Dake D K, Gbagbo F Y. ChatGPT's benefits, acceptance, and ethical challenges for teaching and learning in key African countries: a systematic review of literature from 2022 to 2024J. Discover Education, 2026, 5: 62.
摘要
本文精读的文献来源于Discover Education期刊2026年第5卷第62期,由加纳教育大学的Delali Kwasi Dake和Fred Yao Gbagbo两位学者合作完成。该研究采用系统综述方法,基于PRISMA模型对2022年至2024年间关于ChatGPT在非洲教育中应用的研究进行了全面分析。经过对130项研究的严格筛选,最终纳入44篇符合标准的文章进行综合分析,研究范围覆盖阿尔及利亚、安哥拉、博茨瓦纳、科特迪瓦、埃及、埃塞俄比亚、加纳、肯尼亚、摩洛哥、尼日利亚、南非、坦桑尼亚和突尼斯等13个非洲主要国家。
研究结果表明,ChatGPT在教学和学习过程中发挥了显著的辅助作用,包括提升教学效率、支持个性化学习、改善写作能力和提供多语言支持等方面。然而,研究同时也揭示了ChatGPT在教育应用中存在的重大缺陷,主要集中在伦理使用、安全性和数据保护等领域。这些发现强调了教育利益相关者参与的重要性,以及在实施ChatGPT教学法时制定法律法规和政策框架的必要性,为地方和国际监管机构提供了重要的参考依据。
本文将从技术原理、研究方法、研究发现、区域比较等多个维度对该文献进行深入解读,并结合人工智能教育应用的理论基础,为读者提供全面、系统的知识框架。通过本精读,读者将深入了解ChatGPT在非洲教育领域的应用现状、面临的挑战以及未来发展方向,同时掌握相关的人工智能技术原理和教育技术应用理论。
由于国内无法访问OpenAI官网,因此使用国内镜像站可以注册使用GPT-5.4最新模型。注册入口:AIGCBAR镜像站。如需调用API进行开发,可访问API独立站完成注册。请广大用户注意,翻墙访问境外网站属于违法行为,建议通过合法的国内镜像站使用相关服务。
1 引言
1.1 研究背景与意义
在过去的三十余年间,技术的进步逐步改变了教学方法,并显著提高了教育质量。信息与通信技术(Information and Communication Technologies,ICTs)的出现彻底改变了教育格局,带来了包括计算机、移动设备、通信和网络设备、社交媒体和互联网在内的各种技术辅助工具。ICTs为新技术在教育环境中的蓬勃发展奠定了坚实基础,从而推动了教育普及率、入学率、教学法和收入的增长。
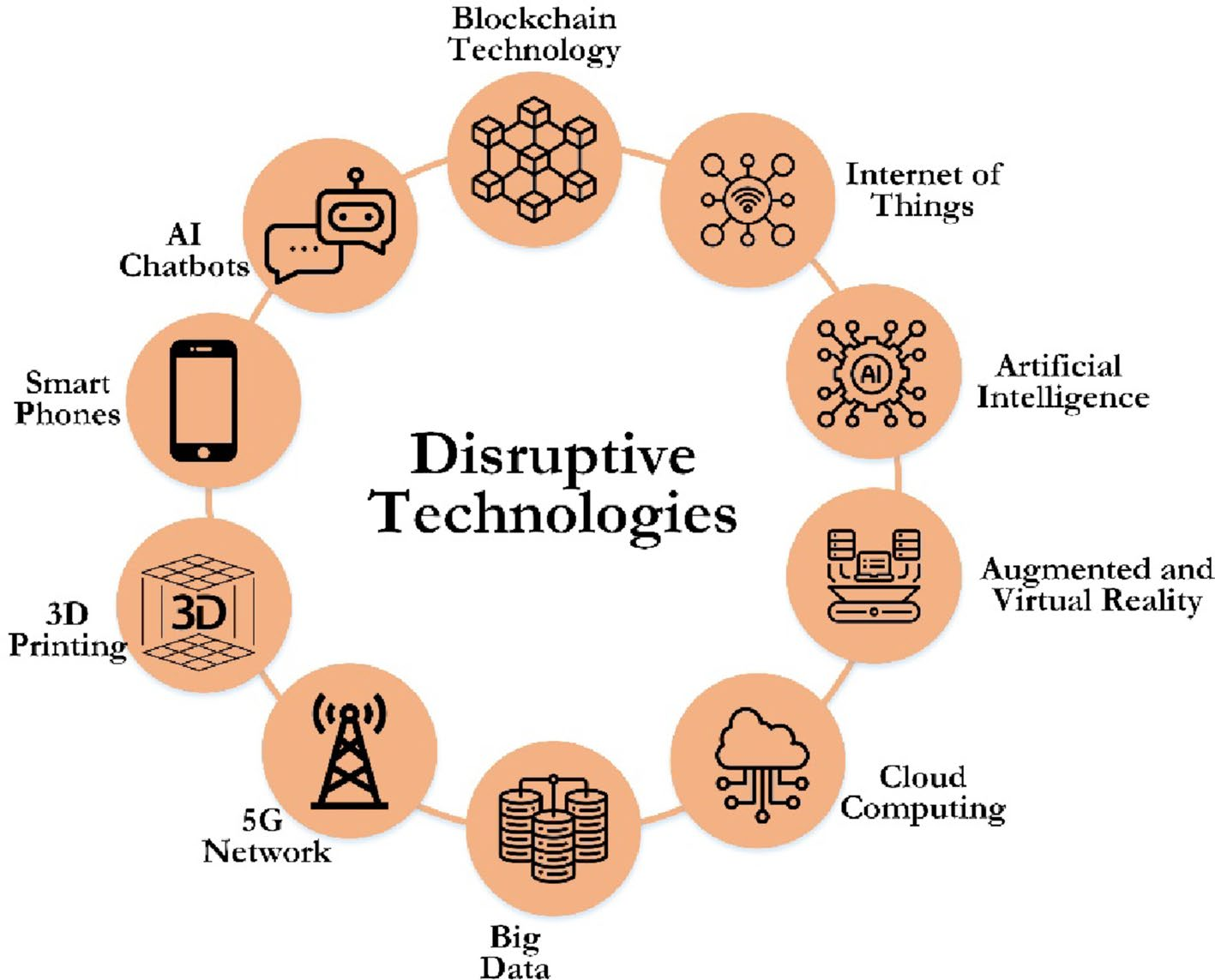
当前,教育领域的技术复杂程度急剧提升,出现了以前难以追踪的教学模式和完全改变教学与学习的虚拟现实。如图1所示,这些颠覆性技术包括物联网(Internet of Things,IoT)、人工智能(Artificial Intelligence,AI)、增强现实(Augmented Reality,AR)和虚拟现实(Virtual Reality,VR)、云计算、区块链技术、大数据、5G网络、智能手机、机器人技术、聊天机器人和3D打印等。
颠覆性技术
物联网 IoT
智能校园
设备互联
数据采集
人工智能 AI
机器学习
自然语言处理
计算机视觉
增强现实 AR/VR
沉浸式学习
虚拟实验室
远程教学
云计算
资源共享
协作平台
弹性扩展
区块链
学历认证
学术记录
去中心化
大数据
学习分析
个性化推荐
决策支持
5G网络
高速传输
低延迟
广泛连接
聊天机器人
智能问答
学习助手
自动评估
在20世纪80年代技术融入教育之前,教学与学习的特点是死记硬背、以教师为中心的教学法、实体教室、固定方法论、被动学习者、低效学习、黑板和石板、印刷材料、资源有限和课程僵化。没有技术的传统教育范式存在潜在的枯燥感,理论与实践之间存在脱节。然而,随着21世纪颠覆性技术走在教育前沿,创新教育方法的激动人心的潜力是无限的。
