1. 研究背景
随着工业、能源、环境等领域数据采集技术的进步,多输入回归预测问题日益普遍。传统的统计回归方法难以处理复杂的非线性关系,而集成学习模型(如提升法)因其高精度和强泛化能力被广泛使用。最小二乘提升(LSBoost) 是一种基于决策树的集成学习方法,通过迭代拟合残差来提升预测性能。然而,其性能高度依赖于超参数(学习率、树数量、最小叶子节点数)的选取。人工调参费时费力且难以保证全局最优。哈里斯鹰优化算法(HHO) 是一种新型元启发式算法,模拟哈里斯鹰的捕食行为,具有收敛速度快、探索与开发平衡好的优点。将HHO用于LSBoost的超参数自动寻优,可有效提升模型预测精度与稳定性。
2. 主要功能
本代码实现以下核心功能:
- 读取多输入单输出的Excel数据;
- 自动划分训练集与测试集(默认80%训练,20%测试);
- 对特征和输出进行Z-score标准化;
- 利用HHO算法优化LSBoost的三个关键超参数:学习率、树数量、最小叶子节点数(基于5折交叉验证RMSE);
- 使用最优参数训练最终LSBoost模型;
- 评估训练集和测试集的预测性能(RMSE、MAE、R²);
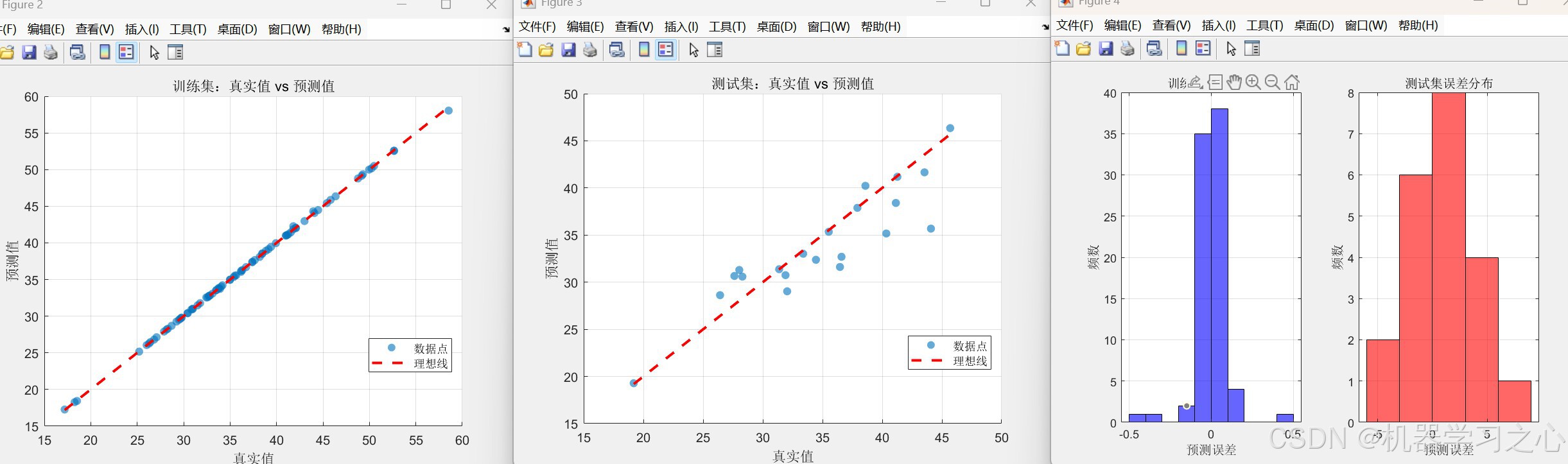
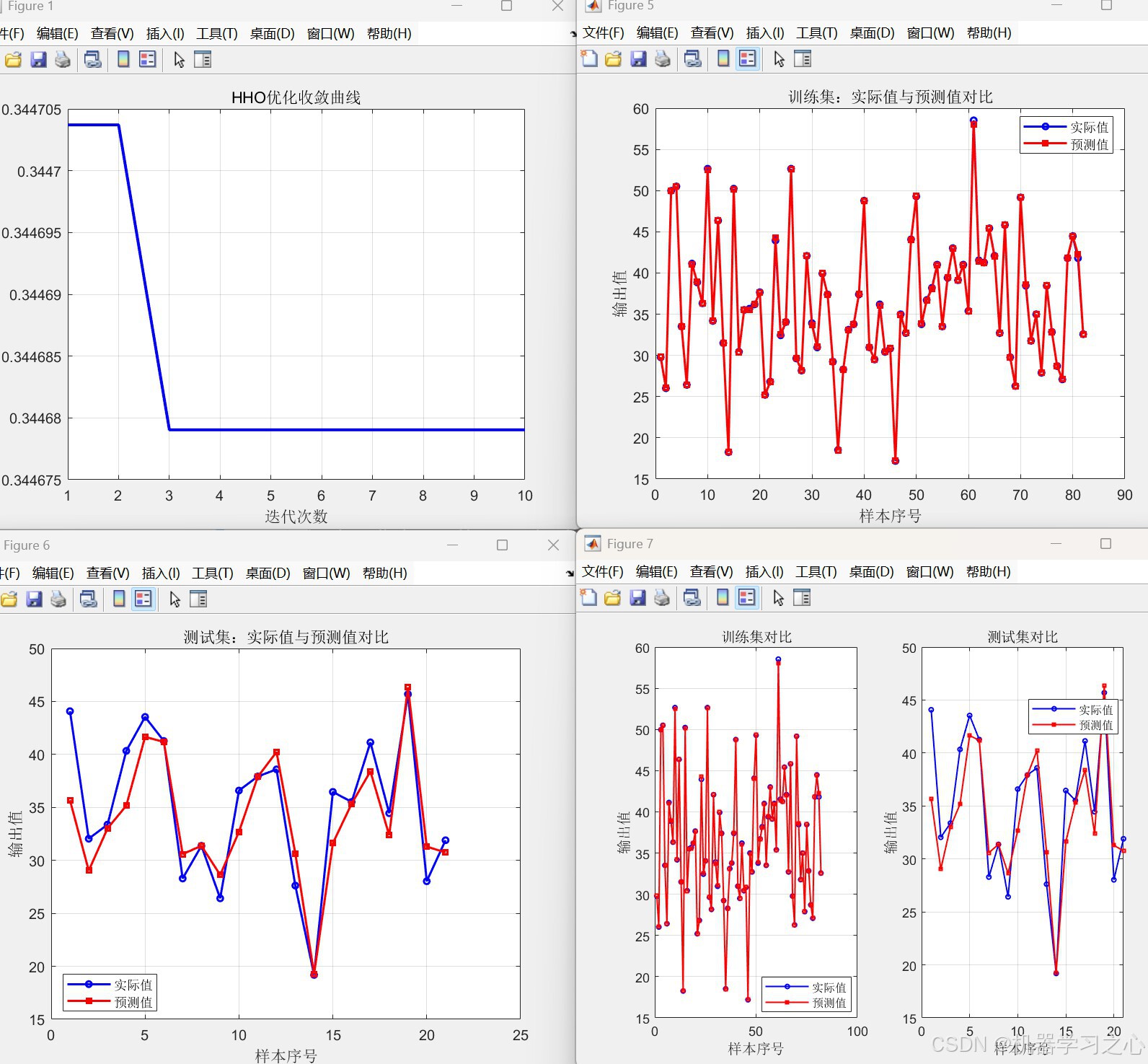
- 可视化:收敛曲线、真实值与预测值散点图、误差直方图、对比曲线图。
3. 算法步骤
代码执行流程可分为以下阶段:
-
数据预处理
- 读取Excel文件,分离特征(7列)与输出(1列)。
- 随机打乱样本顺序,按比例划分为训练集和测试集。
- 对训练集特征和输出进行Z-score标准化(均值0,标准差1),并记录标准化参数,用于测试集转换。
-
HHO超参数优化
- 定义优化变量维度(3维):学习率(lr,0.01,1)、树数量(nTree,10,500取整)、最小叶子节点数(minLeaf,1,50取整)。
- 初始化HHO种群(默认30个个体),每个个体对应一组超参数。
- 在每次迭代中,对每个个体:
- 使用当前超参数构建LSBoost模型(通过
fitrensemble和templateTree)。 - 进行5折交叉验证,计算验证集RMSE作为适应度(目标是最小化RMSE)。
- 使用当前超参数构建LSBoost模型(通过
- 更新全局最优个体及适应度。
- 根据HHO的探索与开发机制(包括软/硬包围、快速俯冲等)更新个体位置。
- 迭代直至最大迭代次数(默认50)。
- 记录收敛曲线。
-
最终模型训练与评估
- 提取HHO得到的最优超参数。
- 在全部训练集上训练LSBoost模型。
- 分别对训练集和测试集进行预测,并反标准化。
