Decoder-only 架构与 KV Cache 深度理解
目录
- [Decoder-only 架构是什么](#Decoder-only 架构是什么)
- [KV Cache 是什么,以及为什么引入](#KV Cache 是什么,以及为什么引入)
- [推理引擎是什么,与 KV Cache 的关系](#推理引擎是什么,与 KV Cache 的关系)
Part 1:Decoder-only 架构 {#part-1}
大模型领域主流使用 Transformer 架构,Decoder-only 指的是仅使用带因果掩码(Causal Mask)的自注意力机制来做生成。
1.1 前向传播流程
Token IDs
↓ Embedding (token → d_model 向量)
┄┄ Decoder Block,重复 N 次 ┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄
x = x + MaskedSelfAttention( RMSNorm(x) ) # 残差 ①
↑ Q、K 上施加 RoPE
↑ score = QKᵀ/√d + CausalMask
↑ output = softmax(score) · V
x = x + FFN_SwiGLU( RMSNorm(x) ) # 残差 ②
┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄┄
↓ Final RMSNorm
↓ LM Head (d_model → vocab_size)
↓ Softmax
Next Token 概率分布核心公式(带因果掩码的注意力):
Attention ( Q , K , V ) = softmax ( Q K T d k + M ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}} + M\right)V Attention(Q,K,V)=softmax(dk QKT+M)V
其中 M M M 是下三角掩码矩阵,使得位置 i i i 只能 attend 到位置 ≤ i \leq i ≤i 的 token。
1.2 为什么有两条残差连接?
Decoder Block 里有两个功能完全不同的子模块,每个都需要独立的残差。
第一条:Attention 子层
x = x + MaskedSelfAttention( RMSNorm(x) )Attention 做的是跨 token 的信息聚合------让每个位置去"看"其他位置,提取上下文关系。但它不增强单个 token 自身的表达,做完之后把原始 x 加回来,保留 token 自身原有的信息。
第二条:FFN 子层
x = x + FFN_SwiGLU( RMSNorm(x) )FFN 做的是逐 token 的特征变换------对每个 token 独立做非线性映射,增强表达能力。同样加回残差,保证 Attention 聚合到的上下文信息不被覆盖掉。
为什么每个子层都要有残差?两个原因:
-
梯度流动:网络 N 层叠加,没有残差梯度会消失,模型训不动。残差提供了一条让梯度直接流回去的"高速公路"。
-
学习增量而非全量:加了残差后,每个子层只需学习"在原有基础上改变多少"。如果某层对当前 token 贡献不大,输出趋向 0,x 近似原样通过------比强迫每层都做大幅变换稳定得多。
两条残差对应两种不同操作(跨 token 聚合 vs 单 token 变换),这个设计从原始 Transformer 论文就确定下来,后续所有变体都继承了它。
1.3 降低 KV Cache 的架构设计:GQA
GQA(分组查询注意力):Q 的头数很多,但 K 和 V 的头数较少,多个 Q 共享一组 K 和 V。这是在模型架构层面减少 KV Cache 体积的核心策略,是 LLaMA 2/3 等现代模型的标配。
Part 2:KV Cache {#part-2}
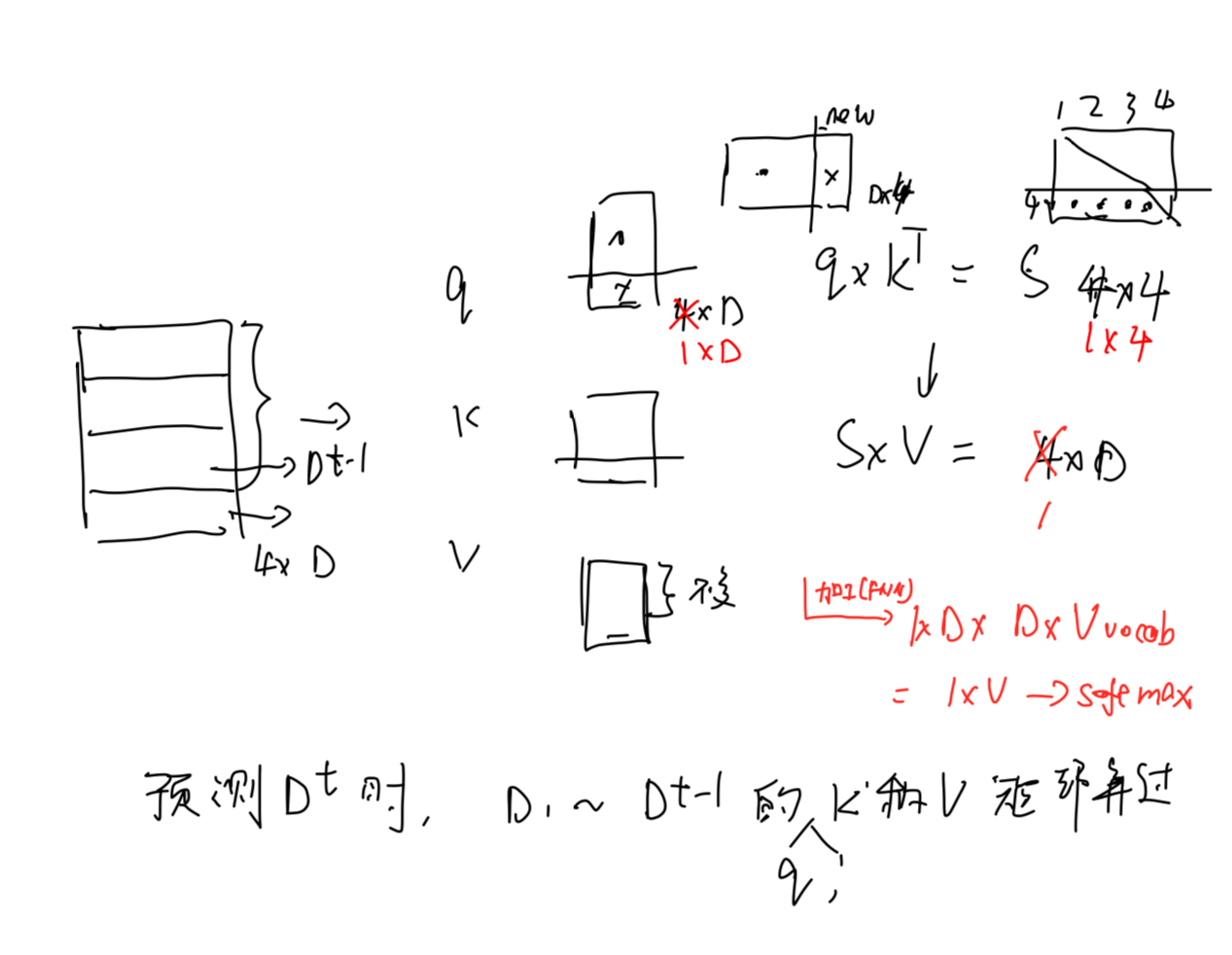
2.1 冗余性在哪里?
自回归生成的过程中,每生成一个新 Token,都需要把整个历史序列重新过一遍注意力计算。
观察下面这段朴素的生成循环输出:
step 0: input shape [1, 2] → q/k/v shape: [1, 2, 512], score shape: [1, 2, 2]
step 1: input shape [1, 3] → q/k/v shape: [1, 3, 512], score shape: [1, 3, 3]
step 2: input shape [1, 4] → q/k/v shape: [1, 4, 512], score shape: [1, 4, 4]问题所在:每一步的 K、V 矩阵,前面的部分都和上一步完全相同,却被重复计算了。这就是冗余。
2.2 朴素版(无 KV Cache)
掩码矩阵的构造:
python
import torch
import torch.nn.functional as F
