ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT
作者:Omar Khattab、Matei Zaharia(斯坦福)
会议:SIGIR 2020
这篇是 神经 信息检索 (Neural IR )领域的里程碑之一 ,提出了 Late Interaction(延迟交互) 架构,解决了 BERT 检索系统 精度与效率不可兼得 的问题。

目录
[一、ColBERT 之前的三类搜索模型](#一、ColBERT 之前的三类搜索模型)
[1 Representation-based Model(表示式模型)](#1 Representation-based Model(表示式模型))
[2 Interaction-based Model(交互式模型)](#2 Interaction-based Model(交互式模型))
[3 Deep LM Interaction Model(BERT类)](#3 Deep LM Interaction Model(BERT类))
[二、ColBERT 的核心思想](#二、ColBERT 的核心思想)
[Step1 Query编码](#Step1 Query编码)
[Step2 Document编码](#Step2 Document编码)
[Step3 Late Interaction](#Step3 Late Interaction)
[1 保留 token-level matching](#1 保留 token-level matching)
[2 可以预计算 document](#2 可以预计算 document)
[3 可以用 ANN 检索](#3 可以用 ANN 检索)
[1 embedding降维](#1 embedding降维)
[2 token filtering](#2 token filtering)
[3 Query augmentation](#3 Query augmentation)
[4 embedding normalization](#4 embedding normalization)
[1 Reranking模式](#1 Reranking模式)
[2 End-to-end retrieval](#2 End-to-end retrieval)
[1 MS MARCO](#1 MS MARCO)
[2 TREC CAR](#2 TREC CAR)
[1 存储巨大](#1 存储巨大)
[2 ANN复杂](#2 ANN复杂)
[3 latency仍然高于BM25](#3 latency仍然高于BM25)
[ColBERT v2(还没深入看)](#ColBERT v2(还没深入看))
主要图片解释
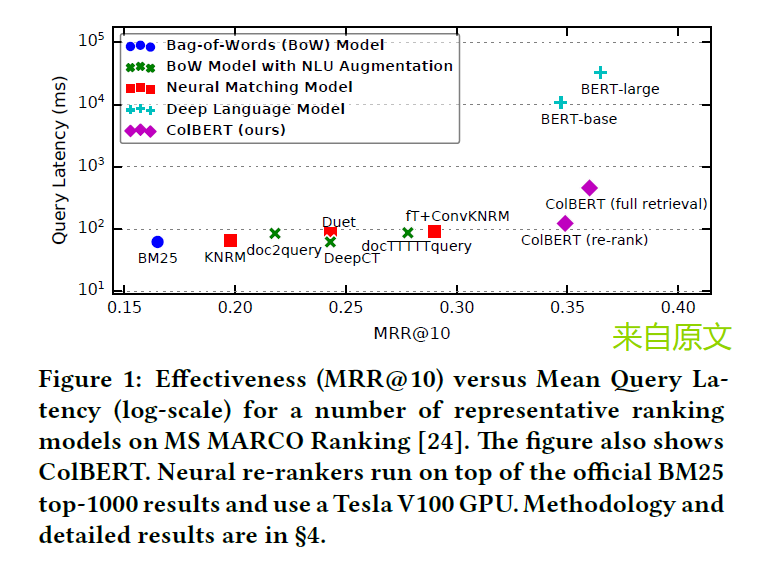
图1展示了不同信息检索模型在检索效果与查询延迟之间的权衡关系 。横轴表示搜索效果(通常使用 MRR@10 衡量),数值越大说明检索结果越准确;纵轴表示查询延迟(Latency),反映系统完成一次查询所需要的时间。传统基于词频统计的方法,如 BM25 ,具有极低的查询延迟,因此在大规模搜索系统中被广泛应用,但其语义理解能力有限,检索效果相对一般。深度学习方法尤其是基于 BERT 的交互模型,能够显著提升语义匹配能力,从而获得更好的检索效果,但由于每个 query--document 对都需要进行一次完整的 Transformer 推理,其计算成本极高,导致查询延迟大幅增加。图中的 ColBERT 位于两者之间的位置,它在保持接近 BERT 检索效果的同时,将查询延迟显著降低,从而证明该方法在效果与效率之间实现了更好的平衡。
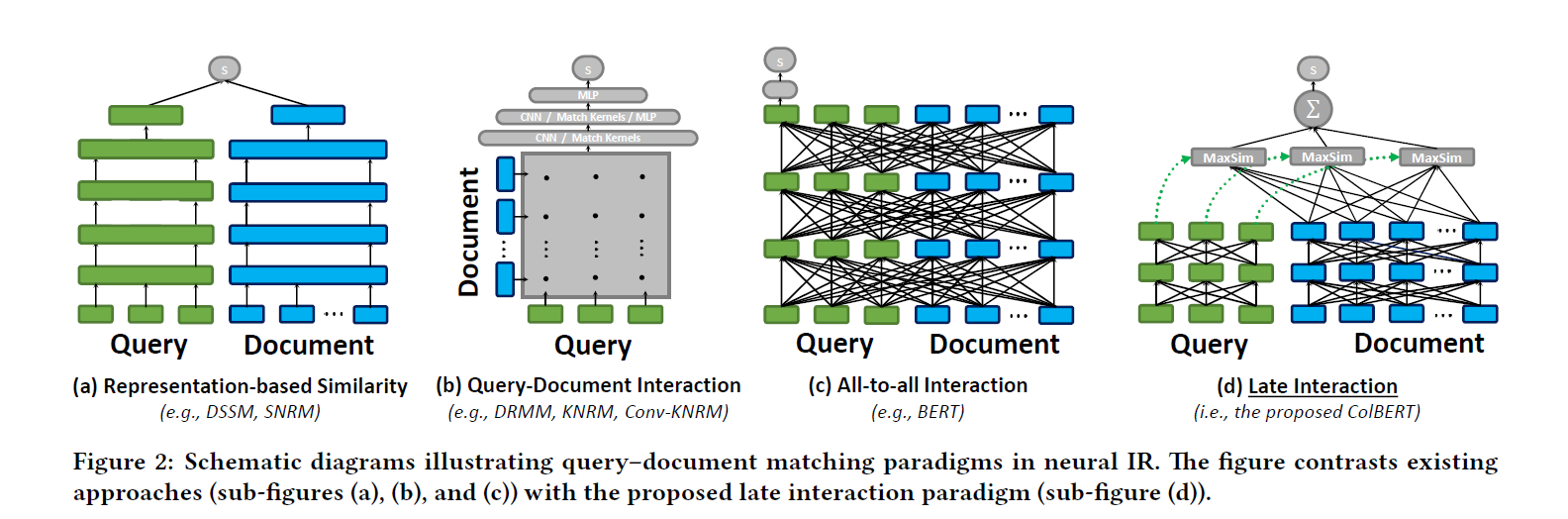
