Shuffle 是 Spark 中代价最高的操作,也是最容易出现性能瓶颈的地方。理解 Shuffle 的完整机制------从触发条件、两阶段执行、历史演进到数据倾斜处理------是写出高性能 Spark 程序的必备基础。
目录
- [什么是 Shuffle,为什么代价高](#什么是 Shuffle,为什么代价高)
- [Shuffle 两阶段流程](#Shuffle 两阶段流程)
- [Shuffle 实现演进:Hash → Sort](#Shuffle 实现演进:Hash → Sort)
- [Sort Shuffle 内部机制详解](#Sort Shuffle 内部机制详解)
- [Spill 溢写机制](#Spill 溢写机制)
- [数据倾斜:Shuffle 最大的敌人](#数据倾斜:Shuffle 最大的敌人)
- [Shuffle 优化全攻略](#Shuffle 优化全攻略)
- 关键参数速查
什么是 Shuffle,为什么代价高
Shuffle 是数据在不同 Partition 间的重新分布过程。 当计算逻辑需要把具有相同 Key 的数据汇聚到同一个节点时(如 groupBy、join、repartition),数据必须跨节点网络传输,这个过程就叫 Shuffle。
触发 Shuffle 的本质是宽依赖 ------一个子 Partition 依赖多个父 Partition 的数据。


Shuffle 的四大代价
| 代价来源 | 说明 | 量级估算 |
|---|---|---|
| 磁盘 I/O | Map 端排序写文件,内存不足时 Spill 溢写 | 数据量的 1~3 倍磁盘写入 |
| 网络 I/O | Reduce 端从所有 Mapper 拉取数据块 | 跨节点传输全量 Shuffle 数据 |
| 序列化开销 | 数据写入磁盘前需序列化,读取后反序列化 | CPU 密集型 |
| GC 压力 | 大量对象创建导致频繁 GC | 严重时引起秒级 Stop-The-World |
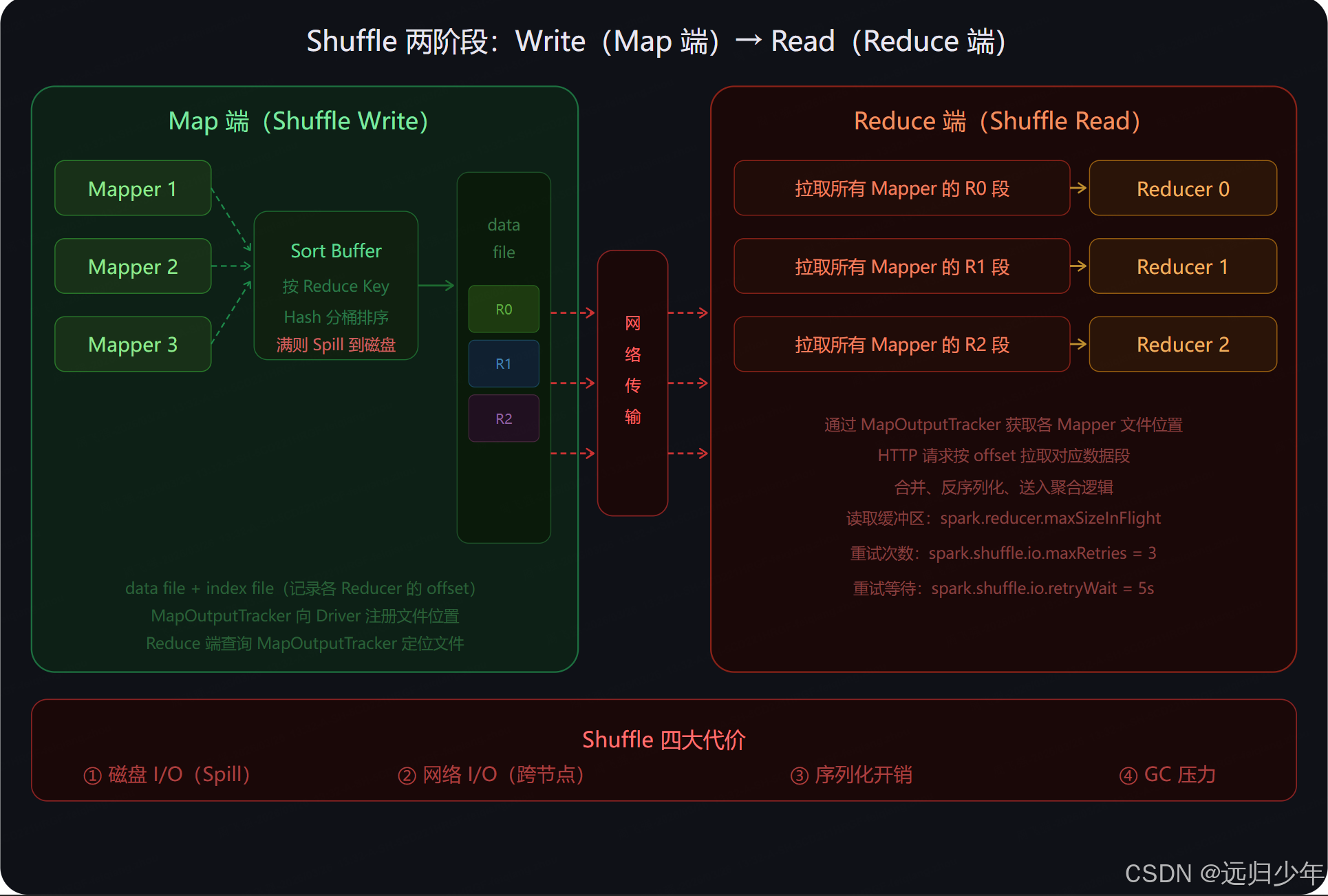
Shuffle 两阶段流程
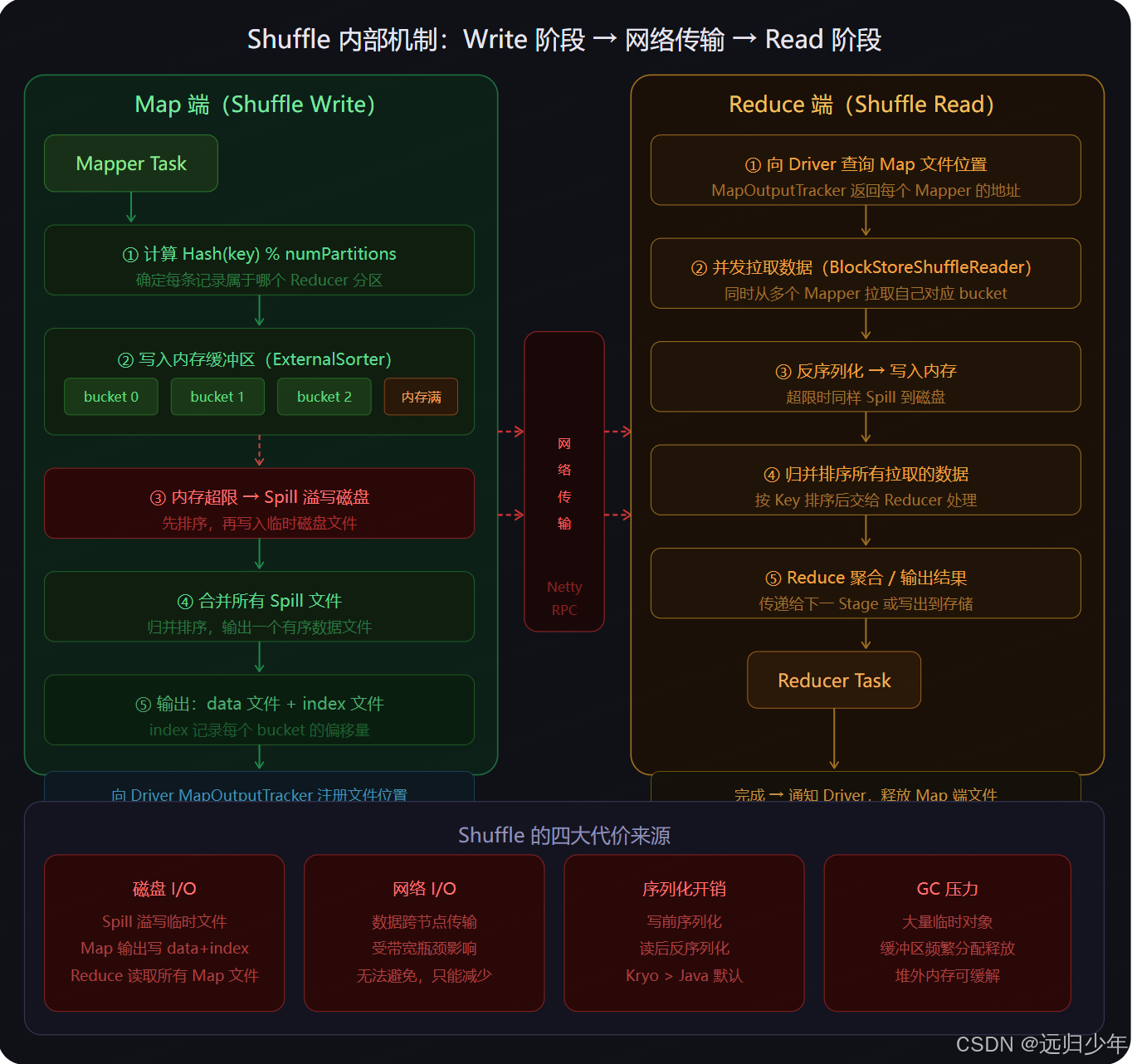
Shuffle 实现演进:Hash → Sort

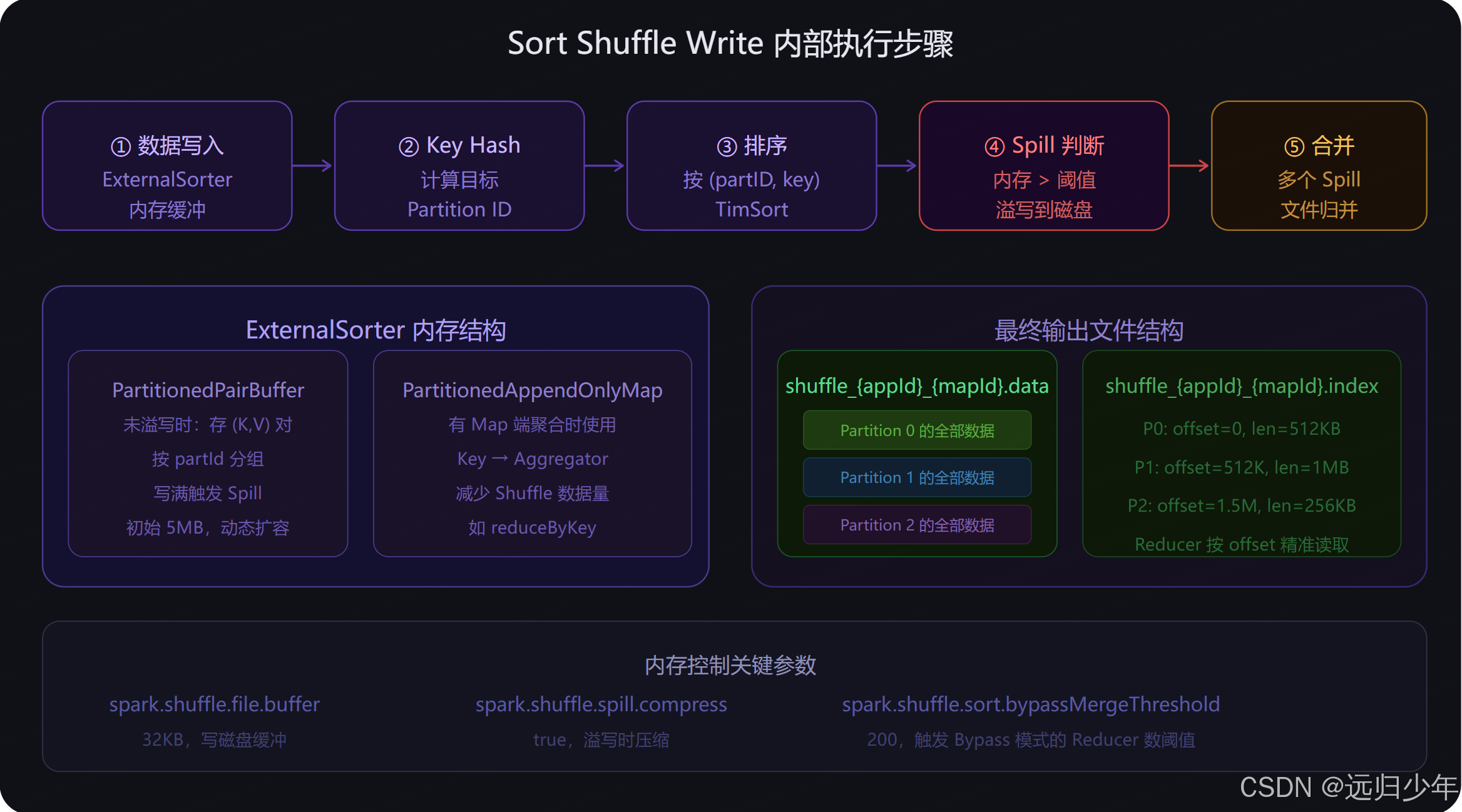
