【大模型LLM学习】从强化学习到GRPO【下】
- [6 SFT与DFT](#6 SFT与DFT)
- [7 GRPO/DAPO/DUPO/GSPO](#7 GRPO/DAPO/DUPO/GSPO)
-
- [7.1 GRPO:基于分组的强化策略优化(Group-based Reinforcement Policy Optimization)](#7.1 GRPO:基于分组的强化策略优化(Group-based Reinforcement Policy Optimization))
-
-
- 核心思想
- 目标函数
- 优势函数(Advantage)
- clip项与重要性采样
- [KL 散度项](#KL 散度项)
-
- [7.2 DAPO(Dynamic Sampling Policy Optimization)](#7.2 DAPO(Dynamic Sampling Policy Optimization))
- [7.3 DUPO(Duplicating Sampling Policy Optimization)](#7.3 DUPO(Duplicating Sampling Policy Optimization))
- [7.4 GSPO(Group Sequence Policy Optimization)](#7.4 GSPO(Group Sequence Policy Optimization))
-
-
- [序列级优势估计(Group-based Advantage Estimation)](#序列级优势估计(Group-based Advantage Estimation))
- [序列级重要性比率(Sequence-level Importance Ratio)](#序列级重要性比率(Sequence-level Importance Ratio))
-
- [8 强化学习奖励稀疏的问题](#8 强化学习奖励稀疏的问题)
- [9 LLM的不确定性对RL的影响](#9 LLM的不确定性对RL的影响)
-
- [9.1 处理RL中训推的"不确定性"------蚂蚁百灵IcePop算法](#9.1 处理RL中训推的“不确定性”——蚂蚁百灵IcePop算法)
- [9.2 处理RL中DSA的"不确定性"------GLM 5](#9.2 处理RL中DSA的“不确定性”——GLM 5)
- [10 参考资料](#10 参考资料)
6 SFT与DFT
在策略梯度部分,可以发现,RL和分类问题有一丝相像,RL只是多了一个来自轨迹的奖励分数权重 R ( τ ) R(\tau) R(τ)。在LLM语境里,每一轮游戏可以认为是输入x,输出完整句子 y y y抵达<EOS>。在《On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification》一文中有进一步的说明,并提出了基于此的DFT算法(相比于DFT只改了一行代码,效果比肩GRPO)。
设 D = { ( x , y ∗ ) } \mathcal{D} = \{(x, y^*)\} D={(x,y∗)} 为采样自专家的数据集,其中 y ∗ y^* y∗ 是输入 x x x 的完整参考答案。SFT在做的事情是最小化句子级别的交叉熵:
L SFT ( θ ) = E ( x , y ∗ ) ∼ D − log π θ ( y ∗ ∣ x ) (6.1) \mathcal{L}{\text{SFT}}(\theta) = \mathbb{E}{(x,y^*) \sim \mathcal{D}} \left -\\log \\pi_\\theta(y\^\* \\mid x) \\right \tag{6.1} LSFT(θ)=E(x,y∗)∼D−logπθ(y∗∣x)(6.1)
其梯度为:
∇ θ L SFT ( θ ) = E ( x , y ∗ ) ∼ D − ∇ θ log π θ ( y ∗ ∣ x ) (6.2) \nabla_\theta \mathcal{L}{\text{SFT}}(\theta) = \mathbb{E}{(x,y^*) \sim \mathcal{D}} \left -\\nabla_\\theta \\log \\pi_\\theta(y\^\* \\mid x) \\right \tag{6.2} ∇θLSFT(θ)=E(x,y∗)∼D−∇θlogπθ(y∗∣x)(6.2)
强化学习(Reinforcement Learning, RL)
