在实际开发中,单表查询远不能满足复杂业务需求 ------ 员工信息散落在员工表、部门表、薪资等级表中,需要跨表关联才能获取完整数据;统计分析时需嵌套查询筛选条件;多结果集合并需用到集合操作符。本文全面拆解 MySQL 复合查询的核心玩法,包括多表查询、自连接、子查询、合并查询,所有 SQL 均采用小写形式,贴合开发规范,附带实战案例和避坑要点
一. 基础回顾:复合查询的前置知识
在学习复杂复合查询前,先回顾基础查询的核心语法,为后续进阶打基础:
sql复制代码
-- 1. 条件筛选:工资>500或岗位为manager,且姓名首字母为J
select * from emp where (sal>500 or job='manager') and ename like 'j%';
-- 2. 多字段排序:部门号升序,工资降序
select * from emp order by deptno asc, sal desc;
-- 3. 计算字段+排序:年薪(sal*12+补贴)降序
select ename, sal*12+ifnull(comm,0) as 年薪 from emp order by 年薪 desc;
-- 4. 聚合查询+筛选:各部门平均工资(保留2位小数)和最高工资
select deptno, format(avg(sal),2) as 平均工资, max(sal) as 最高工资 from emp group by deptno;
-- 5. having筛选聚合结果:平均工资低于2000的部门
select deptno, avg(sal) as avg_sal from emp group by deptno having avg_sal < 2000;
select 表别名1.字段, 表别名2.字段
from 表 表别名1, 表 表别名2
where 表别名1.关联字段 = 表别名2.关联字段 [and 筛选条件];
3.2 实战案例:查询员工的上级领导
需求:查询员工 ford 的上级领导编号和姓名(emp 表中mgr字段是领导的empno)
sql复制代码
-- 方法1:子查询(简单场景)
select empno, ename from emp
where empno = (select mgr from emp where ename='ford');
-- 方法2:自连接(复杂场景更灵活)
select leader.empno as 领导编号, leader.ename as 领导姓名
from emp leader, emp worker -- leader=领导表,worker=员工表
where leader.empno = worker.mgr -- 领导编号=员工的上级编号
and worker.ename = 'ford'; -- 筛选员工为ford
3.3 自连接关键技巧
必须给表起不同别名(如leader、worker),否则 MySQL 无法区分两张 "虚拟表";
关联字段需是表内的关联关系(如员工表的mgr与自身的empno)。
四. 子查询:嵌套查询的灵活用法
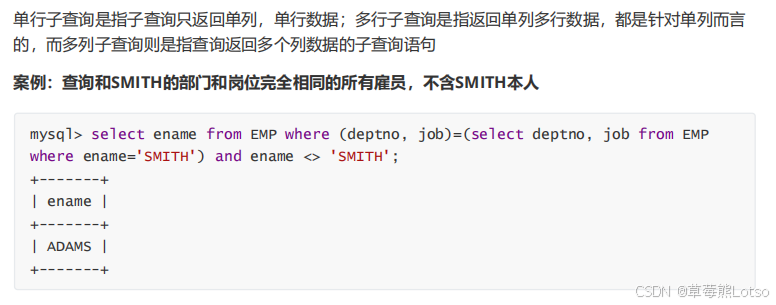
子查询(嵌套查询)是指嵌入在其他 SQL 语句中的 select 语句,按返回结果可分为单行、多行、多列子查询,按位置可分为 where 子句、from 子句中的子查询。
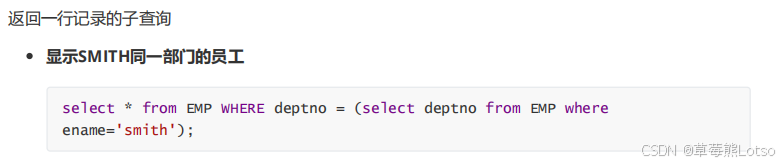
4.1 单行子查询:返回 1 行 1 列结果
适用于筛选条件为 "等于、大于、小于" 单个值的场景,常用比较运算符(=、>、<、>=、<=)。
实战案例:
需求:查询与 smith 同部门的所有员工(不含 smith)
sql复制代码
select * from emp
where deptno = (select deptno from emp where ename='smith') -- 子查询返回smith的部门号
and ename != 'smith'; -- 排除smith本人
select ename, job, sal, deptno from emp
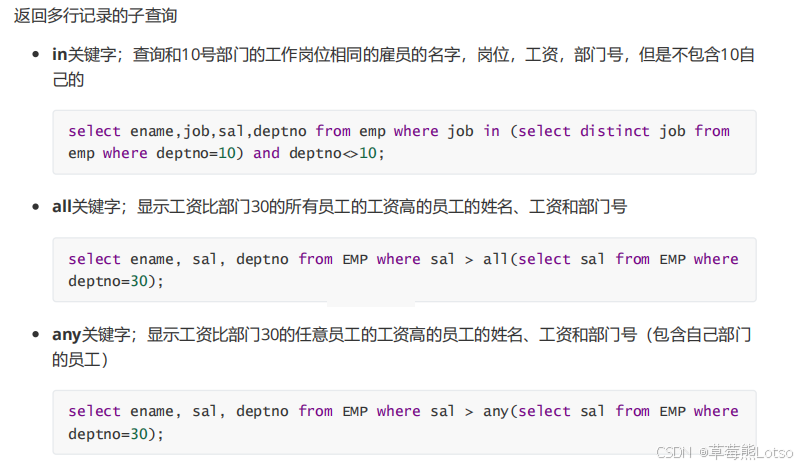
where job in (select distinct job from emp where deptno=10) -- 子查询返回10号部门的所有岗位
and deptno != 10; -- 排除10号部门
4.2.2 all 关键字:大于 / 小于所有值
需求:查询工资比 30 号部门所有员工工资都高的员工
sql复制代码
select ename, sal, deptno from emp
where sal > all(select sal from emp where deptno=30); -- 工资>30号部门所有员工工资