人工智能作为一种颠覆性技术,通过模仿人类智能使机器能够自主学习和推理。人工智能是全球所有行业的流行术语,因为它能够使用机器学习(Machine Learning,ML)算法分析海量数据集,并以惊人的精确度揭示复杂的趋势。人工智能在数据驱动决策方面的进步需要机器学习算法,使计算机能够识别模式并预测不可预见的情况。机器学习是人工智能的一个子集,是利用大量数据构建人工智能应用程序的引擎。机器学习系统基于数据从经验中改进,并自动学习提供预测解决方案。
人工智能的应用领域在过去几十年中呈指数级增长。全球人工智能市场预计将以28.46%的速度扩张,到2030年市场规模将达到8267亿美元。人工智能市场规模的增长包括以下子领域,按降序排列:机器学习、自然语言处理、人工智能机器人、自主和传感器技术以及计算机视觉。
1.2 人工智能在教育领域的应用
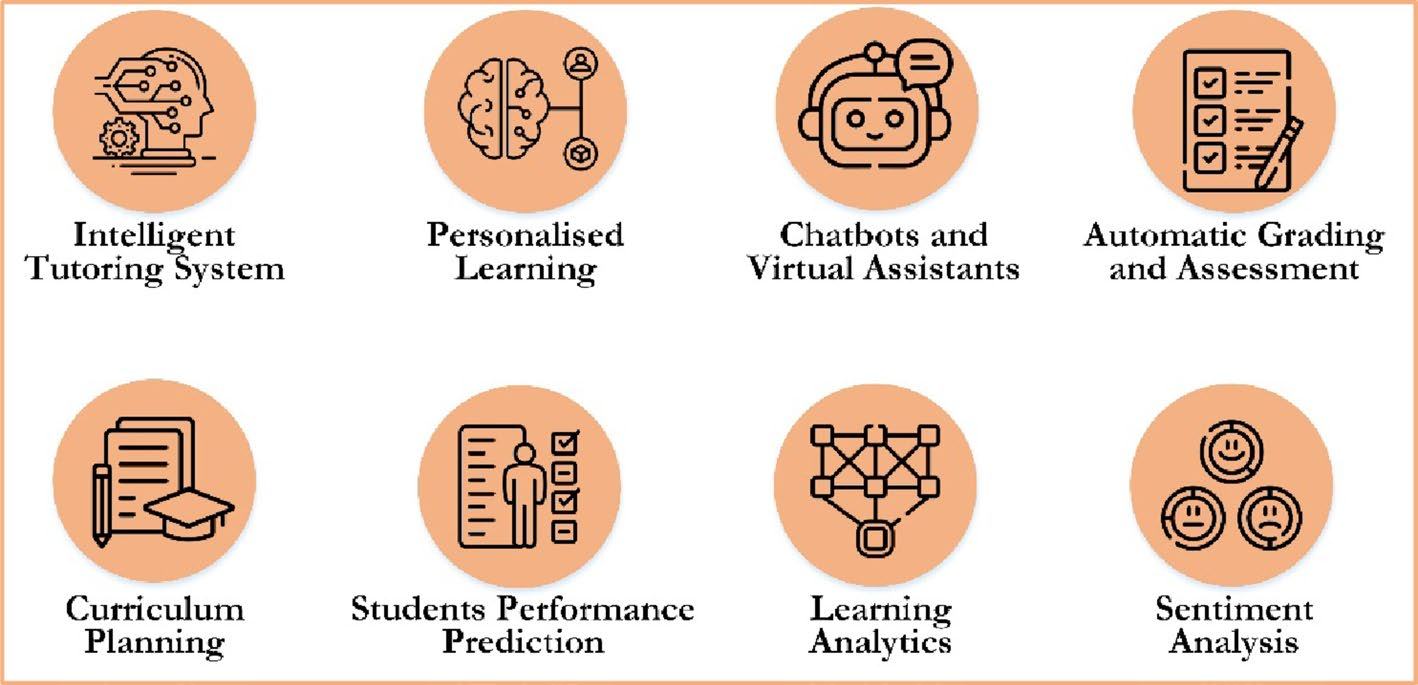
在教育领域,人工智能的利用和采用呈现出良好的趋势,具有多种教学应用。如图2所示,人工智能在教育领域的应用涵盖多个领域,包括课程开发、学生成绩预测、学习分析、情感分析、智能辅导系统、个性化学习、自动评分和评估,以及聊天机器人和虚拟助手的使用。
AI教育应用
课程开发
智能内容生成
课程设计优化
学生成绩预测
学习轨迹分析
预警系统
学习分析
行为模式识别
学习效果评估
情感分析
学习情绪监测
教学反馈优化
智能辅导系统
个性化指导
自适应学习路径
个性化学习
学习风格匹配
内容定制推荐
自动评分评估
作业批改
考试评估
聊天机器人
智能问答
学习助手
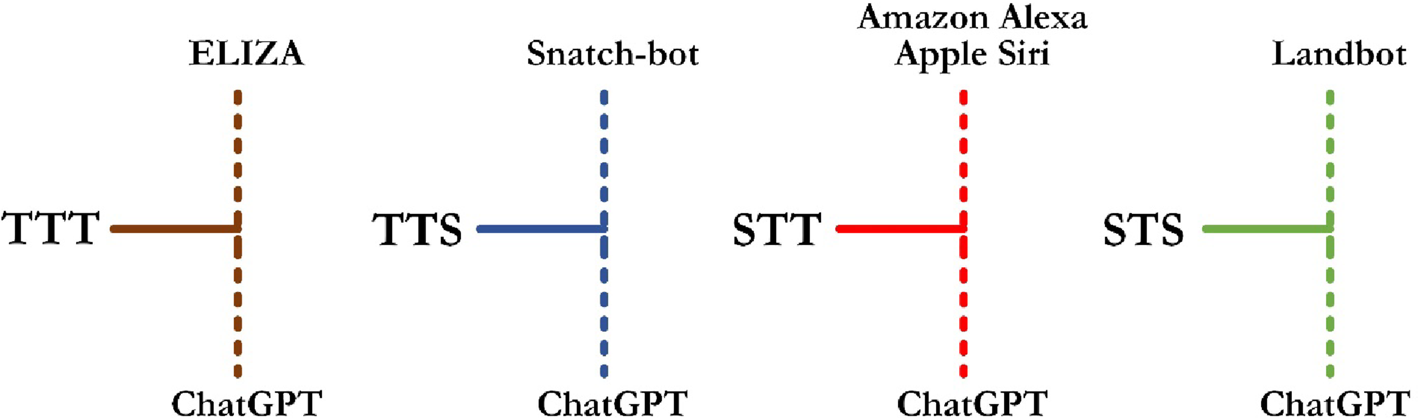
人工智能聊天机器人(AI-Chatbots)近年来得到了广泛使用,其基础建立在自然语言处理(Natural Language Processing,NLP)之上。聊天机器人是为接收人类输入并通过互联网与用户进行响应交流而设计的对话系统。这些聊天机器人通常通过界面运行,利用自然语言处理和机器学习来理解用户查询和意图,同时提供最智能的响应。
AI聊天机器人可以分为四种类型:文本到文本机器人(Text-to-Text Bot,TTT),用户输入文本,聊天机器人通过基于规则或模式匹配机制进行文本响应;文本到语音机器人(Text-to-Speech Bot,TTS),采用交互式架构,允许用户在说话时聆听;语音到文本机器人(Speech-to-Text Bot,STT),使用用户的语音输入生成文本响应;语音到语音机器人(Speech-to-Speech Bot,STS),具有响应口语的框架,STS是一种新型聊天机器人,具有类似语音助手的功能和模仿人类的能力。
1.3 研究目的与问题
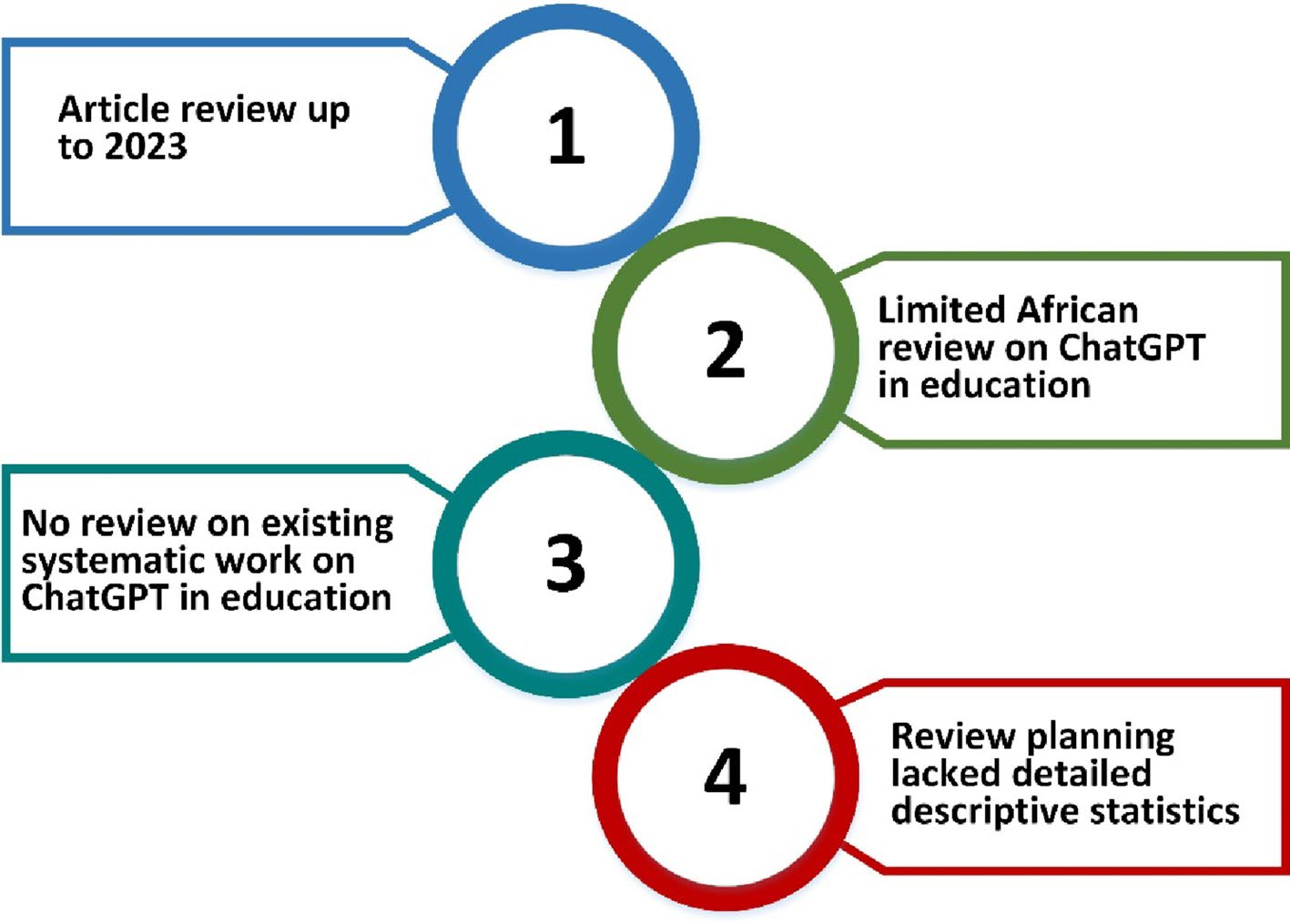
本研究的理由源于尽管ChatGPT在全球范围内快速普及并对教学法产生日益增长的影响,但缺乏针对非洲的系统性评估。大多数关于ChatGPT的系统综述和荟萃分析都是针对全球北方和西方进行的,那里的数字基础设施、教师准备度和政策框架相对先进。尽管全球北方和西方的研究发现具有相当大的价值,但它们对非洲教育系统的直接适用性受到限制,因为这些系统受到独特的社会经济背景影响,如互联网连接不足、机构长期资金不足、教育者数字素养有限以及监管框架脆弱。
非洲目前面临着扩大高等教育机会和提高质量的日益增长的需求。在这种环境下,ChatGPT等新兴数字解决方案为解决持续存在的困难提供了巨大的希望,包括师生比例失衡、资源可用性不足以及个性化学习支持选择有限。然而,不负责任地采用此类技术可能会加剧重大风险,包括通过抄袭进行的学术不诚实、伦理不当行为、数据隐私泄露以及对自动化系统的过度依赖,这可能会削弱教学完整性。
本研究及时且必要,因为它系统地整合了来自13个非洲国家的发现,提供了对效益和挑战的平衡评估,以及针对特定背景的解决方案,包括教师培训、基础设施改善、抄袭检测策略和文化适应的人工智能政策。通过将讨论置于非洲多样化环境的背景下,本综述确保非洲大陆不仅仅是接受全球叙事,而是主动制定基于证据的、伦理的和政策相关的策略,以在非洲教育中整合ChatGPT。
根据研究目标,提出了以下研究问题:
- 非洲主要国家关于ChatGPT在教育中应用的研究总体状况如何?
