1.环境升级
|-----------------|--------------|-------------------|
| ##### 📙J6 量产版本 || ##### J5 CS版本 |
| python | 3.10 & 3.11 | 3.8 |
| torch | 2.3.0+cu118 | 1.13.0+cu116 |
| torchvision | 0.18.0+cu118 | 0.14.0+cu116 |
| ONNX | 1.15.0 | 1.8.0 |
| X86 GCC | 12.2 | 5.4 |
| Linaro GCC | 12.2 | 9.3 |
上述J6量产版本以OE3.2.0为例,J5 CS版本以OE1.1.74为例;
torch版本即将升级到2.6+cuda12.6。
1.1 docker开发
由于老版本docker存在一些兼容性问题(如工具运行失败,python包import失败等异常问题),因此使用J6计算平台的docker时需要确保docker版本满足如下要求:
-
Docker(20.10.10或更高版本,建议安装20.10.10版本)
-
NVIDIA Container Toolkit(1.13.5或更高版本,建议安装1.15.0)
1.2 本地部署
|------------------------|------------------------|---------------------|----------------------------------------|----------------------|
| | horizon-tc-ui 模型集成 | horizon-nn 模型转换 | horizon-plugin-pytorch Pytorch量化插件 | hbdk 编译器 |
| J6 whl包名称 及版本号 | horizon_tc_ui 3.x.x | hmct 2.x.x | horizon-plugin-pytorch J6 & J5共版本 | hbdk4-compiler 4.x.x |
| J5 whl包名称 及版本号 | horizon_tc_ui 1.x.x | horizon-nn 1.x.x | horizon-plugin-pytorch J6 & J5共版本 | hbdk 3.x.x |
由于J5和J6的horizon-tc-ui以及模型转换分开发版,因此无法在同一个环境中同时安装J5和J6的PTQ模型转换环境。建议使用docker开发。
由于J6量化训练环境兼容J5,因此若想在同一个环境中进行J5和J6两个计算平台的QAT训练,则建议直接参考J6用户手册完成J6开发环境安装即可。若想直接在J6训练环境中编译J5模型,可再补充安装J5对应版本hbdk(python3.10版本请联系地平线支持人员获取)即可。
2.算法开发
2.1 浮点模型准备
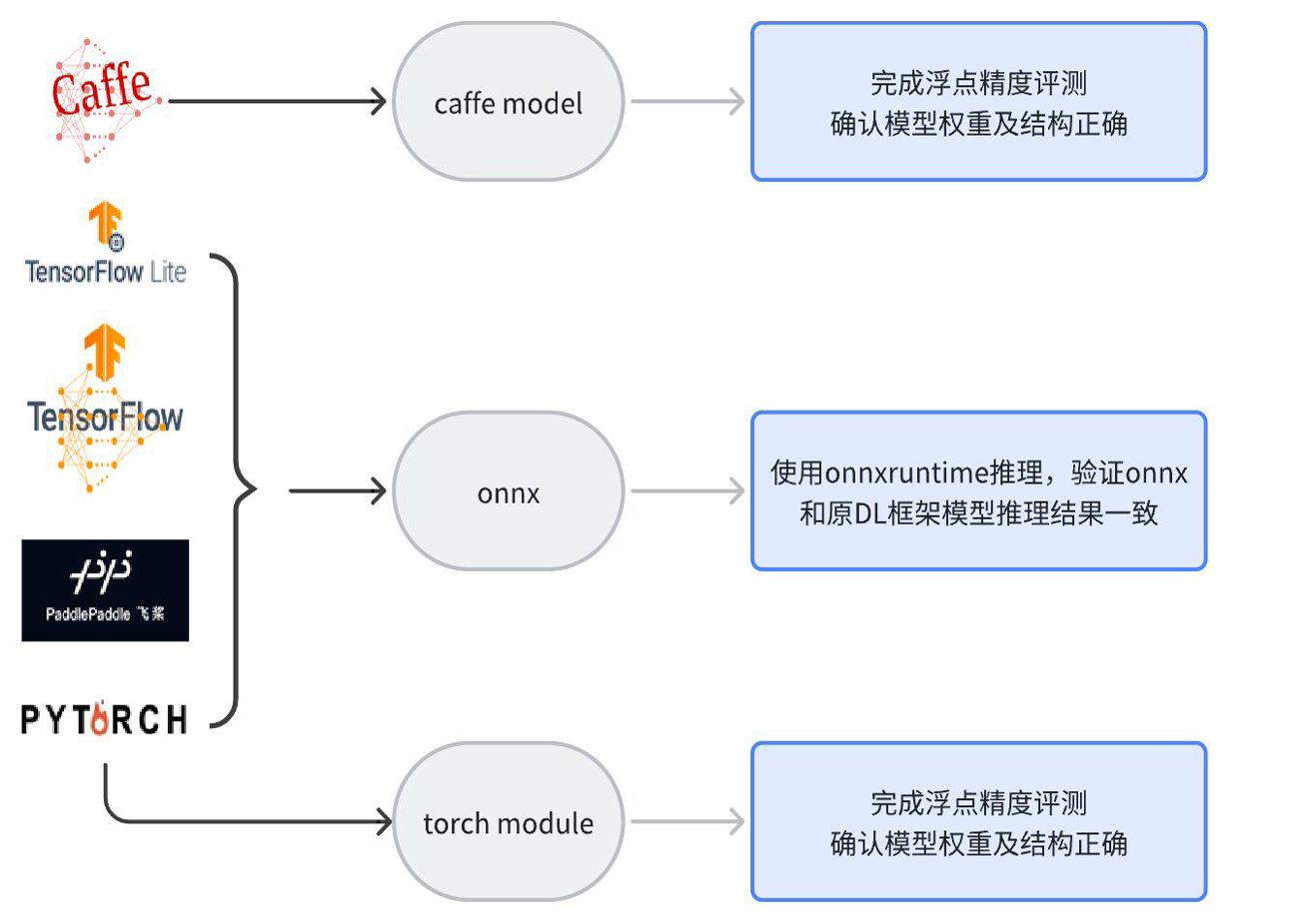
J6和J5计算平台支持的DL框架范围一致,Pytorch框架支持导出为onnx进行模型转换编译,也提供了量化插件用于直接转换编译torch module;支持直接转换caffe模型;其他框架导出为onnx即可支持。各框架版本支持情况如下:
|----------|------------|--------|-------------------|
| ##### 📙J6 量产版本 ||| ##### J5 CS版本 |
| onnx | 推荐版本 | 1.15.0 | 1.8.0 |
| onnx | opset | 10-19 | 10、11 |
| onnx | ir_version | 不高于9 | 不高于7 |
上述J6量产版本以OE3.2.0为例,J5 CS版本以OE1.1.74为例;
2.2 模型量化
2.2.1 PTQ
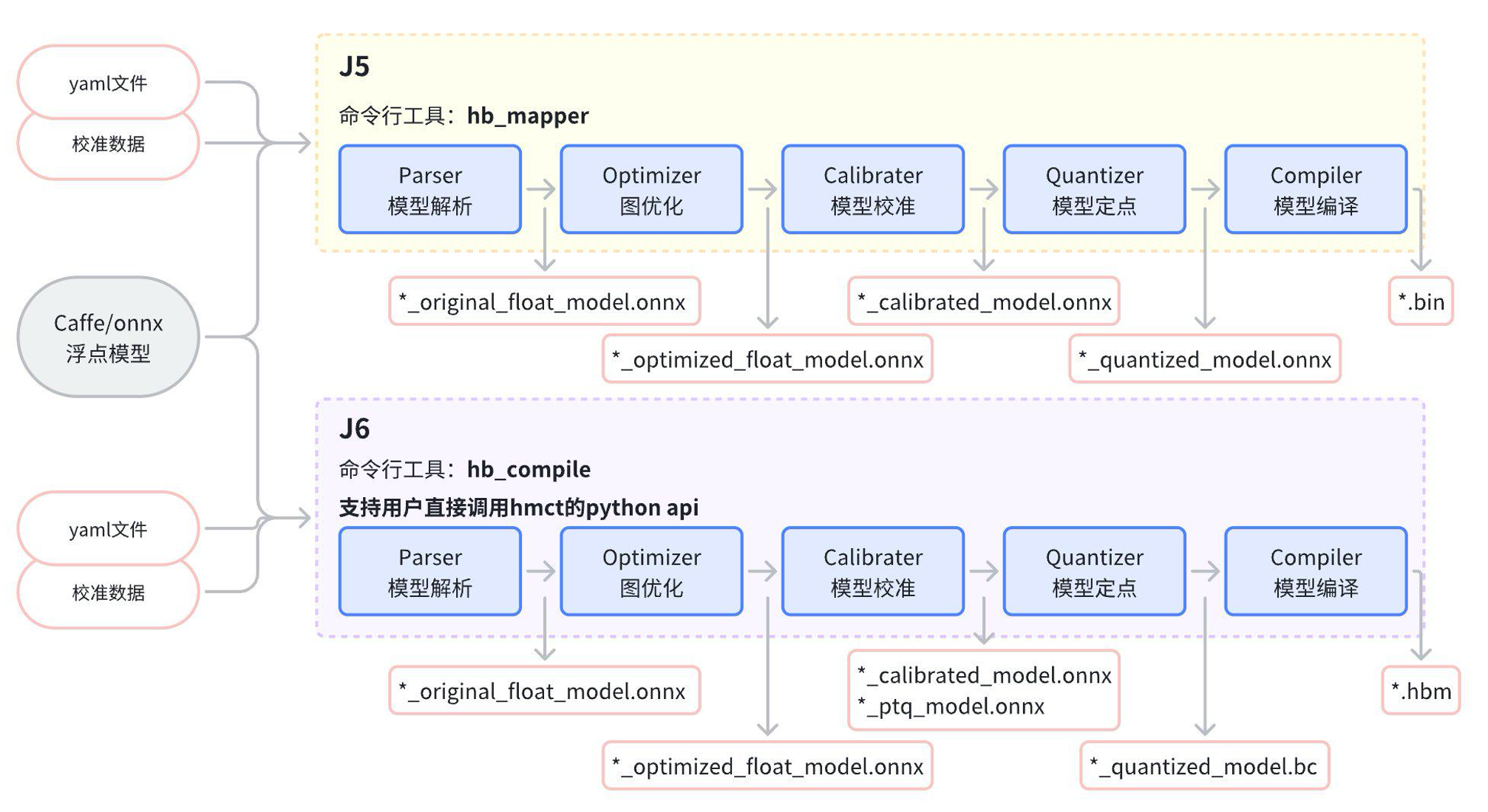
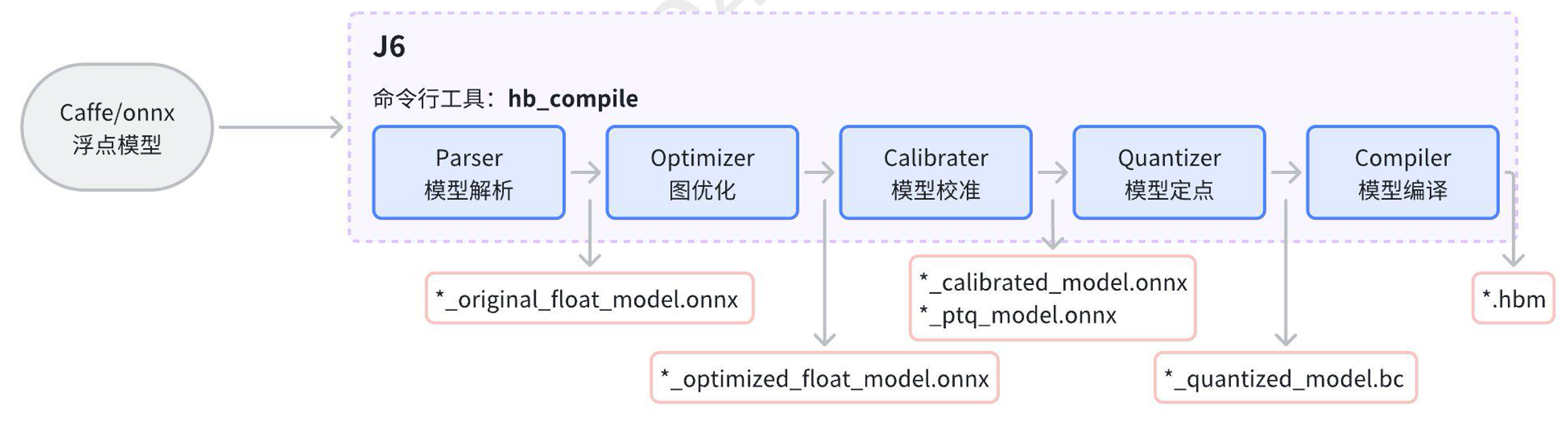
J5 和 J6 PTQ模型转换流程对比图
上图对比了J5和J6的转换流程,从使用流程上来说没有区别,J6为了支持用户灵活使用的需求,释放了Python API给客户。
2.2.1.1命令行工具
关于命令行工具使用有差异的部分通过白底粉色外框标记(主要涉及校准数据、yaml文件以及转换过程产物)。具体差异说明请见下表,从J5迁移J6需重点关注校准数据的处理 差异、onnx模型推理前处理 和新增/失效的yaml参数。J6命令行工具hb_compile的详细使用方式请参考用户手册【hb_compile工具】章节。
|------------------------------------|------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------|
| || J6 | J5 |
| 转换命令 | 模型检查 | hb_compile --march nash-e --model ./xxx.onnx | hb_mapper checker --model-type onnx --march bayes --model ./xxx.onnx |
| 转换命令 | 快速性能评测 | hb_compile --fast-perf --march nash-e --model ./xxx.onnx | hb_mapper makertbin --fast-perf --model-type onnx --march bayes --model ./xxx.onnx |
| 转换命令 | 模型转换 | hb_compile --config config.yaml | hb_mapper makertbin --config config.yaml --model-type onnx |
