目录
核心定位先分清:mini"全能均衡",nano"极致轻量化"
[1. 编码能力(SWE-Bench Pro,修复真实软件Bug)](#1. 编码能力(SWE-Bench Pro,修复真实软件Bug))
[2. 计算机使用能力(OSWorld-Verified,视觉+操作+推理)](#2. 计算机使用能力(OSWorld-Verified,视觉+操作+推理))
[3. 推理与工具调用能力](#3. 推理与工具调用能力)
[4. 运行速度](#4. 运行速度)
没有预热、没有倒计时,OpenAI又一次"静默炸场"。
3月18日,OpenAI悄然上线两款轻量级大模型------GPT-5.4 mini与GPT-5.4 nano,直接瞄准"低成本、高效率"的生产场景,填补了旗舰模型与入门模型之间的空白。不同于以往追求参数规模的升级,这次两款模型的核心差异的在于「性能定位」与「费用门槛」,精准适配不同用户的使用需求,堪称"按需选模"的典范。
今天我们就重点拆解这两款新模型,尤其是大家最关心的性能差距、费用对比,帮你快速判断哪款更适合自己(开发者/企业/普通用户都适用)。

核心定位先分清:mini"全能均衡",nano"极致轻量化"
在聊性能和费用前,先明确两款模型的核心定位------OpenAI的思路很清晰:不搞"一刀切",让不同复杂度的任务,匹配不同成本的模型,避免"杀鸡用牛刀"的资源浪费。
✅ GPT-5.4 mini:主打「性能与成本的平衡」,继承GPT-5.4旗舰版的核心能力,速度比上一代GPT-5 mini提升2倍,能独立完成复杂任务,是"轻量级里的实力派",面向消费端和开发者双重场景。
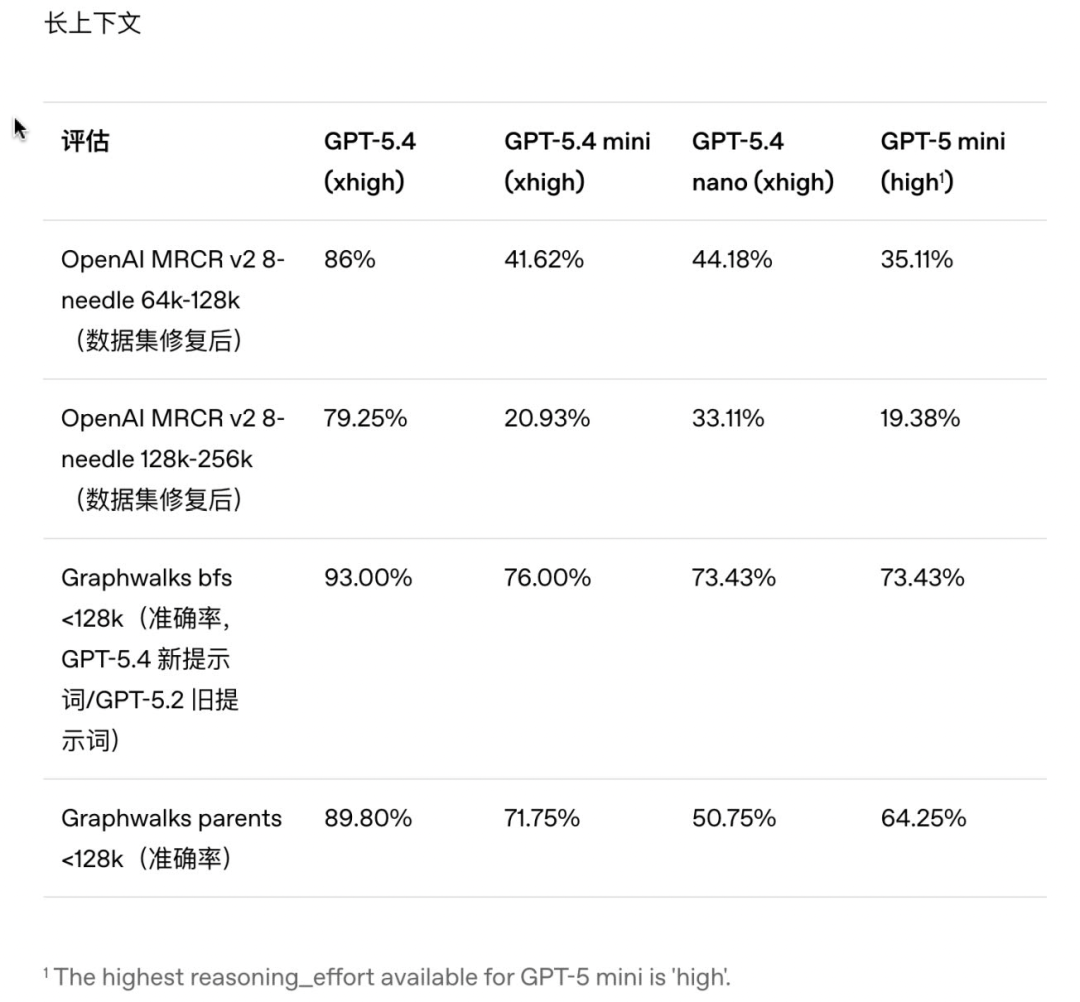
✅ GPT-5.4 nano:主打「极速低成本」,是OpenAI迄今为止最快、最便宜的模型,定位"辅助型工具",不追求全面性能,仅负责简单任务,专为开发者的子智能体场景设计。
简单说:mini能"独当一面",nano只能"打辅助";mini适配复杂执行,nano适配高频琐碎任务。
重点拆解:性能差距到底有多大?(附官方实测数据)
两款模型的性能差距,在官方公布的多项基准测试中体现得淋漓尽致,我们从「核心能力维度」做了直观对比,数据说话更有说服力👇
1. 编码能力(SWE-Bench Pro,修复真实软件Bug)
这是衡量模型工程能力的核心指标,考验模型解决真实GitHub Bug的能力:
-