设 y y y 为从策略 π θ ( ⋅ ∣ x ) \pi_\theta(\cdot \mid x) πθ(⋅∣x) 中采样的回复, r ( x , y ) ∈ R r(x, y) \in \mathbb{R} r(x,y)∈R 为奖励函数。策略目标为:
J ( θ ) = E x ∼ D x , y ∼ π θ ( ⋅ ∣ x ) r ( x , y ) (6.3) J(\theta) = \mathbb{E}_{x \sim \mathcal{D}x,\ y \sim \pi\theta(\cdot \mid x)} \left r(x, y) \\right \tag{6.3} J(θ)=Ex∼Dx, y∼πθ(⋅∣x)r(x,y)(6.3)
其句子级别的策略梯度为:
∇ θ J ( θ ) = E x ∼ D x , y ∼ π θ ( ⋅ ∣ x ) ∇ θ log π θ ( y ∣ x ) r ( x , y ) (6.4) \nabla_\theta J(\theta) = \mathbb{E}_{x \sim \mathcal{D}x,\ y \sim \pi\theta(\cdot \mid x)} \left \\nabla_\\theta \\log \\pi_\\theta(y \\mid x) \\ r(x, y) \\right \tag{6.4} ∇θJ(θ)=Ex∼Dx, y∼πθ(⋅∣x)∇θlogπθ(y∣x) r(x,y)(6.4)
6.1 统一 SFT 与 RL 的梯度表达
通过重要性采样可以将 SFT 梯度重写为策略梯度
从式 (6.2) 的 SFT 梯度出发:
∇ θ L SFT ( θ ) = E ( x , y ∗ ) ∼ D − ∇ θ log π θ ( y ∗ ∣ x ) (6.6) \nabla_\theta \mathcal{L}{\text{SFT}}(\theta) = \mathbb{E}{(x,y^*) \sim \mathcal{D}} \left -\\nabla_\\theta \\log \\pi_\\theta(y\^\* \\mid x) \\right \tag{6.6} ∇θLSFT(θ)=E(x,y∗)∼D−∇θlogπθ(y∗∣x)(6.6)
对于每个输入 x x x,专家演示 ( x , y ∗ ) (x, y^*) (x,y∗) 的期望可显式写为对所有可能输出 y y y 的求和:
E ( x , y ∗ ) ∼ D − ∇ θ log π θ ( y ∗ ∣ x ) = E x ∼ D x ∑ y 1 y = y ∗ ( − ∇ θ log π θ ( y ∣ x ) ) (6.7) \mathbb{E}{(x,y^*) \sim \mathcal{D}} \left -\\nabla_\\theta \\log \\pi_\\theta(y\^\* \\mid x) \\right = \mathbb{E}{x \sim \mathcal{D}x} \sum_y \mathbf{1}y = y\^\* \left( -\nabla\theta \log \pi_\theta(y \mid x) \right) \tag{6.7} E(x,y∗)∼D−∇θlogπθ(y∗∣x)=Ex∼Dxy∑1y=y∗(−∇θlogπθ(y∣x))(6.7)
我们插入模型分布 π θ ( y ∣ x ) \pi_\theta(y \mid x) πθ(y∣x),从而用重要性权重表示求和:
E x ∼ D x ∑ y π θ ( y ∣ x ) ⋅ 1 y = y ∗ π θ ( y ∣ x ) ( − ∇ θ log π θ ( y ∣ x ) ) (6.8) \mathbb{E}{x \sim \mathcal{D}x} \sum_y \pi\theta(y \mid x) \cdot \frac{\mathbf{1}y = y\^\*}{\pi\theta(y \mid x)} \left( -\nabla_\theta \log \pi_\theta(y \mid x) \right) \tag{6.8} Ex∼Dxy∑πθ(y∣x)⋅πθ(y∣x)1y=y∗(−∇θlogπθ(y∣x))(6.8)
其中, 1 y = y ∗ π θ ( y ∣ x ) \frac{\mathbf{1}y = y\^\*}{\pi_\theta(y \mid x)} πθ(y∣x)1y=y∗ 是重要性权重,用于比较专家(狄拉克 δ \delta δ)分布与模型分布。
