(一) 库函数模拟实现
以下是 C/C++ 面试中最高频的 7 个库函数,涵盖内存操作、字符串操作两大类,每个函数均包含「功能介绍」「函数原型」「核心考点」「完整实现」「面试注意」五个模块,是手写实现的核心重点。
1. strlen
功能介绍 :计算字符串的有效长度,不包含字符串结束符 '\0',遍历到 '\0' 时立即停止计算。
函数原型
size_t strlen(const char *str);参数说明:
size_t:返回值类型,本质是unsigned int(无符号整型),用于表示长度 / 大小;str:传入的字符串指针,指向待计算长度的字符串首地址;const:修饰字符串指针,表明函数内部不会修改原字符串内容,是对输入参数的只读保护。
返回值: size_t 类型(无符号整型),返回字符串的有效字符数(不包含 '\0')。
完整实现
版本 1:基础循环版(最易理解,面试保底写法)
size_t my_strlen(const char* str)
{
assert(str);
size_t cnt = 0;
const char* cur = str;
while (*cur != '\0')
{
cnt++;
cur++;
}
return cnt;
}版本 2:递归版(考察递归思维,无额外变量)
size_t my_strlen_rec(const char* str)
{
assert(str);
if (*str == '\0')
return 0;
return 1 + my_strlen_rec(str + 1);
}版本 3:指针减法版(效率最优,面试加分写法)
size_t my_strlen_v2(const char* str)
{
assert(str);
const char* start = str;
while (*str != '\0') {
str++;
}
return str - start;
}面试注意
返回值是 size_t 无符号整数,无符号相减不会出现负数,会变成一个极大的正数,容易导致判断错误。
【例子】
strlen("a") - strlen("abc")本来等于 -2,但无符号会变成很大的数,所以>0结果为真。
必须对指针做非空判断,传入 nullptr 会直接崩溃。
【例子】
strlen(NULL);直接崩溃。
空字符串 "" 长度为 0,符合预期。
【例子】
strlen(""):空字符串仅含 '\0',返回 0(符合预期);strlen(nullptr):传入空指针,程序直接崩溃(必须用assert或条件判断保护)。
与 sizeof 区别:strlen 是函数,运行时计算;sizeof 是运算符,编译时计算。
效率:指针减法版 > 循环版 > 递归版,递归有调用开销且可能栈溢出。
2. strcpy
功能: 字符串拷贝,把源字符串完整拷贝到目标空间,包含 '\0'
函数原型 :
char *strcpy(char *dest, const char *src);参数说明:
- dest:目标字符串指针,要写入
- src:源字符串指针,只读
- const 保护源数据
返回值: char* 类型,返回目标字符串 dest 的起始地址,支持链式调用。
模拟实现
char* my_strcpy(char* dest, const char* src)
{
assert(dest && src);
char* start = dest;
while (*src != '\0')
{
*dest = *src;
dest++;
src++;
}
*dest = '\0';
return start;
}优化版
char* my_strcpy(char* dest, const char* src)
{
assert(dest && src);
char* start = dest;
while (*src)
{
*dest++ = *src++;
}
*dest = '\0';
return start;
}面试注意
必须把 '\0' 一起拷贝,否则字符串没有结束标志。
源字符串必须以 '\0' 结尾,否则会内存越界。
【例子】
char src[] = {'a','b','c'};没有 '\0',会一直往后乱拷贝。
目标空间必须足够大、可修改,不能是常量字符串。
【例子】
char *dest = "hello";是常量,不能写入,一拷贝就崩溃。
必须对 dest 和 src 都做空指针判断。
【例子】
