传统WAM遵循"先想象再执行"的范式------先通过视频扩散模型迭代去噪生成未来画面,再基于这些想象出的画面预测动作。这种设计虽然直观,但测试时延迟极高,动辄几百毫秒甚至数秒。更关键的是,没人能说清楚这种显式未来生成到底对动作预测有多大帮助。论文的核心假设是:WAM的优势可能主要来自训练阶段的视频建模目标,而非测试时的未来生成。
OpenClaw 火到爆,90% 人装不上!2026年4 月 11 日 17:30|叶梓老师免费直播零基础保姆级安装,命令行 / 环境坑一次全解。

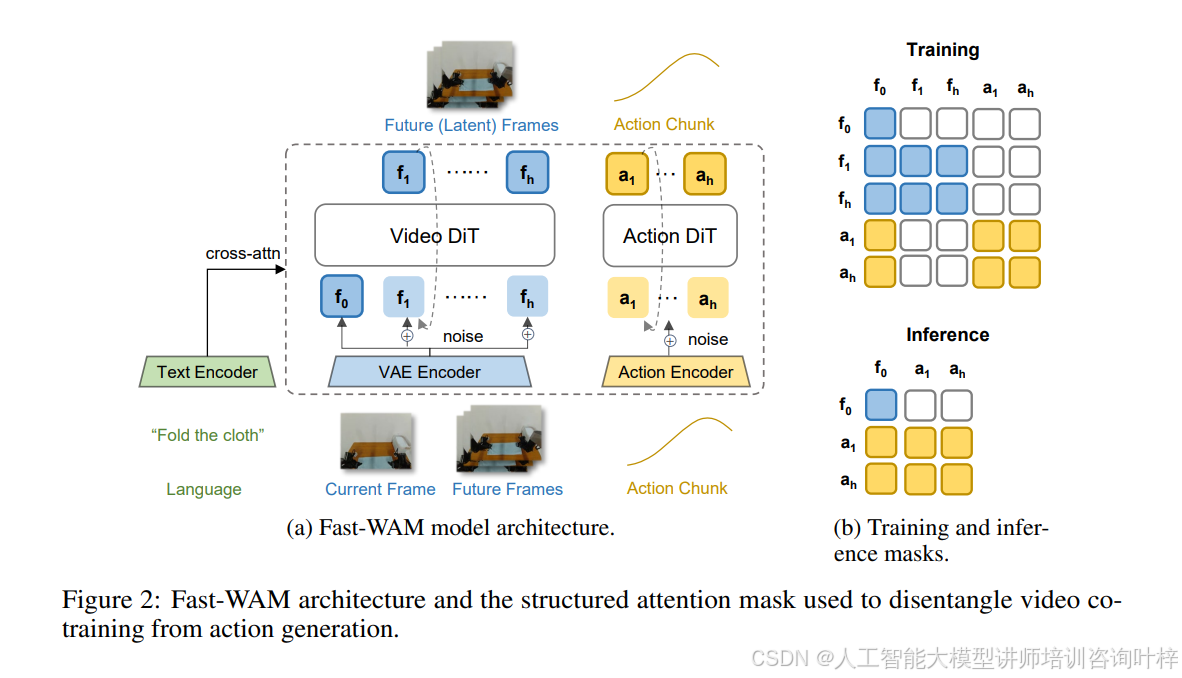
基于这个思路,团队提出了Fast-WAM 。架构上采用混合Transformer(MoT)设计,包含一个视频DiT和一个动作专家DiT,两者共享注意力机制。图2展示了这套架构的训练和推理流程:训练时,当前帧的干净潜变量token、未来帧的噪声token以及动作token分别进入视频DiT和动作DiT,通过结构化的注意力掩码确保