对 y y y 的求和可重写为策略分布 y ∼ π θ ( ⋅ ∣ x ) y \sim \pi_\theta(\cdot \mid x) y∼πθ(⋅∣x) 下的期望:
E x ∼ D x E y ∼ π θ ( ⋅ ∣ x ) 1 \[ y = y ∗ π θ ( y ∣ x ) ( − ∇ θ log π θ ( y ∣ x ) ) ] (6.9) \mathbb{E}{x \sim \mathcal{D}x} \mathbb{E}{y \sim \pi\theta(\cdot \mid x)} \left \\frac{\\mathbf{1}\[y = y\^\*}{\pi_\theta(y \mid x)} \left( -\nabla_\theta \log \pi_\theta(y \mid x) \right) \right] \tag{6.9} Ex∼DxEy∼πθ(⋅∣x)πθ(y∣x)1\[y=y∗(−∇θlogπθ(y∣x))](6.9)
因此,我们得到:
E ( x , y ∗ ) ∼ D − ∇ θ log π θ ( y ∗ ∣ x ) = E x ∼ D x E y ∼ π θ ( ⋅ ∣ x ) 1 \[ y = y ∗ π θ ( y ∣ x ) ( − ∇ θ log π θ ( y ∣ x ) ) ] ⏟ 重采样 + 重加权 (6.10) \mathbb{E}{(x,y^*) \sim \mathcal{D}} \left -\\nabla_\\theta \\log \\pi_\\theta(y\^\* \\mid x) \\right = \mathbb{E}{x \sim \mathcal{D}x} \underbrace{ \mathbb{E}{y \sim \pi_\theta(\cdot \mid x)} \left \\frac{\\mathbf{1}\[y = y\^\*}{\pi_\theta(y \mid x)} \left( -\nabla_\theta \log \pi_\theta(y \mid x) \right) \right] }_{\text{重采样 + 重加权}} \tag{6.10} E(x,y∗)∼D−∇θlogπθ(y∗∣x)=Ex∼Dx重采样 + 重加权 Ey∼πθ(⋅∣x)πθ(y∣x)1\[y=y∗(−∇θlogπθ(y∣x))](6.10)
该式子表明,SFT 梯度可表示为带重要性采样的策略梯度 ,通过引入重要性权重,可以将其转换为策略分布下的期望,其中专家演示分布相对于模型分布被重新加权。
SFT的梯度分析
定义辅助变量(重要性采样权重)为:
w ( y ∣ x ) = 1 π θ ( y ∣ x ) , r ( x , y ) = 1 y = y ∗ w(y \mid x) = \frac{1}{\pi_\theta(y \mid x)}, \quad r(x, y) = \mathbf{1}y = y\^\* w(y∣x)=πθ(y∣x)1,r(x,y)=1y=y∗
- 此处 r ( x , y ) r(x, y) r(x,y)是SFT的奖励函数,仅当生成的输出 y y y 与专家数据 y ∗ y^* y∗ 完全匹配时为 1,否则为 0。
重新整理6.10 并使用上述辅助变量重写,可以得到如下形式:
∇ θ L SFT ( θ ) = − E x ∼ D x , y ∼ π θ ( ⋅ ∣ x ) w ( y ∣ x ) ∇ θ log π θ ( y ∣ x ) r ( x , y ) ( 6.11 ) \nabla_\theta \mathcal{L}{\text{SFT}}(\theta) = -\mathbb{E}{x \sim \mathcal{D}x,\ y \sim \pi\theta(\cdot \mid x)} w(y \\mid x) \\nabla_\\theta \\log \\pi_\\theta(y \\mid x) r(x, y) \quad (6.11) ∇θLSFT(θ)=−Ex∼Dx, y∼πθ(⋅∣x)w(y∣x)∇θlogπθ(y∣x)r(x,y)(6.11)
这种形式的 SFT 梯度现在与策略梯度方程6.4高度一致,我们可以看到,传统的 SFT 精确地是一个带有奖励作为匹配专家轨迹指示函数的 on-policy 梯度 。但是,仔细看会发现,梯度形式上,存在重要性权重 1 / π θ 1/\pi_\theta 1/πθ这一项的偏差。
重要性采样权重 1 / π θ 1/\pi_\theta 1/πθ 是SFT 相对于 RL 泛化能力差的根本原因:
-
权重爆炸(Ill-posed Structure) :
当模型赋予专家响应较低的概率时,权重 w w w 会变得过大,梯度可能会不成比例地增长,使得训练不稳定且容易过拟合。
-
极度稀疏性(Extreme Sparsity) :
由于奖励函数 r ( x , y ) = 1 y = y ∗ r(x, y) = \mathbf{1}y = y\^\* r(x,y)=1y=y∗ 的极度稀疏性,这一问题进一步恶化,因为该函数仅在模型完全匹配专家输出时才非零。
-
结果 :
SFT的优化过程倾向于过拟合罕见的精确匹配示例,破坏了模型在训练数据之外的泛化能力。
DFT的改进
针对SFT的这种奖励偏差问题 (存在重要性权重 1 / π θ 1/\pi_\theta 1/πθ这一项的偏差),对奖励进行动态重加权 :将原始奖励乘以一个校正因子 1 / w 1/w 1/w,该因子由策略概率 π θ ( y ∗ ∣ x ) \pi_\theta(y^* \mid x) πθ(y∗∣x) 给出。由此得到的DFT的梯度为:
∇ θ L DFT ( θ ) = ∇ θ L SFT ( θ ) ⋅ sg ( 1 w ) = ∇ θ L SFT ( θ ) ⋅ sg ( π θ ( y ∗ ∣ x ) ) (6.12) \nabla_\theta \mathcal{L}{\text{DFT}}(\theta) = \nabla\theta \mathcal{L}{\text{SFT}}(\theta) \cdot \text{sg}\left(\frac{1}{w}\right) = \nabla\theta \mathcal{L}{\text{SFT}}(\theta) \cdot \text{sg}\left(\pi\theta(y^* \mid x)\right) \tag{6.12} ∇θLDFT(θ)=∇θLSFT(θ)⋅sg(w1)=∇θLSFT(θ)⋅sg(πθ(y∗∣x))(6.12)
其中:
- sg ( ⋅ ) \text{sg}(\cdot) sg(⋅) 表示停止梯度 (stop-gradient)操作符,确保梯度不会反向传播到权重缩放项 w w w 中;
- w = 1 π θ ( y ∣ x ) w = \frac{1}{\pi_\theta(y \mid x)} w=πθ(y∣x)1 是重要性采样权重。
由于在 SFT 中只有当 y = y ∗ y = y^* y=y∗ 时才有非零贡献,因此可直接用 π θ ( y ∗ ∣ x ) \pi_\theta(y^* \mid x) πθ(y∗∣x) 替代 π θ ( y ∣ x ) \pi_\theta(y \mid x) πθ(y∣x)。
由于梯度不流经缩放项,修正后的 SFT 损失可简化为一个重加权损失函数:
L DFT ( θ ) = E ( x , y ∗ ) ∼ D sg ( π θ ( y ∗ ∣ x ) ) ⋅ log π θ ( y ∗ ∣ x ) (6.13) \mathcal{L}{\text{DFT}}(\theta) = \mathbb{E}{(x,y^*) \sim \mathcal{D}} \left \\text{sg}\\left(\\pi_\\theta(y\^\* \\mid x)\\right) \\cdot \\log \\pi_\\theta(y\^\* \\mid x) \\right \tag{6.13} LDFT(θ)=E(x,y∗)∼Dsg(πθ(y∗∣x))⋅logπθ(y∗∣x)(6.13)
然而,在实际应用中,对整条序列计算重要性权重可能导致数值不稳定 。常见的解决方案是借鉴 PPO 的做法,在词元级别(token level)应用重要性采样。最终的 DFT 损失函数为:
L DFT ( θ ) = E ( x , y ∗ ) ∼ D − ∑ t = 1 ∣ y ∗ ∣ sg ( π θ ( y t ∗ ∣ y \< t ∗ , x ) ) ⋅ log π θ ( y t ∗ ∣ y \< t ∗ , x ) (6.14) \mathcal{L}{\text{DFT}}(\theta) = \mathbb{E}{(x,y^*) \sim \mathcal{D}} \left -\\sum_{t=1}\^{\|y\^\*\|} \\text{sg}\\left(\\pi_\\theta(y_t\^\* \\mid y_{\
DFT的梯度分析
DFT 损失函数的梯度为:
∇ θ L DFT = − sg ( π θ ( y ∗ ∣ x ) ) ⋅ 1 π θ ( y ∗ ∣ x ) ⋅ ∇ θ π θ ( y ∗ ∣ x ) (6.15) \nabla_\theta \mathcal{L}{\text{DFT}} = -\, \text{sg}\left(\pi\theta(y^* \mid x)\right) \cdot \frac{1}{\pi_\theta(y^* \mid x)} \cdot \nabla_\theta \pi_\theta(y^* \mid x) \tag{6.15} ∇θLDFT=−sg(πθ(y∗∣x))⋅πθ(y∗∣x)1⋅∇θπθ(y∗∣x)(6.15)
前向传播中 sg ( π θ ( y ∗ ∣ x ) ) = π θ ( y ∗ ∣ x ) \text{sg}(\pi_\theta(y^* \mid x)) = \pi_\theta(y^* \mid x) sg(πθ(y∗∣x))=πθ(y∗∣x),因此:
∇ θ L DFT = − ( sg ( π θ ( y ∗ ∣ x ) ) π θ ( y ∗ ∣ x ) ) ∇ θ π θ ( y ∗ ∣ x ) (6.16) \nabla_\theta \mathcal{L}{\text{DFT}} = -\left( \frac{\text{sg}(\pi\theta(y^* \mid x))}{\pi_\theta(y^* \mid x)} \right) \nabla_\theta \pi_\theta(y^* \mid x) \tag{6.16} ∇θLDFT=−(πθ(y∗∣x)sg(πθ(y∗∣x)))∇θπθ(y∗∣x)(6.16)
由于分子和分母相等,比例项数值上等于 1,最终得到:
∇ θ L DFT = − ∇ θ π θ ( y ∗ ∣ x ) (6.17) \nabla_\theta \mathcal{L}{\text{DFT}} = -\, \nabla\theta \pi_\theta(y^* \mid x) \tag{6.17} ∇θLDFT=−∇θπθ(y∗∣x)(6.17)
从上式可以发现,DFT 的梯度等价于直接最大化目标 token 的模型概率本身,而非像SFT那样最大化其对数概率:
| 方法 | 损失函数 | 梯度表达式 |
|---|---|---|
| SFT交叉熵(CE) | L CE ( θ ) = − log π θ ( y ∗ ∣ x ) \mathcal{L}{\text{CE}}(\theta) = -\log \pi\theta(y^* \mid x) LCE(θ)=−logπθ(y∗∣x) | ∇ θ L CE = − 1 π θ ( y ∗ ∣ x ) ∇ θ π θ ( y ∗ ∣ x ) \nabla_\theta \mathcal{L}{\text{CE}} = -\frac{1}{\pi\theta(y^* \mid x)} \nabla_\theta \pi_\theta(y^* \mid x) ∇θLCE=−πθ(y∗∣x)1∇θπθ(y∗∣x) |
| DFT | L DFT ( θ ) = − sg ( π θ ( y ∗ ∣ x ) ) ⋅ log π θ ( y ∗ ∣ x ) \mathcal{L}{\text{DFT}}(\theta) = -\text{sg}(\pi\theta(y^* \mid x)) \cdot \log \pi_\theta(y^* \mid x) LDFT(θ)=−sg(πθ(y∗∣x))⋅logπθ(y∗∣x) | ∇ θ L DFT = − ∇ θ π θ ( y ∗ ∣ x ) \nabla_\theta \mathcal{L}{\text{DFT}} = -\nabla\theta \pi_\theta(y^* \mid x) ∇θLDFT=−∇θπθ(y∗∣x) |
DFT的更新更稳定,不同意过拟合,因为:
-
避免极端更新 :
在 CE 中,若模型对某个专家 token 的预测概率极低(如 10 − 5 10^{-5} 10−5),则梯度会被放大 10 5 10^5 105 倍,导致参数剧烈震荡,容易过拟合稀有样本。
-
DFT 的"保守"策略 :
它对所有正确 token 应用相同的更新强度(因子为 1),不因概率高低而区别对待,缓解了过拟合。相比于前LLM时代的focal loss,DFT可以说是反其道而行之,之前是欠拟合是问题,现在是过拟合是问题。
