目标检测
YOLOv1架构
参考论文
基本思想
YOLO 将目标检测统一建模为单阶段的端到端回归任务,直接从输入图像预测目标的边界框位置、置信度以及类别概率。
优点
1、速度极快
yolo把目标检测做成了单阶段、单网络、一次前向传播的并行预测问题。
首先,对于早期的两阶段检测器,如R-CNN而言,他会先生成许多候选框,对这些候选框一一处理,这样大大放慢了速度。而yolo直接把整张图输入网络,然后会一次性预测哪些地方有物体,框的位置,预测类别等,避免了区域提议和大量候选框的重复提特征。
其次,对于整张图,yolo只做一次前向传播,具体流程大概是:
输入一张图->经过卷积神经网络提取特征->在特征图上直接预测目标框和类别->输出类别。
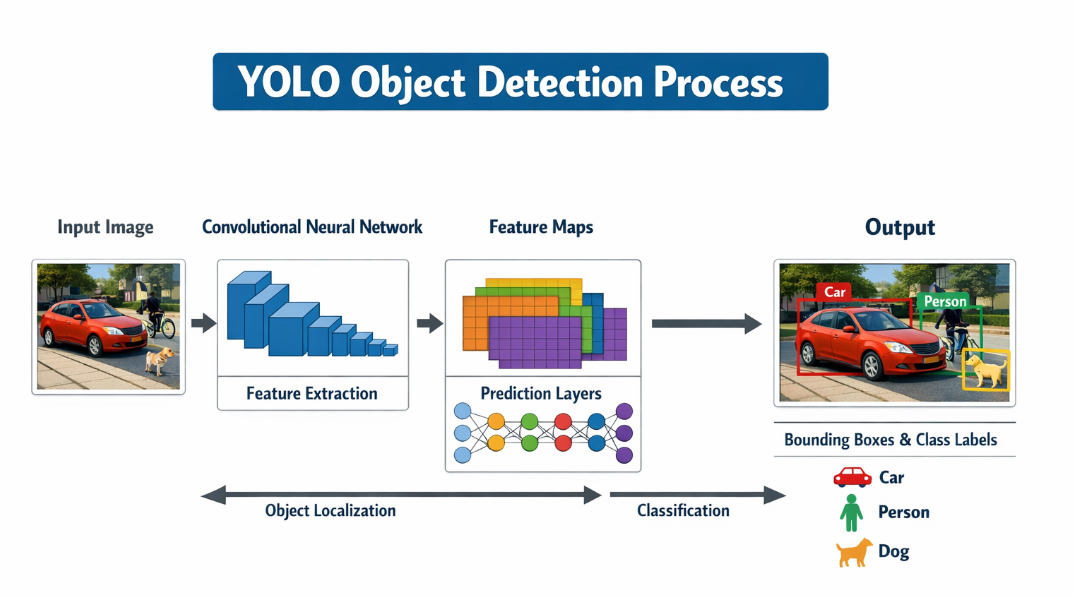
可以说,yolo作为"单阶段检测器",塔在特征图上并行预测,而不是串行处理目标,它共享整张图的特征,而不是为每个后现况重复算特征。
2、yolo具有全局上下文感知能力,背景误检更少
YOLO 在预测时,不是只盯着一个局部小区域看,而是结合整张图的信息一起判断。这说明他能利用全局信息,能结合上下文语义,不容易只因为一个局部纹理像某个物体,就误判成目标。
YOLO 鲁棒性更强,误报率更低,尤其是在背景干扰方面表现更好。
3、yolo泛化能力强,跨域能力好
首先是泛化能力强,YOLO 不仅能在训练时见过的自然图像上工作,还能较好适应新的数据类型;
其次是跨域能力好,在文章中,yolo在自然图像上训练,在艺术画作上测试,这是一种跨域测试,从"照片域"迁移到"艺术图像域",仍然有较好的检测能力。
缺陷
YOLO在准确率上仍然落后于最先进的检测系统。虽然它可以快速地识别图像中的物体,但它很难精确地定位一些物体,特别是小物体。