GPT-5.4 mini:54.4%,距旗舰版GPT-5.4(57.7%)仅差3.3%,比上一代GPT-5 mini(45.7%)提升近9%,几乎摸到旗舰模型的天花板。
-
GPT-5.4 nano:52.4%,虽然略低于mini,但居然比上一代GPT-5 mini还高出近7%,作为轻量模型,这个成绩堪称"惊喜"。
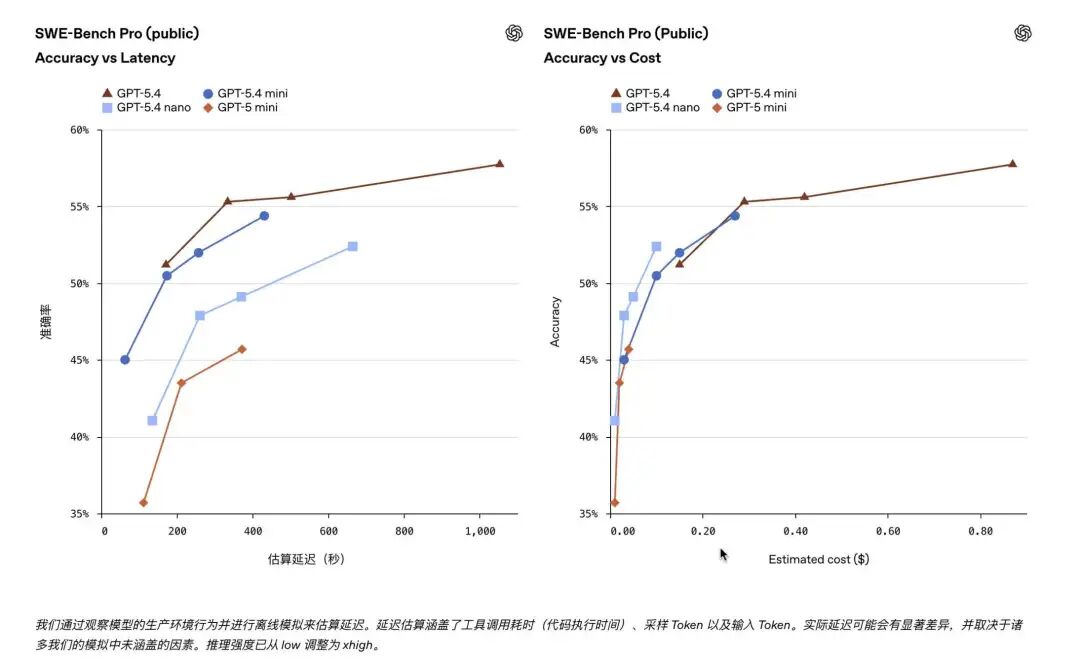
👉 结论:普通编码、调试、前端生成等任务,mini和nano都能胜任;但复杂工程修复,mini更靠谱。
2. 计算机使用能力(OSWorld-Verified,视觉+操作+推理)
这项能力决定模型能否成为"赛博助理",比如解析屏幕截图、操作鼠标键盘:
-
GPT-5.4 mini:72.1%,逼近旗舰版(75.0%),差距不到3个百分点,比上一代GPT-5 mini(42.0%)几乎翻倍,能轻松完成截图解析、UI操作等任务。
-
GPT-5.4 nano:39.0%,不仅远低于mini,甚至略低于上一代GPT-5 mini(42.0%),说明视觉推理和复杂操作是nano的"短板"。
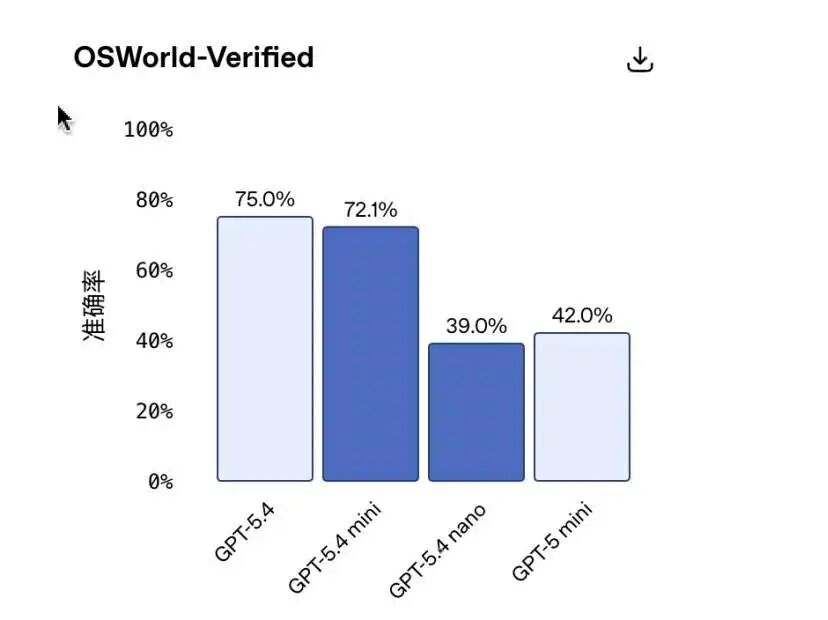
