0 引言
InstructGPT于2022年初发布,是OpenAI为了
解决GPT-3"不听话"问题而推出的改进版本
- 核心目标:让模型更好地理解和遵循人类的指令,使输出更符合用户意图(更具帮助性、更诚实、更无害)
- 关键技术:采用
RLHF(基于人类反馈的强化学习)进行微调- InstructGPT证明了:即使参数量较小的模型,通过RLHF也能在指令遵循能力上超越更大的基础模型
1 GPT-3存在的问题(对齐问题)
该论文解决了一个人工智能中的核心问题:随着语言模型能力增强,
它们并不会天生就更善于遵循用户意图。标准的语言模型目标,例如预测序列中的下一个token,可能导致模型生成无益、潜在有害或未能遵循指令的输出
研究人员确定了几个关键挑战:🌱 模型经常生成听起来合理但事实不准确的信息
🌱 模型可能产生有毒或有害内容
🌱 模型不能可靠地遵循用户给出的具体指令
🌱 模型可能优化那些与实际用户偏好不符的指标
随着语言模型被部署到其输出可能产生重大影响的实际应用中,这些问题变得日益关键。
2 方法与实验细节
RLHF 的核心流程 (3.1节)
这是目前几乎所有顶尖 AI(如 ChatGPT、Claude)都在用的方法。想象你在教一个学生写作文:
🌱 第一步:名师带路(SFT - 监督微调)
🌼 找一群标注员,给他们出题(Prompt),让他们亲手写出完美的标准答案。然后把这些题和答案喂给 GPT-3,让它模仿
🌼 模型学会了基本的"问答格式",不再乱说话
🌱 第二步:建立审美(RM - 奖励模型)🌼 人为标注成本太高,不能一直写。于是让机器人针对一个问题写出 K(4 到 9)个不同的答案,让老师给这些答案排个序(比如:答案 A 比 B 好,B 比 C 好)
🌼 训练出一个"裁判模型"(奖励模型)。它学会了人类的"审美",能自动给AI的回答打分
🌱 第三步:自我进化(RL -强化学习)🌼 让机器人自己跟自己练。它每写一个答案,第二步的"裁判"就给它打分。分数高,它就加强这种做法;分数低,它就改进
🌼 模型回答变得非常符合人类的喜欢
数据(3.2 & 3.3节)
OpenAI 用了两种数据:
🌼 真实的"甲方"需求: 从 OpenAI 测试平台上,挑选了真实用户输入的提问(去掉了隐私信息)
🌼 人工编写:标注员自己编写提示词,比如"请帮我把这段话改成鲁迅的风格"
任务类型: 涵盖了写代码、写故事、写摘要、回答问题等方方面面
人类数据收集(3.4节)
OpenAI 找了约 40 个"人类老师"
🌼 严格筛选: 并不是谁都能当老师,需要通过考试,看这些人是否能识别偏见、歧视和有害信息
🌼 价值观引导:这些老师并不是随意打分,他们手里有一本厚厚的"操作指南",规定了什么是"好的回答"(要有用、要真实、要无害)
模型(3.5节)
SFT(监督微调): 经过监督微调后的GPT-3
RM(奖励模型): 输入用户的提问(提示词)和AI给出的回答,然后给这个回答打一个分数。 分数越高,代表这个回答越好(越符合人类偏好)🌱
模型实现:移除SFT模型的最终非嵌入层(unembedding layer),改为输出一个标量🌱
模型训练阶段:给标注员看同一个问题的 K 个(4到9个)不同AI回答,让他们把这些回答从好到坏排序,生成比较对,输入模型"prompt"+"response_A"/"prompt"+"response_B",通过模型计算输出偏好数值,利用交叉熵损失函数计算损失,反向传播,使得损失实现局部最小🌱
模型使用阶段:基于比较训练出的评分能力输出分数
RL(强化学习):强化学习是智能体通过与环境互动,从奖励信号中学习最优决策策略的方法。你已经有了一个经过监督微调(SFT) 的AI模型,还有一个训练好的奖励模型(RM)。现在你要用强化学习让AI变得更好
PPO (近端策略优化)算法: 强化学习里最常用的方法,负责根据得分来调整机器人的大脑参数🌱 环境:用户提问(提示词)
🌱 AI行动:生成回答
🌱 奖励:奖励模型给这个回答打分
🌱 学习:调整AI,让其生成更高分的回答
KL惩罚:KL散度:衡量两个概率分布的差异,在本篇论文中
衡量PPO模型和SFT模型的输出差异🌱 惩罚机制:如果PPO模型的输出与SFT模型差异太大,就扣分
🌱 作用:模型可能会发现某些奇怪的字符组合(即"对抗性样本")能让 RM 给出满分,于是它会开始狂刷这些无意义的字符。
KL 惩罚的作用是限制当前训练的模型 不要偏离初始的模型太远。它像一根橡皮筋,拉着模型,让它在尝试新表达时别跑太偏,保证生成的还是人话🌱 局限:它只关心"说话像不像原来的样子",而不关心"其他科目的知识(比如做数学题、考历史、翻译法语)有没有丢(PPO-ptx)"
PPO-ptx(近端策略优化+预训练混合): 只用PPO训练后,AI在公开NLP数据集上表现下降!可能原因:过度优化奖励,忘记了通用语言能力在PPO基础上混合预训练梯度:
训练过程 = PPO梯度 + 预训练梯度
评估(3.6节)
如何量化经过训练过后的模型是否更符合人类意图呢?提出了三个"H"标准:
- Helpful(有用性): 你让它干活,它干得漂不漂亮?有没有遵循你的字数要求?