| 转换命令 | 精度调试 | hb_compile -c config.yaml --skip compile | 无 |
| 转换产物 | 模型解析 | *_original_float_model.onnx模型结构不受yaml配置参数的影响(插入前处理节点的过程后移至定点阶段,以简化量化过程的数据预处理),与原始浮点onnx完全一致,因此前处理代码与浮点模型保持一致 | 若配置input_type_rt为非featuremap格式,并配置了归一化相关参数,则*_original_float_model.onnx相较于原始浮点onnx会增加前处理节点,因此前处理代码相较于浮点模型需增加图像格式转换并去掉归一化 |
| 转换产物 | 图优化 | *_optimized_float_model.onnx的前处理代码与*_original_float_model.onnx保持一致 | *_optimized_float_model.onnx的前处理代码与*_original_float_model.onnx保持一致 |
| 转换产物 | 模型校准 | *_calibrated_model.onnx、*_ptq_model.onnx的前处理代码与*_original_float_model.onnx保持一致 | *_calibrated_model.onnx主要用于精度问题debug阶段,前处理代码与*_original_float_model.onnx保持一致 |
| 转换产物 | 模型定点 | 若配置input_type_rt为非featuremap格式,并配置了归一化相关参数,则*_quantized_model.bc中会增加前处理节点,因此前处理代码相较于浮点模型需增加图像格式转换并去掉归一化 | 前处理代码与*_original_float_model.onnx保持一致 |
| 转换产物 | 编译 | *.hbm 前处理代码对齐业务部署需要 | *.bin 前处理代码对齐业务部署需要 |
| 校准数据准备 | 格式 | 支持np.save保存的.npy文件,也兼容np.tofile保存的.bin文件 | 只支持np.to_file保存的二进制.bin文件 |
| 校准数据准备 | 处理过程 | 保持与浮点模型前处理完全一致 | 需要将数据处理至input_type_rt*中间格式 |
| yaml参数 > 除列出的参数外,其他参数配置与J5完全一致 | 新增参数 | seperate_batch:沿第一维将输入节点做拆分,用于片上部署时不同batch的数据可以来源于不同的地址空间的场景。目前只支持onnx模型本身所有输入的第一维为1时,结合input_batch使用,原始模型输入第一维不为1,或者不同输入的batch需要不同的pyramid/resizer输入场景,请参考后文 2.3.2节多batch拆分 做处理。 | - |
| yaml参数 > 除列出的参数外,其他参数配置与J5完全一致 | 新增参数 | debug_mode:支持dump_all_layers_output、dump_calibration_data | - |
| yaml参数 > 除列出的参数外,其他参数配置与J5完全一致 | 新增参数 | quant_config:支持通过json方式从模型、op type、以及单个op三个维度去灵活配置量化精度和校准方式(J5关于校准的相关配置仅作兼容,详细配置说明请参考后文2.2.1.3 quant_config配置说明) | - |
| yaml参数 > 除列出的参数外,其他参数配置与J5完全一致 | 新增参数 | extra_params:支持input_no_padding、output_no_padding,可使得模型输入输出不带padding(有可能会对模型延时产生影响,建议实测确认模型性能是否满足预期) | - |
| yaml参数 > 除列出的参数外,其他参数配置与J5完全一致 | 新增参数 | enable_vpu:模型参数组(model_parameters)新增参数,用于控制是否要启用vpu,当前版本仅支持量化/反量化加速 | |
| yaml参数 > 除列出的参数外,其他参数配置与J5完全一致 | 失效参数 | input_layout_rt:J6编译出的模型输入输出节点shape将保持与浮点完全一致,不再支持通过该参数做输入节点的修改。 | - |
| yaml参数 > 除列出的参数外,其他参数配置与J5完全一致 | 失效参数 | norm_type:通过mean_value、std_value或者scale_value来配置归一化参数即可 | - |
| yaml参数 > 除列出的参数外,其他参数配置与J5完全一致 | 失效参数 | calibration_type:该参数不再支持"load"模式,即J6不再支持load QAT训练后导出的onnx模型;同时该参数仅做兼容,量化配置建议使用quant_config | - |
2.2.1.2 Python API
考虑到J6支持对hbir做修改(如插入节点、修改节点名字等),因此为避免有灵活配置需求的PTQ用户无需在python脚本和命令行工具之间来回切换,因此将hmct(Horizon Model Convert Toolkit 模型转换工具)的API(接口说明请参考 用户手册-进阶内容-HMCT API Reference 章节内容)直接向用户开放,以下是一个简单的使用示例:
import os
import numpy as np
from hmct.api import load_model, build_model
import logging