原理
YOLO 把原本分开的目标检测流程统一到一个神经网络里,直接从整幅图像同时预测所有目标框和类别,实现端到端检测
将输入图像划分为一个 𝑆×𝑆的网格。如果某一目标的中心点落入某个网格单元中,那么该网格单元就负责检测该目标。每个网格单元预测 𝐵 个边界框及其对应的置信度分数。这些置信度分数既反映模型对该边界框中是否包含目标的确信程度,也反映模型对所预测边界框定位精度的判断。形式化地,我们将置信度定义为
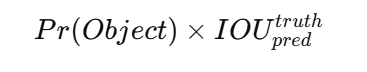
每个边界框包含 5 个预测量:(x)、(y)、(w)、(h) 和 confidence。其中,((x, y)) 表示边界框中心点相对于当前网格单元边界的位置坐标;(w) 和 (h) 表示相对于整幅图像的边界框宽度和高度;最后,confidence 表示预测框与任意真实框之间的 IOU(交并比)。
每个网格单元还会预测 C C C 个条件类别概率 P r ( C l a s s i ∣ O b j e c t ) Pr(Class_i|Object) Pr(Classi∣Object)。这些概率是在该网格单元包含目标这一条件下定义的。无论该网格单元预测多少个边界框 B B B,我们都只为每个网格单元预测一组类别概率。
在测试阶段,我们将条件类别概率与每个边界框的置信度预测相乘:
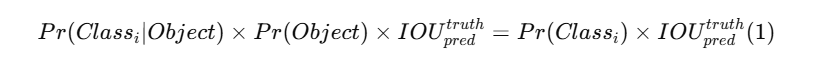
从而得到每个边界框针对各类别的类别特定置信度分数。这些分数同时编码了该边界框中出现某一类别目标的概率,以及预测框与目标真实位置的匹配程度。
