目录
[DLCompiler 整体架构和解决方案](#DLCompiler 整体架构和解决方案)
[DLCompiler 开发算子范式](#DLCompiler 开发算子范式)
[CUDA 模型:](#CUDA 模型:)
[DLCompiler 开发算子流程](#DLCompiler 开发算子流程)
[DLCompiler 开发 GEMM 算子](#DLCompiler 开发 GEMM 算子)
[跨架构的 DSL 扩展](#跨架构的 DSL 扩展)
[Producer/Consumer 编程模型](#Producer/Consumer 编程模型)
[Tile-based 编程接口](#Tile-based 编程接口)
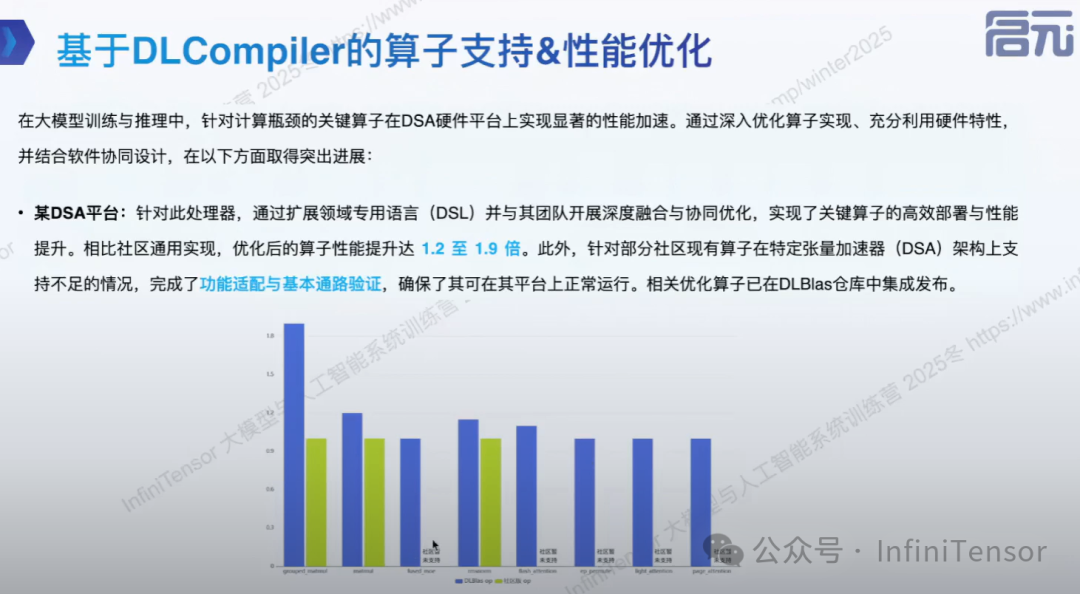
[基于 DLCompiler 的算子支持与性能优化](#基于 DLCompiler 的算子支持与性能优化)