- 非洲学生和教师在使用ChatGPT进行教育目的时遇到的效益和挑战是什么?
- 在非洲教育中伦理/引导式实施ChatGPT的解决方案是什么?
- 非洲教育中ChatGPT采用的区域相似性和差异是什么?
2 ChatGPT技术原理与理论基础
2.1 自然语言处理基础
自然语言处理(Natural Language Processing,NLP)是人工智能的一个重要分支,致力于使计算机能够理解、解释和生成人类语言。NLP的研究历史可以追溯到20世纪50年代,经历了从基于规则的方法到统计方法,再到深度学习方法的演进过程。现代NLP技术的核心在于将自然语言转换为计算机可以处理的数值表示,并通过各种算法模型实现语言理解和生成任务。
NLP的基本任务包括词法分析、句法分析、语义分析和语用分析等多个层次。词法分析负责将文本分割成有意义的词汇单元,并进行词性标注;句法分析关注句子结构,识别词汇之间的语法关系;语义分析旨在理解文本的含义,包括词义消歧和语义角色标注;语用分析则考虑上下文和背景知识对语言理解的影响。
在深度学习时代,词嵌入(Word Embedding)技术成为NLP的基础。Word2Vec、GloVe等模型将词汇映射到连续向量空间,使语义相近的词在向量空间中距离较近。这种分布式表示方法捕捉了词汇之间的语义关系,为后续的语言模型奠定了基础。词嵌入的数学表达式可以表示为:
w ⃗ = f ( w ) ∈ R d \vec{w} = f(w) \in \mathbb{R}^d w =f(w)∈Rd
其中, w w w表示词汇, w ⃗ \vec{w} w 表示其对应的嵌入向量, d d d为向量维度。
语言模型是NLP的核心组件,其目标是计算一个词序列的概率分布。传统语言模型采用n-gram方法,通过统计词序列的出现频率来估计概率。然而,n-gram方法面临数据稀疏和维度灾难等问题。神经网络语言模型通过学习词的分布式表示,有效缓解了这些问题。给定一个词序列 w 1 , w 2 , . . . , w n w_1, w_2, ..., w_n w1,w2,...,wn,语言模型计算其概率:
P ( w 1 , w 2 , . . . , w n ) = ∏ i = 1 n P ( w i ∣ w 1 , . . . , w i − 1 ) P(w_1, w_2, ..., w_n) = \prod_{i=1}^{n} P(w_i | w_1, ..., w_{i-1}) P(w1,w2,...,wn)=i=1∏nP(wi∣w1,...,wi−1)
2.2 Transformer架构详解
Transformer架构是现代大型语言模型的技术基础,由Vaswani等人在2017年的论文"Attention Is All You Need"中首次提出。与传统的循环神经网络(RNN)和长短期记忆网络(LSTM)不同,Transformer完全依赖注意力机制来处理序列数据,实现了并行计算和长距离依赖建模。
2.2.1 自注意力机制
自注意力机制(Self-Attention)是Transformer的核心创新。对于输入序列中的每个位置,自注意力机制计算该位置与其他所有位置的相关性,并基于这些相关性聚合信息。具体而言,给定输入序列 X ∈ R n × d X \in \mathbb{R}^{n \times d} X∈Rn×d,首先通过三个线性变换得到查询(Query)、键(Key)和值(Value)矩阵:
Q = X W Q , K = X W K , V = X W V Q = XW^Q, \quad K = XW^K, \quad V = XW^V Q=XWQ,K=XWK,V=XWV
其中, W Q , W K , W V ∈ R d × d k W^Q, W^K, W^V \in \mathbb{R}^{d \times d_k} WQ,WK,WV∈Rd×dk为可学习的参数矩阵。注意力权重通过查询和键的点积计算:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dk QKT)V
缩放因子 d k \sqrt{d_k} dk 用于防止点积值过大导致softmax函数梯度消失。
自注意力机制
输入序列 X
Query矩阵
Key矩阵
Value矩阵
点积计算
缩放
Softmax归一化
注意力权重
加权聚合
输出
2.2.2 多头注意力
多头注意力(Multi-Head Attention)机制通过并行运行多个自注意力头,使模型能够同时关注不同位置的不同表示子空间。每个头学习不同的注意力模式,最后将所有头的输出拼接并通过线性变换得到最终输出:
MultiHead ( Q , K , V ) = Concat ( head 1 , . . . , head h ) W O \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, ..., \text{head}_h)W^O MultiHead(Q,K,V)=Concat(head1,...,headh)WO
其中, head i = Attention ( Q W i Q , K W i K , V W i V ) \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) headi=Attention(QWiQ,KWiK,VWiV)。
多头注意力的优势在于能够捕捉不同类型的依赖关系。例如,在处理句子时,某些头可能关注句法关系,而其他头可能关注语义关系。这种多样性使模型能够更全面地理解输入序列。
2.2.3 位置编码
由于Transformer不使用循环结构,无法自然地捕捉序列的位置信息。位置编码(Positional Encoding)通过向输入嵌入添加位置信息来解决这个问题。原始Transformer使用正弦和余弦函数生成位置编码:
P E ( p o s , 2 i ) = sin ( p o s / 10000 2 i / d ) PE_{(pos, 2i)} = \sin(pos / 10000^{2i/d}) PE(pos,2i)=sin(pos/100002i/d)
P E ( p o s , 2 i + 1 ) = cos ( p o s / 10000 2 i / d ) PE_{(pos, 2i+1)} = \cos(pos / 10000^{2i/d}) PE(pos,2i+1)=cos(pos/100002i/d)
其中, p o s pos pos是位置索引, i i i是维度索引。这种编码方式使模型能够学习相对位置关系,并且可以外推到训练时未见过的序列长度。
2.2.4 前馈网络与残差连接
每个Transformer层除了注意力子层外,还包含一个前馈神经网络(Feed-Forward Network,FFN)。FFN由两个线性变换和一个激活函数组成:
FFN ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 \text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2 FFN(x)=max(0,xW1+b1)W2+b2
残差连接(Residual Connection)和层归一化(Layer Normalization)是Transformer的重要组成部分。每个子层的输出通过残差连接和层归一化处理:
LayerNorm ( x + Sublayer ( x ) ) \text{LayerNorm}(x + \text{Sublayer}(x)) LayerNorm(x+Sublayer(x))
这种结构有助于缓解深层网络的梯度消失问题,使模型能够有效训练。
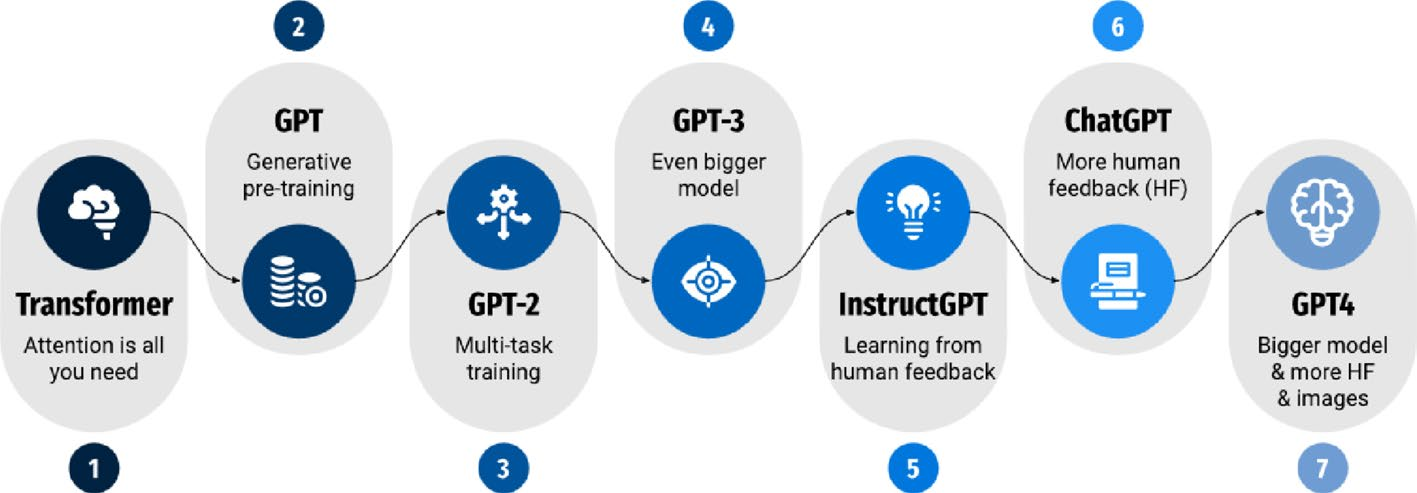
2.3 GPT模型演进历程
GPT(Generative Pre-trained Transformer)系列模型代表了大型语言模型发展的里程碑。从2018年的GPT-1到2023年的GPT-4,每个版本都在模型规模、训练数据和技术架构方面取得了重大突破。
2.3.1 GPT-1:生成式预训练的开端
GPT-1于2018年发布,是OpenAI首次将Transformer架构应用于大规模无监督预训练的尝试。GPT-1采用了12层Transformer解码器,包含约1.17亿个参数,使用约5GB的文本数据进行预训练。GPT-1的核心思想是利用大量无标注文本进行预训练,然后在特定任务上进行微调。这种"预训练+微调"的范式成为后续大型语言模型的标准方法。
GPT-1的预训练目标是语言建模,即预测下一个词:
L = − ∑ i = 1 n log P ( w i ∣ w 1 , . . . , w i − 1 ; θ ) \mathcal{L} = -\sum_{i=1}^{n} \log P(w_i | w_1, ..., w_{i-1}; \theta) L=−i=1∑nlogP(wi∣w1,...,wi−1;θ)
2.3.2 GPT-2:规模扩展与零样本学习
GPT-2于2019年发布,将模型参数扩展到15亿,训练数据增加到40GB的WebText数据集。GPT-2展示了大规模语言模型的涌现能力,能够在没有特定任务训练的情况下完成多种NLP任务,即零样本学习(Zero-shot Learning)。GPT-2的成功表明,模型规模的扩大可以带来性能的显著提升。
2.3.3 GPT-3:上下文学习与少样本能力