Sort Shuffle 内部机制详解
Spill 溢写机制
当 ExternalSorter 的内存缓冲超过阈值时触发 Spill,将当前内存中的数据排序后写入临时文件。一个 Mapper 可能产生多个 Spill 文件,最终在 Stage 结束时合并为一个输出文件。
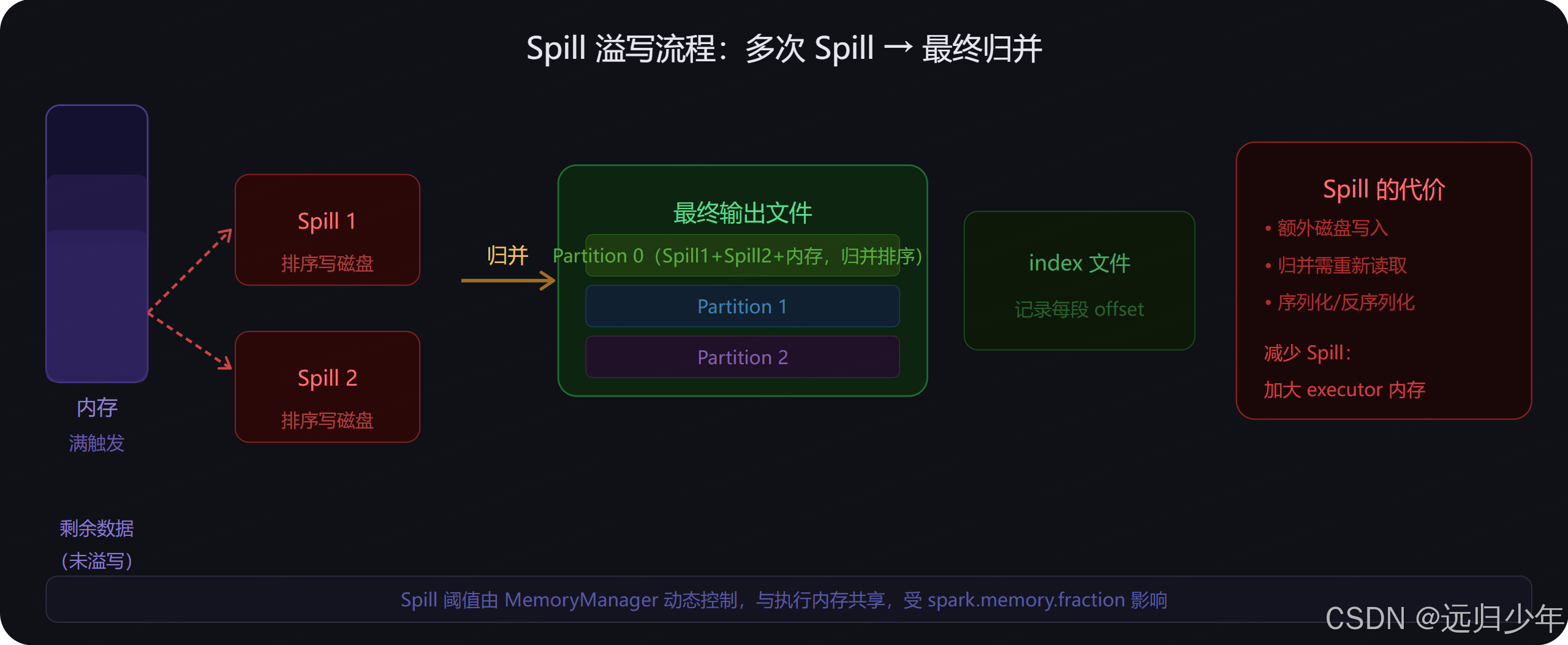
Spill 是性能调优的重要关注点。通过 Spark UI 的 Stage 详情页可以看到每个 Stage 的 Shuffle Spill (Memory) 和 Shuffle Spill (Disk) 指标,如果 Spill 量很大,说明内存不足,需要增加 Executor 内存或减小单个 Task 处理的数据量。
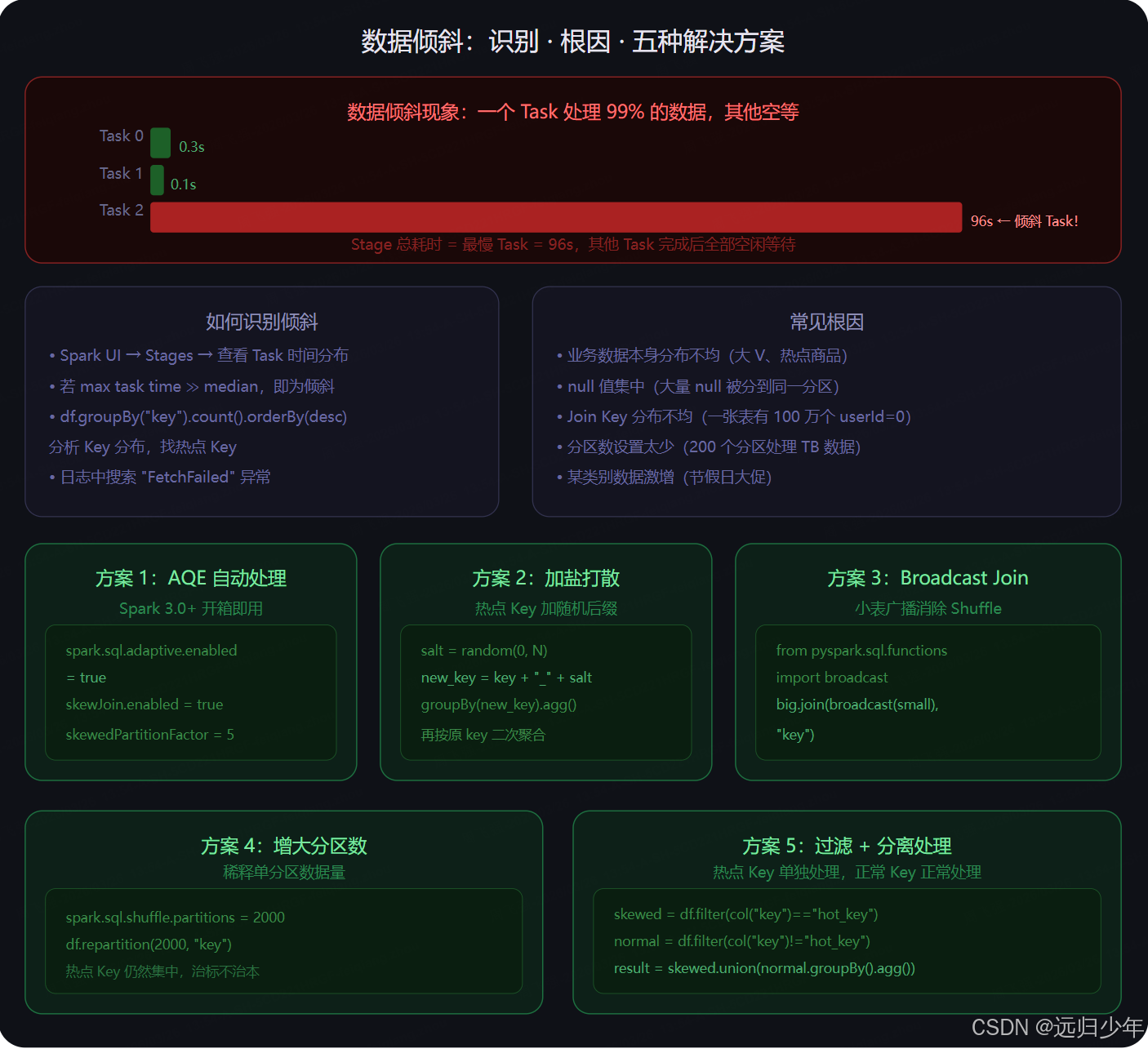
数据倾斜:Shuffle 最大的敌人

Shuffle 优化全攻略

核心代码示例
python
# ── 减少 Shuffle 次数:先过滤再 Shuffle ──
# 差(先 Shuffle 再 filter)
df.groupBy("city").agg(count("*")).filter(col("city") != "unknown")
