PyTorch实战(37)------使用Optuna搜索最优超参数
0. 前言
在自动机器学习一节中,我们完成了对 Auto-PyTorch 的探索。我们成功地在没有指定模型架构和超参数的情况下,通过使用 Auto-PyTorch 自动化构建了 MNIST 数字分类模型。接下来,我们将重点讨论 Optuna------这是一个专注于寻找最优超参数组合、且与 PyTorch 兼容良好的工具。该工具采用的树结构 Parzen 估计器 (Tree-Structured Parzen Estimation, TPE) 和协方差矩阵自适应进化策略 (Covariance Matrix Adaptation Evolution Strategy, CMA-ES) 等先进搜索策略。
除了超参数搜索方法外,该工具还提供了简洁易用的 API 接口。在本节中,我们将再次构建和训练 MNIST 手写数字识别模型,但本节将重点介绍如何使用 Optuna 来确定最优的超参数配置。
1. 定义模型架构
首先,我们将定义一个兼容 Optuna 的模型对象,在模型定义代码中加入 Optuna 提供的 API 实现超参数的可配置化,即对模型的超参数进行参数化。
(1) 首先,导入所需库,其中 optuna 库用于管理超参数搜索过程:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import optuna
device = torch.device("cpu")(2) 定义模型架构。为了使某些超参数(如网络层数和每层单元数)可灵活调整,我们需要在模型定义代码中加入 Optuna 的逻辑控制。如下代码所示,我们首先声明需要 1 到 4 个卷积层,以及后续的 1 到 2 个全连接层:
python
class ConvNet(nn.Module):
def __init__(self, trial):
super(ConvNet, self).__init__()
num_conv_layers = trial.suggest_int("num_conv_layers", 1, 4)
num_fc_layers = trial.suggest_int("num_fc_layers", 1, 2)(3) 随后我们依次堆叠卷积层。每个卷积层后都紧跟一个 ReLU 激活层,且每个卷积层的通道数可在 16 到 64 之间动态调整(通过 trial.suggest_int() 实现)。卷积操作的步长 (stride) 固定为3,填充 (padding) 统一启用。整个卷积块后接一个最大池化层,然后是一个 Dropout 层,dropout 率范围在 0.1 到 0.4 之间:
python
self.layers = []
input_depth = 1 # grayscale image
for i in range(num_conv_layers):
output_depth = trial.suggest_int(f"conv_depth_{i}", 16, 64)
self.layers.append(nn.Conv2d(input_depth, output_depth, 3, 1))
self.layers.append(nn.ReLU())
input_depth = output_depth
self.layers.append(nn.MaxPool2d(2))
p = trial.suggest_float(f"conv_dropout_{i}", 0.1, 0.4)
self.layers.append(nn.Dropout(p))
self.layers.append(nn.Flatten())(4) 接下来,添加一个展平 (flatten) 层,以便连接全连接层。需要定义 __get_flatten_shape 函数来推导展平层的输出形状。随后我们依次添加全连接层,其神经元数量设定在 16 至 64 个之间。每个全连接层后都接一个 Dropout 层,dropout 概率同样设定在 0.1 到 0.4 范围内。最后,添加一个固定的全连接层输出 10 个数值(对应每个类别/数字),后接 LogSoftmax 层。完成所有层定义后,实例化模型对象:
python
input_feat = self._get_flatten_shape()
for i in range(num_fc_layers):
output_feat = trial.suggest_int(f"fc_output_feat_{i}", 16, 64)
self.layers.append(nn.Linear(input_feat, output_feat))
self.layers.append(nn.ReLU())
p = trial.suggest_float(f"fc_dropout_{i}", 0.1, 0.4)
