1.进程为什么需要通信
进程之间需要通信,是因为每个进程都有独立的虚拟地址空间,彼此完全隔离,不能直接访问对方的数据 。为了让多个进程协同完成任务、交换数据、同步执行顺序,就必须通过内核提供的机制进行通信。比如父子进程分工处理数据、服务进程与客户端交互、多个程序共享资源、控制执行先后等,都需要靠进程间通信来实现信息传递与配合。
2.进程间如何通信
inux 进程间通信是让不同进程交换数据的机制,主要通过内核提供的公共介质实现。常用方式:
匿名管道(亲缘进程单向通信)、命名管道(无亲缘也可用)、消息队列、共享内存(效率最高,直接映射同一块物理内存)、信号量(同步互斥)、Socket(跨主机)、信号(简单通知)。多数方式借助内核缓冲区或公共资源完成数据传递,实现进程间协同与数据交互。
3.进程间通信的本质
先让进程看到同一份资源,提供公共资源的人只能是操作系统,公共资源如何提供呢,而这个提供方案只能是系统调用
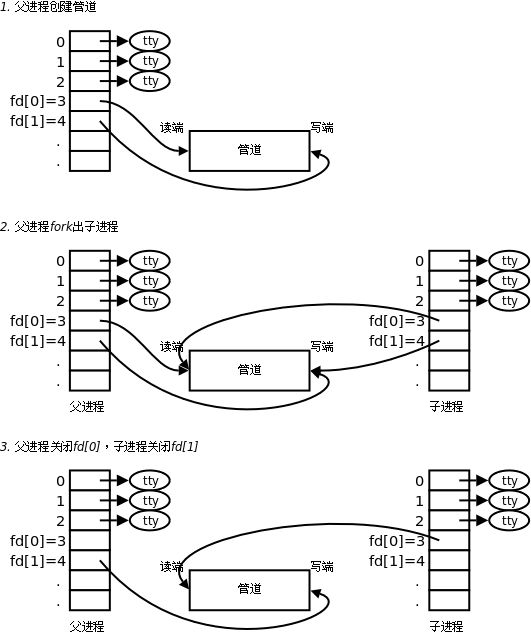
4. 管道
4.1本质
管道通信的本质,是操作系统在内核中开辟一段内存缓冲区,以文件描述符形式暴露给进程,让多个进程通过读写操作完成数据传输,一个进程往文件里写,另一个进程从文件里面读。它是一种半双工、面向字节流的通信方式,数据只能单向流动,遵循先进先出规则,本质是借助内核实现的进程间数据传递机制。
子进程会复制父进程的 PCB(进程控制块)以及 mm_struct(内存描述符)等核心数据结构,但并不会复制物理内存中的文件内容,也不会重新打开文件 ------ 父子进程会共享相同的文件表项(包含文件偏移量、文件状态标志等),因此能看到同一份打开的文件资源;且父子进程持有的文件描述符指向内核中同一个文件结构体,对文件的读写操作会共享偏移量,需注意同步问题以避免数据错乱。
4.2匿名管道
匿名管道是 Linux 内核提供的、基于内存缓冲区实现的进程间通信机制 ,只适用于具有亲缘关系的进程(如父子、兄弟进程)。它在创建时会生成一对文件描述符,分别用于读和写,数据在内核中以字节流形式传输,遵循先进先出规则。匿名管道不产生磁盘文件,进程退出后资源自动释放,通信为半双工模式,数据只能单向流动。由于子进程会继承父进程打开的文件描述符,因此亲缘进程可通过它直接实现简单高效的数据交互。
①半双工和全双工
半双工通信指通信双方可以互相发送数据,但同一时刻只能有一方发送、另一方接收 ,不能双向同时传输,类似对讲机,一方说话时另一方只能收听。全双工通信则允许双方在同一时刻同时发送和接收数据,双向传输互不干扰,如同打电话,双方可以同时讲话与收听。在进程通信中,匿名管道、信号等属于半双工;而普通双向管道、socket 通信通常支持全双工,能更灵活地实现并发数据交互。
② 详细学习匿名管道
bash
who | wc -l统计当前的linux有多少个人在用;| 就会被OS认为是管道;who和wc -l 分别是两个进程,关系是兄弟;
struct_file是被子进程独立创建的,拷贝自父进程;父子进程都可以使用自己的struct_file 上的fd访问对应的内核级缓冲区;父子进程间通信不需要刷新到磁盘上,所以我们如何设计一个纯内存级别的和磁盘没有关系的、配有对应的系统调用接口,让它可以纯内存级的打开一个内存级文件,让它专门来做两个进程之间的通信,是的,这就是OS为我们设计的管道
问题:如果我们不关闭呢?