strcpy(NULL, "abc");直接崩溃。
返回目标起始地址,方便链式调用。
目标空间不足、常量字符串赋值、源字符串无 '\0' 都会导致崩溃或越界。
【例子】
char dest[3]; strcpy(dest, "hello world");空间太小,越界崩溃。
3. strncpy
功能 :带长度限制的字符串拷贝,最多拷贝n个字符从源字符串到目标空间;源字符串长度 < n 时补'\0',源字符串长度 ≥ n 时不补'\0'。
函数原型:
char *strncpy(char *dest, const char *src, size_t n);参数说明:
- dest:目标字符串指针,要写入(需保证足够内存空间容纳
n个字符); - src:源字符串指针,只读;
- const:修饰 src,保护源数据不被修改,体现代码健壮性;
- n:最大拷贝字符数(无符号整数
size_t,避免负数); - 返回值:目标字符串起始地址,支持链式调用。
返回值: char* 类型,返回目标字符串 dest 的起始地址。
模拟实现:
char* my_strncpy(char* dest, const char* src, size_t n)
{
assert(dest && src);
char* start = dest;
while (n > 0 && *src != '\0')
{
*dest = *src;
dest++;
src++;
n--;
}
while (n > 0)
{
*dest = '\0';
dest++;
n--;
}
return start;
}优化版:
char* my_strncpy(char* dest, const char* src, size_t n)
{
assert(dest && src);
char* start = dest;
while (n-- && *src)
{
*dest++ = *src++;
}
while (n-- > 0)
{
*dest++ = '\0';
}
return start;
}面试注意
长度超过 n 时不会自动补 '\0',直接使用 printf/strlen 会越界。
【例子】
strncpy(dest, "abcdef", 3);只拷贝abc,没有 '\0',打印乱码。
长度不足 n 时,剩余空间全部补 '\0'。
【例子】
strncpy(dest, "ab", 5);拷贝ab\0\0\0。
目标空间必须 ≥ n,否则越界崩溃。
目标不能是常量字符串,否则崩溃。
n = 0 时不拷贝任何内容,直接返回目标地址。
与 strcpy 区别:strncpy 有限制、更安全,但需要手动处理结束符。
【例子】
strcpy会自动带 '\0',strncpy拷满 n 个就停,不自动加结束符。
4. strstr
功能: 在一个字符串中查找子串第一次出现位置找到返回地址,找不到返回 NULL
函数原型
char *strstr(const char *str1, const char *str2);参数说明:
- str1:主串(被查找)
- str2:子串(要查找的串)
- 都加 const,不修改数据
返回值: char* 类型
- 找到子串:返回
str2在str1中第一次出现的起始地址; - 未找到子串:返回
NULL; - 特殊情况:若
str2是空字符串"",返回str1的起始地址(库函数规范)。
模拟实现:
char* my_strstr(const char* str1, const char* str2)
{
// 空指针校验
assert(str1 && str2);
if (*str2 == '\0')
return (char*)str1;
const char* cur1 = str1;
const char* cur2 = str2;
const char* ret = str1;
while (*ret != '\0' && *cur2 != '\0')
{
cur1 = cur;
cur2 = str2;
while (*cur1 != '\0' && *cur2 != '\0' && *cur1 == *cur2)
{
cur1++;
cur2++;
}
if (*cur2 == '\0')
return (char*)ret;
if (*cur1 == '\0')
return NULL;
ret++;
}
return NULL;
}面试注意:
