【大模型LLM学习】从强化学习到GRPO 【上】
- [1 Preliminary](#1 Preliminary)
-
- [1.1 符号表示](#1.1 符号表示)
- [1.2 策略评估、预测与控制](#1.2 策略评估、预测与控制)
- [1.3 有模型与免模型](#1.3 有模型与免模型)
-
-
- [状态转移函数 P ( s ′ ∣ s , a ) P(s' \mid s, a) P(s′∣s,a)](#状态转移函数 P ( s ′ ∣ s , a ) P(s' \mid s, a) P(s′∣s,a))
- [奖励函数 R ( s , a ) R(s, a) R(s,a)](#奖励函数 R ( s , a ) R(s, a) R(s,a))
-
- [2 策略梯度](#2 策略梯度)
-
- [2.1 策略梯度的推导](#2.1 策略梯度的推导)
-
- 游戏过程与轨迹
-
- 实际计算:蒙特卡洛估计
- [∇ log p θ ( τ ) \nabla \log p_\theta(\tau) ∇logpθ(τ) 的具体计算](#∇ log p θ ( τ ) \nabla \log p_\theta(\tau) ∇logpθ(τ) 的具体计算)
- [2.2 策略梯度算法](#2.2 策略梯度算法)
- [2.3 策略梯度的实现技巧](#2.3 策略梯度的实现技巧)
-
- 技巧一:添加基线
-
- 问题:奖励总是正的
- 采样偏差加剧问题
- 解决方案:引入基线(Baseline)
- [无基线 vs 有基线](#无基线 vs 有基线)
- 使用原始策略梯度更新(无基线)
- 引入基线后的改进
- 技巧二:为每个动作分配合理的分数
-
- 问题示例
- 改进方案:只计算动作之后的回报
- [进一步优化:引入折扣因子 γ \gamma γ](#进一步优化:引入折扣因子 γ \gamma γ)
- [优势函数(Advantage Function)](#优势函数(Advantage Function))
- 基线的选择与优势函数
-
- [价值函数 vs. 动作价值函数](#价值函数 vs. 动作价值函数)
- 替换基线项
- 优势演员-评论员算法(A2C)
- [3 同策略与异策略](#3 同策略与异策略)
-
-
-
- [同策略(on policy)](#同策略(on policy))
- [异策略(off policy)](#异策略(off policy))
-
-
- [4 重要性采样](#4 重要性采样)
-
- [4.1 用重要性采样实现异策略学习](#4.1 用重要性采样实现异策略学习)
- [4.2 实际更新过程:按状态-动作对计算梯度](#4.2 实际更新过程:按状态-动作对计算梯度)
-
-
- [引入重要性采样:从 θ ′ \theta' θ′ 采样数据训练 θ \theta θ](#引入重要性采样:从 θ ′ \theta' θ′ 采样数据训练 θ \theta θ)
-
- [5 PPO](#5 PPO)
-
-
-
- 第一项:重要性采样的性能估计
- [第二项:KL 散度约束(正则化)](#第二项:KL 散度约束(正则化))
-
- [5.1 近端策略优化惩罚算法(PPO1)](#5.1 近端策略优化惩罚算法(PPO1))
-
-
- 算法流程
- [自适应 KL 惩罚(Adaptive KL Penalty)](#自适应 KL 惩罚(Adaptive KL Penalty))
-
- [5.2 近端策略优化裁剪(PPO2)](#5.2 近端策略优化裁剪(PPO2))
-
1 Preliminary
1.1 符号表示
强化学习是一个与时间相关的序列决策的问题,基本理论框架通常假设环境是一个马尔可夫决策过程(Markov Decision Process, MDP)。里面涉及到状态、动作、状态转移概率、奖励和奖励折扣因子( S 、 A 、 P 、 R 、 γ S、A、P、R、\gamma S、A、P、R、γ),这5 个合集就构成了强化学习马尔可夫决策过程的五元组:
- S S S:状态空间(state space)
- A A A:动作空间(action space)
- P ( s ′ ∣ s , a ) P(s' \mid s, a) P(s′∣s,a):状态转移概率(transition dynamics)
- R ( s , a ) R(s, a) R(s,a) 或 R ( s , a , s ′ ) R(s, a, s') R(s,a,s′):奖励函数(reward function) ,当前的状态以及采取的动作会决定智能体在当前可能得到的奖励多少
- γ ∈ 0 , 1 \gamma \in 0,1 γ∈0,1:回报的折扣因子(discount factor)
MDP 提供了一个数学上清晰、便于分析和求解的模型来描述智能体(agent)与环境(environment)之间的交互。其核心假设是 马尔可夫性(Markov Property),即:
python
"未来状态只依赖于当前状态和当前采取的动作,而与过去的历史无关。" 用公式表示就是:
P ( s t + 1 ∣ s t , a t ) = P ( s t + 1 ∣ s t , a t , s t − 1 , a t − 1 , ... , s 0 , a 0 ) P(s_{t+1} \mid s_t, a_t) = P(s_{t+1} \mid s_t, a_t, s_{t-1}, a_{t-1}, \dots, s_0, a_0) P(st+1∣st,at)=P(st+1∣st,at,st−1,at−1,...,s0,a0)
在这样的设定下,强化学习的目标通常是找到一个策略 π ( a ∣ s ) \pi(a \mid s) π(a∣s),使得期望累积回报 G t G_t Gt 最大化,其中
G t = r t + 1 + γ r t + 2 + γ 2 r t + 3 + . . . G_t = r_{t+1}+ \gamma r_{t+2}+ \gamma^2r_{t+3}+... Gt=rt+1+γrt+2+γ2rt+3+...
这里:
- r t + 1 r_{t+1} rt+1 是在时刻 t + 1 t+1 t+1 获得的即时奖励(第 t t t时刻在状态 s t s_t st时选择了某个动作 a t a_t at后,在时刻 t + 1 t+1 t+1获得的奖励; t + 1 t+1 t+1时刻处于 s t + 1 s_{t+1} st+1状态), G t G_t Gt是累积回报,一直累积到回合结束
- γ ∈ 0 , 1 \gamma \in 0, 1 γ∈0,1 是折扣因子,用于权衡当前与未来奖励的重要性, γ \gamma γ越小,表示越看重短期当下的奖励
价值函数
马尔可夫决策过程中的价值函数(value function)可定义为:
V π ( s ) = E π G t ∣ s t = s V^\pi(s) = \mathbb{E}_\pi \left G_t \\mid s_t = s \\right Vπ(s)=EπGt∣st=s
其中,期望是基于策略 π \pi π 计算的。一旦策略确定,通过对该策略进行采样,可以计算出在状态 s s s 下未来累积回报的期望,即其价值。
此外, Q 函数 (Q-function),也称为动作价值函数 (action-value function),定义为:在状态 s s s 下执行动作 a a a 后,按照策略 π \pi π 继续行动所能获得的累积回报的期望,即
Q π ( s , a ) = E π G t ∣ s t = s , a t = a Q^\pi(s, a) = \mathbb{E}_\pi \left G_t \\mid s_t = s, a_t = a \\right Qπ(s,a)=EπGt∣st=s,at=a
这里的期望同样依赖于策略 π \pi π。
1.2 策略评估、预测与控制
已知马尔可夫决策过程以及要采取的策略 π \pi π,计算价值函数 V π ( s ) V^\pi(s) Vπ(s) 的过程就是策略评估 (policy evaluation)。策略评估也被称为价值预测,也就是预测当前采取的策略最终会产生多少价值。
预测(prediction)和控制(control)则是马尔可夫决策过程(MDP)中的两个核心问题,预测是给定策略,求当前策略下的价值函数;控制是,给定同样的条件,求出在所有可能的策略下最优的价值函数是什么,最优策略是什么。
-
预测(prediction / policy evaluation)
- 目标:评估一个给定的策略
- 输入 :马尔可夫决策过程 ⟨ S , A , P , R , γ ⟩ \langle S, A, P, R, \gamma \rangle ⟨S,A,P,R,γ⟩ 和策略 π \pi π
- 输出 :价值函数 V π V^\pi Vπ
- 说明 :预测是指在给定 MDP 和策略 π \pi π 的情况下,计算该策略对应的价值函数,即估计每个状态 s s s 在策略 π \pi π 下的期望累积回报 V π ( s ) V^\pi(s) Vπ(s)
- 求解方法 :迭代法,从上一时刻的 V t V_t Vt推导下一时刻的,收敛后得到 V π V_\pi Vπ
-
控制(control / policy optimization)
- 目标:搜索最优策略