文件描述符泄露,或者误操作会影响我们的进程;
问题:为什么创建管道,再创建子进程
因为子进程要拷贝父进程的管道;
问题:为什么不只给父进程创建读端?
因为这样的话子进程继承的也是读,就没有人写了;
问题:为什么叫做管道?为什么要只有单向通信
之所以叫管道 ,是因为它像一根真实的管子,数据从一端流入、另一端流出,形象描述内核缓冲区的单向传输。设计为单向通信,是为了实现简单、高效、同步安全,避免双向读写冲突,内核只需维护单方向的字节流,符合进程间 "生产者 - 消费者" 的典型模型,也便于父子进程继承文件描述符后直接使用。
④验证接口
创建管道的接口


cpp
#include <iostream>
#include <string>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/types.h>
//father process read
//child process write
int main()
{
//1.创建管道
int fds[2]={0};
int n=pipe(fds);
if(n != 0)
{
std::cerr<<"Create Pipe Error" <<std ::endl;
return 1;
}
//2.创建进程
pid_t id=fork();
if(id == 0)
{
int cnt=0;
while (true)
{
std::string message="hello ";
message +=std::to_string(getpid());
message +=",";
message +=std::to_string(cnt);
::write(fds[1],message.c_str(),sizeof(message));
sleep(1);
cnt ++;
}
::close(fds[0]);
exit(0);
}
else if(id < 0)
{
std::cerr << "Fork Error" << std::endl;
return 2;
}
else
{
while (true)
{
char buffer [1024];
ssize_t n =::read(fds[0],buffer,1024);
if( n>0)
{
buffer[n] =0;
std ::cout << "child ->father" << buffer <<std::endl;
}
}
::close(fds[1]);
pid_t rid =waitpid(id,nullptr,0);
std::cout <<"father wait child success" <<rid <<std::endl;
}
return 0;
}int pipefd2,是一个输出型参数,未来我们就用这个参数进行我们管道的读写了;fd0读端,fd1写,0下标想象成嘴巴,用来读;1下标想象成笔,笔是用来写的;
代码结果为:
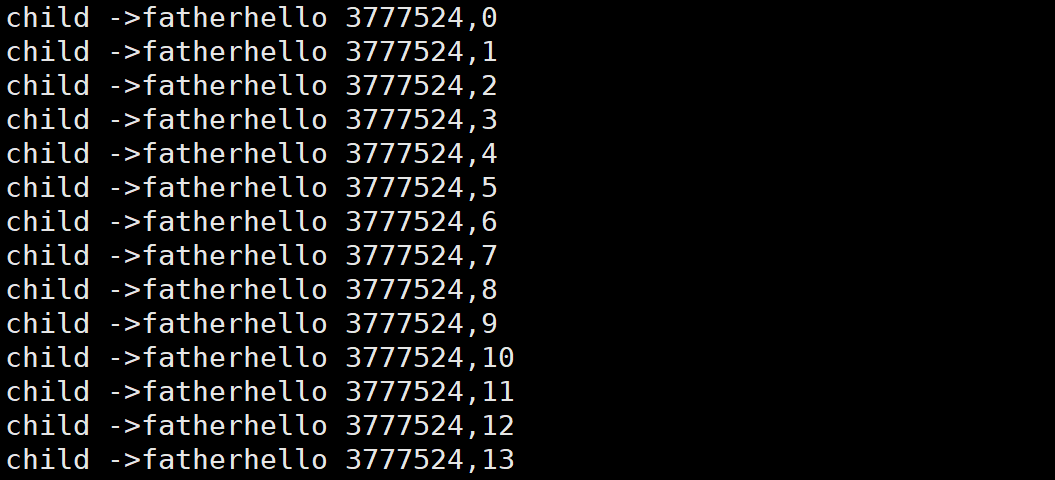
这样我们就创建了一个子进程进行写,父进程进行读的管道;我们发现如果子进程在写的时候5秒写一次,这个时间父进程在等待,也就是有数据读,没数据不读,这种也是一种保护;有没有可能我写一半的时候别人就来读呢?是有这样的可能的,取决于buffer的大小;也有可能写了很多内容才读一点;所以我们要对我们的数据缓冲区保护;
我们发现如果我们让父进程不读,只让子进程写,最后写了64KB就写不进去了,所以管道其实是有大小的,这样也是为了让我们的管道安全;并不是说子进程写多少父进程读多少,读写双方都不关心双发读写多少,所以称为这种情况为面向字节流;
如果子进程写入之后直接退了,也就是写端关闭,这个时候我们的父进程会读取完管道内剩余的内容,最后读到0,表示管道内的内容为空了;