# 打开转换日志信息,设置之后会打印校准方式和onnx信息
logging.basicConfig(level=logging.INFO)
march = "nash"
onnx_path = "./resnet18.onnx"
cali_data_dir = "./calibration_data_rgb"参考后续代码可将ptq_model.onnx转为.bc,并编译得到.hbm:
from hbdk4.compiler.onnx import export
from hbdk4.compiler import save, convert, visualize, compile, hbm_perf
import onnx
onnx_model = onnx.load("ptq_model.onnx")
hb_ptq_model = export(onnx_model, name="my_model")
save(hb_ptq_model, "ptq_model.bc")
hb_quantized_model = convert(hb_ptq_model, "nash-e", advice=True)
#可选,可视化模型
visualize(hb_quantized_model)2.2.1.3 quant_config配置说明
完整的配置参数说明请参考 用户手册-训练后量化(PTQ)-PTQ转换工具-quant_config说明 章节的内容,本节仅介绍quant_config配置和J5配置方式的对应关系:
- default校准
使用J5计算平台时,我们比较推荐用户先配置:calibration_type: default,由工具自动搜索比较合适的校准方式。
J6校准参数组只需配置校准数据集即为default:
calibration_parameters:
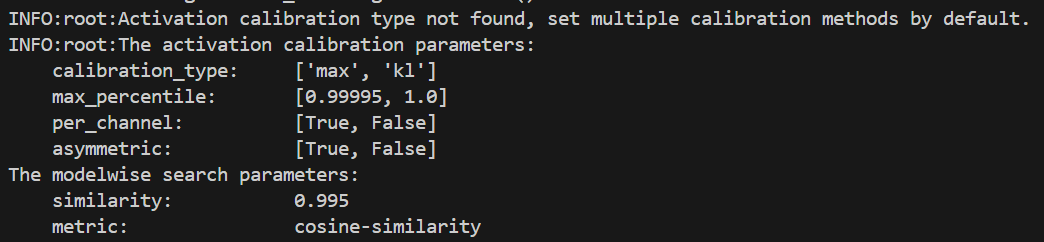
cal_data_dir: './calibration_data'可以从hb_compile.log中看出在不配置calibration_type时,工具默认使用了"default":

而对于调用python api的场景,指定quant_config=None,或者不传入该参数就会默认启用default搜索。

- mix校准
default是对整个模型搜索某种校准方式,有时候可能整个模型中部分op需要不同的校准方式会有更好的精度表现,因此在J5的校准参数中我们支持了mix混合校准:calibration_type: mix**。**
J6校准参数组只需通过quant_config打开layerwise_search即可:
calibration_parameters:
cal_data_dir: './calibration_data'
quant_config: 'config.json'调用python api时则指定quant_config='config.json'
# config.json
{
"model_config": {
"layerwise_search": {
}
}
}
- 其他配置说明
当前支持在modelwise_search时通过activation和weight参数组配置不同的校准方式,如下所示:
{
"model_config": {
// 激活校准参数配置
"activation": {
// 设置激活校准方法,可配置类型:String/List[String]
"calibration_type": "max"/"kl"/["max", "kl"],
// 设置kl校准参数,可配置类型:Int/List[Int]
"num_bin": 1024/2048/[1024, 2048],
// 设置kl校准参数,可配置类型:Int
"max_num_bin": 16384,2.2.2 QAT
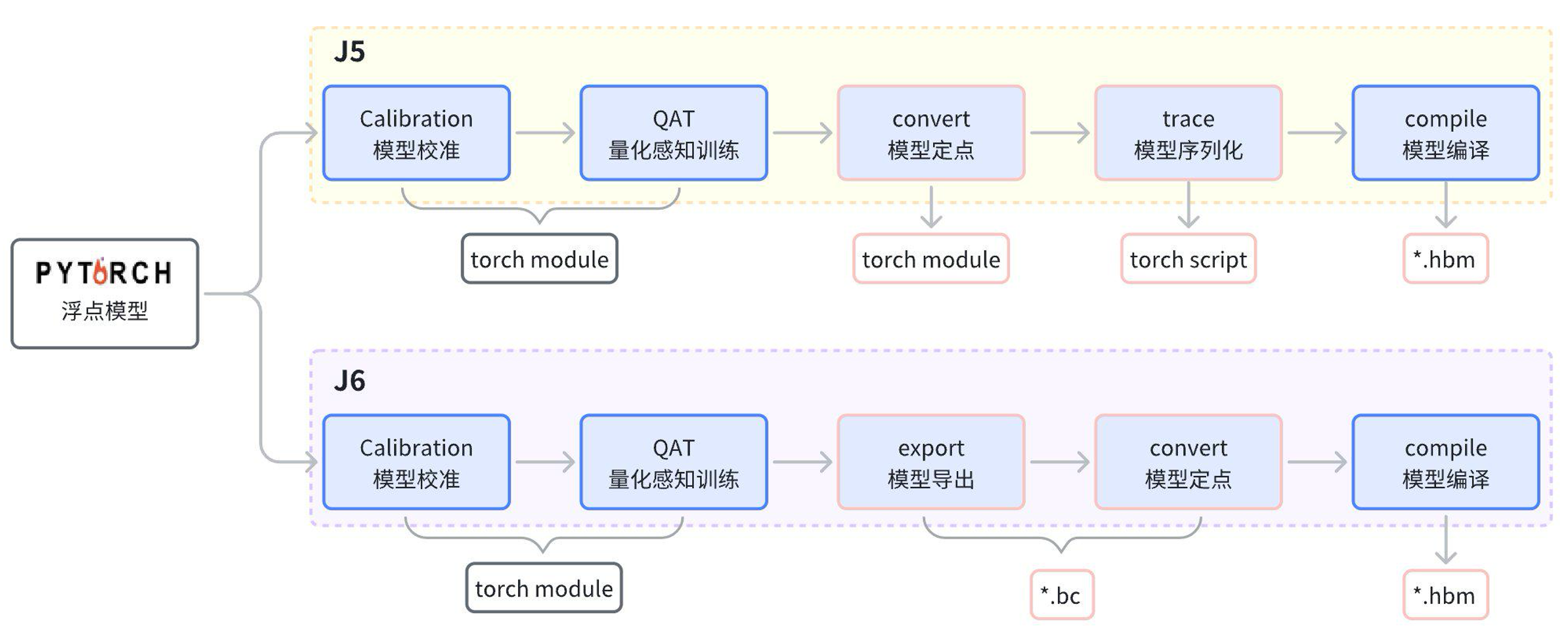
J5 和 J6 QAT模型转换流程对比图
从上图可见,J6相较于J5,主要是在模型序列化阶段采用了不同的技术路径,模型校准和量化训练阶段没有任何区别,只要模型中使用的是J5和J6均可支持的算子,则只需进行一次量化训练,两个平台可复用模型权重。具体使用差异请见如下对比:
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| J6 |
| from horizon_plugin_pytorch.quantization import ( set_fake_quantize, FakeQuantState, ) from horizon_plugin_pytorch.march import March,set_march from horizon_plugin_pytorch.quantization.hbdk4 import export #J6 from hbdk4.compiler import save, convert, visualize, compile, hbm_perf #J6 set_march(March.NASH_E) |
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| J5 |
| from horizon_plugin_pytorch.march import March,set_march from horizon_plugin_pytorch.quantization import ( convert_fx, # J5 check_model, # J5 compile_model, # J5 perf_model, # J5 ) set_march(March.BAYES) |