- 计算RMSE、MAE、R²指标。
-
结果可视化
- 绘制HHO收敛曲线。
- 绘制训练集与测试集的真实值vs预测值散点图(含理想线)。
- 绘制训练集与测试集的预测误差分布直方图。
- 绘制训练集与测试集的预测值与实际值对比曲线(按样本序号)。
4. 技术路线
| 阶段 | 技术方法 |
|---|---|
| 数据处理 | Z-score标准化,随机划分 |
| 优化算法 | 哈里斯鹰优化(HHO) |
| 代理模型 | 最小二乘提升(LSBoost) |
| 适应度评估 | 5折交叉验证均方根误差(RMSE) |
| 模型训练 | fitrensemble + templateTree(决策树模板) |
| 性能评价 | RMSE, MAE, R² |
| 可视化 | MATLAB绘图函数 |
5. 公式原理
5.1 最小二乘提升(LSBoost)
LSBoost是一种加法模型,每次迭代拟合当前残差,逐步减小误差。假设最终模型为:
Fm(x)=Fm−1(x)+ν⋅hm(x) F_m(x) = F_{m-1}(x) + \nu \cdot h_m(x) Fm(x)=Fm−1(x)+ν⋅hm(x)
其中 (h_m(x)) 是第 (m) 棵回归树,(\nu) 为学习率(收缩系数)。通过最小化平方损失函数训练树。集成最终输出为所有树输出的加权和。
5.2 哈里斯鹰优化算法(HHO)
HHO模拟哈里斯鹰的捕食过程,包括探索、开发和多种突袭策略。
-
能量更新 :
E=2E0(1−tT) E = 2E_0\left(1 - \frac{t}{T}\right) E=2E0(1−Tt)其中 E0∈(−1,1)E_0\in(-1,1)E0∈(−1,1)为初始能量,ttt为当前迭代,TTT为最大迭代。当 ∣E∣≥1|E|\ge 1∣E∣≥1时进入探索阶段,否则进入开发阶段。
-
探索阶段 (∣E∣≥1|E|\ge 1∣E∣≥1):
以概率 qqq 选择两种策略之一:
Xnew={Xrand−r1∣Xrand−2r2X(t)∣,q≥0.5(Xrabbit−Xm)−r3(LB+r4(UB−LB)),q<0.5 X_{\text{new}} = \begin{cases} X_{\text{rand}} - r_1 |X_{\text{rand}} - 2r_2 X(t)|, & q \ge 0.5 \\ (X_{\text{rabbit}} - X_m) - r_3 (LB + r_4(UB - LB)), & q < 0.5 \end{cases} Xnew={Xrand−r1∣Xrand−2r2X(t)∣,(Xrabbit−Xm)−r3(LB+r4(UB−LB)),q≥0.5q<0.5其中 XrandX_{\text{rand}}Xrand为随机个体,XrabbitX_{\text{rabbit}}Xrabbit为当前最优位置(猎物),X_m 为种群平均位置,r1∼r4r_1\sim r_4r1∼r4 为随机数。