写端一直写,但是读端已经关闭,这个时候在OS看来是一个浪费时间、浪费空间的事情,所以OS会直接关闭这个进程,以13号信号的方式;低7位为退出信号,次地7位位退出状态;所以想要得到信号让我们的status & 0x7F(01111111),按位与的结果是有0就是0,这样就能得到我们第七位的结果也就是我们的信号了;同理想要得到我们的退出状态,让status & 0xFF(1111 1111)
⑤匿名管道的特点

5.基于匿名管道的应用-进程池
5.1同步和互斥
同步 :指多个进程按约定的先后顺序执行,保证操作有序、结果正确,是 "谁先谁后" 的协调。
互斥 :指多个进程不能同时访问临界资源(如共享内存、文件),同一时间只允许一个进程使用,避免竞争冲突。同步保证秩序,互斥保证安全,二者共同让多进程协同稳定运行。
同步应用场景
- 生产者 - 消费者模型:生产者生产数据后,消费者才能读取,保证执行顺序。
- 父子进程协作:父进程先完成任务,子进程再基于结果运行,依赖先后次序。
- 多步骤任务:如数据处理后再输出,按流程有序执行。
互斥应用场景
- 共享资源访问:多个进程同时操作共享内存、文件,避免数据混乱。
- 打印机使用:多进程打印时,同一时间仅一个进程占用设备。
- 全局变量修改:多进程修改同一变量,防止竞争导致结果错误。
5.2进程池模型
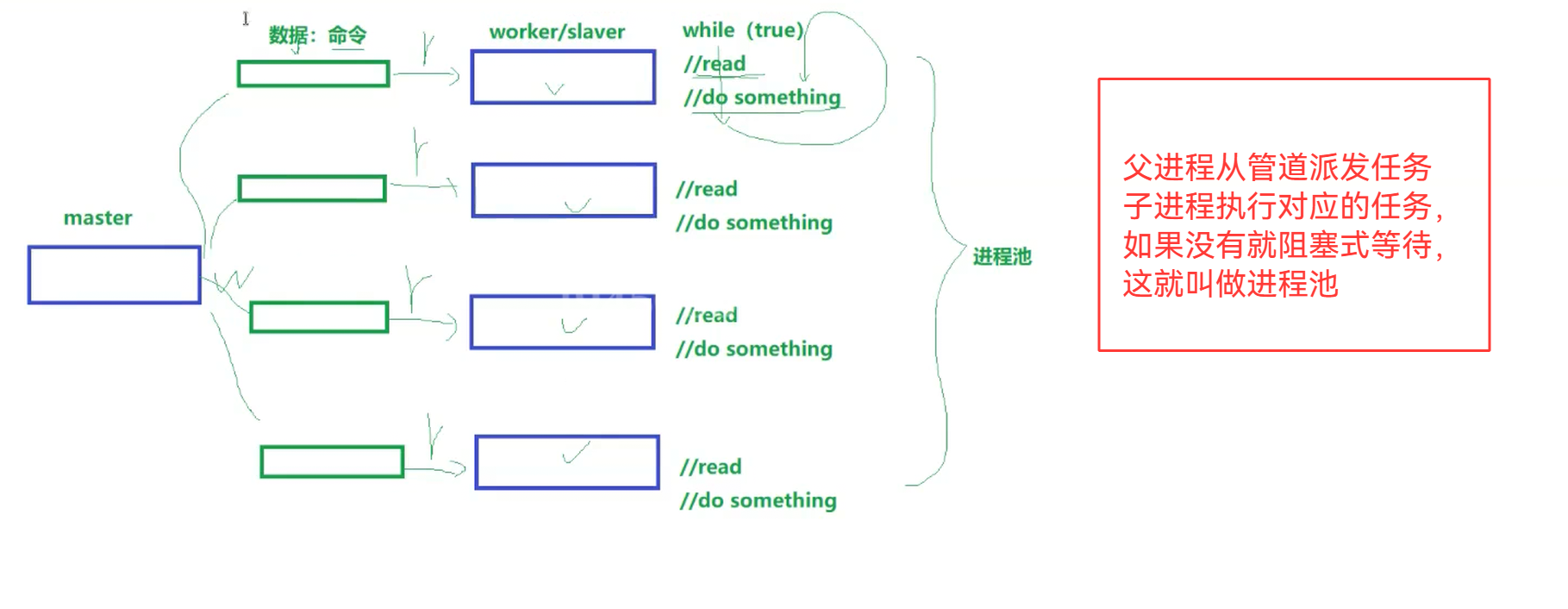
5.3进程池的应用场景
| 应用场景 | 说明 |
|---|---|
| 高并发网络服务器 | Web 服务器、网关、游戏服务器、TCP/UDP 服务,用进程池处理大量客户端连接 |
| 后台任务执行 | 日志处理、数据上报、异步计算、消息消费等不阻塞主线程的后台工作 |
| 批量数据处理 | 日志清洗、文件解析、数据格式转换、音视频转码、图片处理等批量任务 |
| 数据库 / IO 密集服务 | 大量数据库查询、文件读写、网络请求,用进程池并行提升吞吐量 |
| 计算密集型模块 | 算法计算、模型推理、数值计算、仿真计算,利用多核 CPU 并行加速 |
| 安全隔离任务 | 执行第三方代码、解析未知文件、调用外部插件,进程崩溃不影响主程序 |
| 定时任务调度 | 定时备份、定时统计、定时清理、定时同步等周期性任务 |
| 微服务 / 分布式节点 | 微服务中的任务 worker 节点,接收任务并稳定并发执行 |
| 软件类型 | 典型例子 | 是否用进程池 |
|---|---|---|
| Web 服务器 | Nginx、Apache、网关 | ✅ 大量用 |
| 游戏服务器 | 登录服、战斗服、网关 | ✅ 大量用 |
| 数据库 | MySQL、PostgreSQL | ✅ 大量用 |
| 中间件 | 消息队列、分布式存储 | ✅ 大量用 |
| 后端服务 | 微服务、接口服务 | ✅ 大量用 |
| 日志 / 数据系统 | 日志收集、清洗、分析 | ✅ 大量用 |
| 普通手机 / 桌面 App | 微信、抖音、浏览器、编辑器 | ❌ 不用 |
5.4Makefile 拓展
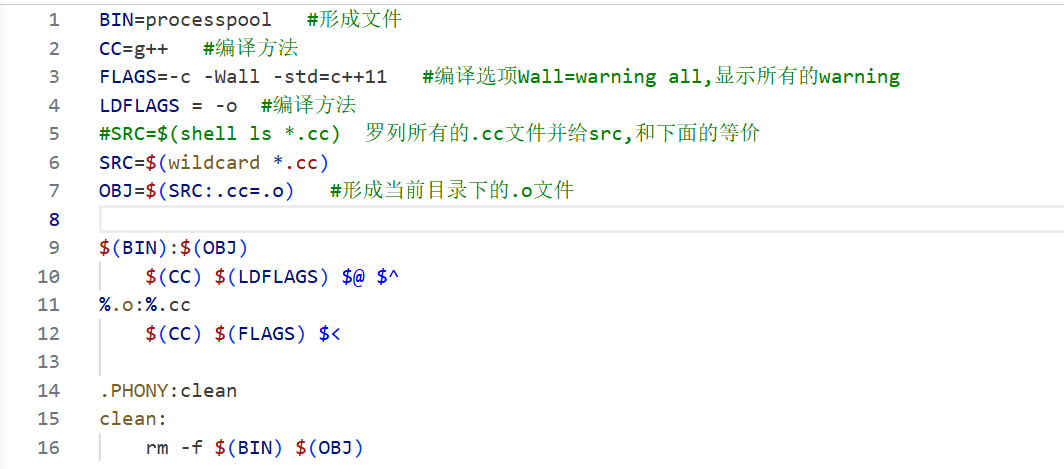
这样的makefile写好,无论新建多少.cc文件,都不再需要对应的makefile ;
5.5 进程池创建
cpp
#include <iostream>
#include <unistd.h>
#include <string>
#include <sys/types.h>
#include <sys/wait.h>
#include <vector>
#include <cstdlib>
#include <functional>
#include "Task.hpp"
using work_t =std::function<void()>;
enum
{
OK = 0 ,
UsageError,
PipeError,
ForkError
};
class channel
{
public:
channel(int wfd,pid_t who)
:_wfd(wfd)
,_who(who)
{
_name="Channel" + std::to_string(wfd) +std::to_string(who);
}
void send(int cmd)
{
::write(_wfd,&cmd,sizeof(cmd));
}
std::string Name( )
{
return _name;
}
void close()
{
::close(_wfd);
}
int ID()
{
return _who;
}
~channel()
{}
private:
int _wfd;
std::string _name;
pid_t _who;
};
void worker()
{
while(true)
{
int cmd =0;
int n= ::read(0,&cmd,sizeof(cmd));
if(n==sizeof(cmd))
{
tm.Excute(cmd);
}
else if(n==0)
{
std::cout <<"pid"<<getpid() <<"quit ...." <<std::endl;
break;
}
else if(n <0)
{
}
}
}
//channels 输出型参数
int InitProcessPool(const int & processnum, std::vector<channel> & channels ,work_t work)
{
for(int i=0;i<processnum;i++)
{
//1.先有管道
int fds[2]={0};
int n = pipe(fds);
if(n < 0)
return PipeError;
//2,创建进程
pid_t id = fork();
if(id < 0)
return ForkError;
if(id ==0)
{
//子进程
::close (fds[1]);
//想让子进程从标准输入0读
dup2(fds[0],0); //用于更改文件描述符,将fds[0]改为0;
work();
::exit(0); //让子进程把自己的工作做完直接退出,不要再走下面的代码
}
//父进程
//pid_t rid=waitpid(id,nullptr,0);
::close (fds[0]);
channels.emplace_back(fds[1],id); //直接传构造
}
return OK;
}
void Debug( std::vector<channel> & channels)
{
for( auto &c :channels)
{
std::cout <<c.Name() << std::endl;
}
}
void DispathchTask(std::vector<channel> channels)
{
int nums=20;
while(nums--)
{
//a.选择一个任务,整数
int task= tm.SelectTask();
int who =0;
//b.选择一个管道channel
channel & curr = channels[who++];
who%= channels.size();
//c.派发任务
curr.send(task);
std::cout << "任务还剩:"<< nums << std::endl;
sleep(2);
}
}
void ExitProcessPool(std::vector<channel> channels)
{
for(auto & c:channels)
{
c.close();
pid_t rid =waitpid(c.ID(),nullptr,0);
if(rid >0)
{
std::cout <<"child" <<rid << "wait.....sucess"<<std::endl;
}
}
}