GPT-3于2020年发布,参数量达到1750亿,训练数据规模为45TB。GPT-3最重要的创新是上下文学习(In-context Learning)能力,即通过在提示中提供少量示例,模型能够快速适应新任务而无需更新参数。GPT-3在少样本(Few-shot)设置下展现出惊人的任务泛化能力,能够完成翻译、问答、摘要、代码生成等多种任务。
2018 GPT-1 1.17亿参数 5GB数据 预训练+微调范式 2019 GPT-2 15亿参数 40GB数据 零样本学习 2020 GPT-3 1750亿参数 45TB数据 上下文学习 2022 ChatGPT 基于GPT-3.5 RLHF优化 对话交互 2023 GPT-4 多模态能力 8195 tokens 安全性增强 GPT模型演进历程
2.3.4 ChatGPT与GPT-4:对话优化与多模态
ChatGPT于2022年11月发布,基于GPT-3.5架构,通过人类反馈强化学习(Reinforcement Learning from Human Feedback,RLHF)进行优化,显著提升了对话交互的质量和安全性。RLHF包括三个步骤:首先,收集人类编写的示范数据训练监督微调模型;然后,收集模型输出的比较数据训练奖励模型;最后,使用PPO算法优化语言模型。
GPT-4于2023年发布,引入了多模态能力,能够处理图像和文本输入。GPT-4在推理能力、事实准确性和安全性方面都有显著提升,上下文窗口扩展到8195个tokens。GPT-4在各种专业考试中表现出色,如在模拟律师资格考试中进入前10%的成绩。
2.4 大型语言模型的教育应用理论
2.4.1 认知负荷理论
认知负荷理论(Cognitive Load Theory,CLT)由Sweller于1988年提出,是教育心理学的重要理论框架。该理论认为,工作记忆容量有限,学习材料的设计应优化认知资源的分配。大型语言模型在教育中的应用可以从认知负荷理论的角度进行分析。
ChatGPT作为智能助手,可以承担部分认知任务,降低学习者的外在认知负荷。例如,在写作任务中,ChatGPT可以帮助生成初稿、检查语法、提供词汇建议,使学习者能够将更多认知资源投入到高阶思维活动中。然而,过度依赖ChatGPT可能导致认知卸载(Cognitive Offloading),使学习者失去必要的认知训练机会。
2.4.2 建构主义学习理论
建构主义学习理论强调学习者主动构建知识的过程。根据皮亚杰的认知发展理论和维果茨基的社会建构主义理论,学习是学习者与环境和他人互动中主动建构意义的过程。ChatGPT可以作为学习者的对话伙伴,提供支架式学习支持。
在维果茨基的最近发展区(Zone of Proximal Development,ZPD)理论框架下,ChatGPT可以扮演"更有能力的他者"角色,在学习者现有水平和潜在发展水平之间提供适当的支持。通过对话交互,ChatGPT可以引导学习者逐步解决问题,促进知识的主动建构。
2.4.3 自我调节学习理论
自我调节学习(Self-Regulated Learning,SRL)理论关注学习者如何主动设定目标、监控进度和调整策略。Zimmerman提出的自我调节学习循环模型包括预见阶段、表现阶段和自我反思阶段。ChatGPT可以在每个阶段提供支持:帮助设定学习目标、提供实时反馈、促进自我评估。
然而,ChatGPT的使用也可能影响学习者的自我调节能力发展。如果学习者过度依赖外部反馈,可能削弱内在的自我监控和评估能力。因此,在将ChatGPT整合到教育中时,需要平衡外部支持和自主学习能力培养。
3 研究方法
3.1 系统综述方法论概述
系统综述(Systematic Review)是一种采用明确、可重复的方法识别、选择和评价相关研究,并收集和分析数据的研究方法。与传统的叙述性综述不同,系统综述遵循严格的协议,确保研究过程的透明性和可重复性。本研究采用PRISMA(Preferred Reporting Items for Systematic Reviews and Meta-Analyses)声明作为指导框架,这是目前系统综述报告的国际标准。
PRISMA声明包括27个条目的检查清单和四阶段流程图,涵盖标题、摘要、引言、方法、结果、讨论和资金等部分。PRISMA流程图清晰地展示了文献筛选过程,包括识别(Identification)、筛选(Screening)、资格评估(Eligibility)和纳入(Included)四个阶段。
纳入阶段
资格评估阶段
筛选阶段
识别阶段
数据库检索
n=130
重复记录去除
n=50
标题/摘要筛选
n=80
排除不相关研究
n=32
全文评估
n=48
不符合纳入标准
n=4
最终纳入分析
n=44
3.2 信息来源与检索策略
为了发现关于人工智能和ChatGPT在非洲主要国家教育中应用的相关研究,研究者在多个学术数据库中进行了全面检索。检索的数据库包括Scopus、ERIC、Springer、ScienceDirect、MDPI、IEEE Xplore、Web of Science、Information Science Institute、ACM Digital Library和Google Scholar。其中,Google Scholar是检索文章最多的来源。
检索策略基于研究问题构建,使用以下检索词组合:"ChatGPT"、"Chatbots"、"artificial intelligence Chatbots",结合"Education"、"Global"、"African Countries"、"Major African Economies"、"Academic Institution"和"Educational Institutions"。在所有数据库中使用类似的检索查询,配合逻辑运算符(AND、OR)生成相关字符串。
检索时间限制在2022年至2024年之间,这一时间范围的选择具有重要意义,因为ChatGPT于2022年11月推出,而本研究于2024年进行。这种时间范围的设定确保了检索结果的相关性和时效性。
3.3 纳入与排除标准
为确保研究质量,本研究制定了明确的纳入和排除标准,如表1所示。
表1 纳入与排除标准
| 标准 | 纳入标准 | 排除标准 |
|---|---|---|
| 文章主题和焦点 | 在选定的非洲主要经济体中关于ChatGPT在教育中应用的研究 | 在选定的非洲主要经济体之外关于ChatGPT在教育中应用的研究 |
| 发表时期 | 2022年至2024年10月发表的研究 | 2022年之前和2024年10月之后发表的研究 |
| 发表类型 | 同行评审期刊文章 | 其他类型的研究(评论、意见、书籍、论文、纪录片、社论) |
| 语言 | 英语 | 非英语 |
| 非洲国家 | 阿尔及利亚、安哥拉、博茨瓦纳、科特迪瓦、埃及、埃塞俄比亚、加纳、肯尼亚、摩洛哥、尼日利亚、南非、坦桑尼亚、突尼斯 | 所有其他国家 |
纳入标准的设定确保了研究的相关性和质量。首先,研究主题必须聚焦于ChatGPT在选定非洲国家的教育应用;其次,研究必须在指定时间范围内发表,以确保时效性;第三,只纳入同行评审期刊文章,保证研究质量;最后,只纳入英语文献,便于统一分析。
3.4 数据收集与分析过程
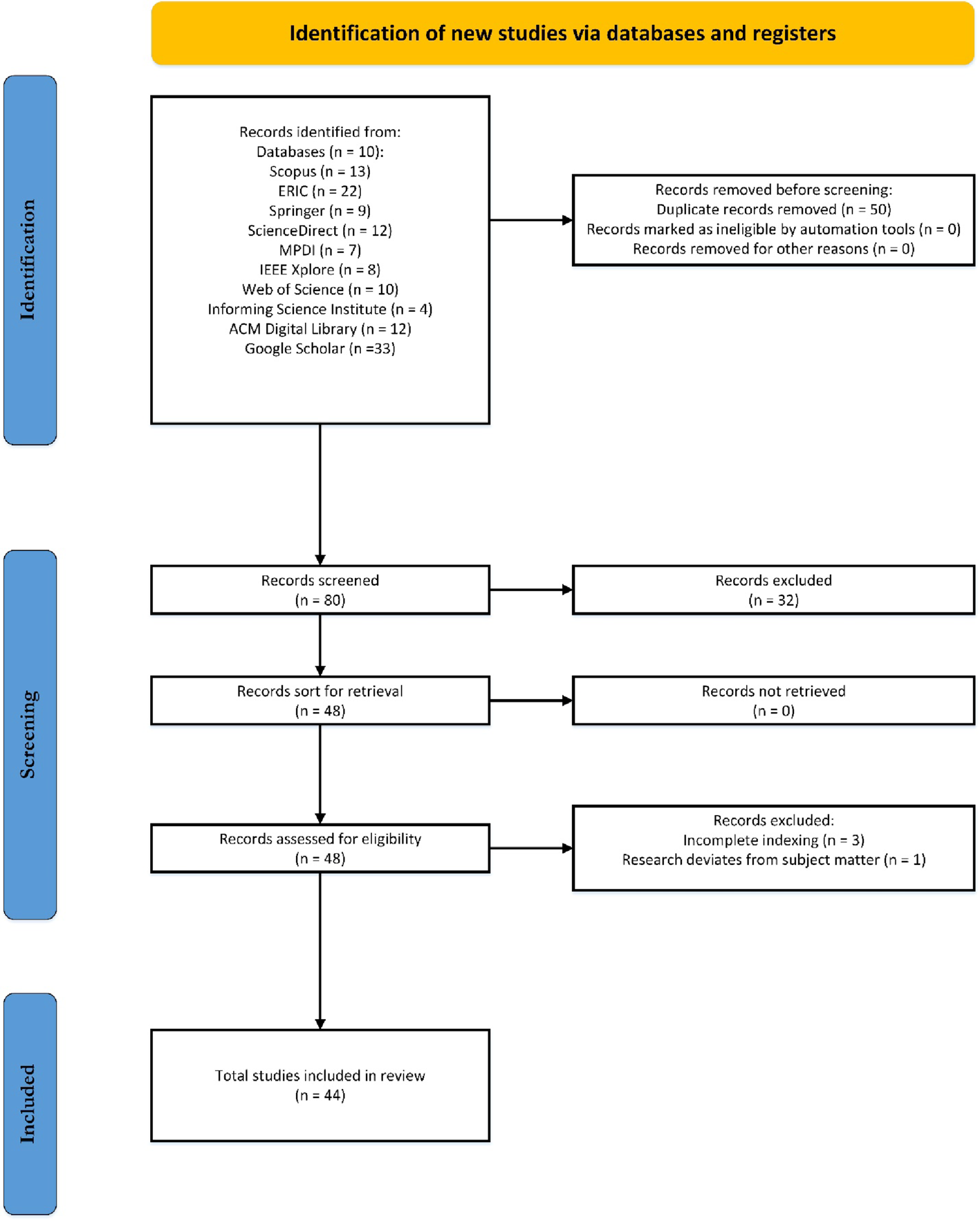
初始检索阶段涉及十个数据库,共检索到130篇文章:Scopus(n=13)、ERIC(n=22)、Springer(n=9)、ScienceDirect(n=12)、MDPI(n=7)、IEEE Xplore(n=8)、Web of Science(n=10)、Informing Science Institute(n=4)、ACM Digital Library(n=12)和Google Scholar(n=33)。
根据纳入和排除标准,首先识别并去除重复记录(n=50),重复记录来源包括Google Scholar(n=29)和IEEE Xplore(n=21)。其次,排除摘要偏离、文章发表日期不符、非英语文章和非洲背景之外的文章。此外,其他类型的研究,包括社论、评论、意见、书籍、论文和纪录片也被排除,共计(n=32)篇。
经过纳入和排除标准的筛选,剩余(n=48)篇文章进入全文评估阶段。其中,三篇研究文章缺乏完整的索引信息,另一篇文章偏离主题。最终,纳入分析的文章总数为(n=44)篇。
3.5 偏倚风险评估
研究承认在检索相关文章过程中可能存在偏倚。为减轻偏倚并确保研究的完整性,文章重复识别过程使用Zotero工具和混合方法评估工具(Mixed Methods Appraisal Tool,MMAT)进行。使用MMAT评估了44篇纳入研究的方法学质量。
大多数论文阐述了明确的研究目标,并采用了与其设计相适应的分析方法。然而,大多数研究是横断面调查,依赖非概率抽样,往往没有报告响应率,这限制了代表性并增加了无响应偏倚的可能性。少数调查工具附有信效度检验证据。定性研究通常适合其研究问题,但许多研究没有讨论数据饱和或提供分析程序的足够细节,难以判断解释的稳健性。混合方法研究很少解释为什么两种方法都是必要的,定性和定量发现的整合有限。少数探索性或概念性贡献超出了MMAT的范围。综合来看,证据基础具有信息性,但存在中等偏倚风险,最一致的担忧来自抽样策略、工具验证和有限的方法学透明度。
此外,所有作者在主要筛选开始前阅读了(n=80)篇全文文章,以减少选择偏倚。
3.6 数据提取与合成
数据提取过程包括多个维度的信息收集。如表2所示,79.55%的评估材料于2024年发表,20.45%于2023年发表。