- 输入 :马尔可夫决策过程 ⟨ S , A , P , R , γ ⟩ \langle S, A, P, R, \gamma \rangle ⟨S,A,P,R,γ⟩
- 输出 :最优价值函数 V ∗ V^* V∗ 和最优策略 π ∗ \pi^* π∗
- 说明 :控制旨在寻找一个最优策略 π ∗ \pi^* π∗,使得在所有可能策略中,其对应的价值函数达到最大,即 V ∗ ( s ) = max π V π ( s ) V^*(s) = \max_\pi V^\pi(s) V∗(s)=maxπVπ(s),同时输出该最优策略 π ∗ \pi^* π∗
- 求解方法:策略迭代和价值迭代
1.3 有模型与免模型
策略迭代和价值迭代等经典动态规划方法都需要已知环境的完整模型,即状态转移函数 P ( s ′ ∣ s , a ) P(s' \mid s, a) P(s′∣s,a) 和奖励函数 R ( s , a ) R(s, a) R(s,a)。由于 P P P 依赖于状态 s s s 和动作 a a a,我们通常需要为每个 ( s , a ) (s, a) (s,a) 对指定一个概率分布。以下是一个包含 2 个状态 S = { s 1 , s 2 } S=\{s_1, s_2\} S={s1,s2} 和 2 个动作 A = { a 1 , a 2 } A=\{a_1, a_2\} A={a1,a2} 的简化示例:
状态转移函数 P ( s ′ ∣ s , a ) P(s' \mid s, a) P(s′∣s,a)
-
若在状态 s 1 s_1 s1 执行动作 a 1 a_1 a1,将会抵达的每个状态的概率:
s ′ s' s′ s 1 s_1 s1 s 2 s_2 s2 P ( s ′ ∣ s 1 , a 1 ) P(s' \mid s_1, a_1) P(s′∣s1,a1) 0.8 0.2 -
在状态 s 1 s_1 s1 执行动作 a 2 a_2 a2,将会抵达的每个状态的概率:
s ′ s' s′ s 1 s_1 s1 s 2 s_2 s2 P ( s ′ ∣ s 1 , a 2 ) P(s' \mid s_1, a_2) P(s′∣s1,a2) 0.1 0.9 -
在状态 s 2 s_2 s2 执行动作 a 1 a_1 a1,将会抵达的每个状态的概率:
s ′ s' s′ s 1 s_1 s1 s 2 s_2 s2 P ( s ′ ∣ s 2 , a 1 ) P(s' \mid s_2, a_1) P(s′∣s2,a1) 0.3 0.7 -
在状态 s 2 s_2 s2 执行动作 a 2 a_2 a2,将会抵达的每个状态的概率:
s ′ s' s′ s 1 s_1 s1 s 2 s_2 s2 P ( s ′ ∣ s 2 , a 2 ) P(s' \mid s_2, a_2) P(s′∣s2,a2) 0.0 1.0
每一行都满足 ∑ s ′ P ( s ′ ∣ s , a ) = 1 \sum_{s'} P(s' \mid s, a) = 1 ∑s′P(s′∣s,a)=1。
奖励函数 R ( s , a ) R(s, a) R(s,a)
| s s s \ a a a | a 1 a_1 a1 | a 2 a_2 a2 |
|---|---|---|
| s 1 s_1 s1 | -1 | 0 |
| s 2 s_2 s2 | 2 | 5 |
此处 R ( s , a ) R(s, a) R(s,a) 表示在状态 s s s 执行动作 a a a 后立即获得的期望奖励。
这类有模型 (model-based)方法在计算过程中并不需要智能体与环境进行交互,而是直接利用模型进行递推或迭代求解(例如表格型方法,环境是已知的,每个状态下查表做最优决策)。然而,在许多实际问题中(如雅达利游戏、围棋、直升机控制、股票交易等),环境的马尔可夫决策过程要么完全未知,要么状态空间过于庞大,使得显式建模和迭代计算变得不可行。
针对复杂场景,免模型强化学习(model-free reinforcement learning)提供了一种替代方案。免模型方法不依赖对转移和奖励函数的先验知识,而是让智能体直接与环境交互,采集大量轨迹(即状态、动作、奖励的序列)。智能体通过从这些经验数据中学习,逐步改进策略,以最大化累积奖励。这种方法更适用于复杂、高维或黑箱式的现实任务。
2 策略梯度
策略梯度(Policy Gradient)是一类基于策略的免模型的强化学习方法。与依赖价值函数间接推导策略的方法不同,策略梯度直接对策略本身进行参数化并优化。
假设策略由参数 θ \theta θ 控制,记为 π θ ( a ∣ s ) \pi_\theta(a \mid s) πθ(a∣s)。这是一个随机性策略 (stochastic policy):给定状态 s s s,它输出在该状态下选择各个动作 a a a 的概率分布。
- 在离散动作空间 中, π θ ( ⋅ ∣ s ) \pi_\theta(\cdot \mid s) πθ(⋅∣s) 通常通过 softmax 参数化,例如:
π θ ( a ∣ s ) = exp ( f θ ( s , a ) ) ∑ a ′ exp ( f θ ( s , a ′ ) ) \pi_\theta(a \mid s) = \frac{\exp(f_\theta(s, a))}{\sum_{a'} \exp(f_\theta(s, a'))} πθ(a∣s)=∑a′exp(fθ(s,a′))exp(fθ(s,a)) - 在连续动作空间 中,常将策略建模为高斯分布,即 π θ ( a ∣ s ) = N ( a ∣ μ θ ( s ) , σ θ ( s ) ) \pi_\theta(a \mid s) = \mathcal{N}(a \mid \mu_\theta(s), \sigma_\theta(s)) πθ(a∣s)=N(a∣μθ(s),σθ(s))。
重要提示 :在实际执行时,智能体不会直接取 arg max a π θ ( a ∣ s ) \arg\max_a \pi_\theta(a \mid s) argmaxaπθ(a∣s)(那会变成确定性策略),而是:
- 通过前向传播计算出每个动作的概率(例如 p 1 , p 2 , p 3 p_1, p_2, p_3 p1,p2,p3);
- 然后从该概率分布中采样一个动作作为实际执行的动作。
这种采样机制保留了探索能力,是策略梯度方法能够有效学习的关键之一。
策略梯度的核心思想是:通过调整参数 θ \theta θ,使得智能体在环境中获得的期望累积回报最大化 。其目标函数通常定义为:
J ( θ ) = E τ ∼ π θ ∑ t = 0 ∞ γ t r t J(\theta) = \mathbb{E}{\tau \sim \pi\theta} \left \\sum_{t=0}\^{\\infty} \\gamma\^t r_t \\right J(θ)=Eτ∼πθt=0∑∞γtrt
其中 τ \tau τ 表示一条由策略 π θ \pi_\theta πθ 生成的轨迹(trajectory)。
通过计算目标函数关于 θ \theta θ 的梯度(即"策略梯度"),并使用梯度上升更新参数,策略可以逐步改进。经典的 REINFORCE 算法就是最基础的策略梯度方法之一。由于策略梯度直接优化策略,且适用于连续和高维动作空间,它成为现代深度强化学习(如 PPO、A3C、DDPG 等)的重要基础。
2.1 策略梯度的推导
强化学习(Reinforcement Learning, RL)通常包含三个主要组成部分:演员(actor) 、环境(environment) 和 奖励函数(reward function) 。在策略梯度方法中,演员通过与环境交互生成轨迹,并从这些轨迹中学习如何调整策略参数 θ \theta θ,以最大化期望累积回报 G t G_t Gt。
演员(Actor)
- 角色 :演员是智能体(agent),它根据当前状态 s t s_t st 选择动作 a t a_t at。
- 目标 :演员的目标是通过与环境交互,最大化其在一场游戏(或一个回合,episode)中获得的总奖励(total reward),即回报 R R R。
2. 环境(Environment)
- 角色:环境是一个函数,它可以是基于规则的环境模型(rule-based model),也可以是复杂的模拟器(如游戏主机)。环境负责接收演员的动作并返回新的状态和相应的奖励。
- 过程 :
- 环境首先输出初始状态 s 1 s_1 s1(例如游戏画面)。
- 接收演员的动作 a 1 a_1 a1 后,环境计算并输出新的状态 s 2 s_2 s2 和奖励 r 1 r_1 r1。
- 这个过程持续进行,直到环境决定终止(例如游戏结束)。
3. 奖励函数(Reward Function)
- 定义 :奖励函数 R ( s , a ) R(s, a) R(s,a) 定义了在状态 s s s 下采取动作 a a a 后立即获得的奖励。
- 累积回报 :在一场比赛(episode)中,所有时刻的奖励加起来构成总奖励(total reward)或回报 G t G_t Gt:
G t = ∑ k = 0 ∞ γ k r t + k + 1 G_t = \sum_{k=0}^{\infty} \gamma^k r_{t+k+1} Gt=k=0∑∞γkrt+k+1
其中 γ ∈ 0 , 1 \gamma \in 0, 1 γ∈0,1 是折扣因子,用于平衡短期和长期奖励的重要性。