|------------------|--------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------|
| | J6 | J5 |
| 量化训练 | 推荐使用J6新的prepare和qconfig配置接口(兼容J5),原接口依然兼容。新接口支持新的trace方式,兼具fx的易用性,同时又减少了fx固有的问题和限制(具体请参考用户手册 量化训练感知.开发指南.Prepare详解>章节)。 | - |
| 模型序列化 | 使用export接口将qat module导出成hbir格式 | 使用torch.jit.trace将quantized module导出成torch script格式 |
| 模型定点 | from hbdk4.compiler import convert | from horizon_plugin_pytorch.quantization import convert |
| 可视化 | from hbdk4.compiler import visualize 支持将hbir模型转成onnx格式进行可视化 | from horizon_plugin_pytorch.quantization import visualize_model 支持将序列化后的quantized.pt模型结构导出为.svg图片进行可视化 |
| 模型检查 | J6模型检查接口还在设计中,建议可以先通过编译O0模型来验证模型的可支持性 | from horizon_plugin_pytorch.quantization import check_model 若可支持,则会打印"This model is supported!" |
| 编译 | from hbdk4.compiler import compile 不再支持input_source和input_layout参数,适配方式请参考后文模型修改及编译章节 | from horizon_plugin_pytorch.quantization import compile_model |
| 性能评测 | from hbdk4.compiler import hbm_perf | from horizon_plugin_pytorch.quantization import perf_model |
| 修改模型输入输出节点名称 | export接口支持指定模型以及模型输入输出名字 | hbdk-attach |
由上述对比可见,将J5模型迁移至J6时,若希望尽可能复用J5的部署代码,则不可避免的需要对模型做一些适配修改,因此需要依据下一章的介绍,写一个符合部署需要的J6模型编译脚本。
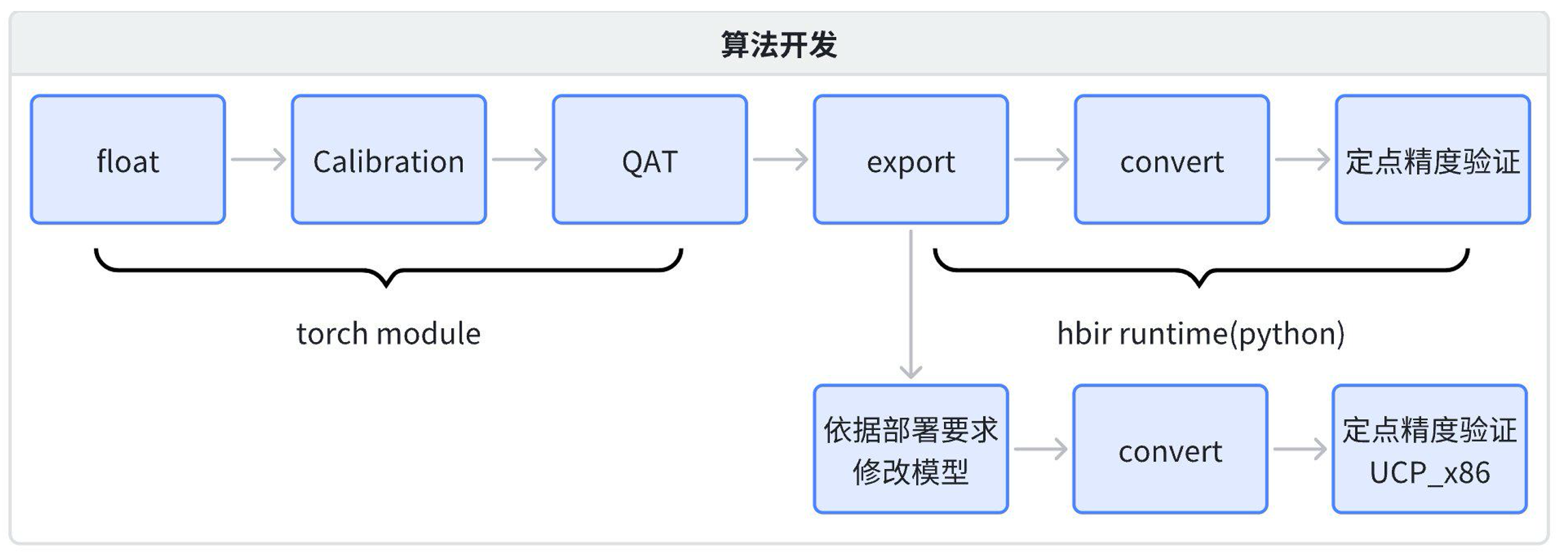
推荐依据上面流程图所示的方式进行J6模型开发:
-
若要确认部署模型精度指标是否达标,建议测试convert后的模型,有两种方案:
-
方案1:使用python api,复用python端前后处理,在cpu集群上评测quantized.bc
-
方案2:使用UCP_x86版本,使用部署前后处理代码,在cpu集群上评测quantized.bc(在x86端推理quantized.bc比.hbm快,推理代码与hbm完成一致)
-
2.3 模型修改及编译
因为实际部署中Pyramid输出数据都是独立的内存,为了简化实现、贴合部署,J6计算平台不再支持batchN pyramid输入(即不支持推理shape第一维不等于1的pyramid/resizer模型),图像输入类模型仅支持独立地址部署。非图像输入模型支持batchN(连续地址),也支持通过拆分batch来实现独立地址部署。
本章除2.3.1节ptq与qat链路导出.bc的方式有区别之外,2.3.2 - 2.3.5的内容不区分.bc的量化方式
由于PTQ链路默认不保存convert之前的.bc文件,若用户需要基于.bc做一些修改,可使用如下方式将ptq_model.onnx转为.bc:
from hbdk4.compiler.onnx import export from hbdk4.compiler import save import onnx onnx_model = onnx.load("ptq_model.onnx") model = export(onnx_model, name="my_model") save(model, "ptq_model.bc")
2.3.1 指定模型输入输出节点名称
2.3.1.1 QAT
由于 export 后的 *.bc 模型输入/输出节点name的生成规则与J5 hbm不同,因此若需要尽可能复用J5的工程代码,则建议在 export 时指定一下模型的输入输出节点的name,同时也便于有多个输入/输出节点shape一样时,可以通过*.bc 或者 *.hbm 模型的name辨别与torch模型之间的对应关系:
from horizon_plugin_pytorch.quantization.hbdk4 import export
hbir_qat_model = export(base_model, example_input, name="my_model", input_names=("input_name1","input_name2"), output_names=("output_name1","output_name2"), native_pytree=False)
# ps:export的name参数,可用于指定模型名称,即工程部署时的 model name字段若想生成的bc文件输入格式与之前版本保持一致,则建议在export过程中设置 native_pytree=False
2.3.2 多Batch拆分