-
开发阶段 (∣E∣<1|E| < 1∣E∣<1):
根据 (E) 和随机数 (r) 分为四种突袭方式:
- 软包围(∣E∣≥0.5,r≥0.5|E|\ge 0.5, r\ge 0.5∣E∣≥0.5,r≥0.5):Xnew=(Xrabbit−X(t))−E∣JXrabbit−X(t)∣X_{\text{new}} = (X_{\text{rabbit}} - X(t)) - E|JX_{\text{rabbit}} - X(t)|Xnew=(Xrabbit−X(t))−E∣JXrabbit−X(t)∣
- 硬包围(∣E∣<0.5,r≥0.5|E|<0.5, r\ge 0.5∣E∣<0.5,r≥0.5):Xnew=Xrabbit−E∣Xrabbit−X(t)∣X_{\text{new}} = X_{\text{rabbit}} - E|X_{\text{rabbit}} - X(t)|Xnew=Xrabbit−E∣Xrabbit−X(t)∣
- 带快速俯冲的软包围(∣E∣≥0.5,r<0.5|E|\ge 0.5, r<0.5∣E∣≥0.5,r<0.5):采用莱维飞行更新
- 带快速俯冲的硬包围(∣E∣<0.5,r<0.5|E|<0.5, r<0.5∣E∣<0.5,r<0.5):类似
其中 J=2(1−r5)J = 2(1 - r_5)J=2(1−r5)为跳跃强度,莱维飞行公式为:
LF(x)=0.01×u⋅σ∣v∣1/β,σ=(Γ(1+β)sin(πβ/2)Γ((1+β)/2)β2(β−1)/2)1/β \text{LF}(x) = 0.01 \times \frac{u \cdot \sigma}{|v|^{1/\beta}}, \quad \sigma = \left( \frac{\Gamma(1+\beta)\sin(\pi\beta/2)}{\Gamma((1+\beta)/2)\beta 2^{(\beta-1)/2}} \right)^{1/\beta} LF(x)=0.01×∣v∣1/βu⋅σ,σ=(Γ((1+β)/2)β2(β−1)/2Γ(1+β)sin(πβ/2))1/β
通常取 β=1.5\beta=1.5β=1.5,u,vu,vu,v 为标准正态分布。
5.3 适应度函数
采用5折交叉验证的均方根误差(RMSE):
RMSE=1nval∑i=1nval(yi−y^i)2 \text{RMSE} = \sqrt{\frac{1}{n_{\text{val}}}\sum_{i=1}^{n_{\text{val}}}(y_i - \hat{y}_i)^2} RMSE=nval1i=1∑nval(yi−y^i)2