- Honest(诚实性):它有没有瞎编?(减少"幻觉"现象)
- Harmless(无害性): 它会不会教你做坏事?会不会歧视别人?
评估方法:真人评分: 让标注员直接给模型打分(1-7 分)
公开考卷: 在一些公开NLP数据集上刷分
3 State of GPT(Andrej Karpathy演讲)
3.1 GPT 类助手模型的完整训练流水线
1. 预训练(Pretraining)
数据集:海量原始互联网文本(数万亿词),特点是数量大、质量低
算法:语言建模(Language Modeling),目标是
预测下一个 token(词/字)模型:得到
基础模型(Base model)资源:需要数千块 GPU,训练数月(比如 GPT、LLaMA、PaLM 都是这类产物),时间耗费最长
2. 有监督微调(Supervised Finetuning, SFT)数据集:由标注人员编写的约 1~10 万条「理想助手对话样本」(prompt, response),特点是数量少、质量高
算法:继续用语言建模,学习如何生成符合人类偏好的回答
模型:得到
SFT 模型(在基础模型上初始化)资源:约 1~100 块 GPU,训练数天(比如 Vicuna-13B 就是典型 SFT 模型)
3. 奖励建模(Reward Modeling, RM)数据集:标注人员编写的约 10~100 万条「回答对比样本」,给不同回答打分排序,特点是数量少、质量高
算法:
二分类任务,学习预测人类对回答的偏好奖励模型:得到
RM 模型(在 SFT 模型上初始化)资源:约 1~100 块 GPU,训练数天
RM模型
输入数据(人工标注)同一个问题 prompt,配一对回答(来自标注人员的比较结果):
好回答 text{good}(人类更喜欢)
坏回答 text{bad}(人类不喜欢)
模型做了什么
- 输入: prompt + text{good} → RM 输出分数 r t e x t g o o d r_{text}good rtextgood
- 输入: prompt + text{good} → RM 输出分数 r t e x t b a d r_{text}bad rtextbad
训练目标
- 让 r t e x t g o o d r_{text}good rtextgood > r t e x t b a d r_{text}bad rtextbad
损失
- L = − y l o g ( s i g m o i d ( r t e x t g o o d − r t e x t b a d ) L = -ylog(sigmoid(r_{text}good -r_{text}bad) L=−ylog(sigmoid(rtextgood−rtextbad)
- 分数差值越大于0,sigmoid结果越接近于1,交叉熵损失函数的值越接近于0
输出结果
训练好的 RM 打分模型(只会给单段回答打分)
4. 强化学习(Reinforcement Learning, RL)数据集:标注人员编写的约 1~10 万条提示词(prompts),特点是数量少、质量高
算法:强化学习(RL),让模型生成能最大化奖励
模型:得到
RL 模型(在 SFT 模型上初始化,用 RM 模型做奖励信号)资源:约 1~100 块 GPU,训练数天(比如 ChatGPT、Claude 就是这类 RLHF 产物)
整体逻辑这条流水线就是 RLHF(人类反馈强化学习) 的完整流程:
- 先用海量数据训出一个"会说话"的
基础模型- 再用高质量对话样本把它"教成"一个会回答问题的助手(
SFT监督微调模型)- 然后让人类给回答打分,训出一个"评委"模型(
RM奖励建模)- 最后用强化学习让模型不断优化,生成更符合人类偏好的回答(
RLHF人类反馈强化学习模型)
3.2 高效使用LLM的实用技巧
提示工程(Prompting)
思维链(CoT):"一步步思考",提升推理准确性
反思(Reflection):让模型自查、修正答案
约束提示:强制输出格式(如JSON、代码)
多轮/集成:多次生成再择优
进阶用法检索增强(RAG):外挂知识库,解决幻觉与时效性
工具调用/插件:联网、计算、调用API
微调(Finetuning):小数据集定制化,适合稳定场景(让AI用特定风格写作)、特定类型任务(法律文件分析、医疗报告生成等)
心智模型LLM≈人类快思考(系统1):直觉、快速、易出错;缺
慢思考(系统2)的深度推理提示≈新编程语言,自然语言驱动模型行为
3.3 关键判断与展望
- 开源 vs 闭源:Meta LLaMA是当时最强开源;OpenAI未开源GPT-4
- 模型规模:参数≠性能,
