一、引言
在完成了线性回归、逻辑回归以及梯度下降的学习之后,我们已经能够训练一个模型。但一个更重要的问题随之而来:
模型效果不好,到底是哪里出了问题?
本篇笔记将围绕以下四个核心内容展开:
-
偏差与方差的诊断(Bias & Variance)
-
正则化对偏差与方差的影响
-
基准性能水平(Baseline)的建立
-
学习曲线(Learning Curves)的分析方法
这些内容是模型调优的核心基础。
二、偏差与方差(Bias & Variance)
2.1 什么是偏差与方差?
在机器学习中,我们通常用两个指标来描述模型问题:
-
偏差(Bias):模型过于简单,无法拟合数据(欠拟合)
-
方差(Variance):模型过于复杂,对训练数据拟合过度(过拟合)
2.2 如何判断偏差与方差?
我们通过两个误差来进行判断:
-
训练误差:
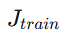
-
验证误差:
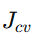
常见判断如下:
| 情况 | |
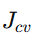 |
结论 |
|---|---|---|---|
| 都很高 | 高 | 高 | 高偏差(欠拟合) |
| 差距大 | 低 | 高 | 高方差(过拟合) |
| 都很低 | 低 | 低 | 模型良好 |
关键思想:
模型是否学会训练数据(看
模型是否泛化到新数据(看
三、正则化与偏差方差
3.1 什么是正则化?
正则化的作用是限制模型复杂度,防止过拟合。
常见形式(L2 正则化):
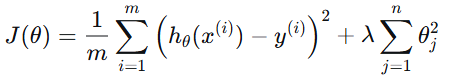
其中:
- λ:正则化强度
3.2 正则化对模型的影响
| λ大小 | 模型情况 | 偏差 | 方差 |
|---|---|---|---|
| λ很小 | 模型复杂 | 低偏差 | 高方差 |
| λ很大 | 模型简单 | 高偏差 | 低方差 |
结论:
正则化是调节偏差-方差平衡的重要工具
四、建立基准性能水平(Baseline)
4.1 为什么需要 Baseline?
在实际问题中,我们不能只看误差大小,还需要一个参考标准。
比如:
-
人类水平错误率
-
现有系统表现
-
简单模型效果
4.2 如何使用 Baseline?
我们通常用 Baseline 来判断:
-
当前模型是否还有提升空间
-
是不是已经接近最优
4.3 结合 Bias 判断
| 情况 | 判断 |
|---|---|
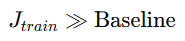 |
高偏差 |
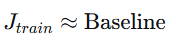 |
偏差正常 |
关键理解:
偏差不是绝对的,而是相对于可达到的最好水平
五、学习曲线(Learning Curves)
5.1 什么是学习曲线?
学习曲线描述的是:
-
训练误差
-
验证误差
随着训练样本数量变化而变化的趋势。
5.2 两种典型情况
情况1:高偏差(欠拟合)
特点:
-
高
-
高
-
两者接近
表现:
- 增加数据没有明显帮助
情况2:高方差(过拟合)
特点:
-
低
-
高
-
差距大
表现:
- 增加数据可以明显改善
5.3 学习曲线的核心作用
用来判断:
-
是否需要更多数据
-
是否需要更复杂模型
-
是否需要正则化
六、整体总结
我们可以把本章内容总结为一个完整流程:
-
训练模型,得到
和 -
与 Baseline 对比,判断偏差
-
比较
与 ,判断方差 -
根据问题选择优化方向:
| 问题 | 解决方案 |
|---|---|
| 高偏差 | 增加模型复杂度、减少正则化 |
| 高方差 | 增加数据、加强正则化 |