图2通过结构示意图对比了几类典型的神经信息检索模型架构,包括表示式模型(representation-based)、交互式模型(interaction-based)、BERT 交互模型以及 ColBERT 的 Late Interaction 结构。表示式模型通过将 Query 和 Document 分别编码为单个向量,然后计算向量相似度完成匹配,因此计算效率很高,但由于信息被压缩到单一向量中,细粒度语义匹配能力有限。交互式模型则在 token 级别构建 Query 与 Document 的交互矩阵,再通过神经网络进行匹配建模,从而获得更丰富的匹配信号,但计算成本增加。BERT cross-encoder 进一步将 Query 与 Document 拼接后输入 Transformer,使模型能够直接学习复杂的跨文本语义关系,因此效果最佳,但推理成本也最高。ColBERT 的 Late Interaction 机制则在两者之间取得折衷,它首先分别对 Query 与 Document 的 token 进行编码,然后在向量空间中进行 token 级相似度匹配,从而既保留了细粒度语义匹配能力,又避免了每个 query--document 对都重新运行 BERT 的计算开销。
|--------------------------|-----------------------|---------|---------|
| 模型类别 | 核心思想 | 优点 | 局限 |
| Representation-based | 文档和查询各自编码为单向量 | 检索速度快 | 语义表达能力弱 |
| Interaction-based | token 级交互矩阵建模 | 匹配信息丰富 | 计算量较大 |
| BERT Cross-Encoder | Query 与 Document 拼接编码 | 效果最好 | 推理极慢 |
| ColBERT Late Interaction | token embedding 后再匹配 | 效果与效率兼顾 | 需要向量索引 |
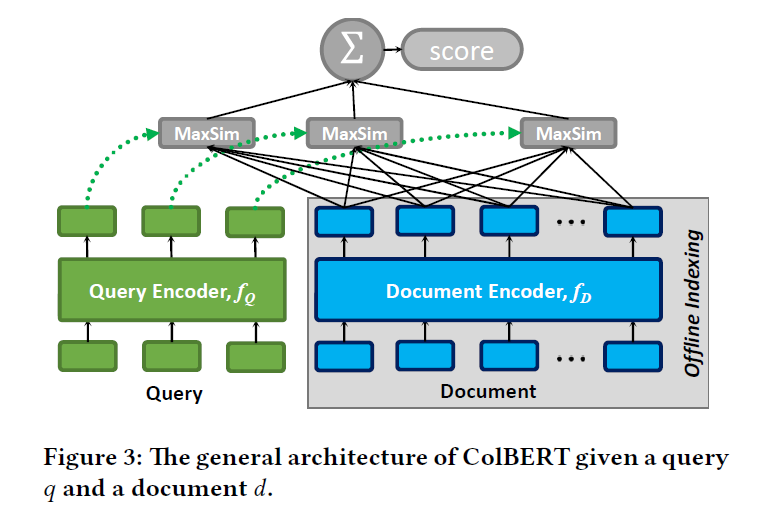
图3展示了 ColBERT 的完整模型结构。与传统 cross-encoder 不同,ColBERT 采用双编码器结构:Query 与 Document 分别输入到共享参数的 BERT 编码器中,并在每个 token 位置生成上下文化的 embedding 表示。与仅使用单一向量表示文本不同,ColBERT 保留了每个 token 的向量表示,从而能够在后续匹配阶段进行细粒度语义计算。在检索阶段,系统通过一种称为 MaxSim(maximum similarity) 的机制计算 Query 与 Document 的相关性:对于 Query 中的每个 token embedding,寻找 Document 中最相似的 token embedding,并将这些最大相似度累加得到最终相关性得分。这种设计使得 Document 的向量可以在离线阶段提前计算并建立索引,而查询阶段只需进行向量相似度计算,从而显著降低在线推理成本。
一、ColBERT 之前的三类搜索模型
1 Representation-based Model(表示式模型)
核心思想:
先把 Query 和 Document 分别编码成一个向量,再计算相似度。
公式思想:
score(q,d) = sim( embedding(q), embedding(d) )
常见方法:
- DSSM:这是一个用于语义匹配的双塔深度模型,通过将查询和文档分别编码为稠密向量,并计算其相似度来实现检索。
- SNRM:这是一个学习高维稀疏向量表示的神经检索模型,旨在模拟传统检索中的特征权重(如TF-IDF),同时具备可解释性。