动作token只能看到当前观察,不能偷看未来视频信息;推理时则完全砍掉未来视频分支,视频DiT只做一次前向传播提取世界表征,动作专家基于这些表征直接生成动作。
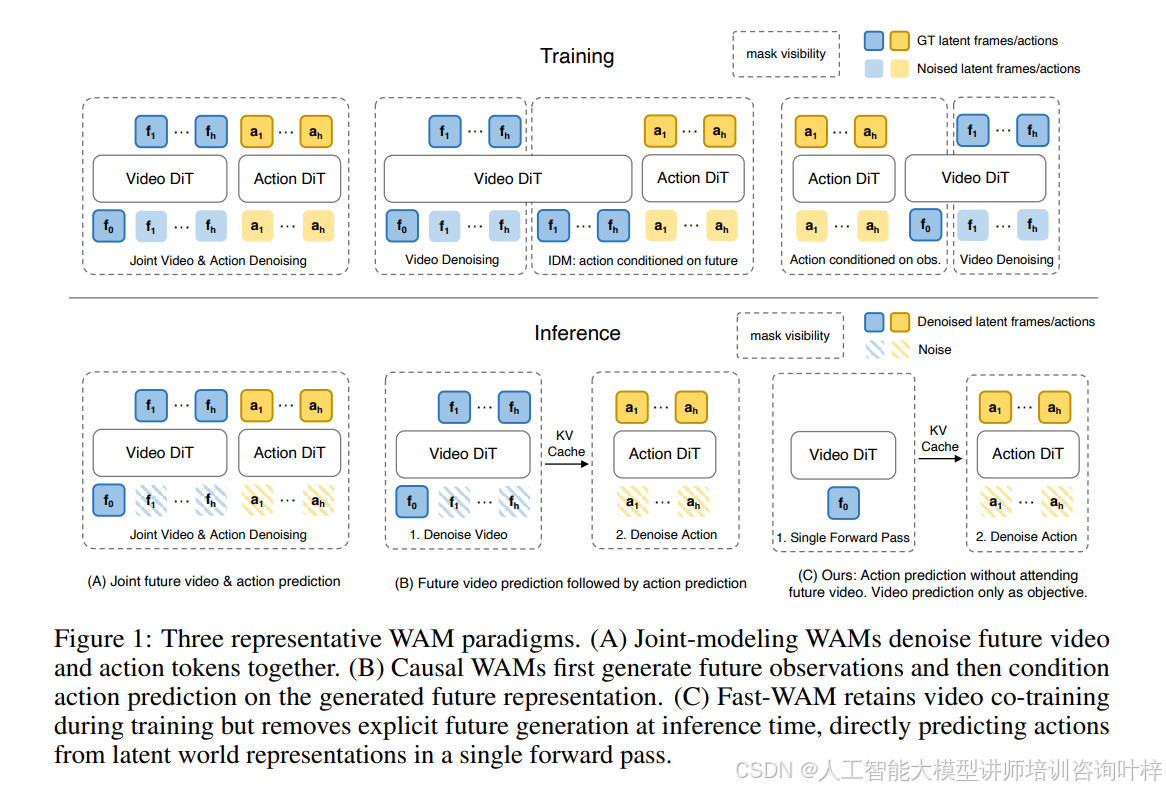
为了严谨验证假设,团队设计了三个对照变体。图1对比了三种代表性范式:(A)联合生成式WAM同时去噪未来视频和动作;(B)因果式WAM先完整生成未来视频再基于其预测动作;(C)Fast-WAM训练时保留视频共训练但推理时跳过未来生成。团队还额外构造了一个去除视频共训练目标的版本,作为检验训练目标本身作用的直接对照。
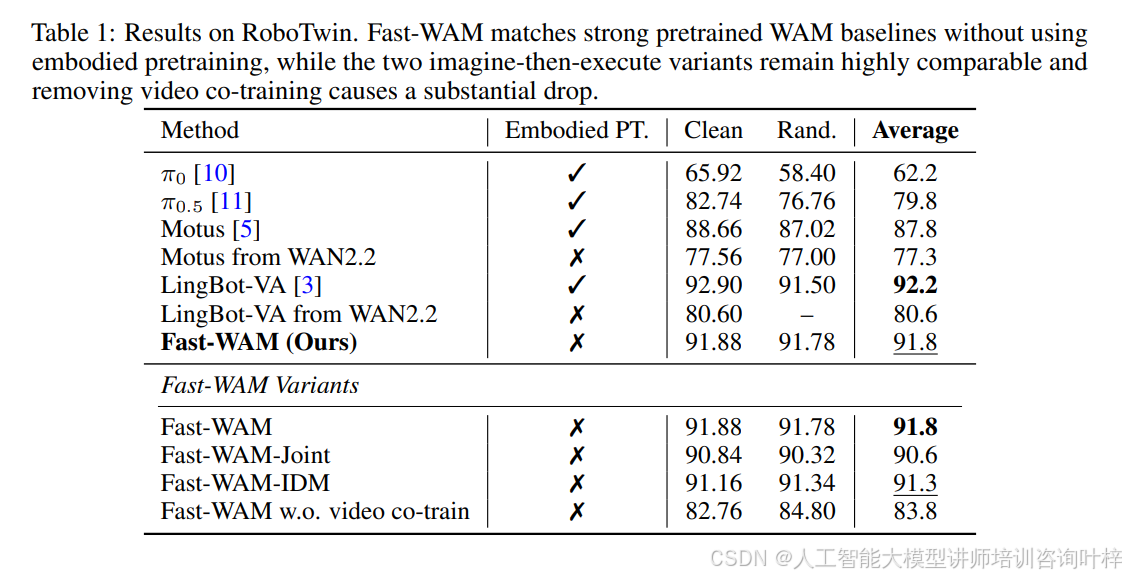
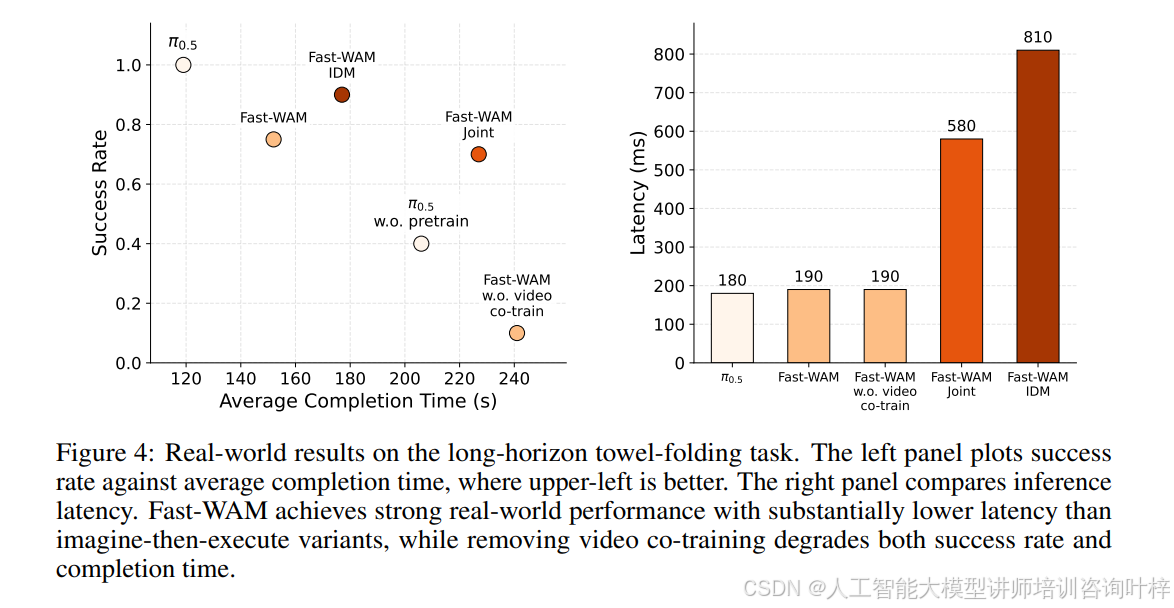
实验结果相当有说服力。在仿真基准测试上,表1 显示Fast-WAM在RoboTwin上达到91.8%的成功率,与联合生成式变体(90.6%)和因果式变体(91.3%)几乎持平,但去除视频共训练后性能骤降至83.8%。