机器学习算法原理与实践-入门(九):基于TensorFlow框架的线性回归
在前一篇文章中,我们使用PyTorch框架实现了线性回归模型,体验了现代深度学习框架的便利性。今天,我们将转向另一个主流框架------TensorFlow,使用相同的线性回归任务,对比不同框架的实现方式和设计理念。TensorFlow由Google开发并维护,在工业界有着广泛的应用,尤其擅长部署和生产环境。
一、TensorFlow vs PyTorch:两大框架的对比
1.1 TensorFlow的特点
TensorFlow最初采用静态计算图 模式,需要先定义完整的计算图再执行。从TensorFlow 2.0开始,默认启用即时执行模式(Eager Execution),使其使用体验更接近PyTorch。
TensorFlow的主要优势:
- 生产部署成熟:TensorFlow Serving、TF Lite等工具链完善
- 跨平台支持:支持移动端、嵌入式设备、浏览器(TensorFlow.js)
- 可视化工具:TensorBoard提供强大的训练可视化
- 社区生态:丰富的预训练模型和工业级解决方案
1.2 与PyTorch的关键差异
| 特性 | TensorFlow | PyTorch |
|---|---|---|
| 计算图 | 默认即时执行,支持静态图优化 | 默认动态计算图 |
| API风格 | 函数式API与面向对象API混合 | 纯Pythonic面向对象 |
| 部署 | 生产部署工具链完善 | 部署生态相对较新 |
| 学习曲线 | 较陡峭,概念较多 | 较平缓,更Pythonic |
| 研究社区 | 广泛,但近年PyTorch增长更快 | 学术界更受欢迎 |
二、TensorFlow实现线性回归的核心步骤
2.1 数据准备与预处理
TensorFlow的数据处理通常结合NumPy和TensorFlow操作,与PyTorch类似,但有一些API差异:
python
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 准备数据(与PyTorch相同的数据集)
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7],
[-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6], [0.4, 34.0], [0.8, 62.3]]
data = np.array(data, dtype=np.float32)
x_data = data[:, 0:1] # 形状变为 (10, 1),符合TensorFlow期望
y_data = data[:, 1:2] # 形状变为 (10, 1)
print(f"数据形状: x_data={x_data.shape}, y_data={y_data.shape}")关键点 :TensorFlow通常期望输入数据是二维的,即使只有一个特征也需要保持[batch_size, 1]的形状。
2.2 模型构建的几种方式
TensorFlow提供了多种构建模型的方式,我们主要介绍两种最常用的:
方式1:Sequential API(最简洁)
python
# 使用Sequential API构建模型
model = tf.keras.Sequential([
tf.keras.layers.Dense(1, input_shape=(1,)) # 线性层,1个输出,1个输入
])
# 查看模型结构
model.summary()输出:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 1) 2
=================================================================
Total params: 2
Trainable params: 2
