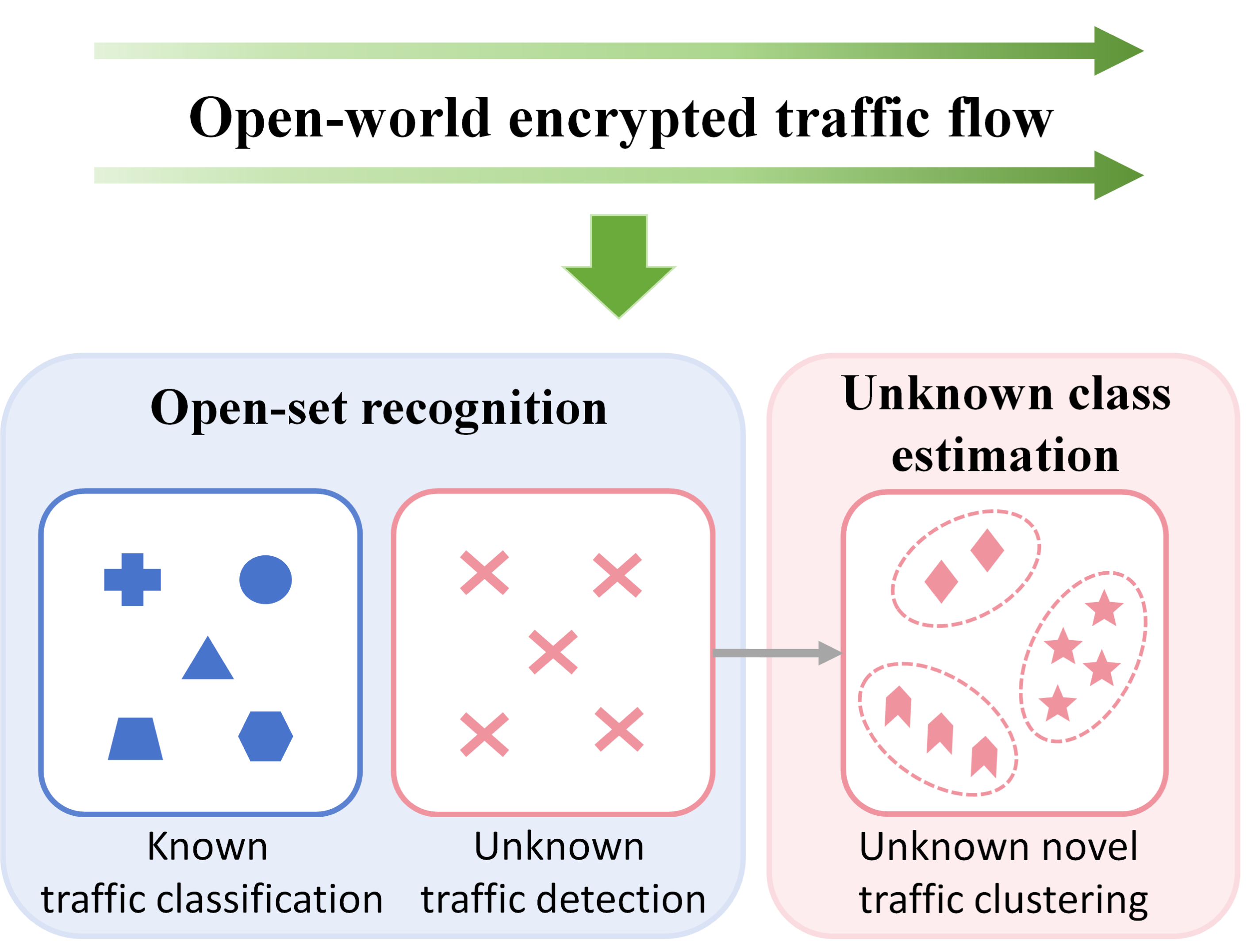
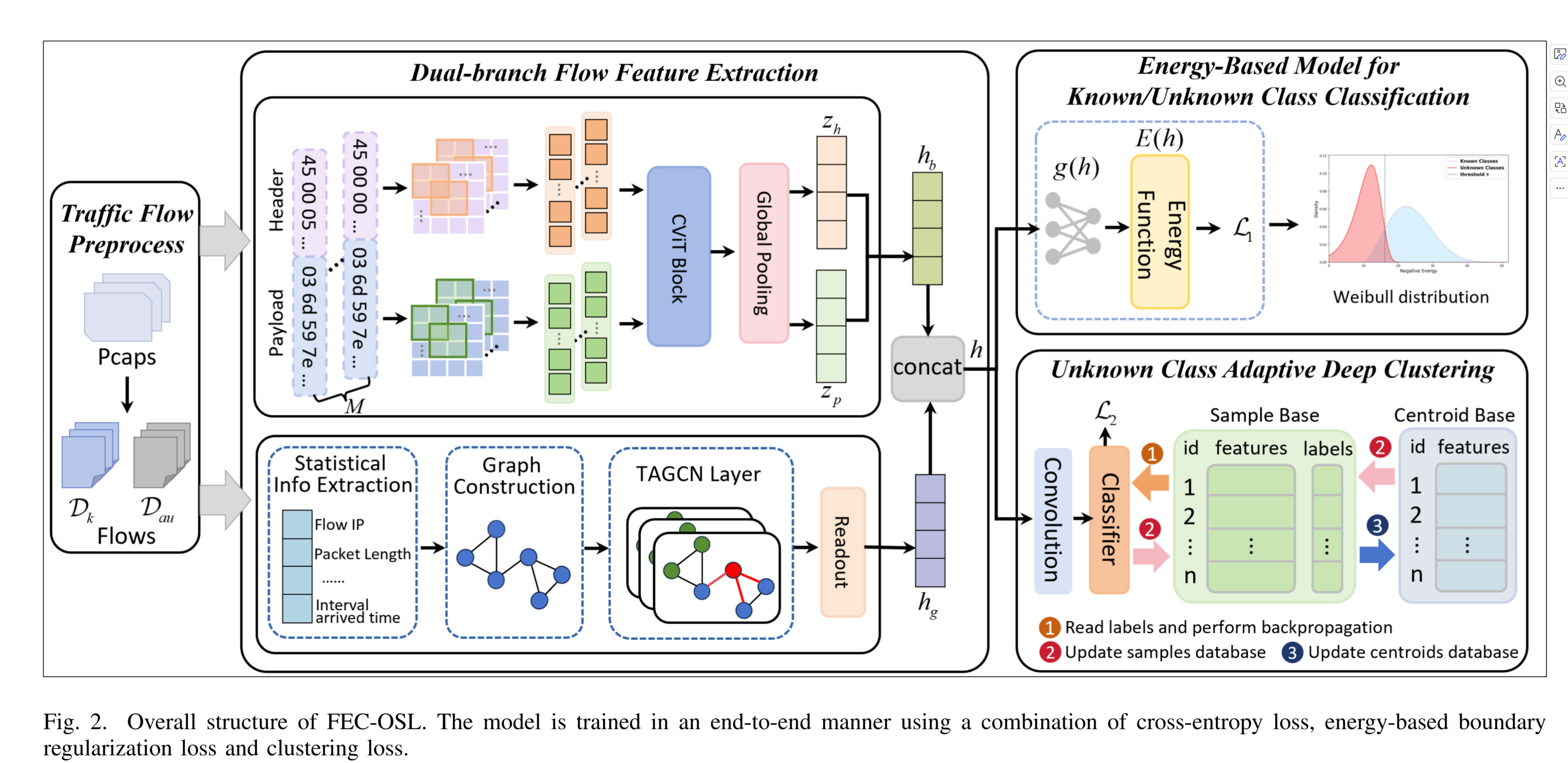
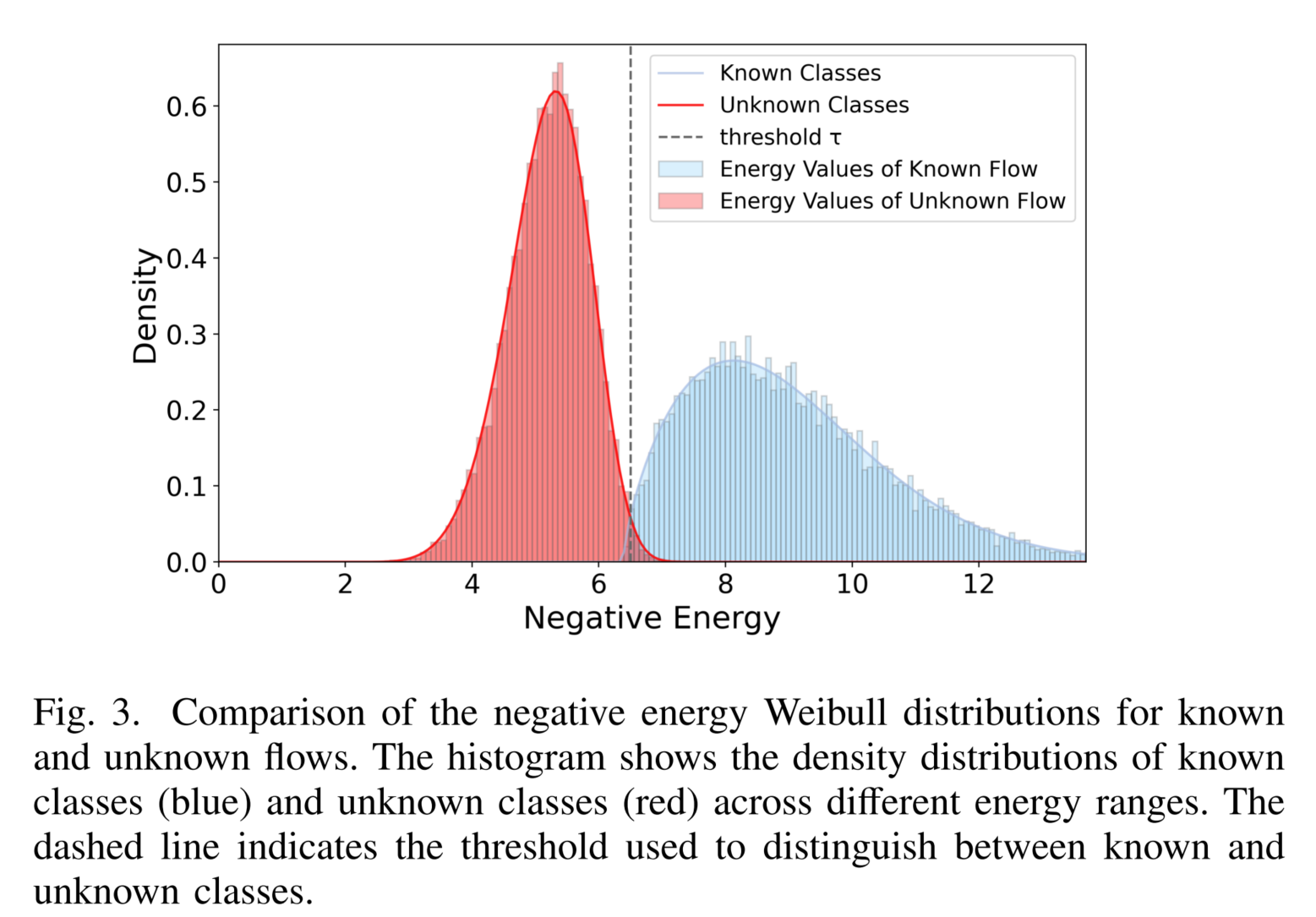
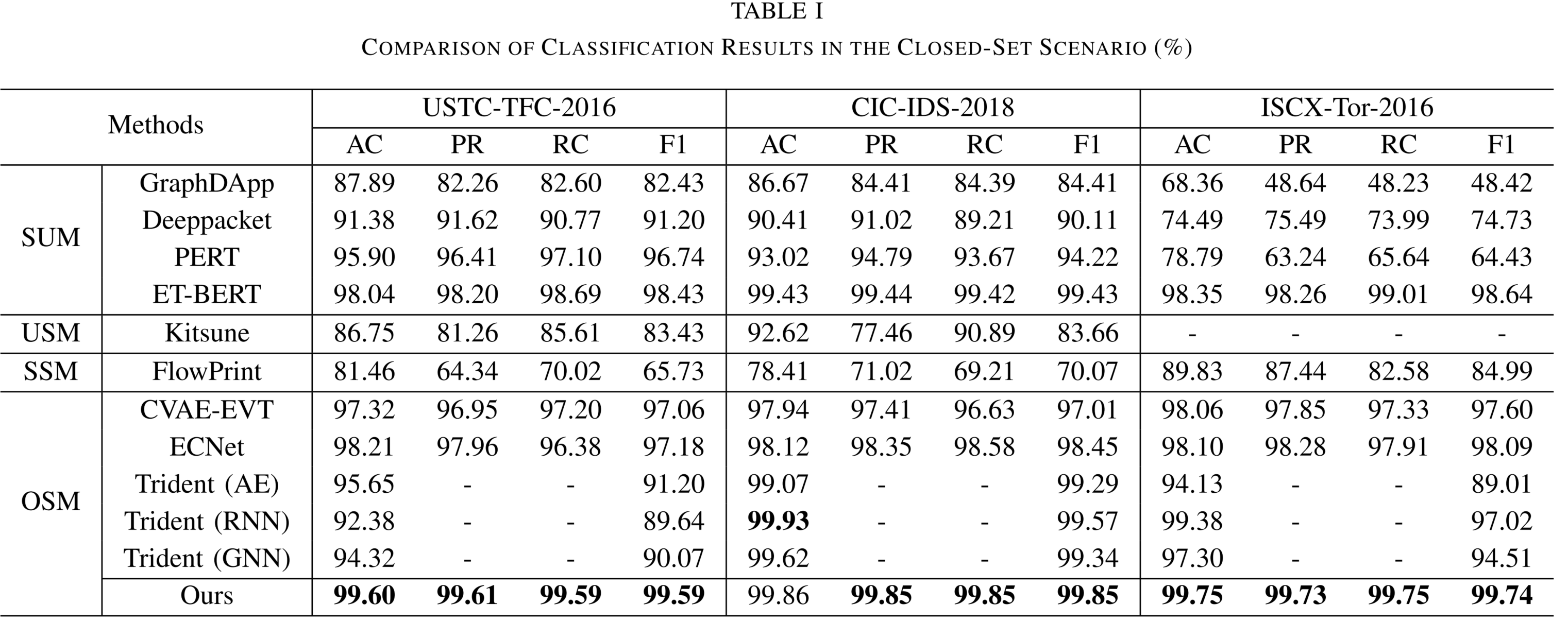
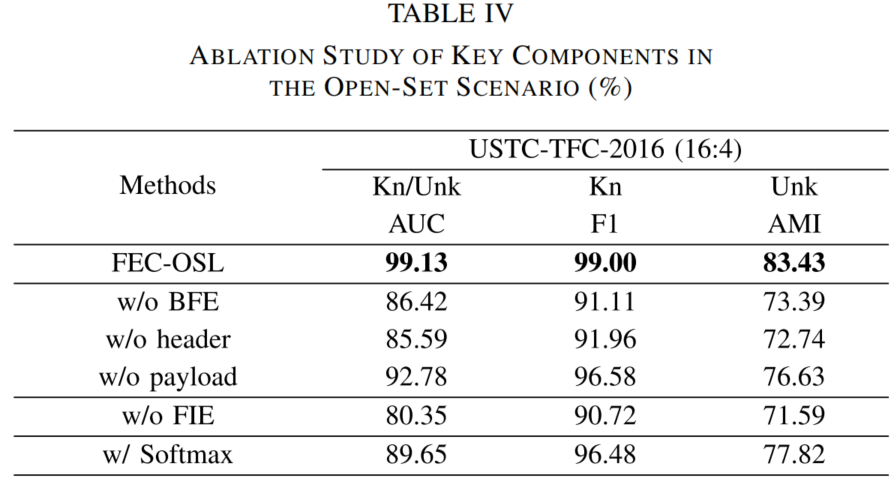
