1、项目介绍与初始化
1.1 项目背景
智能点餐系统是一个基于AI技术的餐厅助手系统,具备以下核心功能:
-
智能菜品推荐与咨询
-
餐厅信息查询服务
-
配送范围检查
-
用户对话交互
1.2 技术栈
-
大模型框架: LangChain
-
AI模型: 通义千问
-
后端框架: FastAPI
-
数据库: MySQL + Pinecone向量数据库
-
地图服务: 高德地图API
-
部署: Uvicorn服务器
1.3 项目结构
这里说一个创建环境的方法,我们之前都是使用anaconda创建虚拟环境,这是sdk层面的隔离.
但这里还有一种成本较低的方法:
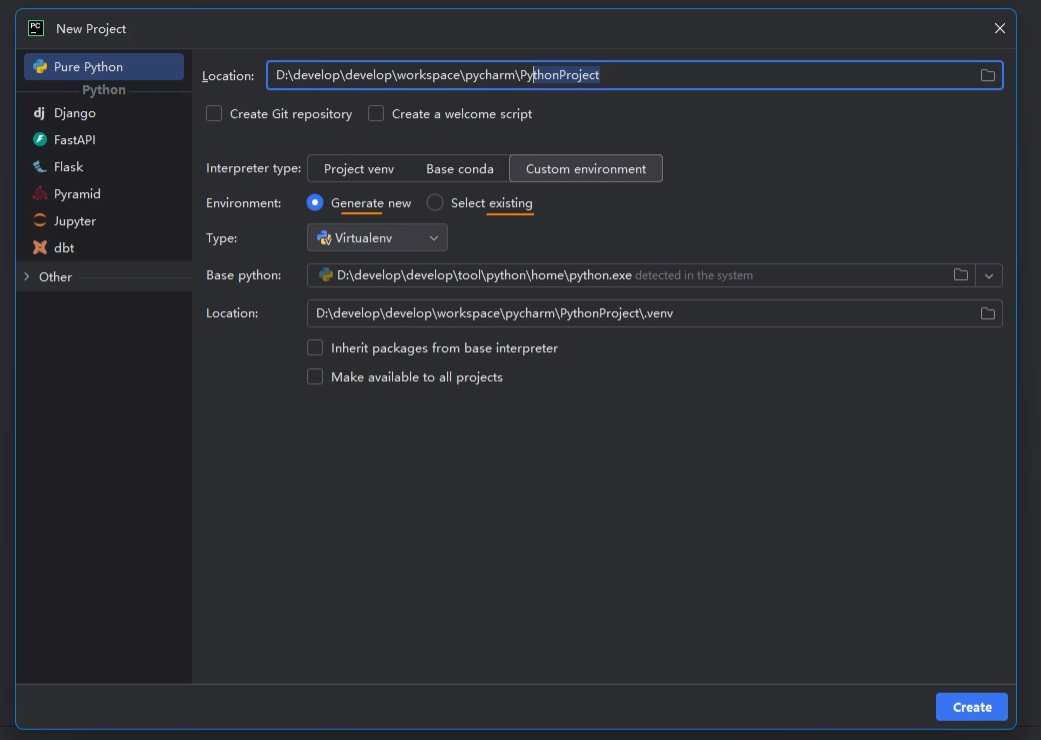
直接custom environment然后generate new这样是把环境建立在项目文件夹之下的.

~=表示该库不会随着版本自动更新,是常用方式之一
创建环境:
python -m venv .venv激活环境:
.\.venv\Scripts\Activate.ps1安装文件中所列举的库:
pip install -r .\requirements.txt需要安装的库:
# ====================== LangChain 大语言模型应用框架 ======================
langchain>=1.0.7
langchain-openai>=1.0.3
langchain-community>=0.4.1
langchain-core>=1.0.7
# ====================== Web 服务框架与服务器 ======================
fastapi>=0.100.0
uvicorn>=0.23.0
# ====================== 数据库驱动 ======================
mysql-connector-python~=9.4.0
# ====================== 向量数据库与云服务 ======================
pinecone~=7.3.0
dashscope>=1.14.0
# ====================== 工具与辅助库 ======================
python-dotenv>=1.0.0
requests>=2.31.0
pydantic~=2.11.72. Python对数据处理中有两种方式的验证
静态检查:(程序员以及编译器)并且不会在运行的时候做约束:类型约束 typing
动态约束:(在程序运行的时候对数据做校验)运行时产生的:动态约束:pydantic库
3.@classmethod
包括:
-
@classmethod的基本含义 -
与普通方法的区别
-
参数
cls的含义 -
调用方式
-
适用场景
-
为什么你的
to_mode代码适合用@classmethod
1. 什么是 @classmethod
@classmethod 是 Python 中的一个装饰器,用来把一个方法定义成类方法。
例如:
class Student:
@classmethod
def show_info(cls):
print("这是一个类方法")这里的 show_info 就不是普通方法,而是类方法。
2. 类方法的核心特点
类方法最重要的特点是:
-
它绑定的是类
-
不是某个具体对象
-
第一个参数通常写成
cls
例如:
class Student:
school = "No.1 School"
@classmethod
def show_school(cls):
print(cls.school)这里的:
cls表示的就是当前类本身,也就是 Student。
3. cls 是什么意思
在类方法中,第一个参数一般写作:
cls它的含义是:
当前这个类本身
例如:
class Student:
school = "No.1 School"
@classmethod
def show_school(cls):
print(cls)
print(cls.school)调用:
Student.show_school()这里的 cls 就相当于:
Student所以:
cls.school实际上就是:
Student.school4. @classmethod 和普通方法的区别
Python 类中常见的方法有两种:
-
普通方法(实例方法)
-
类方法(
@classmethod)
最核心的区别是:
-
普通方法操作的是对象实例
-
类方法操作的是类本身
5. 普通方法是什么
普通方法就是最常见的这种:
class Student:
def say_hello(self):
print("hello")这里的 say_hello 就是普通方法,也叫实例方法。
它的第一个参数一般写成:
selfself 表示:
当前调用这个方法的对象本身
6. 普通方法示例
class Student:
def __init__(self, name):
self.name = name
def introduce(self):
print(f"我是{self.name}")调用:
s = Student("Tom")
s.introduce()输出:
我是Tom这里:
-
s是对象 -
self就代表这个对象s
所以普通方法是和"某个具体对象"绑定的。
7. 类方法示例
class Student:
school = "No.1 School"
@classmethod
def show_school(cls):
print(f"学校是{cls.school}")调用:
Student.show_school()输出:
学校是No.1 School这里 cls 指的就是 Student 这个类。
8. 两者的对比
普通方法
class Student:
def normal_method(self):
print(self)特点:
-
默认第一个参数是
self -
self代表对象 -