表2 文章发表年份分布
| 发表年份 | 文章数量 | 百分比 |
|---|---|---|
| 2024 | 35 | 79.55% |
| 2023 | 9 | 20.45% |
表3展示了各选定非洲国家的文章发表百分比。按降序排列,各非洲国家的文章数量依次为:加纳(18.18%)、阿尔及利亚(15.91%)、尼日利亚(15.91%)、肯尼亚(9.09%)、南非(9.09%)、突尼斯(6.82%)、埃及(4.55%)、埃塞俄比亚(4.55%)、坦桑尼亚(4.55%)、摩洛哥(4.55%)、安哥拉(2.27%)、博茨瓦纳(2.27%)和科特迪瓦(2.27%)。
表3 各非洲国家发表文章分布
| 非洲国家 | 文章数量 | 百分比 |
|---|---|---|
| 加纳 | 8 | 18.18% |
| 阿尔及利亚 | 7 | 15.91% |
| 尼日利亚 | 7 | 15.91% |
| 肯尼亚 | 4 | 9.09% |
| 南非 | 4 | 9.09% |
| 突尼斯 | 3 | 6.82% |
| 埃及 | 2 | 4.55% |
| 埃塞俄比亚 | 2 | 4.55% |
| 坦桑尼亚 | 2 | 4.55% |
| 摩洛哥 | 2 | 4.55% |
| 安哥拉 | 1 | 2.27% |
| 博茨瓦纳 | 1 | 2.27% |
| 科特迪瓦 | 1 | 2.27% |
表4详细列出了研究的方法论、研究焦点和期刊索引情况。方法论分布显示,定量研究方法占主导地位(48%),其次是混合方法(27%)、探索性研究(14%)和定性研究(11%)。
表4 研究方法论与索引分布
| 方法论类型 | 文章数量 | 百分比 |
|---|---|---|
| 定量研究 | 21 | 48% |
| 混合方法 | 12 | 27% |
| 探索性研究 | 6 | 14% |
| 定性研究 | 5 | 11% |
研究焦点分布显示,大多数研究的受访者是教师(41%)和学生(41%),其次是探索性/一般研究(14%),学生和教师组合研究最少(4%)。
关于期刊索引情况,研究发现大多数文章(82%)未发表在Scopus索引期刊上。发表在Scopus索引期刊上可以提高文章的可见性、科学质量和重要性,并获得学术界的广泛认可。
4 研究结果与讨论
4.1 非洲ChatGPT教育研究总体状况
4.1.1 研究数量与分布特征
自2022年11月ChatGPT推出以来,关于ChatGPT在非洲主要经济体教育中应用的研究总体上较为缺乏。来自13个非洲国家的44篇合格文章表明,关于教师和学习者对ChatGPT在教育中使用看法的研究存在不足。值得注意的是,只有18%的文章发表在Scopus索引期刊上。Scopus索引期刊提高了这些论文的可见性和合法性。这解释了为什么现有的关于ChatGPT在教育中使用的全球文献没有识别出与非洲相关的研究。
如表4所示,尼日利亚这样的大国没有Scopus索引或Web of Science索引文章。此外,以下国家没有Scopus或Web of Science索引文章:阿尔及利亚、安哥拉、科特迪瓦、博茨瓦纳、埃及、摩洛哥、坦桑尼亚和突尼斯。安哥拉、博茨瓦纳和科特迪瓦等国家自2022年11月以来只发表了一篇关于ChatGPT在教育中应用的合格文章。
4.1.2 研究方法与质量分析
研究方法论的分析揭示了非洲ChatGPT教育研究的特点。定量研究方法占据主导地位,这反映了研究者倾向于通过问卷调查收集大规模数据,以了解ChatGPT使用的现状和态度。然而,这种方法也存在局限性,如难以深入理解使用者的真实体验和深层动机。
混合方法研究虽然占比较高,但研究质量参差不齐。许多混合方法研究未能有效整合定量和定性数据,两种方法往往是并行使用而非真正融合。定性研究数量较少,这限制了对ChatGPT教育应用的深入理解。
研究质量方面,大多数研究采用便利抽样方法,样本代表性有限。许多研究没有报告响应率,难以评估无响应偏倚的影响。调查工具的信效度检验不足,影响了研究结论的可靠性。
4.2 ChatGPT在教育中的效益分析
4.2.1 教学效率提升
根据研究问题2,研究者基于表5开发了关于ChatGPT在教育中使用效益和挑战的主要主题。如图11所示,就选定的非洲国家而言,ChatGPT在教育中的使用效益主要是用于熟练度、语法和多语言支持,其次是用于行政任务以提高生产力。教师和学生还主要将其用于作业、考试、评估和评分。ChatGPT在教育中使用的最少三个方面是参考文献和书目支持、批判性思维和创造力,以及数据分析。
ChatGPT在提升教学效率方面展现出显著优势。首先,在课程准备方面,ChatGPT能够帮助教师快速生成教学大纲、课程计划和教学材料。研究表明,阿尔及利亚的教师认为ChatGPT具有提高教育质量的潜力。加纳的研究也发现,ChatGPT帮助教师完成行政和教学任务,提高了教师的生产力。
其次,在评估和反馈方面,ChatGPT能够自动化评分过程,提供即时反馈。埃及的研究显示,ChatGPT有助于自动化评估,节省时间。南非的研究也表明,ChatGPT减少了工作量,使教师能够将更多时间投入到教学创新中。
4.2.2 个性化学习支持
ChatGPT在个性化学习方面具有独特优势。通过分析学习者的输入,ChatGPT能够提供针对性的学习建议和资源推荐。肯尼亚的研究发现,ChatGPT为学习者提供了自适应学习体验,增强了学习者的自尊和效能感。摩洛哥的研究表明,ChatGPT促进了学生的自主学习。
个性化学习的理论基础源于建构主义学习理论。ChatGPT作为智能学习伙伴,能够根据学习者的认知水平和学习风格调整交互方式。这种适应性使学习者能够在自己的最近发展区内获得适当的支持,促进知识的主动建构。
然而,个性化学习支持也面临挑战。ChatGPT缺乏对学习者情感状态的理解,难以提供情感支持。此外,过度依赖ChatGPT可能导致学习者失去自主探索和发现的机会。
4.2.3 语言学习与多语言支持
ChatGPT在语言学习领域展现出巨大潜力。作为基于大规模语料库训练的语言模型,ChatGPT能够提供高质量的语言输入和输出示范。阿尔及利亚的研究发现,ChatGPT在语言教学和学习方面表现良好。埃塞俄比亚的研究也表明,ChatGPT支持多语言检索信息。
多语言支持对于非洲教育具有特殊意义。非洲大陆拥有超过2000种语言,语言多样性既是文化资源也是教育挑战。ChatGPT的多语言能力可以帮助跨越语言障碍,促进教育资源的共享和传播。然而,研究也发现ChatGPT在处理某些非洲本土语言时存在局限性,需要进一步改进。
4.2.4 研究与学术写作支持
ChatGPT在研究和学术写作方面提供了重要支持。突尼斯的研究发现,ChatGPT帮助生成想法,建议词汇和句子结构改进。尼日利亚的研究表明,ChatGPT能够清晰解释复杂概念,帮助教师创建课程笔记、考试题目、作业和评估。
在文献综述方面,ChatGPT能够快速总结相关研究,帮助研究者了解领域动态。然而,研究者也警告ChatGPT可能提供虚假信息或重复响应,需要使用者具备批判性评估能力。
4.3 ChatGPT在教育中的挑战分析
4.3.1 学术诚信问题
如图12所示,在非洲主要国家采用ChatGPT教育的主要挑战包括:伦理、透明度、信任、隐私、安全和偏见;懒惰、教师和学生的习惯循环,以及通用内容、可信度、不准确内容和脱离语境的响应。系统综述还发现,ChatGPT抑制了批判性思维、认知和创造力。
学术诚信是ChatGPT教育应用面临的最突出挑战。多项研究报道了学生使用ChatGPT进行抄袭和学术不端行为。加纳的研究发现,ChatGPT导致学生抄袭。肯尼亚的研究表明,ChatGPT助长了学术不诚实。尼日利亚的研究也指出,ChatGPT促进了学生作弊。
抄袭问题的根源在于ChatGPT生成的内容难以被传统抄袭检测工具识别。ChatGPT生成的文本是原创的,但并非学生自己的作品,这给学术诚信带来了新的挑战。研究者建议开发专门的ChatGPT抄袭检测软件,并制定明确的学术诚信政策。
4.3.2 批判性思维与创造力影响
ChatGPT的过度使用可能对学习者的批判性思维和创造力产生负面影响。加纳的研究发现,学生过度依赖ChatGPT会失去学科理解,抑制问题解决能力。摩洛哥的研究表明,ChatGPT减少了创造力和学生之间的社交互动。
从认知负荷理论的角度分析,ChatGPT虽然可以降低外在认知负荷,但过度依赖可能导致必要认知负荷的减少。学习者需要通过主动思考和问题解决来构建知识,过度依赖外部工具可能削弱这一过程。
创造力的发展需要探索和试错的过程。当学习者可以直接获得ChatGPT生成的答案时,可能失去探索的动力和机会。这种"认知卸载"虽然提高了效率,但可能损害深度学习和创新能力的发展。
4.3.3 数据隐私与安全风险
数据隐私和安全是ChatGPT教育应用的重要关切。多项研究表达了对ChatGPT数据收集和使用方式的担忧。埃塞俄比亚的研究指出,ChatGPT存在数据隐私和安全问题。加纳的研究也发现了ChatGPT的隐私和数据安全问题。
ChatGPT在交互过程中收集用户输入的信息,这些信息可能包含敏感的个人数据或学术内容。用户对数据如何被存储、处理和使用缺乏了解,这引发了隐私担忧。此外,ChatGPT的训练数据可能包含偏见,导致输出结果存在歧视性内容。
4.3.4 技术基础设施限制
非洲国家在ChatGPT教育应用方面面临独特的基础设施挑战。阿尔及利亚的研究发现,大学在技术上装备不足,基础设施投资至关重要。埃塞俄比亚的研究强调需要有效的互联网连接来访问人工智能应用。