训练token量更关键(LLaMA 65B > GPT-3 175B)。- 未来方向:软件3.0------自然语言编程、LLM作为新型计算机/操作系统、自主智能体(Agent)崛起
4 RLHF详解
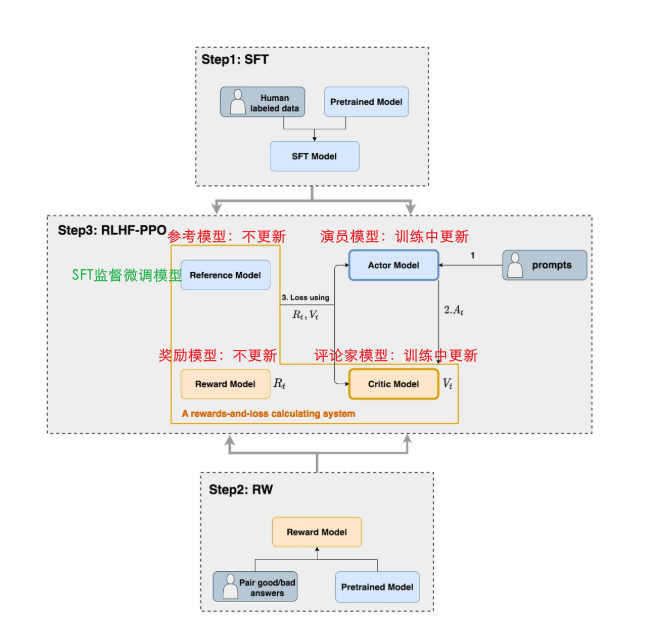
4.1 RLHF中的模型
在RLHF-PPO阶段,一共有四个主要模型,分别是:
🌱Actor Model:演员模型,这就是我们想要训练的目标语言模型,一般使用SFT(监督微调)模型初始化 ,输入prompt,输出一个或多个answer🌱 生成的 answer 会被送入由 Reward、Critic、Reference 组成的 "评价体系",接收各类反馈(奖励、约束、收益预估);根据 "评价体系" 计算出的Actor loss更新自身参数,不断优化生成能力,最终能生成符合人类喜好的回复
🌱Critic Model:评论家模型🌱 Critic模型的作用是
预测当前状态下未来能获得的总奖励期望值,为每个动作提供"价值参考",帮助判断即时奖励的好坏🌱 在语言生成中,通常只有完整回答才有RM评分。Critic为中间步骤提供价值估计,让模型知道每个token对最终得分的贡献
🌱 当Reward Model给出即时奖励时,Critic的价值预测作为基准:
- 如果 即时奖励 + 下一状态价值 > 当前状态价值 → 这个动作比预期好
- 如果 即时奖励 + 下一状态价值 < 当前状态价值 → 这个动作比预期差
🌱Reward Model:奖励模型,通过已经预训练好的模型计算每次Action真实的奖励值(因为是已经训练好的模型,所以在RLHF中参数是不会变化的)🌱 输入prompt + answer,输出一个奖励分数(把人类偏好转化为可计算的奖励信号;替代人工实时打分,让强化学习可以自动化运行)
🌱Reference Model:参考模型(SFT监督微调模型)🌱 作用是防止 Actor 模型 "训歪"------ 让 Actor 在贴合人类喜好的同时,尽量和基础的 SFT 模型输出分布相似,避免生成内容过于离谱、脱离模型原本的能力边界
4.2 损失函数
4.2.1 损失函数构成
RLHF 需要训练的只有两个模型:Actor模型(生成回答)、Critic模型(估计价值)
Reward Model 和 Reference Model 都是冻结的不训练
总损失 = Actor 损失 + Critic 损失
总损失 = PPO策略损失 + 价值损失系数 × 价值损失 + 熵奖励系数 × 熵奖励
PPO策略损失(核心)
目标:让训练模型的回答获得更高分数(奖励)
L c l i p = − m i n ( r a t i o × A , c l i p ( r a t i o , 1 − ε , 1 + ε ) × A ) L_{clip} = -min(ratio × A, clip(ratio, 1-ε, 1+ε) × A) Lclip=−min(ratio×A,clip(ratio,1−ε,1+ε)×A)
PPO策略损失前面是负号,我们的目标是最大化期望回报,所以损失加负号,最小化损失就是最大化目标
ratio = 新策略概率 / 旧策略概率(新旧策略对同一动作的概率比,用来衡量新旧策略差异)
A(优势函数)反应动作相对好坏(得分)
clip剪裁机制:限制ratio范围,实现信任区域,稳定训练
价值损失目标:让Critic模型学会准确评估状态价值
L v a l u e = ( V p r e d − G t ) 2 / N L_{value} = (V_{pred} - G_t)² / N Lvalue=(Vpred−Gt)2/N
价值损失前面是正号,我们要最小化预测误差,所以损失是正的MSE
G t G_t Gt是折扣累计回报
V p r e d V_{pred} Vpred是Critic模型预测状态价值
熵奖励目标:鼓励探索,防止策略过早收敛,避免单一答案,保持生成多样性
L e n t r o p y = − 熵 ( π ( ⋅ ∣ s ) ) L_{entropy} = -熵(π(·|s)) Lentropy=−熵(π(⋅∣s))
熵奖励前面是负号,熵奖励的目标是保持多样性,得到高熵,所以最大化熵,最小化损失
4.2.2 模型在损失函数中的作用
SFT模型(Reference模型)
输入:prompt + answer
输出:每个token的生成概率(固定不变)
用于计算KL散度
RM模型(Reward Model)输入:prompt + answer
输出:一个answer对应一个分值
作用:提供真实评分(真实奖励值)
Critic模型输入:prompt + answer
输出:每个状态的预测值
作用:提供每个状态的预测值,通过训练让其不断接近折扣累计回报