子串为空字符串时,必须返回主串起始地址(库函数规范)。
主串为空、子串非空时,返回 NULL。
必须对 str1 和 str2 做空指针判断,否则崩溃。
匹配规则是「第一次出现的位置」,不是所有位置。
【例子】
strstr("ababc", "ab");返回第一个 'a' 的地址,不是第三个。
区分「返回地址」和「返回索引」:函数返回的是指针地址,不是下标。
【例子】
strstr("abcdef", "cd") - "abcdef"等于 2(下标)。
暴力匹配法是面试基础要求,KMP 算法是加分项(不用写但要懂原理)。
【例子】面试官问「有没有更高效的写法」,可以说 KMP 算法(利用部分匹配表减少回溯)。
5. strcmp
功能介绍:比较两个字符串的内容(按 ASCII 码值逐字符比较),返回比较结果;区分大小写,直到遇到不同字符或 '\0' 为止。
函数原型
int strcmp(const char *str1, const char *str2);参数说明
str1:第一个待比较的字符串指针,const修饰;str2:第二个待比较的字符串指针,const修饰;const:修饰两个参数,表明函数内部不修改字符串内容。
返回值: int 类型,返回值规则(面试必记):
str1 < str2:返回 负数 (通常是第一个不同字符的 ASCII 差值:str1[i] - str2[i]);str1 == str2:返回 0;str1 > str2:返回 正数 (通常是第一个不同字符的 ASCII 差值:str1[i] - str2[i])。
完整实现
int my_strcmp(const char* str1, const char* str2)
{
assert(str1 && str2);
while (*str1 != '\0' && *str2 != '\0' && *str1 == *str2)
{
str1++;
str2++;
}
return *str1 - *str2;
}面试注意
比较规则:按 ASCII 码值 逐字符比较,区分大小写(大写字母 ASCII < 小写字母)。
【例子】
strcmp("Abc", "abc")返回负数('A'=65 < 'a'=97),strcmp("abc", "Abc")返回正数。
返回值是「差值」而非固定的 -1/0/1(不同编译器可能有差异,但核心是正负 / 0)。
【例子】
strcmp("a", "c")返回 -2(97-99),strcmp("c", "a")返回 2,strcmp("abc", "abc")返回 0。
比较到第一个不同字符就停止,无需比较后续字符。
空字符串规则:strcmp("", "a") 返回负数,strcmp("a", "") 返回正数,strcmp("", "") 返回 0。
必须对 str1 和 str2 做空指针判断,否则崩溃。
与 strncmp 的区别(拓展):strcmp 无长度限制,strncmp 最多比较 n 个字符。
6. memcpy
功能介绍 :内存拷贝,从源内存地址 src 拷贝 n 个字节到目标内存地址 dest;不处理内存重叠,仅适用于无重叠的内存拷贝场景。
函数原型
void *memcpy(void *dest, const void *src, size_t n);参数说明
dest:目标内存地址指针,可写入;src:源内存地址指针,只读,const修饰;n:要拷贝的字节数,类型为size_t(无符号整型);void*:通用指针类型,支持任意数据类型(字符、整型、结构体等)的拷贝。
返回值: void* 类型,返回目标内存 dest 的起始地址,支持链式调用。
完整实现
void* my_memcpy(void* dest, const void* src, size_t n)
{
assert(dest && src);
char* d = (char*)dest;
const char* s = (const char*)src;
while (n--) {
*d++ = *s++;
}
return dest;
}面试注意
按字节拷贝,支持任意数据类型(字符、数组、结构体等)。
不处理内存重叠,重叠拷贝会导致数据错乱。
【例子】
int arr[5] = {1,2,3,4,5}; memcpy(arr+1, arr, 8);本意想拷贝 1,2 到 2,3 位置,结果变成 1,1,1,4,5(数据重叠覆盖)。
必须对 dest 和 src 做空指针判断,否则崩溃。