👉 结论:需要"看屏幕干活"的场景(比如AI Agent、自动化操作),只能选mini;nano完全不适合这类任务。
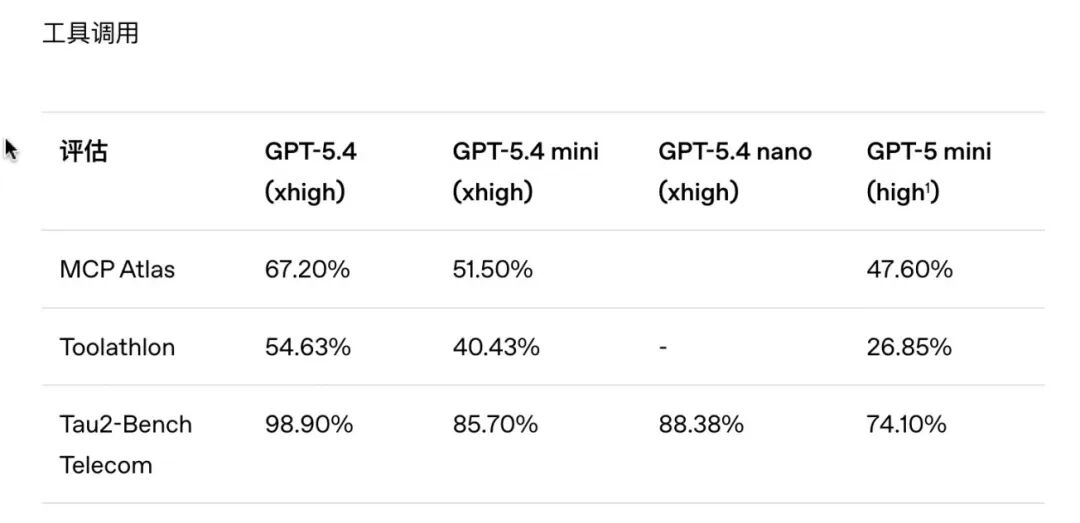
3. 推理与工具调用能力
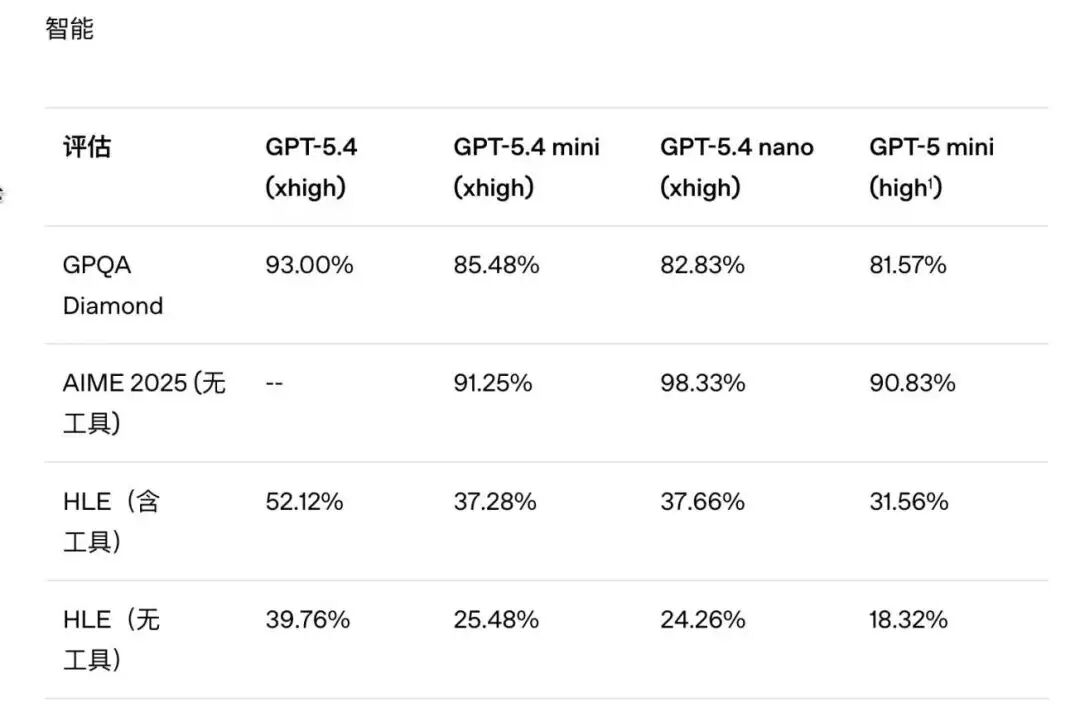
这是模型"能干活"的关键,尤其是复杂任务链的执行能力:
-
GPT-5.4 mini:在博士级推理基准GPQA Diamond中得85.5%,与旗舰版仅差7.5%;工具调用基准Toolathlon得40.4%,碾压上一代GPT-5 mini(26.9%),能独立完成多步骤工具组合任务。
-
GPT-5.4 nano:推理能力尚可(GPQA Diamond得82.8%),但工具调用能力较弱,仅适合简单的单一工具调用,无法处理复杂任务链。
4. 运行速度
-
GPT-5.4 mini:推理速度约100-150 Token/s,是上一代的2倍以上,延迟低至500ms,能实现"秒级响应"。
-
GPT-5.4 nano:推理速度高达250+ Token/s,是三款模型中最快的,适合对延迟要求极高的场景(如实时排序、日志处理)。
最关键的费用对比:差价4倍,直降1/12!