Actor模型输入:prompt + answer
输出:每个token的生成概率(随着反向传播动态变化)
作用:生成最终的模型
🌱 PPO算法是针对一个answer还是针对answer中的每个token进行计算的?🌱 答:针对每一个token;每个token的生成是一个独立决策,每个决策应该根据其贡献的未来回报来评估,不能把所有决策混为一谈
🌱 例如:一个团队项目整体评分很高,但需要知道每个人的贡献,才能公平奖励,有效改进
4.2.3 Loss实现过程
1.计算每个token的KL散度
K L t = π a c t o r ( a t ∣ s t ) × l o g ( π a c t o r ( a t ∣ s t ) / π s f t ( a t ∣ s t ) ) KL_t = π_{actor}(a_t|s_t) × log(π_{actor}(a_t|s_t) / π_{sft}(a_t|s_t)) KLt=πactor(at∣st)×log(πactor(at∣st)/πsft(at∣st))
π a c t o r ( a t ∣ s t ) π_{actor}(a_t|s_t) πactor(at∣st):Actor模型(旧策略)在上文条件下生成当前token的概率,旧策略生成了每个token,新策略只是在训练,还没有生成token,所以使用旧策略
π s f t ( a t ∣ s t ) ) π_{sft}(a_t|s_t)) πsft(at∣st)):SFT模型在上文条件下生成当前token的概率
2.计算即时奖励(RM得到的真实奖励 - KL散度,不能因为讨好RM模型得到更多的奖励,逐渐跑偏,需要用KL散度控制,让Actor模型不能与SFT模型偏差过大)即时奖励公式: r t = R M − β × K L = 奖励模型分数 − K L 惩罚系数 × K L 散度 r_t = RM - β×KL = 奖励模型分数 - KL惩罚系数 × KL散度 rt=RM−β×KL=奖励模型分数−KL惩罚系数×KL散度
因为整个answer只有一个answer值,所以只有最后一个token有RM奖励值,最后一个token的即时奖励 = 奖励模型分数 - KL惩罚系数 × KL散度,其他token的即时奖励 = - KL惩罚系数 × KL散度
3.Critic模型预测状态价值
4.计算折扣累计回报即时奖励反向计算折扣累计回报,未来总收益分到每个token上的现值
5.计算优势函数(这个动作比平时动作好多少,反应动作相对好坏)单步优势 ≈ r t + γ × V ( s t + 1 ) − V ( s t ) 单步优势 ≈ r_t +γ×V(s_{t+1}) - V(s_t) 单步优势≈rt+γ×V(st+1)−V(st)
γ × V ( s t + 1 ) γ×V(s_{t+1}) γ×V(st+1):未来的优势要打折,所以要乘以 γ γ γ
当前状态值 V ( s t ) V(s_t) V(st) => 相当于基线,跟当前状态比较,如果正值代表该动作好,如果负值代表该动作不好
为什么要这么设计:直接学每个动作的价值很困难(词表太大)
当前动作优势 = 即时奖励 + 下个状态价值 - 当前状态价值(状态值的改变是这个动作带来的) 当前状态指的是token还没有生成前的状态(行动还未发生的状态)举例:下象棋:走这一步可以立即带来奖励(比如吃掉对方的马 + 10分),并且改变了整盘棋的局势,当前状态棋局胜率是50%,该动作发生后,未来状态棋局胜率变成70%
6.计算PPO策略损失 L_clip(改进生成策略)r a t i o t = π n e w ( a t ∣ s t ) / π o l d ( a t ∣ s t ) = 训练后 A c t o r 模型生成的 t o k e n 概率 / 训练前 A c t o r 模型生成的 t o k e n 概率 ratio_t = π_{new}(a_t|s_t) /π_{old}(a_t|s_t) = 训练后Actor模型生成的token概率/训练前Actor模型生成的token概率 ratiot=πnew(at∣st)/πold(at∣st)=训练后Actor模型生成的token概率/训练前Actor模型生成的token概率
L c l i p = − m i n ( r a t i o t × A t , c l i p ( r a t i o t , 1 − ε , 1 + ε ) × A t ) = − m i n ( 概率比值 × 优势函数 , c l i p ( 概率比值 , 1 − ε , 1 + ε ) × 优势函数 ) L_{clip} = -min(ratio_t × A_t, clip(ratio_t, 1-ε, 1+ε) × A_t) = -min(概率比值 × 优势函数, clip(概率比值, 1-ε, 1+ε) × 优势函数) Lclip=−min(ratiot×At,clip(ratiot,1−ε,1+ε)×At)=−min(概率比值×优势函数,clip(概率比值,1−ε,1+ε)×优势函数)
