一、合并有序顺序表(C 语言版 )
题 1.将两个有序(非递减)顺序表La 和Lb 合并为一个新的有序(非递减)顺序表。
核心思路 :双指针法,同时遍历两个有序表,每次取较小值放入新表,最后处理剩余元素,保证合并后依然有序。
cpp
#include <stdio.h>
#include <stdlib.h>
// 定义顺序表结构
#define MAXSIZE 100 // 可根据需求调整最大长度
typedef struct {
int *elem; // 动态数组指针,存储数据元素
int length; // 当前表中元素个数
} SqList;
/**
* 功能:合并两个非递减有序顺序表 La 和 Lb,得到新的非递减有序顺序表 Lc
* 参数:La - 待合并的第一个有序顺序表
* Lb - 待合并的第二个有序顺序表
* Lc - 合并后的新有序顺序表(引用传递,用于返回结果)
* 时间复杂度:O(La.length + Lb.length),只需遍历两个表各一次
* 空间复杂度:O(La.length + Lb.length),需要为新表分配内存
*/
void MergeSqList(SqList La, SqList Lb, SqList *Lc) {
int i = 0, j = 0, k = 0; // i:La遍历指针, j:Lb遍历指针, k:Lc写入指针
// 新表长度为两个表长度之和
Lc->length = La.length + Lb.length;
// 为新表分配动态内存
Lc->elem = (int *)malloc(Lc->length * sizeof(int));
if (Lc->elem == NULL) { // 内存分配失败处理
printf("内存分配失败!\n");
exit(1);
}
// 双指针遍历两个表,取较小元素放入Lc
while (i < La.length && j < Lb.length) {
if (La.elem[i] <= Lb.elem[j]) {
Lc->elem[k++] = La.elem[i++]; // La元素更小,放入Lc并移动指针
} else {
Lc->elem[k++] = Lb.elem[j++]; // Lb元素更小,放入Lc并移动指针
}
}
// 处理La剩余元素(若有)
while (i < La.length) {
Lc->elem[k++] = La.elem[i++];
}
// 处理Lb剩余元素(若有)
while (j < Lb.length) {
Lc->elem[k++] = Lb.elem[j++];
}
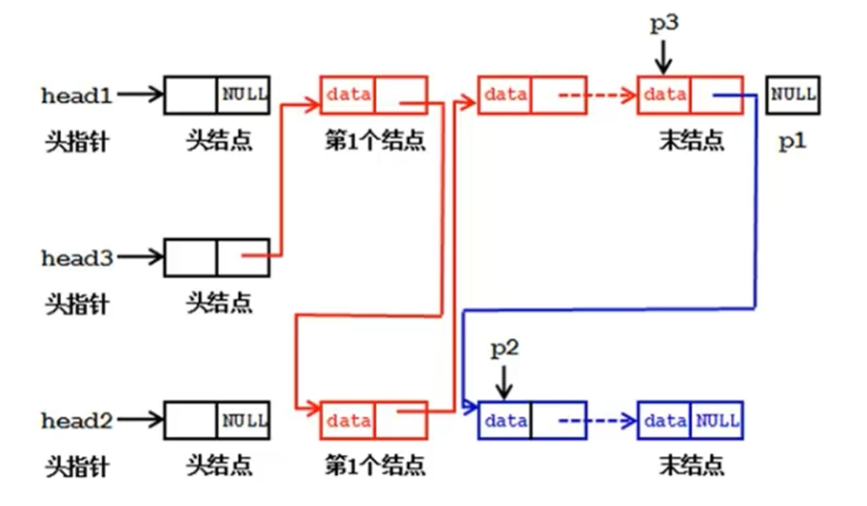
}二、合并有序单链表(C 语言版)
题 2.将两个有序(非递减)单链表La 和Lb合并为一个新的有序(非递减)单链表。
核心思路 :原地合并,复用 La 的头节点和两个链表的原有节点,仅通过指针重连实现有序合并,空间效率极高。
cpp
#include <stdio.h>
#include <stdlib.h>
// 定义单链表节点结构
typedef struct LNode {
int data; // 数据域
struct LNode *next; // 指针域,指向下一个节点
} LNode, *LinkList;
/**
* 功能:合并两个非递减有序单链表 La 和 Lb,得到新的非递减有序单链表 Lc(原地修改,复用节点)
* 参数:La - 待合并的第一个有序单链表(带头节点)
* Lb - 待合并的第二个有序单链表(带头节点)
* Lc - 合并后的新有序单链表(引用传递,指向La的头节点)
* 时间复杂度:O(len(La) + len(Lb)),遍历两个链表各一次
* 空间复杂度:O(1),仅使用几个指针,无额外节点分配
*/
void MergeLinkList(LinkList La, LinkList Lb, LinkList *Lc) {
LNode *p, *q, *r;
p = La->next; // p指向La第一个数据节点
q = Lb->next; // q指向Lb第一个数据节点
*Lc = La; // Lc复用La的头节点,节省空间
r = *Lc; // r指向新链表Lc的尾部,用于连接新节点
// 双指针遍历两个链表,按大小连接节点
while (p != NULL && q != NULL) {