self.layers.append(nn.Dropout(p))
input_feat = output_feat
self.layers.append(nn.Linear(input_feat, 10))
self.layers.append(nn.LogSoftmax(dim=1))
self.model = nn.Sequential(*self.layers)
def _get_flatten_shape(self):
conv_model = nn.Sequential(*self.layers)
op_feat = conv_model(torch.rand(1, 1, 28, 28))
n_size = op_feat.data.view(1, -1).size(1)
return n_size(5) 该模型初始化函数依赖于 Optuna 提供的 trial 对象,该对象将决定模型的超参数设置。最后,定义 forward 方法:
python
def forward(self, x):
return self.model(x)(6) 完成模型对象的定义后加载数据集:
python
train_ds = datasets.MNIST('./data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1302,), (0.3069,))]))
test_ds = datasets.MNIST('./data', train=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1302,), (0.3069,))]))
train_dataloader = torch.utils.data.DataLoader(train_ds, batch_size=32, shuffle=True)
test_dataloader = torch.utils.data.DataLoader(test_ds, batch_size=500, shuffle=True)在本节中,我们已经成功定义了参数化模型对象并完成了数据集加载。接下来,定义模型训练/测试流程以及优化器调度方案。
2. 定义模型训练流程
模型训练本身涉及优化器、学习率等超参数。在本节中,我们将利用 Optuna 的参数化能力来定义训练过程。
(1) 首先,定义训练过程:
python
def train(model, device, train_dataloader, optim, epoch):
model.train()
for b_i, (X, y) in enumerate(train_dataloader):
X, y = X.to(device), y.to(device)
optim.zero_grad()
pred_prob = model(X)
loss = F.nll_loss(pred_prob, y) # nll is the negative likelihood loss
loss.backward()
optim.step()
if b_i % 500 == 0:
print('epoch: {} [{}/{} ({:.0f}%)]\t training loss: {:.6f}'.format(
epoch, b_i * len(X), len(train_dataloader.dataset),
100. * b_i / len(train_dataloader), loss.item()))(2) 为了符合 Optuna API 的要求,测试过程需要返回一个模型性能度量指标------在本节中为准确率 (accuracy),以便 Optuna 能基于该指标比较不同超参数配置:
python
def test(model, device, test_dataloader):
model.eval()
loss = 0
success = 0
with torch.no_grad():
for X, y in test_dataloader:
X, y = X.to(device), y.to(device)
pred_prob = model(X)
loss += F.nll_loss(pred_prob, y, reduction='sum').item() # loss summed across the batch
pred = pred_prob.argmax(dim=1, keepdim=True) # use argmax to get the most likely prediction
success += pred.eq(y.view_as(pred)).sum().item()
loss /= len(test_dataloader.dataset)