本文是由上海人工智能实验室团队讲解其推出的 DLCompiler,DLCompiler 在 Triton 编程模型基础上进行了扩展,通过针对 DSA 芯片的后端适配,实现算子高效执行。
算子开发现状
DSA架构特性
国产 AI 芯片多采用 DSA 架构,与通用 GPU 存在显著差异:
-
• 专用计算单元:Cube(矩阵计算)、Vector(向量计算)、Scale(标量计算)
-
• 多级缓存体系:L0A、L0B、L0C 等多级片上缓存
-
• 数据搬运机制:需要显式管理数据从主机到片上缓存的搬运过程
开发门槛高
传统国产芯片算子开发面临多重挑战:
-
• 硬件知识要求:需要深入了解芯片架构、内存层次、计算单元特性
-
• 代码复杂度高:单个 Matmul 算子可能需要数百行底层代码
-
• 调优困难:手动优化逻辑复杂,性能与维护难以兼顾
-
• 架构兼容性:不同代际芯片架构差异大,代码复用性差
生态碎片化
- • 各家厂商提供独立的软件栈,开发者需要针对不同厂商重复开发相同功能,造成资源浪费。
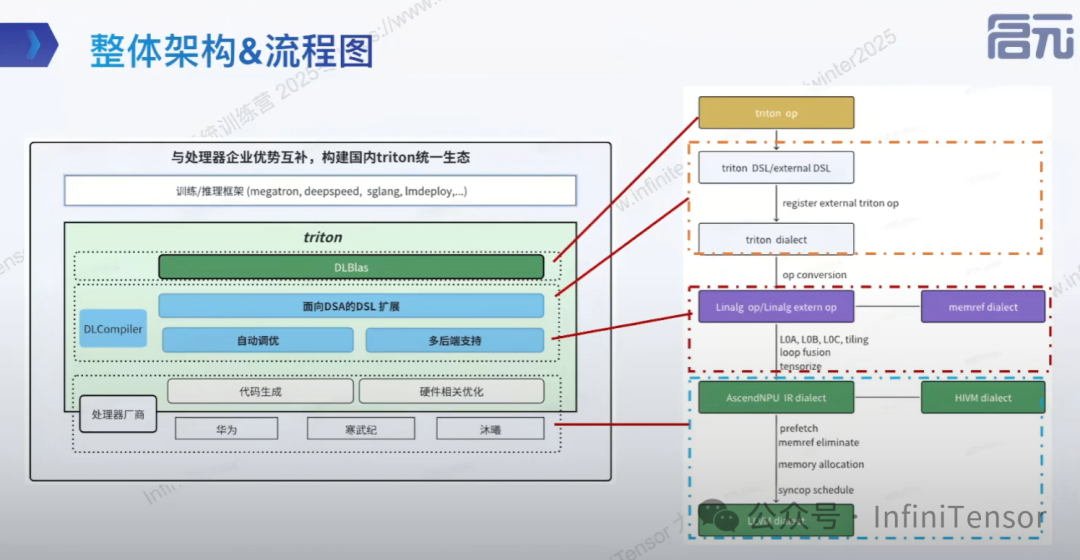
DLCompiler 整体架构和解决方案
整体架构和流程
安装和测试

DLCompiler 开发算子范式
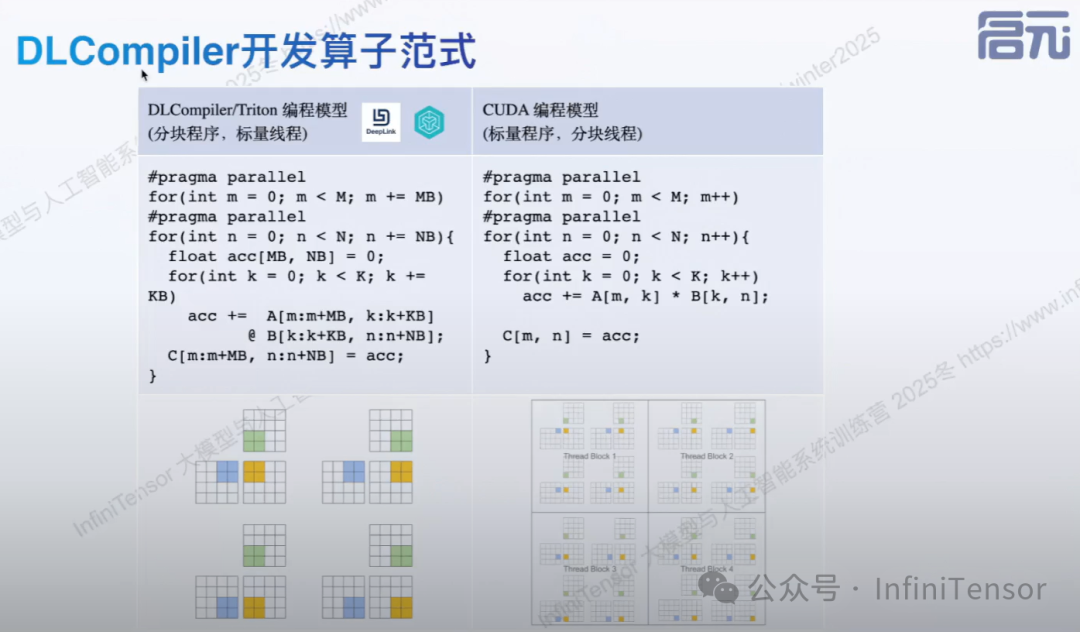
编程范式差异
CUDA 模型:
-
• 处理单元:每个线程处理单个数据点
-
• 编程粒度:标量级别的细粒度控制
-
• 代码复杂度:需要手动管理内存、同步、边界条件
DLCompiler/Triton 模型:
-
• 处理单元:每个 program 处理一个数据块(tile)
-