mask = -(1 - torch.tril(torch.ones(4, 4))) * torch.tensor(float('inf'))
mask = torch.nan_to_num(mask, nan=0.0)
p = F.softmax(mask, dim=-1)输出(可以看到:每一行只能 attend 到自身及之前的位置):
mask:
[[ 0.00e+00, -3.40e+38, -3.40e+38, -3.40e+38],
[ 0.00e+00, 0.00e+00, -3.40e+38, -3.40e+38],
[ 0.00e+00, 0.00e+00, 0.00e+00, -3.40e+38],
[ 0.00e+00, 0.00e+00, 0.00e+00, 0.00e+00]]
softmax(mask):
[[1.0000, 0.0000, 0.0000, 0.0000],
[0.5000, 0.5000, 0.0000, 0.0000],
[0.3333, 0.3333, 0.3333, 0.0000],
[0.2500, 0.2500, 0.2500, 0.2500]]朴素 Decoder 实现:
python
import torch.nn as nn
import math
class Attention(nn.Module):
def __init__(self, dim=512):
super().__init__()
self.dim = dim
self.wq = nn.Linear(dim, dim)
self.wk = nn.Linear(dim, dim)
self.wv = nn.Linear(dim, dim)
self.wo = nn.Linear(dim, dim)
def forward(self, x, mask, verbose=False):
q, k, v = self.wq(x), self.wk(x), self.wv(x)
s = q @ k.transpose(2, 1) / math.sqrt(self.dim)
if verbose:
print('(q,k,v,s).shape:', q.shape, k.shape, v.shape, s.shape)
s = s + mask.unsqueeze(0)
p = F.softmax(s, dim=-1)
return self.wo(p @ v)
class SimpleDecoder(nn.Module):
def __init__(self, dim=512, vocab_size=100, max_len=1024):
super().__init__()
self.embd = nn.Embedding(vocab_size, dim)
self.attn = Attention(dim)
self.lm_head = nn.Linear(dim, vocab_size)
self.mask = -(1 - torch.tril(torch.ones(max_len, max_len))) * float('inf')
self.mask = torch.nan_to_num(self.mask, nan=0.0)
def forward(self, x, verbose=False):
bs, seq_len = x.shape
X = self.embd(x)
X = self.attn(X, self.mask[:seq_len, :seq_len], verbose=verbose)
return self.lm_head(X)
def generation(model, input_ids, max_new_token=100):
for i in range(max_new_token):
with torch.no_grad():
logits = model.forward(input_ids, verbose=True)
next_token = torch.argmax(F.softmax(logits[:, -1, :], dim=-1), dim=-1, keepdim=True)
input_ids = torch.cat([input_ids, next_token], dim=-1)
return input_ids运行输出(可见每步输入序列都在增长,K/V 全部重算):
step 0: input [69, 47] → q/k/v: [1,2,512], score: [1,2,2]
step 1: input [69, 47, 15] → q/k/v: [1,3,512], score: [1,3,3] ← 前2个token被重复计算
step 2: input [69,47,15,15] → q/k/v: [1,4,512], score: [1,4,4] ← 前3个token被重复计算2.3 引入 KV Cache 之后