表2的LIBERO结果呈现相同模式:Fast-WAM平均成功率97.6%,与两个想象-执行变体(98.5%和98.0%)差距极小,而无视频共训练版本跌至93.5%。
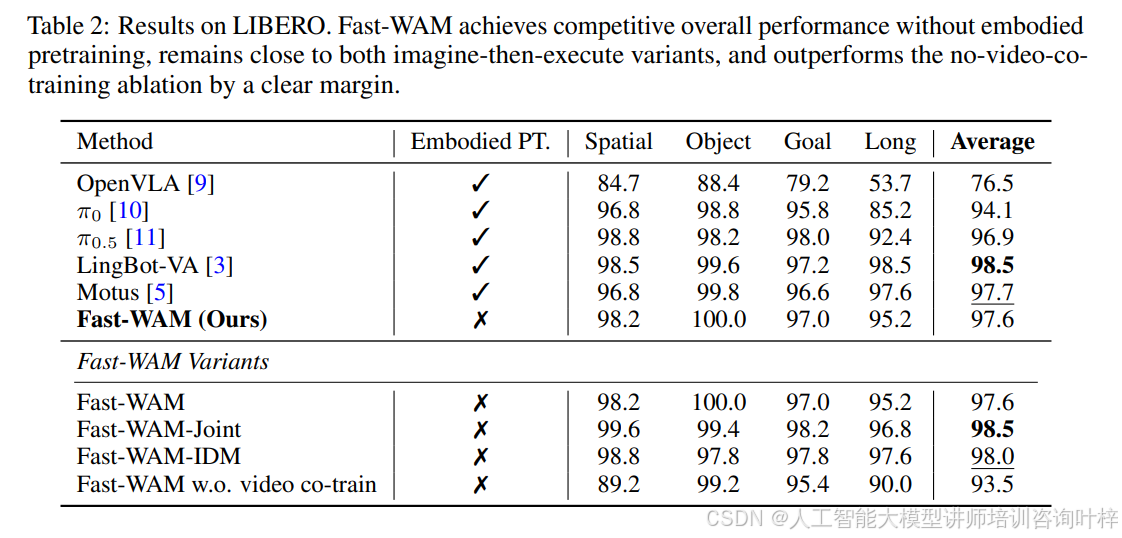
图4的柱状图直观展示了推理延迟对比------Fast-WAM仅需190毫秒,比联合生成式(580毫秒)和因果式(810毫秒)快了4倍以上,与VLA基线π₀.₅(180毫秒)相当。在真实世界的毛巾折叠任务中,Fast-WAM不仅保持了高成功率,完成时间也更短,展现出优秀的闭环控制能力。
这些发现暗示了一个反直觉的结论:WAM中视频预测的主要价值在于训练阶段塑造更好的世界表征,而非测试时显式生成未来画面。换句话说,让模型"学会想象"比让它"真的去想象"更重要。Fast-WAM用单遍前向传播替代迭代去噪,既保留了世界建模带来的表征优势,又实现了实时推理,为具身智能的落地应用提供了更实用的技术路径。