• 编程粒度:块级别的粗粒度抽象
-
• 自动优化:编译器自动处理内存布局、并行化等细节
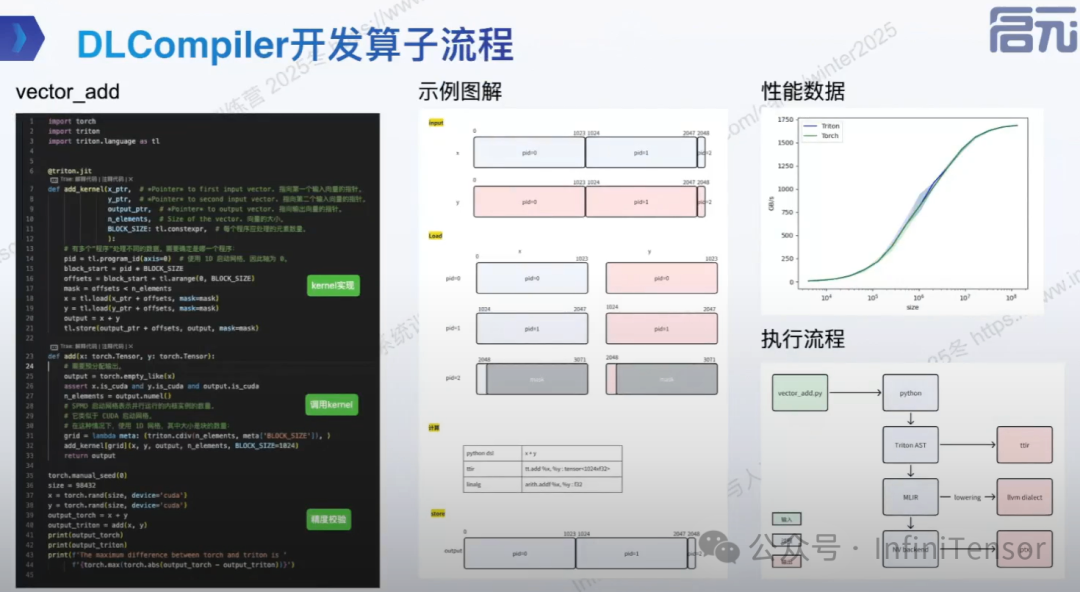
DLCompiler 开发算子流程
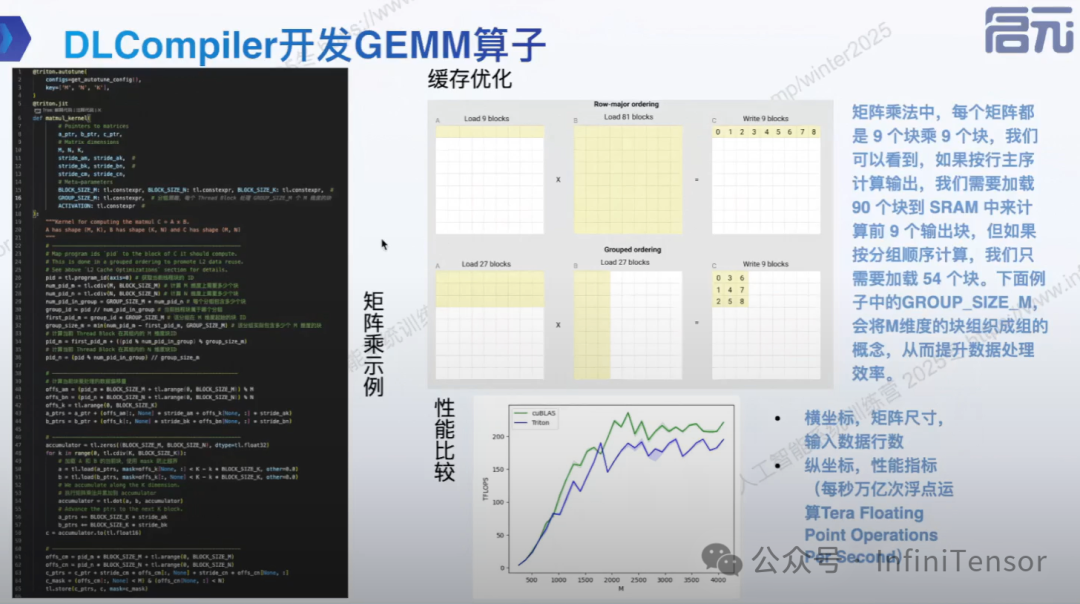
DLCompiler 开发 GEMM 算子
跨架构的 DSL 扩展

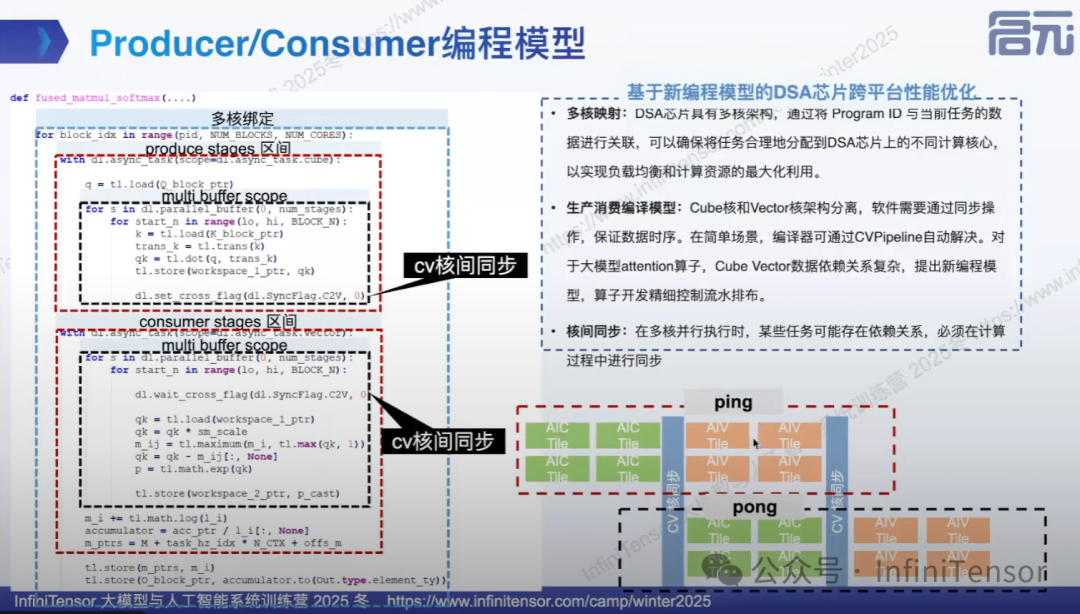
Producer/Consumer 编程模型
创新性地将生产者-消费者模型引入算子开发,通过将 Cube 计算(生产者)和 Vector 计算(消费者)解耦,实现流水线并行,显著提升硬件利用率:
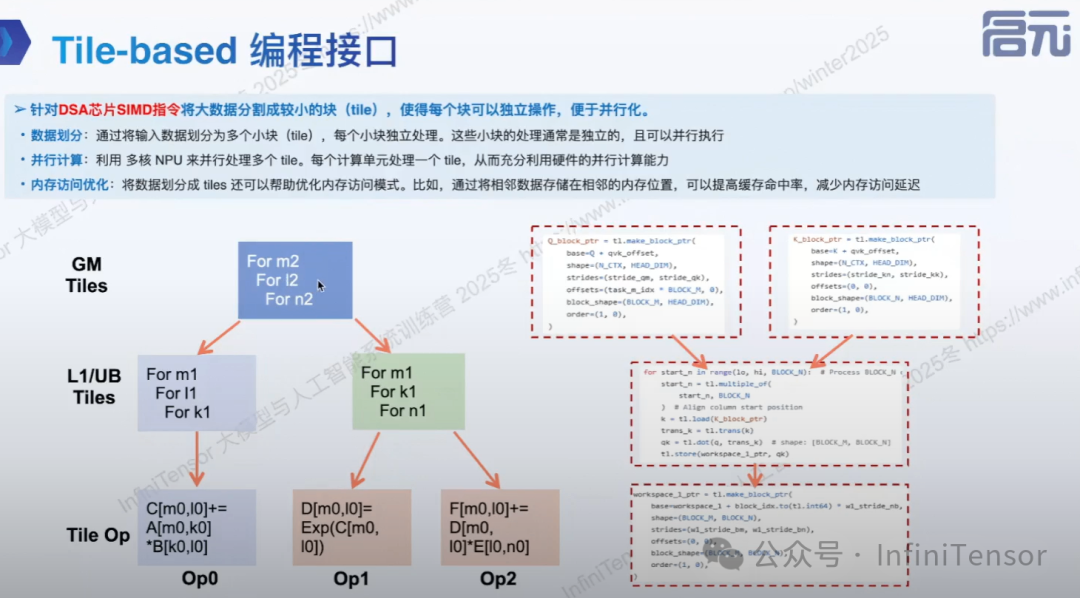
Tile-based 编程接口