游戏过程与轨迹
在一个回合(episode)中,环境和演员之间的交互形成一个序列,称为轨迹(trajectory)。具体步骤如下:
- 初始状态 :环境"吐出"初始状态 s 1 s_1 s1。
- 演员决策 :演员看到状态 s 1 s_1 s1,并通过策略 π θ ( a ∣ s ) \pi_\theta(a \mid s) πθ(a∣s) 采样得到动作 a 1 a_1 a1。
- 环境响应 :环境接收到动作 a 1 a_1 a1,并更新状态到 s 2 s_2 s2,同时给出奖励 r 1 r_1 r1。
- 重复交互 :演员继续观察新状态 s 2 s_2 s2,选择动作 a 2 a_2 a2,环境再给出新状态 s 3 s_3 s3 和奖励 r 2 r_2 r2。
- 终止条件:这个过程持续进行,直到环境判断游戏结束(例如达到特定条件或时间限制)。
整个过程中形成的轨迹 τ \tau τ 可以表示为:
τ = ( s 1 , a 1 , r 1 , s 2 , a 2 , r 2 , ... , s T ) \tau = (s_1, a_1, r_1, s_2, a_2, r_2, \ldots, s_T) τ=(s1,a1,r1,s2,a2,r2,...,sT)
其中 T T T 是回合的终止步数。
给定演员的策略参数 θ \theta θ,轨迹 τ \tau τ 出现的概率由环境动态 和策略行为 共同决定:
p θ ( τ ) = p ( s 1 ) ∏ t = 1 T π θ ( a t ∣ s t ) p ( s t + 1 ∣ s t , a t ) p_\theta(\tau) = p(s_1) \prod_{t=1}^{T} \pi_\theta(a_t \mid s_t) \, p(s_{t+1} \mid s_t, a_t) pθ(τ)=p(s1)t=1∏Tπθ(at∣st)p(st+1∣st,at)
其中:
- p ( s 1 ) p(s_1) p(s1) 是初始状态分布;
- π θ ( a t ∣ s t ) \pi_\theta(a_t \mid s_t) πθ(at∣st) 是演员在状态 s t s_t st 下选择动作 a t a_t at 的概率(由参数 θ \theta θ 决定);
- p ( s t + 1 ∣ s t , a t ) p(s_{t+1} \mid s_t, a_t) p(st+1∣st,at) 是环境的状态转移概率(通常未知且不可控)。
每个轨迹 τ \tau τ 对应一个总回报 R ( τ ) = ∑ t = 1 T r t R(\tau) = \sum_{t=1}^{T} r_t R(τ)=∑t=1Trt,其中 r t = R ( s t , a t ) r_t = R(s_t, a_t) rt=R(st,at) 由外部奖励函数给出。由于策略是随机的,且环境可能具有随机性,R ( τ ) R(\tau) R(τ) 是一个随机变量 。因此,强化学习的目标不是最大化某一条轨迹的奖励,而是最大化其期望回报 :
R ˉ θ = E τ ∼ p θ ( τ ) R ( τ ) = ∑ τ R ( τ ) p θ ( τ ) \bar{R}\theta = \mathbb{E}{\tau \sim p_\theta(\tau)}R(\\tau) = \sum_{\tau} R(\tau) \, p_\theta(\tau) Rˉθ=Eτ∼pθ(τ)R(τ)=τ∑R(τ)pθ(τ)
优化的目标是最大化期望回报 R ˉ θ = E τ ∼ p θ ( τ ) R ( τ ) \bar{R}\theta = \mathbb{E}{\tau \sim p_\theta(\tau)}R(\\tau) Rˉθ=Eτ∼pθ(τ)R(τ)。为此,需计算其关于策略参数 θ \theta θ 的梯度:
∇ R ˉ θ = ∑ τ R ( τ ) ∇ p θ ( τ ) \nabla \bar{R}\theta = \sum{\tau} R(\tau) \, \nabla p_\theta(\tau) ∇Rˉθ=τ∑R(τ)∇pθ(τ)
利用恒等式:
∇ f ( x ) = f ( x ) ∇ log f ( x ) \nabla f(x) = f(x) \, \nabla \log f(x) ∇f(x)=f(x)∇logf(x)
可得:
∇ p θ ( τ ) = p θ ( τ ) ∇ log p θ ( τ ) \nabla p_\theta(\tau) = p_\theta(\tau) \, \nabla \log p_\theta(\tau) ∇pθ(τ)=pθ(τ)∇logpθ(τ)
代入上面的式子可以得到:
∇ R ˉ θ = ∑ τ R ( τ ) p θ ( τ ) ∇ log p θ ( τ ) = E τ ∼ p θ ( τ ) R ( τ ) ∇ log p θ ( τ ) \begin{aligned} \nabla \bar{R}\theta &= \sum{\tau} R(\tau) \, p_\theta(\tau) \, \nabla \log p_\theta(\tau) \\ &= \mathbb{E}{\tau \sim p\theta(\tau)} \left R(\\tau) \\, \\nabla \\log p_\\theta(\\tau) \\right \end{aligned} ∇Rˉθ=τ∑R(τ)pθ(τ)∇logpθ(τ)=Eτ∼pθ(τ)R(τ)∇logpθ(τ)
实际计算:蒙特卡洛估计
由于轨迹空间通常巨大或无限,无法遍历所有 τ \tau τ,所以是通过采样来近似期望:
- 使用当前策略 π θ \pi_\theta πθ 与环境交互,采集 N N N 条轨迹 { τ ( 1 ) , ... , τ ( N ) } \{\tau^{(1)}, \dots, \tau^{(N)}\} {τ(1),...,τ(N)};
- 计算每条轨迹的回报 R ( τ ( i ) ) R(\tau^{(i)}) R(τ(i)) 和 ∇ log p θ ( τ ( i ) ) \nabla \log p_\theta(\tau^{(i)}) ∇logpθ(τ(i));
- 用样本均值估计梯度:
∇ R ˉ θ ≈ 1 N ∑ i = 1 N R ( τ ( i ) ) ∇ log p θ ( τ ( i ) ) \nabla \bar{R}\theta \approx \frac{1}{N} \sum{i=1}^N R(\tau^{(i)}) \, \nabla \log p_\theta(\tau^{(i)}) ∇Rˉθ≈N1i=1∑NR(τ(i))∇logpθ(τ(i))
∇ log p θ ( τ ) \nabla \log p_\theta(\tau) ∇logpθ(τ) 的具体计算
轨迹 τ = ( s 1 , a 1 , s 2 , a 2 , ... , s T ) \tau = (s_1, a_1, s_2, a_2, \dots, s_T) τ=(s1,a1,s2,a2,...,sT) 的概率可分解为:
p θ ( τ ) = p ( s 1 ) ∏ t = 1 T − 1 π θ ( a t ∣ s t ) p ( s t + 1 ∣ s t , a t ) p_\theta(\tau) = p(s_1) \prod_{t=1}^{T-1} \pi_\theta(a_t \mid s_t) \, p(s_{t+1} \mid s_t, a_t) pθ(τ)=p(s1)t=1∏T−1πθ(at∣st)p(st+1∣st,at)
取对数:
log p θ ( τ ) = log p ( s 1 ) + ∑ t = 1 T − 1 log π θ ( a t ∣ s t ) + log p ( s t + 1 ∣ s t , a t ) \log p_\theta(\tau) = \log p(s_1) + \sum_{t=1}^{T-1} \left \\log \\pi_\\theta(a_t \\mid s_t) + \\log p(s_{t+1} \\mid s_t, a_t) \\right logpθ(τ)=logp(s1)+t=1∑T−1logπθ(at∣st)+logp(st+1∣st,at)
对其求梯度:
∇ log p θ ( τ ) = ∇ log p ( s 1 ) + ∑ t = 1 T − 1 ∇ log π θ ( a t ∣ s t ) + ∇ log p ( s t + 1 ∣ s t , a t ) \nabla \log p_\theta(\tau) = \nabla \log p(s_1) + \sum_{t=1}^{T-1} \left \\nabla \\log \\pi_\\theta(a_t \\mid s_t) + \\nabla \\log p(s_{t+1} \\mid s_t, a_t) \\right ∇logpθ(τ)=∇logp(s1)+t=1∑T−1∇logπθ(at∣st)+∇logp(st+1∣st,at)
由于:
- p ( s 1 ) p(s_1) p(s1) 是初始状态分布,由环境决定,与策略参数 θ \theta θ 无关 ,故 ∇ log p ( s 1 ) = 0 \nabla \log p(s_1) = 0 ∇logp(s1)=0;
