1)算法基本思想
采用快慢指针(双指针)法,在不改变链表结构、仅遍历一次链表的前提下找到倒数第 k 个节点:
-
定义两个指针
fast(快指针)和slow(慢指针),初始都指向链表的第一个数据节点(表头节点的下一个节点)。 -
先让
fast指针向前移动k步,此时fast与slow之间恰好间隔k-1个节点,两者距离为k。 -
之后让
fast和slow同时以相同速度向后移动,直到fast指向NULL(到达链表末尾)。 -
此时
slow指针指向的节点就是倒数第 k 个节点。 -
若在
fast先走k步的过程中就遇到NULL,说明链表长度不足k,查找失败。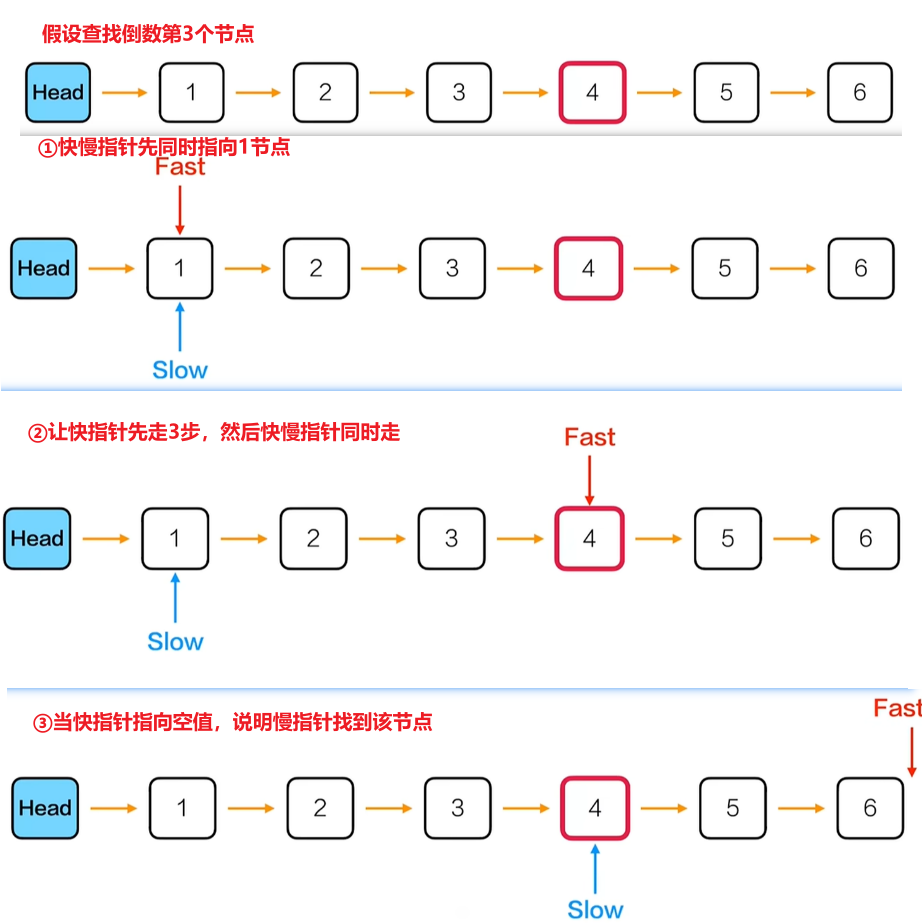
2)算法详细实现步骤
- 初始化指针 :
- 定义
fast和slow指针,均指向表头节点的下一个节点(即链表第一个有效数据节点)。
- 定义
- 快指针先行 :
- 循环
k次,让fast指针向后移动;若移动过程中fast变为NULL,说明链表长度小于k,直接返回0。
- 循环
- 同步移动指针 :
- 当
fast不为NULL时,fast和slow同时向后移动,直到fast指向NULL。
- 当
- 输出结果 :
- 若成功找到,输出
slow指向节点的data值,并返回1;否则返回0。
- 若成功找到,输出
3)核心代码逐行注释
cpp
int findNodeFS(Node *L, int k) {
// 初始化快慢指针,均指向第一个有效数据节点(表头节点L不存数据)
Node *fast = L->link;
Node *slow = L->link;
// 快指针先走k步,拉开与慢指针的距离
for (int i = 0; i < k; i++) {
// 若快指针在k步内遇到NULL,说明链表长度 < k,直接返回0
if (fast == NULL) {
return 0;
}
fast = fast->link; // 快指针向后移动一个节点
}
// 快慢指针同步移动,直到快指针到达链表末尾(NULL)
while (fast != NULL) {
fast = fast->link; // 快指针后移
slow = slow->link; // 慢指针后移,始终与快指针保持k步距离
}
// 此时慢指针恰好停在倒数第k个节点上
printf("倒数第%d个节点的值为:%d\n", k, slow->data);
return 1; // 查找成功
}完整可运行代码(C 语言)
cpp
#include <stdio.h>
#include <stdlib.h>
// 定义链表节点结构
typedef struct Node {
int data; // 数据域
struct Node *link; // 指针域,指向下一个节点
} Node;
// 函数:查找倒数第k个节点
// 参数:L-链表头指针(带表头节点),k-倒数位置
// 返回:1-查找成功,0-查找失败
int findNodeFS(Node *L, int k) {
// 1. 初始化快慢指针,指向第一个数据节点(跳过表头节点)
Node *fast = L->link; // 快指针
Node *slow = L->link; // 慢指针
// 2. 快指针先向前走k步
for (int i = 0; i < k; i++) {
// 若快指针提前走到NULL,说明链表长度不足k,查找失败