n 是字节数,不是元素个数,计算错误会导致拷贝不完整 / 越界。
【例子】拷贝 3 个 int 元素,
n要传3*sizeof(int),不是 3。
返回目标起始地址,支持链式调用。
与 strcpy 区别:memcpy 按字节拷贝(无 '\0' 限制),strcpy 按字符串拷贝(遇 '\0' 停止)。
【例子】拷贝含 '\0' 的二进制数据,用
memcpy;拷贝字符串,用strcpy。
7. memmove
功能介绍 :内存拷贝(增强版),从源内存地址 src 拷贝 n 个字节到目标内存地址 dest;处理内存重叠 ,是 memcpy 的安全版本。
函数原型:
void *memmove(void *dest, const void *src, size_t n);参数说明
dest:目标内存地址指针,可写入;src:源内存地址指针,只读,const修饰;n:要拷贝的字节数,类型为size_t(无符号整型);void*:通用指针类型,支持任意数据类型拷贝。
返回值: void* 类型,返回目标内存 dest 的起始地址。
完整实现
void* my_memmove(void* dest, const void* src, size_t n)
{
assert(dest && src);
char* d = (char*)dest;
const char* s = (const char*)src;
if (d < s)
{
while (n--) *d++ = *s++;
}
else
{
d += n - 1;
s += n - 1;
while (n--)
{
*d = *s;
d--;
s--;
}
}
return dest;
}面试注意
核心优势:处理内存重叠,拷贝更安全(面试必问与 memcpy 的区别)。
【例子】
int arr[5] = {1,2,3,4,5}; memmove(arr+1, arr, 8);正确拷贝为 1,1,2,4,5。
拷贝逻辑分两种:
-
目标地址 < 源地址:从前向后拷贝(和 memcpy 一样);
-
目标地址 > 源地址:从后向前拷贝(避免覆盖未拷贝的源数据)。
【例子】
dest=arr+1,src=arr,目标地址更大,从后向前拷贝第二个 int(2),再拷贝第一个 int(1)。
按字节拷贝,支持任意数据类型,n 是字节数不是元素数。
必须做空指针判断,否则崩溃。
与 memcpy 的关系:memmove 是 memcpy 的超集,无重叠时两者效果一致,有重叠时优先用 memmove。
【例子】面试官问「什么时候用 memcpy,什么时候用 memmove」,回答:无重叠用 memcpy(效率略高),有重叠用 memmove(安全)。
返回目标起始地址,支持链式调用。
(二) 自定义类型
1. 结构体内存对齐
对齐规则
- 第一个成员 :直接从偏移量
0处开始存放。 - 其他成员 :对齐到
min(自身类型大小, 默认对齐数)的整数倍偏移量处。 - 结构体总大小 :必须是该结构体最大对齐数(所有成员对齐数的最大值)的整数倍。
- 嵌套结构体 :嵌套的结构体成员,对齐到其内部最大成员的对齐数;最终结构体总大小,仍需对齐到外层结构体的最大对齐数。
解题步骤
- 确定对齐数 :对每个成员,计算其对齐数 =
min(成员类型大小, 默认对齐数)。 - 分配内存位置 :
- 第一个成员从偏移
0开始,占用的格子数 = 成员类型本身的字节数(1 字节 = 1 个格子)。 - 后续成员从「对齐数的整数倍」偏移量处开始,占用的格子数 = 成员类型本身的字节数。
- 第一个成员从偏移
- 计算总大小 :列出所有成员的对齐数,取最大值作为该结构体的最大对齐数;最终结构体大小必须是这个最大对齐数的整数倍。
【例子】
struct S1 { double d; char c; int d; };解析:
拓展:
struct S2 { double a; char b; struct S1; };解析:

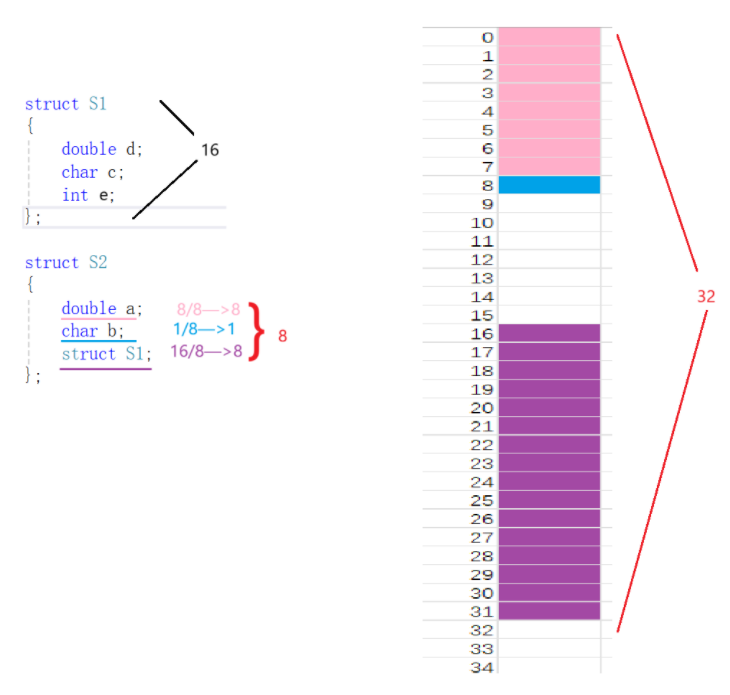
核心考点
- 设计目的 :以空间换时间,通过内存对齐减少 CPU 读取次数,提升数据访问效率。
- 核心能力:熟练手动计算任意结构体的内存大小,理解填充字节的作用。
- 优化技巧:调整成员顺序(将小类型成员集中放置)可有效减少填充,节约内存空间。
- 平台差异 :不同编译器默认对齐数不同,VS 默认对齐数为
8,Linux 默认对齐数为4。
拓展:
为什么要对齐了?