基础设施限制包括:互联网连接不稳定、电力供应不足、数字设备缺乏、技术支持能力有限等。这些限制不仅影响ChatGPT的可访问性,也加剧了教育不平等。城市和农村地区之间的数字鸿沟可能进一步扩大。
4.4 概念框架:效益、挑战与解决方案的综合分析
4.4.1 三维分析框架
虽然现有的关于ChatGPT教育应用的全球综述提供了有价值的见解,但许多综述倾向于重申常见的类别,如翻译支持、反馈提供、抄袭风险和内容生成。这些研究提供了重要的起点,但主要是描述性的,往往忽视了背景差异。相比之下,本综述通过提出一个概念框架推进了讨论,该框架在针对非洲教育背景的结构类型学中综合了效益、挑战和解决方案。
表6中的框架沿三个主要维度组织:效益、挑战和解决方案。这些维度通过三个背景层面进行进一步分析,这些层面在非洲尤为突出:教学层面、制度层面和社会文化层面。这种多维矩阵允许对证据进行比较性阅读,不仅展示ChatGPT为教育提供了什么,还展示其使用如何受到课堂实践、制度能力和更广泛的社会文化现实的影响。
表6 非洲教育中ChatGPT的概念框架
| 维度 | 教学层面 | 制度层面 | 社会文化层面 |
|---|---|---|---|
| 效益 | 提高教学效率(课程规划、评分、评估);支持个性化学习;改善写作和多语言学习 | 减少行政工作量;支持课程设计;促进研究生产力 | 在资源受限的环境中扩大教育机会;跨越语言鸿沟;支持包容性 |
| 挑战 | 学术不诚实、抄袭和过度依赖;批判性思维和创造力下降 | 基础设施薄弱、互联网不可靠、教师培训有限;缺乏制度政策和抄袭检测系统 | 算法偏见、缺乏文化适应、城乡学校之间获取不平等;师徒关系和社交互动的侵蚀 |
| 解决方案 | 对教师和学生进行伦理培训;促进创造力和问题解决能力的评估设计 | 制度和国家人工智能政策框架;基础设施投资;抄袭检测工具;人工智能融入课程 | 支持本土语言和文化相关内容;注重公平的人工智能策略;针对非洲教育现实的伦理准则 |
4.4.2 教学层面的分析
在教学层面,综述发现ChatGPT增强了课程准备、评估和多语言学习。然而,它同时也创造了抄袭、批判性思维下降和学生过度依赖的风险。这一层面的发现反映了ChatGPT作为教学工具的双重性:既是效率提升器,也可能是学习质量的威胁。
教学层面的解决方案需要平衡效率和质量。教师培训应关注如何有效整合ChatGPT,同时保持对学生高阶思维能力的培养。评估设计需要创新,减少ChatGPT可能带来的负面影响,如采用口头答辩、实践操作等难以被ChatGPT替代的评估方式。
4.4.3 制度层面的分析
在制度层面,ChatGPT支持行政效率和课程创新,但这些效益受到许多非洲国家基础设施薄弱、监管框架脆弱和政策方向有限的制约。制度层面的挑战反映了非洲教育系统的结构性问题,这些问题在ChatGPT引入之前就存在,但ChatGPT的应用可能加剧这些问题的可见性。
制度层面的解决方案需要系统性的政策干预。国家和教育机构需要制定明确的人工智能使用政策,建立抄袭检测系统,投资基础设施建设。这些措施需要政府、教育机构和技术提供者的协同努力。
4.4.4 社会文化层面的分析
在社会文化层面,ChatGPT有潜力在资源不足的环境中扩大教育机会,跨越语言鸿沟。然而,关于文化偏见、城乡地区之间获取不平等以及传统师徒结构侵蚀的担忧持续存在。社会文化层面的分析揭示了ChatGPT教育应用的社会影响,这些影响超越了教学和制度层面。
社会文化层面的解决方案需要关注公平性和文化适应性。ChatGPT的开发应考虑非洲的文化背景,支持本土语言。教育政策应关注数字鸿沟问题,确保所有学习者都能公平地获得人工智能教育工具。
ChatGPT教育应用框架
解决方案维度
挑战维度
效益维度
伦理培训
教学效率提升
学术诚信问题
个性化学习支持
批判性思维下降
多语言能力
基础设施限制
研究生产力
数据隐私风险
政策框架
基础设施投资
文化适应
5 区域比较分析
5.1 北非地区:基础设施与文化适应
5.1.1 研究发现概述
北非地区,特别是阿尔及利亚、摩洛哥和突尼斯,其讨论高度重视基础设施和技术准备度。多项研究强调了现有数字基础设施的局限性以及由此产生的对ChatGPT的制度依赖。与其他地区相比,算法偏见和文化适应问题在该地区也更为突出。
阿尔及利亚的研究主要关注教师对ChatGPT的态度和使用情况。研究发现,大多数教师认为ChatGPT有潜力提高教育质量,但同时也表达了对技术过度依赖和学生创造力下降的担忧。阿尔及利亚大学在技术装备方面存在不足,基础设施投资被认为是重要的改进方向。
摩洛哥的研究聚焦于ChatGPT对学术写作的影响。研究发现,ChatGPT为学生提供了即时的内容支持,帮助改进句子结构,但也存在内容范围有限、缺乏更新知识、不引用来源等问题。摩洛哥研究者建议开发专门的抄袭检测软件,并制定伦理指导原则。
突尼斯的研究评估了ChatGPT在医学教育中的能力。研究发现,ChatGPT能够提供连贯和认知性的响应,有效处理临床数据和生物医学信息,但在处理药理学、病理学和临床肺病学等学科问题时面临挑战。研究还发现了ChatGPT响应中的偏见和文化适应困难。
5.1.2 区域特点分析
北非地区的ChatGPT教育应用呈现出以下特点:首先,基础设施问题是首要关切,反映了该地区数字化发展的不平衡;其次,文化适应问题受到重视,阿拉伯语和法语的使用背景对ChatGPT的应用提出了特殊要求;第三,教师培训需求突出,需要提升教师使用ChatGPT的能力。
北非地区的解决方案优先考虑基础设施投资、人工智能融入课程以及部署抄袭检测系统。这些解决方案反映了该地区对技术基础设施和制度建设的重视。
5.2 西非地区:学术诚信与伦理框架
5.2.1 研究发现概述
西非文献,特别是来自加纳和尼日利亚的研究,主要关注学生滥用和学术诚信问题。在这里,ChatGPT较少被视为对基础设施稳定的威胁,而更多地被视为对教育诚实的直接挑战。抄袭、表面学习和问题解决能力丧失是反复出现的主题。
加纳的研究涵盖了多个方面,包括教师和学生对ChatGPT的认知、态度和使用情况。研究发现,ChatGPT帮助教师完成行政和教学任务,提高生产力,但也导致学生抄袭。加纳研究者强调需要培训教育利益相关者,提高对ChatGPT的认识,并将负责任的人工智能整合到课程中。
尼日利亚的研究探讨了ChatGPT对学术研究和教育的影响。研究发现,ChatGPT能够增强教学和学习,提供响应式查询结果,清晰解释复杂概念,但也增加了学生抄袭,促进了懒惰的学术态度。尼日利亚研究者建议教育负责任地使用人工智能应用,并制定伦理和技术框架。
5.2.2 区域特点分析
西非地区的ChatGPT教育应用呈现出以下特点:首先,学术诚信问题是核心关切,反映了该地区对教育质量的重视;其次,学生滥用问题突出,需要制定明确的使用规范;第三,伦理框架建设需求迫切,需要平衡技术采用和学术诚信。
西非地区的解决方案强调创建伦理框架、开展意识宣传活动以及平衡人工智能采用与传统学习模式的策略。这些解决方案反映了该地区对教育伦理和学生发展的关注。
5.3 东非地区:评估完整性与学习成果
5.3.1 研究发现概述
东非地区,主要由肯尼亚、埃塞俄比亚和坦桑尼亚代表,其关键关切是评估完整性和学习成果。肯尼亚的研究特别强调了缺勤和伪造作品作为ChatGPT采用的后果。该地区还强调了连接性的局限性,这阻碍了对人工智能工具的公平获取。
肯尼亚的研究调查了ChatGPT对本科宗教教育师范生自适应学习体验的影响。研究发现,ChatGPT提供自我解释的响应,增强学习者的自尊和效能感,但也鼓励学生懒惰,导致学习成果不佳。肯尼亚研究者建议教育学生和教师如何使用ChatGPT,并改革评估系统,强调当面参与。
埃塞俄比亚的研究探讨了学生对人工智能聊天机器人的满意度。研究发现,ChatGPT用于考试准备、作业和研究目的,支持多语言信息检索,帮助参考文献和书目支持,解释复杂主题,节省时间并提高生产力。然而,也存在数据隐私和安全问题、个性化学习困难、生成内容质量问题以及对批判性思维的负面影响。
坦桑尼亚的研究调查了大学生对ChatGPT的看法。研究发现,ChatGPT用于作业、研究提案和报告写作,提供教育机会,增加学生的创造力和创新,帮助学生准备考试。但也降低了学生的批判性思维,减少了学生的自主性,促进了懒惰,鼓励学术不诚实。
5.3.2 区域特点分析
东非地区的ChatGPT教育应用呈现出以下特点:首先,评估完整性是核心关切,反映了该地区对教育质量的关注;其次,互联网连接限制影响公平获取,加剧了数字鸿沟;第三,学习成果问题受到重视,需要平衡技术应用和学习效果。
东非地区的解决方案集中在改革评估系统,强调当面参与和更严格的评估方法,同时投资互联网基础设施和教师培训。这些解决方案反映了该地区对教育公平和学习质量的关注。
5.4 南部非洲地区:伦理治理与就业影响
5.4.1 研究发现概述
南部非洲地区,包括南非、博茨瓦纳和安哥拉,其特点是对伦理治理和劳动力市场影响的关注。除了抄袭和隐私担忧外,南非的学术研究明确提出了由于人工智能自动化导致教师失业的可能性。因此,该地区的解决方案强烈倡导制定伦理准则、制度政策和意识研讨会,以指导负责任的使用。
南非的研究探讨了女性学者和研究人员对ChatGPT的使用情况。研究发现,ChatGPT帮助减少工作量,提供多语言支持,易于访问,帮助文献综述,改进写作技能。但也减少了在传统图书馆的时间,限制了学生和教师的批判性思维,一些响应不准确,导致偏见和抄袭,减少了协作和社交互动。南非研究者建议开展意识研讨会,加强技术支持,制定政策文件支持ChatGPT的伦理使用。
博茨瓦纳的研究开发了教育机构采用ChatGPT的测量工具。研究发现,ChatGPT在学术工作中有用,帮助完成学生项目,是用户友好的平台。但也创造了习惯循环。