Non-trainable params: 0
_________________________________________________________________方式2:函数式API(更灵活)
python
# 使用函数式API构建模型
inputs = tf.keras.Input(shape=(1,))
outputs = tf.keras.layers.Dense(1)(inputs)
model = tf.keras.Model(inputs=inputs, outputs=outputs)2.3 模型参数查看
在TensorFlow中,查看模型参数的方式与PyTorch略有不同:
python
# 获取权重和偏置
weights, bias = model.layers[0].get_weights()
print(f"初始权重: {weights[0][0]:.4f}")
print(f"初始偏置: {bias[0]:.4f}")
print(f"参数总数: {model.count_params()}")2.4 损失函数与优化器配置
python
# 定义损失函数和优化器
loss_function = tf.keras.losses.MeanSquaredError() # 均方误差
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01) # 随机梯度下降
# 编译模型(TensorFlow特有步骤)
model.compile(optimizer=optimizer, loss=loss_function)注意 :TensorFlow需要显式调用compile()方法配置训练参数,这是与PyTorch的主要区别之一。
三、完整代码实现
python
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
# ============ 1. 数据准备 ============
# 设置随机种子确保可复现性
tf.random.set_seed(42)
np.random.seed(42)
# 准备数据集
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7],
[-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6], [0.4, 34.0], [0.8, 62.3]]
data = np.array(data, dtype=np.float32)
x_data = data[:, 0:1] # 形状: (10, 1)
y_data = data[:, 1:2] # 形状: (10, 1)
print("数据准备完成")
print(f"x_data形状: {x_data.shape}, y_data形状: {y_data.shape}")
print(f"x_data范围: [{x_data.min():.2f}, {x_data.max():.2f}]")
print(f"y_data范围: [{y_data.min():.2f}, {y_data.max():.2f}]\n")
# ============ 2. 定义模型 ============
# 使用Sequential API构建线性回归模型
model = tf.keras.Sequential([
tf.keras.layers.Dense(1, input_shape=(1,), name='linear_layer')
])
# 查看模型结构
print("模型结构:")
model.summary()
print()
# 获取初始参数
initial_weights, initial_bias = model.layers[0].get_weights()
