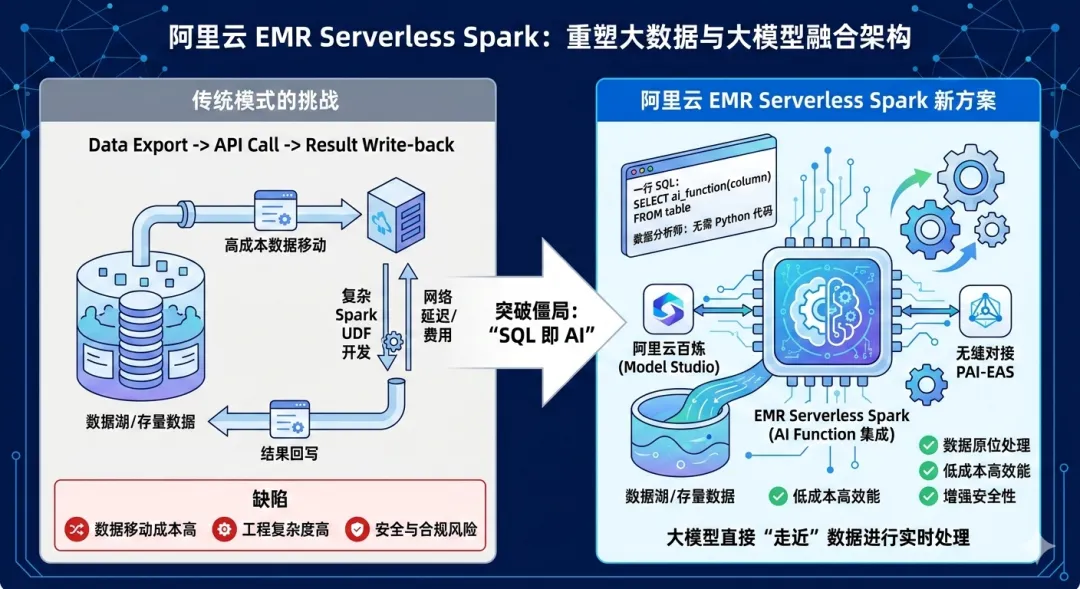
将大模型应用于海量存量数据曾是一道无解题:是为了调用 API 而忍受 PB 级数据的漫长搬运?还是为了封装 HTTP 请求而让分析师去啃复杂的 Spark UDF 代码?亦或是冒着合规风险将敏感数据移出安全域?
今天,阿里云 EMR Serverless Spark 解决了这些难题。 通过深度集成 AI Function 能力,并无缝对接 阿里云百炼(Model Studio) 与 阿里云人工智能平台 PAI 模型在线服务 PAI-EAS ,定义了"SQL 即 AI"的新解决思路------数据分析师只需一行 SQL,即可直接调用世界顶尖的大模型。无需编写一行 Python 代码,无需移动任何数据,让大模型直接"走近"数据进行实时处理。
全球趋势:当 SQL 遇上大模型
放眼全球,"Data + AI" 的融合已成为大势所趋。业界领先的云厂商如 Databricks 和 Snowflake,已纷纷推出了类似 "AI Functions" 或 "Cortex AI" 的功能,试图将大模型能力下沉到数据引擎层。他们的核心逻辑是一致的:消除数据与 AI 之间的工程鸿沟,让非机器学习专家也能通过熟悉的 SQL 接口使用大模型。
阿里云 EMR Serverless Spark 顺应全球技术变革浪潮,提供了既符合主流架构规范、又懂复杂业务语境的通用解决方案。您无需为了使用 AI 而改变现有的数据底座,只需让 AI 像 SUM()、COUNT() 一样,作为原生函数直接嵌入 SQL。这种"无感集成"的方式,正在重塑数据处理的未来工作方式。
百炼与 PAI:两种接入模式的工程实践
EMR Serverless Spark 的 AI Function 绝非空中楼阁,它依托于阿里云强大的 AI 基础设施,提供了两种核心对接模式,覆盖从快速验证到企业级生产的全场景需求。
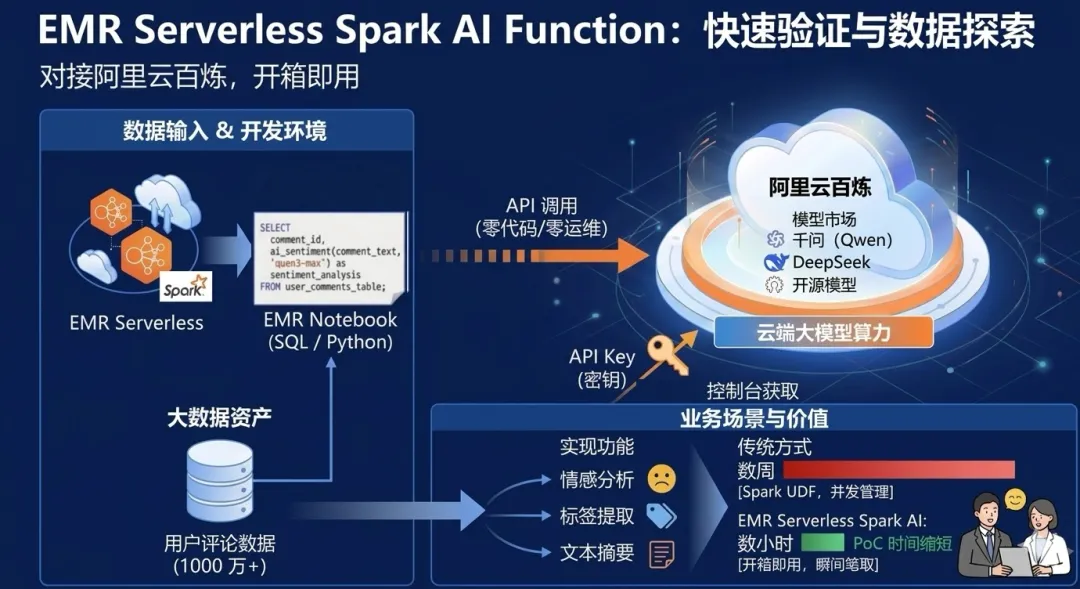
1. 快速验证:对接阿里云百炼,开箱即用
