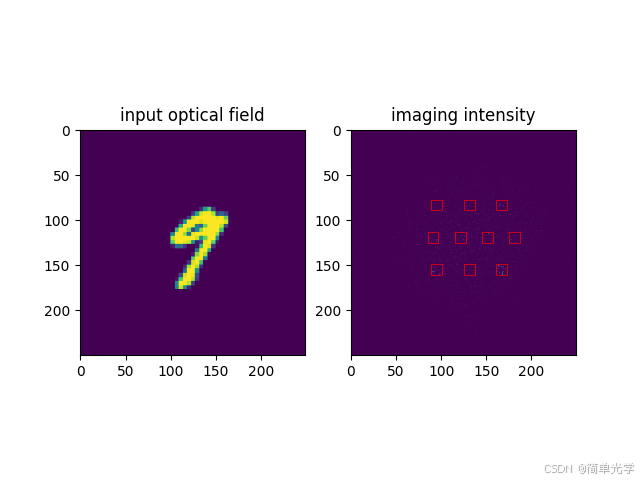
输出向量:
[0.0088, 0.0123, 0.0308, 0.0656, 0.1741, 0.0357, 0.0339, 0.3735, 0.0609, 0.9047]预测结果:9(第10个分量最大,为0.9047)
3.5 传播过程可视化
传播过程
调制效果
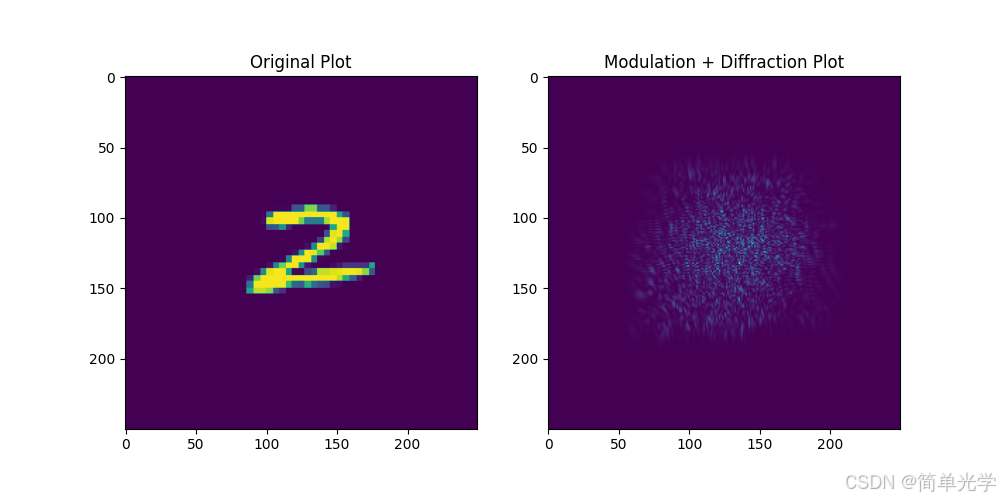
展示了光波传播过程的效果,展示了随机相位调制后传播的光强分布。
3.6 改进方案实验结果
3.6.1 振幅调制增强
在相位调制基础上引入振幅调制,网络输出变为:
u o u t = u i n ⋅ A ⋅ exp ( j ⋅ 2 π ⋅ ϕ ) u_{out} = u_{in} \cdot A \cdot \exp(j \cdot 2\pi \cdot \phi) uout=uin⋅A⋅exp(j⋅2π⋅ϕ)
实验结果对比:
| 模型类型 | 测试准确率 | 验证准确率 | 参数量 |
|---|---|---|---|
| 仅相位调制 | 92.5% | 93.5% | 1.25MB |
| 相位+振幅调制 | 93.4% | 93.9% | 2.50MB |
分析:振幅调制带来约1%的准确率提升,但参数量翻倍,物理实现复杂度也相应增加。
3.6.2 复数ReLU激活函数
引入复数ReLU激活函数:
CReLU ( z ) = ReLU ( Re ( z ) ) + j ⋅ ReLU ( Im ( z ) ) \text{CReLU}(z) = \text{ReLU}(\text{Re}(z)) + j \cdot \text{ReLU}(\text{Im}(z)) CReLU(z)=ReLU(Re(z))+j⋅ReLU(Im(z))
实验结果:
| 模型类型 | 测试准确率 | 验证准确率 | 训练准确率 |
|---|---|---|---|
| 无激活函数 | 92.5% | 93.5% | 92.86% |
| 复数ReLU | 96.98% | 97.01% | 98.80% |
典型训练输出:
Epoch [6/6], Training Loss: 0.0046, Training Accuracy: 98.80%,
Validation Loss: 0.0059, Validation Accuracy: 97.01%
Test Accuracy: 96.98%分析:
- 复数ReLU带来显著的性能提升,准确率从92.5%跃升至96.98%
- 引入的非线性特性有效增强了网络的表达能力
- 局限性:物理实现困难,目前尚难以找到适合的光学介质来实现复数激活函数
3.6.3 非相干光传播实验
采用非相干光源进行实验,测试准确率仅达到约58%。根据理论分析,这是因为非相干光缺乏负值运算能力,极大地限制了网络的表达能力。
3.6.4 可学习传播距离实验
尝试将传播距离z设为可学习参数,实验发现:
- 高学习率:z值剧烈波动,准确率在10%附近徘徊