- p ( s t + 1 ∣ s t , a t ) p(s_{t+1} \mid s_t, a_t) p(st+1∣st,at) 是环境的状态转移概率,也不依赖于 θ \theta θ ,故 ∇ log p ( s t + 1 ∣ s t , a t ) = 0 \nabla \log p(s_{t+1} \mid s_t, a_t) = 0 ∇logp(st+1∣st,at)=0
因此,最终有:
∇ log p θ ( τ ) = ∑ t = 1 T − 1 ∇ log π θ ( a t ∣ s t ) \nabla \log p_\theta(\tau) = \sum_{t=1}^{T-1} \nabla \log \pi_\theta(a_t \mid s_t) ∇logpθ(τ)=t=1∑T−1∇logπθ(at∣st)
只有智能体在每个时间步选择动作的概率 π θ ( a t ∣ s t ) \pi_\theta(a_t \mid s_t) πθ(at∣st) 对梯度有贡献,其余部分(环境动态)不影响策略优化。
代入后,最终梯度估计为:
∇ R ˉ θ ≈ 1 N ∑ n = 1 N ∑ t = 1 T n − 1 R ( τ ( n ) ) ∇ log π θ ( a t ( n ) ∣ s t ( n ) ) \nabla \bar{R}\theta \approx \frac{1}{N} \sum{n=1}^N \sum_{t=1}^{T_n - 1} R(\tau^{(n)}) \, \nabla \log \pi_\theta(a_t^{(n)} \mid s_t^{(n)}) ∇Rˉθ≈N1n=1∑Nt=1∑Tn−1R(τ(n))∇logπθ(at(n)∣st(n))
策略梯度的大小由两个关键因素共同决定:
-
回报(Reward) : R ( τ ) R(\tau) R(τ) 或其时间步分解形式(如 G t G_t Gt)
→ 衡量当前行为序列的"好坏"。回报越高,对应动作越值得被强化。
-
策略对数概率的梯度 : ∇ log π θ ( a t ∣ s t ) \nabla \log \pi_\theta(a_t \mid s_t) ∇logπθ(at∣st)
→ 指示"如何调整参数 θ \theta θ 才能增加该动作的概率"。
因此,策略梯度可理解为:
若某动作出现在高回报轨迹中 → 增大该动作的概率;
若某动作出现在低(或负)回报轨迹中 → 降低该动作的概率
2.2 策略梯度算法
数据收集与采样
为了计算策略梯度,我们需要通过智能体与环境交互来收集数据。具体步骤如下:
-
初始化智能体 :使用当前参数 θ \theta θ 初始化智能体。
-
与环境交互:
- 智能体在每个状态 s t s_t st 下根据策略 π θ ( a ∣ s ) \pi_\theta(a \mid s) πθ(a∣s) 选择动作 a t a_t at
- 记录每一步的状态-动作对 ( s t , a t ) (s_t, a_t) (st,at) 及其对应的奖励 r t r_t rt
- 完成一局游戏(episode),得到完整的轨迹 τ = ( s 1 , a 1 , r 1 , s 2 , a 2 , r 2 , ... , s T ) \tau = (s_1, a_1, r_1, s_2, a_2, r_2, \dots, s_T) τ=(s1,a1,r1,s2,a2,r2,...,sT) 和总奖励 R ( τ ) R(\tau) R(τ)
-
多次采样 :重复上述过程多次,收集多个轨迹 { τ ( 1 ) , τ ( 2 ) , ... , τ ( N ) } \{\tau^{(1)}, \tau^{(2)}, \dots, \tau^{(N)}\} {τ(1),τ(2),...,τ(N)}。
梯度计算与模型更新
利用收集到的数据,我们可以计算策略梯度并更新模型参数 θ \theta θ:
-
计算对数概率的梯度 :
对于每条轨迹 τ ( n ) \tau^{(n)} τ(n),计算每个时间步的状态-动作对的对数概率及其梯度:
∇ log π θ ( a t n ∣ s t n ) \nabla \log \pi_\theta(a_t^n \mid s_t^n) ∇logπθ(atn∣stn) -
加权求和 :
将每条轨迹的总奖励 R ( τ ( n ) ) R(\tau^{(n)}) R(τ(n)) 作为权重,加权求和所有轨迹的梯度:
∇ R ˉ θ ≈ 1 N ∑ n = 1 N R ( τ ( n ) ) ∑ t = 1 T n ∇ log π θ ( a t n ∣ s t n ) \nabla \bar{R}\theta \approx \frac{1}{N} \sum{n=1}^N R(\tau^{(n)}) \sum_{t=1}^{T_n} \nabla \log \pi_\theta(a_t^n \mid s_t^n) ∇Rˉθ≈N1n=1∑NR(τ(n))t=1∑Tn∇logπθ(atn∣stn) -
更新参数 :
使用梯度上升更新策略参数 θ \theta θ, α \alpha α 是学习率:
θ ← θ + α ∇ R ˉ θ \theta \leftarrow \theta + \alpha \nabla \bar{R}_\theta θ←θ+α∇Rˉθ
策略梯度 vs 分类问题
类似于分类任务中的交叉熵损失函数,我们最大化对数似然(log likelihood):
max 1 N ∑ n = 1 N ∑ t = 1 T n log π θ ( a t n ∣ s t n ) \max \frac{1}{N} \sum_{n=1}^N \sum_{t=1}^{T_n} \log \pi_\theta(a_t^n \mid s_t^n) maxN1n=1∑Nt=1∑Tnlogπθ(atn∣stn)
但在强化学习中,目标函数前乘以轨迹的总奖励 R ( τ ) R(\tau) R(τ),分类问题里面一般没有这个权重:
max 1 N ∑ n = 1 N R ( τ ( n ) ) ∑ t = 1 T n log π θ ( a t n ∣ s t n ) \max \frac{1}{N} \sum_{n=1}^N R(\tau^{(n)}) \sum_{t=1}^{T_n} \log \pi_\theta(a_t^n \mid s_t^n) maxN1n=1∑NR(τ(n))t=1∑Tnlogπθ(atn∣stn)
实际实现
在实际实现中,使用深度学习框架来自动计算损失函数和梯度:
-
定义网络结构 :构建策略网络 π θ ( a ∣ s ) \pi_\theta(a \mid s) πθ(a∣s)。
-
计算损失 :
loss = − 1 N ∑ n = 1 N R ( τ ( n ) ) ∑ t = 1 T n log π θ ( a t n ∣ s t n ) \text{loss} = - \frac{1}{N} \sum_{n=1}^N R(\tau^{(n)}) \sum_{t=1}^{T_n} \log \pi_\theta(a_t^n \mid s_t^n) loss=−N1n=1∑NR(τ(n))t=1∑Tnlogπθ(atn∣stn)负号表示梯度上升最大化期望回报
-
反向传播:调用框架内置的反向传播功能自动计算梯度并更新参数。
2.3 策略梯度的实现技巧
蘑菇书里面提到了策略梯度里面实现时可以采用的2种技巧,分别为"添加基线"和"分配合适的分数"
技巧一:添加基线
在策略梯度算法中,我们通过最大化如下目标来更新策略:
1 N ∑ n = 1 N R ( τ ( n ) ) ∑ t = 1 T n log π θ ( a t ( n ) ∣ s t ( n ) ) \frac{1}{N} \sum_{n=1}^N R(\tau^{(n)}) \sum_{t=1}^{T_n} \log \pi_\theta(a_t^{(n)} \mid s_t^{(n)}) N1n=1∑NR(τ(n))t=1∑Tnlogπθ(at(n)∣st(n))
问题:奖励总是正的
在许多任务中(如乒乓球游戏,得分范围为 0--21),总回报 R ( τ ) R(\tau) R(τ) 始终非负。这会导致一个严重问题:
- 所有被采样的动作都会被"鼓励"(因为 R ( τ ) > 0 R(\tau) > 0 R(τ)>0),
- 即使某些动作实际上表现平庸(比如只得了 0 分),其概率也会被提升。
虽然不同轨迹的 R ( τ ) R(\tau) R(τ) 有大有小,理论上高回报的动作会被提升更多,但由于策略输出是概率分布(归一化) ,若多个动作同时被提升,未被采样的动作反而会被动下降。
采样偏差加剧问题
在实际训练中,我们仅对少量轨迹进行采样。例如,在某个状态 s s s 下有三个可行动作 { a , b , c } \{a, b, c\} {a,b,c},但某次采样可能只执行了 b b b 和 c c c,从未尝试 a a a。
- 由于 R ( τ ) > 0 R(\tau) > 0 R(τ)>0,算法会提升 b b b 和 c c c 的概率;
- 而 a a a 虽未被尝试(未必差),却因概率归一化而被错误地抑制。
这显然不合理------我们希望只提升"好于平均水平"的行为,而非所有被采样的行为,否则对没采样到的不公平。
解决方案:引入基线(Baseline)
如果对回报减去一个基线值 b b b ,将梯度更新改为:
∇ R ˉ θ ≈ 1 N ∑ n = 1 N ∑ t = 1 T n ( R ( τ ( n ) ) − b ) ∇ log π θ ( a t ( n ) ∣ s t ( n ) ) \nabla \bar{R}\theta \approx \frac{1}{N} \sum{n=1}^N \sum_{t=1}^{T_n} \big( R(\tau^{(n)}) - b \big) \, \nabla \log \pi_\theta(a_t^{(n)} \mid s_t^{(n)}) ∇Rˉθ≈N1n=1∑Nt=1∑Tn(R(τ(n))−b)∇logπθ(at(n)∣st(n))
- 若 R ( τ ) > b R(\tau) > b R(τ)>b:该轨迹中的动作被鼓励;
- 若 R ( τ ) < b R(\tau) < b R(τ)<b:即使 R ( τ ) > 0 R(\tau) > 0 R(τ)>0,只要低于平均,就应被惩罚。
这样,梯度信号就有正有负,能更合理地区分"好动作"和"坏动作"。
无基线 vs 有基线
假设在某个状态 s s s 下,有三个可行动作: a a a、 b b b、 c c c。
当前策略输出的概率分布为:
π θ ( a ∣ s ) = 0.2 , π θ ( b ∣ s ) = 0.5 , π θ ( c ∣ s ) = 0.3 \pi_\theta(a \mid s) = 0.2,\quad \pi_\theta(b \mid s) = 0.5,\quad \pi_\theta(c \mid s) = 0.3 πθ(a∣s)=0.2,πθ(b∣s)=0.5,πθ(c∣s)=0.3
现在我们与环境交互 只采样了两条轨迹,动作a没有被采样到:
- 轨迹 1:在状态 s s s 执行动作 b b b,最终总回报 R ( τ ( 1 ) ) = 10 R(\tau^{(1)}) = 10 R(τ(1))=10
- 轨迹 2:在状态 s s s 执行动作 c c c,最终总回报 R ( τ ( 2 ) ) = 8 R(\tau^{(2)}) = 8 R(τ(2))=8
使用原始策略梯度更新(无基线)
根据目标函数:
L = R ( τ ( 1 ) ) log π θ ( b ∣ s ) + R ( τ ( 2 ) ) log π θ ( c ∣ s ) \mathcal{L} = R(\tau^{(1)}) \log \pi_\theta(b \mid s) + R(\tau^{(2)}) \log \pi_\theta(c \mid s) L=R(τ(1))logπθ(b∣s)+R(τ(2))logπθ(c∣s)
梯度会推动:
- π θ ( b ∣ s ) \pi_\theta(b \mid s) πθ(b∣s) 增大(权重 10)
- π θ ( c ∣ s ) \pi_\theta(c \mid s) πθ(c∣s) 增大(权重 8)
但由于策略必须满足 π θ ( a ∣ s ) + π θ ( b ∣ s ) + π θ ( c ∣ s ) = 1 \pi_\theta(a \mid s) + \pi_\theta(b \mid s) + \pi_\theta(c \mid s) = 1 πθ(a∣s)+πθ(b∣s)+πθ(c∣s)=1,
当 b b b 和 c c c 的概率都被提升时,a a a 的概率只能被动下降 ,动作 a a a 被"冤枉"了,它可能其实很好,只是没被采样到。
例如,更新后可能变为:
π θ ( a ∣ s ) = 0.1 , π θ ( b ∣ s ) = 0.6 , π θ ( c ∣ s ) = 0.3 \pi_\theta(a \mid s) = 0.1,\quad \pi_\theta(b \mid s) = 0.6,\quad \pi_\theta(c \mid s) = 0.3 πθ(a∣s)=0.1,πθ(b∣s)=0.6,πθ(c∣s)=0.3
引入基线后的改进
若设基线 b = 平均回报 = ( 10 + 8 ) / 2 = 9 b = \text{平均回报} = (10 + 8)/2 = 9 b=平均回报=(10+8)/2=9,则更新信号变为:
- 对 b b b: 10 − 9 = + 1 10 - 9 = +1 10−9=+1 → 鼓励
- 对 c c c: 8 − 9 = − 1 8 - 9 = -1 8−9=−1 → 惩罚
此时,只有真正"高于平均水平"的动作 b b b 被提升,而 c c c 被抑制, 动作 a a a 虽未采样,但不再因"所有回报为正"而被连带惩罚,保留了探索机会。
技巧二:为每个动作分配合理的分数
在基础策略梯度(如 REINFORCE)中,整条轨迹的所有状态-动作对都使用相同的总回报 R ( τ ) R(\tau) R(τ) 作为权重 :
∇ R ˉ θ ∝ ∑ t R ( τ ) ∇ log π θ ( a t ∣ s t ) \nabla \bar{R}\theta \propto \sum{t} R(\tau) \, \nabla \log \pi_\theta(a_t \mid s_t) ∇Rˉθ∝t∑R(τ)∇logπθ(at∣st)
但这显然不合理:一局游戏的结果好坏,并不能代表其中每个动作的好坏。
问题示例
考虑一场简短游戏:
- 在状态 s a s_a sa 执行动作 a 1 a_1 a1 → 获得 +5 分
- 在状态 s b s_b sb 执行动作 a 2 a_2 a2 → 获得 0 分
- 在状态 s c s_c sc 执行动作 a 3 a_3 a3 → 被扣 2 分
- 总回报 R ( τ ) = + 3 R(\tau) = +3 R(τ)=+3
虽然总分为正,但动作 a 2 a_2 a2 可能实际上导致了后续进入 s c s_c sc 并被扣分 。因此,把 +3 全部归功于 a 2 a_2 a2 是错误的。
改进方案:只计算动作之后的回报
更合理的方式是:一个动作的"功劳"应仅由它执行之后获得的奖励决定 。 即,对于时间步 t t t 的动作 a t a_t at,其贡献应为:
G t = ∑ t ′ = t T r t ′ G_t = \sum_{t'=t}^{T} r_{t'} Gt=t′=t∑Trt′
于是,策略梯度更新变为:
∇ R ˉ θ ≈ 1 N ∑ n = 1 N ∑ t = 1 T n ( ∑ t ′ = t T n r t ′ ( n ) − b ) ∇ log π θ ( a t ( n ) ∣ s t ( n ) ) \nabla \bar{R}\theta \approx \frac{1}{N} \sum{n=1}^N \sum_{t=1}^{T_n} \left( \sum_{t'=t}^{T_n} r_{t'}^{(n)} - b \right) \nabla \log \pi_\theta(a_t^{(n)} \mid s_t^{(n)}) ∇Rˉθ≈N1n=1∑Nt=1∑Tn(t′=t∑Tnrt′(n)−b)∇logπθ(at(n)∣st(n))
进一步优化:引入折扣因子 γ \gamma γ
由于越远的未来,当前动作的影响越弱 ,我们通常对未来的奖励进行指数折扣 :
G t = ∑ t ′ = t T γ t ′ − t r t ′ , γ ∈ 0 , 1 G_t = \sum_{t'=t}^{T} \gamma^{t' - t} r_{t'}, \quad \gamma \in 0, 1 Gt=t′=t∑Tγt′−trt′,γ∈0,1
- 若 γ = 0 \gamma = 0 γ=0:只关心即时奖励(短视)
- 若 γ = 1 \gamma = 1 γ=1:未来奖励与当前等价(无折扣)
- 实践中常取 γ = 0.9 \gamma = 0.9 γ=0.9 或 0.99 0.99 0.99
更新公式变为:
∇ R ˉ θ ≈ 1 N ∑ n = 1 N ∑ t = 1 T n ( ∑ t ′ = t T n γ t ′ − t r t ′ ( n ) − b ) ∇ log π θ ( a t ( n ) ∣ s t ( n ) ) \nabla \bar{R}\theta \approx \frac{1}{N} \sum{n=1}^N \sum_{t=1}^{T_n} \left( \sum_{t'=t}^{T_n} \gamma^{t' - t} r_{t'}^{(n)} - b \right) \nabla \log \pi_\theta(a_t^{(n)} \mid s_t^{(n)}) ∇Rˉθ≈N1n=1∑Nt=1∑Tn(t′=t∑Tnγt′−trt′(n)−b)∇logπθ(at(n)∣st(n))
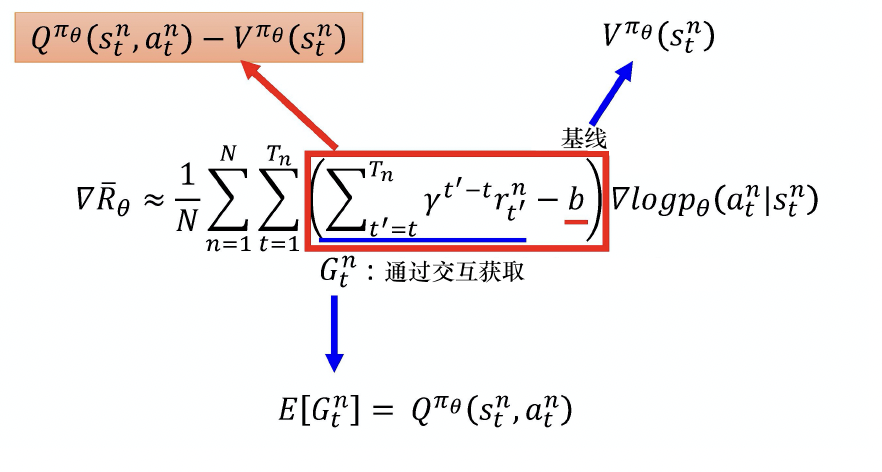
优势函数(Advantage Function)
括号内的项定义为优势函数 (Advantage Function):
A θ ( s t , a t ) = ∑ t ′ = t T γ t ′ − t r t ′ ⏟ 动作 a t 之后的实际回报 − b ( s t ) ⏟ 基线(baseline) A^\theta(s_t, a_t) = \underbrace{\sum_{t'=t}^{T} \gamma^{t' - t} r_{t'}}{\text{动作 } a_t \text{ 之后的实际回报}} - \underbrace{b(s_t)}{\text{基线(baseline)}} Aθ(st,at)=动作 at 之后的实际回报 t′=t∑Tγt′−trt′−基线(baseline) b(st)
