Respond to Change With Constancy: Instruction-Tuning with LLM for Non-I.I.D. Network Traffic Classification
Xinjie Lin, Gang Xiong, Member, IEEE, Gaopeng Gou, Wenqi Dong, Jing Yu, Zhen Li, and Wei Xia
以不变应万变:基于大语言模型指令微调的非独立同分布网络流量分类
林欣杰,熊刚(IEEE 会员),苟高鹏,董文琪,于晶,李振,夏威
X. Lin et al., "Respond to Change With Constancy: Instruction-Tuning With LLM for Non-I.I.D. Network Traffic Classification," in IEEE Transactions on Information Forensics and Security, vol. 20, pp. 5758-5773, 2025, doi: 10.1109/TIFS.2025.3574971.
摘要
加密流量分类在网络安全中极具挑战性,因其需从无内容语义的流量数据中提取鲁棒特征 。现有方法面临两大关键瓶颈:
(i)分布漂移问题 :多数方法基于封闭世界假设,难以适应真实网络中持续演化的流量模式 ;
(ii)对标注数据的高度依赖:在标注稀缺或不可用的场景下,模型泛化能力严重受限。
尽管大语言模型(LLMs)已在众多领域展现出强大的任务泛化能力 ,但其在流量分析中的应用仍受限于难以适配网络流量特有的结构与语义特性。
为此,本文提出一种新型流量表征模型------ETooL (Encrypted Traffic Out-of-Distribution Instruction Tuning with LLM),首次将大语言模型与流量结构知识深度融合 ,通过自监督指令微调 (self-supervised instruction tuning)范式,建立文本语义与流量交互行为之间的映射关系。
实验表明,ETooL 在有监督与零样本 (zero-shot)两类设置下均表现出更强的分类鲁棒性与卓越的泛化能力 。尤为突出的是,其在多个基准数据集上显著提升 F1 分数:
- APP53 (I.I.D.):达 93.19% (↑6.62%)和 92.11%(↑4.19%);
- APP53 (O.O.D.,分布外):提升至 74.88% (↑18.17%)和 72.13%(↑15.15%);
- ISCX-Botnet (O.O.D.):分别达到 95.03% (↑9.16%)和 81.95%(↑12.08%)。
此外,我 重点提炼(供快速阅读):
✅ 核心创新 :提出 ETooL 框架 ,首次实现 LLM 与网络流量结构的指令对齐。
✅ 关键技术 :自监督指令微调 ,无需大量人工标注即可建模流量-文本关联。
✅ 性能突破 :在 分布外 (O.O.D.)场景下 F1 提升高达 18.17% ,显著优于现有方法。
✅ 新基准发布 :构建 NETD 数据集 ,支持动态分布漂移研究。
✅ 实用价值 :兼顾高精度 与高效推理,推动 LLM 在网络安全中的落地应用。
一、引言
作为网络安全与网络管理的一项关键技术,流量分类 旨在识别来自不同应用或网络服务的流量类别 1--6,已被广泛应用于安全攻击检测 、服务质量保障(QoS)等场景,帮助网络内容与服务提供商为用户打造更安全、更高质量的网络体验。
近年来,网络流量的全面加密已逐渐成为现实 ,传统的基于明文特征的显式指纹识别方法正逐步失效。为应对加密流量分析的需求,研究者提出了多种技术路径:
(i)基于统计特征的方法 15, 40:从加密流量中提取统计特征(如包长、时序、方向等),并结合经典机器学习算法进行分类;
(ii)基于原始特征的方法 8, 22:直接利用原始流量特征(如字节序列、流级元数据),通过深度学习模型捕捉复杂模式;
(iii)基于原始数据报(datagram)18--20:采用深度神经网络直接学习数据报字节间的隐式关联,实现端到端分类。
然而,遗憾的是 ,现有大多数加密流量分析方法的有效性均建立在一个关键假设之上:训练与测试流量服从独立同分布 (I.I.D.)。该假设依赖于从训练分布中最小化经验误差的学习范式。
但在实际网络安全场景中,这一假设极为脆弱且不切实际 。网络应用的交互信息与行为模式随时间动态演化------例如,应用程序版本更新 、不同时间段的用户行为差异 9--11 等,都会导致流量分布发生显著变化。其最直观的表现是:现有模型在测试阶段性能急剧下降。
因此,当前研究普遍面临网络流量动态变化所引发的概率分布漂移问题 :即新的特征分布无法被已训练好的分类模型准确映射到原有类别标签上 14, 31。这一挑战严重制约了加密流量分类系统在开放、演化的现实网络环境中的鲁棒性与实用性。
为应对流量分类模型在分布外 (Out-of-Distribution, O.O.D.)条件下性能下降的问题,一种最直观且常用的技术 32, 38, 39 是定期重新训练模型以适应流量变化(如图 1(a) 所示)。
然而,模型更新需收集标注样本并重新训练分类器 ,耗费大量时间与人力。此外,应用程序频繁更新 与对旧分布的遗忘效应,使得在更新成本与性能退化之间难以取得平衡 31--33。
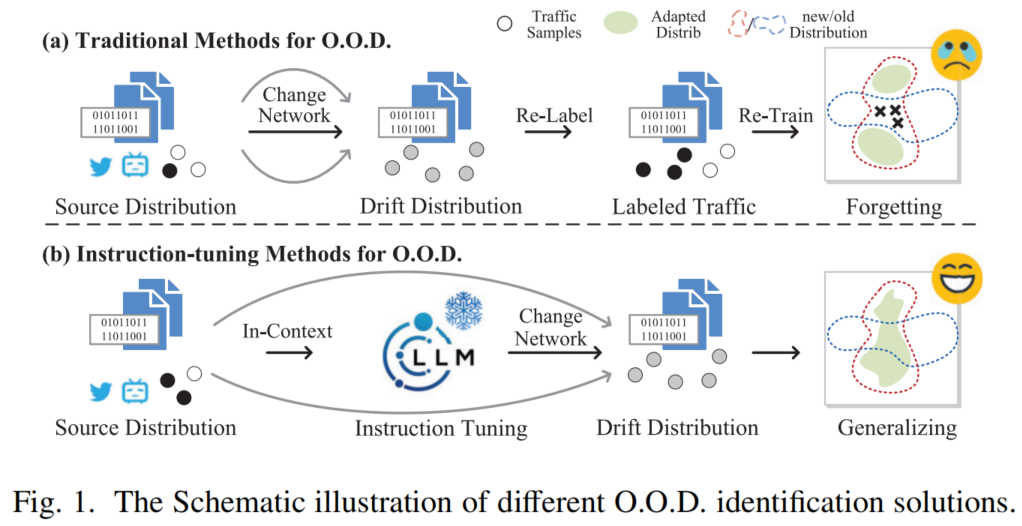
现有方法在处理分布外流量检测时存在两个根本性缺陷:
(1) 特征不稳定性
当前广泛使用的流量特征------无论是从单个数据包还是单条流中提取的、源自包级信息的特征------在分布漂移下稳定性较弱 ,缺乏对流量本质模式的鲁棒表征能力。
(2) 泛化能力不足
现有研究框架通常依赖人工构建的实验环境 或大规模标注数据 来拟合特定分布;而真实网络环境极为复杂:应用层行为高度多样且动态变化 ,传输机制的交互模式持续演进 ,这些因素共同冲击并瓦解了现有实验中的理想化假设,导致模型在现实场景中泛化性能严重受限。
研究表明 39--42,相邻流的时间顺序 与包级突发行为 (packet-level bursts)对流量指纹识别具有显著贡献。此外,同一应用在版本更新后仍保持稳定的突发模式 ,已被证明是构建鲁棒流量表征的关键特征。
与此同时,预训练方法在流量分析领域正日益受到关注。例如,ET-BERT 12 在多项任务中展现出强大的泛化能力,提供了一种可行的流量表征框架,但仍未能彻底解决分布外泛化的核心挑战。
近年来,大语言模型 (LLMs)在多模态等领域不断取得突破。凭借海量知识与无监督学习能力,LLMs 能够获得数据外推 (extrapolation)与场景迁移 (transfer)能力,并在某些任务中涌现出"涌现能力 "(emergent capabilities)21。这种强大的泛化能力可通过指令微调(instruction tuning)------仅需少量标注数据------高效迁移到目标领域(即"领域专用 LLM",Domain-LLM)13, 16, 17。
受此启发,我们提出:将稳定的流量表征与大语言模型相结合,以应对分布外加密流量分类的挑战。
为此,本文提出一种面向分布外 (O.O.D.)场景的新型流量图指令微调模型 ,命名为 ETooL (Encrypted Traffic Out-of-Distribution Instruction Tuning with Large Language Model)。
ETooL 的核心思想是设计流交互表征 ,使 LLM 能够在无需针对新分布重新训练的前提下(见图 1(b)),学习网络流的内在属性。具体而言:
- 首先 ,我们引入流图(flow graph),将流之间的交互特性转化为可学习的图结构;
- 其次 ,通过对比学习(contrastive learning)对齐文本语义与流图结构,使 LLM 能够"理解"流量特征;
- 在指令微调阶段 ,模型通过一项名为 BURST 图匹配 (BURST Graph Matching)的自监督任务作为学习信号,引导 LLM 捕捉底层传输结构(即 BURST 模式),从而增强其对流量上下文关联的建模能力;
- 在第二阶段微调中 ,我们进一步使用面向流量分类的特定指令对 LLM 进行精调,使其更适配加密流量识别任务。
本文主要贡献总结如下:
I. 提出 ETooL 指令微调模型
首次将流量领域的结构化知识 与大语言模型的泛化能力 对齐,专为分布外加密流量分类设计,显著提升 O.O.D. 泛化性能。
II. 创新性设计自监督指令任务
提出 BURST 图匹配 (BURST Graph Matching)这一流级自监督指令微调任务 ,增强 LLM 对流交互机制的理解;同时引入任务定制化指令微调,提升模型对加密流量分类的适应性。
III. 构建首个动态非 I.I.D. 流量数据集 NETD
我们设计并发布了 NETD 数据集 ,专为支持非独立同分布 (Non-I.I.D.)流量分类研究而构建。据我们所知,这是首个面向分布外加密流量研究的动态分布流量基准,为数据驱动的 O.O.D. 研究提供坚实支撑。
IV. 实现 SOTA 性能,泛化能力显著领先
ETooL 在 7 个加密流量分类数据集 上(涵盖 I.I.D. 与 O.O.D. 场景)均取得当前最优性能 ,任务包括:加密应用分类 、恶意服务识别 、分布灵活的流量分类 等。相比现有方法,F1 分数显著提升 :
+6.62%、+4.19%、+18.17%、+15.15%、+9.16%、+12.08% 和 +2.88%。
二、预备知识
A. 问题定义
攻击者可利用加密流量实施旁路攻击 (side-channel attack),以判断受害者是否访问了某一组受监控的应用程序;而防御方则通过对加密流量进行入侵检测分析,识别攻击者是否使用恶意程序渗透受控网络。
本文假设攻击者或防御者无法获取数据包的明文载荷 。在此前提下,我们将加密网络流 定义为:对应于唯一五元组(源 IP、目的 IP、源端口、目的端口、协议)的双向数据包序列。
分布外 (Out-of-Distribution, O.O.D.)的核心目标是:
利用来自已知分布 的流量数据,学习可迁移的流量知识 ,使得当数据分布发生变化时,测试数据与标签之间的映射关系尽可能保持稳定,从而在新分布下提升流量识别任务的准确性。
具体而言,我们将分布外加密流量分类问题形式化如下:
设初始数据域为
D={(x,y)∣x∈X, y∈Y}∼P(x,y), \mathcal{D} = \{(x, y) \mid x \in \mathcal{X},\ y \in \mathcal{Y}\} \sim P(x, y), D={(x,y)∣x∈X, y∈Y}∼P(x,y),
其中X\mathcal{X}X为流量样本空间,Y\mathcal{Y}Y为标签空间。
目标数据域为
D′={(x,y)∣x∈X, y∈Y}∼P′(x,y), \mathcal{D}' = \{(x, y) \mid x \in \mathcal{X},\ y \in \mathcal{Y}\} \sim P'(x, y), D′={(x,y)∣x∈X, y∈Y}∼P′(x,y),
即从与初始域不同的联合概率分布 P′(x,y)P'(x, y)P′(x,y)中采样得到的新分布流量数据。
学习目标是构建一个映射函数fθ:X→Yf_\theta : \mathcal{X} \rightarrow \mathcal{Y}fθ:X→Y,使其在流量数据的边缘分布发生偏移 (即P(X)≠P′(X)P(X) \neq P'(X)P(X)=P′(X))时,仍能保持条件分布不变,从而维持标签预测的准确性:
P′(Y∣X)=P(Y∣X),当P(X)≠P′(X).(1) P'(Y \mid X) = P(Y \mid X), \quad \text{当} \quad P(X) \neq P'(X). \tag{1} P′(Y∣X)=P(Y∣X),当P(X)=P′(X).(1)
换言之,尽管流量的输入分布发生变化 (如因应用更新、网络环境改变等),但给定流量特征下的类别语义应保持一致。模型需具备在此类分布偏移下仍能准确分类的能力。
强调 O.O.D. 问题的本质:输入分布变,但语义映射不变。
B. 现有数据集调研
数据集是当代流量分类研究中不可或缺的核心组成部分,其在推动该领域取得巨大进展方面发挥了关键作用。它们不仅为模型训练提供了可靠的数据来源,也为不同方法的性能评估与横向比较提供了相对公平的基准。
然而,由于应用场景的多样性以及网络协议的持续演进,新的流量数据集不断被发布以满足不同的研究目标。但绝大多数现有数据集仍基于独立同分布 (I.I.D.):即训练集与测试集中的样本应相互独立且服从同一分布。
事实上,在真实场景中,我们无法预知或控制测试数据的分布 ,因此 I.I.D. 假设永远无法严格成立 25。这意味着,仅在训练数据上最小化经验误差,并不能保证模型在测试数据上表现良好。
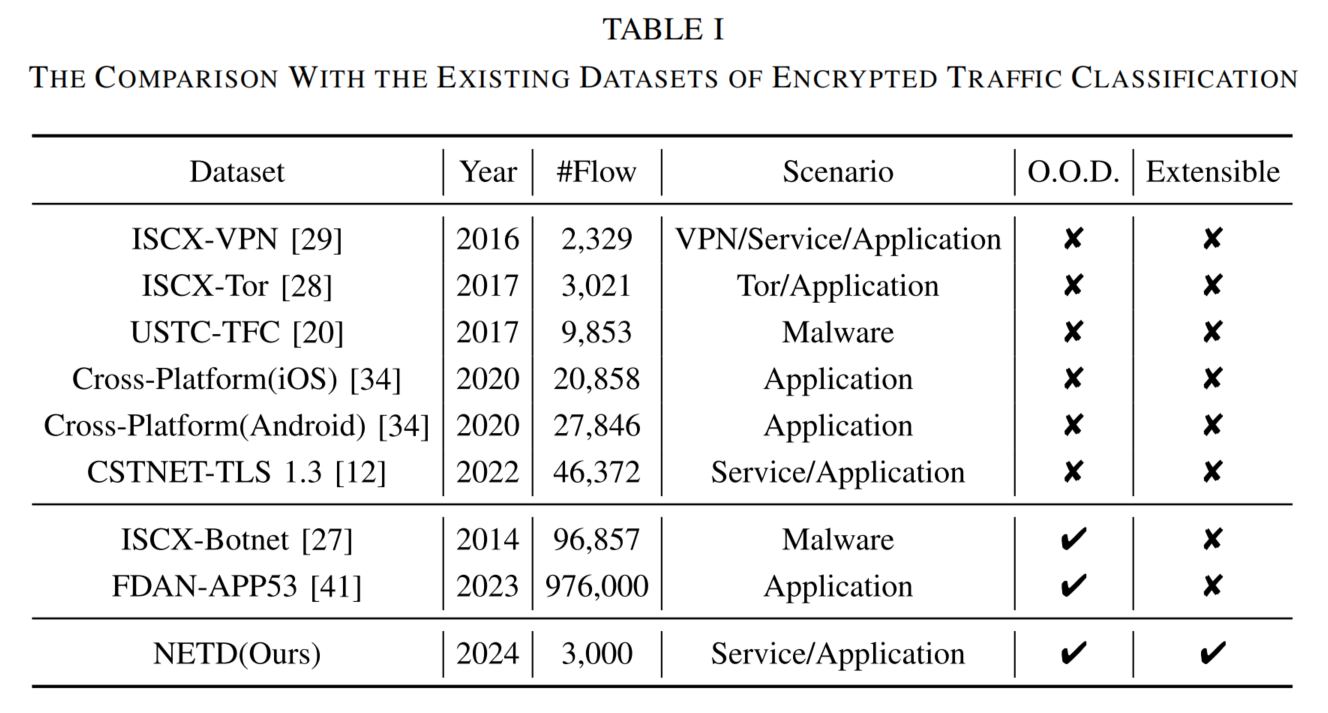
表 I 列举了若干具有代表性的流量数据集,涵盖虚拟专用网(VPN)、恶意软件(malware)、移动服务等多种研究场景。然而,这些数据集大多在采集时未充分考虑测试场景中普遍存在的非独立同分布(Non-I.I.D.)。仅有少数数据集显式地引入了分布变化因素。例如:
- ISCX-Botnet 数据集通过在训练集与测试集中使用不同类型和规模的恶意/良性流量,人为构建了分布差异;
- FDAN-APP53 (简称 APP53)则同时考虑时间因素 与设备因素,以模拟现实环境中因应用程序版本更新所引发的分布偏移。
然而,真实网络中导致分布偏移的因素极为复杂------包括应用行为演化、用户习惯变化、网络拓扑调整等------要全面覆盖并捕获这些因素,往往需要大量人力与长时间的数据采集 。例如,若要建模时间维度上的分布漂移,就必须在多个不同时段持续收集流量数据,成本高昂。
针对上述挑战,本文提出 NETD (Non-I.I.D. Encrypted Traffic Dataset)------一个面向分布外场景的加密流量数据集。NETD 具备以下优势:
- 支持动态调节分布偏移程度;
- 低成本、高效率、易使用;
- 可复用现有公开数据集进行构建。
尤为关键的是,此前尚无任何流量数据集支持对流量分布偏差程度进行可控调节 ,而 NETD 首次实现了对不同程度 O.O.D. 流量的可控建模。具体构建方法详见第 VIII-A 节。
逻辑清晰:从"数据集重要性" → "I.I.D. 假设局限" → "现有数据集不足" → "NETD 创新点"层层递进;
C. 动机分析
大语言模型(LLMs)在涉及丰富语义与自然语言理解的任务中已展现出卓越性能,充分体现了其强大的泛化能力。针对加密网络流量分类这一看似缺乏语义信息的任务,我们仍认为引入 LLM 技术具有充分依据,主要基于以下四点考量:
(1) LLM 应用于加密流量分类的可行性
尽管加密流量本身不包含明文语义,但将 LLM 引入加密流量分析的研究正迅速兴起。多项工作 12, 13 已证实:基于预训练架构的 LLM 能显著提升流量分类任务的泛化能力 。通过将流量特征转化为序列化格式(如时间序列或字节序列),可自然地与 LLM 的输入范式对齐,从而有效增强模型对未知分布的适应性。
(2) 结构化流量图表示的有效性
研究表明,基于图结构的流量表示能够有效捕获流间稳定的交互模式 41。为更进一步应对流量数据中的分布偏移挑战 ,我们提出将流量图 (traffic graph)作为 LLM 微调的输入表征。实验验证:在分布偏移条件下,引入图结构表征可带来显著且可量化的性能提升。
(3) LLM 从结构化数据中学习的可行性
虽然 LLM 最初为文本设计,但近期研究 49 已证明其具备跨模态泛化能力 ,可有效处理表格、图、时序等非文本结构化数据 。这一发现启发我们探索将 LLM 与网络流量的图结构表征相结合 ,旨在将其强大的迁移学习与泛化能力拓展至非语言领域。
(4) LLM 架构的独特优势
我们对比了基于流量序列表示的 LLM 方法 12, 24 与传统人工智能技术。值得注意的是,现有大多数方法并未显式解决分布偏移问题 ;而部分 O.O.D. 检测方案 31 甚至需提前获取未知类别的流量样本 ,这违背了真实分布外检测的严格设定(即测试分布完全不可见)。相比之下,LLM 架构天然支持零样本学习(zero-shot learning),使其成为应对开放世界、动态网络环境的理想选择。
综上,LLM 在泛化能力 、结构适应性 与开放场景鲁棒性方面的综合优势,构成了本文提出 ETooL 框架的核心动因。
三、相关工作
本节综述已提出的加密流量分类方法,涵盖基于统计特征的方法 、基于深度学习的方法 ,以及预训练与指令微调 (instruction tuning)技术。需要指出的是,以深度包检测(Deep Packet Inspection, DPI)为代表的明文指纹构造方法因依赖未加密载荷,在全面加密背景下已不再适用,故本文不予讨论。
A. 加密流量分类
1) 统计方法
为高效分析复杂流量,多数加密流量研究采用与加密无关的统计特征 。例如,CUMUL 15 通过精度评估筛选出104维统计特征,并将其作为支持向量机(SVM)的输入以识别网站流量;AppScanner 40 则利用数据包大小的统计特征训练随机森林分类器。
尽管结合统计特征的机器学习方法能够处理复杂流量,但其性能高度依赖专家手工设计的特征,难以构建通用性强、可适应海量且持续演化的应用与网站的统计表征 36。
2) 深度学习模型
近年来,结合原始特征或原始数据报的监督式深度学习方法成为主流,旨在自动提取判别性特征,摆脱人工设计依赖。
- FS-Net 22 利用循环神经网络(RNN)从加密流量的原始包长序列中自动学习表征;
- Deeppacket 19 与 TSCRNN 18 则直接对原始载荷(payload)进行建模;
- Traffic Interaction Graph 7 将流间交互建模为图结构,基于图表示学习流关联关系,显著提升了流量识别能力。
然而,此类方法通常依赖大量标注数据 以捕获有效特征,导致在有限数据范围内学习到有偏的表征,泛化能力受限。
7 M. Shen, J. Zhang, L. Zhu, K. Xu, and X. Du, "Accurate decentralized application identification via encrypted traffic analysis using graph neural networks," IEEE Trans. Inf. Forensics Security , vol. 16, pp. 2367--2380, 2021.
18 K. Lin, X. Xu, and H. Gao, "TSCRNN: A novel classification scheme of encrypted traffic based on flow spatiotemporal features for efficient management of IIoT," Comput. Netw. , vol. 190, May 2021, Art. no. 107974.
19 M. Lotfollahi, M. J. Siavoshani, R. S. H. Zade, and M. Saberian, "Deep packet: A novel approach for encrypted traffic classification using deep learning," Soft Comput. , vol. 24, no. 3, pp. 1999--2012, Feb. 2020.
22 C. Liu, L. He, G. Xiong, Z. Cao, and Z. Li, "FS-Net: A flow sequence network for encrypted traffic classification," in Proc. IEEE Conf. Comput. Commun. (INFOCOM), Paris, France, Jul. 2019, pp. 1171--1179.
B. 预训练与指令微调
预训练技术通过自监督学习从海量无标签数据中学习无偏的数据表示,不仅大幅降低对标注数据的依赖,还能显著提升下游任务性能。在加密流量分类领域,预训练模型正作为新兴架构被引入以增强泛化能力:
- PERT 24 将 ALBERT 迁移至加密流量分类,在 VPN 场景中取得性能提升;
- ET-BERT 12 设计了更适配流量数据报的预训练任务,在多任务流量分类中表现优异,验证了预训练模型在该领域的强大泛化潜力;
- MT-FlowFormer 46 与 Flow-MAE 47 则从"视觉视角"出发,利用预训练模型捕捉流间相关性,提升流识别性能。
尽管如此,现有预训练研究普遍未考虑非独立同分布(Non-I.I.D.),因而未能真正解决开放动态网络环境下的核心挑战。
24 H. Y. He, Z. Guo Yang, and X. N. Chen, "PERT: Payload encoding representation from transformer for encrypted traffic classification," in Proc. ITU Kaleidoscope, Ind.-Driven Digit. Transformation (ITU K) , Ha Noi, Vietnam, Dec. 2020, pp. 1--8.
12 X. Lin, G. Xiong, and G. Gou, "ET-BERT: A contextualized datagram representation with pre-training transformers for encrypted traffic classification," in Proc. ACM Web Conf. , Lyon, France, F. Laforest, R. Troncy, E. Simperl, D. Agarwal, A. Gionis, and I. Herman, Eds., 2022, pp. 633--642.
46 R. Zhao, X. Deng, Z. Yan, J. Ma, Z. Xue, and Y. Wang, "MTFlowFormer: A semi-supervised flow transformer for encrypted traffic classification," in Proc. 28th ACM SIGKDD Conf. Knowl. Discov. Data Min. , A. Zhang and H. Rangwala, Eds., Aug. 2022, pp. 2576--2584.
47 Z. Hang, Y. Lu, Y. Wang, and Y. Xie, "Flow-MAE: Leveraging masked AutoEncoder for accurate, efficient and robust malicious traffic classification," in Proc. 26th Int. Symp. Res. Attacks, Intrusions Defenses, Hong Kong, Oct. 2023, pp. 297--314.