最终的输出张量大小为 S ∗ S ∗ ( B ∗ 5 + C ) S*S*(B*5+C) S∗S∗(B∗5+C)
(总共S*S个格子,每个格子预测B个边界框,每个边界框预测五个值,每个网格还要预测C个类别概率)
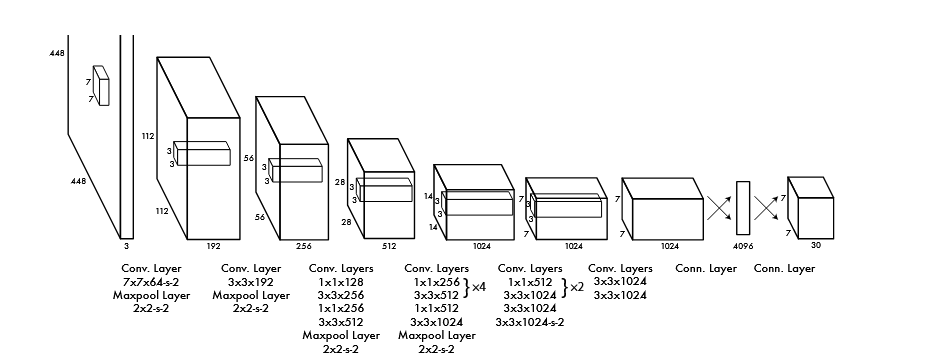
网络设计
将模型实现为一个卷积神经网络,网络前部的卷积层用于从图像中提取特征,后部的全连接层用于预测输出的类别概率和边界框坐标。
该网络由24个卷积层和2个全连接层组成,仅使用 1 ∗ 1 1*1 1∗1的降维卷积层,随后接 3 ∗ 3 3*3 3∗3的卷积层。
对于一些大目标,或者位于多个网格便捷附近的目标的情况,可能会出现多个框检测到同一个目标的情况,这种情况下我们需要用非极大值抑制(NMS),来删除重复框,只保留最好的那个框。
尝试在本地用yolov8跑一些实验
首先我创建了一个conda 虚拟环境yolov8src,用于跑实验。
而后在github上clone了clone https://github.com/ultralytics/ultralytics.git这个仓库,用于试验。
创建完环境之后,初步写了一个用于跑实验的python脚本来验证是否可行。
python
from ultralytics import YOLO
model = YOLO("yolov8n.yaml")
model.train(data="coco8.yaml", epochs=3, imgsz=640)结果大致如下:
从中可以看到,此代码能够调用yolo模型,虽然此次实验并未进行有效学习,但是目的达到。
而后,我又写了一个pro版本:
python
from ultralytics import YOLO
def main():