void Usage(std::string proc)
{
std::cout << "Usage "<< proc << "process-num"<< std::endl;
}
int main(int argc ,char*argv[])
{
if(argc != 2)
{
Usage(argv[0]);
return UsageError;
}
int nums = std ::stoi(argv[1]); //把一个char*转为整数
std ::vector<channel> channels; //如果不保存起来一次循环后进程结束,管道会被释放
//1.初始化进程池
InitProcessPool(nums,channels,worker);
// Debug(channels);
//2.派发任务
DispathchTask(channels);
//3.退出进程池
ExitProcessPool(channels);
return OK;
}Task.hpp
cpp
#pragma once
#include <iostream>
#include <unordered_map>
#include <functional>
#include <ctime>
using task_t = std::function<void()>;
static int number = 0;
void download()
{
std::cout<< "Im download task" << std::endl;
}
void sql()
{
std::cout<< "Im databases task" << std::endl;
}
void log()
{
std::cout<< "Im log task" << std::endl;
}
class TaskManger
{
public:
TaskManger()
{
srand(time(nullptr));
InsertTask(download) ;
InsertTask(log) ;
InsertTask(sql) ;
}
void InsertTask(task_t t)
{
tasks[number++]=t;
}
int SelectTask()
{
return rand() % number;
}
void Excute(int number)
{
if(tasks.find(number) ==tasks.end()) return;
tasks[number]();
}
~TaskManger()
{
}
private:
std::unordered_map<int,task_t> tasks;
};
TaskManger tm;重点bug

6.命名管道

创建命名管道
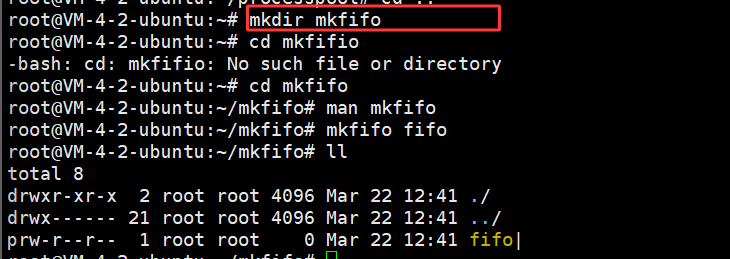

生成了一个p开头的 fifo 命名管道的文件;
6.1什么是命名管道
命名管道(FIFO,First In First Out)是一种半双工的进程间通信机制 ,它在文件系统中以特殊文件形式存在,所以有文件名和inode ,,允许无亲缘关系的进程间进行数据交换。与匿名管道(pipe)不同,命名管道可被多个进程通过路径名访问,生命周期独立于创建进程,只要文件未删除就可长期使用。它遵循先进先出的读写规则,数据按写入顺序被读取,且默认以阻塞模式工作:读端会等待数据写入,写端会等待读端打开。命名管道常用于客户端 - 服务器架构,例如日志收集、命令行工具间的数据传递,既保留了管道的简单易用性,又突破了匿名管道仅能用于父子进程的限制,是跨进程通信的轻量方案。
进程间通信的本质是让不同的进程看到同一份文件,所以不同的进程通过命名管道的文件路径一个以写方式,一个以读方式就能看到这份资源;这份资源不需要每个进程都拷贝,只用加载到文件内核缓冲区就可以了;但是我们的管道文件和普通文件的区别是管道文件不刷新到磁盘,只在文件内核级缓冲区;