# 好(先 filter 再 Shuffle,数据量减少)
df.filter(col("city") != "unknown").groupBy("city").agg(count("*"))
# ── reduceByKey 替代 groupByKey(Map 端预聚合)──
# 差:groupByKey 把所有数据发到 Reduce 端再聚合
rdd.groupByKey().mapValues(sum)
# 好:reduceByKey 在 Map 端先做局部聚合
rdd.reduceByKey(lambda a, b: a + b)
# ── 手动 Broadcast 消除 Shuffle ──
from pyspark.sql.functions import broadcast
large_df.join(broadcast(small_df), "id")
# ── 数据倾斜:Key 加盐 ──
import random
from pyspark.sql.functions import concat, lit, floor, rand
# Step 1:热点表加盐(随机 0~9 前缀)
skewed_df = df.withColumn("salted_key",
concat(lit(str(int(random.random() * 10))), col("key")))
# Step 2:小表复制 10 份
replicated_df = small_df.withColumn("replica",
explode(array([lit(str(i)) for i in range(10)]))) \
.withColumn("salted_key", concat(col("replica"), col("key")))
# Step 3:按盐化 Key join
result = skewed_df.join(replicated_df, "salted_key")关键参数速查
python
# ── Shuffle 核心参数 ──
spark.conf.set("spark.sql.shuffle.partitions", "200") # Shuffle 后分区数,重要!