7.计算价值损失 L_value(训练Critic准确评估)L v a l u e = ( V p r e d − G t ) 2 / N = ( C r i t i c 模型预测值 − 折扣累计汇报 ) 2 的均值 L_{value} = (V_{pred} - G_t)² / N = (Critic模型预测值 - 折扣累计汇报)² 的均值 Lvalue=(Vpred−Gt)2/N=(Critic模型预测值−折扣累计汇报)2的均值
8.计算熵奖励 L_entropy(保持答案多样性)动作熵 = − Σ π n e w ( a ∣ s ) × l o g ( π n e w ( a ∣ s ) ) = − Σ 训练后 A c t o r 模型输出 t o k e n 概率 × l o g ( 训练后 A c t o r 模型输出 t o k e n 概率 ) 动作熵 = -Σ π_{new}(a|s) × log(π_{new}(a|s)) = -Σ 训练后Actor模型输出token概率 × log(训练后Actor模型输出token概率) 动作熵=−Σπnew(a∣s)×log(πnew(a∣s))=−Σ训练后Actor模型输出token概率×log(训练后Actor模型输出token概率)
实际使用时使用
策略熵(详见下面示例)L e n t r o p y = 熵的负值(因为要最大化熵) L_{entropy} = 熵的负值(因为要最大化熵) Lentropy=熵的负值(因为要最大化熵)
9.计算总损失 L_totalL t o t a l = L c l i p + c 1 × L v a l u e + c 2 × L e n t r o p y L_{total} = L_{clip} + c_1 × L_{value} + c_2 × L_{entropy} Ltotal=Lclip+c1×Lvalue+c2×Lentropy
通常 c 1 c_1 c1 = 0.5, c 2 c_2 c2 = 0.01
4.2.4 具体例子
基础数据
(1)Actor模型生成回答,并获取Actor模型(更新前、更新后)token生成概率、SFT模型token生成概率,用于计算KL散度
python
# 假设的token ID和概率
tokens = ["木星", "是", "太阳系", "最大", "的", "行星"]
token_ids = [100, 101, 102, 103, 104, 105] # 假设ID
# 旧策略概率(Actor当前策略)
π_old = [0.40, 0.65, 0.70, 0.75, 0.80, 0.85]
# SFT模型概率
π_sft = [0.90, 0.85, 0.80, 0.75, 0.85, 0.90]
# 新策略概率(Actor更新后的策略,训练中计算)
π_new = [0.45, 0.68, 0.72, 0.78, 0.82, 0.87](2)RM模型输出真实得分
python
# 完整回答的RM评分
full_answer = "木星是太阳系最大的行星"
rm_score = 8.5计算过程
1.计算每个token的KL散度
python
# KL(π_old || π_sft) = π_old × log(π_old/π_sft)
# π_old = [0.40, 0.65, 0.70, 0.75, 0.80, 0.85]
# π_sft = [0.90, 0.85, 0.80, 0.75, 0.85, 0.90]
import math
KL = []
for t in range(6):
kl_t = π_old[t] * math.log(π_old[t] / π_sft[t])
KL.append(kl_t)
# 计算结果:
# t0: 0.40×log(0.40/0.90) = 0.40×(-0.8109) = -0.3244
# t1: 0.65×log(0.65/0.85) = 0.65×(-0.2697) = -0.1753
# t2: 0.70×log(0.70/0.80) = 0.70×(-0.1335) = -0.0935
# t3: 0.75×log(0.75/0.75) = 0.75×0 = 0.0
# t4: 0.80×log(0.80/0.85) = 0.80×(-0.0606) = -0.0485
# t5: 0.85×log(0.85/0.90) = 0.85×(-0.0572) = -0.0486
KL = [-0.3244, -0.1753, -0.0935, 0.0, -0.0485, -0.0486]2.计算即时奖励