accuracy = 100. * success / len(test_dataloader.dataset)
print('\nTest dataset: Overall Loss: {:.4f}, Overall Accuracy: {}/{} ({:.0f}%)\n'.format(
loss, success, len(test_dataloader.dataset), accuracy))
return accuracy在传统模型训练过程中,直接实例化模型和优化函数并设置学习率,然后在函数外部启动训练循环。但为了遵循 Optuna API 规范,现在需要将所有操作封装在一个目标函数中,该函数接收与模型对象 __init__ 方法相同的 trial 参数。
(4) 此处仍需 trial 对象参与,因为学习率取值和优化器选择也属于需要决策的超参数范畴:
python
def objective(trial):
model = ConvNet(trial)
opt_name = trial.suggest_categorical("optimizer", ["Adam", "Adadelta", "RMSprop", "SGD"])
lr = trial.suggest_float("lr", 1e-1, 5e-1, log=True)
optimizer = getattr(optim, opt_name)(model.parameters(), lr=lr)
for epoch in range(1, 3):
train(model, device, train_dataloader, optimizer, epoch)
accuracy = test(model, device, test_dataloader)
trial.report(accuracy, epoch)
if trial.should_prune():
raise optuna.exceptions.TrialPruned()
return accuracy在每个 epoch 中,我们会记录模型测试流程返回的准确率。此外,在每个 epoch 中,都会执行"剪枝" (prune) 判断------即决定是否跳过当前 epoch。这是 Optuna 提供的另一个功能,用于加速超参数搜索过程,以免浪费时间在不佳的超参数上。
3. Optuna 超参数搜索
在本节中,将实例化一个 Optuna study 对象,并使用模型之前定义的和训练流程,针对给定模型和数据集执行 Optuna 的超参数搜索过程。
(1) 准备好所有必要的组件后,即可启动超参数搜索流程,在 Optuna 中,称之为研究 (study),每次超参数搜索迭代称为一个"试验" (trial):
python
study = optuna.create_study(study_name="pytorch_learning", direction="maximize")
study.optimize(objective, n_trials=100, timeout=2000)direction 参数用于指导 Optuna 比较不同超参数配置。由于我们的评估指标是准确率,因此需要最大化该指标。我们设置研究的最长运行时间为 2000 秒,或最多进行 10 次不同搜索------以先达到的条件为准。执行上述命令后,输出结果如下所示:
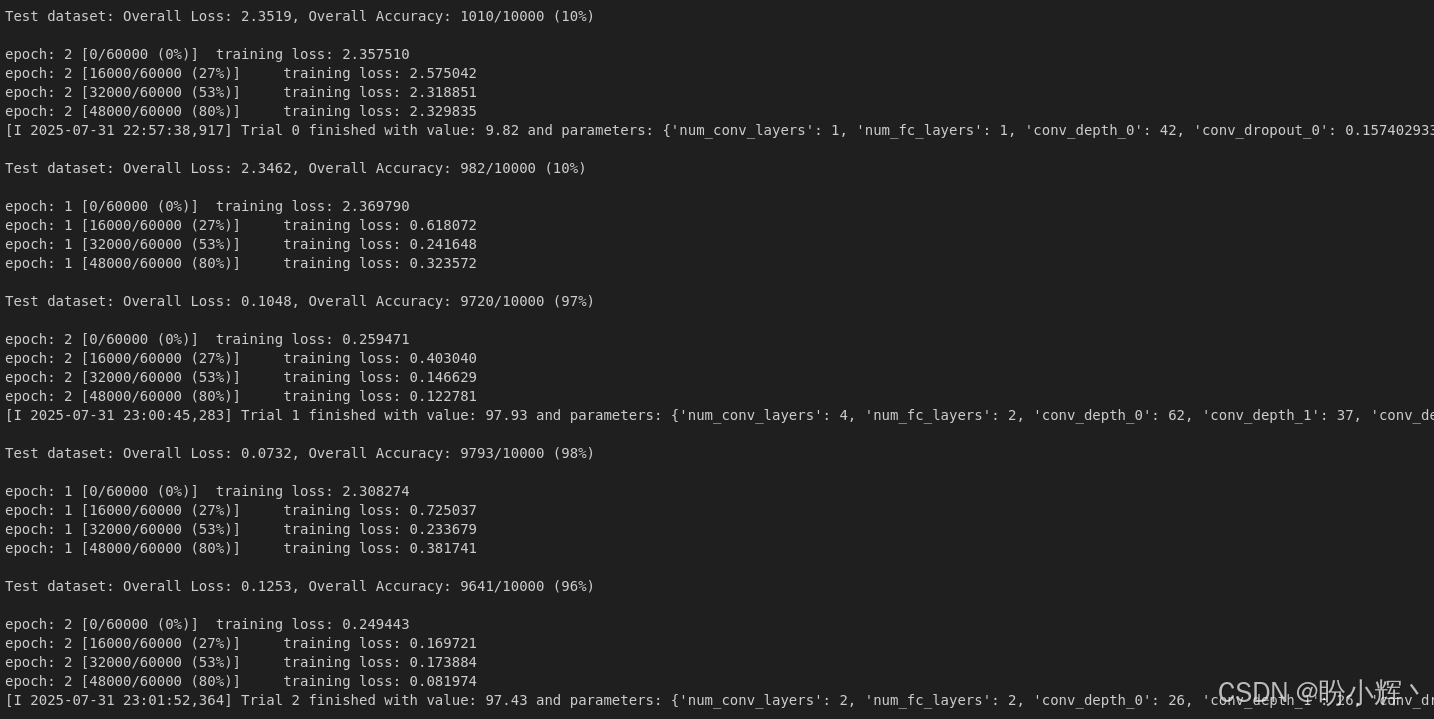
可以看到,第 4 次试验结果最优,测试集准确率达到 98.83%,而有些试验被提前终止(剪枝)。日志中还记录了每个未被剪枝试验的超参数配置。以最优试验为例:该配置包含三个卷积层(特征图数量分别为 52、51 和 32),以及 1 个全连接层等。
(2) 每个试验都会被标记为完成 (completed) 或剪枝 (pruned) 状态,可通过以下代码进行区分:
python
pruned_trials = [t for t in study.trials if t.state == optuna.trial.TrialState.PRUNED]
complete_trials = [t for t in study.trials if t.state == optuna.trial.TrialState.COMPLETE](3) 可以通过以下代码查看最优试验的超参数配置:
python
print("results: ")
print("num_trials_conducted: ", len(study.trials))
print("num_trials_pruned: ", len(pruned_trials))
print("num_trials_completed: ", len(complete_trials))