print(f"初始参数: w={initial_weights[0][0]:.4f}, b={initial_bias[0]:.4f}")
# ============ 3. 配置损失函数和优化器 ============
loss_fn = tf.keras.losses.MeanSquaredError() # 均方误差损失
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01) # 随机梯度下降
# 编译模型
model.compile(optimizer=optimizer, loss=loss_fn)
# ============ 4. 可视化设置 ============
# 创建图形窗口
fig = plt.figure(figsize=(12, 6))
gs = gridspec.GridSpec(2, 2)
# 左上子图:数据点和拟合直线
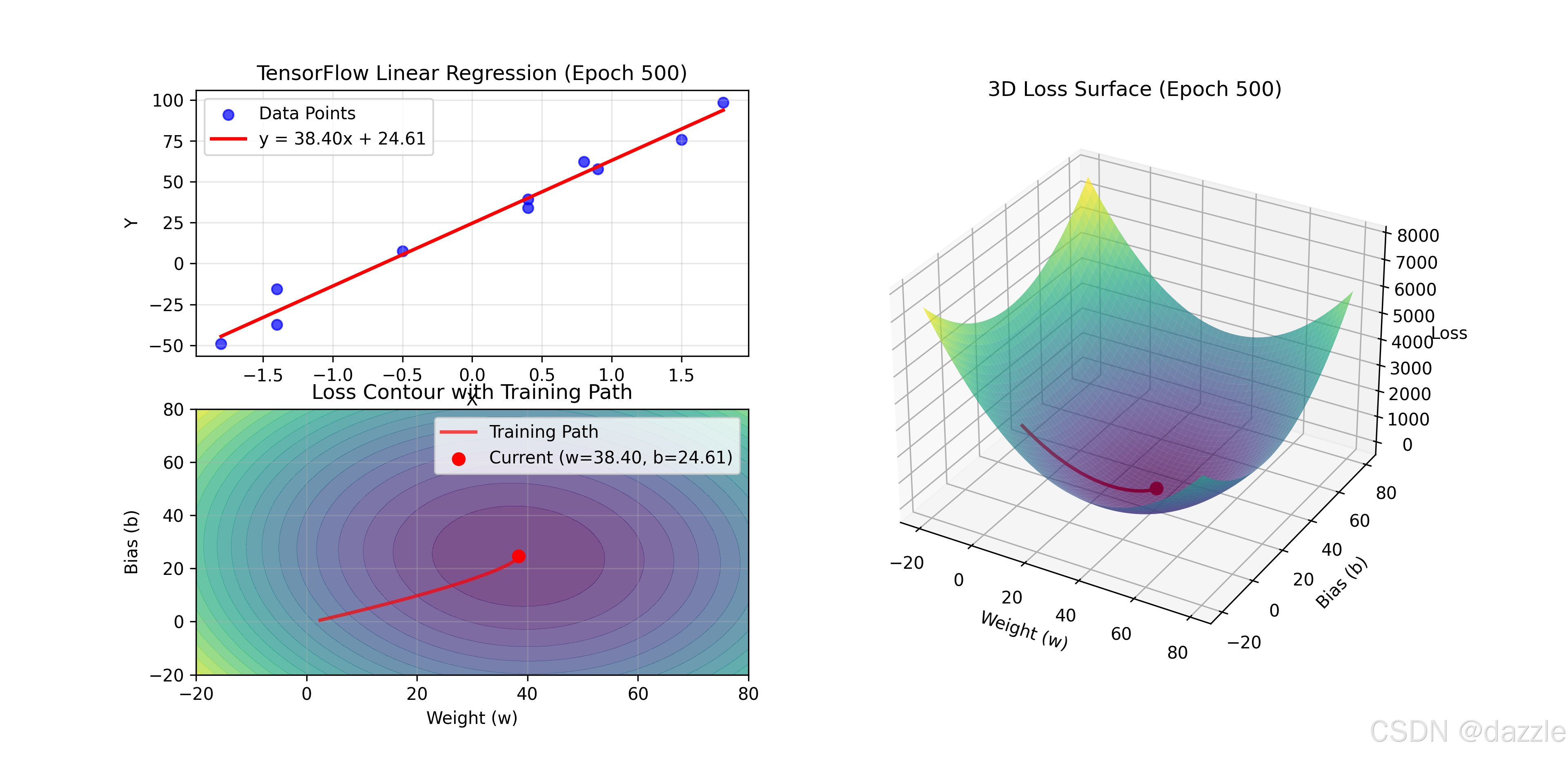
ax_data = fig.add_subplot(gs[0, 0])
ax_data.set_xlabel("X")
ax_data.set_ylabel("Y")
ax_data.set_title("Linear Regression with TensorFlow")
ax_data.grid(True, alpha=0.3)
# 左下子图:损失函数等高线
ax_contour = fig.add_subplot(gs[1, 0])
ax_contour.set_xlabel("Weight (w)")
ax_contour.set_ylabel("Bias (b)")
ax_contour.set_title("Loss Contour Plot")
ax_contour.grid(True, alpha=0.3)
# 右侧子图:三维损失函数曲面
ax_3d = fig.add_subplot(gs[:, 1], projection='3d')
ax_3d.set_xlabel('Weight (w)')
ax_3d.set_ylabel('Bias (b)')
ax_3d.set_zlabel('Loss')
ax_3d.set_title("3D Loss Surface")
# ============ 5. 准备损失函数可视化数据 ============
# 定义损失计算函数
def compute_loss_for_visualization(w, b):
"""计算给定参数下的MSE损失"""
y_pred = w * x_data + b
return np.mean((y_pred - y_data) ** 2)
# 生成参数网格
w_range = np.linspace(-20, 80, 50)
b_range = np.linspace(-20, 80, 50)
W, B = np.meshgrid(w_range, b_range)
# 计算网格点的损失值
loss_grid = np.zeros_like(W)
for i in range(len(w_range)):
for j in range(len(b_range)):
loss_grid[j, i] = compute_loss_for_visualization(W[j, i], B[j, i])
# 绘制初始三维曲面
ax_3d.plot_surface(W, B, loss_grid, cmap='viridis', alpha=0.7)
# ============ 6. 训练循环 ============
epochs = 500
display_freq = 50 # 每50个epoch显示一次
train_history = [] # 记录训练历史
loss_history = [] # 记录损失历史
param_history = [] # 记录参数历史
print("开始训练...")