需要先创建对象,再调用
调用方式:
s = Student()
s.normal_method()类方法
class Student:
@classmethod
def class_method(cls):
print(cls)特点:
-
默认第一个参数是
cls -
cls代表类 -
不需要创建对象,类就能直接调用
调用方式:
Student.class_method()9. 你可以这样记
普通方法
面向"这个对象"的数据和行为。
比如:
-
学生姓名
-
学生成绩
-
某个订单金额
这些都属于对象自己的属性。
类方法
面向"整个类"的数据和行为。
比如:
-
学校名称
-
配置项
-
工厂方法
-
通用转换规则
这些更偏向类级别,不依赖某一个具体对象。
10. 为什么普通方法用 self
因为实例方法通常要访问对象自己的属性。
例如:
class Dog:
def __init__(self, name):
self.name = name
def bark(self):
print(f"{self.name} 在叫")这里每只狗名字不一样:
d1 = Dog("旺财")
d2 = Dog("小黑")调用:
d1.bark()
d2.bark()输出:
旺财 在叫
小黑 在叫所以普通方法关注的是"每个对象自己的状态"。
11. 为什么类方法用 cls
因为类方法通常要访问类变量,或者做一些和类整体相关的逻辑。
例如:
class Dog:
species = "犬类"
@classmethod
def show_species(cls):
print(cls.species)这里 species 对所有 Dog 对象都一样,所以不需要具体某只狗来调用。
12. 调用方式区别
普通方法
一般通过对象调用:
obj.method()虽然理论上也能写成:
Class.method(obj)但通常不这么写。
类方法
一般通过类调用:
Class.method()当然对象也能调:
obj.class_method()但本质上传进去的还是类,不是对象。
13. 一个对比例子
class User:
platform = "ChatGPT"
def __init__(self, name):
self.name = name
def show_name(self):
print(f"用户名是{self.name}")
@classmethod
def show_platform(cls):
print(f"平台是{cls.platform}")普通方法调用
u = User("Alice")
u.show_name()输出:
用户名是Alice这里访问的是对象属性 self.name。
类方法调用
User.show_platform()输出:
平台是ChatGPT这里访问的是类属性 cls.platform。
14. 使用场景区别
普通方法适合
当方法需要用到实例属性时。
比如:
-
用户介绍自己
-
订单计算总价
-
学生成绩展示
例如:
class Order:
def __init__(self, price, count):
self.price = price
self.count = count
def total_price(self):
return self.price * self.count这里必须用 self.price 和 self.count,所以要用普通方法。
类方法适合
场景 1:访问类变量
class Config:
app_name = "Demo"
@classmethod
def show_app_name(cls):
return cls.app_name场景 2:写工厂方法
这个非常常见:
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
@classmethod
def from_string(cls, text):
name, age = text.split(",")
return cls(name, int(age))调用:
p = Person.from_string("Tom,20")这里类方法相当于提供了另一种创建对象的方式。
15. 为什么你的 to_mode 代码适合 @classmethod
你之前的代码是:
@classmethod
def to_mode(cls, mode_input: PathModeInput) -> PathMode:
if mode_input in cls.MODE_MAPPING:
return cls.MODE_MAPPING[mode_input]
raise ValueError(f"不支持的路径模式: {mode_input},支持的模式: {list(cls.MODE_MAPPING.keys())}")15.1 这段代码在做什么
它的作用是:
-
把用户输入的
"1"、"2"、"3" -
转换成真正的路径模式
"walking"、"bicycling"、"driving"
例如假设类里有:
MODE_MAPPING = {
"1": "walking",
"2": "bicycling",
"3": "driving"
}那么:
RouteConfig.to_mode("1")会返回:
"walking"15.2 为什么这里适合用类方法
因为它依赖的是:
cls.MODE_MAPPING也就是类级别的映射表。
它不需要某个具体对象的属性,所以没必要先创建实例。
直接这样调用就很自然:
RouteConfig.to_mode("1")如果写成普通方法,就要先创建对象:
obj = RouteConfig()
obj.to_mode("1")这样反而显得多余。
15.3 这段代码逐行解释
@classmethod
def to_mode(cls, mode_input: PathModeInput) -> PathMode:意思是:
-
这是一个类方法
-
cls代表当前类 -
mode_input的类型是PathModeInput -