特点:
- 可以 预计算 document embedding
- 检索速度非常快
- 但表达能力弱
因为:
Query → 1个向量
Doc → 1个向量
大量信息被压缩。
2 Interaction-based Model(交互式模型)
核心思想:
不先压缩成单向量,而是直接建模 Query 和 Document 的词级交互。
例如:
构建一个 interaction matrix
query_word_i vs document_word_j
例如:
|----|----------|----------|----------|
| | doc1 | doc2 | doc3 |
| q1 | sim | sim | sim |
| q2 | sim | sim | sim |
然后用
- CNN
- Kernel pooling
- MLP
学习匹配。
代表模型:
- DRMM
- KNRM
- ConvKNRM
- Duet
优点:
- 捕获 细粒度匹配
缺点:
- 每个 query-doc 都要计算
- 无法预计算 document
- 计算成本高
3 Deep LM Interaction Model(BERT类)
这是 interaction model 的升级版。
核心思想:
把 Query 和 Document 拼接输入 Transformer:
CLS query tokens SEP document tokens
然后:
BERT → relevance score
例如:
- BERT ranker
- DuoBERT
优点:
- 语义理解能力非常强
- 当前效果最好
缺点:
计算量爆炸
因为:
每个 query-doc pair 都要跑一遍 BERT
如果:
query = 1
document = 1000
就要:
跑1000次BERT
延迟很大。
|----------------------|--------------------------|-------------|-----------|--------|-------------|
| 模型类型 | 核心思想 | 是否预计算文档 | 计算复杂度 | 精度 | 代表模型 |
| Representation-based | Query / Doc 各变成一个向量再算相似度 | ✅ 可以 | 低 | 较低 | DSSM, SNRM |
| Interaction-based | 构建 Query-Doc 词级交互矩阵 | ❌ 不可以 | 中 | 较高 | DRMM, KNRM |
| Deep LM Interaction | Query+Doc 一起输入 BERT | ❌ 不可以 | 非常高 | 最高 | BERT ranker |
二、ColBERT 的核心思想
作者提出一种新架构:
Late Interaction
核心思想:
保留 token-level 交互,但推迟交互。
架构思想:
query encode separately document encode separately then interaction
而不是:
query + document → BERT
三、ColBERT整体架构
论文结构如下:
Query Encoder (BERT) Document Encoder (BERT) ↓ token embeddings ↓ Late Interaction (MaxSim) ↓ score
具体流程:
Step1 Query编码
输入:
CLS Q q1 q2 q3 ...
得到:
Eq = {v1, v2, v3 ...}
每个 token 一个向量。
Step2 Document编码
输入:
CLS D d1 d2 d3 ...