model = YOLO("yolov8n.pt")
model.train(
data="coco8.yaml",
epochs=20,
imgsz=640,
batch=8,
device="cpu",
workers=0,
project="runs",
name="train_pretrained",
pretrained=True,
verbose=True
)
if __name__ == "__main__":
main()相较于上一个版本,此版本用了yolov8.pt去预训练权重,且训练了20轮。
最终的results结果如下:
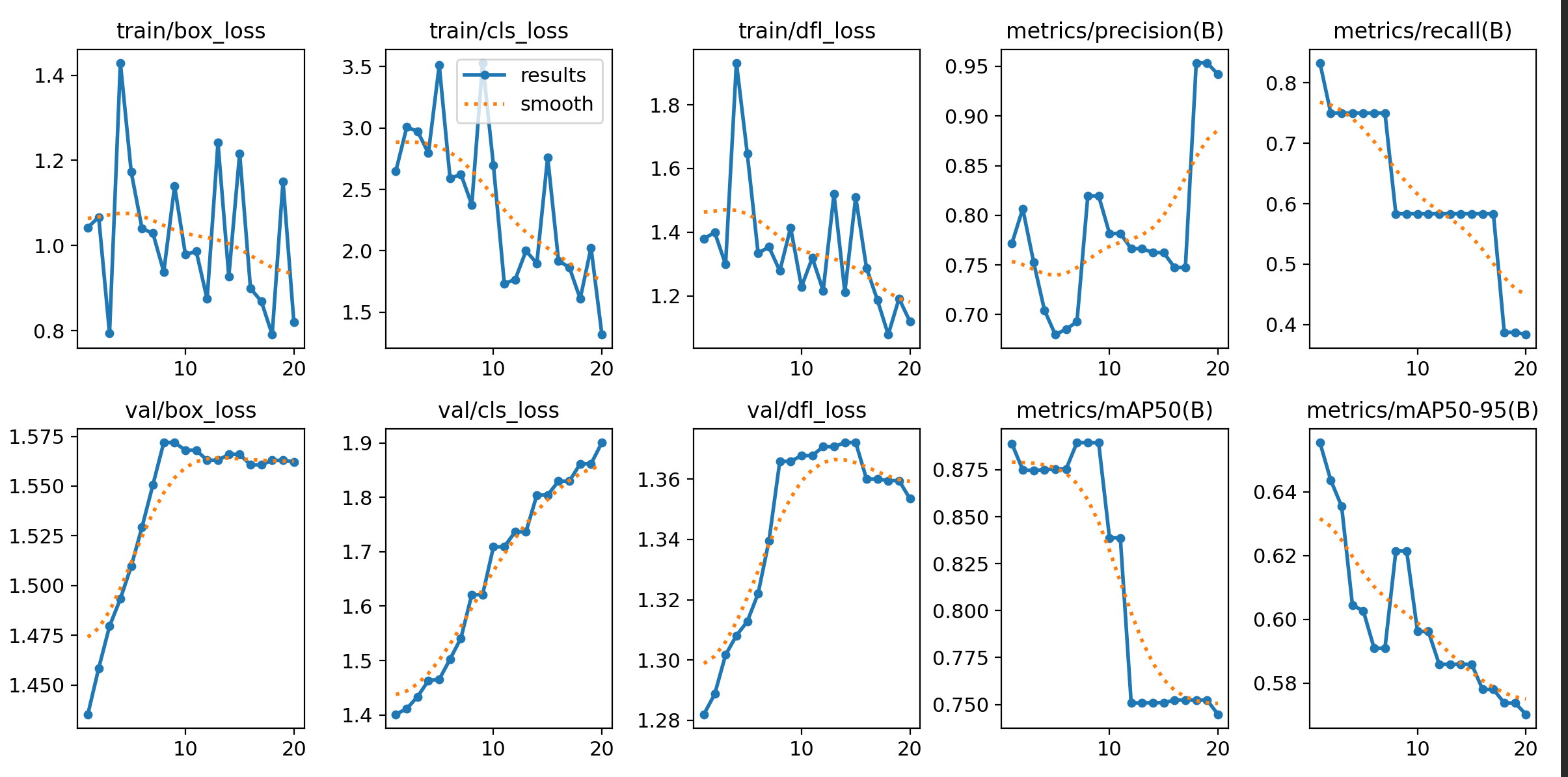
这张图可以说明,这个模型确实学到了东西,但是已经出现了比较明显的过拟合/泛化变差的趋势。
前三章图片表示训练损失,可以看到训练损失整体趋势是往下走的,说明模型在训练集上确实在学习。
但是后面的两张图说明 P r e c i s i o n Precision Precision上升,但是 R e c a l l Recall Recall下降,这意味着模型变得"越来越保守",说明模型有着过拟合倾向,或许数据太少是一个可能的原因。
但是,下面三张验证损失却在持续往上走,维持高位。这说明模型的训练损失下降但是验证损失上升,泛化能力并没有得到同步提升
最后两张mAP50和mAP50-95整体趋势都在下降,这说明训练越往后,验证集上的综合检测效果反而更差。
epoch=10:
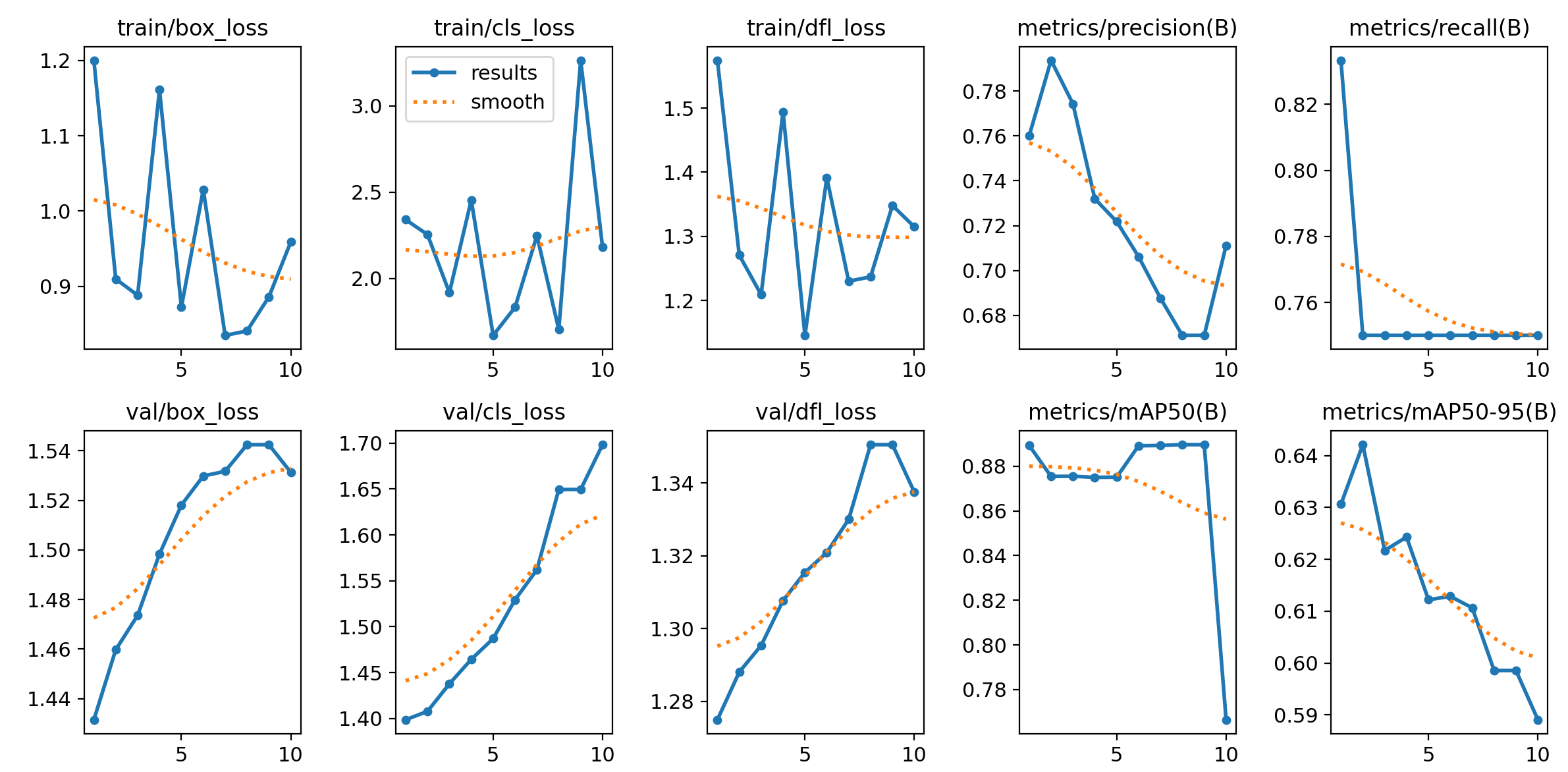
从图中可以看到,epoch=10,有一点过拟合迹象,但比20轮更轻,整体更像"该早停了"的状态
采用best.pt的参数