- 含义 :在状态 s t s_t st 执行动作 a t a_t at,相对于"平均水平"有多好。
- 关键性质 :优势函数衡量的是相对优势(relative advantage),而非绝对回报。
- 基线 b ( s t ) b(s_t) b(st) 通常是状态相关的,可由一个神经网络(称为 评论员,Critic)估计。
基线的选择与优势函数
在策略梯度中,基线 b b b 的选择对训练稳定性至关重要。一个常见且有效的方法是使用状态价值函数 V π θ ( s ) V^{\pi_\theta}(s) Vπθ(s) 作为基线。
价值函数 vs. 动作价值函数
-
状态价值函数 V π θ ( s ) V^{\pi_\theta}(s) Vπθ(s):
表示在状态 s s s 下,按照策略 π θ \pi_\theta πθ 执行直到 episode 结束的期望累积回报 。它不依赖具体动作。
-
动作价值函数 Q π θ ( s , a ) Q^{\pi_\theta}(s, a) Qπθ(s,a):
表示在状态 s s s 下先执行动作 a a a ,再按策略 π θ \pi_\theta πθ 继续执行的期望回报。它显式依赖动作。
两者关系为:
V π θ ( s ) = E a ∼ π θ ( ⋅ ∣ s ) Q π θ ( s , a ) V^{\pi_\theta}(s) = \mathbb{E}{a \sim \pi\theta(\cdot \mid s)} \left Q\^{\\pi_\\theta}(s, a) \\right Vπθ(s)=Ea∼πθ(⋅∣s)Qπθ(s,a)
优势函数 的形式定义为:
A π θ ( s , a ) = Q π θ ( s , a ) − V π θ ( s ) A^{\pi_\theta}(s, a) = Q^{\pi_\theta}(s, a) - V^{\pi_\theta}(s) Aπθ(s,a)=Qπθ(s,a)−Vπθ(s)
- 若 A π θ ( s , a ) > 0 A^{\pi_\theta}(s, a) > 0 Aπθ(s,a)>0:动作 a a a 比当前策略在 s s s 下的"平均水平"更好;
- 若 A π θ ( s , a ) < 0 A^{\pi_\theta}(s, a) < 0 Aπθ(s,a)<0:动作 a a a 比平均水平更差。
由于 Q Q Q 围绕 V V V 波动, A π θ ( s , a ) A^{\pi_\theta}(s, a) Aπθ(s,a) 天然有正有负,非常适合作为策略梯度中的权重。
替换基线项
在策略梯度更新中,我们将原来的折扣回报减基线项:
∑ t ′ = t T n γ t ′ − t r t ′ ( n ) − b \sum_{t'=t}^{T_n} \gamma^{t' - t} r_{t'}^{(n)} - b t′=t∑Tnγt′−trt′(n)−b
替换为优势函数估计 :
A π θ ( s t ( n ) , a t ( n ) ) ≈ ∑ t ′ = t T n γ t ′ − t r t ′ ( n ) − V π θ ( s t ( n ) ) A^{\pi_\theta}(s_t^{(n)}, a_t^{(n)}) \approx \sum_{t'=t}^{T_n} \gamma^{t' - t} r_{t'}^{(n)} - V^{\pi_\theta}(s_t^{(n)}) Aπθ(st(n),at(n))≈t′=t∑Tnγt′−trt′(n)−Vπθ(st(n))
注意:实际中 Q π θ Q^{\pi_\theta} Qπθ 难以直接计算,因此常用蒙特卡洛回报 (即从 t t t 开始的实际折扣回报)作为 Q Q Q 的无偏估计,再减去 V π θ ( s t ) V^{\pi_\theta}(s_t) Vπθ(st) 得到 A A A。
优势演员-评论员算法(A2C)
使用优势函数的策略梯度算法称为 优势演员-评论员(Advantage Actor-Critic, A2C):
- Actor (演员):策略网络 π θ ( a ∣ s ) \pi_\theta(a \mid s) πθ(a∣s),负责选择动作;
- Critic (评论员):价值网络 V ϕ ( s ) V^\phi(s) Vϕ(s),用于估计 V π θ ( s ) V^{\pi_\theta}(s) Vπθ(s),作为基线。
最终的策略梯度目标为:
∇ R ˉ θ ∝ E A π θ ( s t , a t ) ∇ log π θ ( a t ∣ s t ) \nabla \bar{R}_\theta \propto \mathbb{E} \left A\^{\\pi_\\theta}(s_t, a_t) \\, \\nabla \\log \\pi_\\theta(a_t \\mid s_t) \\right ∇Rˉθ∝EAπθ(st,at)∇logπθ(at∣st)
这既解决了分数分配问题 (通过未来回报),又通过状态价值基线降低了方差。
3 同策略与异策略
在强化学习中,智能体需要一边和环境互动(比如玩游戏),一边从经验中学习。但"怎么用这些经验"有两种不同的思路,对应两类算法:同策略 (on-policy)和异策略 (off-policy)。
在上面提到的都是"同策略"或者说在线的方式,智能体一边探索环境计算reward一边学习,数据只使用一次。其典型特点是:智能体使用当前策略与环境交互,生成一批轨迹数据,立即用于计算梯度并更新策略,之后这些数据就被丢弃。因为梯度是基于当前策略 π θ \pi_{\theta} πθ下采样得到的轨迹对 θ \theta θ求导,一旦策略更新,旧数据就不再反映新策略的行为分布,因此不能重复使用。这种方式也被称为"在线学习"。策略梯度是一个很花时间的算法,大部分的时间都在采样数据。
同策略(on policy)
- 核心思想 :智能体用当前正在使用的策略 去和环境互动,然后直接用这些互动数据来改进自己。
- 特点 :
- 因为要兼顾探索(尝试新动作)和利用(用已知好动作),策略往往比较"谨慎"。比如在悬崖边走路时,它会故意绕远路,生怕一不小心掉下去。
- 策略在训练中不断变化(比如慢慢减少随机性),所以学到的知识只适用于"此刻的自己"。
- 是在线方式,数据一次性使用,不使用过去的数据
异策略(off policy)
- 核心思想 :智能体用一个专门负责探索的策略 (行为策略)去和环境互动,但用这些数据去优化一个完全不同的目标策略(通常是"最优"策略)。
- 特点 :
- 探索和学习被分开了:探索可以很"疯狂",但学习的目标始终是"最好"的那个策略。
- 因为目标策略不用亲自冒险,它可以更激进地追求高回报,哪怕某些路径风险很高。
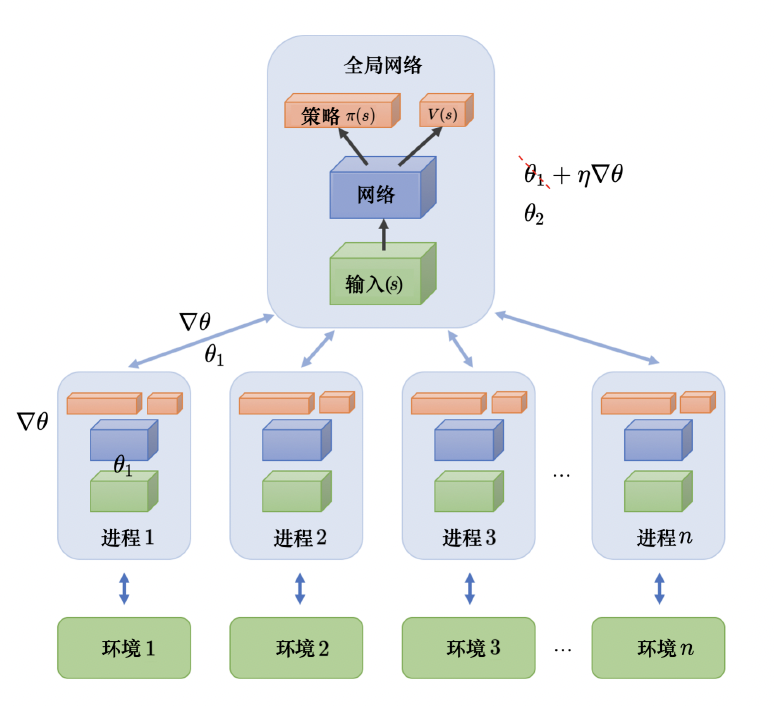
- 数据利用率更高------过去任何探索得到的经验,都可以用来改进当前最优策略。
- 可以并行化、异步化:例如A3C异步优势演员-评论员算法,所有的演员都是平行跑的,每一个演员各做各的,不管彼此。
要实现这种异策略算法,需要有办法能够使用智能体过去和环境交互的数据进行训练,这就需要用到重要性采样的方式。
4 重要性采样
策略梯度(Policy Gradient)是一种典型的同策略(on-policy)算法。其流程是:
- 使用当前策略 π θ \pi_\theta πθ(由演员执行)与环境交互,采集一批轨迹 τ \tau τ;
- 利用这些轨迹按策略梯度公式更新参数 θ \theta θ;
- 丢弃数据,重新采样 ,因为更新后的策略 π θ ′ \pi_{\theta'} πθ′ 已与旧数据分布不一致。
其理论基础是:
∇ R ˉ θ = E τ ∼ p θ ( τ ) R ( τ ) ∇ log p θ ( τ ) \nabla \bar{R}\theta = \mathbb{E}{\tau \sim p_\theta(\tau)} \left R(\\tau) \\, \\nabla \\log p_\\theta(\\tau) \\right ∇Rˉθ=Eτ∼pθ(τ)R(τ)∇logpθ(τ)
该期望依赖于当前策略 π θ \pi_\theta πθ 生成的轨迹分布 p θ ( τ ) p_\theta(\tau) pθ(τ) 。一旦 θ \theta θ 更新为 θ ′ \theta' θ′,旧数据就不再符合新分布。这导致策略梯度算法效率低下 :大部分时间花在与环境交互采样上,而每批数据只能用于一次参数更新。
为了提升效率,我们希望转向异策略(off-policy)方法:
- 用一个固定的策略 π θ ′ \pi_{\theta'} πθ′(演员策略)去采样大量数据;
- 然后用这些数据多次更新另一个目标策略 π θ \pi_\theta πθ。
只要目标策略 π θ \pi_\theta πθ 能够从 π θ ′ \pi_{\theta'} πθ′ 产生的数据中有效学习,就可以采样一次 ,但多次更新 θ \theta θ,复用历史数据的经验。要实现这个目标,需要使用重要性采样的方式。
4.1 用重要性采样实现异策略学习
问题来了:数据来自 π θ ′ \pi_{\theta'} πθ′,而我们要估计的是 π θ \pi_\theta πθ 下的期望,怎么办?
