
前言
在开发一个内容型应用时,我们经常会遇到这样一个场景:用户满怀期待地在搜索框里敲下几个关键词,结果却返回了一堆"看起来不太对"的内容------要么搜不到想要的,要么搜出来的排序完全不符合直觉。更糟糕的是,当数据量达到几十万、上百万时,原本顺畅的搜索开始变慢,甚至直接超时。
这就是我最近在项目中遇到的实际问题。起初,我们依赖数据库的 LIKE 查询,后来尝试了 MySQL 的全文索引,但效果始终不理想。最终,我们决定引入 Elasticsearch(简称 ES)来构建独立的搜索模块。
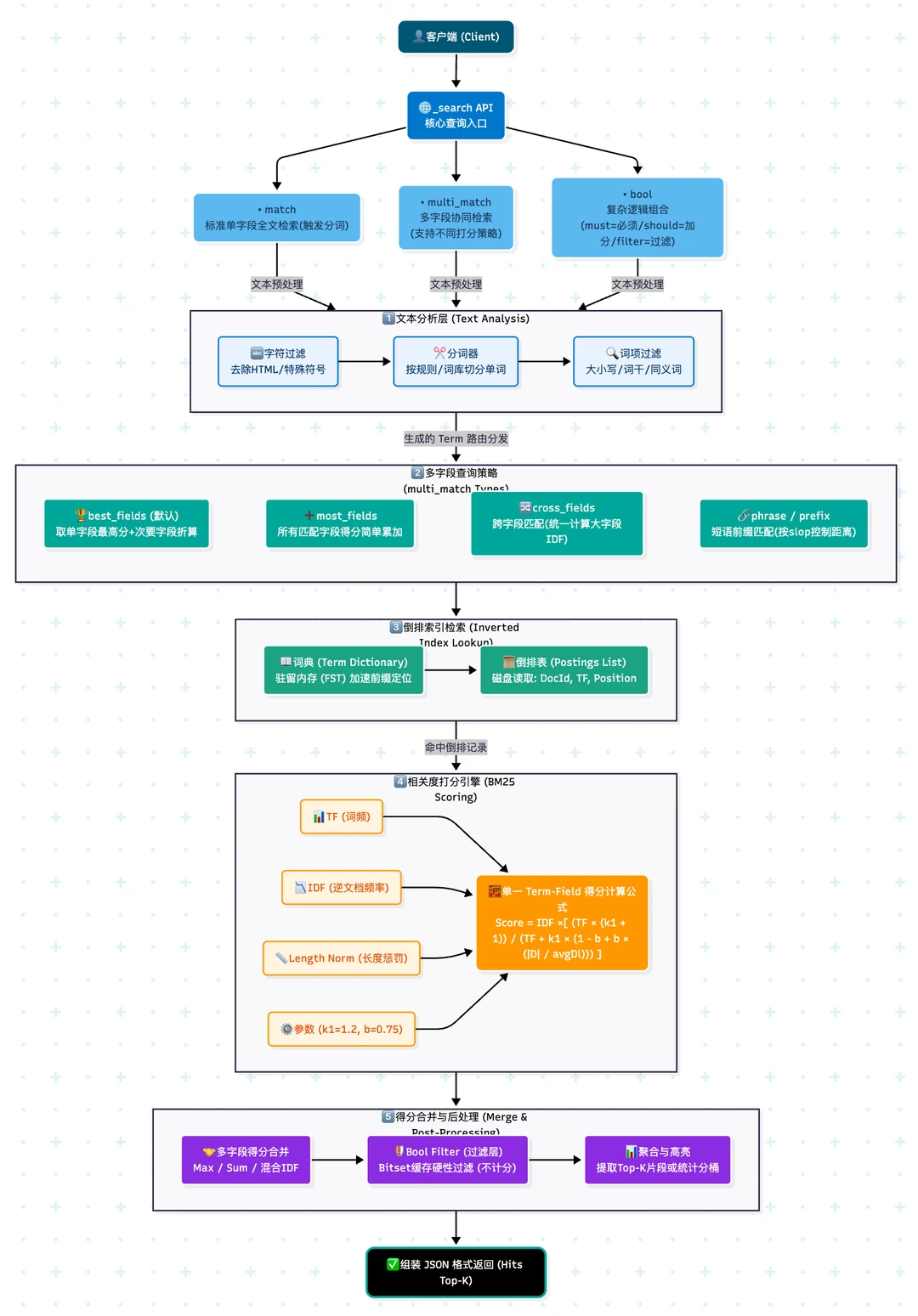
一、基础铺垫:Elasticsearch 是什么,它能解决什么
在深入代码之前,我们先理解 ES 的本质。
1.1 倒排索引:ES 的核心武器
传统数据库(比如 MySQL)使用正排索引 :你有一篇文章,数据库会记录"这篇文章 ID 是 1,标题是 xxx,内容是 xxx"。当你搜索"搜索引擎"这个词时,数据库需要扫描每一行,用 LIKE 去匹配。数据量一大,这几乎就是全表扫描。
ES 使用的是倒排索引。它会事先把所有文档的内容"分词",然后建立一张"词 → 文档"的映射表:
| 词 | 包含该词的文档 ID |
|---|---|
| 搜索 | 1, 3, 5 |
| 引擎 | 1, 2, 4 |
| 架构 | 2, 3 |
当你搜索"搜索引擎"时,ES 快速找到"搜索"和"引擎"对应的文档列表,然后取交集(或并集),再根据相关性打分排序。这个查找过程是 O(1) 级别的,不会随着文档数量线性增长。
1.2 分词:中文搜索的灵魂
英文单词有天然的空格分隔,但中文不同。比如"产品经理"这四个字,如果按单字拆分,搜"产品"时可能会把"产"和"品"分开匹配,产生大量噪声。如果按整词拆分,搜"经理"时又可能搜不到"产品经理"。
这就是分词要解决的问题。我们项目中使用的 IK 分词器,提供了两种模式:
- ik_max_word:最大化切分,比如"产品经理"拆成 产品, 经理, 产品经理,召回率高。
- ik_smart:智能切分,比如"产品经理"只拆成 产品经理,准确率高。
1.3 相关性评分:不仅仅是"匹配"
ES 默认使用 BM25 算法计算文档与查询的相关性得分。它考虑的因素包括:
- 词频(TF):关键词在文档中出现次数越多,得分越高。
- 逆文档频率(IDF):关键词在所有文档中越罕见,得分越高。
- 字段长度:短字段命中比长字段命中更有价值。
这比数据库的"要么匹配要么不匹配"的二元逻辑要精细得多。
二、为什么要单独做一个搜索模块
有了基础认识之后,我们来看一个更现实的问题:当数据量增长到一定规模,为什么不能再继续依赖数据库?
2.1 数据库查询的局限
假设我们有一个内容表,用户想搜"Elasticsearch 实战"。如果用 LIKE '%Elasticsearch%实战%',会发生什么?
- 无法利用索引 :前导通配符
%会让 B+Tree 索引失效。 - 分词能力弱:搜"搜索"时,包含"搜索引擎"的文章可能匹配不上。
- 排序单一:只能按发布时间或某个固定字段排序,无法体现"哪个结果更相关"。
- 深分页性能差 :
OFFSET 10000 LIMIT 20实际上要扫描并丢弃前 10000 条。
即使使用 MySQL 的 FULLTEXT 全文索引,依然存在以下问题:
- 对中文支持不够好,分词效果差。
- 难以叠加业务权重(比如点赞数、浏览数对排序的影响)。
- 高亮、联想建议等高级功能支持弱。
2.2 我们期望的搜索是什么样的
一个"好"的搜索,不应该只是"能搜到",而应该是:
- 搜得快:毫秒级响应。
- 搜得准:标题命中比正文命中更重要,热门内容比冷门内容更靠前。
- 体验好:关键词高亮、输入框实时联想。
- 稳定:深分页不崩溃,数据变更后能快速被搜到。
这些需求如果全部用数据库去拼凑,开发成本和维护成本会极高。而 Elasticsearch 恰恰是为这些场景设计的。
三、架构设计:读写分离与索引快照
引入 ES 不是简单的"加个依赖",我们需要重新设计数据流向。
3.1 读写分离模式
我们采用了经典的读写分离架构:
- 写入侧:业务数据写入 MySQL 后,通过异步事件(Kafka 消息)同步到 ES。写入主库是强一致的,索引更新是最终一致的。
- 读取侧:搜索请求直接访问 ES,不再回源查数据库。
这样做的好处是:搜索查询不阻塞主业务,ES 挂了也不会影响发帖、评论等核心功能。
3.2 为什么要在 ES 里冗余字段
一个很容易忽略的问题:搜索结果页要展示哪些内容?