返回值类型是
PathMode
if mode_input in cls.MODE_MAPPING:检查传入的输入值是否在映射表中。
return cls.MODE_MAPPING[mode_input]如果存在,就返回对应的路径模式。
raise ValueError(f"不支持的路径模式: {mode_input},支持的模式: {list(cls.MODE_MAPPING.keys())}")如果输入不合法,就抛出错误,并告诉你支持哪些值。
16. 一句话总结
@classmethod 的本质是:
把方法绑定到类,而不是对象。
所以:
-
普通方法用
self,处理对象自己的数据 -
类方法用
cls,处理类级别的数据和逻辑
如果一个方法主要依赖类变量、配置、映射表,或者需要提供工厂式创建对象的能力,那么就很适合使用 @classmethod。
4.@tool
1. @tool 是什么
@tool 本质上是一个装饰器(decorator) 。 它常见于 LangChain 里,用来把一个普通的 Python 函数,包装成一个 可被大模型调用的工具(Tool)。
也就是说:
-
原来它只是一个普通函数
-
加上
@tool之后 -
大模型或 Agent 就能把它当成"工具"来使用
2. 为什么要用 @tool
在基于大模型的应用里,模型本身只会"生成文字",但很多任务不能只靠文字完成,比如:
-
查天气
-
计算数字
-
查询数据库
-
调用接口
-
获取菜单信息
-
检查配送范围
这时候,就需要把这些真实功能写成函数,再通过 @tool 暴露给模型使用。
所以,@tool 的作用可以简单理解为:
把普通函数注册成"大模型可调用的能力"。
3. 一个最简单的例子
from langchain.tools import tool
@tool
def get_weather(city: str) -> str:
"""查询某个城市的天气"""
return f"{city}今天晴天,25度。"4. 这段代码怎么理解
先看函数本身
def get_weather(city: str) -> str:这说明原本它只是一个普通函数:
-
输入:
city -
输出:字符串
比如你直接在 Python 里调用:
get_weather("北京")它就会返回天气结果。
再看 @tool
@tool这一行写在函数上面,表示:
-
不再只是普通函数
-
而是把这个函数"标记"为一个工具
-
让 Agent / LLM 能识别它、调用它
所以你可以把它理解成:
get_weather = tool(get_weather)装饰器本质上就是这种写法的简化形式。
5. @tool 的核心作用
@tool 主要有下面几个作用。
(1)把函数变成工具对象
普通函数只能由程序员调用。 加上 @tool 之后,LangChain 能把它识别为一个工具。
(2)读取函数签名
例如:
def get_weather(city: str) -> str:LangChain 会知道:
-
这个工具叫
get_weather -
它需要一个参数
city -
参数类型是
str
这有助于模型正确传参。
(3)读取函数说明
函数里的文档字符串很重要,例如:
"""查询某个城市的天气"""模型会根据这段说明判断:
-
这个工具是干什么的
-
什么情况下该调用它
所以写工具时,函数说明一定要清楚。
6. @tool 的工作流程
可以把它理解成下面这套流程:
第一步:你定义函数
@tool
def search_menu(keyword: str) -> str:
"""根据关键词搜索菜单"""
return "找到菜品:鱼香肉丝"第二步:把函数交给 Agent
Agent 知道现在有一个工具叫 search_menu。
第三步:用户提问
比如用户说:
帮我找一下带鱼的菜
第四步:模型判断是否调用工具
模型会想:
-
这个问题不是直接聊天
-
需要查询菜单
-
所以应该调用
search_menu
第五步:执行工具并返回结果
工具真正运行后,把结果返回给模型,再由模型组织成自然语言回复用户。
7. 和普通函数的区别
| 对比项 | 普通函数 | 加了 @tool 的函数 |
|---|---|---|
| 本质 | Python 函数 | 被包装后的工具 |
| 谁来调用 | 程序员手动调用 | Agent / 模型也能调用 |
| 是否有工具描述 | 不一定 | 通常需要清晰描述 |
| 是否用于 Agent 系统 | 一般不能直接用 | 可以直接接入 Agent |
8. 写 @tool 时要注意什么
8.1 文档字符串要写清楚
例如:
@tool
def delivery_check(address: str) -> str:
"""检查某个地址是否在配送范围内"""
...这里的说明越清楚,模型越容易正确使用它。
8.2 参数不要设计得太乱
尽量保持:
-
参数名清楚
-
参数数量不要太多
-
参数类型明确
例如下面就比较清楚:
@tool
def get_price(product_name: str) -> str:
"""查询商品价格"""
...而下面这种就不太好:
@tool
def do_something(a, b, c):
...因为模型很难理解每个参数到底代表什么。
8.3 返回值尽量可读
工具运行后,最终还是要给模型看。 所以返回值最好是:
-
结构清楚
-
含义明确
-
不要太混乱
例如:
return "该地址在配送范围内,预计送达时间25分钟。"就比返回一堆难懂的数据更适合直接对话场景。
9. 一个更贴近实际的例子
比如做一个点餐助手:
from langchain.tools import tool
@tool
def check_delivery(address: str) -> str:
"""检查用户地址是否在配送范围内"""
if "大学城" in address:
return "在配送范围内"
return "不在配送范围内"当用户问:
我在大学城可以送吗?