针对国产芯片的多级缓存体系,DLCompiler 实现了精细化的 Tile 管理:
数据搬运优化
-
• Global Memory → L0A/L0B:预取下一轮计算所需数据
-
• L0C → Global Memory:异步写回计算结果
-
• 重叠计算与搬运:最大化硬件资源利用率
计算流水化
将算子分解为多个阶段:
-
- 数据加载阶段:从全局内存加载数据到片上缓存
-
- 计算阶段:执行 Cube/Vector 计算
-
- 结果写回阶段:将结果写回全局内存
各阶段可并行执行,形成高效的计算流水线。
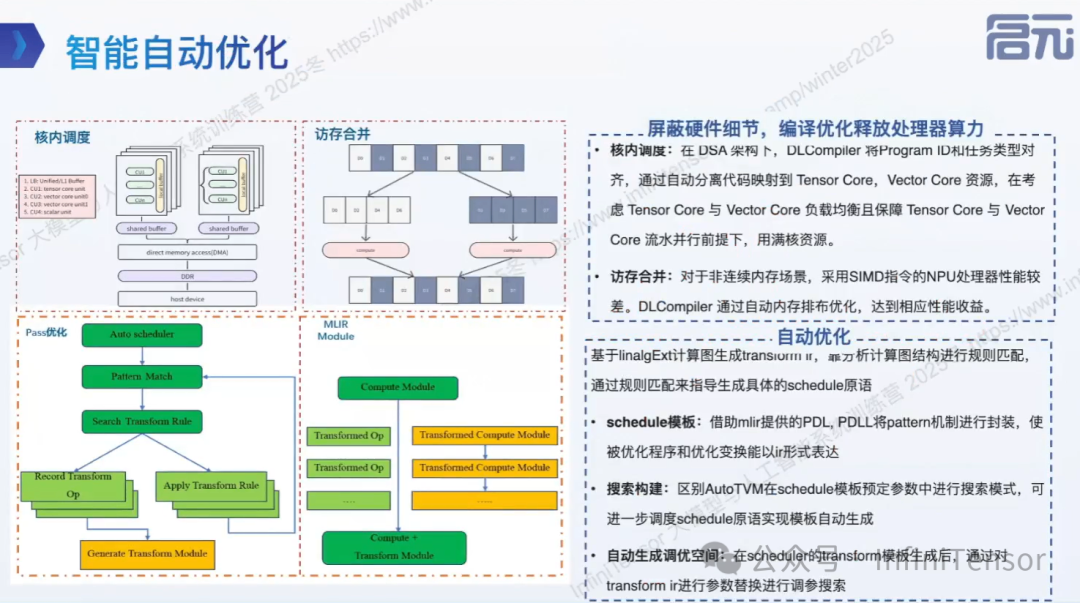
智能自动优化
DLCompiler 内置多个优化 Pass:
生态建设和成果展示
上层框架对接和生态建设
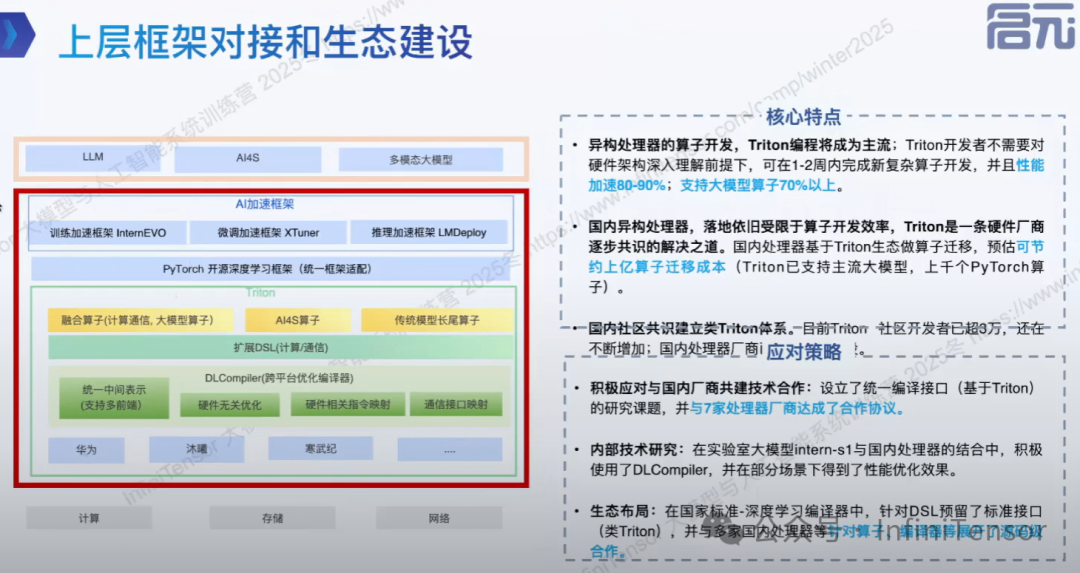