print("-" * 50)
# 自定义训练循环(更灵活的控制)
for epoch in range(epochs):
with tf.GradientTape() as tape:
# 前向传播
y_pred = model(x_data, training=True)
# 计算损失
loss_value = loss_fn(y_data, y_pred)
# 计算梯度
gradients = tape.gradient(loss_value, model.trainable_variables)
# 应用梯度更新参数
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
# 记录历史
loss_history.append(loss_value.numpy())
current_weights, current_bias = model.layers[0].get_weights()
param_history.append((current_weights[0][0], current_bias[0]))
# 定期显示训练进度
if (epoch + 1) % display_freq == 0 or epoch == 0:
current_loss = loss_value.numpy()
current_w = current_weights[0][0]
current_b = current_bias[0]
print(f"Epoch {epoch+1:3d}/{epochs} - Loss: {current_loss:.4f}, "
f"w: {current_w:.4f}, b: {current_b:.4f}")
# ============ 更新可视化 ============
# 清除旧图形
ax_data.clear()
ax_contour.clear()
ax_3d.clear()
# 左上图:数据点和拟合直线
ax_data.scatter(x_data, y_data, color='blue', label='Data Points', alpha=0.7)
x_line = np.linspace(x_data.min(), x_data.max(), 100).reshape(-1, 1)
y_line = model.predict(x_line, verbose=0)
ax_data.plot(x_line, y_line, 'r-', linewidth=2,
label=f'y = {current_w:.2f}x + {current_b:.2f}')
ax_data.set_xlabel('X')
ax_data.set_ylabel('Y')
ax_data.set_title(f'TensorFlow Linear Regression (Epoch {epoch+1})')
ax_data.legend()
ax_data.grid(True, alpha=0.3)
# 左下图:损失等高线
contour = ax_contour.contourf(W, B, loss_grid, levels=20, cmap='viridis', alpha=0.7)
# 绘制训练路径
if len(param_history) > 1:
path_w, path_b = zip(*param_history)
ax_contour.plot(path_w, path_b, 'r-', linewidth=2, alpha=0.7, label='Training Path')
ax_contour.scatter(current_w, current_b, color='red', s=50,
label=f'Current (w={current_w:.2f}, b={current_b:.2f})')
ax_contour.set_xlabel('Weight (w)')
ax_contour.set_ylabel('Bias (b)')
ax_contour.set_title('Loss Contour with Training Path')
ax_contour.legend()
ax_contour.grid(True, alpha=0.3)
# 右侧图:三维损失曲面和训练路径
ax_3d.plot_surface(W, B, loss_grid, cmap='viridis', alpha=0.7)
if len(param_history) > 1:
# 计算路径上每个点的损失值
path_loss = [compute_loss_for_visualization(w, b) for w, b in param_history]
ax_3d.plot(path_w, path_b, path_loss, 'r-', linewidth=2, label='3D Training Path')
ax_3d.scatter(current_w, current_b, path_loss[-1], color='red', s=50)
ax_3d.set_xlabel('Weight (w)')
ax_3d.set_ylabel('Bias (b)')
ax_3d.set_zlabel('Loss')
ax_3d.set_title(f'3D Loss Surface (Epoch {epoch+1})')
# 短暂暂停以便观察
plt.pause(0.05)
# ============ 7. 训练结果分析 ============
print("\n" + "=" * 50)
print("训练完成!")