对于希望快速验证业务场景、PoC 验证或进行数据探索的团队,阿里云百炼是最高效的选择。百炼提供了丰富的模型市场,包括千问(Qwen)系列、DeepSeek 等主流开源模型。
在 EMR Serverless Spark 中,您无需关心模型的部署、扩缩容或 API 鉴权细节,只需在百炼控制台获取密钥,即可在 SQL 中直接调用云端大模型。
场景实战:
假设您需要对 1000 万条电商用户评论进行情感分析和标签提取。过去这需要编写复杂的 Spark UDF 并管理并发限制。现在,只需一行 SQL:
plaintext
SELECT
comment_id,
ai_sentiment(comment_text, 'qwen3-max') as sentiment_analysis
FROM user_comments_table;瞬间,大模型化身为您的数据清洗工。这种"零代码、零运维"的体验,让业务分析师也能直接驾驭大模型,将 PoC(概念验证)的时间从数周缩短至数小时。无论是文本摘要、实体抽取还是多轮对话模拟,百炼的强大算力都能通过简单的 SQL 函数触手可及。
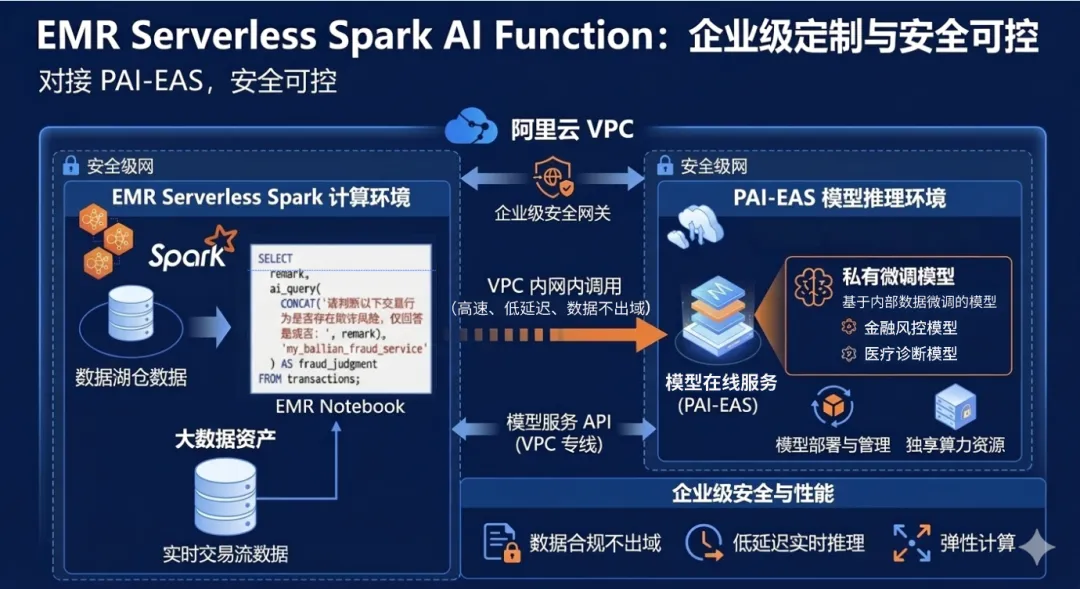
2. 企业级定制:对接 PAI-EAS,安全可控
对于金融、医疗等对数据隐私极其敏感,或拥有自研微调模型的企业,PAI-EAS(模型在线服务)提供了坚实的底座。
您可以将私有模型(如基于内部数据微调的风控模型、医疗诊断模型)部署在 PAI-EAS 上,并通过 VPC 内网与 EMR Serverless Spark 打通。这不仅保证了数据不出域,更利用了阿里云内网的高速低延迟特性,实现了企业级的安全与性能双重保障。
场景实战:
在实时反欺诈场景中,数据隐私与安全至关重要。通过注册 PAI-EAS 服务为外部模型源,EMR Serverless Spark 能够在确保"数据不出域"的前提下,直接于计算流程中调用专属模型,实现便捷、高效的安全风控处理。
plaintext
SELECT
remark,
ai_query(
CONCAT('请判断以下交易行为是否存在欺诈风险,仅回答是或否:', remark),
'my_bailian_fraud_service'