在我们的场景里,搜索结果列表需要展示:标题、摘要、作者头像、昵称、标签、封面图、点赞数、收藏数、浏览数。
如果 ES 只存一个 content_id,然后每次搜索都要回 MySQL 补全这些字段,那么:
- 每页产生 N 次数据库查询,延迟叠加。
- 代码复杂,需要处理结果合并、异常兜底。
我们的方案是读优化:在写入 ES 时,就把列表需要展示的所有字段冗余进去。这样一次 ES 查询就能返回完整数据,换来了搜索接口的极简和稳定。
代价是:索引占用的磁盘空间变大了,而且内容更新时需要同步更新 ES 中的冗余字段。但这个代价在搜索场景下是完全值得的。
四、索引设计:字段类型决定能力边界
索引 Mapping 的设计直接影响搜索的效果和性能。我们遵循一个核心原则:检索用 Text + 分词,过滤/排序/展示用 Keyword。
4.1 字段类型的选择
| 字段用途 | 类型 | 说明 |
|---|---|---|
| 标题、正文 | text + IK 分词 |
全文检索,参与相关性评分 |
| 状态、标签 | keyword |
精确匹配、过滤、聚合 |
| 作者 ID、计数 | long / integer |
排序、过滤 |
| 发布时间 | date |
排序、范围查询 |
| 联想建议 | completion |
前缀补全专用,延迟极低 |
4.2 一个字段同时满足多种需求
有时同一个字段既需要全文搜索,又需要精确过滤。比如"标题"字段:
- 搜索时希望按"包含关键词"打分。
- 某些场景下需要按"标题完全等于某值"过滤。
我们的做法是使用 fields 子字段:
json
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}这样,title 用于全文检索,title.keyword 用于精确匹配和排序。
4.3 中文分词的"索引宽、查询窄"策略
IK 分词器的两种模式各有优劣。我们采用了"索引宽、查询窄"的平衡策略:
- 索引时(写入) :使用
ik_max_word。例如"产品经理"会被切分为 产品, 经理, 产品经理。这样能保证高召回率------搜"产品"或"经理"都能命中。 - 查询时(搜索) :使用
ik_smart。例如用户搜"产品经理",只被切分为 产品经理。这样避免了搜一个长词时匹配到大量只包含单字的无关内容。
这是一种成熟且经典的配置方案,既保证了"能搜到",又保证了"搜得准"。
五、搜索逻辑:如何让结果"像人类在搜"
真正的搜索体验,核心在于排序。我们来看搜索接口的核心实现。
5.1 宽召回:multi_match + 字段权重
搜索时,我们同时检索 title 和 body,但标题的重要性显然高于正文。ES 的 multi_match 支持字段权重:
fields: ["title^3", "body"]^3 表示标题命中得分是正文命中的 3 倍。这个倍数是经验值,可以根据业务调整。
5.2 业务加权:function_score
光有文本相关性还不够。一篇点赞多、浏览高的内容,通常比一篇零互动的内容更值得推荐。我们使用 function_score 在 BM25 得分基础上叠加热度因子:
score = BM25_score + log1p(like_count) * 2.0 + log1p(view_count) * 1.0为什么用 log1p?因为对数函数可以让热度增长的边际效应递减。点赞从 0 到 10 的权重提升明显,但从 1000 到 1010 的提升很小。这样避免了头部爆款内容"碾压"一切,让长尾精准内容也有机会露出。
5.3 过滤条件:bool + filter
不是所有内容都应该被搜到。我们通过 bool 查询的 filter 子句来过滤:
status = published:只搜已发布的内容。tags可选过滤:如果用户选了标签,追加terms查询。
filter 子句的好处是:它不参与相关性打分,但会被缓存,执行效率极高。
5.4 稳定排序:search_after 解决深分页
深分页是 ES 的一个经典痛点。传统的 from/size 分页,在 ES 里是这样工作的:
from = 10000, size = 20
→ 每个分片先取前 10020 条
→ 协调节点汇总后排序
→ 丢弃前 10000 条,返回最后 20 条随着页码加深,每个分片要扫描的文档数线性增长,最终拖垮集群。
我们的方案是使用 search_after 游标分页。它不依赖偏移量,而是"从上一页最后一条的位置继续往后查"。
关键在于:排序字段必须是全序的,否则分页可能重复或跳页。我们使用了五层排序:
1. _score desc // 相关性优先