print("=" * 50)
final_weights, final_bias = model.layers[0].get_weights()
final_w = final_weights[0][0]
final_b = final_bias[0]
final_loss = loss_history[-1]
print(f"最终参数: w = {final_w:.4f}, b = {final_b:.4f}")
print(f"最终损失: {final_loss:.4f}")
print(f"训练总轮数: {epochs}")
print(f"初始损失: {loss_history[0]:.4f}")
print(f"损失下降: {loss_history[0] - final_loss:.4f} ({((loss_history[0] - final_loss)/loss_history[0]*100):.1f}% reduction)")
# ============ 8. 模型评估与预测 ============
print("\n模型预测示例:")
print("-" * 30)
# 准备测试数据
test_x = np.array([[-2.0], [-1.0], [0.0], [1.0], [2.0]], dtype=np.float32)
# 使用模型进行预测
predictions = model.predict(test_x, verbose=0)
print("输入 X | 预测 Y")
print("-" * 20)
for i in range(len(test_x)):
print(f"{test_x[i][0]:6.1f} | {predictions[i][0]:8.2f}")
# ============ 9. 损失曲线可视化 ============
# 创建损失曲线图
fig_loss, ax_loss = plt.subplots(figsize=(8, 5))
ax_loss.plot(range(1, len(loss_history) + 1), loss_history, 'b-', linewidth=2)
ax_loss.set_xlabel('Epoch')
ax_loss.set_ylabel('Loss')
ax_loss.set_title('Training Loss Curve (TensorFlow)')
ax_loss.grid(True, alpha=0.3)
ax_loss.set_yscale('log') # 对数尺度更容易观察损失下降
# 标记关键点
ax_loss.scatter([1, len(loss_history)], [loss_history[0], loss_history[-1]],
color='red', s=100, zorder=5)
ax_loss.annotate(f'Start: {loss_history[0]:.2f}',
xy=(1, loss_history[0]), xytext=(10, 10),
textcoords='offset points')
ax_loss.annotate(f'End: {loss_history[-1]:.4f}',
xy=(len(loss_history), loss_history[-1]), xytext=(-60, 10),
textcoords='offset points')
# ============ 10. 显示所有图形 ============
plt.tight_layout()
plt.show()
print("\n" + "=" * 50)
print("TensorFlow线性回归实验完成!")