该操作请在 convert 前完成,且需要在调整输入数据来源之前完成。
典型应用场景:BEV模型在部署时,多V输入来源于不同的摄像头,因此需要将pyramid输入节点沿batch维度做拆分。
from hbdk4.compiler import load
model = load("qat_model.bc")
func = model[0]
# 依据部署需要,维护一个独立地址部署的输入节点名称列表,或index列表
# 输入节点名采用上一节的方式进行了自定义修改
batch_input = ["input_name1"]
# 为和历史版本保持兼容,建议使用flatten_inputs将输入展开,如下代码同时兼容新旧版本模型:
for input in func.flatten_inputs[::-1]:
if input.name in batch_input:2.3.3 输入数据前处理
该操作请在 convert 前完成
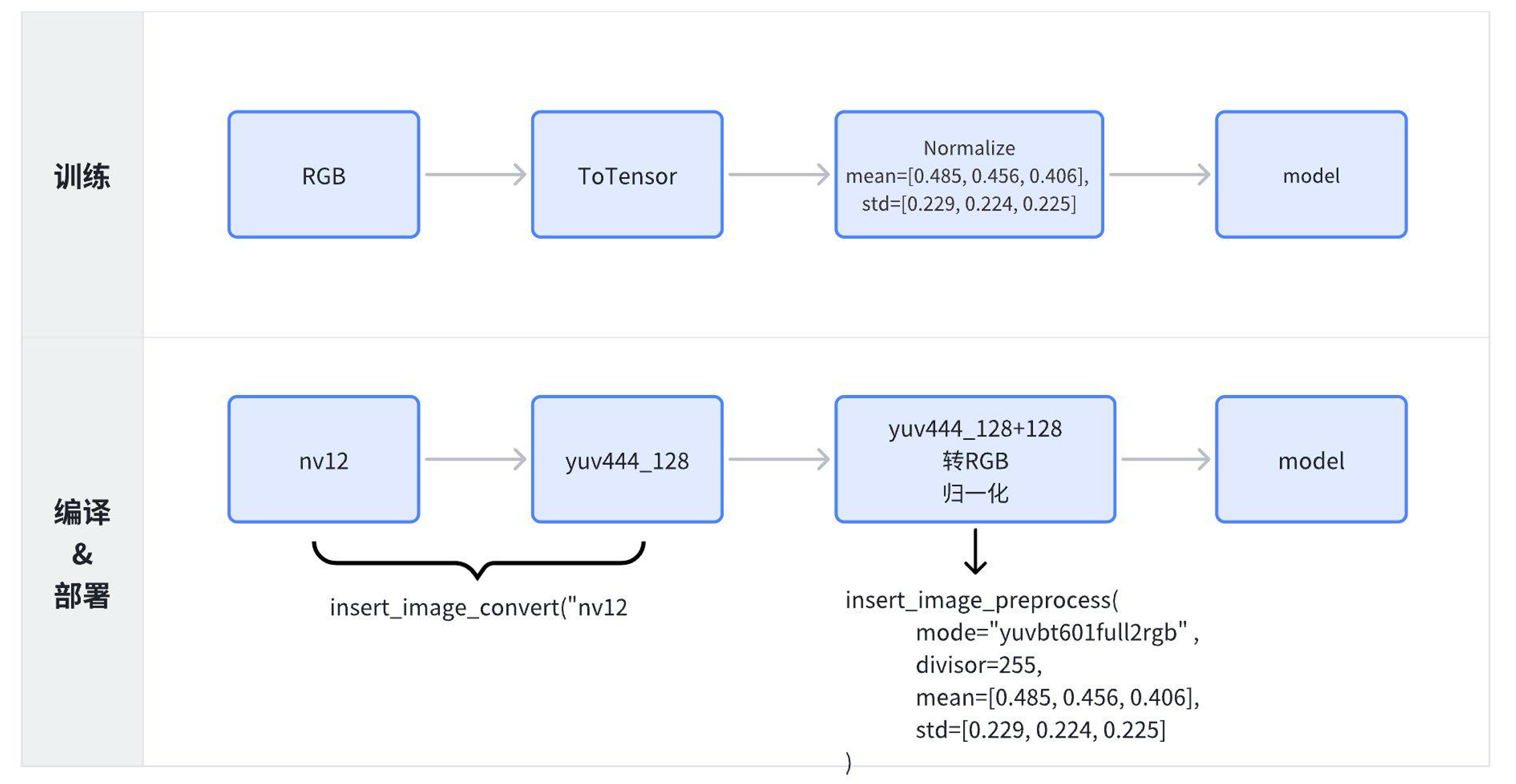
resizer_input = ["resize"] # 部署时数据来源于resizer的输入节点名称列表
pyramid_input = ["pym"] # 部署时数据来源于pyramid的输入节点名称列表
# 为和历史版本保持兼容,建议使用flatten_inputs将输入展开,如下代码同时兼容新旧版本模型:
for input in func.flatten_inputs[::-1]:
if input.name in pyramid_input:
# pyramid&resizer 只支持 NHWC 的 input layout,若原始输入layout为NHWC,则无需插入transpose
node = input.insert_transpose(permutes=[0, 3, 1, 2])
# 插入前处理节点,具体可参考下一节的说明
node = node.insert_image_preprocess(mode=None, divisor=1, mean=[128, 128, 128], std=[128, 128, 128])insert_image_preprocess 方法包括以下参数:
-
mode,可选值包含:
-
"yuvbt601full2rgb" YUVBT601Full 转 RGB (默认)
-
"yuvbt601full2bgr" YUVBT601Full 转 BGR
-
"yuvbt601video2rgb" YUVBT601Video 转 RGB 模式
-
"yuvbt601video2bgr" YUVBT601Video 转 BGR 模式
-
"bgr2rgb" BGR转RGB
-
"rgb2bgr" RGB 转 BGR
-
"skip" 不进行图像格式的转换,仅进行 preprocess 处理
-
-
数据转换除数divisor,int 类型,默认为 255
-
均值mean,double 类型,长度与输入c方向对齐,默认为 0.485, 0.456, 0.406
-
标准差值std,double 类型,长度与输入c方向对齐,默认为 0.229, 0.224, 0.225
迁移注意事项:
插入前处理节点后输入数据处理流程如下:
部署输入数据 -> 色彩转换 -> 数据格式转换 (int 转 float, 即除 divisor) -> 减均值 mean -> 除标准差 std -> 输出(数据类型为 float)-> 量化 ->model
由于hbdk4-compiler ≥ 4.1.2的insert接口返回了新节点,因此可基于返回值连续修改模型输入节点信息,例如我们可以将batch拆分和插入输入数据前处理的步骤联合起来做:
from hbdk4.compiler import load
model = load("qat_model.bc")
func = model[0]
batch_input = ["input_name1"] # 需要使用独立地址方式部署的输入节点名称列表
resizer_input = ["resize"] # 部署时数据来源于resizer的输入节点名称列表
pyramid_input = ["pym"] # 部署时数据来源于pyramid的输入节点名称列表
def channge_source(input, source):
node = input.insert_transpose(permutes=[0, 3, 1, 2])2.3.4 调整输入输出数据排布
浮点训练时通常模型输入输出均为NCHW(在GPU上,NCHW格式通常比NHWC格式跑得更快),但是部署时可能模型输入/输出更改为NHWC会使得前后处理代码的实现更高效,优先建议在deploy model中通过添加transpose修改输入输出排布。也可在导出qat.bc之后通过 insert_transpose 接口在模型首尾处插入transpose 节点来改变其数据排布:
from hbdk4.compiler import load
model = load("model.bc")
func = model[0]
# 在第一个输入节点后插入transpose节点,将原NCHW的输入,修改成NHWC
func.inputs[0].insert_transpose(permutes=[0, 3, 1, 2])迁移注意事项:
-
插 transpose 节点建议在 convert 之前完成;
-
请注意正确配置 transpose 的维度变换顺序,例如:
-
模型输入:NHWC ---> transpose0,3,1,2 ---> NCHW ---> model