安哥拉的研究探讨了人工智能在英语教学中的整合。研究发现,ChatGPT促进英语教学,支持教学和学习,帮助评估和评分,定制学习体验。但也使教师和学生懒惰,存在隐私、信任和透明度问题,可能基于算法产生偏见。
5.4.2 区域特点分析
南部非洲地区的ChatGPT教育应用呈现出以下特点:首先,伦理治理是核心关切,反映了该地区对负责任技术使用的重视;其次,就业影响问题受到关注,特别是教师职业的未来;第三,对平衡技术采用和人际互动的需求突出。
南部非洲地区的解决方案强烈倡导制定伦理准则、制度政策和意识研讨会,以指导负责任的使用。同时,该地区对平衡技术采用和保护教育就业的敏感性更高。
5.5 区域比较总结
南部非洲地区
解决方案
伦理治理
人际互动平衡
就业影响
东非地区
解决方案
评估完整性
学习成果关注
互联网连接限制
西非地区
解决方案
学术诚信问题
伦理框架需求
学生滥用风险
北非地区
解决方案
基础设施问题
教师培训需求
文化适应挑战
对北非、西非、东非和南部非洲研究的比较分析揭示了ChatGPT在教育背景下的感知和应用存在显著的相似性。教师和学生都指出了该工具在课程准备、作业支持、语言学习和减少日常工作量方面的有用性。学生经常将ChatGPT描述为方便和节省时间的工具,而教育者则经常强调其在评分和课程设计中提高效率的潜力。
除了这些效益外,几乎每个区域研究都提出了类似的担忧。最常见的是抄袭、学术不诚实以及学生对系统过度依赖的危险,这对其创造力和问题解决能力产生了连锁影响。关于数据保护、算法偏见以及响应生成方式缺乏透明度的担忧也出现在整个非洲大陆。
在提出的解决方案方面也存在一定程度的共识。各研究作者强调教师和学生培训的重要性、制度和政策框架的必要性,以及基础设施在确保公平和可持续获取方面的作用。这些共同主题表明,尽管背景可能有所不同,但ChatGPT在教育中的机遇和风险得到广泛和一致的认可。
6 ChatGPT教育应用的伦理框架与政策建议
6.1 伦理原则与指导准则
6.1.1 教育人工智能伦理的核心原则
ChatGPT在教育中的应用需要遵循一系列伦理原则,以确保技术的负责任使用。这些原则包括透明性、公平性、隐私保护、问责制和人类监督。
透明性原则要求教育利益相关者了解ChatGPT的工作原理、局限性和潜在风险。教师应向学生明确说明何时可以使用ChatGPT,何时需要独立完成工作。教育机构应公开其人工智能使用政策,确保所有利益相关者了解相关规定。
公平性原则关注ChatGPT使用的可及性和结果公正。教育机构应确保所有学生都能公平地获得ChatGPT相关资源,避免数字鸿沟加剧教育不平等。同时,ChatGPT的评估应用应避免算法偏见对特定学生群体的歧视。
隐私保护原则要求保护用户数据安全和隐私。教育机构应制定数据保护政策,明确ChatGPT使用过程中收集的数据如何被存储、处理和使用。学生应被告知其数据可能被收集,并有权选择是否使用ChatGPT。
问责制原则明确各方责任。教育机构、教师、学生和技术提供者都应对ChatGPT的使用承担相应责任。当出现问题时,应有明确的问责机制和处理流程。
人类监督原则强调人工智能应作为辅助工具而非替代人类决策。教师应保持对教学过程的主导权,学生应保持对学习的主动权。ChatGPT的建议应经过人类审核后才能实施。
6.1.2 使用指南与最佳实践
基于伦理原则,研究提出了以下ChatGPT教育使用指南:
对于教师而言,应将ChatGPT作为教学辅助工具而非替代品。在使用ChatGPT准备教学材料时,应审核和修改生成的内容,确保其准确性和适当性。教师应教育学生如何负责任地使用ChatGPT,培养其批判性思维能力。
对于学生而言,应将ChatGPT作为学习支持工具而非答案生成器。在使用ChatGPT时,应理解生成内容的原理,评估其准确性,并将其作为学习的起点而非终点。学生应遵守学术诚信规范,明确标注ChatGPT的使用情况。
对于教育机构而言,应制定明确的ChatGPT使用政策,包括允许使用的场景、禁止使用的情况、违规处理措施等。机构应提供相关培训,帮助教师和学生掌握ChatGPT的有效使用方法。
6.2 政策框架建议
6.2.1 国家层面政策建议
国家层面的政策框架应涵盖以下几个方面:
首先,制定人工智能教育战略。各国应制定明确的人工智能教育发展战略,将ChatGPT等人工智能工具纳入教育现代化规划。战略应明确发展目标、实施路径和评估指标。
其次,建立监管机制。政府应建立人工智能教育应用的监管机制,包括技术标准、使用规范、质量评估等。监管应平衡创新促进和风险防控。
第三,投资基础设施建设。政府应加大对教育信息化的投资,改善互联网连接、数字设备和电力供应等基础设施条件,为人工智能教育应用创造良好环境。
第四,支持教师培训。政府应支持教师人工智能素养培训项目,提升教师使用ChatGPT等工具的能力。培训应涵盖技术操作、教学整合和伦理意识等方面。
第五,促进研究和评估。政府应支持人工智能教育应用的研究和评估,了解技术应用的效果和影响,为政策调整提供证据支持。
6.2.2 机构层面政策建议
教育机构层面的政策框架应涵盖以下几个方面:
首先,制定机构使用政策。各教育机构应制定适合自身情况的ChatGPT使用政策,明确使用范围、规范要求和违规处理。
其次,整合课程设计。机构应将人工智能素养纳入课程体系,教育学生如何负责任地使用ChatGPT等工具。课程设计应平衡技术应用和核心能力培养。
第三,建立支持系统。机构应建立技术支持和教学支持系统,帮助教师和学生解决使用ChatGPT过程中遇到的问题。
第四,开发评估方法。机构应开发适应人工智能时代的新型评估方法,减少ChatGPT可能带来的学术诚信问题,同时评估学生的真实能力。
第五,营造伦理文化。机构应营造负责任使用人工智能的伦理文化,通过宣传、培训和案例分享等方式提升利益相关者的伦理意识。
6.3 技术解决方案
6.3.1 抄袭检测系统
针对ChatGPT可能带来的学术诚信问题,研究建议开发专门的抄袭检测系统。这些系统应能够识别ChatGPT生成的内容,区分人类写作和机器生成文本。
技术实现方面,可以采用以下方法:分析文本的语言特征,如词汇多样性、句法复杂度、语义连贯性等;检测文本中的统计模式,如词频分布、n-gram特征等;使用机器学习模型分类人类写作和机器生成文本。
然而,抄袭检测系统也面临挑战。ChatGPT生成的文本具有高度的原创性和多样性,难以通过简单的模式匹配检测。此外,学生可能对ChatGPT生成的内容进行修改,进一步增加检测难度。因此,技术解决方案应与教育方法相结合,培养学生的学术诚信意识。
6.3.2 数据保护框架
针对数据隐私和安全问题,研究建议建立健壮的数据保护框架。框架应涵盖数据收集、存储、处理和使用的全过程。
数据收集方面,应遵循最小化原则,只收集必要的数据。用户应被告知数据收集的目的和范围,并有权选择是否提供数据。
数据存储方面,应采用安全存储技术,如加密存储、分布式存储等。数据应存储在本地服务器或可信的云服务中,避免跨境数据传输带来的风险。
数据处理方面,应建立数据处理规范,明确数据访问权限和处理流程。敏感数据应进行脱敏处理,保护用户隐私。
数据使用方面,应明确数据使用范围,禁止将教育数据用于商业目的。用户应有权查看、修改和删除其个人数据。
6.3.3 文化适应与本地化
针对文化适应问题,研究建议ChatGPT支持本地内容和文化敏感性。具体措施包括:
首先,支持非洲本土语言。ChatGPT应扩展对非洲语言的支持,使更多学习者能够使用母语进行交互。这需要收集和标注非洲语言数据,训练专门的语言模型。
其次,适应文化背景。ChatGPT的响应应考虑非洲的文化背景,避免输出与文化价值观冲突的内容。这需要在训练数据中纳入非洲文化内容,并进行文化敏感性调整。
第三,支持本地教育内容。ChatGPT应能够访问和引用本地教育资源,如本地教材、学术期刊和教育网站。这需要建立本地教育资源数据库,并与ChatGPT集成。
7 与现有综述的比较研究
7.1 与全球综述的对比
7.1.1 效益发现的比较
Memarian和Doleck、Elbanna和Armstrong以及Bettayeb等人的综述提到了语言翻译、减少行政负担、个性化学习、语法增强、异步响应、增强参与和多样化评估作为ChatGPT在教育中使用的主要优势。他们识别的优势与本研究的发现一致,尽管他们的研究是在非洲之外进行的。
相比之下,Marta Montenegro-Rueda等人和Rahman和Watanobe的综述提到了分析技能发展、协作和团队合作作为ChatGPT在教育中的优势,而这在本研究中被发现是一个劣势。这一差异可能反映了非洲教育背景的特殊性,如班级规模大、资源有限等,这些因素可能影响协作学习的效果。
7.1.2 挑战发现的比较
Bettayeb等人、Memarian和Doleck、Elbanna和Armstrong以及Rahman和Watanobe的综述发现的挑战与本研究一致,提到了透明度、抄袭、偏见、伦理担忧、隐私、懒惰、缺乏高阶技能、机构声誉和信任作为ChatGPT在教育中使用的问题。
这些一致性表明,ChatGPT教育应用的挑战具有普遍性,不受地域限制。然而,非洲背景下的挑战可能更为突出,如基础设施限制加剧了数字鸿沟问题,监管框架薄弱增加了伦理风险。
7.1.3 解决方案发现的比较
在寻找引导实施的解决方案方面,Bettayeb等人强调了ChatGPT教育实施政策框架的必要性。Marta Montenegro-Rueda等人提到了制度支持、技术基础设施、文化背景和社会经济地位对伦理实施的重要性,而Lo强调了使用人工智能聊天机器人时抄袭检测器的重要性。