python
β = 0.1
rewards = []
# 前5个token
for t in range(5):
r_t = -β * KL[t]
rewards.append(r_t)
# 最后一个token
r_5 = rm_score - β * KL[5]
rewards.append(r_5)
# 计算结果:
# t0: -0.1×(-0.3244) = 0.03244
# t1: -0.1×(-0.1753) = 0.01753
# t2: -0.1×(-0.0935) = 0.00935
# t3: -0.1×0.0 = 0.0
# t4: -0.1×(-0.0485) = 0.00485
# t5: 8.5 - 0.1×(-0.0486) = 8.5 + 0.00486 = 8.50486
rewards = [0.03244, 0.01753, 0.00935, 0.0, 0.00485, 8.50486]
3.Critic模型预测状态价值
python
# 每个token生成前的状态价值
states = [
"太阳系最大的行星是?", # s0 - 开始状态
"太阳系最大的行星是?木星", # s1
"太阳系最大的行星是?木星是", # s2
"太阳系最大的行星是?木星是太阳系", # s3
"太阳系最大的行星是?木星是太阳系最大", # s4
"太阳系最大的行星是?木星是太阳系最大的", # s5
"太阳系最大的行星是?木星是太阳系最大的行星" # s6 - 终止状态
]
# Critic预测的价值
V_old = [5.0, 6.0, 7.0, 8.0, 8.5, 9.0, 0.0]
时间步: 状态 → 动作 → 下一个状态
t=0: s0 → a0("木星") → s1
t=1: s1 → a1("是") → s2
t=2: s2 → a2("太阳系") → s3
t=3: s3 → a3("最大") → s4
t=4: s4 → a4("的") → s5
t=5: s5 → a5("行星") → s_终止
4.计算折扣累计回报
python
γ = 0.99
returns = [0] * 6
# 从最后一个token向前计算
returns[5] = rewards[5] # 8.50486
# t=4
returns[4] = rewards[4] + γ * returns[5]
= 0.00485 + 0.99 * 8.50486
= 0.00485 + 8.41981 = 8.42466
# t=3
returns[3] = rewards[3] + γ * returns[4]
= 0.0 + 0.99 * 8.42466 = 8.34041
# t=2
returns[2] = rewards[2] + γ * returns[3]
= 0.00935 + 0.99 * 8.34041 = 0.00935 + 8.25701 = 8.26636
# t=1
returns[1] = rewards[1] + γ * returns[2]
= 0.01753 + 0.99 * 8.26636 = 0.01753 + 8.18370 = 8.20123
# t=0
returns[0] = rewards[0] + γ * returns[1]
= 0.03244 + 0.99 * 8.20123 = 0.03244 + 8.11922 = 8.15166
returns = [8.15166, 8.20123, 8.26636, 8.34041, 8.42466, 8.50486]5.计算优势函数
(1)计算TD误差 δ_t(单步评分,用来量化当前Action的好坏)
python
# V = [5.0, 6.0, 7.0, 8.0, 8.5, 9.0, 0.0]
# 关键:最后一个动作后进入终止状态,价值为0
# V(s_终止) = 0
δ = []
for t in range(6):
if t < 5: # 前5个动作
# δ_t = r_t + γ×V(s_{t+1}) - V(s_t)
δ_t = rewards[t] + γ * V[t+1] - V[t]
else: # t=5,最后一个动作
# δ_5 = r_5 + γ×V(s_终止) - V(s_5)
# V(s_终止) = 0
δ_t = rewards[5] + γ * 0 - V[5]
δ.append(δ_t)