事实上,我们如果用 b e s t . p t best.pt best.pt内的参数去跑,效果理应最好。
python
from ultralytics import YOLO
model = YOLO(r"C:\Users\huang\ultralytics\runs\detect\runs\train_pretrained\weights\best.pt")
model.train(
data="coco8.yaml",
epochs=5,
imgsz=640,
batch=8,
device="cpu",
workers=0,
project="runs",
name="continue_train"
)最终的结果如下:
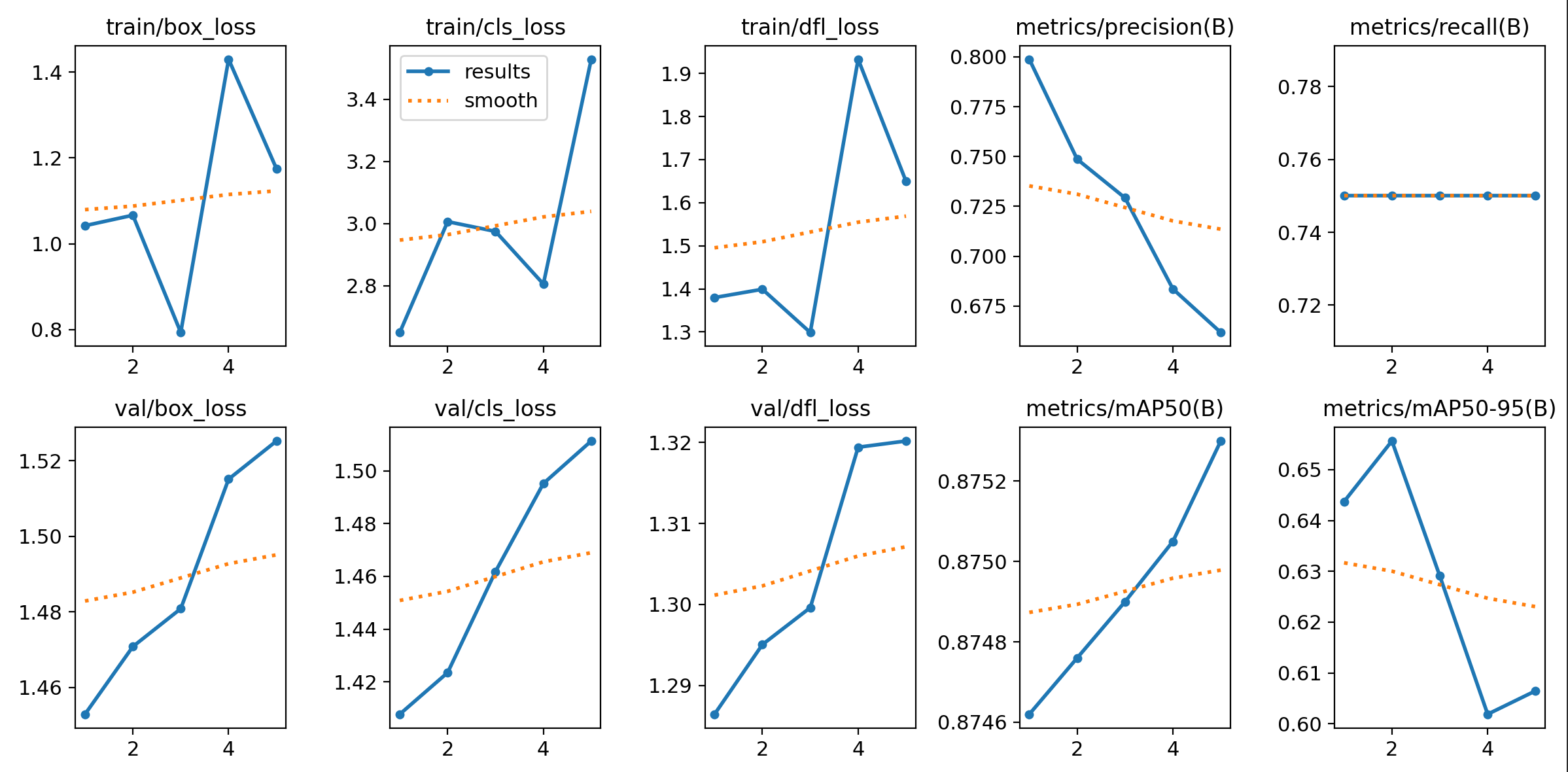
相较于上面的两次结果,此次结果虽然也表现出过拟合,但是相对合理一点。
总结来说:
通过三组实验可以看出,YOLOv8 在 coco8 这类超小规模数据集上具有较快的收敛速度,但也表现出明显的过拟合敏感性。首先,在 20 epoch 训练中,虽然训练损失持续下降,但验证损失上升、召回率下降以及 mAP 指标后期退化,表明训练后期泛化能力减弱。相比之下,10 epoch 的训练结果更为稳定,主指标保持在较高水平,因此更适合作为当前任务设置下的初始训练轮数。进一步地,以 best.pt 为起点继续训练 5 epoch 后,模型的 mAP50 基本维持不变,但 mAP50-95 略有下降,同时验证损失继续上升,说明继续训练并未带来实质性性能增益。综合来看,在当前小数据集和 CPU 训练条件下,最佳策略并不是延长训练轮数,而是采用中前期性能最优的 best.pt 作为最终模型。