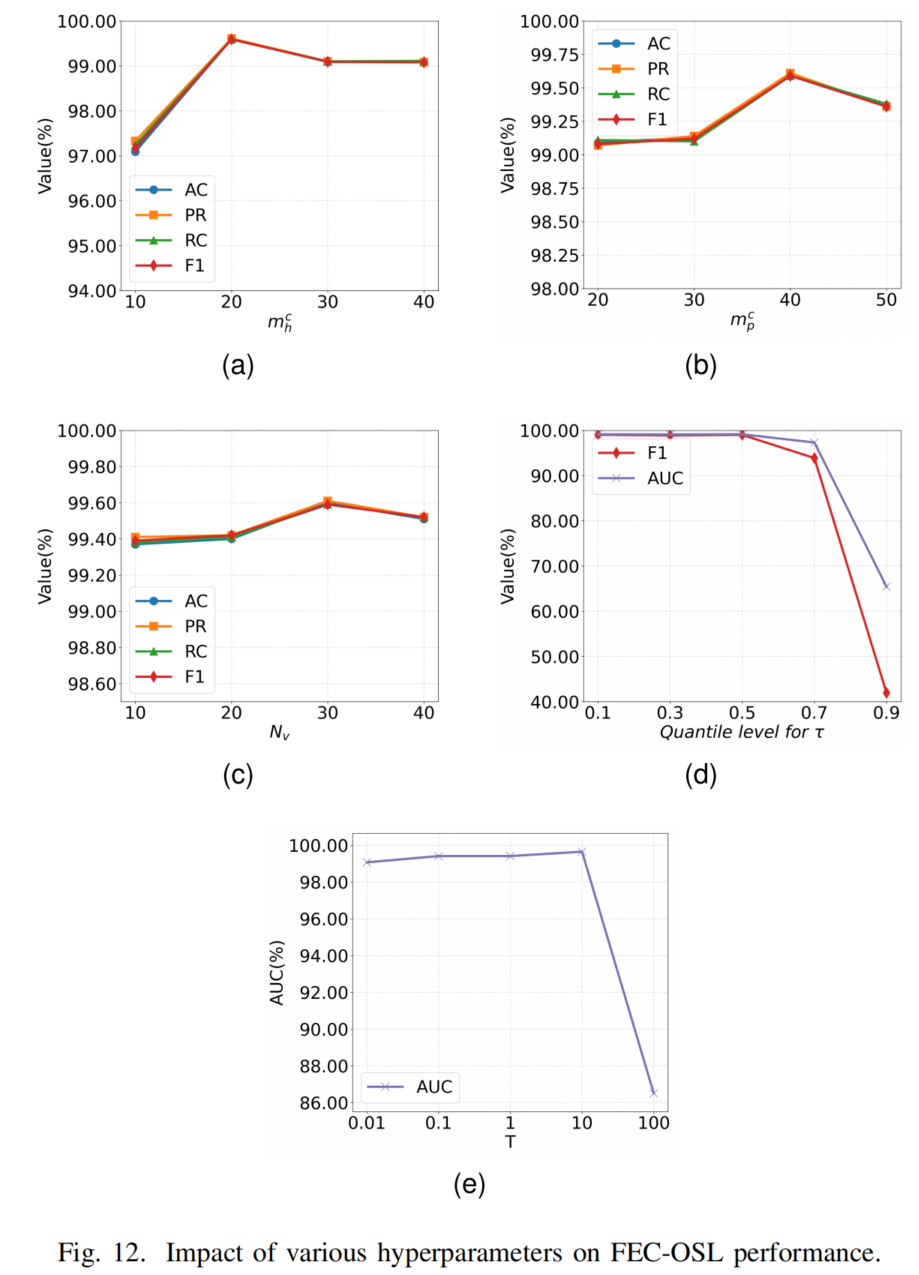
End-to-End Open-Set Semi-Supervised Learning for Fine-Grained Encrypted Traffic Classification
Qian Yang, Wenxuan He, Minghao Chen, Hongyu Du, Sisi Shao, Fei Wu, Shangdong Liu, Yimu Ji, and Kui Ren, Fellow, IEEE
面向细粒度加密流量分类的端到端开集半监督学习
杨倩,何文轩,陈明浩,杜鸿宇,邵思思,吴飞,刘山东,季一木,任奎(IEEE Fellow)
Q. Yang et al ., "End-to-End Open-Set Semi-Supervised Learning for Fine-Grained Encrypted Traffic Classification," in IEEE Transactions on Information Forensics and Security, vol. 21, pp. 1347-1362, 2026, doi: 10.1109/TIFS.2026.3653575.