6.2命名管道和匿名管道的区别
| 对比维度 | 命名管道(FIFO) | 匿名管道(pipe) |
|---|---|---|
| 存在形式 | 以特殊文件 形式存在于文件系统中 | 仅存在于进程内存中,无实体文件 |
| 访问方式 | 通过路径名访问,支持无亲缘关系进程 | 仅通过文件描述符传递,仅限亲缘进程(父子 / 兄弟) |
| 生命周期 | 独立于创建进程,需手动删除才会消失 | 随创建进程结束而自动销毁 |
| 通信方向 | 半双工(单向),可双向需创建两个管道 | 半双工(单向),双向需创建两个管道 |
| 阻塞特性 | 默认阻塞,读等待写、写等待读 | 默认阻塞,读端无数据 / 写端无读端时阻塞 |
| 典型用途 | 客户端 - 服务器架构、跨进程日志 / 数据传递 | 父子进程间简单通信、shell 管道命令 |
| 创建 / 使用 | mkfifo() 创建,open()/read()/write() 访问 |
pipe() 直接创建,配合 fork() 传递描述符 |
7.命名管道的实现
从上面学习了的命名管道的特性,我们知道了创建命名管道的系统调用函数mkfifo,并且因为命名管道本质上是文件,所以我们对命名管道的操作可以转为对文件的操作,可以使用系统调用函数write,read,close等等,而我们的命名管道需要在两个完全没有关系的进程间实现通信,所以我们的可以创建两个可执行程序,分别是Server.cc、Client.cc,服务端和客户端,我们让客户端充当向管道中写的操作,为服务端充当读,最后开启两个xshell观察本地通信情况;值得注意的是,我们的管道具有特性就是一端关闭,另一端会一直读到0才结束,所以我们在一端关闭的时候,要让另一端退出循环;
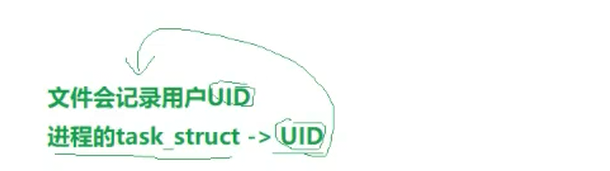
我们在创建文件的时候,会设置文件的mode ,也就是未来进程使用这个文件的权限,而因为文件会记录用户的UID,进程task_struct中也会记录当前进程的UID,通过对比两者判断是否能对文件做操作;

Server.hpp
cpp
#include <iostream>
#include <string>
#include <unistd.h>
#include "Comm.hpp"
class Init
{
public:
Init()
{
umask(0);
int n = ::mkfifo(gpipeFile.c_str(), gmode);
if (n < 0)
{
// std::cerr << "管道创建失败" << std::endl;
return;
}
std::cout << "管道创建成功" << std::endl;
}
~Init()
{
int n = ::unlink(gpipeFile.c_str());
if (n < 0)
{
// std::cerr << "管道删除失败" << std::endl;
return;
}
std::cout << "管道删除成功" << std::endl;
}
private:
};
Init init;
class Server
{
public:
Server()
: _fd(gdefaultfd)
{
}
bool OpenPipeForRead()
{
_fd = OpenPipe(FORREAD);
if (_fd < 0)
{
std::cerr << "Open failed" << std::endl;
return false;
}
return true;
}
int RecvPipe(std::string *out)
{
char buffer[gsize];
ssize_t n = ::read(_fd, buffer, sizeof(buffer) - 1);
// sizeof(buffer)-1是期望读到的元素个数,n是实际读到的元素个数