4.2.3 any 关键字:大于 / 小于任意一个值
需求:查询工资比 30 号部门任意员工工资高的员工(含自身部门)
sql复制代码
select ename, sal, deptno from emp
where sal > any(select sal from emp where deptno=30); -- 工资>30号部门至少一个员工工资
4.3 多列子查询:返回多行多列结果
适用于筛选条件需匹配 "多个字段组合" 的场景,子查询返回多列,主查询用括号接收字段组合。
实战案例:
需求:查询与 smith 部门和岗位完全相同的员工(不含 smith)
sql复制代码
select ename from emp
where (deptno, job) = (select deptno, job from emp where ename='smith') -- 匹配部门+岗位组合
and ename != 'smith';
4.4 from 子句中的子查询:临时表用法
将子查询结果当作 "临时表",用于复杂统计分析(如先聚合再关联),核心是给临时表起别名。
实战案例 1:查询高于本部门平均工资的员工
sql复制代码
select emp.ename, emp.deptno, emp.sal, format(tmp.asal,2) as 部门平均工资
from emp,
(select avg(sal) as asal, deptno as dt from emp group by deptno) tmp -- 临时表:各部门平均工资
where emp.deptno = tmp.dt -- 员工部门=临时表部门
and emp.sal > tmp.asal; -- 员工工资>部门平均工资
实战案例 2:查询各部门工资最高的员工
sql复制代码
select emp.ename, emp.sal, emp.deptno, tmp.ms as 部门最高工资
from emp,
(select max(sal) as ms, deptno from emp group by deptno) tmp -- 临时表:各部门最高工资
where emp.deptno = tmp.deptno
and emp.sal = tmp.ms;
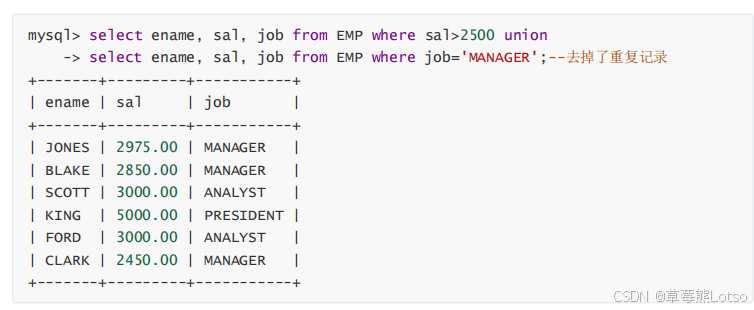
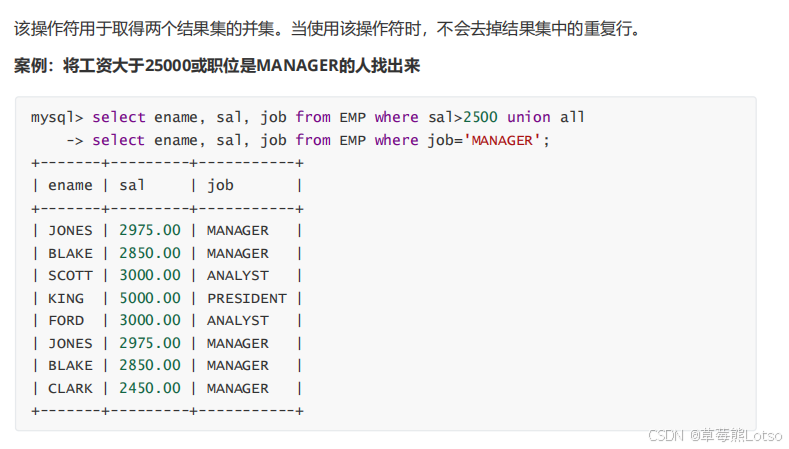
-- 去重合并(自动删除重复行)
select 字段 from 表1 where 条件
union
select 字段 from 表2 where 条件;
-- 不去重合并(保留重复行,性能更优)
select 字段 from 表1 where 条件
union all
select 字段 from 表2 where 条件;
select e.emp_no, s.salary
from employees e, salaries s
where e.emp_no = s.emp_no
and s.from_date = e.hire_date
order by e.emp_no desc;
真题 2:生成所有表的 count 查询语句
sql复制代码
select concat('select count(*) from ', table_name, ';') as count_sql
from information_schema.tables
where table_schema = 'your_database_name'; -- 替换为你的数据库名
真题 3:获取所有非 manager 的员工 emp_no
sql复制代码
select emp_no from employees
where emp_no not in(select emp_no from dept_manager);
真题 4:获取所有员工当前的 manager(排除 manager 是自己的情况)
sql复制代码
select e.emp_no, d.emp_no as manager
from dept_emp as e, dept_manager as d
where e.dept_no = d.dept_no
and e.emp_no != d.emp_no;
七. 总结
MySQL 复合查询是解决复杂业务需求的核心,核心要点总结:
多表查询:通过关联字段消除笛卡尔积,适用于跨表提取数据;
自连接:同表当作两张表,适用于表内关联(如员工与领导);
子查询:嵌套在 where/from 子句中,灵活筛选和统计,需注意单行 / 多行匹配规则;
合并查询:union(去重)和 union all(不去重),适用于多结果集合并;
避坑关键:关联字段一致、临时表起别名、优先选择高效语法(如 union all 替代 union)。