模型就可能调用:
check_delivery("大学城")然后得到结果:
"在配送范围内"再组织成对用户的回复。
10. @tool 和 @classmethod 的区别
这两个前面都有 @,但作用完全不同。
@tool
作用是:
- 把函数变成给大模型调用的工具
@classmethod
作用是:
-
把方法变成"类方法"
-
第一个参数是
cls -
用来操作类本身,而不是对象实例
所以:
-
@tool是 给 Agent/LLM 系统用的 -
@classmethod是 Python 面向对象语法的一部分
两者不是一类东西。
11. 一句话理解
可以直接记住这句话:
@tool就是把一个普通函数,包装成大模型可以调用的工具。
12. 最后总结
@tool 的重点有四个:
-
它是一个装饰器
-
它把普通函数变成工具
-
它让 Agent/大模型能自动调用这个函数
-
写工具时,函数名、参数、文档说明都要清楚
13. 适合新手的记忆方式
你可以这样记:
-
def:定义一个函数 -
@tool:告诉系统"这个函数不是只给人写代码用的,也可以给模型调用"
所以:
@tool
def xxx(...):
...本质上就是:
把
xxx注册成一个工具。
5.memory组件
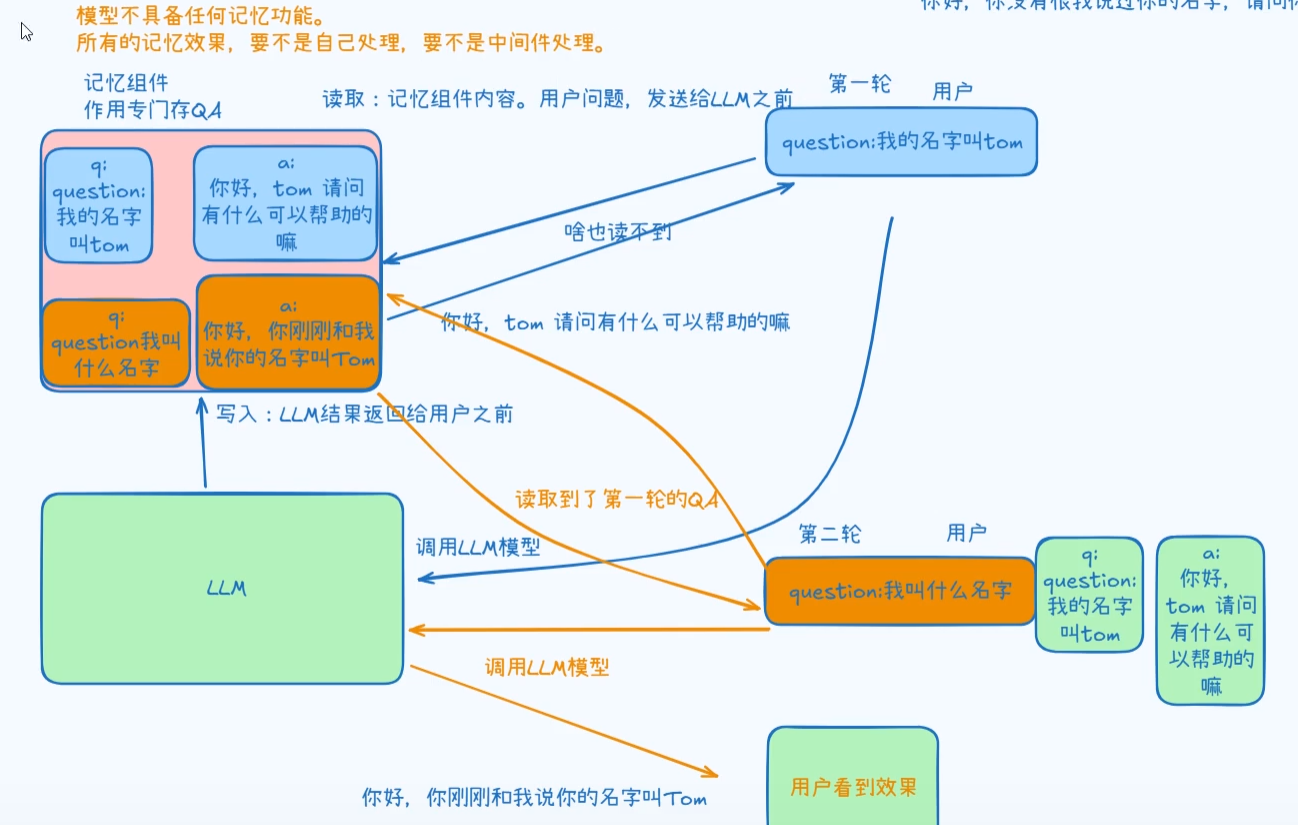
LLM 本身没有记忆能力,所谓"记住用户说过的话",其实是靠外部的记忆组件实现的。
流程分两轮看:
第一轮:
用户说"我的名字叫 Tom"。
系统先把这句话发给 LLM,LLM 回复后,再把这一轮的问答存进记忆组件里。
第二轮:
用户问"我叫什么名字"。
这时系统会先去记忆组件里查找历史,发现第一轮里存过"我的名字叫 Tom",再把这条历史和当前问题一起发给 LLM。
所以 LLM 就能回答:"你刚刚和我说你的名字叫 Tom。"
所以这张图的核心就是:
不是模型自己记住了,而是系统先存历史,再把历史取出来给模型用。
一句话概括:
记忆效果 = 外部存储 + 检索历史 + LLM生成回答。
核心结构:
agent/assistant.py
├── 第26行 _session_store = {} ← 存所有会话历史的字典
├── 第30行 _get_history(session_id) ← 读取历史
├── 第35行 _save_history(...) ← 写入历史
└── 第47行 _build_context_query(...) ← 把历史拼接到当前问题里逐行讲解整个记忆模块的原理:
第一部分:数据结构定义(第24~27行)
_session_store: Dict[str, List[Dict]] = {}
MAX_HISTORY = 10_session_store 是一个普通的 Python 字典,住在内存里。
结构长这样:
{
"sess_abc123": [
{"role": "user", "content": "有什么好吃的?"},