if (p->data <= q->data) {
r->next = p; // 连接p节点到Lc尾部
r = p; // r移动到新尾部
p = p->next; // p后移
} else {
r->next = q; // 连接q节点到Lc尾部
r = q; // r移动到新尾部
q = q->next; // q后移
}
}
// 连接剩余节点(哪个链表不为空就连接哪个)
r->next = (p != NULL) ? p : q;
free(Lb); // 释放Lb的头节点(数据节点已复用,无需释放)
}三、就地逆置单链表(C 语言版 )
题 3.将带有头节点的单链表就地逆置。即元素的顺序逆转,而辅助空间复杂度为0(1)。
核心思路 :头插法逆置,将原链表节点逐个从头部插入新链表(头节点之后),最终实现顺序反转,无需额外内存。
cpp
#include <stdio.h>
#include <stdlib.h>
typedef struct LNode {
int data;
struct LNode *next;
} LNode, *LinkList;
/**
* 功能:对带头节点的单链表进行就地逆置(元素顺序反转,辅助空间O(1))
* 参数:L - 待逆置的单链表(带头节点,引用传递,直接修改原链表)
* 时间复杂度:O(n),n为链表长度,只需遍历一次
* 空间复杂度:O(1),仅用两个辅助指针,无额外节点分配
*/
void ReverseLinkList(LinkList *L) {
LNode *p, *q;
p = (*L)->next; // p指向第一个数据节点
(*L)->next = NULL; // 头节点先断开与原链表的连接
// 头插法逆置:逐个将原链表节点插入到头节点之后
while (p != NULL) {
q = p->next; // q记录p的下一个节点,防止断链
p->next = (*L)->next; // p节点的next指向当前头节点后的第一个节点
(*L)->next = p; // 头节点连接p节点,完成头插
p = q; // p后移,处理下一个节点
}
}四、查找链表中间节点(C 语言版 + 详细注释)
题 4.带有头节点的单链表L,设计一个尽可能高效的算法求L中的中间节点。
核心思路 :快慢指针法,快指针速度是慢指针 2 倍,快指针到尾时慢指针正好在中间,避免先遍历求长度再找中间的冗余操作。
cpp
#include <stdio.h>
#include <stdlib.h>
typedef struct LNode {
int data;
struct LNode *next;
} LNode, *LinkList;
/**
* 功能:查找带头节点单链表的中间节点(高效算法:快慢指针法)
* 参数:L - 待查找的单链表(带头节点)
* 返回:中间节点的指针;若链表为空,返回头节点
* 时间复杂度:O(n),n为链表长度,快指针仅遍历一次
* 空间复杂度:O(1),仅用两个指针
* 说明:奇数长度返回正中间节点,偶数长度返回前半部分最后一个节点
*/
LinkList FindMiddle(LinkList L) {
LNode *p, *q;
p = L; // 快指针:每次走两步
q = L; // 慢指针:每次走一步
// 快指针走到末尾时,慢指针恰好走到中间
while (p != NULL && p->next != NULL) {
p = p->next->next; // 快指针走两步
q = q->next; // 慢指针走一步
}
return q;
}五、删除链表中绝对值重复元素(C 语言版 + 详细注释)
题1.用单链表保存m个整数,节点的结构(data,next),且|data|<=n(n为正整数)。现要求设计一个时间复杂度尽可能高效的算法,对于链表中data 的绝对值相等的节点,仅保留第一次出现的节点而删除其余绝对值相等的节点。
核心思路 :用数组标记已出现的绝对值,遍历链表时若当前节点绝对值已标记则删除,否则标记后继续遍历,时间复杂度最优。
cpp
#include <stdio.h>
#include <stdlib.h>
#include <stdlib.h> // 用于abs()函数
typedef struct LNode {
int data;
struct LNode *next;
} LNode, *LinkList;
/**