核心思路 :把历史 token 的 K、V 缓存下来,每步只计算当前新 token 的 Q/K/V,然后把新的 K/V 拼接到缓存上。
关键变化:mask 只需要取最后一行,因为新 token 只需要知道自己能 attend 到哪些历史位置。
有KV Cache
单个token
拼接
追加
token 4
新token
只算新 Q K V
KV Cache
历史 K V
无KV Cache
完整序列
token 1
2
3
Q K V 全算
重复计算历史
python
class AttentionKVCache(nn.Module):
def __init__(self, dim=512):
super().__init__()
self.dim = dim
self.wq = nn.Linear(dim, dim)
self.wk = nn.Linear(dim, dim)
self.wv = nn.Linear(dim, dim)
self.wo = nn.Linear(dim, dim)
self.kv_cache = None # 缓存历史 K、V
def forward(self, x, mask, verbose=False):
q, k, v = self.wq(x), self.wk(x), self.wv(x)
if verbose:
print('(q,k,v).shape:', q.shape, k.shape, v.shape)
print('KV Cache:', 'empty' if self.kv_cache is None else self.kv_cache[0].shape)
# 更新缓存:首次填入,之后追加
if self.kv_cache is None:
self.kv_cache = [k, v]
else:
self.kv_cache[0] = torch.cat((self.kv_cache[0], k), dim=1)
self.kv_cache[1] = torch.cat((self.kv_cache[1], v), dim=1)
# Q 与完整历史 K 做 attention
s = q @ self.kv_cache[0].transpose(2, 1) / math.sqrt(self.dim)
# mask 只取最后一行(新 token 对全部历史的可见性)
mask = mask[-1, :].unsqueeze(0).unsqueeze(1)
s = s + mask
if verbose:
print('(s, mask).shape:', s.shape, mask.shape)
p = F.softmax(s, dim=-1)
return self.wo(p @ self.kv_cache[1])
class SimpleDecoderKVCache(nn.Module):
def __init__(self, dim=512, vocab_size=100, max_len=1024):
super().__init__()
self.embd = nn.Embedding(vocab_size, dim)
self.attn = AttentionKVCache(dim)
self.lm_head = nn.Linear(dim, vocab_size)
self.mask = -(1 - torch.tril(torch.ones(max_len, max_len))) * float('inf')
self.mask = torch.nan_to_num(self.mask, nan=0.0)
def forward(self, x, cur_len, verbose=False):
bs, seq_len = x.shape
X = self.embd(x)
X = self.attn(X, self.mask[:cur_len, :cur_len], verbose=verbose)
return self.lm_head(X)
def generation_kv(model, input_ids, max_new_token=100):
input_len = input_ids.shape[1]
output_ids = input_ids.clone()
for i in range(max_new_token):
with torch.no_grad():
logits = model.forward(input_ids, cur_len=input_len + i, verbose=True)
next_token = torch.argmax(F.softmax(logits[:, -1, :], dim=-1), dim=-1, keepdim=True)
input_ids = next_token # 每步只输入 1 个新 token
output_ids = torch.cat([output_ids, next_token], dim=-1)