if (fast == NULL) {
return 0;
}
fast = fast->link; // 快指针后移
}
// 3. 快慢指针同时向后移动,直到快指针到达链表末尾
while (fast != NULL) {
fast = fast->link; // 快指针后移
slow = slow->link; // 慢指针后移
}
// 4. 此时慢指针指向倒数第k个节点,输出结果
printf("倒数第%d个节点的值为:%d\n", k, slow->data);
return 1; // 查找成功
}
// 辅助函数:创建新节点
Node* createNode(int data) {
Node *newNode = (Node*)malloc(sizeof(Node));
newNode->data = data;
newNode->link = NULL;
return newNode;
}
// 辅助函数:尾插法创建链表(带表头节点)
Node* createList(int arr[], int n) {
Node *head = (Node*)malloc(sizeof(Node)); // 创建表头节点(不存数据)
head->link = NULL;
Node *tail = head; // 尾指针,便于尾插
for (int i = 0; i < n; i++) {
Node *newNode = createNode(arr[i]);
tail->link = newNode; // 新节点插入尾部
tail = newNode; // 尾指针后移
}
return head;
}
// 辅助函数:释放链表内存
void freeList(Node *head) {
Node *p = head;
while (p != NULL) {
Node *temp = p;
p = p->link;
free(temp);
}
}
// 主函数:测试
int main() {
int arr[] = {1, 2, 3, 4, 5, 6}; // 测试数据
int n = sizeof(arr)/sizeof(arr[0]);
Node *list = createList(arr, n); // 创建链表
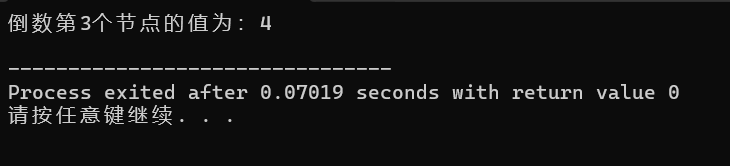
int k = 3; // 查找倒数第3个节点
int result = findNodeFS(list, k);
if (result == 0) {
printf("查找失败:链表长度不足%d\n", k);
}
freeList(list); // 释放内存
return 0;
}运行结果截图
算法复杂度分析
- 时间复杂度 :O(n),仅遍历链表一次,快指针总共走
n步,慢指针走n-k步,整体为线性时间。 - 空间复杂度:O(1),仅使用两个额外指针,无其他辅助空间。
该方法高效且无需额外存储,是链表找倒数第 k 个节点的最优解法之一。
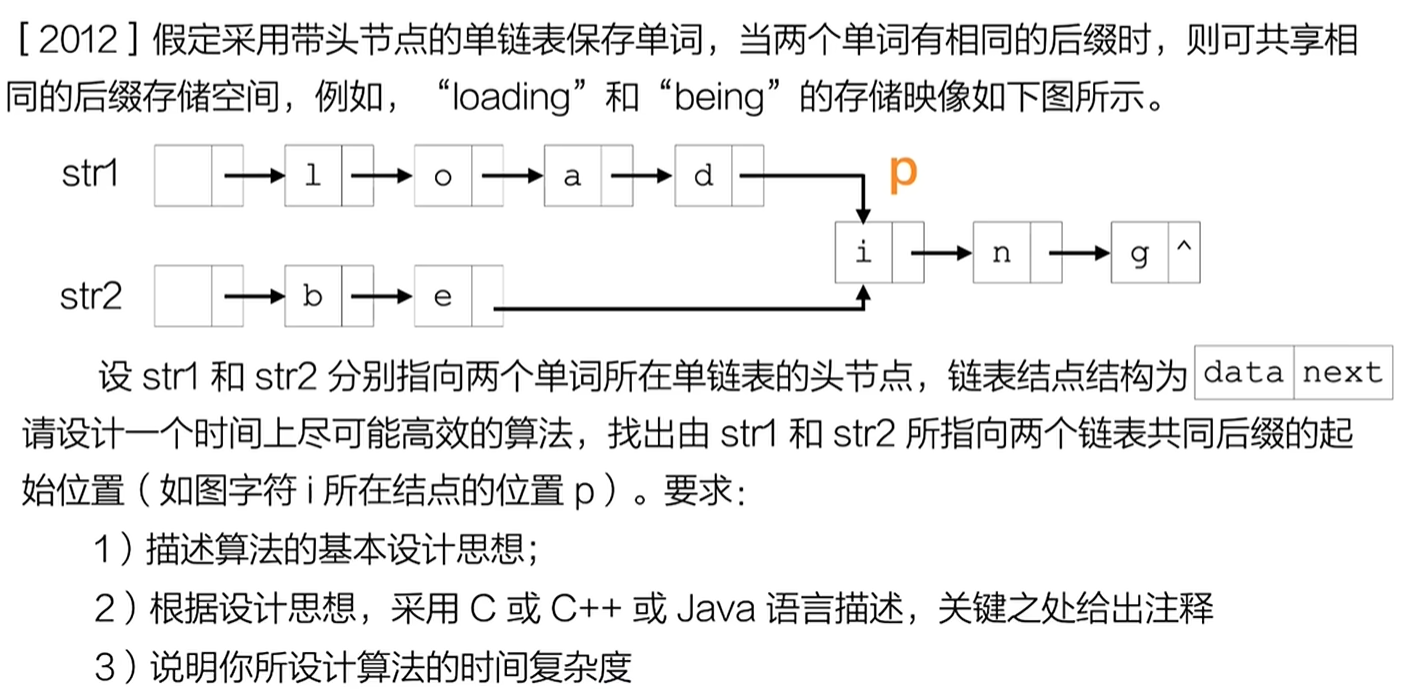
1)算法基本设计思想
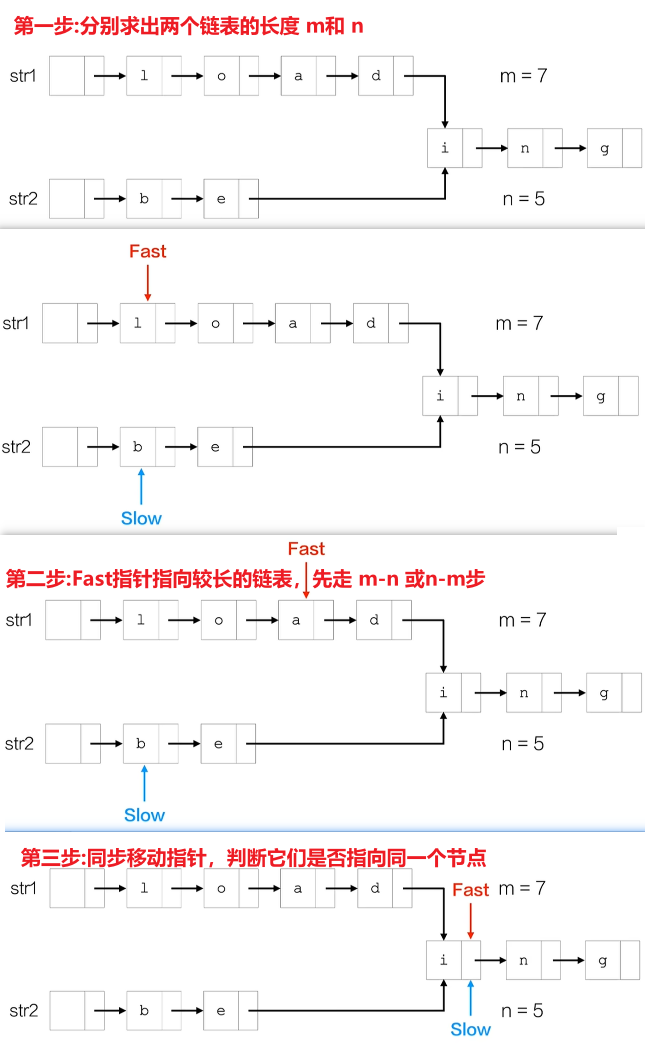
这道题本质是求两个带头结点单链表的公共后缀起始节点 (即链表的 "相交节点"),采用长度差 + 双指针的高效思路:
- 第一步:求长度 :分别遍历两个链表,得到它们的长度