- 低学习率:z值几乎不变,无法起到优化作用
该方案最终被放弃。
3.7 模型复杂度分析
| 指标 | 数值 |
|---|---|
| 总参数量 | 25,626,850 |
| 单层调制参数 | 250×250 = 62,500 |
| 权重文件大小 | 1.25MB(相位调制)/ 2.50MB(相位+振幅) |
| 单次前向传播时间(CPU) | ~50ms |
| 单次前向传播时间(GPU) | ~5ms |
四、讨论与总结
4.1 主要发现
-
基准性能优越:本实现在仅相位调制的基准模型上达到93.5%的验证准确率,超过原始论文的91.75%,验证了网络架构和训练策略的有效性。
-
层数效应显著:网络深度对性能影响显著,但存在饱和效应。5层网络已能实现较高准确率,继续增加层数的边际效益有限。
-
非线性激活关键:引入复数ReLU激活函数将准确率提升至97%,表明非线性变换对光学神经网络性能至关重要,但物理实现仍面临挑战。
-
振幅调制有助益:振幅调制可带来约1%的性能提升,但需权衡参数量和实现复杂度。
4.2 技术优势
- 低能耗:光传播本身不消耗电能,仅调制片制造需要能量投入
- 高速度:光速传播实现近实时的推断能力
- 并行性:可同时处理多个输入信号
4.3 技术挑战
- 非线性实现:目前尚缺乏便捷实现光学非线性激活函数的介质
- 制造精度:多层调制片的高精度制造存在工艺挑战
- 噪声敏感:光学系统的噪声可能影响分类稳定性
4.4 未来展望
- 探索新型光学材料以实现非线性激活函数
- 优化调制片布局以降低制造难度
- 研究噪声鲁棒性提升方法
- 拓展至更复杂的分类任务
参考文献
1 Xing Lin, Yair Rivenson, Nezih T. Yardimci, et al. All-optical machine learning using diffractive deep neural networks. Science, 361(6406):1004-1008, 2018.
2 Wetzstein G, Ozcan A, Gigan S, et al. Inference in artificial intelligence with deep optics and photonics. Nature, 588:39-47, 2020.
五、程序开发
博主(博士研究生)🛰️: easy_optics,在光学检测领域可提供实验指导、程序开发、申博指导、论文指导。
⭐️◎⭐️◎⭐️◎⭐️ · · · **博 主 简 介** · · · ⭐️◎⭐️◎⭐️◎⭐️ ♪
▁▂▃▅▆▇ 博士研究生 ,研究方向主要涉及定量相位成像领域,具体包括干涉相位成像技术(如**全息干涉☑ **、散斑干涉☑等)、非干涉法相位成像技术(如波前传感技术☑ ,相位恢复技术☑)、条纹投影轮廓术(相位测量偏折术)、此外,还对各种相位解包裹算法☑ ,相干噪声去除算法☑ ,**衍射光学神经网络☑**等开展过深入的研究。
程序获取、程序开发、实验指导,软硬系统开发,科研服务,申博指导,🛰️easy_optics或如下。