-
模型输入:NCHW ---> transpose0,2,3,1 ---> NHWC ---> model
-
模型输出:model ---> NCHW ---> transpose0,2,3,1 ---> NHWC
-
2.3.5 算子删除
该操作需要在 convert 后完成,因为 convert 前模型都还是浮点输入输出,没有生成量化反量化节点:
quantized_model = convert(qat_model, march)
# remove_io_op会递归删除所有可被删除的节点
quantized_model[0].remove_io_op(op_types = ["Dequantize","Quantize","Cast","Transpose","Reshape"])若进行了删除动作,需要在后处理中根据业务需要进行功能补全,例如实现量化、反量化的逻辑。
OE3.0.31版本支持使用VPU推理量化反量化,只需在conver时启用vpu即可
quantized_model = convert(qat_model, march, enable_vpu=True)量化计算参考代码:
quantized_x = clamp(floor(x / scale + 0.5), -128, 127)
uint8_t quantize_core(float input, float scale, int32_t zero_point) {
int quantized_data = std::nearbyint(input / scale + zero_point);
return static_cast(std::min(std::max(0, quantized_data), 255));
}Tips1:
当前qat链路的op.name较为冗长,难以通过remove_io_op(op_names=\[\])来删除指定节点,可暂时采用下面的临时方案删除与某输入/输出节点直接相连的节点:
def remove_op_by_ioname(func, io_name=None): for loc in func.inputs + func.outputs: if not loc.is_removable[0]: continue attached_op = loc.get_attached_op[0] removed = None output_name = attached_op.outputs[0].name input_name = attached_op.inputs[0].name if io_name in [output_name, input_name]: removed, diagnostic = loc.remove_attached_op()Tips2:
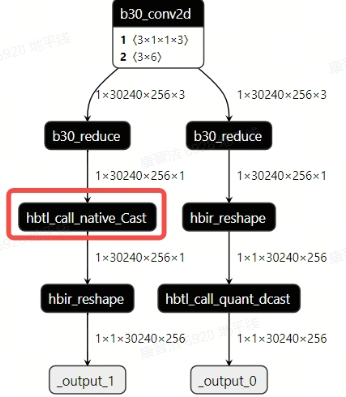
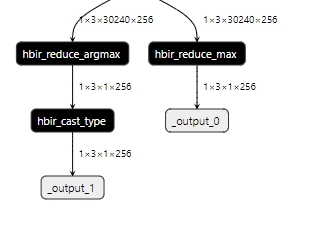
当前argmax节点的输出结构由于reshape在cast之后(如下图所示),因此无法直接通过remove_io_op删除cast,建议用户依据执行argmax操作维度的尺寸,在torch模型中将输出的index cast到对应数据类型再导出onnx/.bc,则convert后argmax将直接以对应精度输出,不会存在cast节点。
示例:
对dim=2求max,index最大值为30239(超出int8表示范围了),则尾部插入cast转int16
value, index = torch.max(scores, dim=2, keepdim=True) return value,index.to(torch.int16)qat.bc模型结构
convert后的模型结构:
2.4 性能测试及调优
使用hb_compile工具编译模型会默认生成静态性能评估文件(.html & .json)。若需要自行评测某模型的性能,具体可参考后文介绍:
2.4.1 静态性能评测
from hbdk4.compiler import hbm_perf
hbm_perf("xxx.hbm")
"""
hbdk4.compiler.hbm_tools.hbm_perf(model: str, output_dir: str = None):
model (str): Hbm model file name
output_dir (str): Output directory to hold the results, default to the current path
"""2.4.2 动态性能评测
由于Pyramid和Resizer模型中存在一些动态的属性,因此使用hrt_model_exec perf工具评测时需要指定一下这些属性。非图像输入类模型则沿用J5的评测命令即可:
ps:为了提高用户评测效率,工具内部自动依据模型输入大小计算了最小stride
hrt_model_exec perf --model_file pyramid.hbm hrt_model_exec perf --model_file resizer.hbm --input_file=test.jpg,test.jpg,roi.txt --input_img_properties=Y,UV
2.4.2.1 Pyramid输入
stride计算方式(W32对齐):
// 假设tensor输入尺寸valid_shape=(1,112,112,2,),tensor_type=HB_DNN_TENSOR_TYPE_U8,stride= (-1,-1,2,1,)
// stride[3]=sizeof(tensor_type) -> 1