len1和len2。 - 第二步:对齐起点 :让较长链表的指针先向前移动
|len1 - len2|步,使两个指针距离链表末尾的步数相同。 - 第三步:同步遍历 :两个指针同时向后移动,直到指向同一个节点,该节点就是共同后缀的起始位置;若遍历到末尾仍未相遇,则无公共后缀。
这种方法只需要遍历链表两次,时间效率很高,且不需要额外存储空间。
核心代码(查找公共后缀的核心逻辑)
cpp
// 定义链表节点结构
typedef struct Node {
char data; // 存储字符(单词的字母)
struct Node *next; // 指向下一个节点的指针
} Node;
// 核心函数:找到两个带头结点单链表的共同后缀起始节点
// 参数:str1、str2 分别为两个链表的头指针(带头结点)
// 返回:共同后缀的起始节点指针,无公共后缀则返回 NULL
Node* findCommonSuffix(Node *str1, Node *str2) {
// 边界处理:若任一链表为空,直接返回 NULL
if (str1 == NULL || str2 == NULL) {
return NULL;
}
// 步骤1:计算两个链表的长度
Node *p = str1->next; // 跳过表头节点,指向第一个数据节点
int len1 = 0;
while (p != NULL) { // 遍历str1统计长度
len1++;
p = p->next;
}
p = str2->next; // 重置指针,遍历str2
int len2 = 0;
while (p != NULL) { // 遍历str2统计长度
len2++;
p = p->next;
}
// 步骤2:让较长链表的指针先走长度差步,对齐起点
Node *longList = str1->next; // 初始假设str1更长
Node *shortList = str2->next;
int diff = abs(len1 - len2); // 计算长度差
// 修正长短链表指针(若str2更长则交换)
if (len1 < len2) {
longList = str2->next;
shortList = str1->next;
}
// 长链表指针先走diff步,与短链表指针对齐
for (int i = 0; i < diff; i++) {
longList = longList->next;
}
// 步骤3:同步遍历,寻找第一个相同的节点(公共后缀起点)
while (longList != NULL && shortList != NULL) {
if (longList == shortList) { // 找到公共后缀起始节点
return longList;
}
// 两个指针同步后移
longList = longList->next;
shortList = shortList->next;
}
// 无公共后缀
return NULL;
}核心代码关键注释说明
- 长度计算:通过两次遍历分别统计两个链表的有效长度(跳过表头节点),为后续对齐指针做准备;
- 指针对齐:让较长链表的指针先移动「长度差」步,确保两个指针到链表末尾的距离一致;
- 同步遍历:两个指针同时后移,第一个指向同一地址的节点就是公共后缀的起始位置;
- 边界处理:提前判断空链表,避免空指针访问错误。
- 时间复杂度 :O(m+n),其中 m、n 分别为两个链表的长度。