{"role": "assistant", "content": "推荐北京烤鸭..."},
{"role": "user", "content": "它多少钱?"},
{"role": "assistant", "content": "北京烤鸭售价88元..."},
],
"sess_xyz456": [...] # 另一个用户的会话
}MAX_HISTORY = 10 表示每个会话最多保留10轮对话,防止字典无限增长。
第二部分:读取历史(第30~32行)
def _get_history(session_id: str) -> List[Dict]:
return _session_store.get(session_id, [])根据 session_id 去字典里取历史记录,如果没有就返回空列表。第一次对话时必然是空列表。
第三部分:保存历史(第35~44行)
def _save_history(session_id: str, user_msg: str, assistant_msg: str):
if session_id not in _session_store:
_session_store[session_id] = []
history = _session_store[session_id]
history.append({"role": "user", "content": user_msg})
history.append({"role": "assistant", "content": assistant_msg})
if len(history) > MAX_HISTORY * 2:
_session_store[session_id] = history[-(MAX_HISTORY * 2):]每次 AI 回复完之后调用这个函数,把这一轮的用户问题和 AI 回复成对存入列表。
MAX_HISTORY * 2 是因为每轮对话存两条(用户一条、助手一条),10轮 = 20条。超出就用切片 [-20:] 丢掉最旧的,保留最新20条。
第四部分:构造带上下文的问题(第47~56行)
def _build_context_query(query: str, history: List[Dict]) -> str:
if not history:
return query
history_text = "\n".join(
f"{'用户' if h['role'] == 'user' else '助手'}:{h['content']}"
for h in history[-6:] # 最近3轮
)
return f"【历史对话】\n{history_text}\n\n【当前问题】\n{query}"这是记忆发挥作用的核心。
它把历史对话拼成一段文字,附在当前问题前面,一起发给工具(工具再传给大模型)。效果如下:
【历史对话】
用户:有什么好吃的推荐?
助手:推荐北京烤鸭,皮脆肉嫩,售价88元...