基于 DLCompiler 的算子支持与性能优化
未来发展方向
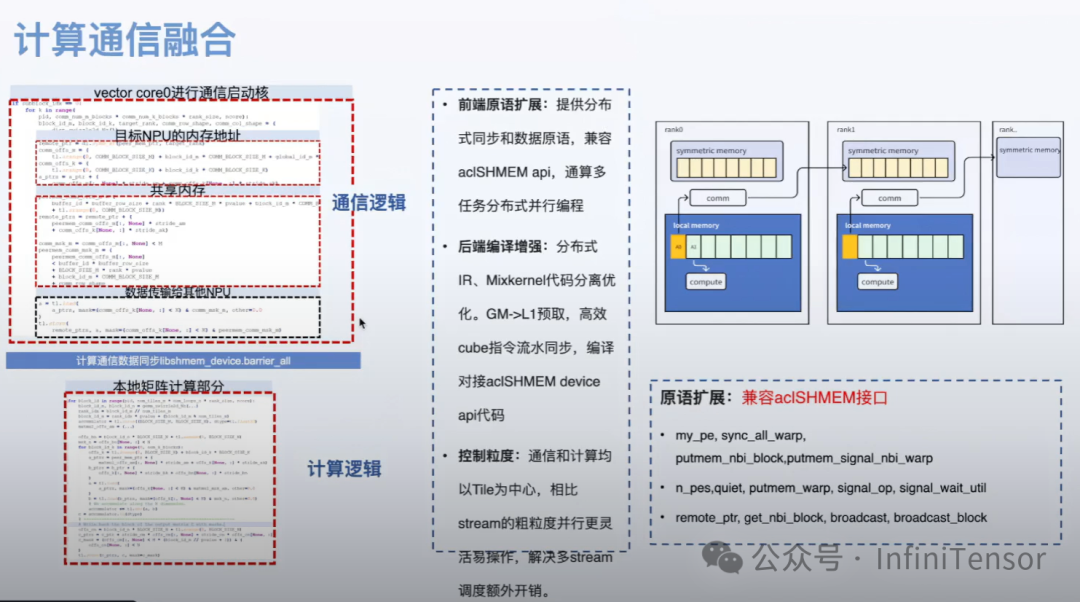
当前 DLCompiler 主要优化单卡内部算子,未来将扩展至多卡场景:
-
• 通信隐藏:在计算的同时进行通信
-
• 流水线优化:跨设备的计算-通信流水线
-
• 拓扑感知:根据网络拓扑优化通信模式
总结
本文介绍了算子开发现状,主要讲解 DLCompiler 的架构、生态建设和成果以及未来发展规划。
DLCompiler 通过扩展 Triton 的编程模型,为国产 DSA 芯片提供了高效的算子开发解决方案。它不仅降低了国产芯片的开发门槛,还通过统一的编程接口促进了生态整合。随着大模型对算力需求的持续增长,DLCompiler 这类深度学习编译器将成为连接算法创新与硬件加速的重要桥梁,推动国产 AI 芯片生态的健康发展。