print("results from best trial:")
trial = study.best_trial
print("accuracy: ", trial.value)
print("hyperparameters: ")
for key, value in trial.params.items():
print("{}: {}".format(key, value))输出结果如下所示:

输出结果显示总试验次数与成功完成的试验次数,并详细展示最优试验的模型超参数,包括:网络层数、各层神经元数量、学习率、优化器调度等关键信息。
通过使用 Optuna,我们成功为手写数字分类模型定义了多种超参数的取值范围。借助 Optuna 的超参数搜索算法,我们运行了 10 次不同试验,并在其中一次试验中获得了 98.83 %的最高准确率。来自最优试验的模型(包括架构和超参数)可用于更大规模数据集的训练,从而应用于生产系统。
小结
自动机器学习 (AutoML) 能够为给定神经网络自动寻找最优架构与最佳超参数配置。在本节中,我们介绍了一个 AutoML 工具 Optuna,它专为 PyTorch 模型提供超参数搜索功能。通过本节的学习,可以运用 Optuna 为任何 PyTorch 编写的神经网络模型寻找最优超参数。当面对超大规模模型和/或需要调整的超参数数量极多时,Optuna 还支持分布式搜索。值得注意的是,Optuna 不仅支持 PyTorch,还兼容 TensorFlow、scikit-learn、MXNet 等主流机器学习框架。
系列链接
PyTorch实战(1)------深度学习(Deep Learning)
PyTorch实战(2)------使用PyTorch构建神经网络
PyTorch实战(3)------PyTorch vs. TensorFlow详解
PyTorch实战(4)------卷积神经网络(Convolutional Neural Network,CNN)
PyTorch实战(5)------深度卷积神经网络
PyTorch实战(6)------模型微调详解
PyTorch实战(7)------循环神经网络
PyTorch实战(8)------图像描述生成
PyTorch实战(9)------从零开始实现Transformer
PyTorch实战(10)------从零开始实现GPT模型
PyTorch实战(11)------随机连接神经网络(RandWireNN)
PyTorch实战(12)------图神经网络(Graph Neural Network,GNN)
PyTorch实战(13)------图卷积网络(Graph Convolutional Network,GCN)
PyTorch实战(14)------图注意力网络(Graph Attention Network,GAT)
PyTorch实战(15)------基于Transformer的文本生成技术
PyTorch实战(16)------基于LSTM实现音乐生成
PyTorch实战(17)------神经风格迁移
PyTorch实战(18)------自编码器(Autoencoder,AE)
PyTorch实战(19)------变分自编码器(Variational Autoencoder,VAE)
PyTorch实战(20)------生成对抗网络(Generative Adversarial Network,GAN)
PyTorch实战(21)------扩散模型(Diffusion Model)
PyTorch实战(22)------MuseGAN详解与实现
PyTorch实战(23)------基于Transformer生成音乐
PyTorch实战(24)------深度强化学习
PyTorch实战(25)------使用PyTorch构建DQN模型
PyTorch实战(26)------PyTorch分布式训练
PyTorch实战(27)------自动混合精度训练
PyTorch实战(28)------PyTorch深度学习模型部署
PyTorch实战(29)------使用TorchServe部署PyTorch模型
PyTorch实战(30)------使用TorchScript和ONNX导出通用PyTorch模型
PyTorch实战(31)------在Android上部署PyTorch模型
PyTorch实战(32)------在iOS上构建PyTorch应用
PyTorch实战(33)------使用fastai进行快速原型开发
PyTorch实战(34)------基于PyTorch Lightning的跨硬件模型训练
PyTorch实战(35)------使用PyTorch Profiler分析模型推理性能
PyTorch实战(36)------PyTorch自动机器学习