其中 nvaln_{\text{val}}nval 为验证集样本数。适应度越小,参数越优。
6. 参数设定
| 参数类型 | 名称 | 值/范围 | 说明 |
|---|---|---|---|
| 数据划分 | 训练比例 | 0.8 | 训练集占比80% |
| 标准化 | 方法 | Z-score | 均值0,标准差1 |
| HHO | 种群规模 | 30 | 个体数 |
| 最大迭代 | 50 | 迭代次数 | |
| 优化维度 | 3 | 学习率、树数量、最小叶子节点数 | |
| 优化变量 | 学习率 | 0.01, 1 | 控制每棵树贡献 |
| 树数量 | 10, 500 | 集成中树的总数(取整) | |
| 最小叶子节点数 | 1, 50 | 决策树叶子最小样本数(取整) | |
| 交叉验证 | 折数 | 5 | K折交叉验证 |
| LSBoost | 方法 | LSBoost | 最小二乘提升 |
| 弱学习器 | 回归树 | 通过templateTree创建 |
|
| 随机种子 | rng(42) | 固定 | 确保结果可重复 |
7. 运行环境
- 软件:MATLAB R2018b 及以上版本(推荐R2020b以上)
- 工具箱 :
- Statistics and Machine Learning Toolbox(提供
fitrensemble、templateTree、kfoldLoss等) - MATLAB 基础功能(绘图、矩阵运算)
- Statistics and Machine Learning Toolbox(提供
- 硬件:建议内存 ≥ 8GB,CPU主频 ≥ 2.0 GHz(HHO迭代+交叉验证需要一定计算量)
8. 应用场景
本代码适用于多种多输入单输出的回归预测问题,典型应用包括:
- 工业过程控制:根据工艺参数预测产品质量指标(如浓度、纯度)。
- 能源系统:基于气象数据、设备参数预测光伏/风电功率。
- 环境监测:利用污染物浓度、气象因子预测空气质量指数(AQI)。
- 金融预测:结合多项经济指标预测股票指数或收益率。
- 生物医学:根据生理参数(血压、心率等)预测疾病风险评分。
通过HHO自动优化LSBoost超参数,可快速建立高精度预测模型,减少人工调参成本,尤其适合需要快速部署且要求高泛化能力的场景。
总结:本代码实现了哈里斯鹰优化算法与最小二乘提升模型的集成,形成一套完整的回归预测流程。用户只需准备好Excel数据(特征在前,输出在后),运行即可获得优化后的模型及评估结果,并可方便地应用于实际工程预测任务。