假设我们想计算 E x ∼ p f ( x ) \mathbb{E}_{x \sim p}f(x) Ex∼pf(x),但无法从分布 p p p 采样,只能从另一个分布 q q q 采样。
通过重要性采样 (Importance Sampling),我们可以改写期望为:
E x ∼ p f ( x ) = ∫ f ( x ) p ( x ) d x = ∫ f ( x ) p ( x ) q ( x ) q ( x ) d x = E x ∼ q f ( x ) ⋅ p ( x ) q ( x ) \mathbb{E}{x \sim p}f(x) = \int f(x) p(x) \, dx = \int f(x) \frac{p(x)}{q(x)} q(x) \, dx = \mathbb{E}{x \sim q}\left f(x) \\cdot \\frac{p(x)}{q(x)} \\right Ex∼pf(x)=∫f(x)p(x)dx=∫f(x)q(x)p(x)q(x)dx=Ex∼qf(x)⋅q(x)p(x)
- p ( x ) q ( x ) \frac{p(x)}{q(x)} q(x)p(x) 称为重要性权重
- 只要 q ( x ) = 0 q(x) = 0 q(x)=0 时 p ( x ) = 0 p(x) = 0 p(x)=0(即 q q q 的支撑集包含 p p p),该变换就成立
于是,即使数据来自 q q q,我们也能无偏估计 p p p 下的期望。
将上述思想用于策略梯度:
- 原本需从 p θ ( τ ) p_\theta(\tau) pθ(τ) 采样(由策略 π θ \pi_{\theta} πθ 生成);
- 现在从 p θ ′ ( τ ) p_{\theta'}(\tau) pθ′(τ) 采样(由策略 π θ ′ \pi_{\theta'} πθ′ 生成);
- 引入重要性权重修正分布差异:
∇ R ˉ θ = E τ ∼ p θ ′ ( τ ) p θ ( τ ) p θ ′ ( τ ) ⋅ R ( τ ) ∇ log p θ ( τ ) \nabla \bar{R}\theta = \mathbb{E}{\tau \sim p_{\theta'}(\tau)} \left \\frac{p_\\theta(\\tau)}{p_{\\theta'}(\\tau)} \\cdot R(\\tau) \\nabla \\log p_\\theta(\\tau) \\right ∇Rˉθ=Eτ∼pθ′(τ)pθ′(τ)pθ(τ)⋅R(τ)∇logpθ(τ)
其中:
- p θ ( τ ) p θ ′ ( τ ) \frac{p_\theta(\tau)}{p_{\theta'}(\tau)} pθ′(τ)pθ(τ) 是整条轨迹的重要性权重;
- 它衡量"目标策略 π θ \pi_\theta πθ 生成该轨迹的可能性"相对于"行为策略 π θ ′ \pi_{\theta'} πθ′"的比值。
这样实现了异策略的RL,θ ′ \theta' θ′ 负责探索和采样, θ \theta θ 负责学习,两者解耦。
应用限制
虽然重要性采样在理论上无偏,但当 p p p 和 q q q 差异很大时,方差会急剧增大。
- 例如:若 p ( x ) p(x) p(x) 在某区域概率高,而 q ( x ) q(x) q(x) 几乎为零,则少数采样到该区域的点会被赋予极大权重;
- 若采样次数不足,估计结果可能严重偏离真实期望(如正负颠倒)。
因此,实际应用中需限制 θ \theta θ 与 θ ′ \theta' θ′ 的差异(例如 PPO 通过裁剪重要性权重来控制更新步长)。
4.2 实际更新过程:按状态-动作对计算梯度
在策略梯度中,我们并不给整条轨迹 τ \tau τ 分配一个统一的分数,而是对每个状态-动作对 ( s t , a t ) (s_t, a_t) (st,at) 单独打分。
具体地,梯度更新可写为:
E ( s t , a t ) ∼ π θ A θ ( s t , a t ) ∇ log p θ ( a t ∣ s t ) \mathbb{E}{(s_t, a_t) \sim \pi\theta} \left A\^\\theta(s_t, a_t) \\nabla \\log p_\\theta(a_t \\mid s_t) \\right E(st,at)∼πθAθ(st,at)∇logpθ(at∣st)
其中:
- A θ ( s t , a t ) A^\theta(s_t, a_t) Aθ(st,at) 是优势函数 (advantage),表示在状态 s t s_t st 执行动作 a t a_t at 的相对好坏;
- ∇ log p θ ( a t ∣ s t ) \nabla \log p_\theta(a_t \mid s_t) ∇logpθ(at∣st) 是对数概率的梯度,决定如何调整参数以增加该动作的概率。
若 A θ ( s t , a t ) > 0 A^\theta(s_t, a_t) > 0 Aθ(st,at)>0:说明这个动作好,应增大其概率 ;若 A θ ( s t , a t ) < 0 A^\theta(s_t, a_t) < 0 Aθ(st,at)<0:说明这个动作差,应减小其概率。
引入重要性采样:从 θ ′ \theta' θ′ 采样数据训练 θ \theta θ
现在我们希望使用由另一个策略 π θ ′ \pi_{\theta'} πθ′ 生成的数据来训练 θ \theta θ,用一个固定的"演员" θ ′ \theta' θ′ 采集数据,用另一个"学习者" θ \theta θ 来分析和优化。由于两者分布不同,需要引入重要性采样进行修正。
最终的梯度估计变为:
E ( s t , a t ) ∼ π θ ′ p θ ( s t , a t ) p θ ′ ( s t , a t ) ⋅ A θ ( s t , a t ) ∇ log p θ ( a t ∣ s t ) \mathbb{E}{(s_t, a_t) \sim \pi{\theta'}} \left \\frac{p_\\theta(s_t, a_t)}{p_{\\theta'}(s_t, a_t)} \\cdot A\^\\theta(s_t, a_t) \\nabla \\log p_\\theta(a_t \\mid s_t) \\right E(st,at)∼πθ′pθ′(st,at)pθ(st,at)⋅Aθ(st,at)∇logpθ(at∣st)
其中:
- p θ ( s t , a t ) p θ ′ ( s t , a t ) \frac{p_\theta(s_t, a_t)}{p_{\theta'}(s_t, a_t)} pθ′(st,at)pθ(st,at) 是重要性权重,用于修正两个策略之间的概率差异;
- A θ ( s t , a t ) A^\theta(s_t, a_t) Aθ(st,at) 是根据目标策略 θ \theta θ 估计的优势(即:我们想评估的是 θ \theta θ 的行为质量)。
5 PPO
重要性采样是要求 π θ \pi_\theta πθ 与 π θ ′ \pi_{\theta'} πθ′ 不要差太远,如果 π θ \pi_\theta πθ 与 π θ ′ \pi_{\theta'} πθ′ 差异太大,重要性权重会变得极大或极小,导致方差爆炸 ,训练不稳定,重要性采样的效果就不太好。PPO(近端策略优化,proximal policy optimization)通过加入约束来使得这两个分布不差太远。
PPO的目标是优化如下目标函数:
J PPO θ ′ ( θ ) = J θ ′ ( θ ) − β ⋅ KL ( θ , θ ′ ) J_{\text{PPO}}^{\theta'}(\theta) = J^{\theta'}(\theta) - \beta \cdot \text{KL}(\theta, \theta') JPPOθ′(θ)=Jθ′(θ)−β⋅KL(θ,θ′)
其中:
- J θ ′ ( θ ) J^{\theta'}(\theta) Jθ′(θ) 是基于旧策略 π θ ′ \pi_{\theta'} πθ′ 采集的数据,对新策略 π θ \pi_\theta πθ 的性能估计;
- KL ( θ , θ ′ ) \text{KL}(\theta, \theta') KL(θ,θ′) 是新旧策略之间的 KL 散度,衡量两者分布的差异;
- β > 0 \beta > 0 β>0 是超参数,控制约束强度。
第一项:重要性采样的性能估计
J θ ′ ( θ ) = E ( s t , a t ) ∼ π θ ′ p θ ( a t ∣ s t ) p θ ′ ( a t ∣ s t ) A θ ′ ( s t , a t ) J^{\theta'}(\theta) = \mathbb{E}{(s_t, a_t) \sim \pi{\theta'}} \left \\frac{p_\\theta(a_t \\mid s_t)}{p_{\\theta'}(a_t \\mid s_t)} A\^{\\theta'}(s_t, a_t) \\right Jθ′(θ)=E(st,at)∼πθ′pθ′(at∣st)pθ(at∣st)Aθ′(st,at)