1 F. Santoso and A. Finn, "An in-depth examination of artificial intelligence-enhanced cybersecurity in robotics, autonomous systems, and critical infrastructures," IEEE Trans. Services Comput. , vol. 17, no. 3, pp. 1293--1310, May 2024.
2 E. Papadogiannaki and S. Ioannidis, "A survey on encrypted network traffic analysis applications, techniques, and countermeasures," ACM Comput. Surv. , vol. 54, no. 6, pp. 1--35, Jul. 2022.
3 S. Rezaei and X. Liu, "Deep learning for encrypted traffic classification: An overview," IEEE Commun. Mag. , vol. 57, no. 5, pp. 76--81, May 2019.
4 M. Shen, M. Wei, L. Zhu, and M. Wang, "Classification of encrypted traffic with second-order Markov chains and application attribute bigrams," IEEE Trans. Inf. Forensics Security , vol. 12, no. 8, pp. 1830--1843, Aug. 2017.
5 Z. Ling, J. Luo, K. Wu, W. Yu, and X. Fu, "TorWard: Discovery of malicious traffic over tor," in Proc. IEEE Conf. Comput. Commun. (INFOCOM) , Apr. 2014, pp. 1402--1410.
6 N. Hua, H. Song, and T. V. Lakshman, "Variable-stride multi-pattern matching for scalable deep packet inspection," in Proc. IEEE Conf. Comput. Commun. (INFOCOM) , Apr. 2009, pp. 415--423.
8 R. R. Jagat, D. S. Sisodia, and P. Singh, "Detecting web attacks from HTTP weblogs using variational LSTM autoencoder deviation network," IEEE Trans. Services Comput. , vol. 17, no. 5, pp. 2210--2222, Sep. 2024.
9 T. van Ede et al., "FlowPrint: Semi-supervised mobile-app fingerprinting on encrypted network traffic," in Proc. Netw. Distrib. Syst. Secur. Symp. (NDSS) , Feb. 2020, pp. 1--18.
10 X. Hu, W. Gao, G. Cheng, R. Li, Y. Zhou, and H. Wu, "Toward early and accurate network intrusion detection using graph embedding," IEEE Trans. Inf. Forensics Security , vol. 18, pp. 5817--5831, 2023.
11 M. Lotfollahi, M. J. Siavoshani, R. S. H. Zade, and M. Saberian, "Deep packet: A novel approach for encrypted traffic classification using deep learning," Soft Comput. , vol. 24, no. 3, pp. 1999--2012, Feb. 2020.
12 Y. Yue, X. Chen, Z. Han, X. Zeng, and Y. Zhu, "Contrastive learning enhanced intrusion detection," IEEE Trans. Netw. Service Manage., vol. 19, no. 4, pp. 4232--4247, Dec. 2022.
13 E. M. Rudd, A. Rozsa, M. Gunther, and T. E. Boult, "A survey of stealth malware attacks, mitigation measures, and steps toward autonomous open world solutions," IEEE Commun. Surveys Tuts. , vol. 19, no. 2, pp. 1145--1172, 2017.
14 W. J. Scheirer, A. de Rezende Rocha, A. Sapkota, and T. E. Boult, "Toward open set recognition," IEEE Trans. Pattern Anal. Mach. Intell. , vol. 35, no. 7, pp. 1757--1772, Jul. 2013.
15 J. Jia and P. K. Chan, "Representation learning with function call graph transformations for malware open set recognition," in Proc. Int. Joint Conf. Neural Netw. (IJCNN) , Jul. 2022, pp. 1--8.
16 S. Dang, Z. Cao, Z. Cui, Y. Pi, and N. Liu, "Open set incremental learning for automatic target recognition," IEEE Trans. Geosci. Remote Sens. , vol. 57, no. 7, pp. 4445--4456, Jul. 2019.