if (n > 0)
{
buffer[n] = 0; // n是读取的元素个数,n为0就
// 是将读取的最后一个元素置为0,防止溢出
*out = buffer;
}
return n;
}
void ClosePipe()
{
ClosePipeHelp(_fd);
}
~Server()
{
}
private:
int _fd = 0;
};
cpp
#include "Server.hpp"
#include <iostream>
int main()
{
Server s;
s.OpenPipeForRead();
std::string message;
while (true)
{
if(s.RecvPipe(&message) > 0)
{
std::cout << "Clinet say #" << message << std::endl;
}
else
{
break;
}
}
std::cout<<"Client quit , me too" << std::endl;
s.ClosePipe();
return 0;
}Client.hpp
cpp
#include <iostream>
#include <string>
#include "Comm.hpp"
class Client
{
public :
Client()
:_fd(gdefaultfd)
{}
bool OpenPipeForWRITE()
{
_fd = OpenPipe(FORWRITE);
if (_fd < 0)
{
std::cerr << "Open failed" << std::endl;
return false;
}
return true;
}
int SendPipe(const std::string &in)
{
return ::write(_fd, in.c_str(),in.size());
}
void ClosePipe()
{
ClosePipeHelp(_fd);
}
~Client()
{}
private:
int _fd;
};
cpp
#include "Client.hpp"
#include <iostream>
int main()
{
Client client;
client.OpenPipeForWRITE();
std::string message;
while (true)
{
std::cout << "可以开始写了" ;
std::getline(std::cin, message);
client.SendPipe(message);
}
client.ClosePipe();
std::cout << "Client" << std::endl;
return 0;
}Comm.hpp
cpp
#pragma once
#include <iostream>
#include <string>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <fcntl.h>
std::string gpipeFile = "./fifo";
mode_t gmode = 0600;
int gsize = 1024;
int gdefaultfd = -1;
const int FORWRITE = O_WRONLY;
const int FORREAD = O_RDONLY;
int OpenPipe(int flag)
{
int fd = ::open(gpipeFile.c_str(), O_RDONLY);
if (fd < 0)
{
std::cerr << "Open failed" << std::endl;
return fd;
}
return fd;
}
void ClosePipeHelp(int fd)
{
if (fd >= 0)
::close(fd);
}