另一方面,提示学习 (Prompting)37 通过任务特定的提示(prompt)引导预训练模型,显著减少对微调或大量标注数据的需求。近期,提示学习已在自然语言处理、计算机视觉及网络服务优化等任务中展现出强大的广义迁移能力 43, 45。 指令微调范式进一步融合预训练、微调与提示学习,通过少量甚至零样本即可实现高效任务适配,显著增强迁移学习中的泛化能力 26, 48。
然而,在加密流量分类领域,指令微调的研究仍近乎空白 。 为此,本文提出一种融合领域知识的通用流量表征方法 ,充分考虑流量模态的独特性,并设计两项面向流量的指令微调任务 ,以确保流量表征具备强大的广义迁移能力,尤其面向 Non-I.I.D. 与 O.O.D. 场景。
四、ETooL 概览
本节介绍 ETooL 的设计思路。传统加密流量分析通常聚焦于从单一数据流中提取多维特征 ,并在独立同分布(I.I.D.)假设下分析流模式。然而,这一假设在真实场景中往往脆弱且不现实:单一数据流的模式更容易因分布偏移而性能下降 ,而多流交互模式则更具鲁棒性。
为此,本文目标是学习加密流量的通用交互关联模式 ,并在不同分布变化场景下实现更优的流量分类。我们提出 ETooL ------一种基于通用预训练大模型 的分布外加密流量分类框架,旨在解决网络领域中加密流量的分布外识别难题。
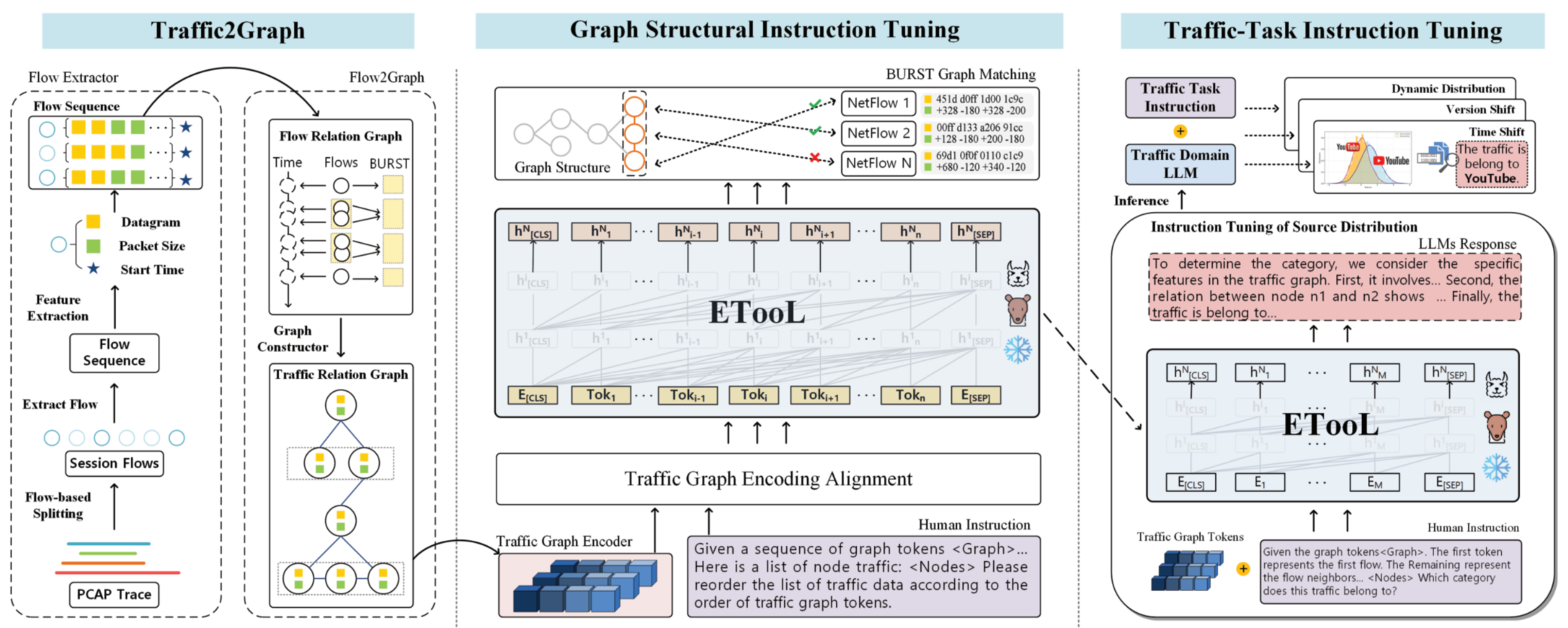
如图 2 所示,ETooL 框架包含两阶段微调 与三大核心组件:
- 流量交互图结构表示(Traffic2Graph);
- 图结构指令微调(Graph Structural Instruction Tuning);
- 流量任务指令微调(Traffic-Task Instruction Tuning)。
1. 流量交互图结构表示(Traffic2Graph)
受 FRG 特征 41 在应对模糊流量与概念漂移方面能力的启发,我们提出:利用多粒度特征的流间交互作为构建流量表征的通用模式。
41 M. Jiang et al., "Accurate mobile-app fingerprinting using flow-level relationship with graph neural networks," Comput. Netw., vol. 217, Nov. 2022, Art. no. 109309.
网络流量关系图(TRG)基于不同流之间的关联拓扑构建,图中包含多粒度的流量特征。具体而言:
- 节点 :表示相邻时间窗口内的多个网络流,每个节点包含原始数据报序列 (Raw Datagram, RD)与包长序列(Packet Length, PL);
- 边 :表示不同流之间的关联关系,包括邻接边 (adjacency edges)与突发边(burst edges),分别刻画流间的时序交互与突发模式关联。
2. 图结构指令微调(Graph Structural Instruction Tuning)
本阶段提出两个核心模块:
- 流量-图对齐模块:将流量特征与拓扑关系图在编码空间中对齐;
- 流量-图结构指令微调范式:帮助大语言模型(LLM)捕捉并学习流间关联,解决现有 LLM 难以理解流量特征信息与图结构的痛点。
具体而言,基于对齐后的表示,我们设计包含流量特征信息的自然语言指令数据 ,通过自监督微调引导模型更好理解流量图结构知识。
3. 流量任务指令微调(Traffic-Task Instruction Tuning)
为使大语言模型适应分布外流量识别任务,本阶段提出流量任务指令微调模块:基于 LLM 已学习的流量领域结构知识,设计面向流量分类的指令数据。
通过构建关联图(correlation graph)表示多流交互特性,并结合预训练模型的自监督学习能力,我们实现:
- 网络交互与上下文关联的学习;
- 在分布外流量任务下的泛化识别能力。
✅ 结构化流量表征 :首次将多流交互建模为图结构(TRG),融合原始数据报、包长序列 与突发边关联 ,增强分布偏移下的鲁棒性。
✅ 双阶段指令微调 : 第一阶段 :通过自监督图结构对齐 ,解决 LLM 对流量特征与图结构的理解难题; 第二阶段 :基于领域知识设计任务专用指令 ,提升模型在分布外场景下的适应性。
✅ 分布外泛化能力 :结合图结构与指令微调,实现对未知分布流量的高效识别,突破传统 I.I.D. 假设限制。
五、Traffic2Graph
在真实网络中,为提升应用响应速度与用户体验,多个网络流常在短时间内并发建立 。这种现象可通过被动流量捕获观察到:多个通信流同时创建并传输消息。该现象被称为 BURST(突发),是近年来流量特征挖掘与表征中的核心概念。具体而言:
- 包级 BURST:指一系列连续数据包,其到达时间间隔小于一个较小的时间阈值;
- 流级 BURST :指在短时间窗口内建立的多个网络流,用于刻画流间的协作关系。
研究表明,此类流量结构对加密流量分析极为有效。 其中,包级 BURST 反映了服务于同一资源请求/响应的多个数据包的时序特性; 而 流级 BURST 则揭示了多个流协同完成同一网络功能的交互模式。
为更深入地捕捉原始流量中流之间的交互关系,我们提出 Traffic2Graph 模块 ,旨在构建一种具有判别性且通用的流量表征 ,能够反映不同 Web 应用在流级 BURST 特征上的差异性。
该模块包含两个核心流程:
(1) 流提取器 (Flow Extractor):从每个输入网络流中提取数据报(datagram)与包长信息,融合多维流特征;
(2) 流到图转换(Flow2Graph):根据时序与连接关系,将融合特征的流构建成图结构,以更有效地表征 BURST 中的流间关联。
值得注意的是,尽管 Web 应用开发者常实现相似功能,但因业务模型理解与开发实践的差异,会在网络流量层面呈现出截然不同的流协作模式 。因此,本节聚焦于流间交互的两类关键关系:邻接关系 (adjacency)与突发关系(bursting):
- 邻接关系 :描述相邻网络流之间的连接性,在本文中被扩展为相邻 BURST 结构之间的贯通连接;
- 突发关系 :指同一 BURST 结构内部并发流之间的连接。
这两种多维关联共同刻画了网络流之间的时序依赖 与序列协作,支撑网络服务功能的实现。
A. 流提取器(Flow Extractor)
多维流量信息的融合有助于适应更广泛的流量识别任务。我们重点关注两类广泛使用且有效的特征:数据报(datagram)。
特别地,为适配指令微调阶段的流数据输入,我们参考 CETP 30 对大语言模型(LLM)的词元表示(token representation)进行扩展:
(1) 数据报序列 (Sequence of Datagrams)
从每个数据报中提取前 128 字节,构建富含信息的流量表征单元,以在预训练阶段获取更丰富的上下文信息。
具体地,将原始流量数据报中的十六进制字节序列按双字节切分 ,编码为字节对序列。每个单元的取值范围为 0--65535。
例如,
{ee08bf56...}被表示为{ee08, bf56, ...}。
(2) 有向包长序列 (Directed Packet Size Sequence)包长序列的构建沿用传统流统计表征方法,但在提取包大小的同时保留通信方向信息:
+表示客户端 → 服务器的数据包;-表示服务器 → 客户端的返回包。
例如,一个双向流的有向包长序列为:{+128, -74, -1020, +378, ...}。
B. 流到图转换(Flow2Graph)
设某客户端在特定时间段内使用某一 Web 应用所产生的所有网络流集合为SSS,我们为其构建一个图结构。
利用图数据结构能表达丰富节点信息及非连通节点间关系 的优势,我们采用流量关系图 (Traffic Relation Graph, TRG)来建模流间的邻接 与突发 关系。具体构建过程见 Algorithm 1。
基于流在时间维度上的邻接与突发边关系,以及各流的特征信息,TRG 的节点与边定义如下:
(1) 节点集合VVV :每个网络流对应 TRG 中的一个节点。每个节点包含多维流特征:
- 数据报序列
- 有向包长序列
- 包消息类型序列
- 包时间间隔序列等
由于网络流的起始时间戳动态可变,我们主要关注有向包长序列 与数据报序列作为核心特征。
(2) 边集合EEE :TRG 包含两类关联边:
-
邻接边 (Adjacency Edge):连接不同 BURST 结构之间的流 。 首先,根据流级 BURST 划分规则(见下文),将流集SSS分割为若干 BURST 结构; 然后,将前一个 BURST 的最后一个流 ,连接至下一个 BURST 的第一个和最后一个流,形成跨 BURST 的邻接关系。
-
突发边 (Burst Edge):连接同一 BURST 结构内的并发流 。 流级 BURST 的划分依据为:若两个网络流的起始时间戳之差小于预设时间邻域阈值γ\gammaγ,则视为属于同一 BURST。
✅ BURST 双层级建模 :同时利用包级 与流级 BURST,全面刻画流量时序与协作特性;
✅ 多粒度图结构 :节点融合原始数据报+有向包长 ,边区分邻接 与突发 ,精准表达流间复杂关系;
✅ 方向感知特征 :包长序列保留通信方向,增强语义判别力;
✅ 可扩展表征:数据报双字节编码适配 LLM 词元空间,为后续指令微调奠定基础。