spark.conf.set("spark.shuffle.file.buffer", "32k") # Map 端写文件缓冲
spark.conf.set("spark.reducer.maxSizeInFlight", "48m") # Reduce 端每次拉取缓冲
spark.conf.set("spark.shuffle.io.maxRetries", "3") # 拉取失败重试次数
spark.conf.set("spark.shuffle.io.retryWait", "5s") # 重试等待时间
spark.conf.set("spark.shuffle.compress", "true") # 压缩 Shuffle 数据(默认 true)
spark.conf.set("spark.shuffle.spill.compress", "true") # 压缩溢写数据(默认 true)
# ── Sort Shuffle 子模式阈值 ──
spark.conf.set("spark.shuffle.sort.bypassMergeThreshold", "200") # BypassMerge 触发阈值
# ── AQE 优化参数 ──
spark.conf.set("spark.sql.adaptive.enabled", "true") # 默认 true
spark.conf.set("spark.sql.adaptive.advisoryPartitionSizeInBytes", "64mb") # 合并目标大小
spark.conf.set("spark.sql.adaptive.skewJoin.enabled", "true") # 倾斜 Join 优化
spark.conf.set("spark.sql.adaptive.skewJoin.skewedPartitionFactor", "5") # 倾斜判断倍数
spark.conf.set("spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes", "256mb") # 倾斜阈值
# ── Broadcast 阈值 ──
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", "10mb") # 小于此值自动广播,-1 关闭
# ── 诊断参数 ──
spark.conf.set("spark.eventLog.enabled", "true") # 开启事件日志,用于 History Server
# Spark UI 中关注:
# Stage 详情 → Shuffle Read/Write 大小
# Task 列表 → Duration 分布(识别倾斜)
# Summary Metrics → Shuffle Spill (Disk)总结
Shuffle 是 Spark 中最复杂、代价最高的操作,理解它需要把握三条主线:
一、历史演进脉络:Hash Shuffle 因文件数 M×R 爆炸被废弃,Sort Shuffle 通过每个 Mapper 只写 1 个数据文件 + 1 个索引文件,将文件数降至 2M,顺序写磁盘极大提升了 I/O 效率。
二、内部执行机制 :Mapper 端通过 ExternalSorter 对数据按 (partitionId, key) 排序,内存不足时 Spill 溢写临时文件,最终归并为一个数据文件;Reducer 端通过 MapOutputTracker 定位文件位置,按 index 文件中的 offset 精准拉取对应分区的数据段。
三、优化的本质 :所有 Shuffle 优化都围绕两个核心------减少 Shuffle 的次数 和减少每次 Shuffle 的数据量 。能用 Broadcast 就广播,消除 Shuffle;能在 Map 端预聚合(reduceByKey)就不在 Reduce 端全量拉取(groupByKey);遇到数据倾斜优先用 AQE 自动处理,其次考虑 Key 加盐。
附件:数据倾斜:识别 * 根因 * 解决方案
本章基于 Apache Spark 3.x / 4.x,Shuffle 实现细节参见源码 core/src/main/scala/org/apache/spark/shuffle/