// stride[2]=stride[3]*valid_shape[3] -> 2
// stride[1]=ALIGN_32(stride[2]*valid_shape[2]) -> 2*112=224
// stride[0]=stride[1]*valid_shape[1] -> 224*112=25088
#define ALIGN_32(value) ((value + (32-1)) & ~(32-1))perf命令(Pyramid输入的模型其stride为动态,可以不用指定,工具会自动计算):
假设模型输入尺寸为Y=(1,224,224,1),UV=(1,112,112,2,)
hrt_model_exec perf --model_file pyramid.hbm --input_stride="50176,224,1,1;25088,224,2,1"2.4.2.2 Resizer输入
由于Resizer输入的模型其stride以及valid_shape均为动态,且模型性能与roi参数相关,需要用户提供真实的推理数据和roi信息。若提供的Y和UV数据为jpg图像,则需要通过input_img_properties参数指定该图片需要处理成的数据格式。若指定的input_valid_shape与jpg图像尺寸不符,则工具会将原图resize至指定尺寸。
perf命令:
假设希望评测的是原图尺寸为HxW=300x300,ROI=(0,0,200,200)下的性能数据,则perf命令如下所示(valid_shape和stride可以不用指定,工具会自动计算)::
hrt_model_exec perf --model_file=mobilenetv1_224x224_resizer.hbm --input_file=1.jpg,1.jpg,roi.txt --input_img_properties=Y,UV --input_valid_shape="1,300,300,1;1,150,150,2" --input_stride="96000,320,1,1;48000,320,2,1"roi.txt(使用空格隔开:left top right bottom):
0 0 200 2002.5 精度测试及调优
2.5.1 PTQ
PTQ精度debug工具J6与J5使用方式一致,精度分析推荐流程也一致,具体请参考社区文章 精度验证及调优建议流程。有区别之处在于J6平台的定点模型(*_quantized_model.bc)是hbir格式,其推理方式如下所示:
import numpy as np
# 加载地平线依赖库
from horizon_tc_ui.hb_runtime import HBRuntime
# 准备模型运行的输入,此处`input.npy`为处理好的数据
data = np.load("input.npy")
# 加载模型文件,根据实际模型进行设置
# ONNX模型
sess = HBRuntime("model.onnx")
# HBIR模型2.5.2 QAT

在J6计算平台上,若使用新的prepare接口,默认会调用check_qat_model,在prepare之后会生成model_check_result.txt文件。
-
通过model_check_result.txt检查模型qconfig配置是否正确、是否有未融合的结构以及对精度不友好的共享模块。
-
验证全 int16 精度调优,确认模型的精度上限,排查工具使用问题和量化不友好模块。若int16不达标,则建议先观察模型中每层的数据分布范围,若的确存在数值范围超出int16的计算,则代表该模型可能需要引入部分fp16的计算(若能通过优化算法将数值范围控制在更小的区间,则对性能和精度都会更加友好)。
-
使用debug工具分析节点敏感度,依据敏感度配置模型中需要使用int16的比例。
需要注意的是,J5计算平台的定点模型是torch module/torch script格式,而J6计算平台则是hbir格式(*.bc),推理hbir和.hbm的代码如下所示:
2.5.2.1 pyramid输入
from hbdk4.compiler import load, Hbm
import numpy as np
import cv2
import torch
hbir = load("./model_output/mobilenetv1_224x224_nv12_quantized_model.bc")
img = "../../01_common/test_data/cls_images/zebra_cls.jpg"
def image2nv12(image):
image = image.astype(np.uint8) 2.5.2.2 resizer输入
from hbdk4.compiler import load, Hbm
import numpy as np
import cv2
import torch
hbir = load("./model_output/mobilenetv1_224x224_resizer_quantized_model.bc")
img = "../../01_common/test_data/cls_images/zebra_cls.jpg"
def image2nv12(image):
image = image.astype(np.uint8) 2.6 工具
|-------------------------|--------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------|
| 工具名称 | J6 | J5 |