17 Z. Zhao, Z. Li, Z. Song, W. Li, and F. Zhang, "Trident: A universal framework for fine-grained and class-incremental unknown traffic detection," in Proc. ACM Web Conf. , May 2024, pp. 1608--1619.
18 S.-J. Xu, G.-G. Geng, X.-B. Jin, D.-J. Liu, and J. Weng, "Seeing traffic paths: Encrypted traffic classification with path signature features," IEEE Trans. Inf. Forensics Security , vol. 17, pp. 2166--2181, 2022.
19 H. Jiang, B. Kim, M. Y. Guan, and M. R. Gupta, "To trust or not to trust a classifier," in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS) , 2018, pp. 5546--5557.
20 D. Hendrycks, "A baseline for detecting misclassified and out-of-distribution examples in neural networks," in Proc. Int. Conf. Learn. Represent. (ICLR) , Apr. 2017, pp. 1--12.
21 J. Zhang, F. Li, F. Ye, and H. Wu, "Autonomous unknown-application filtering and labeling for DL-based traffic classifier update," in Proc. IEEE Conf. Comput. Commun. (INFOCOM) , Jul. 2020, pp. 397--405.
22 J. Yang, X. Chen, S. Chen, X. Jiang, and X. Tan, "Conditional variational auto-encoder and extreme value theory aided two-stage learning approach for intelligent fine-grained known/unknown intrusion detection," IEEE Trans. Inf. Forensics Security, vol. 16, pp. 3538--3553, 2021.
23 M. Ester, H. Kriegel, J. Sander, and X. Xu, "A density-based algorithm for discovering clusters in large spatial databases with noise," in Proc. 2nd Int. Conf. Knowl. Discovery Data Mining (KDD) , 1996, pp. 226--231.
24 A. M. Ikotun, A. E. Ezugwu, L. Abualigah, B. Abuhaija, and J. Heming, "K-means clustering algorithms: A comprehensive review, variants analysis, and advances in the era of big data," Inf. Sci., vol. 622, pp. 178--210, Apr. 2023.
10 X. Hu, W. Gao, G. Cheng, R. Li, Y. Zhou, and H. Wu, "Toward early and accurate network intrusion detection using graph embedding," IEEE Trans. Inf. Forensics Security , vol. 18, pp. 5817--5831, 2023.
11 M. Lotfollahi, M. J. Siavoshani, R. S. H. Zade, and M. Saberian, "Deep packet: A novel approach for encrypted traffic classification using deep learning," Soft Comput., vol. 24, no. 3, pp. 1999--2012, Feb. 2020.
25 Q. Zhou, L. Wang, H. Zhu, T. Lu, and V. S. Sheng, "WF-transformer: Learning temporal features for accurate anonymous traffic identification by using transformer networks," IEEE Trans. Inf. Forensics Security, vol. 19, pp. 30--43, 2024.
26 Y. Mirsky, T. Doitshman, Y. Elovici, and A. Shabtai, "Kitsune: An ensemble of autoencoders for online network intrusion detection," in Proc. Netw. Distrib. Syst. Secur. Symp. (NDSS), Feb. 2018, pp. 1--15.
9 T. van Ede et al., "FlowPrint: Semi-supervised mobile-app fingerprinting on encrypted network traffic," in Proc. Netw. Distrib. Syst. Secur. Symp. (NDSS), Feb. 2020, pp. 1--18.
20 D. Hendrycks, "A baseline for detecting misclassified and out-of-distribution examples in neural networks," in Proc. Int. Conf. Learn. Represent. (ICLR), Apr. 2017, pp. 1--12.
27 L. Yang et al., "CADE: Detecting and explaining concept drift samples for security applications," in Proc. 30th USENIX Secur. Symp. (USENIX Secur.), Aug. 2021, pp. 2327--2344.
17 Z. Zhao, Z. Li, Z. Song, W. Li, and F. Zhang, "Trident: A universal framework for fine-grained and class-incremental unknown traffic detection," in Proc. ACM Web Conf., May 2024, pp. 1608--1619.
22 J. Yang, X. Chen, S. Chen, X. Jiang, and X. Tan, "Conditional variational auto-encoder and extreme value theory aided two-stage learning approach for intelligent fine-grained known/unknown intrusion detection," IEEE Trans. Inf. Forensics Security, vol. 16, pp. 3538--3553, 2021.
1 F. Santoso and A. Finn, "An in-depth examination of artificial intelligence-enhanced cybersecurity in robotics, autonomous systems, and critical infrastructures," IEEE Trans. Services Comput. , vol. 17, no. 3, pp. 1293--1310, May 2024.
2 E. Papadogiannaki and S. Ioannidis, "A survey on encrypted network traffic analysis applications, techniques, and countermeasures," ACM Comput. Surv. , vol. 54, no. 6, pp. 1--35, Jul. 2022.
3 S. Rezaei and X. Liu, "Deep learning for encrypted traffic classification: An overview," IEEE Commun. Mag. , vol. 57, no. 5, pp. 76--81, May 2019.