六、图结构指令微调
为增强大语言模型(LLM)对流量图结构信息 的理解能力,ETooL 将流量图结构编码 与自然语言语义空间 进行对齐。该对齐旨在使语言模型能够利用其固有的语言理解能力,有效解析流量特征及其贯通连接关系。
为此,我们设计了一个流量图编码对齐模块 (Flow Graph Encoding Alignment Module),其目标是在大语言模型的指令微调过程中保留流量图的结构上下文信息 ,从而将流量语义理解 与图拓扑结构关系有效关联。
A. 流量图编码对齐
受跨模态对齐研究(如 CLIP)的启发,我们将流量特征以对比学习 (contrastive learning)的形式融入图结构编码过程,实现流量图结构 与流量信息表征的对齐与融合。
具体而言,我们在 ETooL 框架中集成一个带有预训练参数的图神经网络编码器 ,并通过对比学习方法,使其输出的图表示 与流表示相互对应。
设流量图表示为G(V,E,A,X)G(V, E, A, X)G(V,E,A,X),其中:
- VVV:节点集合(每个节点对应一个网络流);
- EEE:边集合;
- AAA:图邻接矩阵;
- XXX:节点特征。
第nnn个节点对应的流量特征信息表示为
C={ci∈Rli×d∣1≤i≤N}, C = \{ c_i \in \mathbb{R}^{l_i \times d} \mid 1 \leq i \leq N \}, C={ci∈Rli×d∣1≤i≤N},
其中lil_ili表示第iii个节点的输入长度,NNN为节点总数,ddd为特征维度。
通过任意图表示编码器fgf_gfg(例如 Graph Transformer)和流表示编码器fnf_nfn(例如 ET-BERT),可分别获得图结构编码与流特征编码:
H=fg(G),N=fn(C)(2) H = f_g(G), \quad N = f_n(C) \tag{2} H=fg(G),N=fn(C)(2)
其中:
- HHH:由图神经网络生成的结构级图编码表示;
- NNN:与节点关联的流特征编码表示。
随后,通过对比学习对不同维度的流量-图表示进行对齐,其相似度计算如下:
si=(gi1(norm(H))⋅gi2(norm(N))⊤)⋅exp(τ)(3) s_i = \left( g^1_i(\text{norm}(H)) \cdot g^2_i(\text{norm}(N))^\top \right) \cdot \exp(\tau) \tag{3} si=(gi1(norm(H))⋅gi2(norm(N))⊤)⋅exp(τ)(3)
最终的对齐损失函数定义为:
L=∑i12λiCE(si,y)+CE(si⊤,y)(4) \mathcal{L} = \sum_i \frac{1}{2} \lambda_i \left \\text{CE}(s_i, y) + \\text{CE}(s_i\^\\top, y) \\right \tag{4} L=i∑21λiCE(si,y)+CE(si⊤,y)(4)
其中:
- y=(0,1,...,−1)⊤y = (0, 1, \dots, -1)^\topy=(0,1,...,−1)⊤为对比学习的目标对齐标签(即正样本对在相同位置);
- sis_isi表示对比学习中的相似度度量;
- gi1,gi2g^1_i, g^2_igi1,gi2为不同信息路径的投影编码器;
- τ\tauτ为温度系数(temperature coefficient),用于调节相似度分布的锐度;
- λi\lambda_iλi为不同难度样本对的加权系数;
- CE(⋅)\text{CE}(\cdot)CE(⋅)表示交叉熵损失函数;
- norm(⋅)\text{norm}(\cdot)norm(⋅)表示归一化操作(如 L2 归一化)。
✅ 跨模态对齐思想 :借鉴 CLIP 的图文对齐范式,将"图结构"与"流语义"视为两种"模态",通过对比学习建立语义关联;
✅ 双编码器架构:
图编码器fgf_gfg捕捉拓扑结构(邻接、突发边等);
流编码器fnf_nfn提取内容特征(数据报、包长序列等);
✅ 对称对比损失 :公式 (4) 中同时计算sis_isi与si⊤s_i^\topsi⊤的损失,确保双向对齐稳定性;
✅ 自适应加权 :引入λi\lambda_iλi对难样本赋予更高权重,提升模型对复杂交互模式的学习能力。
B. 突发图匹配(Burst Graph Matching)
前述的编码对齐机制使得流量特征可作为指令线索的一部分 ,并与流量图结构建立关联理解。为进一步将大语言模型(LLM)的语言理解能力 与图学习任务 对齐,我们采用预训练指令微调范式 ,增强 LLM 对特定流量学习任务的适应性,使其能够针对流量图结构数据生成更准确且上下文恰当的输出。
尽管 LLM 具备强大的泛化上下文理解能力,但其缺乏对网络通信行为及流量特征的原生理解 。同时,流量理解能力的构建应独立于具体分类任务 。为此,我们引入自监督指令微调 (self-supervised instruction tuning),将流量图结构知识注入 LLM,以有效提升其对流量上下文信息的理解能力。
具体而言,我们设计了一项结构感知的交互式流图匹配任务 (interactive structure-aware flow graph matching task)。该任务利用无标签的加密流量数据 ,生成流量图结构表征,并将其作为指令的一部分用于 LLM 微调。在此过程中,流量图结构本身充当自监督信号单元 ,引导 LLM 结合自然语言描述 与流量序列,区分不同的图节点。
指令设计(Instruction Design)
流量图匹配任务由三个核心组件构成:
(i) 流量图 (traffic graph);
(ii) 问题指令 (problem instruction);
(iii) ETooL 响应(response)。
对于输入流量图中的每个节点,我们将其指定为中心节点 ,并采用 h-hop 随机邻居采样策略 提取其子图结构。提供给 LLM 的输入是自然语言描述 与流量特异性特征的组合。
具体地,指令包含以下三部分:
- 一个
<graph>指示单元; - 被打乱顺序的 BURST 流量特征(disrupted BURST traffic features);
- 一段文本化的问题描述(如"请将以下打乱的流量特征按正确的流顺序重新排列")。
任务目标 :将每个由图节点表示的网络流,与其对应的流量特征正确对齐。
实现方式 :模型需通过理解图节点间的拓扑关系 ,对打乱的 BURST 特征表示进行重排序。
效果 :该过程促使模型建立流量图结构表征 与关联流量特征之间的语义关联,从而提升其对网络流量行为的推理与理解能力。
微调策略(Tuning Strategy)
为降低计算开销并防止灾难性遗忘,我们采用轻量级对齐投影(lightweight alignment projection)策略:
- 冻结 LLM 主干参数(包括注意力块、词元嵌入、层归一化层等);
- 冻结预训练图神经网络编码器的所有层;
- 仅优化投影层(projection layer)的参数。
微调完成后,投影层能有效将编码后的流量图表示 映射到对应的节点表示空间 ,使 LLM 能够将这些节点表示与各类节点级特征语义对齐。
具体实现上,我们使用一个投影器 (如线性映射模块),在图节点表示 与流量特征指令表示 之间建立对应关系。
在自然语言指令中,原本的 <graph> 指示单元被替换为对齐后的图节点表示,格式如下:
{<graph begin>, <graph token>₁, ..., <graph token>ₙ, <graph end>}通过这种方式,流量图结构被无缝嵌入指令序列,使 LLM 能够像处理文本一样处理结构化图信息。
由于该匹配过程是自监督的 ,模型可高效利用来自多种流量场景的大量无标签流图数据 ,显著提升所学投影器的泛化能力,为后续分布外流量识别奠定坚实基础。
✅ 首创自监督图-语言对齐任务 :通过"打乱-重排"机制,将图拓扑关系转化为 LLM 可学习的指令信号;
✅ 结构化指令嵌入 :将图节点表示编码为特殊词元序列,实现图结构与 LLM 输入空间的无缝融合;
✅ 参数高效微调 :仅训练投影层,冻结 LLM 与 GNN 主干,兼顾性能与效率;
✅ 无标签数据驱动:充分利用未标注流量,解决 O.O.D. 场景下标注稀缺难题。
七、流量任务指令微调
在完成自监督指令微调后,我们进一步设计面向加密流量分类任务的专用指令微调方法 。该过程旨在定制大语言模型 (LLM),使其推理行为符合特定分类任务的约束与需求。通过引入任务专属指令对 LLM 进行微调,可引导模型生成更契合流量学习目标的响应,从而显著提升其在不同分布下加密流量识别任务中的适应能力。
在流量任务指令微调阶段,指令模板由三部分构成。其中,流量图信息 包含随时间采集的多个流量样本,用于构建子图。针对特定流量分类任务φ\varphiφ,我们基于训练对(X,y)(X, y)(X,y)对流量表征进行建模。
此阶段继续冻结完整的 LLM 主干网络 与流-图编码器,仅更新两部分参数:
- 从 Burst Graph Matching 阶段继承的结构感知投影器(structure-aware projector);