这是标准的重要性采样形式:
- 数据由旧策略 π θ ′ \pi_{\theta'} πθ′ 生成;
- 使用重要性权重 p θ ( a t ∣ s t ) p θ ′ ( a t ∣ s t ) \frac{p_\theta(a_t \mid s_t)}{p_{\theta'}(a_t \mid s_t)} pθ′(at∣st)pθ(at∣st) 将其"转换"为新策略下的期望;
- A θ ′ ( s t , a t ) A^{\theta'}(s_t, a_t) Aθ′(st,at) 是根据 θ ′ \theta' θ′ 估计的优势函数
第二项:KL 散度约束(正则化)
为避免策略更新过大,PPO 引入了 KL 散度惩罚项 :
− β ⋅ KL ( θ , θ ′ ) -\beta \cdot \text{KL}(\theta, \theta') −β⋅KL(θ,θ′)
- 它的作用是限制策略更新的步长,防止新策略偏离旧策略太远;
- 类似于正则化项,确保学习过程平稳;
- 实际上,这相当于在"允许多大程度地改变策略"之间做一个权衡。
PPO 算法有两个主要的变种:近端策略优化惩罚(PPO-penalty)和近端策略优化裁剪(PPO-clip)
5.1 近端策略优化惩罚算法(PPO1)
PPO1 是 PPO 的原始形式之一,也称为 带 KL 惩罚的近端策略优化 。其核心思想是:在保证策略更新不过大的前提下,允许多次利用同一批采样数据进行训练。
算法流程
-
初始化 策略参数 θ 0 \theta_0 θ0。
-
在第 k k k 次迭代中:
- 使用旧策略 π θ k \pi_{\theta_k} πθk 与环境交互,采集一批轨迹(状态-动作对);
- 基于这些数据,估计优势函数 A θ k ( s t , a t ) A^{\theta_k}(s_t, a_t) Aθk(st,at);
- 构造 PPO 目标函数:
J θ k PPO ( θ ) = J θ k ( θ ) − β ⋅ KL ( θ , θ k ) J^{\text{PPO}}{\theta_k}(\theta) = J{\theta_k}(\theta) - \beta \cdot \text{KL}\left( \theta, \theta_k \right) JθkPPO(θ)=Jθk(θ)−β⋅KL(θ,θk)
其中:
J θ k ( θ ) ≈ ∑ ( s t , a t ) p θ ( a t ∣ s t ) p θ k ( a t ∣ s t ) A θ k ( s t , a t ) J_{\theta_k}(\theta) \approx \sum_{(s_t, a_t)} \frac{p_\theta(a_t \mid s_t)}{p_{\theta_k}(a_t \mid s_t)} A^{\theta_k}(s_t, a_t) Jθk(θ)≈(st,at)∑pθk(at∣st)pθ(at∣st)Aθk(st,at)
-
多次更新 θ \theta θ:
- 与传统策略梯度(如 REINFORCE)不同,PPO无需每轮都重新采样
- 利用重要性采样 ,可对同一组由 θ k \theta_k θk 生成的数据多次优化 θ \theta θ
- 即使 θ \theta θ 逐渐偏离 θ k \theta_k θk,只要 KL 散度可控,训练仍稳定
自适应 KL 惩罚(Adaptive KL Penalty)
KL 惩罚项中的权重 β \beta β 需要合理设置。PPO 论文提出一种动态调整机制:
- 设定两个阈值: KL min \text{KL}{\min} KLmin 和 KL max \text{KL}{\max} KLmax;
- 每次优化后计算实际的 KL ( θ , θ k ) \text{KL}(\theta, \theta_k) KL(θ,θk):
- 若 KL ( θ , θ k ) > KL max \text{KL}(\theta, \theta_k) > \text{KL}_{\max} KL(θ,θk)>KLmax:说明约束太弱 → 增大 β \beta β;
- 若 KL ( θ , θ k ) < KL min \text{KL}(\theta, \theta_k) < \text{KL}_{\min} KL(θ,θk)<KLmin:说明约束过强(策略几乎没变)→ 减小 β \beta β。
5.2 近端策略优化裁剪(PPO2)
如果不想显式计算 KL 散度,可以使用 PPO2(即 Clipped PPO),它是 PPO 最常用、最高效的实现形式,PPO2和GRPO算法长得很类似。
目标函数
PPO2 的目标函数为:
J θ k PPO2 ( θ ) ≈ ∑ ( s t , a t ) min ( p θ ( a t ∣ s t ) p θ k ( a t ∣ s t ) A θ k ( s t , a t ) , clip ( p θ ( a t ∣ s t ) p θ k ( a t ∣ s t ) , 1 − ε , 1 + ε ) A θ k ( s t , a t ) ) J^{\text{PPO2}}{\theta_k}(\theta) \approx \sum{(s_t, a_t)} \min \left( \frac{p_\theta(a_t \mid s_t)}{p_{\theta_k}(a_t \mid s_t)} A^{\theta_k}(s_t, a_t),\ \text{clip}\left( \frac{p_\theta(a_t \mid s_t)}{p_{\theta_k}(a_t \mid s_t)},\ 1 - \varepsilon,\ 1 + \varepsilon \right) A^{\theta_k}(s_t, a_t) \right) JθkPPO2(θ)≈(st,at)∑min(pθk(at∣st)pθ(at∣st)Aθk(st,at), clip(pθk(at∣st)pθ(at∣st), 1−ε, 1+ε)Aθk(st,at))
其中:
- ε \varepsilon ε 是超参数(通常设为 0.1 或 0.2);
clip(r, 1−ε, 1+ε)将重要性权重 r = p θ p θ k r = \frac{p_\theta}{p_{\theta_k}} r=pθkpθ 限制在区间 1 − ε , 1 + ε 1-\\varepsilon, 1+\\varepsilon 1−ε,1+ε 内;min表示取两项中较小值。
裁剪机制如何工作?
无论 A A A 正负,只要策略更新过大( r r r 超出 1 − ε , 1 + ε 1-\\varepsilon, 1+\\varepsilon 1−ε,1+ε),目标函数就会"变平",**自动抑制进一步更新,防止两个分布差异过大
以 ε = 0.2 \varepsilon = 0.2 ε=0.2 为例:
- 若 p θ p θ k < 0.8 \frac{p_\theta}{p_{\theta_k}} < 0.8 pθkpθ<0.8 → clip 输出为 0.8;
- 若 p θ p θ k > 1.2 \frac{p_\theta}{p_{\theta_k}} > 1.2 pθkpθ>1.2 → clip 输出为 1.2;
- 否则,输出等于输入。
情况一:优势 A > 0 A > 0 A>0(动作是好的)
- 我们希望增大 该动作的概率(即增大 p θ p_\theta pθ);
- 但若 p θ p θ k > 1.2 \frac{p_\theta}{p_{\theta_k}} > 1.2 pθkpθ>1.2,clip 项会"卡住"在 1.2;
- 此时,
min(未裁剪项, 裁剪项)会选择 裁剪项(因为未裁剪项更大); - 目标函数不再随 p θ p_\theta pθ 增大而上升 → 梯度趋近于 0 → 更新停止。
情况二:优势 A < 0 A < 0 A<0(动作是坏的)
- 我们希望减小该动作的概率;
- 若 p θ p θ k < 0.8 \frac{p_\theta}{p_{\theta_k}} < 0.8 pθkpθ<0.8,clip 项固定为 0.8;
- 未裁剪项更小(因为 r < 0.8 r < 0.8 r<0.8 且 A < 0 A < 0 A<0,所以 r A > 0.8 A rA > 0.8A rA>0.8A);
min会选择未裁剪项 ,但一旦 r < 0.8 r < 0.8 r<0.8,继续减小 p θ p_\theta pθ 不会再降低目标函数(因为裁剪项已成上限);- 实际上,当 r r r 远小于 0.8 时,目标函数趋于平缓 → 梯度接近 0。
clip 是否让梯度为 0?
- 在裁剪区域(如 r > 1 + ε r > 1+\varepsilon r>1+ε 且 A > 0 A > 0 A>0),目标函数 = ( 1 + ε ) A (1+\varepsilon) A (1+ε)A,与 p θ p_\theta pθ 无关;
- 因此,对 θ \theta θ 求导后,梯度为 0;
- 这等价于"在更新过大的方向上不提供梯度信号",从而自然限制策略变化。