2. publish_time desc // 新内容优先
3. like_count desc // 热门内容优先
4. view_count desc // 浏览多优先
5. content_id desc // 唯一 ID 兜底最后一层 content_id 是保证全序的关键。没有它,前四个字段可能有大量重复值,导致 search_after 定位不准。
5.5 高亮:让用户知道为什么命中
搜索结果返回高亮片段,能帮助用户快速判断相关性。我们在查询时开启 highlight,对 title 和 body 返回高亮片段,然后在服务层合并成一个 snippet。
这个细节虽然小,但很能提升体验。
六、增量同步:事件驱动的索引更新
索引和数据库之间如何保持同步?我们设计了基于 Outbox 模式的异步同步机制。
6.1 为什么不用双写
最直观的想法是:业务代码里同时写 MySQL 和 ES。但这样会有两个问题:
- 耦合:业务逻辑和索引逻辑混在一起。
- 一致性风险:写 MySQL 成功但写 ES 失败,数据就不一致了。
6.2 Outbox 模式
我们的方案是:
- 业务写 MySQL 时,同时写一条"变更事件"到 outbox 表。
- 一个独立的后台进程(Canal + Kafka)读取 outbox 表,发布到 Kafka。
- 搜索消费者监听 Kafka,根据事件更新 ES。
这样做到了:
- 解耦:业务代码不感知 ES 的存在。
- 可靠:outbox 表和业务表在同一个事务里,要么都成功,要么都失败。
- 幂等 :消息可能被重复消费,但
upsert操作天然幂等。
6.3 准实时 vs 强一致
这种异步模式带来的是"最终一致性"。用户刚发布的内容,可能需要几秒钟才能在搜索结果中看到。在我们的业务场景中,这个延迟是可以接受的。如果追求强一致,可以考虑同步写入,但代价是牺牲性能和可用性。
七、联想建议:输入框的实时补全
搜索框的"实时联想"功能,如果也用全文检索去做,性能会很差。ES 提供了专门的 Completion Suggester,它基于 FST(有限状态转换器)结构,能在 O(1) 时间内完成前缀匹配。
我们为 title_suggest 字段设置了 completion 类型,然后在查询时:
suggest: {
title_suggest: {
prefix: "用户输入的前缀",
completion: {
field: "title_suggest",
size: 10
}
}
}返回的候选词直接作为下拉提示,不参与全文打分,响应时间通常在毫秒级。
八、历史数据回灌:索引重建的兜底
当我们第一次上线搜索模块,或者索引 Mapping 需要变更时,已有的历史数据需要批量导入 ES。
我们在 SearchIndexService 中实现了启动时的自动回灌:
- 检查索引文档数量是否为 0。
- 分页从数据库拉取已发布内容(每页 500 条)。
- 逐条调用
upsert写入 ES。 - 记录日志,完成后退出。
这个机制保证了新部署的实例能自动完成索引初始化,无需人工干预。
九、总结:收获与思考
回顾整个搜索模块的设计和开发过程,我总结了几个核心收获:
9.1 理解工具的边界
Elasticsearch 非常强大,但它不是万能的。比如:
- 它不适合做事务性操作。
- 数据同步有延迟,不适合强一致性场景。
- 深分页虽然用
search_after解决了,但第一次查询仍然需要排序。
选择技术方案时,要清楚它能解决什么,不能解决什么。
9.2 读优化是搜索的核心策略
搜索的本质是"读多写少"。我们通过冗余字段换查询性能,通过异步同步换系统稳定性。这个思路在很多读密集型场景都适用。
9.3 排序决定搜索的"智商"
用户对搜索体验的感知,很大程度上来自排序。文本相关性、热度、时效性、唯一 ID 兜底------这四层排序的组合,让结果既"相关"又"合理"。
9.4 分页没有银弹
传统分页简单直接,但无法支撑大数据量。search_after 解决了深分页问题,但它依赖全序排序字段,且游标需要由客户端维护。选择哪种分页方案,取决于具体场景。
9.5 异步同步的可靠性设计
事件驱动的索引同步,让系统更健壮,但也带来了复杂度:消息幂等、异常重试、消费者监控......这些都是需要额外考虑的点。但相比同步双写的耦合和风险,这个代价是值得的。
最后,我想说:搜索是一个"看起来简单,做起来复杂"的领域。从分词到排序,从高亮到联想,每个细节都值得深入推敲。希望这篇文章能给你带来一些启发,无论是正在设计搜索模块,还是在优化现有系统。
搜索的终点不是"能搜到",而是让用户觉得"这个系统懂我"。而我们要做的,就是用技术去无限接近这个目标。
坚持下去吧,拒绝焦虑!!!