4 M. Shen, M. Wei, L. Zhu, and M. Wang, "Classification of encrypted traffic with second-order Markov chains and application attribute bigrams," IEEE Trans. Inf. Forensics Security , vol. 12, no. 8, pp. 1830--1843, Aug. 2017.
5 Z. Ling, J. Luo, K. Wu, W. Yu, and X. Fu, "TorWard: Discovery of malicious traffic over tor," in Proc. IEEE Conf. Comput. Commun. (INFOCOM) , Apr. 2014, pp. 1402--1410.
6 N. Hua, H. Song, and T. V. Lakshman, "Variable-stride multi-pattern matching for scalable deep packet inspection," in Proc. IEEE Conf. Comput. Commun. (INFOCOM) , Apr. 2009, pp. 415--423.
8 R. R. Jagat, D. S. Sisodia, and P. Singh, "Detecting web attacks from HTTP weblogs using variational LSTM autoencoder deviation network," IEEE Trans. Services Comput. , vol. 17, no. 5, pp. 2210--2222, Sep. 2024.
9 T. van Ede et al., "FlowPrint: Semi-supervised mobile-app fingerprinting on encrypted network traffic," in Proc. Netw. Distrib. Syst. Secur. Symp. (NDSS) , Feb. 2020, pp. 1--18.
10 X. Hu, W. Gao, G. Cheng, R. Li, Y. Zhou, and H. Wu, "Toward early and accurate network intrusion detection using graph embedding," IEEE Trans. Inf. Forensics Security , vol. 18, pp. 5817--5831, 2023.
11 M. Lotfollahi, M. J. Siavoshani, R. S. H. Zade, and M. Saberian, "Deep packet: A novel approach for encrypted traffic classification using deep learning," Soft Comput. , vol. 24, no. 3, pp. 1999--2012, Feb. 2020.
12 Y. Yue, X. Chen, Z. Han, X. Zeng, and Y. Zhu, "Contrastive learning enhanced intrusion detection," IEEE Trans. Netw. Service Manage. , vol. 19, no. 4, pp. 4232--4247, Dec. 2022.
13 E. M. Rudd, A. Rozsa, M. Gunther, and T. E. Boult, "A survey of stealth malware attacks, mitigation measures, and steps toward autonomous open world solutions," IEEE Commun. Surveys Tuts. , vol. 19, no. 2, pp. 1145--1172, 2017.
14 W. J. Scheirer, A. de Rezende Rocha, A. Sapkota, and T. E. Boult, "Toward open set recognition," IEEE Trans. Pattern Anal. Mach. Intell. , vol. 35, no. 7, pp. 1757--1772, Jul. 2013.
15 J. Jia and P. K. Chan, "Representation learning with function call graph transformations for malware open set recognition," in Proc. Int. Joint Conf. Neural Netw. (IJCNN) , Jul. 2022, pp. 1--8.
16 S. Dang, Z. Cao, Z. Cui, Y. Pi, and N. Liu, "Open set incremental learning for automatic target recognition," IEEE Trans. Geosci. Remote Sens. , vol. 57, no. 7, pp. 4445--4456, Jul. 2019.
17 Z. Zhao, Z. Li, Z. Song, W. Li, and F. Zhang, "Trident: A universal framework for fine-grained and class-incremental unknown traffic detection," in Proc. ACM Web Conf. , May 2024, pp. 1608--1619.
18 S.-J. Xu, G.-G. Geng, X.-B. Jin, D.-J. Liu, and J. Weng, "Seeing traffic paths: Encrypted traffic classification with path signature features," IEEE Trans. Inf. Forensics Security , vol. 17, pp. 2166--2181, 2022.
19 H. Jiang, B. Kim, M. Y. Guan, and M. R. Gupta, "To trust or not to trust a classifier," in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS) , 2018, pp. 5546--5557.
20 D. Hendrycks, "A baseline for detecting misclassified and out-of-distribution examples in neural networks," in Proc. Int. Conf. Learn. Represent. (ICLR) , Apr. 2017, pp. 1--12.
21 J. Zhang, F. Li, F. Ye, and H. Wu, "Autonomous unknown-application filtering and labeling for DL-based traffic classifier update," in Proc. IEEE Conf. Comput. Commun. (INFOCOM) , Jul. 2020, pp. 397--405.
22 J. Yang, X. Chen, S. Chen, X. Jiang, and X. Tan, "Conditional variational auto-encoder and extreme value theory aided two-stage learning approach for intelligent fine-grained known/unknown intrusion detection," IEEE Trans. Inf. Forensics Security , vol. 16, pp. 3538--3553, 2021.
23 M. Ester, H. Kriegel, J. Sander, and X. Xu, "A density-based algorithm for discovering clusters in large spatial databases with noise," in Proc. 2nd Int. Conf. Knowl. Discovery Data Mining (KDD) , 1996, pp. 226--231.