- 一个轻量级的任务专用分类头(classification head)。
ETooL 利用第一阶段训练所得的结构感知投影器参数作为初始状态θ\thetaθ,并在此基础上进行微调,以预测流量标签yyy:
y=ETooL(X∣(θ;φ))(5) y = \text{ETooL}(X \mid (\theta; \varphi)) \tag{5} y=ETooL(X∣(θ;φ))(5)
完成上述双阶段指令微调 (且保持关键模块参数冻结)后,大语言模型对流量图结构的理解与推理能力显著增强,从而能够高效处理各类流量图分析任务。
八、实验评估
本节通过六类不同的加密流量分类场景任务(见 VIII-A 节),验证 ETooL 在分布外 (O.O.D.)中的优越泛化性与有效性,并证明其仍能良好适配传统同分布(I.I.D.)流量识别任务。
随后,我们将模型与 6 种基线方法进行对比(VIII-B 节),并对关键组件进行消融分析(VIII-C 节)。此外,还包括:
- 动态分布偏移场景下的性能分析(VIII-D 节);
- 模型效率评估(VIII-E 节);
- 超参数选择分析(VIII-F 节)。
A. 实验设置
1) 数据集描述
表2:数据集的统计信息。经处理后用于分类的实际数据集数量。 NETD 的类别和样本量由实际使用的数据集决定。
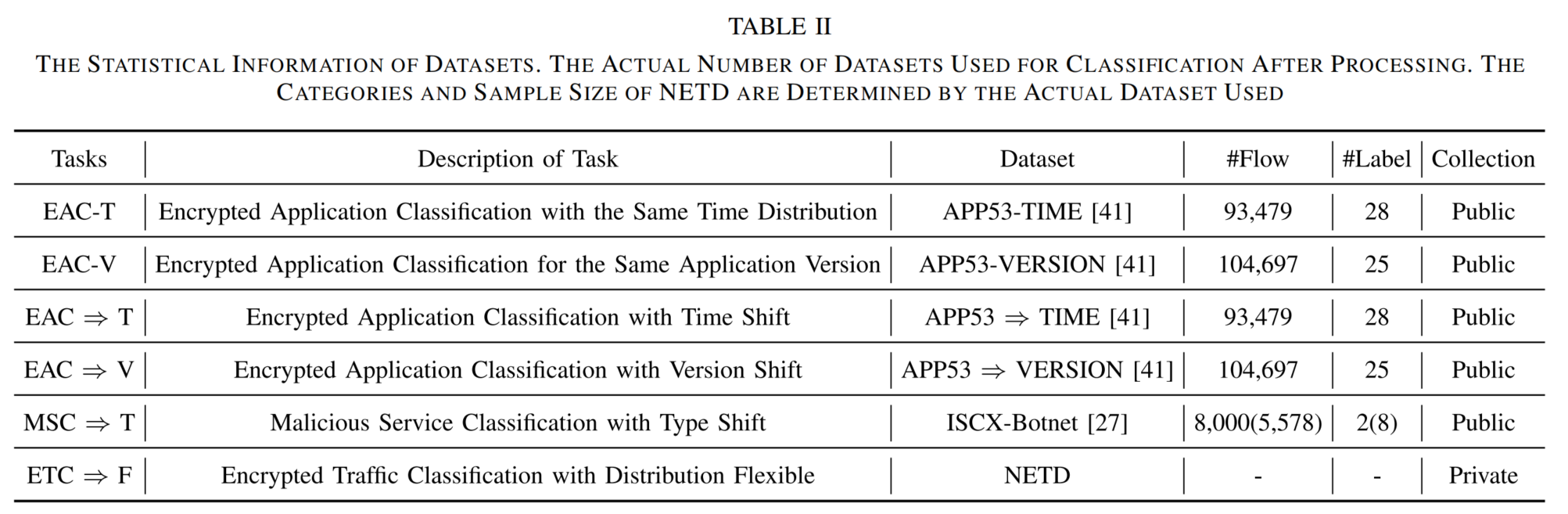
为全面评估 ETooL 的有效性与泛化能力,我们在四个公开数据集 与一个新提出的数据集 上开展五类加密流量分类任务,具体任务与数据集对应关系见 表 II 。我们在公开数据集 APP53 41 上同时进行 I.I.D. 与 O.O.D. 实验。该数据集包含从 Google Apps Marketplace 中选取的用户规模最大的 53 款 Web 应用,由志愿者在不同设备、不同时间、不同版本 下采集流量。 然而,目前公开的 APP53 仅提供在 Xiaomi 5Plus 设备 上、不同时期与版本采集的加密流量。因此,我们围绕此限制设计实验:
仅选取 APP53 中经历版本更新与时间演进 的应用,分别构建 I.I.D. 实验 (训练/测试来自相同分布)与 Non-I.I.D. 实验(训练/测试来自不同时间或版本)。
尽管 APP53 包含部分 O.O.D. 场景,但现有公开的、专门用于 O.O.D. 流量识别评估的数据集仍然稀缺 。大多数公开数据集仍遵循 I.I.D. 假设,未显式建模分布变化的影响 ,难以支持对 O.O.D. 方法的有效评估。目前,缺乏能模拟多样化 O.O.D. 场景的基准数据集,严重制约了该方向的研究进展。
为此,我们设计并构建了 NETD (Dynamic Non-I.I.D. Encrypted Traffic Dataset)------一个支持动态调节分布偏移程度的分布外加密流量数据集 。NETD 基于现有公开数据集 ISCX-VPN 29 构建,通过利用流量数据中目标概念与背景上下文的内在变异性 ,实现可控的分布偏移,从而模拟由时间演进等客观因素引发的分布变化。
具体而言,我们将任意一种网络行为视为流量数据中的上下文主成分 (principal component),其余行为作为次成分 (secondary components)。通过调整目标任务中主成分与次成分的比例偏差,即可灵活控制分布偏移的程度。
为量化分布偏移对数据集的影响,我们引入 非独立同分布指数 (Non-I.I.D. Index, NI)35。给定特征提取器GGG与类别CCC,NI 定义如下:
NI(C)=∥EG(XCtrain)−EG(XCtest)σ(G(XC))∥22(6) \text{NI}(C) = \left\| \frac{ \mathbb{E}G(X\^{\\text{train}}_C) - \mathbb{E}G(X\^{\\text{test}}_C) }{ \sigma(G(X_C)) } \right\|_2^2 \tag{6} NI(C)= σ(G(XC))EG(XCtrain)−EG(XCtest) 22(6)
其中:
- XC=XCtrain∪XCtestX_C = X^{\text{train}}_C \cup X^{\text{test}}_CXC=XCtrain∪XCtest表示类别CCC的完整数据;
- E⋅\mathbb{E}\\cdotE⋅表示一阶矩(即均值),用于刻画训练集与测试集表征的期望分布;
- σ(⋅)\sigma(\cdot)σ(⋅)为标准差,用于对表征维度进行归一化;
- ∥⋅∥2\|\cdot\|_2∥⋅∥2为 L2 范数,用于度量训练集与测试集之间分布差异的程度。
NI 值越大,表明该类别在训练与测试之间的分布偏移越显著,任务难度越高。
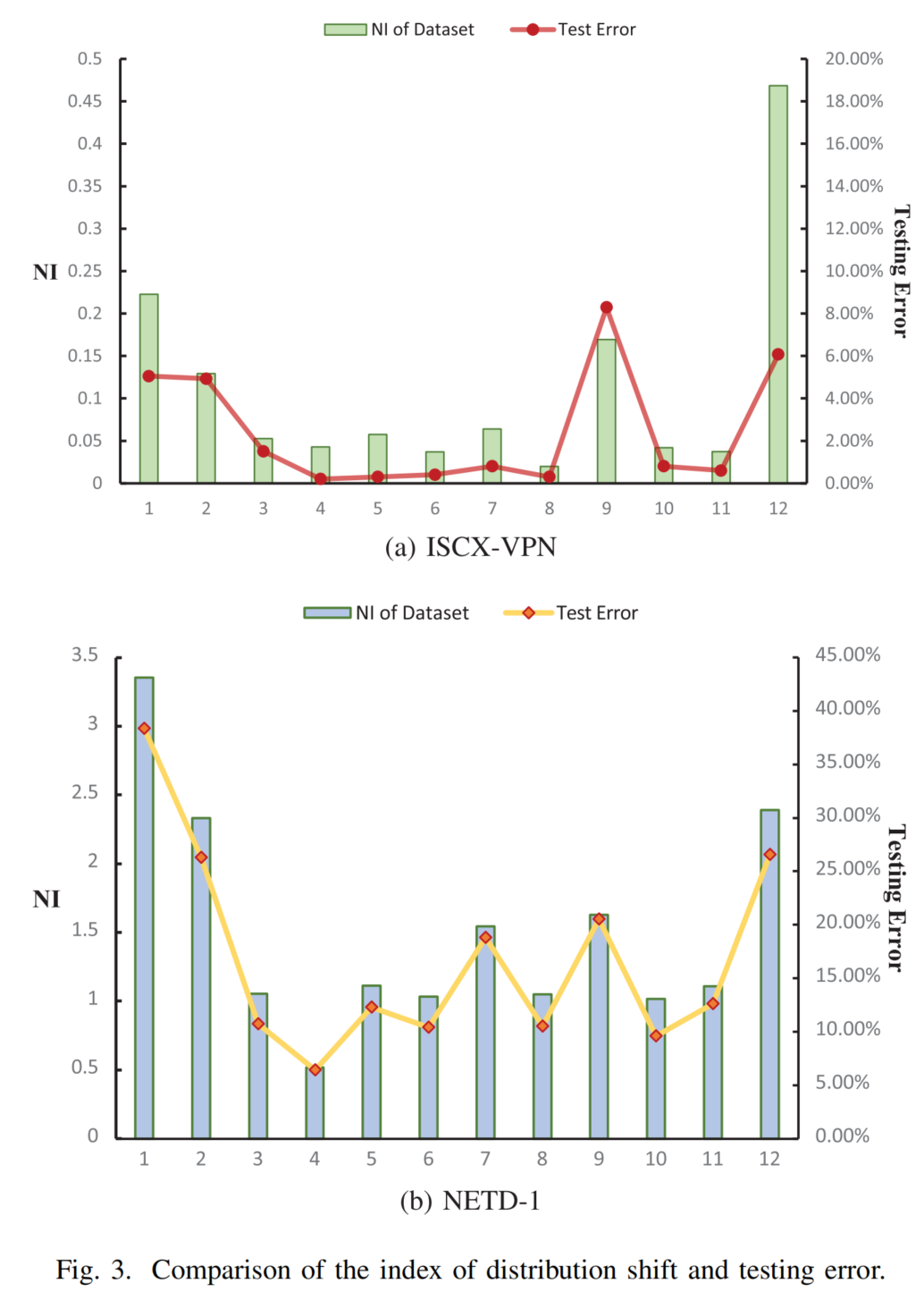
✅ 公式严谨还原 : 强调 NI 指数的物理意义:量化分布偏移强度。
✅ 逻辑清晰递进 : 从"为何需要 NETD" → "如何构建 NETD" → "如何度量其偏移程度",层层深入; 明确指出当前 O.O.D. 数据集的研究空白与本文贡献。
✅ 突出创新价值 : 强调 NETD 是首个支持动态调节分布偏移程度 的加密流量数据集; 双阶段微调策略兼顾泛化性 与任务适配性。
2) 下游任务
根据 表 II,我们设计了六类加密流量分类任务,以全面评估模型在不同分布场景下的性能:
- 任务 1:同时间分布下的加密应用分类 (EAC-T)
目标:对同一时间段内采集的应用流量进行识别与分类。 - 任务 2:同应用版本下的加密应用分类 (EAC-V)
目标:对来自同一应用版本的流量进行分类。 - 任务 3:时间偏移下的加密应用分类 (EAC ⇒ T)
目标:基于时间跨度 (间隔一个月)对应用流量进行分类。
具体设置:在任务 1 的设定下进行微调,并以零样本 (zero-shot)方式在不同时段采集的流量上测试。 - 任务 4:版本偏移下的加密应用分类 (EAC ⇒ V)
目标:基于应用版本更新 对流量进行分类。
具体设置:在任务 2 的设定下进行微调,并以零样本方式 在其他版本采集的流量数据上测试。 - 任务 5:类型偏移下的恶意服务分类 (MSC ⇒ T)
目标:对具有类型偏移的僵尸网络 (botnet)。
设定:良性流量为一类,僵尸网络流量包含 16 种类型,但训练集仅包含其中 7 类。除默认的二分类外,我们还引入多分类场景(ISCX-Botnet Multi-Class)。 - 任务 6:分布灵活可变的加密流量分类 (ETC ⇒ F)
目标:在不同分布变化条件下 对加密流量进行分类。
设定:将 12 个 Web 服务通过上下文的不同偏移方式划分为四组具有不同分布特性的数据集。

注:在分析 APP53 数据集时,我们发现其原始工作存在标签与类别描述不一致的问题,且难以获得完全准确的标注。具体而言:
- 版本变化涉及 25 个应用类别,而非原文所述的 22 个;
- 标注不一致导致测试准确率偏低。
此外,在 ISCX-Botnet(多分类)中,仅有 5 个类别可映射到已知标签。为此,我们基于原始组合数据集补充了剩余两个类别 。
因此,本文所有实验均基于实际获取的数据集 进行,以确保评估结果的准确性。各类别分布详见 表 III。
围绕上述任务,我们开展实验以回答以下关键研究问题(RQs):
- RQ1 :所提出的 ETooL 框架在有监督与零样本设置下对流量分类的性能如何?(见 VIII-B 节)
- RQ2:ETooL 框架中各关键组件对整体性能的贡献如何?(见 VIII-C 节)
- RQ3 :模型在动态分布偏移场景下的泛化能力如何?(见 VIII-D 节)
- RQ4 :ETooL 框架的计算效率如何?(见 VIII-E 节)
- RQ5 :超参数选择对结果的影响程度如何?(见 VIII-F 节)
3) 对比方法
我们选取当前应用指纹识别领域的代表性 SOTA 方法作为基线,涵盖三类技术路线:
- 统计特征方法:AppScanner 40、CUMUL 15;
- 深度学习方法:Deep Fingerprinting (DF) 8、FS-Net 22、GraphDApp 7;
- 预训练方法:PERT 24、ET-BERT 12。
这些方法被广泛采用,代表了流级流量检测的不同技术范式,常作为对比研究的标准基线。
4) 评估指标
每项实验均采用以下四种典型指标进行评估:
- 准确率 (Accuracy, AC):TP+TNTP+TN+FP+FN\frac{TP + TN}{TP + TN + FP + FN}TP+TN+FP+FNTP+TN
- 精确率 (Precision, PR):TPTP+FP\frac{TP}{TP + FP}TP+FPTP
- 召回率 (Recall, RC):TPTP+FN\frac{TP}{TP + FN}TP+FNTP
- F1 分数 (F1-Score):2⋅PR⋅RCPR+RC\frac{2 \cdot PR \cdot RC}{PR + RC}PR+RC2⋅PR⋅RC
为避免多类别数据不平衡导致的评估偏差,我们采用宏平均(Macro Average)23,即对每个类别的 PR、RC 和 F1 分别求均值:
Macro-Precision=1N∑i=1NPrecisioni, \text{Macro-Precision} = \frac{1}{N} \sum_{i=1}^{N} \text{Precision}i, Macro-Precision=N1i=1∑NPrecisioni,
Macro-Recall=1N∑i=1NRecalli, \text{Macro-Recall} = \frac{1}{N} \sum{i=1}^{N} \text{Recall}i, Macro-Recall=N1i=1∑NRecalli,
Macro-F1=1N∑i=1NF1i.(7) \text{Macro-F1} = \frac{1}{N} \sum{i=1}^{N} F1_i. \tag{7} Macro-F1=N1i=1∑NF1i.(7)
5) 实现细节
- 基础模型 :采用 Vicuna-7B-v1.5 作为 LLM 主干。该模型在标准 Transformer 基础上进行了多项优化:
- 将 LayerNorm 替换为 RMSNorm;
- 将 Multi-Head Attention 替换为 Grouped-Query Attention;
- 使用 Rotary Position Embedding 替代传统位置编码;
- 激活函数由 ReLU 改为 SwiGLU。
- 模型架构 :包含 32 个解码器层,每层含 32 个自注意力头,注意力模块中q,k,vq, k, vq,k,v向量维度均为 128。
- 训练配置 :
- 学习率:2×10−32 \times 10^{-3}2×10−3
- Warmup 比例:3×10−23 \times 10^{-2}3×10−2
- 训练轮次:3
- 批大小:2
- LLM 最大输入长度:2,048
- BURST 时间阈值:设为 1 秒。
- 实验环境:PyTorch 2.1.0,NVIDIA Tesla A800 GPU(80 GB 显存)。
B. 总体性能对比(RQ1)
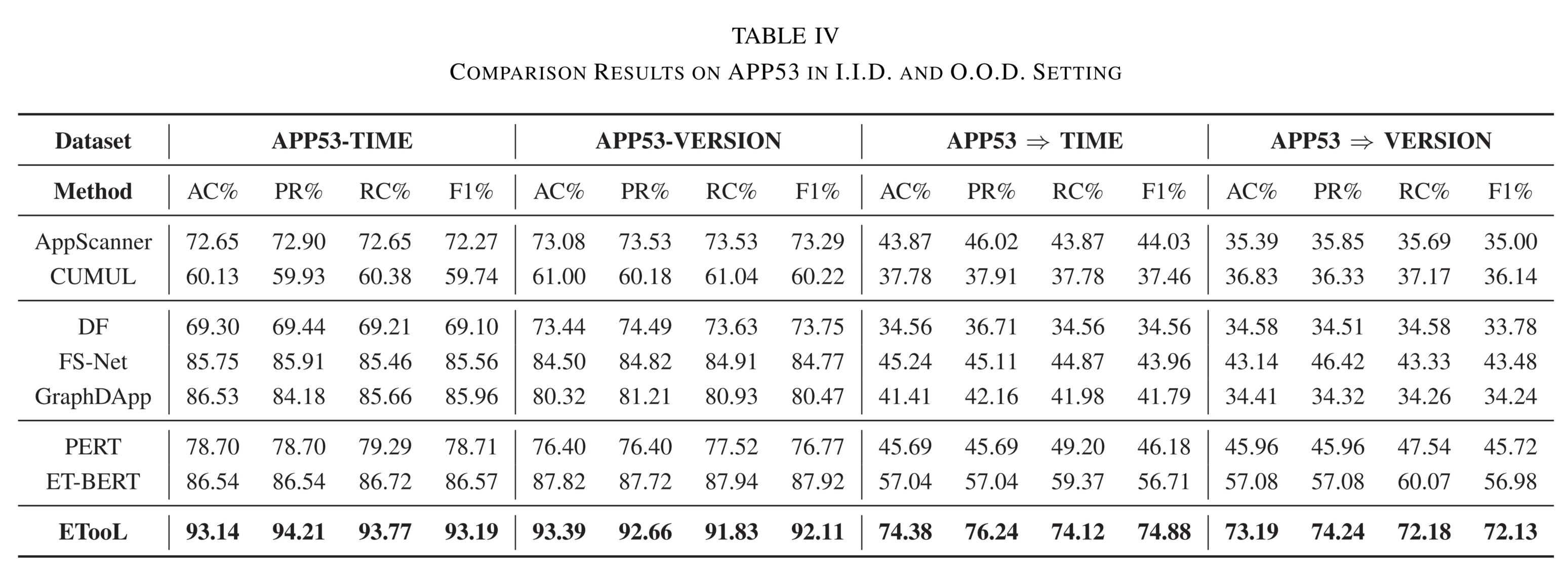
我们在多类流量分类任务上开展实验,涵盖有监督 与零样本 (zero-shot)两种设置。整体性能如 表 IV 所示。ETooL 在两类场景下均显著优于各类 SOTA 基线方法。
1) 同分布(I.I.D.)下的通用加密流量分类
首先,我们在理想实验设定下(即 I.I.D. 场景)评估 ETooL 与现有方法在应用分类任务中的性能。该部分结果亦作为后续分析模糊流量与概念漂移影响的基准。
在 I.I.D. 场景中,ETooL 相较于代表性基线方法(ET-BERT、FS-Net、AppScanner),在 F1 分数上平均提升 5.41%、7.49% 和 19.87%。
- 在 EAC-TIME 任务中 ,ETooL 的 F1 分数分别比 ET-BERT、FS-Net 和 AppScanner 提高 6.62%、7.63% 和 20.92% 。
APP53 数据集中同质流的相互干扰严重制约了传统特征构建方法(如 CUMUL、AppScanner),表明专家驱动的特征工程有效性正在减弱 。
虽然 DF 与 FS-Net 利用深度学习自动提取特征,可在 I.I.D. 流上识别加密流量,但其性能受限于网络架构设计、特征选择策略及标注数据规模有限 。
尽管 ET-BERT 凭借预训练优势展现出更强识别能力,但其仅依赖单流输入 的局限性仍制约了性能上限。
相比之下,ETooL 无需大规模流级预训练 ,而是通过指令微调激活大语言模型的理解能力 ,从有限标注数据中挖掘多流关联 与上下文关系,从而在具挑战性的 I.I.D. 场景中实现高效识别。 - 在 EAC-VERSION 任务中 ,ETooL 相较上述三类领先方法,F1 分数分别提升 4.19%、7.34% 和 18.82% 。
该任务难度更高,源于:
(i) 应用版本类别数量更多;
(ii) 相似流量间的干扰更强。
尽管如此,ETooL 仍表现出卓越鲁棒性 ,验证了其对流量特征的强大理解与泛化能力。
2) 非独立同分布(Non-I.I.D.)下的加密流量分类
本小节进一步探索 ETooL 在分布偏移场景下的泛化能力。通过引入更多指令数据对模型进行微调,以有效应对各类 O.O.D. 任务。
与 I.I.D. 实验不同,此处重点评估模型在分布变化下的分布外泛化性能。
根据 表 IV ,当面对流分布变化时,基线方法性能显著下降 。而 ETooL 不仅性能退化最小 ,且在 APP53 ⇒ TIME 与 APP53 ⇒ VERSION 任务中,相较代表性基线,F1 分数平均提升 16.66%、29.79% 和 33.42%。
-
在 EAC ⇒ TIME 任务中 (时间偏移):
现有方法在未采用 O.O.D. 处理策略时,识别准确率大幅下降。例如:
- AppScanner:I.I.D. 下 F1=72.27%,时间偏移后降至 44.03%;
- FS-Net 与 ET-BERT 也分别降至 43.96% 与 56.71% 。
这表明时间间隔变化引发的分布偏移对现有方法构成严峻挑战。
相比之下,ETooL 表现出极强鲁棒性 ,性能退化极小。这说明:尽管流量分布随时间演变,但其中仍存在不变的内在属性 ------这些属性根植于流量传输拓扑中的关联结构 与流间上下文关系 。ETooL 能有效捕获并整合这些信息至推理机制,从而在时变条件下保持优异泛化能力。
-
在 EAC ⇒ VERSION 任务中 (版本偏移):
版本更新带来的分布偏移比时间变化更具挑战性 。该任务需在同一时段采集同一应用两个不同版本 的加密流量,而版本间网络接口或服务逻辑差异 导致流量分布显著不同。
此时,AppScanner 性能骤降至 35.00% ,FS-Net 与 ET-BERT 也分别降至 43.48% 与 56.98% 。
而 ETooL 依然保持最小性能损失,显著优于现有方法。
-
恶意流量检测验证 :
我们进一步在恶意流量识别 任务中验证 ETooL 性能。分布偏移主要源于僵尸网络类型差异 。
在 MSC ⇒ T(二分类) 任务中,测试集包含训练阶段未见过的僵尸网络类型,要求模型具备更强泛化能力。
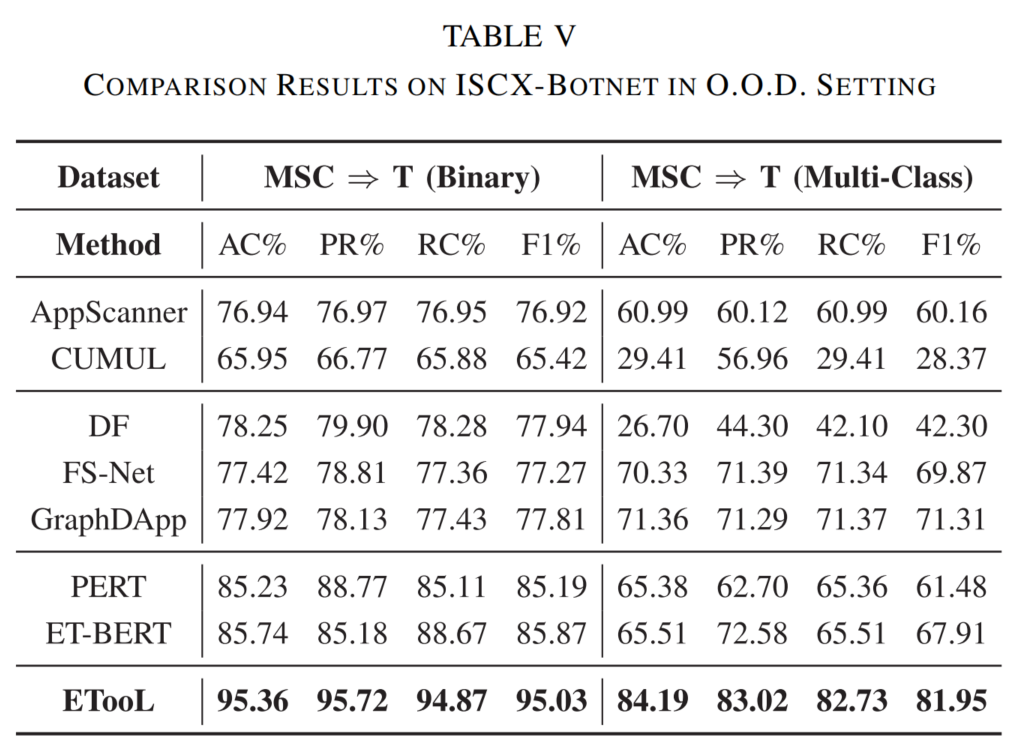
如 表 V 所示:
- AppScanner 与 FS-Net(依赖包长特征)在已知类型上表现较好,说明包长是跨分布共性的重要载体;
- DF 使用原始数据报作为特征,优于 PERT、ET-BERT 等预训练方法,印证预训练架构对性能的增益。
ETooL 在两类恶意流量检测任务中,分别超越最优基线 9.16% 与 12.08%。原因在于:
(1) 通过 TRG 融合包长 与数据报 特征,并引入流并发性 与时序关系 ,捕获更丰富的流量交互;
(2) 大模型架构通过预训练增强推理能力 ,同时提升对图结构的理解,从而更有效地泛化至未知分布。
C. 消融研究(RQ2)
为量化各子模块贡献,我们开展消融实验,结果见 表 VI 。依次移除原始数据报 、包长序列 、图结构指令微调 与LLM 主干,验证各组件在不同任务中的作用。
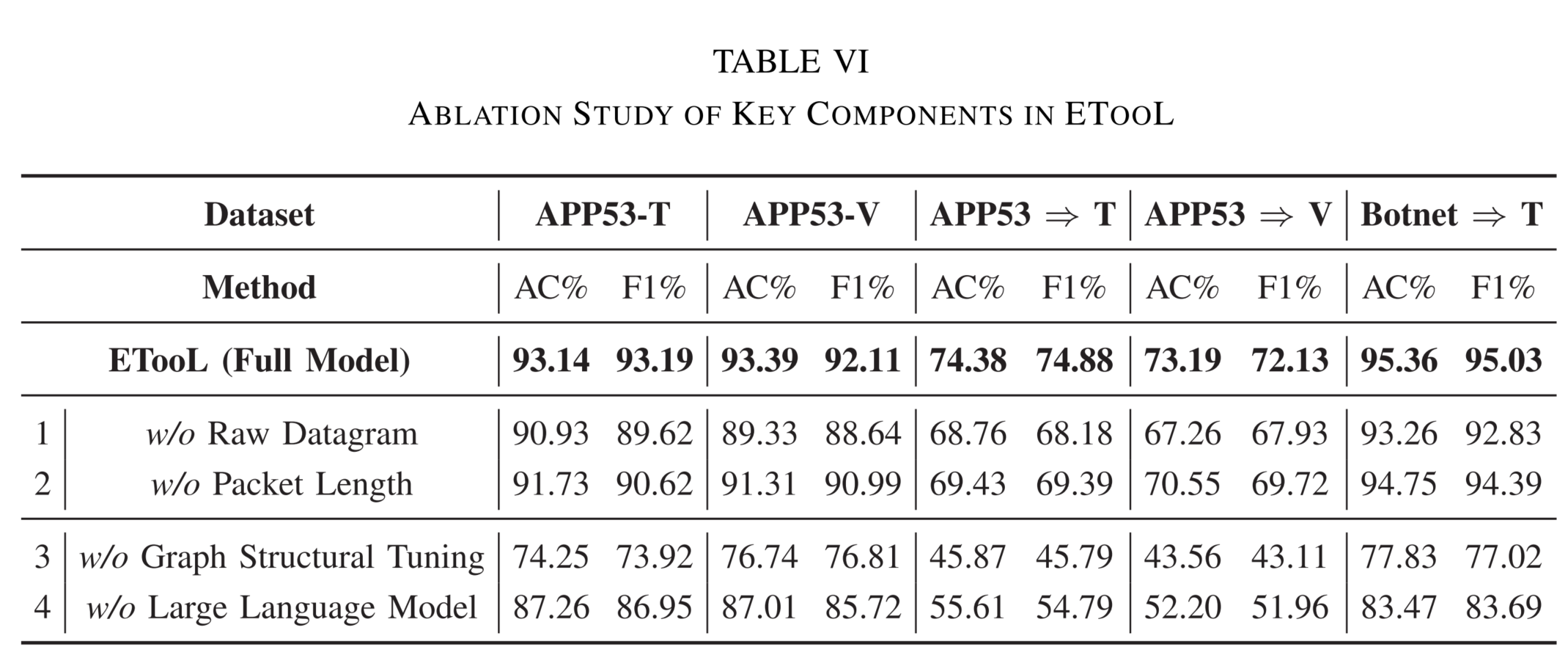
(1) 流量输入粒度的影响(模型 "1--2")
- 移除数据报序列(模型 "1"):F1 平均下降 4.02%;
- 移除包长序列(模型 "2"):F1 平均下降 2.44% 。
结果表明:数据报提供更显著的性能增益,但多粒度特征融合仍是关键。
(2) 图结构与图指令微调的作用 (模型 "3")该模型不使用流量关系图 ,直接对 LLM 进行流级指令微调。
结果:所有场景性能显著下降 ,F1 平均降低 22.13% 。
说明:流量关联结构 与图指令微调范式 对 ETooL 学习流量上下文至关重要。
此外,基于交互的建模方式能有效捕捉分布偏移下的表征相似性,显著提升 O.O.D. 识别能力。
(3) LLM 推理能力的必要性 (模型 "4")该模型使用未初始化的 Graph Transformer 对流图进行监督训练,完全移除指令微调机制 。
结果:相较 ETooL,F1 平均下降 12.84% 。
表明:大语言模型提供的理解与推理能力 ,在缓解分布偏移导致的误分类方面不可或缺,为 O.O.D. 流量识别提供关键支撑。
✅ ETooL 全面领先 :在 I.I.D. 与 O.O.D. 场景下均显著优于 SOTA 方法;✅ O.O.D. 鲁棒性强 :在时间/版本偏移、未知恶意类型等挑战下保持高性能;
✅ 多流图结构关键 :TRG 与图指令微调贡献最大(消融下降 22.13%);
✅ LLM 推理不可替代 :纯图模型无法替代 LLM 的泛化与推理能力;
✅ 数据报 > 包长:原始字节信息比统计特征更具判别力。
D. 泛化能力探究(RQ3)
为更深入衡量 ETooL 与对比方法在分布变化场景下的性能差异,我们在 ISCX-VPN(I.I.D. 设置) 与动态分布偏移流量数据集 NETD 上开展加密流量分类能力分析。
如 第 VIII-A1 节 所述,NETD 的构建主要通过控制两个关键因素实现:比例偏置 (proportional bias)与组成偏置(compositional bias)。具体设置如下:
基础数据集构成
ISCX-VPN 数据集包含 VPN 与 Non-VPN 两类环境下的 6 种服务类型 ,共涵盖 17 个具体应用,包括:
- 即时通讯(Chat):ICQ、AIM、Skype、Facebook、Hangouts;
- 电子邮件(Email):SMPTS、POP3S、IMAPS;
- 文件传输(File Transfer):Skype、FTPS、SFTP;
- P2P 下载(P2P):uTorrent、Transmission;
- 流媒体(Streaming):Vimeo、YouTube;
- 语音通话(VoIP):Facebook、Skype、Hangouts。
本实验以混合流量场景下的服务级识别为目标,将上述各类服务作为构成成分进行组合。
比例偏置设置(Proportional Bias Setting)
在此设定下,确保每个目标类别的构成成分同时出现在训练集与测试集中 。对每个服务类别,随机选定一个主成分 (primary component),其余为次成分 (minor components)。通过设定主导比例(dominant ratio)控制主次成分的相对占比:
Dominant Ratio=NDominantNMinor(8) \text{Dominant Ratio} = \frac{N_{\text{Dominant}}}{N_{\text{Minor}}} \tag{8} Dominant Ratio=NMinorNDominant(8)
其中:
- NDominantN_{\text{Dominant}}NDominant表示主成分的样本数量;
- NMinorN_{\text{Minor}}NMinor表示次成分的平均样本数量。
通过固定训练集或测试集中的主导比例 ,并在另一集合中改变比例偏置,可模拟不同强度的分布偏移场景。
组成偏置设置(Compositional Bias Setting)
与比例偏置不同,组成偏置模拟的是训练数据未能覆盖完整分布 的情形。通过调整训练集与测试集中各服务类别的构成成分数量,可模拟不同程度的信息缺失,从而实现分布偏置。
设当前类别所有上下文成分的全集为C0C^0C0,则训练集与测试集的构建策略如下:
-
训练集候选集合 :
T={T⊂C0 | 1≤∣T∣≤N−1},∣T∣=∑k=1N−1(Nk)=2N−2(9) T = \left\{ T \subset C^0 \,\middle|\, 1 \leq |T| \leq N - 1 \right\}, \quad |T| = \sum_{k=1}^{N-1} \binom{N}{k} = 2^N - 2 \tag{9} T={T⊂C0 1≤∣T∣≤N−1},∣T∣=k=1∑N−1(kN)=2N−2(9) -
测试集候选集合 :
S={S⊂C0 | 1≤∣S∣≤N},∣S∣=∑m=1N(Nm)=2N−1(10) S = \left\{ S \subset C^0 \,\middle|\, 1 \leq |S| \leq N \right\}, \quad |S| = \sum_{m=1}^{N} \binom{N}{m} = 2^N - 1 \tag{10} S={S⊂C0 1≤∣S∣≤N},∣S∣=m=1∑N(mN)=2N−1(10)
其中:
- TTT表示训练数据的可选子集(至少包含 1 个、至多N−1N-1N−1个成分);
- SSS表示测试数据的可选子集(可包含全部NNN个成分);
- NNN为当前类别上下文成分的总数。
NETD 四类 O.O.D. 数据集构建
基于 ISCX-VPN,我们构建了四个具有不同分布偏移特性的 O.O.D. 流量数据集:
- NETD-1 :采用比例偏置策略 ,按主/次成分 1:3 的比例随机采样生成训练集与测试集,二者分布均发生偏移;
- NETD-2 :与 NETD-1 类似,但主/次成分采样比例为 3:1;
- NETD-3 :采用组成偏置策略 ,训练集仅包含目标服务类别中 80% 的上下文应用 ,其余 20% 未在训练中出现,测试集则使用完整数据集;
- NETD-4 :与 NETD-3 类似,但训练集仅包含目标服务类别中 20% 的上下文应用,分布偏移更为剧烈。
注:在 NETD-3 与 NETD-4 中,还可进一步结合比例偏置(如调整主/次成分比例)构造更极端的分布偏移。
实验结果分析
如 图 4 所示,在动态 Non-I.I.D. 加密流量数据集上的对比结果清晰表明:ETooL 在各类数据集上均取得最优分类性能。
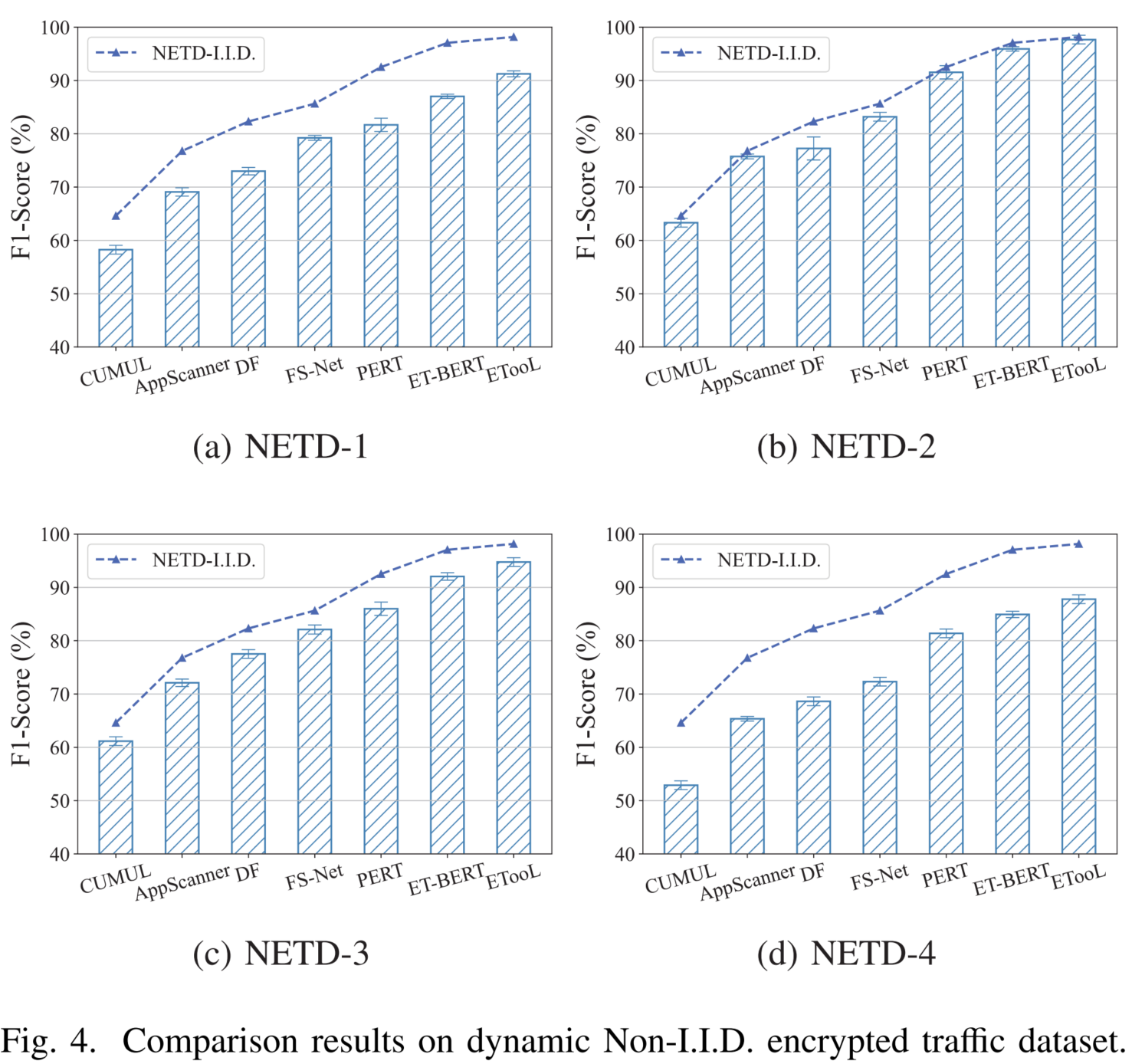
- 图中柱状图表示各方法在 O.O.D. 场景下的识别结果,折线表示其在 I.I.D. 设置下的性能基准。
- 值得注意的是,在 I.I.D. 场景下,ETooL 与 ET-BERT 性能相当;
- 然而,在两类典型的 Non-I.I.D. 场景(比例偏置与组成偏置)下,ETooL 显著优于所有对比方法 ,展现出卓越的鲁棒性与分类准确性。
这一结果验证了 ETooL 能够有效应对由成分比例变化 或成分缺失引发的分布偏移,其核心优势在于:
通过图结构指令微调 与大语言模型的上下文推理能力 ,捕获流量中跨成分的不变关联模式,从而在分布动态变化的复杂环境中保持稳定泛化性能。
E. 模型效率研究(RQ4)
本研究旨在评估所提模型在训练阶段的计算效率。
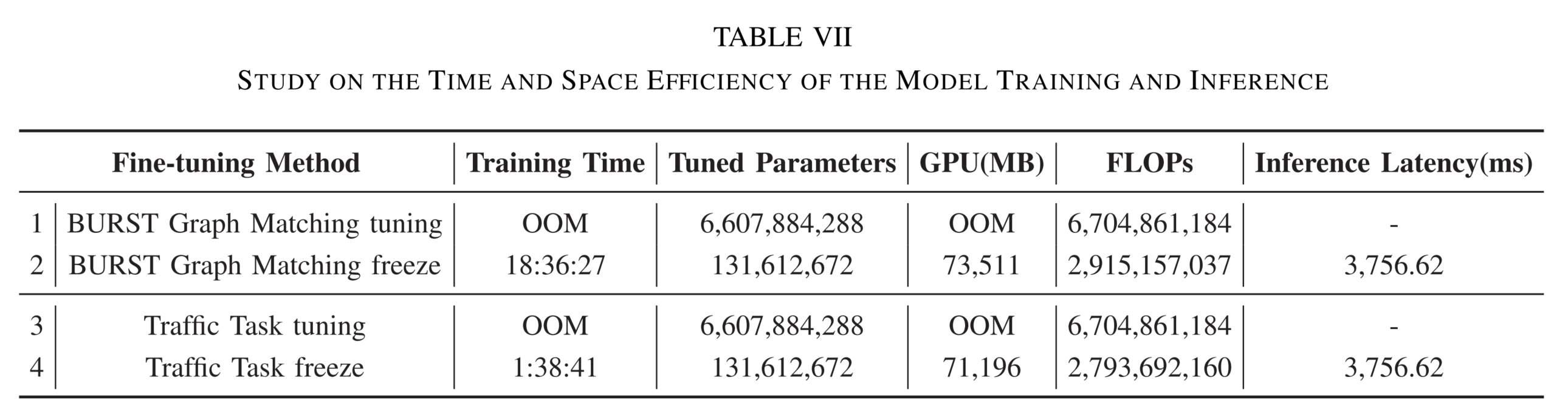
如 表 VII 所示,我们的指令微调框架采用两阶段策略 :在整个过程中,大语言模型 (LLM)均被冻结,仅对流-图对齐投影层 (flow-graph aligned projection layer)进行优化。我们在配备双卡 NVIDIA A800(每卡 80GB 显存)的环境中,对比了冻结参数 (freeze)与全参数微调(tuning)两种策略,在以下维度进行效率评估:
- 训练时间;
- 可调参数量;
- 单 GPU 显存占用(MB);
- 模型计算量;
- 推理延迟(毫秒/响应)。
实验发现:
在相同条件下,即使将批大小(batch size)设为 1,对 LLM 进行全参数微调仍会触发 GPU 显存溢出 (Out of Memory)错误。
而采用参数冻结策略 后,不仅训练过程可稳定运行,还可显著增大训练批大小。
此外,相较于全参数微调,冻结策略使参与指令微调的参数量减少超过 50 倍,从而大幅降低模型计算开销与训练时间。
为进一步评估 ETooL 的推理效率 ,我们在单张 NVIDIA A800 上测量其在 NETD 数据集上的推理延迟。
尽管当前版本尚未满足实时检测 (real-time detection),但其在辅助决策 (assisted decision-making)等场景中具有显著优势------此类场景对分布外加密流量的高精度识别至关重要。
特别地,当结合可解释性策略 50 对 LLM 的泛化能力进行正则化后,ETooL 有望进一步优化,具备在线部署的可行性。
F. 超参数分析(RQ5)
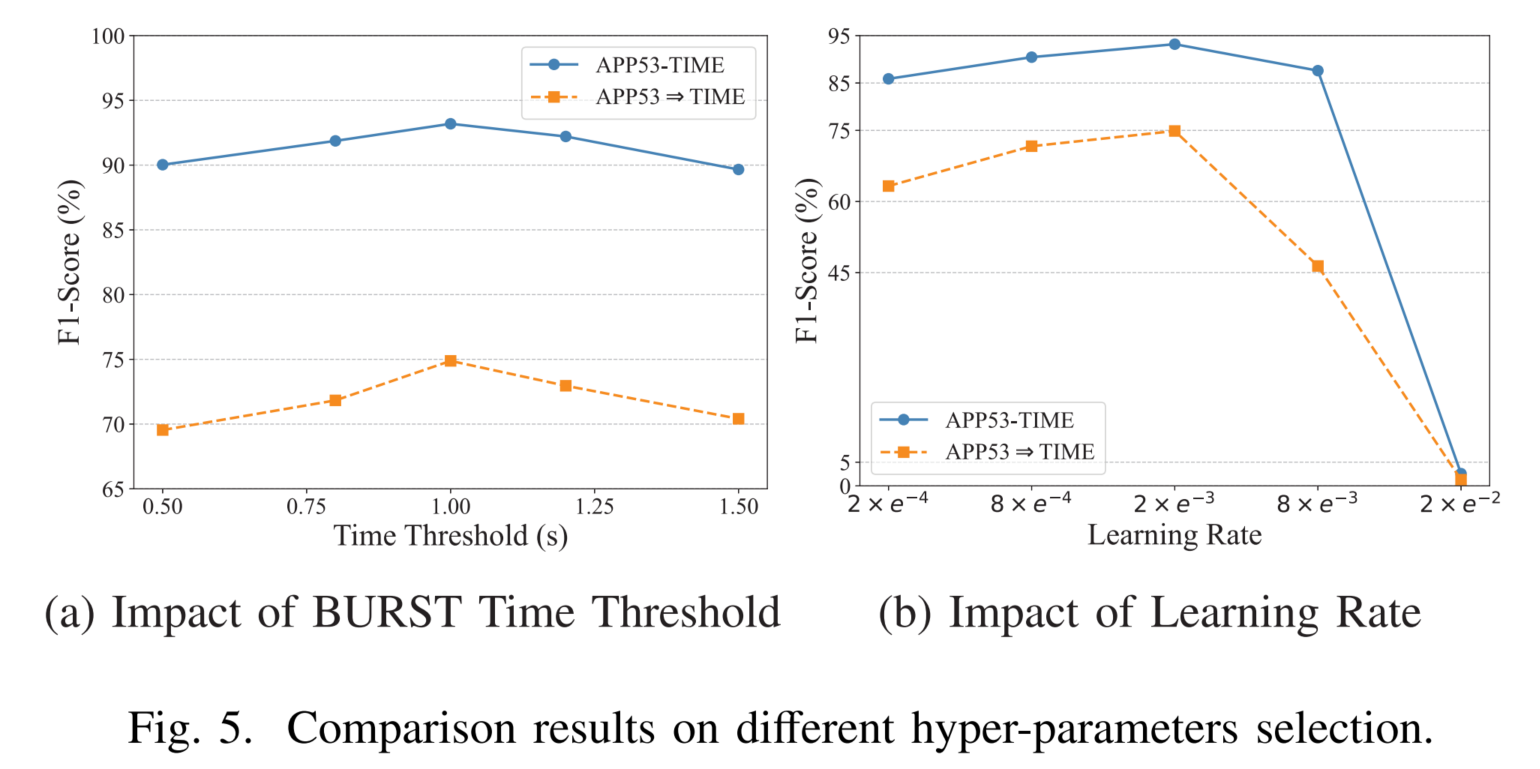
本分析旨在评估训练阶段超参数选择对模型性能的影响 。如 图 5 所示,BURST 时间阈值 与学习率在 I.I.D. 与 O.O.D. 测试场景中均对性能产生显著影响。
-
关于 BURST 时间阈值 :
若阈值过小,不同功能的流可能被错误聚合到同一 BURST 中 ;
若阈值过大,则可能导致功能无关的流被合并 ,破坏语义边界。
通过在多个时间阈值下进行实验,我们发现:约 1 秒的阈值能取得最优性能,这一设定在经验上平衡了流聚合的粒度与语义一致性。
-
关于学习率 :
受限于批大小,若学习率设置过高,模型在收敛点附近易出现震荡或过冲 (overshoot),导致梯度方差增大甚至发散;
若学习率过低,则收敛速度过慢,需更多训练步数补偿。
经多组实验验证,学习率设为2×10−32 \times 10^{-3}2×10−3 时,模型在各类任务中表现最佳。
九、结论
本文提出 ETooL (Encrypted Traffic Understanding with Large Language Models)------一种高效且分布自适应的流量大语言模型 ,旨在提升流量分类模型的泛化能力。
所提框架将基于流交互知识构建的流量图结构 ,注入大语言模型的指令微调范式中。我们在 7 个加密流量数据集 上,于 I.I.D. 与 Non-I.I.D. 设置下 对 ETooL 的泛化能力进行了全面评估。结果表明,该方法在有监督 与零样本场景中均表现出色。
实验清晰证实:
相较于现有加密流量分类方法,ETooL 在分布外泛化能力上具有显著优势。
ETooL 框架通过大语言模型的自适应指令微调机制 ,有效融合了流量特征 与交互关联模式 。这使其能够在识别新分布流量 的同时,保留对历史分布流量的知识 ,从而避免传统模型依赖反复重训练(iterative retraining)的局限,为动态网络环境下的流量理解提供了全新范式。
REFERENCES
1 S. Rezaei and X. Liu, "Deep learning for encrypted traffic classification: An overview," IEEE Commun. Mag. , vol. 57, no. 5, pp. 76--81, May 2019.