) AS fraud_judgment
FROM transactions;这种架构的特点是:数据无需离开安全的 VPC 环境,直接在湖仓内部完成推理,既满足了严格的合规要求,又享受了 Serverless Spark 弹性计算带来的极致性能。
技术价值分析:为什么选择"SQL 即 AI"?
阿里云 EMR Serverless Spark 将 AI 能力原生融入 SQL 引擎,让"SQL 即 AI"不仅仅是一句口号,而是具备显著落地优势的实战方案:
-
极致性价比:依托 Serverless 架构,按实际计算量和推理调用量付费。在大模型推理这种波峰波谷明显的场景下,相比传统预留资源模式,成本可大幅降低。
-
网络零成本与低延迟:百炼、PAI 与 EMR 同属阿里云生态,内网互通免流量费,且延迟极低。相比之下,跨云或公网调用不仅慢,还会产生高昂的流量账单。
-
全栈中文优化:内置针对中文语境优化的 Prompt 模板和模型参数,更懂中国业务逻辑,尤其在处理中文自然语言任务时表现卓越。
-
安全合规:完全符合国内数据安全法规,提供细粒度的权限控制和审计日志,让企业用得更放心。
展望未来:构建 Data+AI 的无限可能
EMR Serverless Spark 与百炼、PAI 的集成,意味着ETL 不再是数据处理的唯一主角,AI 智能分析正式担当起关键决策者的角色。它并没有取代传统的机器学习流程,而是填补了大规模数据预处理与高阶认知推理之间的空白。
未来,随着多模态模型(图像、视频理解)和 Agent 编排能力的进一步融入,我们有望看到更复杂的场景在 SQL 层面得以实现:例如直接在 SQL 中分析监控视频流中的异常行为,或让 AI Agent 自主规划数据清洗步骤。对于技术团队而言,现在的重点不再是"如何构建一个能调用 AI 的系统",而是"如何利用现有的数据资产,通过最简单的接口,快速验证 AI 带来的业务价值"。
阿里云 EMR Serverless Spark 诚邀您体验这一变革。 无论您是希望通过百炼快速试错,还是通过 PAI 构建企业级 AI 应用,我们都已准备好助您一臂之力。