只是形式上是RL,本质上是修改SFT权重的DFT,在效果上接近甚至超过on policy的RL:
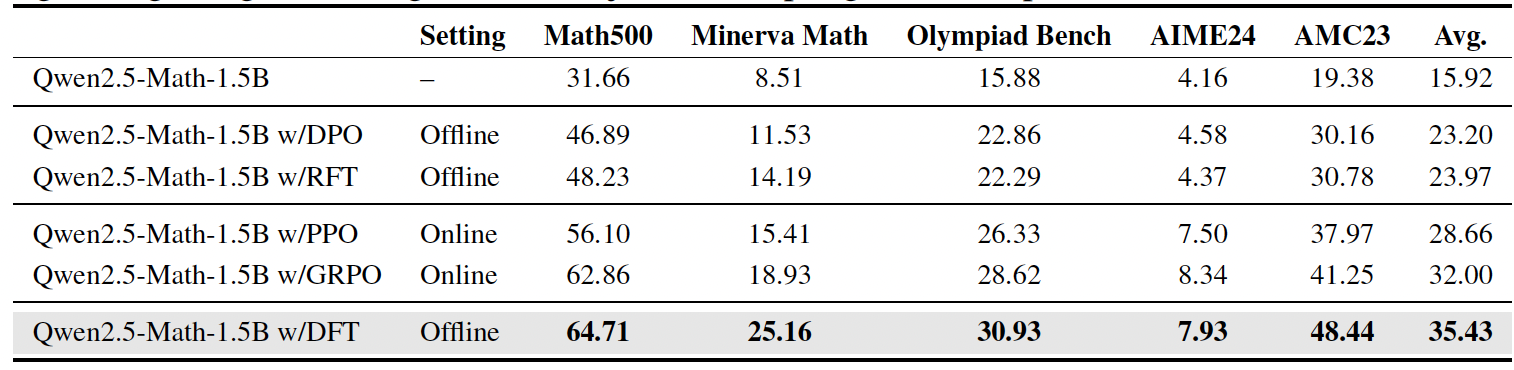
7 GRPO/DAPO/DUPO/GSPO
7.1 GRPO:基于分组的强化策略优化(Group-based Reinforcement Policy Optimization)
GRPO 旨在通过对每个问题采样多个输出并进行分组比较 ,提升训练稳定性和泛化能力。它结合了 PPO 的思想,并引入了群体奖励归一化 与KL 散度约束。
核心思想
GRPO中涉及3个模型:
| 模型 | 符号 | 作用 | 是否更新 |
|---|---|---|---|
| 当前训练策略(Actor/Trainer) | π θ \pi_\theta πθ | 当前正在优化的目标策略,用于生成新动作/输出 | 是 |
| 旧策略(Behavior / Sampling Policy/ Sampler) | π θ old \pi_{\theta_{\text{old}}} πθold | 用于与环境交互、采样一组输出 {o_i} | 固定,仅用于采样 |
| 参考策略(Reference Policy) | π ref \pi_{\text{ref}} πref | 通常是预训练模型或 SFT 模型,用于 KL 正则化,防止偏离太远 | 固定 |
对于每一个输入问题 q q q,GRPO 执行以下步骤:
- 从旧策略 π θ old \pi_{\theta_{\text{old}}} πθold 中采样一组输出 { o 1 , o 2 , ... , o G } \{o_1, o_2, \dots, o_G\} {o1,o2,...,oG};
- 为每个输出分配一个奖励 r i r_i ri(例如来自人类标注或奖励模型);
- 计算每个输出的优势函数 A i A_i Ai,使用组内奖励的均值和标准差进行归一化;
- 最大化一个综合目标函数,该函数同时考虑优势、重要性采样和策略稳定性。
目标函数
GRPO 的优化目标如下:
J GRPO ( θ ) = E q ∼ P ( Q ) , { o i } i = 1 G ∼ π θ old ( O ∣ q ) 1 G ∑ i = 1 G ( min ( π θ ( o i ∣ q ) π θ old ( o i ∣ q ) A i , clip ( π θ ( o i ∣ q ) π θ old ( o i ∣ q ) , 1 − ε , 1 + ε ) A i ) − β D KL ( π θ ∥ π ref ) ) \mathcal{J}{\text{GRPO}}(\theta) = \mathbb{E}{q \sim P(Q), \{o_i\}{i=1}^G \sim \pi{\theta_{\text{old}}}(O|q)} \left \\frac{1}{G} \\sum_{i=1}\^{G} \\left( \\min \\left( \\frac{\\pi_\\theta(o_i\|q)}{\\pi_{\\theta_{\\text{old}}}(o_i\|q)} A_i,\\ \\text{clip}\\left( \\frac{\\pi_\\theta(o_i\|q)}{\\pi_{\\theta_{\\text{old}}}(o_i\|q)},\\ 1-\\varepsilon,\\ 1+\\varepsilon \\right) A_i \\right) - \\beta \\mathbb{D}_{\\text{KL}}(\\pi_\\theta \\\| \\pi_{\\text{ref}}) \\right) \\right JGRPO(θ)=Eq∼P(Q),{oi}i=1G∼πθold(O∣q)G1i=1∑G(min(πθold(oi∣q)πθ(oi∣q)Ai, clip(πθold(oi∣q)πθ(oi∣q), 1−ε, 1+ε)Ai)−βDKL(πθ∥πref))
其中:
- π ref \pi_{\text{ref}} πref 是参考策略(如预训练模型或 SFT 模型);
- ε \varepsilon ε 和 β \beta β 是超参数;
- A i A_i Ai 是第 i i i 个输出的优势函数。
- π θ ( o i ∣ q ) π θ old ( o i ∣ q ) \frac{\pi_\theta(o_i \mid q)}{\pi_{\theta_{\text{old}}}(o_i \mid q)} πθold(oi∣q)πθ(oi∣q) 是重要性采样权重