print("=" * 50)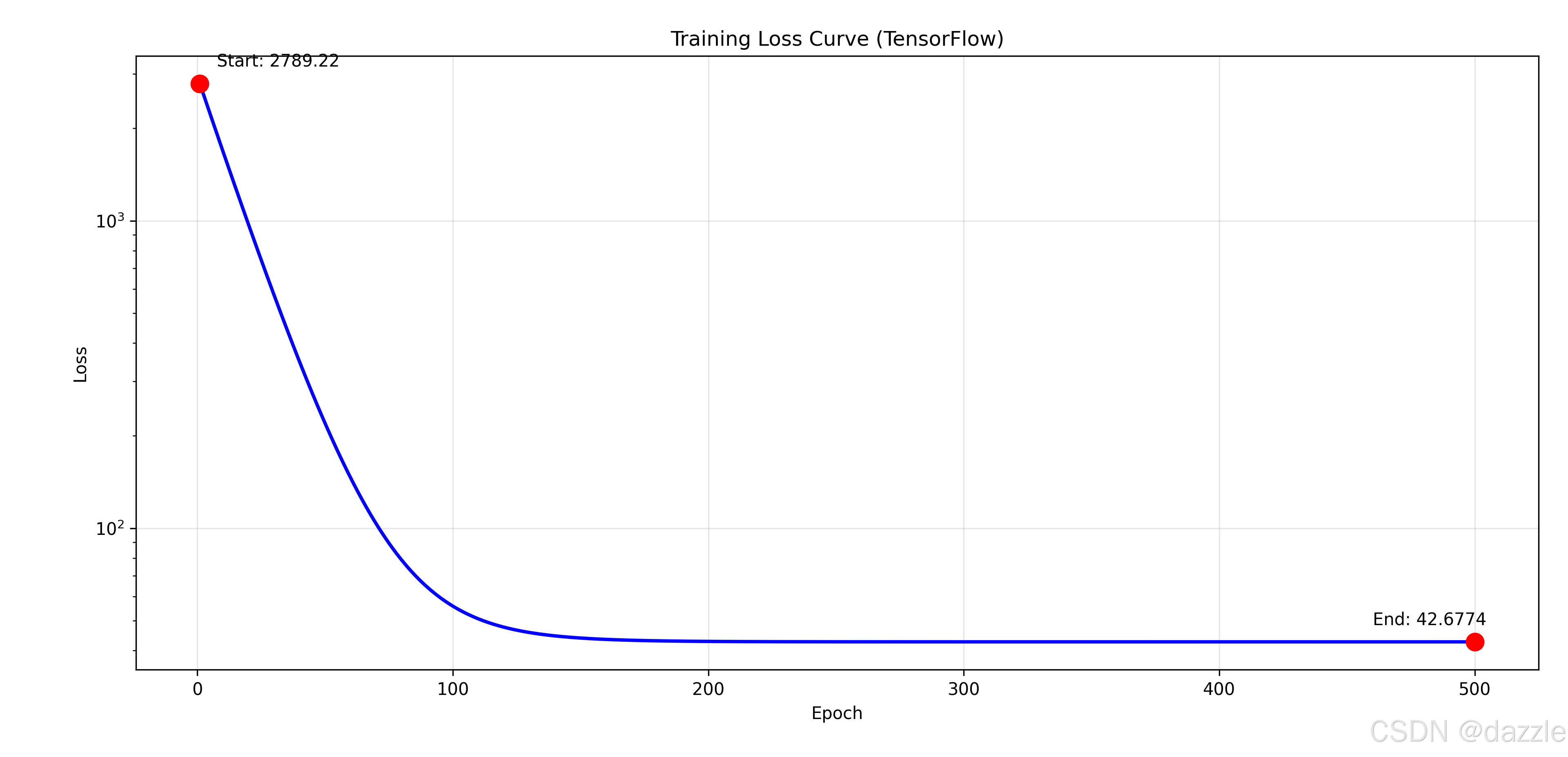
四、TensorFlow核心概念解析
4.1 GradientTape:自动求导的核心
TensorFlow 2.x使用tf.GradientTape()实现自动求导:
python
with tf.GradientTape() as tape:
y_pred = model(x_data) # 前向传播
loss = loss_fn(y_data, y_pred) # 计算损失
# 自动计算梯度
gradients = tape.gradient(loss, model.trainable_variables)工作机制:
GradientTape记录所有在上下文中的操作tape.gradient()根据记录的计算图自动计算梯度- 梯度应用于可训练参数更新
4.2 Keras API的三个层次
TensorFlow的Keras API提供三个层次的抽象:
高层次:使用fit()方法
python
# 最简单的方式,但不适合自定义训练循环
history = model.fit(x_data, y_data,
epochs=500,
batch_size=10,
verbose=0)中层次:自定义训练循环(本文采用)
提供灵活性,同时保持代码简洁。
低层次:完全自定义
直接操作Tensor,适合研究新算法。
4.3 模型保存与加载
TensorFlow提供多种模型保存格式:
python
# 保存整个模型(推荐)
model.save('linear_regression_model.h5')
# 加载模型
loaded_model = tf.keras.models.load_model('linear_regression_model.h5')
# 保存权重
model.save_weights('model_weights.h5')
# 加载权重
model.load_weights('model_weights.h5')五、TensorFlow与PyTorch实现对比
5.1 代码结构对比
| 部分 | TensorFlow | PyTorch |
|---|---|---|
| 模型定义 | tf.keras.Sequential()或函数式API |
nn.Module继承 |
| 损失函数 | tf.keras.losses.MSE() |
nn.MSELoss() |
| 优化器 | tf.keras.optimizers.SGD() |
torch.optim.SGD() |
| 训练循环 | GradientTape上下文 |
直接计算梯度 |
| 数据形状 | 期望[batch, features] |
期望[batch, features] |
5.2 执行模式差异
TensorFlow:
- 默认即时执行(Eager Execution)
- 支持
@tf.function装饰器转为图模式提升性能 - 计算图优化适合部署
PyTorch:
- 纯动态计算图
- 更直观的调试体验
- 更适合研究和实验
5.3 性能考量
对于简单模型如线性回归,两者性能差异不大。但在复杂场景下:
- 训练速度:TensorFlow图模式可能更快
- 内存使用:PyTorch动态图可能更灵活
- 部署:TensorFlow生态更成熟
下一篇预告
在体验了PyTorch和TensorFlow两大框架后,我们将继续探索国产深度学习框架:
机器学习算法原理与实践-入门(十):基于PaddlePaddle框架的线性回归
我们将使用百度开发的PaddlePaddle框架,了解国产深度学习框架的特点和优势,完成三框架对比的最后一环。