尽管他们提出的伦理实施解决方案与本研究一致,但本研究进一步建议了监管控制机制和法律、情感基调、支持本地内容、数据保护框架、师徒制和培训作为人工智能聊天机器人有效融入教学法的重要因素。这些补充建议反映了非洲教育背景的特殊需求。
7.2 本研究的创新贡献
7.2.1 非洲视角的独特性
本综述在非洲背景下具有创新性。它评估了来自非洲主要国家的44篇文章,以确定ChatGPT教育研究在非洲大陆的程度。这是第一篇关于ChatGPT在非洲教育使用的综述,发现呼吁立即采取行动,通过培训、指导法律、政策、伦理准则和标准确保ChatGPT正确融入教学法。
非洲视角的独特性体现在以下几个方面:首先,关注非洲特有的基础设施挑战;其次,考虑非洲的文化和语言多样性;第三,针对非洲教育系统的结构性问题提出解决方案。
7.2.2 概念框架的贡献
本研究提出的概念框架将效益、挑战和解决方案整合在三维矩阵中,为理解ChatGPT教育应用提供了系统性视角。框架考虑了教学、制度和社会文化三个层面,超越了简单的效益-挑战二元分析。
这一框架可以指导后续研究和政策制定。研究者可以基于框架开展更深入的专题研究,政策制定者可以参考框架设计综合性政策方案。
8 结论与未来展望
8.1 研究结论
本综合综述在非洲背景下具有创新意义。它评估了来自非洲主要国家的44篇文章,以确定ChatGPT教育研究在非洲大陆的程度。首先,综述考察了ChatGPT在教育中使用的优势。其次,研究讨论了采用ChatGPT进行教育目的的劣势。最后,概述了ChatGPT在教育中结构化实施的解决方案,供政策制定者、教育者、学生和开发者遵守。
这是第一篇关于ChatGPT在非洲教育使用的综述,发现呼吁立即采取行动,通过培训、指导法律、政策、伦理准则和标准确保ChatGPT正确融入教学法。总体而言,评估强调了ChatGPT的重要性及其为教育利益相关者提供的重大帮助,但警告教育当局不要忽视其在缺乏适当监管情况下的潜在危险。
8.2 研究局限性
尽管本研究阐明了ChatGPT在非洲主要国家教育中的效益和挑战,但仍存在一些局限性。研究范围的限制仅限于某些非洲国家,这抑制了发现对所有非洲国家的推广。其次,尽管研究者努力纳入规定年份内发表的所有文章,但研究可能没有捕获目标国家的每篇相关文章。一些被审查的非洲国家研究产出有限,高质量期刊出版物稀缺,这限制了详细跨国分析的深度。最后,研究依赖于截至2024年的文章。
8.3 未来研究方向
未来的研究计划在2026年之前对ChatGPT在教育中的应用进行另一项系统综述,涵盖所有非洲国家。这将扩大研究范围,提供更全面的非洲ChatGPT教育应用图景。
此外,未来研究可以关注以下方向:开展纵向研究,追踪ChatGPT教育应用的长期影响;进行实验研究,评估ChatGPT在不同教育场景中的效果;开展比较研究,对比不同国家ChatGPT教育政策的实施效果;开发评估工具,测量学生和教师的人工智能素养。
8.4 对中国教育的启示
虽然本研究聚焦于非洲国家,但其发现对中国教育也具有重要的启示意义。中国在人工智能教育应用方面处于全球领先地位,但也面临类似的挑战,如学术诚信、数据隐私、教师培训等。
首先,中国可以借鉴非洲的经验,制定完善的人工智能教育伦理框架,明确ChatGPT等工具的使用边界和规范。其次,中国应关注数字鸿沟问题,确保人工智能教育资源的公平分配。第三,中国应加强教师人工智能素养培训,提升教师整合人工智能工具的能力。第四,中国应开发本土化的人工智能教育解决方案,考虑中国的文化背景和教育特点。
参考文献
1 Dake D K, Gbagbo F Y. ChatGPT's benefits, acceptance, and ethical challenges for teaching and learning in key African countries: a systematic review of literature from 2022 to 2024J. Discover Education, 2026, 5: 62.
2 Vaswani A, Shazeer N, Parmar N, et al. Attention is all you needC//Advances in neural information processing systems. 2017: 5998-6008.
3 Brown T, Mann B, Ryder N, et al. Language models are few-shot learnersC//Advances in neural information processing systems. 2020, 33: 1877-1901.
4 OpenAI. GPT-4 Technical ReportJ. arXiv preprint arXiv:2303.08774, 2023.
5 Sweller J. Cognitive load theoryM//Psychology of learning and motivation. Academic Press, 2011, 55: 37-76.
6 Zimmerman B J. A social cognitive view of self-regulated academic learningJ. Journal of educational psychology, 1989, 81(3): 329.
7 Chen L, Chen P, Lin Z. Artificial intelligence in education: A reviewJ. IEEE Access, 2020, 8: 75264-75278.
8 Zawacki-Richter O, Marín V I, Bond M, et al. Systematic review of research on artificial intelligence applications in higher education---where are the educators?J. International Journal of Educational Technology in Higher Education, 2019, 16(1): 1-27.
9 Bettayeb S, Al-Sharafi Z, Mufadhal A, et al. The conversational impact of ChatGPT in education: A systematic literature reviewJ. 2023.
10 Lo C K. What is the impact of ChatGPT on education? A rapid review of the literatureJ. Education Sciences, 2023, 13(4): 410.
11 Memarian B, Doleck T. ChatGPT in education: Methods, potentials, and limitationsJ. Computers and Education: Artificial Intelligence, 2023, 5: 100177.
12 Elbanna A, Armstrong A. The benefits and challenges of ChatGPT in education: A systematic reviewJ. 2023.
13 Rahman M M, Watanobe Y. ChatGPT for education and research: A review of benefits and challengesJ. 2023.
14 Montenegro-Rueda M, Fernández-Cerero J, Fernández-Batanero F. ChatGPT in education: A systematic reviewJ. 2023.
15 Haleem A, Javaid M, Qadri M A, et al. Understanding the role of digital technologies in education: A reviewJ. Sustainable Operations and Computers, 2022, 3: 275-285.
16 Statista. Artificial intelligence market size worldwideEB/OL. 2024. https://www.statista.com/outlook/tmo/artificial-intelligence/worldwide.
17 Exploding Topics. ChatGPT users statisticsEB/OL. 2024. https://explodingtopics.com/blog/chatgpt-users.
18 Hong Q, Li S, Wu C, et al. Applications, benefits, challenges, and areas of development in the use of AI-chatbots in education: A systematic literature reviewJ. Digital Education Review, 2025, 47: 1-20.