内存对齐的核心目的是以 "少量空间浪费" 换 "CPU 读取效率提升"(空间换时间):
- CPU 并非逐字节读取内存,而是按固定大小的 "内存块"(如 4/8 字节)批量读取;
- 若数据未对齐(跨内存块),CPU 需多次读取并拼接数据,效率极低;
- 对齐规则让数据落在内存块的整数倍偏移处,CPU 单次即可读取完整数据,大幅提升访问速度;
- 结构体对齐是编译器自动实现的,代价是产生少量填充字节,牺牲少量内存空间。
如何修改默认对齐数?
修改默认对齐数用**
#pragma pack(n)**指令:
- **
#pragma pack(1):**取消所有对齐(无填充字节,空间最省但效率最低);- **
#pragma pack(4):**强制对齐到 4 字节(Linux 默认);- **
#pragma pack():**无参数时恢复编译器默认对齐数(仅写这行无法修改,需配合带参数的指令)。
2. 位段
位段(Bit-field)是结构体的特殊形式,允许把数据拆分成二进制位 来存储,核心目的是极致节约内存(比如用 1 位存布尔值,而非 1 字节)。
语法规则:
struct 位段名 {
类型 变量名: 位数; // 位数表示该变量占用的二进制位数
};⚠️注意:位段的类型只能是 int/unsigned int/signed int/char(本质都是整数类型)。
核心特性
内存分配:
-
位段的位会打包存储到「一个整型大小的内存单元」(如 32 位系统下,int 型位段先填 32 位,满了再开新单元);
-
跨平台差异大:C 标准未规定 "剩余位是否复用""位段的存储顺序(高低位)",不同编译器结果不同(面试高频考点)。
【例子】
struct BS1 { unsigned int a:1; unsigned int b:3; unsigned int c:29; };解析:
把
unsigned int类型的位段想象成:✅ 一个固定大小的快递箱 = 4 字节 = 32 个小格子(1 位 = 1 个格子);
✅ 位段的每个成员 = 要装的小物件,占几个格子就写几(比如 a 占 1 格,b 占 3 格);
✅ 规则:先把第一个箱子装满 32 格,装不下了再开新箱子。
布骤:
unsigned int a:1:1 格放进第一个箱子,占第 1 格 → 剩余 31 格
unsigned int b:3:3 格接着放进第一个箱子,占 2-4 格 → 累计 4 格,剩余 28 格
unsigned int c:29:29 格要放 29 格,但第一个箱子只剩 28 格 → 装不下!直接开第二个箱子,把 29 格全放进新箱子
可知:
- 第一个箱子:用了 4 格,剩 28 格(没用也不能给 c 用);
- 第二个箱子:用了 29 格,剩 3 格;
- 总占用:2 个箱子 = 2×4 字节 = 8 字节。
长度限制:位段的 "位数" 不能超过对应类型的总位数。
【例子】
struct BS2 { char a:9; // 非法:char仅8位,位数9超限→编译报错 int b:33; // 非法:int仅32位,位数33超限 };
空位段 :可写 int :0; 强制结束当前内存单元,后续位段从新单元开始。
【例子】
struct BS3 { unsigned int a:1; int :0; // 强制结束当前单元 unsigned int b:2; // 新4字节单元开始 }; // 总大小:8字节(无空位段则仅4字节)
面试高频考点
1. 位段 vs 结构体(核心区别)
| 维度 | 结构体 | 位段 |
|---|---|---|
| 内存单位 | 按字节对齐分配 | 按二进制位打包分配 |
| 内存占用 | 大(有填充字节) | 小(极致省空间) |
| 跨平台兼容性 | 好(对齐规则统一) | 差(存储规则不统一) |
2. 面试必答问题
问:位段的优点?
- 答:极致节约内存(如用 1 位存布尔值,而非 1 字节),适合嵌入式 / 网络协议等内存 / 带宽紧张的场景。
问:位段的缺点?
