导读
乒乓球、网球、羽毛球------这三大球拍运动的视觉分析一直是体育AI的热门方向,但现有数据集存在两个共性短板:只关注单一运动的球追踪,且完全忽略了球拍这一核心交互物体。球拍的姿态直接决定了击球方向和旋转,不建模球拍就无法真正理解比赛。
本文介绍的 RacketVision 是首个同时标注球位置和球拍姿态(边界框+5关键点)的多运动基准,覆盖乒乓球、网球和羽毛球共 942 场职业比赛、43.5 万帧,定义了球追踪、球拍姿态估计和球轨迹预测三个递进任务。实验揭示了一个关键发现:将球拍姿态特征朴素拼接到轨迹预测模型中,性能反而低于只用球坐标的基线;但引入 Cross-Attention 融合机制后,LSTM 模型在关键击球帧上准确利用球拍信息,最终在三项运动上全面超越纯球轨迹基线。
论文信息
- 标题:RacketVision: A Multiple Racket Sports Benchmark for Unified Ball and Racket Analysis
- 作者:Linfeng Dong, Yuchen Yang, Hao Wu, Wei Wang, Yuenan Hou, Zhihang Zhong†, Xiao Sun†
- 机构:上海人工智能实验室、浙江大学、复旦大学、中国科学技术大学
- 日期:2026 年 1 月 28 日(arXiv v3)
- DOI:arXiv:2511.17045
一、球拍运动分析缺什么?现有数据集只追球、不看拍
现有球拍运动数据集(如 TrackNet、TrackNetv2、OpenTTGames)存在两个关键限制:
- 只做单一运动的球追踪:每个数据集只覆盖一种运动,无法挖掘不同球拍运动之间的共享运动模式
- 完全缺少球拍标注:尽管球拍是决定击球方向和旋转的核心物体,但没有数据集提供球拍的位置和姿态信息
与已有数据集的规模对比:
| 数据集 | 分辨率 | 运动数 | 比赛数 | 帧数 | 标注类型 |
|---|---|---|---|---|---|
| TrackNet | 720p | 1 | 10 | 19k | 球 |
| TrackNetv2 | 720p | 1 | 19 | 78k | 球 |
| OpenTTGames | 1080p | 1 | 12 | 55k | 球 |
| RacketVision | 1080p | 3 | 942 | 435k | 球+球拍 |
RacketVision 在帧数上是此前最大数据集的 5.6 倍,且首次引入球拍姿态标注(边界框+5个关键点)。
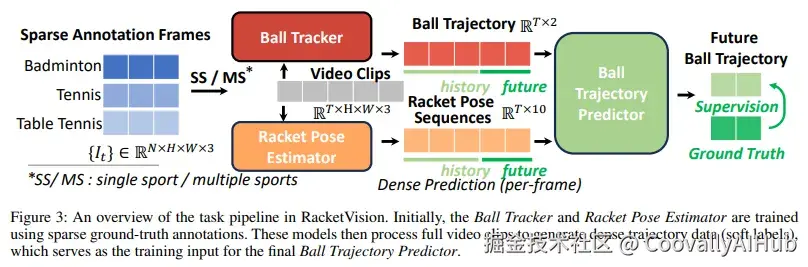
二、三项运动、三个递进任务:从感知到预测的完整流水线
数据集构成
数据来源为 YouTube 上 942 场职业比赛的广播视频,经过有效片段切分和稀疏标注(每个片段均匀采样 20% 的帧进行人工标注):
| 运动 | 比赛数 | 片段数 | 帧数 | 时长(秒) | 球标注 | 球拍标注 |
|---|---|---|---|---|---|---|
| 乒乓球 | 50 | 780 | 170,027 | 3,878 | 19,495 | 6,648 |
| 网球 | 431 | 431 | 150,399 | 4,285 | 21,544 | 7,395 |
| 羽毛球 | 461 | 461 | 114,753 | 4,592 | 23,003 | 10,578 |
| 合计 | 942 | 1,672 | 435,179 | 12,755 | 64,042 | 24,621 |
球拍标注包含每个球拍的边界框 和5个关键点(顶部、底部、手柄、左侧、右侧),用于捕捉球拍在帧中的姿态。
三个递进任务
论文定义了从低层感知到高层预测的三个相互关联的任务:
任务一:球追踪(Ball Tracking) ------预测目标帧中球的坐标和可见性。分为单帧和多帧(使用前5帧作为时序上下文)两种设置。
任务二:球拍姿态估计(Racket Pose Estimation) ------预测每个球拍的边界框和5个关键点坐标,采用单帧设置。
任务三:球轨迹预测(Ball Trajectory Prediction) ------给定历史球位置序列(可选加入球拍姿态),预测未来若干帧的球轨迹。分为短轨迹(历史20帧→预测5帧)和长轨迹(历史80帧→预测20帧)两种设置。
三个任务形成流水线:球追踪器和球拍姿态估计器先在稀疏标注帧上训练,再对完整视频生成逐帧的密集预测("软标签"),为轨迹预测器提供训练数据。
图片来源于原论文
三、多运动联合训练显著提升泛化,背景建模大幅降低定位误差
球追踪结果
论文以 TrackNetV3 为核心架构,对比了单运动(SS)与多运动(MS)训练、是否使用背景建模(BM)、单帧与多帧(#F=1 vs #F=4)的影响:
| 模型 | BM | #F | 乒乓球 mAP | 网球 mAP | 羽毛球 mAP |
|---|---|---|---|---|---|
| TrackNetV3 | ✓ | 4 | 68.3 | 68.7 | 72.5 |
| MS-TrackNetV3 | ✓ | 4 | 71.1 | 81.9 | 83.1 |
三个关键发现:
- 多运动联合训练显著提升泛化:MS-TrackNetV3 在网球 mAP 上比单运动版本提升 +19.2%(81.9 vs 68.7),羽毛球 +14.6%(83.1 vs 72.5)
- 背景建模大幅降低定位误差 :加入背景中值帧后,TrackNetV3(#F=1)的 MDE 在乒乓球降低 54.0%,网球 61.4%,羽毛球 54.8%
- 多帧输入提升检测但存在精度权衡:4帧输入提升了 Recall 和 mAP,但偶尔因运动模糊引入轻微的坐标抖动
球拍姿态估计结果
论文使用 RTMPose 作为基线,多运动训练同样带来一致提升:
| 训练方式 | 乒乓球 PCK@0.2 | 网球 PCK@0.2 | 羽毛球 PCK@0.2 |
|---|---|---|---|
| 单运动(SS) | 75.6 | 83.7 | 82.1 |
| 多运动(MS) | 81.8(+6.17%) | 89.6(+5.97%) | 88.5(+6.36%) |
一个值得关注的现象:侧面关键点远比结构关键点难检测。顶部、底部、手柄的准确率均在 92% 以上,而左侧、右侧关键点仅为 64.8%-80.1%。论文分析原因是侧边常被手部遮挡,且对快速运动和视角变化高度敏感。

图片来源于原论文
四、消融实验:朴素拼接球拍特征反而有害,Cross-Attention 融合才是关键
轨迹预测任务是本文最核心的实验,也揭示了关于多模态融合的关键洞察。
三种输入与融合方式
- Ball-Only:仅输入历史球坐标,纯单模态基线
- Concat Fusion:将球坐标和球拍姿态的嵌入拼接后送入模型
- Cross-Attention Fusion:球轨迹序列作为 Query,球拍姿态序列作为 Key/Value,通过注意力机制动态加权
短轨迹预测结果(历史20帧→预测5帧)
| 模型 | 输入 | 融合方式 | 乒乓球 ADE | 乒乓球 FDE | 网球 ADE | 网球 FDE | 羽毛球 ADE | 羽毛球 FDE |
|---|---|---|---|---|---|---|---|---|
| LSTM | Ball | - | 41.9 | 64.0 | 23.8 | 37.6 | 37.5 | 60.7 |
| LSTM | Ball+Racket | Concat | 58.1 | 86.6 | 29.3 | 45.3 | 45.7 | 70.7 |
| LSTM | Ball+Racket | CrossAttn | 38.3 | 60.4 | 22.8 | 35.7 | 37.0 | 59.3 |
长轨迹预测结果(历史80帧→预测20帧)
| 模型 | 输入 | 融合方式 | 乒乓球 ADE | 乒乓球 FDE | 网球 ADE | 网球 FDE | 羽毛球 ADE | 羽毛球 FDE |
|---|---|---|---|---|---|---|---|---|
| LSTM | Ball | - | 113.9 | 184.3 | 62.5 | 108.7 | 118.7 | 194.7 |
| LSTM | Ball+Racket | Concat | 139.9 | 198.9 | 76.8 | 125.0 | 134.5 | 203.3 |
| LSTM | Ball+Racket | CrossAttn | 101.3 | 161.3 | 55.5 | 94.7 | 114.6 | 187.6 |
三个核心发现
1. 朴素拼接(Concat)一致地损害性能。在 LSTM 和 Transformer 两种骨干上,Concat 融合的 ADE/FDE 均差于纯 Ball-Only 基线。原因是数据集中大量样本处于球在空中飞行状态,此时球拍信息不相关甚至是噪声,Concat 方式无差别地融合了这些无用信息,干扰了轨迹动力学的学习。
2. Cross-Attention 在关键击球帧上表现优异。Cross-Attention 机制让模型学会在击球瞬间加大球拍信息的权重,在球飞行过程中自动忽略球拍信号。从可视化结果看,Cross-Attention 模型能利用球拍姿态准确预测击球后的转向点和飞行方向。
3. 整体提升幅度受数据构成影响。由于短轨迹样本中大量是球在飞行中的片段(无球拍交互),Cross-Attention 在这些样本上表现与 Ball-Only 相当,整体统计改进不算巨大;但在有击球事件的关键帧上,改进显著。

图片来源于原论文
五、总结与思考
RacketVision 的核心贡献是填补了球拍运动分析中"只追球不看拍"的空白,提供了首个包含球拍姿态标注的多运动基准。多运动联合训练一致提升了球追踪和球拍姿态估计的泛化能力,而轨迹预测实验则揭示了一个有实际指导意义的结论:多模态数据的价值高度依赖于融合架构------朴素拼接不如不融合,Cross-Attention 才能正确地在关键时刻利用球拍信息。
局限性方面:
- 稀疏标注策略:仅标注 20% 的帧,虽然降低了标注成本,但可能遗漏快速运动中的关键帧
- 球拍侧面关键点难题:左右关键点准确率(64.8%-80.1%)与顶部/底部/手柄(>92%)差距明显,遮挡和视角变化仍是待解决的挑战
- 轨迹预测的统计改进有限:Cross-Attention 的优势集中在击球帧,而大量飞行帧稀释了整体指标,未来可能需要针对事件帧的专门评估协议