2 C. Fu, Q. Li, M. Shen, and K. Xu, "Realtime robust malicious traffic detection via frequency domain analysis," in Proc. ACM SIGSAC Conf. Comput. Commun. Secur. , Y. Kim, J. Kim, G. Vigna, and E. Shi, Eds., Nov. 2021, pp. 3431--3446.
3 S. Luo et al., "An in-depth study of microservice call graph and runtime performance," IEEE Trans. Parallel Distrib. Syst. , vol. 33, no. 12, pp. 3901--3914, Dec. 2022.
4 K. Ye, H. Shen, Y. Wang, and C.-Z. Xu, "Multi-tier workload consolidations in the cloud: Profiling, modeling and optimization," IEEE Trans. Cloud Comput. , vol. 10, no. 2, pp. 899--912, Apr. 2022.
5 Q. Yuan, G. Gou, Y. Zhu, Y. Zhu, G. Xiong, and Y. Wang, "MCRe: A unified framework for handling malicious traffic with noise labels based on multidimensional constraint representation," IEEE Trans. Inf. Forensics Security , vol. 19, pp. 133--147, 2024.
6 B. Anderson and D. McGrew, "Machine learning for encrypted malware traffic classification: Accounting for noisy labels and non-stationarity," in Proc. 23rd ACM SIGKDD Int. Conf. Knowl. Discovery Data Mining , Halifax, NS, Canada, Aug. 2017, pp. 1723--1732.
7 M. Shen, J. Zhang, L. Zhu, K. Xu, and X. Du, "Accurate decentralized application identification via encrypted traffic analysis using graph neural networks," IEEE Trans. Inf. Forensics Security , vol. 16, pp. 2367--2380, 2021.
8 P. Sirinam, M. Imani, M. Juarez, and M. Wright, "Deep fingerprinting: Undermining website fingerprinting defenses with deep learning," in Proc. ACM SIGSAC Conf. Comput. Commun. Secur. (CCS) , Toronto, ON, Canada, Jul. 2018, pp. 1928--1943.
9 P. Liu, L. Li, Y. Yan, M. Fazzini, and J. Grundy, "Identifying and characterizing silently-evolved methods in the Android API," in Proc. IEEE/ACM 43rd Int. Conf. Softw. Eng., Softw. Eng. Pract. (ICSE-SEIP) , Madrid, Spain, May 2021, pp. 308--317.
10 E. Gourdin, P. Maille, G. Simon, and B. Tuffin, "The economics of CDNs and their impact on service fairness," IEEE Trans. Netw. Service Manage. , vol. 14, no. 1, pp. 22--33, Mar. 2017.
11 M. Market. (2020). Mobile CDN Market --- Global Industry Report . Online. Available: https://www.transparencymarketresearch.com/mobile-cdn-market.html
12 X. Lin, G. Xiong, and G. Gou, "ET-BERT: A contextualized datagram representation with pre-training transformers for encrypted traffic classification," in Proc. ACM Web Conf. , Lyon, France, F. Laforest, R. Troncy, E. Simperl, D. Agarwal, A. Gionis, and I. Herman, Eds., 2022, pp. 633--642.
13 T. Cui et al., "TrafficLLM: Enhancing large language models for network traffic analysis with generic traffic representation," 2025, arXiv:2504.04222.
14 V. Rimmer, D. Preuveneers, M. Juarez, T. V. Goethem, and W. Joosen, "Automated website fingerprinting through deep learning," in Proc. Netw. Distrib. Syst. Secur. Symp. , San Diego, CA, USA, Aug. 2018.
15 A. Panchenko et al., "Website fingerprinting at internet scale," in Proc. Netw. Distrib. Syst. Secur. Symp. , San Diego, CA, USA, Jul. 2016.
16 Y. Tian, R. Gan, Y. Song, J. Zhang, and Y. Zhang, "ChiMed-GPT: A Chinese medical large language model with full training regime and better alignment to human preferences," in Proc. 62nd Annu. Meeting Assoc. Comput. Linguistics , Bangkok, Thailand, 2024, pp. 7156--7173.
17 K. Yang, T. Zhang, Z. Kuang, Q. Xie, J. Huang, and S. Ananiadou, "MentaLLaMA: Interpretable mental health analysis on social media with large language models," in Proc. ACM Web Conf. , Singapore, May 2024, pp. 4489--4500.
18 K. Lin, X. Xu, and H. Gao, "TSCRNN: A novel classification scheme of encrypted traffic based on flow spatiotemporal features for efficient management of IIoT," Comput. Netw. , vol. 190, May 2021, Art. no. 107974.
19 M. Lotfollahi, M. J. Siavoshani, R. S. H. Zade, and M. Saberian, "Deep packet: A novel approach for encrypted traffic classification using deep learning," Soft Comput. , vol. 24, no. 3, pp. 1999--2012, Feb. 2020.
20 W. Wang, M. Zhu, X. Zeng, X. Ye, and Y. Sheng, "Malware traffic classification using convolutional neural network for representation learning," in Proc. Int. Conf. Inf. Netw. (ICOIN) , Da Nang, Vietnam, Jan. 2017, pp. 712--717.
21 J. Wei et al., "Emergent abilities of large language models," in Proc. Trans. Mach. Learn. Res. , Aug. 2022.
22 C. Liu, L. He, G. Xiong, Z. Cao, and Z. Li, "FS-Net: A flow sequence network for encrypted traffic classification," in Proc. IEEE Conf. Comput. Commun. (INFOCOM) , Paris, France, Jul. 2019, pp. 1171--1179.
23 C. Liu, W. Wang, M. Wang, F. Lv, and M. Konan, "An efficient instance selection algorithm to reconstruct training set for support vector machine," Knowl.-Based Syst. , vol. 116, pp. 58--73, Jan. 2017.
24 H. Y. He, Z. Guo Yang, and X. N. Chen, "PERT: Payload encoding representation from transformer for encrypted traffic classification," in Proc. ITU Kaleidoscope, Ind.-Driven Digit. Transformation (ITU K) , Ha Noi, Vietnam, Dec. 2020, pp. 1--8.
25 A. Torralba and A. A. Efros, "Unbiased look at dataset bias," in Proc. CVPR , Colorado Springs, CO, USA, Jun. 2011, pp. 1521--1528.
26 J. Tang et al., "GraphGPT: Graph instruction tuning for large language models," in Proc. 47th Int. ACM SIGIR Conf. Res. Develop. Inf. Retr. , Washington, DC, USA, Jul. 2024, pp. 491--500.
27 E. B. Beigi, H. H. Jazi, N. Stakhanova, and A. A. Ghorbani, "Towards effective feature selection in machine learning-based botnet detection approaches," in Proc. IEEE Conf. Commun. Netw. Secur. , San Francisco, CA, USA, Sep. 2014, pp. 247--255.
28 A. H. Lashkari, G. D. Gil, M. S. I. Mamun, and A. A. Ghorbani, "Characterization of Tor traffic using time based features," in Proc. 3rd Int. Conf. Inf. Syst. Secur. Privacy (ICISSP) , Porto, Portugal, P. Mori and S. Furnell, Eds., Feb. 2017, pp. 253--262.
29 G. Draper-Gil, A. H. Lashkari, M. S. I. Mamun, and A. A. Ghorbani, "Characterization of encrypted and VPN traffic using time-related features," in Proc. 2nd Int. Conf. Inf. Syst. Secur. Privacy , Rome, Italy, P. Mori, Ed., Feb. 2016, pp. 407--414.
30 X. Lin et al., "CETP: A novel semi-supervised framework based on contrastive pre-training for imbalanced encrypted traffic classification," Comput. Secur. , vol. 143, Aug. 2024, Art. no. 103892.
31 M. Jiang, M. Cui, C. Liu, G. Gou, G. Xiong, and Z. Li, "Zero-relabeling mobile-app identification over drifted encrypted network traffic," Comput. Netw. , vol. 228, Jun. 2023, Art. no. 109728.
32 R. Attarian, L. Abdi, and S. Hashemi, "AdaWFPA: Adaptive online website fingerprinting attack for tor anonymous network: A stream-wise paradigm," Comput. Commun. , vol. 148, pp. 74--85, Dec. 2019.
33 Q. Meng et al., "Beyond known threats: A novel strategy for isolating and detecting unknown malicious traffic," J. Inf. Secur. Appl. , vol. 89, Mar. 2025, Art. no. 103920.
34 T. van Ede et al., "FlowPrint: Semi-supervised mobile-app fingerprinting on encrypted network traffic," in Proc. Netw. Distrib. Syst. Secur. Symp. , San Diego, CA, USA, Jul. 2020.
35 Y. He, Z. Shen, and P. Cui, "Towards non-I.I.D. image classification: A dataset and baselines," Pattern Recognit. , vol. 110, Feb. 2021, Art. no. 107383.
36 M. Shen, Y. Liu, L. Zhu, K. Xu, X. Du, and N. Guizani, "Optimizing feature selection for efficient encrypted traffic classification: A systematic approach," IEEE Netw. , vol. 34, no. 4, pp. 20--27, Jul. 2020.
37 F. Petroni et al., "Language models as knowledge bases?," in Proc. Conf. Empirical Methods Natural Lang. Process. 9th Int. Joint Conf. Natural Lang. Process. (EMNLP-IJCNLP) , Jul. 2019, pp. 2463--2473.
38 M. Juarez, S. Afroz, G. Acar, C. Diaz, and R. Greenstadt, "A critical evaluation of website fingerprinting attacks," in Proc. ACM SIGSAC Conf. Comput. Commun. Secur. , Scottsdale, AZ, USA, Nov. 2014, pp. 263--274.
39 K. Al-Naami et al., "Adaptive encrypted traffic fingerprinting with bidirectional dependence," in Proc. 32nd Annu. Conf. Comput. Secur. Appl. , Dec. 2016, pp. 177--188.
40 V. F. Taylor, R. Spolaor, M. Conti, and I. Martinovic, "Robust smartphone app identification via encrypted network traffic analysis," IEEE Trans. Inf. Forensics Security , vol. 13, no. 1, pp. 63--78, Jan. 2018.
41 M. Jiang et al., "Accurate mobile-app fingerprinting using flow-level relationship with graph neural networks," Comput. Netw. , vol. 217, Nov. 2022, Art. no. 109309.
42 X. Wang et al., "Combine intra- and inter-flow: A multimodal encrypted traffic classification model driven by diverse features," Comput. Netw. , vol. 245, May 2024, Art. no. 109403.
43 K. Zhou, J. Yang, C. C. Loy, and Z. Liu, "Learning to prompt for vision-language models," Int. J. Comput. Vis. , vol. 130, no. 9, pp. 2337--2348, Sep. 2022.
44 J. He et al., "TransFG: A transformer architecture for fine-grained recognition," in Proc. 36th AAAI Conf. Artif. Intell., 34th Conf. Innov. Appl. Artif. Intell. , May 2022, pp. 852--860.
45 D. Wu et al., "NetLLM: Adapting large language models for networking," in Proc. ACM SIGCOMM Conf. , Sydney, NSW, Australia, Aug. 2024, pp. 661--678.
46 R. Zhao, X. Deng, Z. Yan, J. Ma, Z. Xue, and Y. Wang, "MTFlowFormer: A semi-supervised flow transformer for encrypted traffic classification," in Proc. 28th ACM SIGKDD Conf. Knowl. Discov. Data Min. , A. Zhang and H. Rangwala, Eds., Aug. 2022, pp. 2576--2584.
47 Z. Hang, Y. Lu, Y. Wang, and Y. Xie, "Flow-MAE: Leveraging masked AutoEncoder for accurate, efficient and robust malicious traffic classification," in Proc. 26th Int. Symp. Res. Attacks, Intrusions Defenses , Hong Kong, Oct. 2023, pp. 297--314.
48 Y. Wang et al., "Self-instruct: Aligning language models with self-generated instructions," in Proc. 61st Annu. Meeting Assoc. Comput. Linguistics , Toronto, ON, Canada, Oct. 2023, pp. 13484--13508.
49 B. Jin, G. Liu, C. Han, M. Jiang, H. Ji, and J. Han, "Large language models on graphs: A comprehensive survey," IEEE Trans. Knowl. Data Eng. , vol. 36, no. 12, pp. 8622--8642, Dec. 2024.
50 D. Han et al., "Rules refine the riddle: Global explanation for deep learning-based anomaly detection in security applications," in Proc. ACM SIGSAC Conf. Comput. Commun. Secur., Salt Lake City, UT, USA, Dec. 2024, pp. 4509--4523.