# 手动计算:
# t0: 0.03244 + 0.99×6.0 - 5.0 = 0.03244 + 5.94 - 5.0 = 0.97244
# t1: 0.01753 + 0.99×7.0 - 6.0 = 0.01753 + 6.93 - 6.0 = 0.94753
# t2: 0.00935 + 0.99×8.0 - 7.0 = 0.00935 + 7.92 - 7.0 = 0.92935
# t3: 0.0 + 0.99×8.5 - 8.0 = 0.0 + 8.415 - 8.0 = 0.415
# t4: 0.00485 + 0.99×9.0 - 8.5 = 0.00485 + 8.91 - 8.5 = 0.41485
# t5: 8.50486 + 0.99×0 - 9.0 = 8.50486 - 9.0 = -0.49514 # 注意是负的!
δ = [0.97244, 0.94753, 0.92935, 0.415, 0.41485, -0.49514](2)计算GAE优势(整体趋势评估,不只看当前这一步,还看后续影响)
python
# 传统方法(只看当前):
优势 = 当前TD误差 = -20 # 结论:不好
# GAE方法(看整体趋势):
优势 = 当前TD误差 + 0.9×下一时刻优势
= -20 + 0.9×(+70)
= -20 + 63 = 43 # 结论:整体还是好的!
python
λ = 0.95
advantages = [0] * 6
# 从后向前计算
advantages[5] = δ[5] # -0.49514
# t=4
advantages[4] = δ[4] + γ * λ * advantages[5]
= 0.41485 + 0.99×0.95×(-0.49514)
= 0.41485 + 0.9405×(-0.49514)
= 0.41485 - 0.4657 = -0.05085
# t=3
advantages[3] = δ[3] + γ * λ * advantages[4]
= 0.415 + 0.9405×(-0.05085)
= 0.415 - 0.0478 = 0.3672
# t=2
advantages[2] = δ[2] + γ * λ * advantages[3]
= 0.92935 + 0.9405×0.3672
= 0.92935 + 0.3454 = 1.27475
# t=1
advantages[1] = δ[1] + γ * λ * advantages[2]
= 0.94753 + 0.9405×1.27475
= 0.94753 + 1.1989 = 2.14643
# t=0
advantages[0] = δ[0] + γ * λ * advantages[1]
= 0.97244 + 0.9405×2.14643
= 0.97244 + 2.0187 = 2.99114
advantages = [2.99114, 2.14643, 1.27475, 0.3672, -0.05085, -0.49514]6.计算PPO策略损失 L_clip(改进生成策略)
python
π_old = [0.40, 0.65, 0.70, 0.75, 0.80, 0.85]
π_new = [0.45, 0.68, 0.72, 0.78, 0.82, 0.87]
# 计算ratio
ratios = [
0.45/0.40 = 1.125, # t0
0.68/0.65 = 1.04615, # t1
0.72/0.70 = 1.02857, # t2
0.78/0.75 = 1.04, # t3
0.82/0.80 = 1.025, # t4
0.87/0.85 = 1.02353 # t5
]
# 优势函数
advantages = [2.99114, 2.14643, 1.27475, 0.3672, -0.05085, -0.49514]
# PPO-Clip损失
ε = 0.2
clip_min, clip_max = 0.8, 1.2
policy_losses = []
for t in range(6):
ratio = ratios[t]
A = advantages[t]
clipped = max(min(ratio, clip_max), clip_min)
surr1 = ratio * A
surr2 = clipped * A
# 公式:L_clip = -min( ratio*A, clip(ratio)*A )
# 作用:无论 A 正负,自动选择"更保守"的更新方向
# A > 0 好动作 → min 选小的 → loss 负 → 鼓励
# A < 0 坏动作 → min 选更负的 → loss 正 → 惩罚
policy_loss_t = -min(surr1, surr2)
policy_losses.append(policy_loss_t)
# 计算结果:
# t0: A=2.99114>0, ratio=1.125, clipped=1.2
# min=1.125×2.99114=3.365, loss=-3.365
# t1: A=2.14643>0, ratio=1.04615
# loss=-2.244
# t2: A=1.27475>0, ratio=1.02857
# loss=-1.311
# t3: A=0.3672>0, ratio=1.04
# loss=-0.382
# t4: A=-0.05085<0, ratio=1.025
# min=1.025×(-0.05085)=-0.0521, loss=0.0521(A<0,需要惩罚,loss为正)
# t5: A=-0.49514<0, ratio=1.02353
# min=1.02353×(-0.49514)=-0.5067, loss=0.5067
policy_losses = [-3.365, -2.244, -1.311, -0.382, 0.0521, 0.5067]
# 平均策略损失
L_clip = sum(policy_losses) / 6
= (-3.365-2.244-1.311-0.382+0.0521+0.5067)/6
= (-6.7432)/6 = -1.123877.计算价值损失 L_value(训练Critic准确评估)
python