* 功能:删除单链表中绝对值重复的节点,仅保留第一次出现的节点
* 参数:L - 待处理的单链表(带头节点,引用传递,直接修改原链表)
* n - 元素绝对值的最大值(题目给定|data|≤n)
* 时间复杂度:O(m),m为链表长度,仅遍历一次
* 空间复杂度:O(n),用数组标记已出现的绝对值,空间换时间
*/
void DeleteRep(LinkList *L, int n) {
LNode *p, *q;
int x;
// 标记数组:flag[x]=1表示绝对值x已出现,0表示未出现
int *flag = (int *)malloc((n + 1) * sizeof(int));
if (flag == NULL) {
printf("内存分配失败!\n");
exit(1);
}
// 初始化标记数组为0
for (int i = 0; i <= n; i++) {
flag[i] = 0;
}
p = *L; // p指向头节点,用于遍历和删除操作
while (p->next != NULL) {
x = abs(p->next->data); // 取当前节点数据的绝对值
if (flag[x] == 0) { // 该绝对值未出现过
flag[x] = 1; // 标记为已出现
p = p->next; // p后移,处理下一个节点
} else { // 该绝对值已出现,删除当前节点
q = p->next; // q指向待删除节点
p->next = q->next; // 跳过待删除节点,连接前后节点
free(q); // 释放待删除节点内存
}
}
free(flag); // 释放标记数组内存
}六、补充:课时四练习题
1. 拆分链表(奇数位到 A,偶数位到 B)
1.给定一个带表头结点的单链表A分解为两个带头结点的单链表A和B,使得A表中含有原表中序号为奇数的元素,而B表中含有原表中序号为偶数的元素,且保持其相对顺序不变
cpp
#include <stdio.h>
#include <stdlib.h>
typedef struct LNode {
int data;
struct LNode *next;
} LNode, *LinkList;
/**
* 功能:将带头节点的单链表A拆分为A(奇数位)和B(偶数位),保持相对顺序
* 参数:A - 原链表(拆分后存奇数位)
* B - 新链表(存储偶数位,需先分配头节点)
*/
void SplitList(LinkList A, LinkList *B) {
LNode *p, *r, *s;
p = A->next; // p遍历原链表
*B = (LinkList)malloc(sizeof(LNode)); // 为B分配头节点
(*B)->next = NULL;
r = A; // r指向A的尾部
s = *B; // s指向B的尾部
int cnt = 1; // 计数当前节点位置
while (p != NULL) {
if (cnt % 2 == 1) { // 奇数位,留在A
r->next = p;
r = p;
} else { // 偶数位,移到B
s->next = p;
s = p;
}
p = p->next;
cnt++;
}
r->next = NULL; // 断开A的尾部
s->next = NULL; // 断开B的尾部
}2. 递归删除值为 x 的节点(不带头节点)
设计一个递归算法,删除不带头结点的单链表L中所有值为x的结点(统计值等于x的数目)intCountX(Lnode * HL,ElemType x)
cpp
typedef struct LNode {
int data;
struct LNode *next;
} LNode;
/**
* 功能:递归删除不带头节点链表中所有值为x的节点,返回删除个数
* 参数:HL - 链表头指针(引用传递)
* x - 待删除的值
* 返回:删除的节点总数
*/
int CountX(LNode **HL, int x) {
if (*HL == NULL) return 0; // 递归终止:链表为空
LNode *p = *HL;
if (p->data == x) { // 当前节点需要删除
*HL = p->next; // 头指针指向下一个节点
free(p);
return 1 + CountX(HL, x); // 递归处理剩余节点,计数+1
} else {