- 答:跨平台兼容性差(存储顺序、剩余位复用规则不统一),且位段不能用
&取地址(最小寻址单位是字节)。
问:位段和结构体的核心区别?
- 答:结构体按字节对齐分配内存,位段按二进制位打包分配,位段更省内存但兼容性差。
3. 易错点
- 位段的位数不能超过类型总位数(如
char a:9;编译报错); - 位段不支持跨平台移植,工业级项目需谨慎使用;
#pragma pack对齐指令对位段无效(位段按位分配,不受字节对齐规则影响)。
3. 联合体(共用体)union
核心特点
✅所有成员共用同一块内存
【例子】
union Un { char c; // 1字节 int i; // 4字节 }; union Un u; // 所有成员地址完全相同 printf("&u = %p, &u.c = %p, &u.i = %p\n", &u, &u.c, &u.i); // 输出地址一致
✅同一时间只能有效使用一个成员
✅对一个成员赋值,会覆盖其他成员的内容
【例子】
u.i = 0x12345678; // 给int成员赋值 printf("u.i = %x\n", u.i); // 输出:12345678 u.c = 0xff; // 给char成员赋值,覆盖int低字节 printf("u.i = %x\n", u.i); // 输出:123456ff(被覆盖)
大小规则
联合体大小 = 最大成员的大小,且总大小需满足整体内存对齐规则
union Un2 {
char c; // 1字节
double d; // 8字节(最大成员)
};
// 32/64位系统下大小均为8字节(最大成员大小,且满足8字节对齐)
printf("union Un2大小:%zu\n", sizeof(union Un2)); // 输出:8核心考点
✅所有成员地址相同 :如上 "共用内存" 示例,可直接打印地址验证;
✅经典用法:判断 CPU 大小端 (面试高频题)
【例子】
int is_little_endian() { union { int i; char c; } un = {.i = 1}; // 小端存储:01 00 00 00;大端存储:00 00 00 01 return un.c; // 小端返回1,大端返回0 }
✅节省内存 :相比结构体(成员占独立内存),联合体共用内存,适合 "同一时间仅需使用一个成员" 的场景(如存储不同类型的配置参数)。
精简总结
联合体成员共用同一块内存,赋值会互相覆盖,大小为最大成员大小且满足对齐;核心应用是判断大小端,相比结构体更节省内存,缺点是同一时间只能使用一个成员。
4. 枚举 enum
核心特点
✅常量集合,默认从 0 开始依次递增
【例子】
// 定义枚举(默认:MON=0, TUE=1, WED=2...) enum Week { MON, TUE, WED }; printf("MON = %d, TUE = %d\n", MON, TUE); // 输出:0 1
✅ 自定义初始值
【例子】
// 手动指定起始值,后续仍递增(JAN=1, FEB=2, MAR=3) enum Month { JAN = 1, FEB, MAR }; printf("FEB = %d\n", FEB); // 输出:2
✅枚举常量是编译期确定的不可修改值 (运行时无法赋值修改)
【例子】
MON = 10; // 编译报错:枚举常量是只读的
核心考点
✅类型安全,比 #define 更规范
【例子】
// #define 缺陷:无类型检查,易重复定义 #define MON 0 // 枚举优势:有专属类型,编译器可检查,作用域清晰 enum Week day = MON;
✅本质是整型
【例子】
enum Week day = TUE; // 可直接赋值给整型变量,本质是int类型 int num = day; printf("day = %d\n", num); // 输出:1
✅可直接比较、在 switch 中使用 (面试高频场景)
【例子】
enum Week today = WED; // 1. 直接比较 if (today == WED) { printf("今天是周三\n"); } // 2. switch中使用(规范写法) switch (today) { case MON: printf("周一\n"); break; case TUE: printf("周二\n"); break; case WED: printf("周三\n"); break; default: break; }
精简总结
枚举是整型常量集合,默认从 0 递增(可自定义初始值);相比 #define 更规范(有类型检查),本质是整型,可直接比较或在 switch 中使用,常用于定义状态、选项等固定常量(如错误码、日期)。
以上就是我整理的全部知识点啦,大家后续有补充或发现疏漏、错误,欢迎在评论区一起交流探讨~感谢各位的阅读!