# 价值损失:MSE(V(s_t), G_t) = MSE(预测值, 折扣累计回报)
value_losses = []
for t in range(6):
loss_t = (V[t] - returns[t]) ** 2
value_losses.append(loss_t)
# 计算结果:
# t0: (5.0-8.15166)² = 9.933
# t1: (6.0-8.20123)² = 4.845
# t2: (7.0-8.26636)² = 1.603
# t3: (8.0-8.34041)² = 0.116
# t4: (8.5-8.42466)² = 0.00567
# t5: (9.0-8.50486)² = 0.245
value_losses = [9.933, 4.845, 1.603, 0.116, 0.00567, 0.245]
# 平均价值损失
L_value = sum(value_losses) / 6 = 16.74767/6 = 2.791288.计算熵奖励 L_entropy(保持答案多样性)
python
# 新策略对每个token的概率(主词概率)
π_new_main = [0.45, 0.68, 0.72, 0.78, 0.82, 0.87]
# 为了计算熵,我们需要完整的概率分布(策略熵)
# 如果计算动作熵:-π(a_t|s_t) × log π(a_t|s_t),只考虑当前动作
# 假设每个token的剩余概率均匀分布在其他词上
vocab_size = 50000 # 假设词表大小
entropies = []
for t in range(6):
p_main = π_new_main[t] # 主词概率
p_rest = (1 - p_main) / (vocab_size - 1) # 其他词平均概率
# 计算熵:H = -p_main*log(p_main) - Σ p_rest*log(p_rest)
# 简化计算:Σ p_rest*log(p_rest) ≈ (vocab_size-1) × p_rest × log(p_rest)
entropy_t = -p_main * math.log(p_main)
if p_rest > 0:
entropy_t -= (vocab_size - 1) * p_rest * math.log(p_rest)
entropies.append(entropy_t)
# 计算结果:
# t0: p_main=0.45, p_rest=(1-0.45)/49999=0.000011
# -0.45×log(0.45) = -0.45×(-0.7985) = 0.3593
# -49999×0.000011×log(0.000011) = -0.55×(-11.412) = 6.2766
# entropy_0 = 0.3593 + 6.2766 = 6.6359
# t1: p_main=0.68, p_rest=0.0000064
# -0.68×log(0.68) = -0.68×(-0.3857) = 0.2623
# -49999×0.0000064×log(0.0000064) = -0.32×(-11.958) = 3.8266
# entropy_1 = 0.2623 + 3.8266 = 4.0889
# t2: p_main=0.72, p_rest=0.0000056
# -0.72×log(0.72) = -0.72×(-0.3285) = 0.2365
# -49999×0.0000056×log(0.0000056) = -0.28×(-12.089) = 3.385
# entropy_2 = 0.2365 + 3.385 = 3.6215
# t3: p_main=0.78, p_rest=0.0000044
# -0.78×log(0.78) = -0.78×(-0.2485) = 0.1938
# -49999×0.0000044×log(0.0000044) = -0.22×(-12.332) = 2.713
# entropy_3 = 0.1938 + 2.713 = 2.9068
# t4: p_main=0.82, p_rest=0.0000036
# -0.82×log(0.82) = -0.82×(-0.1985) = 0.1628
# -49999×0.0000036×log(0.0000036) = -0.18×(-12.532) = 2.2558
# entropy_4 = 0.1628 + 2.2558 = 2.4186
# t5: p_main=0.87, p_rest=0.0000026
# -0.87×log(0.87) = -0.87×(-0.1393) = 0.1212
# -49999×0.0000026×log(0.0000026) = -0.13×(-12.856) = 1.6713
# entropy_5 = 0.1212 + 1.6713 = 1.7925
entropies = [6.6359, 4.0889, 3.6215, 2.9068, 2.4186, 1.7925]
# 平均熵
mean_entropy = sum(entropies) / 6 = 21.4642 / 6 = 3.5774
# 熵奖励损失 = -平均熵
L_entropy = -mean_entropy = -3.57749.计算总损失
python
# L_total = L_clip + c1 × L_value + c2 × L_entropy
c1 = 0.5 # 价值损失系数
c2 = 0.01 # 熵奖励系数
# 前面计算的结果:
L_clip = -1.12387 # 策略损失(负的,因为要最大化)
L_value = 2.79128 # 价值损失(正的,要最小化)
L_entropy = -3.5774 # 熵损失(负的,要最大化熵)
# 计算总损失
L_total = L_clip + c1 * L_value + c2 * L_entropy
= -1.12387 + 0.5 * 2.79128 + 0.01 * (-3.5774)
= -1.12387 + 1.39564 - 0.035774
= 0.236996 # 约0.237参考
Training language models to follow instructions with human feedback