【当前问题】
它多少钱?大模型看到这段内容,自然就知道"它"指的是北京烤鸭。本质上是把记忆拼进了 Prompt,不是什么神奇技术。
第五部分:主流程串联(chat_with_assistant)
def chat_with_assistant(query: str, session_id: str = None):
history = _get_history(session_id) # 1. 读历史
tool_name = select_tool(query, history) # 2. 选工具(工具选择也参考历史)
context_query = _build_context_query(...) # 3. 拼上下文
raw = menu_recommendation_tool.invoke(context_query) # 4. 带上下文调工具
_save_history(session_id, query, response) # 5. 存历史整个流程就是:读历史 → 拼进问题 → 调工具 → 存历史,循环往复。
整体数据流图
用户发消息(带 session_id)
↓
读取 _session_store 里的历史
↓
把历史 + 当前问题拼成 context_query
↓
发给工具 → 工具发给大模型
↓
大模型"看到"完整上下文,给出连贯回复
↓
把这轮对话存回 _session_store局限性
| 问题 | 原因 |
|---|---|
| 重启后记忆丢失 | _session_store 是内存变量,进程结束就没了 |
| 多进程不共享 | uvicorn 多 worker 时每个进程有自己的字典 |
| 无法跨设备 | 换浏览器/刷新页面就是新 session_id,从零开始 |
要持久化记忆,需要把 _session_store 换成 Redis 或 MySQL。
6.mcp
1. MCP 是什么
MCP 是 Model Context Protocol ,中文一般叫 模型上下文协议。
它是一套开放标准,用来让 AI 应用统一连接外部系统,比如文件、数据库、搜索、日历、计算器、业务接口等。
你可以先记一句:
MCP 不是某个具体工具,而是一套"让 AI 调工具、读数据、拿上下文"的标准。
2. 为什么会有 MCP
以前如果你想让 AI 连接外部能力,通常要自己写很多"定制对接":
-
这个 AI 接 GitHub,单独写一套
-
那个 AI 接数据库,再写一套
-
换一个客户端,又重写一套
这样会很乱、很碎片化。
MCP 的目标就是把这件事标准化:
服务端按统一协议暴露能力,客户端按统一协议调用能力。
3. MCP 里最核心的两边
MCP Client
客户端,也就是 AI 应用这一边。 比如某个聊天助手、IDE 插件、桌面 AI、Agent 系统。
MCP Server
服务端,也就是把能力暴露出来的一边。 比如:
-
文件系统 server
-
数据库 server
-
GitHub server
-
搜索 server
-
你自己写的餐厅工具 server
客户端连接 server 后,就能发现并调用这些能力。
4. MCP 提供的三类核心能力
1)Resources
给模型或用户看的 上下文和数据。 比如文件内容、数据库记录、配置文件、网页文本。
2)Prompts
可复用的 提示模板 / 工作流模板。 服务器可以提供参数化 prompt,让客户端调用。
3)Tools
可执行的 函数能力。 比如查数据库、调 API、计算、搜索、执行命令。
你现在最需要重点理解的,就是 Tools。
5. 围绕你这段代码,MCP 应该怎么理解
你现在这段代码本质上已经有了 工具雏形:
-
general_inquiry_tool -
menu_recommendation_tool -
delivery_range_tool
它们现在是 LangChain 本地工具:
@tool
def general_inquiry_tool(query: str) -> str:
...@tool 的意思是:
把普通 Python 函数变成 LangChain Agent 可调用的工具。
但这还不是 MCP。 因为它只是 你程序内部注册的工具,不是一个按 MCP 标准对外暴露的工具服务。
所以你可以这样区分:
你现在的代码
本地工具定义
MCP
把这类工具标准化暴露出去的协议层
6. 你这段代码放到 MCP 里,各自对应什么
general_inquiry_tool
这是一个 tool 作用:回答餐厅营业时间、地址、WiFi、停车等常规问题。
menu_recommendation_tool
这也是一个 tool 作用:先检索菜品,再让 LLM 基于结果回答。
delivery_range_tool
还是一个 tool 作用:先抽取地址,再调用地图/配送逻辑判断能不能送。
也就是说:
你已经把"业务能力"写出来了,只差把它们按 MCP 的方式暴露给外部客户端。
7. 你现在的调用逻辑 vs MCP 的调用逻辑
你现在的 LangChain 逻辑
-
用户提问
-
Agent 判断调用哪个工具
-
调用 Python 函数
-
返回结果
比如用户问:
三里屯能送吗?