如果说性能决定"能不能用",那费用就决定"用不用得起"。两款模型的定价差距显著,且均比旗舰版GPT-5.4便宜太多,我们整理了清晰的对比表(单位:美元/百万Token):
| 模型 | 输入价格 | 输出价格 | 与旗舰版GPT-5.4比价 | 与mini比价 |
|---|---|---|---|---|
| GPT-5.4(旗舰) | 2.50 | 15.00 | 基准 | ------ |
| GPT-5.4 mini | 0.75 | 4.50 | 输出价格仅1/3 | 基准 |
| GPT-5.4 nano | 0.20 | 1.25 | 输出价格仅1/12 | 输出价格约1/4 |
补充两个关键信息,帮你算清成本账:
-
计费方式:输入(你提问的内容)和输出(模型回答的内容)分开计费,输出价格通常高于输入,这也是多数大模型的计费逻辑。
-
渠道差异:GPT-5.4 mini在API、Codex、ChatGPT三端同步开放,Free与Go用户可直接使用;GPT-5.4 nano仅通过API向开发者开放,普通用户暂时无法直接调用。
举个例子:处理100万Token的输出内容,用旗舰版需15美元,用mini仅需4.5美元,用nano仅需1.25美元,成本差距一目了然。对高频使用的开发者和企业来说,长期使用能节省大量成本。
怎么选?一张表搞定(普通用户+开发者适配)
不用纠结,根据自身需求对号入座即可,避免花冤枉钱、用错模型:
✅ 普通用户(ChatGPT日常使用):选GPT-5.4 mini,性能足够用(聊天、写文案、简单答疑),响应快,成本低,Free用户也能直接调用。
✅ 开发者(搭建AI系统/智能体):
-
复杂子任务(代码修复、截图解析、多工具调用):选GPT-5.4 mini,性价比最高,在Codex中仅消耗旗舰版30%的配额。
-
简单子任务(数据分类、日志处理、基础提取):选GPT-5.4 nano,极速低成本,适合大规模并行执行。
✅ 企业(大规模部署):采用"旗舰+mini+nano"分层架构,旗舰版负责决策规划,mini负责复杂执行,nano负责琐碎辅助,最大化降低成本。
背后的信号:OpenAI的战略重心变了
这次两款轻量级模型的发布,本质上是OpenAI的战略转向------从"追求最强模型"到"追求最实用的模型生态"。
正如OpenAI官方所说,最好的AI系统,不是用最大的模型处理所有事情,而是让旗舰模型(GPT-5.4)做决策、协调,让mini和nano做执行、辅助,形成"分工明确的协作系统"。这种思路,也正在成为整个AI行业的共识。
值得一提的是,虽然GPT-5.4 mini和nano性价比突出,但在价格上仍不及部分国产模型(如DeepSeek V3.2、Kimi-K2.5),有开发者直言"mini发布即面临竞争"。但不可否认的是,OpenAI的技术积累的让两款轻量级模型在性能稳定性上依然有优势,实际体验如何,还需要长期落地检验。
最后总结一句:GPT-5.4 mini和nano的发布,真正实现了"按需选模、按需付费",无论是普通用户还是开发者,都能找到适合自己的低成本选项。后续随着模型的进一步优化,或许会有更多场景被激活,我们也会持续关注最新动态。
你更关注哪款模型?评论区聊聊你的使用场景和选型思路~
# OpenClaude命令实战|核心控制三剑客/reasoning+/verbose+/status 实操指南
OpenClaw多Agents协作3种模式实测对比:你选对了吗?少走弯路,效率直接翻倍
# Claude 4.6迎来核心升级,实战Claude Code+OpenClaw手把手搭建自家龙虾
英伟达GTC 2026炸场!1万亿GPU生意+OpenClaw生态王炸,老黄的Agent时代来了