return CountX(&(p->next), x); // 递归处理下一个节点
}
}3. 单链表元素递增排序(直接插入排序)
有一个带头结点的单链表L,设计一个算法使其元素递增有序
cpp
#include <stdio.h>
#include <stdlib.h>
typedef struct LNode {
int data;
struct LNode *next;
} LNode, *LinkList;
/**
* 功能:对带头节点的单链表进行递增排序(直接插入排序思想)
* 参数:L - 待排序的单链表(带头节点)
*/
void SortList(LinkList L) {
if (L->next == NULL || L->next->next == NULL) return; // 空表或仅一个节点无需排序
LNode *p, *q, *pre, *temp;
p = L->next->next; // p从第二个节点开始遍历
L->next->next = NULL; // 第一个节点作为有序表初始部分
while (p != NULL) {
temp = p; // temp保存当前待插入节点
p = p->next; // p后移,防止断链
// 寻找temp在有序表中的插入位置
pre = L;
q = L->next;
while (q != NULL && q->data < temp->data) {
pre = q;
q = q->next;
}
// 插入temp到pre和q之间
temp->next = q;
pre->next = temp;
}
}4. 找两个单链表的公共节点(长度差法)
给定两个单链表,编写算法找出两个链表的公共结点
cpp
#include <stdio.h>
#include <stdlib.h>
typedef struct LNode {
int data;
struct LNode *next;
} LNode, *LinkList;
/**
* 功能:查找两个单链表的公共节点(若存在)
* 参数:L1, L2 - 两个待查找的单链表(带头节点)
* 返回:公共节点指针;若无公共节点,返回NULL
*/
LinkList FindCommonNode(LinkList L1, LinkList L2) {
// 计算两个链表长度
int len1 = 0, len2 = 0;
LNode *p = L1, *q = L2;
while (p->next != NULL) { len1++; p = p->next; }
while (q->next != NULL) { len2++; q = q->next; }
// 长链表指针先移动差值步,使两指针到尾部距离相同
p = L1; q = L2;
if (len1 > len2) {
for (int i = 0; i < len1 - len2; i++) p = p->next;
} else {
for (int i = 0; i < len2 - len1; i++) q = q->next;
}
// 同时遍历,找到第一个相同节点即为公共节点
while (p != NULL && q != NULL) {
if (p == q) return p;
p = p->next;
q = q->next;
}
return NULL; // 无公共节点
}总结
| 功能 | 核心思想 | 时间复杂度 | 空间复杂度 |
|---|---|---|---|
| 合并有序顺序表 | 双指针遍历取小 | O(m+n) | O(m+n) |
| 合并有序单链表 | 原地指针重连 | O(m+n) | O(1) |
| 单链表就地逆置 | 头插法 | O(n) | O(1) |
| 找链表中间节点 | 快慢指针 | O(n) | O(1) |
| 删除绝对值重复节点 | 数组标记 + 遍历 | O(m) | O(n) |
| 拆分链表 | 遍历分奇偶 | O(n) | O(1) |
| 递归删除节点 | 递归回溯 | O(n) | O (n)(递归栈) |
| 链表排序 | 直接插入排序 | O(n²) | O(1) |
| 找公共节点 | 长度差 + 同步遍历 | O(m+n) | O(1) |
关键技巧:
- 链表操作多用双指针 / 快慢指针,避免多次遍历冗余。
- 原地操作尽量复用节点 / 头节点,减少内存开销。
- 涉及重复 / 计数问题,可用数组 / 哈希表标记,空间换时间。