- 第一次遍历:分别计算两个链表长度,共 O(m+n)。
- 第二次遍历:对齐指针后同步遍历,最多 O(min(m,n)) 步。
- 整体时间复杂度为线性,是该问题的最优解法。
- 空间复杂度:O(1),仅使用了常数个额外指针变量,无其他辅助空间。
完整代码如下:
cpp
#include <stdio.h>
#include <stdlib.h>
// 定义链表节点结构
typedef struct Node {
char data; // 存储字符(单词的字母)
struct Node *next; // 指向下一个节点的指针
} Node;
// 函数:找到两个链表的共同后缀起始节点
// 参数:str1、str2 分别为两个链表的头指针(带头结点)
// 返回:共同后缀的起始节点指针,无公共后缀则返回 NULL
Node* findCommonSuffix(Node *str1, Node *str2) {
// 边界处理:若任一链表为空,直接返回 NULL
if (str1 == NULL || str2 == NULL) {
return NULL;
}
// --- 步骤1:分别计算两个链表的长度 ---
Node *p = str1->next; // p 指向 str1 的第一个数据节点
int len1 = 0;
while (p != NULL) { // 遍历 str1 统计长度
len1++;
p = p->next;
}
p = str2->next; // p 指向 str2 的第一个数据节点
int len2 = 0;
while (p != NULL) { // 遍历 str2 统计长度
len2++;
p = p->next;
}
// --- 步骤2:对齐两个指针的起始位置 ---
Node *longList = str1->next; // 指向较长链表的第一个数据节点
Node *shortList = str2->next; // 指向较短链表的第一个数据节点
int diff = abs(len1 - len2); // 计算长度差
// 让较长链表的指针先走 diff 步,对齐到与短链表末尾同距的位置
if (len1 < len2) {
longList = str2->next;
shortList = str1->next;
}
for (int i = 0; i < diff; i++) {
longList = longList->next;
}
// --- 步骤3:同步遍历,寻找共同节点 ---
while (longList != NULL && shortList != NULL) {
if (longList == shortList) { // 找到共同后缀的起始节点
return longList;
}
// 两个指针同步向后移动
longList = longList->next;
shortList = shortList->next;
}
// 遍历到末尾仍未相遇,说明无公共后缀
return NULL;
}
// ------------------- 辅助函数(用于创建和测试链表) -------------------
// 创建一个新节点
Node* createNode(char data) {
Node *newNode = (Node*)malloc(sizeof(Node));
newNode->data = data;