return output_ids运行输出(引入 KV Cache 后,每步只有 1 个 token 过 Q/K/V,历史 K/V 从缓存读取):
loop 0: input [69, 47] → q/k/v: [1,2,512] KV Cache: empty score: [1,2,2]
loop 1: input [65] → q/k/v: [1,1,512] KV Cache: [1,2,512] score: [1,1,3]
loop 2: input [65] → q/k/v: [1,1,512] KV Cache: [1,3,512] score: [1,1,4]
output: [69, 47, 65, 65, 98]关键对比:
| 无 KV Cache | 有 KV Cache | |
|---|---|---|
| 每步计算量 | O(n²),随序列长度平方增长 | O(n),只算新 token |
| 每步输入 token 数 | 全部历史 | 仅 1 个新 token |
| 显存占用 | 无额外缓存 | KV Cache 随序列线性增长 |
2.4 KV Cache 的显存上限问题
问题:上述实现的 KV Cache 会无限增长,显存终将耗尽。
StreamingLLM 的解法:将 KV Cache 拆为两个固定部分:
KV Cache = Attention Sinks ⏟ 前 4 个 token + Recent Window ⏟ 最近 N 个 token \text{KV Cache} = \underbrace{\text{Attention Sinks}}{\text{前 4 个 token}} + \underbrace{\text{Recent Window}}{\text{最近 N 个 token}} KV Cache=前 4 个 token Attention Sinks+最近 N 个 token Recent Window
KV Cache 结构
Attention Sinks
前 ~4 个 token
永久保留
丢弃区
中间 token
Recent Window
最近 N 个 token
滑动保留
| 部分 | 作用 | 为什么保留 |
|---|---|---|
| Attention Sinks(开头 ~4 个 token) | 稳定注意力数值计算 | 实验发现模型对第一个 token 的注意力权重异常集中,移除会导致注意力分布崩溃 |
| Recent Window(滑动窗口) | 提供当前语义上下文 | 局部连贯性的核心来源 |
| 中间部分 | 丢弃 | 长文本中模型对中间信息的依赖是稀疏的,性价比最低 |
Part 3:推理引擎(Inference Engine){#part-3}
3.1 什么是推理引擎?
推理引擎是专为 AI 模型在生产环境中"跑得快、省显存、高并发"而设计的软件系统。
类比:PyTorch 是汽车制造厂 ,负责把模型"造"出来;推理引擎(vLLM、TensorRT-LLM、TGI)是底盘和传动系统,负责让造好的车以最高效率跑起来。
在工业界,很少直接用 PyTorch 的 model.forward() 对外提供服务,而是把训练好的模型权重交给推理引擎托管。
3.2 为什么不能用朴素的 for 循环?
用原生 PyTorch 线上服务会遇到三大痛点:
① 显存浪费
即使加了 torch.no_grad(),PyTorch 的灵活计算图仍会产生额外内存开销。
② 无法高效并发(Batching 问题)
100 个用户同时发请求,每个请求长度不一(5 个字 ~ 500 个字)。朴素实现无法把这些请求拼成高效的 Batch。推理引擎引入了 Continuous Batching(动态批处理):无论请求何时到来、长度多少,都能像俄罗斯方块一样塞进 GPU 并行计算。
③ 缺乏底层算子优化
推理引擎用 C++ + CUDA 重写并融合关键算子(Attention、Linear 等),消除不必要的数据搬运,大幅提升吞吐。
3.3 推理引擎与 KV Cache 的关系(核心)
毫不夸张地说,现代推理引擎的核心任务之一,就是"管理 KV Cache"。
在真实业务中,KV Cache 面临两大工程难题:
① 显存无底洞
KV Cache 大小随生成长度线性增长。1000 个并发用户、每人对话上千 token,GPU 显存会被 KV Cache 撑爆,而不是被模型权重本身撑爆。
② 显存碎片化
不知道用户会生成 10 个词还是 1000 个词:
- 提前分配大块显存 → 用户早停则浪费
- 按需分配 → 产生大量碎片,最终 OOM
vLLM 的解法:PagedAttention
借鉴操作系统的虚拟内存分页思想:
用户请求 KV Cache
显存管理器
Block 1
固定大小
Block 2
固定大小
Block N
固定大小
逻辑上连续
物理上可不连续
- 把 KV Cache 切成固定大小的"Block(页)"
- 无论序列多长,推理引擎都能像操作系统管理内存页一样,动态分配和回收 Block
- 显存利用率从朴素实现的 ~20% 提升到 >90%