24 A. M. Ikotun, A. E. Ezugwu, L. Abualigah, B. Abuhaija, and J. Heming, "K-means clustering algorithms: A comprehensive review, variants analysis, and advances in the era of big data," Inf. Sci. , vol. 622, pp. 178--210, Apr. 2023.
25 Q. Zhou, L. Wang, H. Zhu, T. Lu, and V. S. Sheng, "WF-transformer: Learning temporal features for accurate anonymous traffic identification by using transformer networks," IEEE Trans. Inf. Forensics Security , vol. 19, pp. 30--43, 2024.
26 Y. Mirsky, T. Doitshman, Y. Elovici, and A. Shabtai, "Kitsune: An ensemble of autoencoders for online network intrusion detection," in Proc. Netw. Distrib. Syst. Secur. Symp. (NDSS) , Feb. 2018, pp. 1--15.
27 L. Yang et al., "CADE: Detecting and explaining concept drift samples for security applications," in Proc. 30th USENIX Secur. Symp. (USENIX Secur.) , Aug. 2021, pp. 2327--2344.
28 X. Han et al., "ContraMTD: An unsupervised malicious network traffic detection method based on contrastive learning," in Proc. ACM Web Conf. , May 2024, pp. 1680--1689.
29 X. Han et al., "DE-GNN: Dual embedding with graph neural network for fine-grained encrypted traffic classification," Comput. Netw. , vol. 245, May 2024, Art. no. 110372.
30 H. Zhang et al., "TFE-GNN: A temporal fusion encoder using graph neural networks for fine-grained encrypted traffic classification," in Proc. ACM Web Conf. , Apr. 2023, pp. 2066--2075.
31 X. Han, S. Liu, J. Liu, B. Jiang, Z. Lu, and B. Liu, "ECNet: Robust malicious network traffic detection with multi-view feature and confidence mechanism," IEEE Trans. Inf. Forensics Security , vol. 19, pp. 6871--6885, 2024.
32 A. Dosovitskiy et al., "An image is worth 16x16 words: Transformers for image recognition at scale," in Proc. Int. Conf. Learn. Represent. (ICLR) , May 2021, pp. 1--22.
33 A. Vaswani et al., "Attention is all you need," in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS) , vol. 30, 2025, pp. 5998--6008.
34 Y.-H. Cao, H. Yu, and J. Wu, "Training vision transformers with only 2040 images," in Proc. Eur. Conf. Comput. Vis. (ECCV) , 2022, pp. 220--237.
35 M. Shen, J. Zhang, L. Zhu, K. Xu, and X. Du, "Accurate decentralized application identification via encrypted traffic analysis using graph neural networks," IEEE Trans. Inf. Forensics Security , vol. 16, pp. 2367--2380, 2021.
36 M. Shen, Y. Liu, L. Zhu, X. Du, and J. Hu, "Fine-grained webpage fingerprinting using only packet length information of encrypted traffic," IEEE Trans. Inf. Forensics Security , vol. 16, pp. 2046--2059, 2021.
37 J. Du, S. Zhang, G. Wu, J. M. F. Moura, and S. Kar, "Topology adaptive graph convolutional networks," in Proc. Int. Conf. Learn. Represent. (ICLR) , 2017, pp. 1--13.
38 W. Grathwohl et al., "Your classifier is secretly an energy-based model and you should treat it like one," in Proc. Int. Conf. Learn. Represent. (ICLR) , Apr. 2020, pp. 1--23.
39 R. Peng, H. Zou, H. Wang, Z. YaWen, Z. Huang, and J. Zhao, "Energy-based automated model evaluation," in Proc. Int. Conf. Learn. Represent. (ICLR) , May 2024, pp. 1--39.
40 C. Lai, D. N. P. Murthy, and M. Xie, "Weibull distributions and their applications," in Springer Handbooks . Cham, Switzerland: Springer, 2006, pp. 63--78.
41 W. Wang, M. Zhu, X. Zeng, X. Ye, and Y. Sheng, "Malware traffic classification using convolutional neural network for representation learning," in Proc. Int. Conf. Inf. Netw. (ICOIN) , Jan. 2017, pp. 712--717.
43 A. H. Lashkari, G. D. Gil, M. S. I. Mamun, and A. A. Ghorbani, "Characterization of Tor traffic using time based features," in Proc. 3rd Int. Conf. Inf. Syst. Secur. Privacy (ICISSP) , Feb. 2017, pp. 253--262.
44 H. Y. He, Z. Guo Yang, and X. N. Chen, "PERT: Payload encoding representation from transformer for encrypted traffic classification," in Proc. ITU Kaleidoscope, Ind.-Driven Digit. Transformation (ITU K) , Dec. 2020, pp. 1--8.
45 X. Lin, G. Xiong, G. Gou, Z. Li, J. Shi, and J. Yu, "ET-BERT: A contextualized datagram representation with pre-training transformers for encrypted traffic classification," in Proc. ACM Web Conf., Apr. 2022, pp. 633--642.