newNode->next = NULL;
return newNode;
}
// 尾插法创建带头结点的单链表
Node* createList() {
Node *head = (Node*)malloc(sizeof(Node)); // 头结点(不存数据)
head->next = NULL;
return head;
}
// 在链表尾部插入新节点
void insertTail(Node *head, char data) {
Node *p = head;
while (p->next != NULL) {
p = p->next;
}
p->next = createNode(data);
}
// 释放链表内存
void freeList(Node *head) {
Node *p = head;
while (p != NULL) {
Node *temp = p;
p = p->next;
free(temp);
}
}
// ------------------- 主函数(测试) -------------------
int main() {
// 创建 str1: "loading"
Node *str1 = createList();
insertTail(str1, 'l');
insertTail(str1, 'o');
insertTail(str1, 'a');
insertTail(str1, 'd');
// 创建 str2: "being"
Node *str2 = createList();
insertTail(str2, 'b');
insertTail(str2, 'e');
// 手动构造共享后缀 "ing"
Node *nodeI = createNode('i');
Node *nodeN = createNode('n');
Node *nodeG = createNode('g');
nodeI->next = nodeN;
nodeN->next = nodeG;
// 将共享后缀接到两个链表的尾部
Node *p = str1;
while (p->next != NULL) p = p->next;
p->next = nodeI;
p = str2;
while (p->next != NULL) p = p->next;
p->next = nodeI;
// 查找共同后缀起始节点
Node *result = findCommonSuffix(str1, str2);
if (result != NULL) {
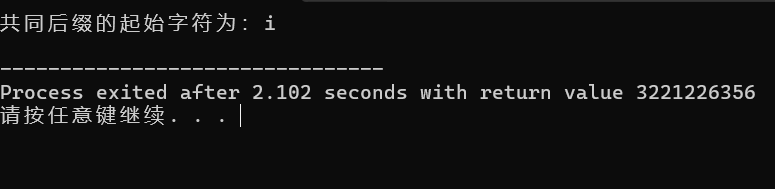
printf("共同后缀的起始字符为:%c\n", result->data); // 应输出 'i'
} else {
printf("无共同后缀\n");
}
// 释放内存(注意:共享部分只释放一次)
free(nodeG);
free(nodeN);
free(nodeI);
freeList(str1);
freeList(str2);
return 0;
}总结
- 核心思路是长度差对齐 + 双指针同步遍历,时间复杂度 O(m+n),空间复杂度 O(1);
- 关键逻辑是先让长链表指针 "追上" 短链表指针,再同步移动找公共节点;
- 最终返回的节点指针直接指向公共后缀的第一个节点,可通过该节点遍历完整公共后缀。
运行结果截图 :