Agent 可能就调用:
delivery_range_tool(query)MCP 的逻辑
-
AI 客户端连接 MCP server
-
客户端发现有哪些 tool / resource / prompt
-
用户提问
-
AI 选择调用某个 MCP tool
-
MCP server 执行你的逻辑
-
返回结果
所以:
你的函数逻辑没变,变的是"被发现和被调用的方式"。
8. 为什么大家会说 MCP 很重要
因为它解决的是"重复集成"的问题。
以前:
-
每个 AI 应用都要单独接一次工具
-
每个工具都要针对不同 AI 写不同接口
有了 MCP:
-
工具服务按 MCP 暴露一次
-
支持 MCP 的客户端都能接
9. 围绕 MCP,你最该抓住的几个关键词
协议
它是标准,不是单个框架。
连接
它解决 AI 和外部系统怎么接。
上下文
不仅能调工具,还能给模型补充数据和资源。
工具化
把真实业务能力封装成可调用能力。
可复用
写一次,多个客户端都能接。
10. 用你的餐厅项目举一个完整例子
假设你以后把它改成 MCP server。
那么外部 AI 客户端连接进来后,可能会看到:
-
general_inquiry_tool -
menu_recommendation_tool -
delivery_range_tool
用户问:
推荐一个适合两个人吃的辣菜
客户端就可能调用:
menu_recommendation_tool
你的服务端内部仍然做这件事:
-
search_menu_items(query, top_k=5) -
拼接
menu_context -
call_llm(query, prompt) -
返回推荐结果
对外部客户端来说,它不关心你内部细节,只关心:
-
这个工具叫什么
-
参数是什么
-
返回结果是什么
这就是 MCP 的价值。
11. 和 @tool 的关系,最容易混淆的点
很多初学者会把 @tool 和 MCP 混在一起。
你要这样记:
@tool
是 LangChain 的写法。 作用:把函数变成 LangChain 可调用工具。
MCP
是协议。 作用:让这类工具能力可以被 不同 AI 客户端统一发现和调用。
所以:
@tool更像"在本地注册工具" MCP 更像"把工具标准化对外发布"
12. 一句话总结
围绕 MCP,你可以直接记住这句:
MCP 是一套让 AI 统一连接外部数据、提示模板和可执行工具的协议;你现在写的 LangChain
@tool函数,就是很适合被包装成 MCP tools 的业务能力。
7.sessionId
session_id 的原理
本质:一个"名牌"
session_id 就是一个字符串标识符,用来区分"这条消息是谁发的"。
它本身不存任何数据,只是一把钥匙,后端拿这把钥匙去字典里找对应的历史记录。
前端:怎么生成的
// App.vue 第414行
const sessionId = ref('sess_' + Date.now().toString(36) + Math.random().toString(36).slice(2, 6))拆开来看:
'sess_' → 固定前缀,方便识别
Date.now() → 当前时间戳,比如 1711190400000
.toString(36) → 转成36进制字符串,比如 "lkz1c0"(更短)
Math.random() → 随机数,比如 0.847392
.toString(36) → 转成 "0.uqk3z..."
.slice(2, 6) → 取4位,比如 "uqk3"
最终结果: sess_lkz1c0uqk3页面加载时生成一次,之后固定不变。每次发消息都带上这个 ID:
// 发消息时
chatAPI.sendMessage(q, sessionId.value)
// → POST /chat { query: "有啥吃的", session_id: "sess_lkz1c0uqk3" }后端:怎么用这把钥匙
# assistant.py 简化逻辑
_session_store = {
"sess_lkz1c0uqk3": [历史消息列表], # 用户A
"sess_xyz9999abc": [历史消息列表], # 用户B
}
def chat_with_assistant(query, session_id):
history = _session_store.get(session_id, []) # 用 ID 取历史
# ... 处理 ...
_session_store[session_id].append(新消息) # 用 ID 存历史同一个 session_id 每次来,都能取到同一份历史,上下文就连贯了。
生命周期图
打开浏览器
│
▼
生成 session_id = "sess_abc" ← 只生成一次
│
├── 第1条消息 → 带 "sess_abc" → 后端存: {"sess_abc": [问1, 答1]}
│
├── 第2条消息 → 带 "sess_abc" → 后端读到[问1,答1], 存: [问1,答1,问2,答2]
│
├── 第3条消息 → 带 "sess_abc" → 后端读到[问1,答1,问2,答2], AI知道上下文
│
刷新页面
│
▼
生成新 session_id = "sess_xyz" ← 重新生成,历史归零为什么不用用户登录ID?
因为这个项目没有登录系统。用随机生成的 ID 代替,简单够用。
缺点是:
- 刷新页面 → 新 ID → 历史丢失
- 换设备 → 新 ID → 历史丢失
- 后端重启 →
_session_store清空 → 所有历史丢失
8.正则表达式
原代码
match = re.search(r'MENU_IDS:\s*(\[.*?\])', response, re.DOTALL)这句代码的作用
这句代码的作用是:
在
response这段文本里,查找MENU_IDS: [ ... ]这种格式的内容。
例如它要找的内容可能是:
MENU_IDS: ["101", "205"]也可以是:
MENU_IDS:
["101", "205"]甚至是多行写法:
MENU_IDS: [
"101",
"205"
]1. re.search(...) 是什么
re.search() 是 Python 里用来做 正则查找 的函数。
它的作用是:
-
在一整段字符串里
-
查找第一个符合规则的内容
如果找到了,返回一个 匹配对象 match 如果没找到,返回 None
例如:
import re
text = "我的名字叫Tom"
match = re.search("Tom", text)这里就能找到 Tom。
2. 正则规则部分
r'MENU_IDS:\s*(\[.*?\])'这是查找规则。
前面的 r 表示 原始字符串(raw string),方便写正则,不用额外处理反斜杠。
3. 规则拆开讲
MENU_IDS:
表示先匹配固定文本:
MENU_IDS:也就是说,字符串里必须先出现这个标记。
\s*
表示匹配 0 个或多个空白字符。
其中:
-
\s表示空白字符,比如空格、换行、Tab -
*表示前面的内容可以出现任意次,包括 0 次
所以下面这些都能匹配:
MENU_IDS:["101","205"]
MENU_IDS: ["101","205"]
MENU_IDS:
["101","205"](\[.*?\])
这一部分表示:
匹配一个中括号包起来的内容,并把它单独捕获出来。
拆开看:
\[
匹配左中括号 [
.*?