| hb_perf | 无。只提供python api : from hbdk4.compiler import hbm_perf hbm_perf("xxx.hbm") | 静态性能分析工具 |
| hb_pack | 暂无。 | 打包*.bin |
| hb_model_info | 查看*.hbm和*.bc编译时的依赖及参数信息、*.onnx模型基本信息,查询*.bc可删除节点。可视化通过添加-v参数即可(hbir和hbm都支持) | 查看*.bin编译时的依赖及参数信息 |
| hb_verifier | 支持onnx模型之间、onnx模型与hbir模型之间以及hbir与hbm之间的一致性对比。具体使用说明请参考用户手册-训练后量化(PTQ)-PTQ转换工具-hb_verifier工具 章节内容 | 使用方式见社区文章第1.3.2节:https://developer.horizon.cc/forumDetail/71036815603174578 |
| hb_model_modifier | 无。 节点删除功能的yaml配置方式与J5一致(递归删除),也可参考前文2.3.5节修改.bc模型 | 支持通过name和type按特定顺序删除节点 |
| hb_custom_op | 无,功能合入hb_config_generator | 生成含有自定义OP模板的python文件 |
| hb_eval_preprocess | 使用方式同J5 | 用于生成ai_benchmark板端推理需要的输入数据 |
| hb_config_generator | J6新增,生成最简yaml或者全量yaml模版。 生成自定义OP模板的python文件 | 无 |
| vec_diff | 无 | 使用较少,通常通过yaml文件中的output_nodes截断模型来定位一致性问题 |
2.7 应用开发
由于J6系列计算平台通用性提高,因此为了适应更广泛的模型推理,参考python对数据的定义方式:
- 提供整数(int)、浮点数(float)、布尔值(bool)等基础数据类型的支持,移除部分特殊数据类型:
|---------------|---------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------|
| 类型 | 变更内容 | 变更说明 |
| hbDNNDataType | 移除枚举类型: HB_DNN_IMG_TYPE_Y HB_DNN_IMG_TYPE_NV12 HB_DNN_IMG_TYPE_NV12_SEPARATE HB_DNN_IMG_TYPE_YUV444 HB_DNN_IMG_TYPE_RGB HB_DNN_IMG_TYPE_BGR | pym/resizer输入都作为普通 tensor,不再区分图像类型 |
-
通过stride(步长)来定义内存中元素之间的存储间隔(用户通过该参数可创建非连续的数据存储方式,例如实现图像输入在内存中以二维形态存储,并通过stride参数来完成添加/移除padding的相关操作)。不再提供"layout"信息。
-
通过valid_shape来获取tensor的维度和每个维度有效数据的大小。
-
用户通过stride和valid_shape信息来计算对齐后的每个维度的大小,不再提供aligned_shape信息。
即hbDNNTensorProperties结构体做出如下调整
|-----------------------|-----------------------------------------------------------------------|----------------------------------------------|
| 类型 | 变更内容 | 变更说明 |
| hbDNNTensorProperties | 移除枚举字段alignedShape | 属性和stride重叠 |
| hbDNNTensorProperties | 移除枚举字段tensorLayout | 模型不再感知layout,完全由用户自己决定,此字段废弃 |
| hbDNNTensorProperties | 移除枚举字段shift | 无该量化方式 |
| hbDNNTensorProperties | 字段类型调整 alignedByteSize int32_t -> int64_t stride int32_t -> int64_t | 考虑到大模型的引入,int32_t已经没办法表示完整的值域大小,因此扩展到int64_t |
- 每个Tensor仅对应一个内存地址:
|-------------|-----------------------------|-----------------------------------------------|
| 类型 | 变更内容 | 变更说明 |
| hbDNNTensor | 字段调整 sysMem4 -> sysMem | 以往这个数组是为了支持nv12输入的,最新的接口已经不支持这种类型输入,因此不需要数组类型 |
2.7.1 图像输入(重要)
J6 工具链为了设计更好的图像输入的部署实现逻辑,对图像输入模型的部署流程进行了一些优化,例如插入Pyramid输入节点或Resizer节点后模型的Input Nodes将发生变化,以及Padding、Stride的规则有新的变化,详细内容请阅读用户手册**【板端部署实践指导】与【UCP-模型推理开发】**章节。
2.7.2 非图像输入
推荐使用UCP新的推理接口,该接口可用于灵活创建同步/异步的推理任务,并通过连续创建任务的方式实现批量推理,只返回一次中断的推理方式:
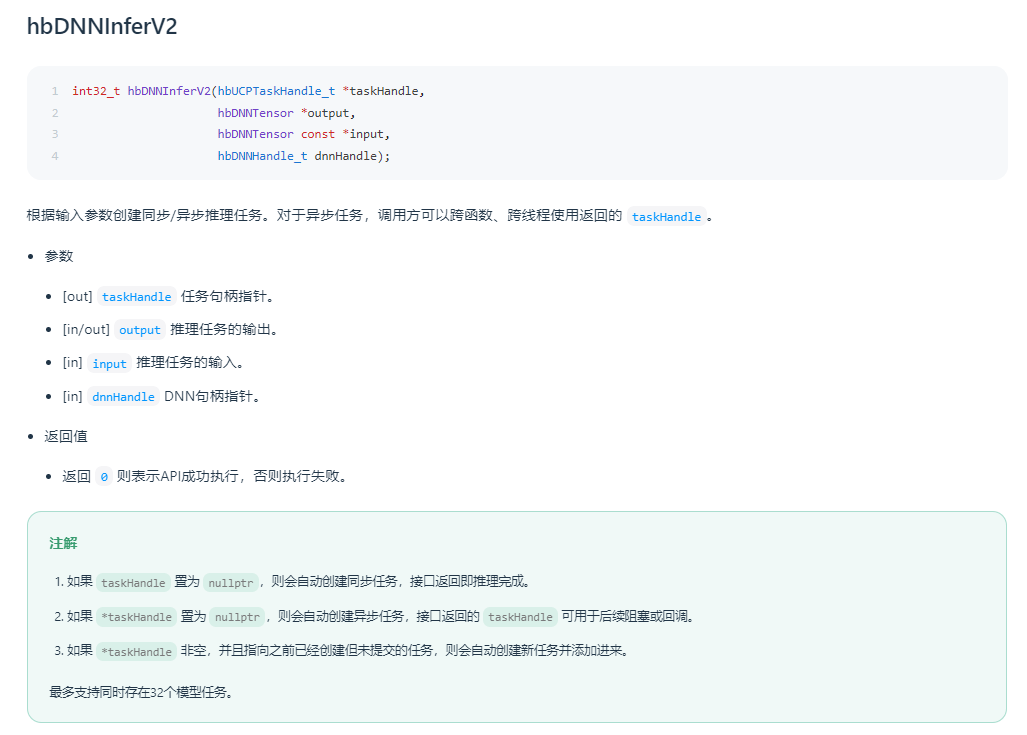
再配合任务提交接口即可完成模型推理任务。