得到:
Ed = {u1, u2, u3 ...}
每个 token 一个向量。
重要:
document embedding 可以提前计算并存储。
Step3 Late Interaction
核心公式:
S_{q,d} = \\sum_{i \\in \|E_q\|} \\max_{j \\in \|E_d\|} E_{q_i} \\cdot E_{d_j}
含义:
(1)S_{q,d}表示:Query q 和 Document d 的相关性得分,数值越大,文档越相关
(2)Eq 和E_d表示:
E_q → Query 的 token embedding 集合
E_d → Document 的 token embedding 集合
在 ColBERT 中:
- Query 不再是 一个向量
- Document 也不再是 一个向量
而是:
每个 token → 一个向量
例如:
Query:
"machine learning"
→ token embeddings
E_q = e_machine , e_learning
Document:
"deep learning methods for machine intelligence"
E_d = e_deep, e_learning, e_methods, ...
(3)E_{q_i}
表示:
Query 第 i 个 token 的 embedding
例如:
E_q = q1, q2, q3
则:
E_{q_1}
E_{q_2}
E_{q_3}
(4)E_{d_j}
表示:
Document 第 j 个 token 的 embedding
例如:
E_d = d1, d2, d3, d4, ...
(5)E_{q_i} \\cdot E_{d_j}
表示:
两个 embedding 的点积
也可以理解为:
cosine similarity
因为 ColBERT 训练时会 L2 normalize embedding。
所以:
dot product ≈ cosine similarity
流程:
query token → 找最相似doc token例如:
query: apple price
doc: apple stock market price today
apple → apple
price → price这叫:MaxSim
四、优势
Late Interaction 的关键优势:
1 保留 token-level matching
dual encoder:
query → single vector
doc → single vector信息丢失很严重哈。
ColBERT:
token-level interaction精度更高。
2 可以预计算 document
document 只编码一次。
offline:
doc → BERT → token vectors在线只需要:
query encode
+
vector similarity3 可以用 ANN 检索
作者使用:FAISS 做两阶段检索:
Stage1:ANN search candidate tokens
Stage2:re-rank documents
五、工程层面
论文在工程层面做了很多优化:
1 embedding降维
BERT hidden size:768
ColBERT压缩成:128
减少内存。
2 token filtering
去掉:标点符号 token,减少向量数量。
3 Query augmentation
一个我一开始看不懂的设计:query padding:mask,让模型学会 query expansion。
4 embedding normalization
所有向量:L2 normalize
这样:dot product = cosine similarity 计算更快。
六、检索流程
ColBERT有两种用法。
1 Reranking模式
流程:
BM25 → top1000 docs ColBERT rerank
步骤:
query encode
load doc embeddings
compute MaxSim
2 End-to-end retrieval
直接 ANN 搜索。
步骤:
1.FAISS token search
2.找到候选文档
3.ColBERT re-ranking
七、实验结果
数据集:
1 MS MARCO
规模:
9M passages
1M queries
指标:
MRR@10
2 TREC CAR
Wikipedia retrieval。
实验结论
精度
ColBERT
MRR@10 ≈ 34.9
接近:
BERT reranker ≈ 36
速度
相比 BERT reranker:
170× faster
FLOPs:
14000× less
八、消融实验
作者做了消融实验:
如果把max换成:average效果明显下降。
原因:query token 的语义匹配是稀疏的
例如:query: iphone battery issue
document中:battery才是关键。
MaxSim可以突出:best matching evidence
九、ColBERT的缺点
论文也提到了问题:
1 存储巨大
因为:每个token一个向量,而不是一个文档一个向量。
例如:document = 200 tokens,存储:200 vectors,比 DPR(Dense Passage Retrieval:Q,D单向量) 大很多。
2 ANN复杂
因为:token-level index,不是 document-level。
3 latency仍然高于BM25
BM25:几十毫秒
ColBERT:几百毫秒
十、ColBERT对后续研究的影响
这篇论文直接影响了 现代RAG系统。
很多系统是:BM25 → ColBERT rerank
或者:DPR → ColBERT rerank
后来发展出:
ColBERT v2(还没深入看)
这里的github源码在如下链接: https://github.com/stanford-futuredata/ColBERT
改进:
- Residual compression
- storage reduction
- faster ANN
十一、ColBERT在RAG中的地位
在 RAG 检索架构中:
|---------|--------|
| 模型 | 作用 |
| BM25 | 快速召回 |
| DPR | 语义召回 |
| ColBERT | 精细排序 |
很多工业架构:
Stage1 recall
Stage2 rerank
ColBERT就是:
state-of-the-art reranker
十二、总结
ColBERT提出了一个非常关键的思想:
token-level interaction + document precomputation
使得检索精度和速度都处于较高水平。噢耶
(WenJGo^_^全文完)