表示任意字符,尽量少匹配,直到遇到右中括号为止。 这里的 ? 表示 非贪婪匹配。
\]
匹配右中括号 ]
外层的 (...)
表示 分组捕获
也就是说,这一段内容后面可以通过:
match.group(1)单独取出来。
例如:
MENU_IDS: ["101", "205"]那么:
match.group(1)得到的是:
["101", "205"]4. response
response表示要在哪个字符串里查找。
例如:
response = '''
推荐您试试宫保鸡丁和鱼香肉丝。
MENU_IDS: ["101", "205"]
'''程序就会在这整段字符串里找符合规则的内容。
5. re.DOTALL
re.DOTALL这个参数表示:
让正则里的
.也能匹配换行符。
默认情况下,. 是不能匹配换行的。 加了 re.DOTALL 之后,就能匹配这种多行写法:
MENU_IDS: [
"101",
"205"
]所以这个参数的作用就是:
支持跨行匹配
[ ... ]里的内容。
6. 匹配成功后 match 里有什么
如果找到了:
MENU_IDS: ["101", "205"]那么 match 就是一个匹配对象。
常见用法有:
match.group(0)
返回整个匹配内容:
MENU_IDS: ["101", "205"]match.group(1)
返回括号里捕获的内容:
["101", "205"]match.start()
返回匹配开始的位置。
7. 一个完整例子
import re
response = '''
推荐您试试宫保鸡丁和鱼香肉丝。
MENU_IDS: ["101", "205"]
'''
match = re.search(r'MENU_IDS:\s*(\[.*?\])', response, re.DOTALL)
print(match.group(0))
print(match.group(1))输出:
MENU_IDS: ["101", "205"]
["101", "205"]8. 为什么用 .*? 而不是 .*
因为:
-
.*是 贪婪匹配,会尽可能多地匹配 -
.*?是 非贪婪匹配,会尽量少匹配
这里我们只想匹配到第一个 ] 为止,所以用 .*? 更安全。
9. 一句话总结
这句代码:
match = re.search(r'MENU_IDS:\s*(\[.*?\])', response, re.DOTALL)本质上是在做三件事:
-
找到
MENU_IDS: -
跳过后面的空格或换行
-
提取后面的
[ ... ]列表内容
10. 最简理解版
你可以直接记:
这句代码就是在回复文本中,找到
MENU_IDS:后面的列表,并把列表单独抓出来。
9.r'MENU_IDS:\s*(\[.*?\])' 讲解
原表达式
r'MENU_IDS:\s*(\[.*?\])'它是什么意思
这个是一个 正则表达式,作用是:
匹配
MENU_IDS:后面跟着的一个中括号列表。
比如它可以匹配:
MENU_IDS: ["101", "205"]拆开看
1. r''
前面的 r 表示:
原始字符串(raw string)
作用是让反斜杠 \ 按原样保留,方便写正则。
例如:
r"\s"表示正则里的空白字符。
2. MENU_IDS:
这部分表示匹配固定文本:
MENU_IDS:也就是说,字符串里要先出现这几个字符。
3. \s*
这一段表示:
0 个或多个空白字符
其中:
-
\s表示空格、换行、Tab 等空白字符 -
*表示前面的内容可以出现任意次,包括 0 次
所以这些都能匹配:
MENU_IDS:["1","2"]
MENU_IDS: ["1","2"]
MENU_IDS:
["1","2"]4. (\[.*?\])
这一段表示:
匹配一个中括号包起来的内容,并把它提取出来
继续拆开:
\[
匹配左中括号 [ 因为 [ 在正则里有特殊含义,所以要写成 \[。
.*?
表示中间的任意内容:
-
.= 任意字符 -
*= 任意多个 -
?= 非贪婪匹配,尽量少匹配
也就是:
从
[开始,匹配到最近的]为止
\]
匹配右中括号 ]
外层的 (...)
表示 分组捕获
也就是后面可以单独取出这部分内容。
例如:
MENU_IDS: ["101", "205"]那么括号捕获到的是:
["101", "205"]整体连起来理解
所以:
r'MENU_IDS:\s*(\[.*?\])'整体意思就是:
先找到
MENU_IDS:,再跳过后面的空格或换行,然后抓取后面的[ ... ]列表。
例子
文本:
response = '推荐菜如下\nMENU_IDS: ["101", "205"]'用这个正则去匹配,就会找到:
-
整体匹配结果:
MENU_IDS: ["101", "205"] -
分组提取结果:
["101", "205"]
一句话记忆
你可以直接记成:
这个正则就是用来找
MENU_IDS:后面的列表。