优势函数(Advantage)
优势函数 A i A_i Ai 使用组内奖励进行标准化:
A i = r i − mean ( { r 1 , r 2 , ... , r G } ) std ( { r 1 , r 2 , ... , r G } ) A_i = \frac{r_i - \text{mean}(\{r_1, r_2, \dots, r_G\})}{\text{std}(\{r_1, r_2, \dots, r_G\})} Ai=std({r1,r2,...,rG})ri−mean({r1,r2,...,rG})
clip项与重要性采样
在 GRPO (Group-based Reinforcement Policy Optimization)中,clip 操作继承自 PPO(近端策略优化),其核心作用是:限制策略更新的幅度,防止新策略 π θ \pi_\theta πθ 相对于旧策略 π θ old \pi_{\theta_{\text{old}}} πθold 发生剧烈变化,从而保证训练稳定性 。
其中:
- r i = π θ ( o i ∣ q ) π θ old ( o i ∣ q ) r_i = \dfrac{\pi_\theta(o_i \mid q)}{\pi_{\theta_{\text{old}}}(o_i \mid q)} ri=πθold(oi∣q)πθ(oi∣q) 是重要性采样权重;
- ε \varepsilon ε 是超参数(通常设为 0.1 或 0.2);
- clip ( r , 1 − ε , 1 + ε ) \text{clip}(r, 1-\varepsilon, 1+\varepsilon) clip(r,1−ε,1+ε) 将 r r r 限制在区间 1 − ε , 1 + ε 1 - \\varepsilon,\\ 1 + \\varepsilon 1−ε, 1+ε 内。
具体规则为:
- 若 r < 1 − ε r < 1 - \varepsilon r<1−ε,输出 1 − ε 1 - \varepsilon 1−ε;
- 若 r > 1 + ε r > 1 + \varepsilon r>1+ε,输出 1 + ε 1 + \varepsilon 1+ε;
- 否则,输出 r r r。
本质上,clip + min 构成了一个"软性安全边界",确保策略更新既有效又不过激
-
当优势 A i > 0 A_i > 0 Ai>0(该输出较好):
- 希望增大 π θ ( o i ∣ q ) \pi_\theta(o_i \mid q) πθ(oi∣q);
- 但若 r i > 1 + ε r_i > 1 + \varepsilon ri>1+ε,说明新策略已大幅提高该动作概率;
- 此时
min会选择裁剪项 ( 1 + ε ) A i (1+\varepsilon) A_i (1+ε)Ai,使目标函数不再随 r i r_i ri 增大而上升; - → 梯度趋近于 0,更新自动停止。
-
当优势 A i < 0 A_i < 0 Ai<0(该输出较差):
- 希望减小 π θ ( o i ∣ q ) \pi_\theta(o_i \mid q) πθ(oi∣q);
- 若 r i < 1 − ε r_i < 1 - \varepsilon ri<1−ε,说明概率已过低;
- 裁剪项 ( 1 − ε ) A i (1-\varepsilon) A_i (1−ε)Ai(注意 A i < 0 A_i<0 Ai<0)会大于原始项 r i A i r_i A_i riAi;
min选择原始项,但继续减小 r i r_i ri 对目标改善有限;- → 梯度自然衰减,避免过度惩罚。
KL 散度项
KL 散度项用于控制策略更新幅度:
D KL ( π θ ∥ π ref ) = π ref ( o i ∣ q ) π θ ( o i ∣ q ) − log π ref ( o i ∣ q ) π θ ( o i ∣ q ) − 1 \mathbb{D}{\text{KL}}(\pi\theta \| \pi_{\text{ref}}) = \frac{\pi_{\text{ref}}(o_i|q)}{\pi_\theta(o_i|q)} - \log \frac{\pi_{\text{ref}}(o_i|q)}{\pi_\theta(o_i|q)} - 1 DKL(πθ∥πref)=πθ(oi∣q)πref(oi∣q)−logπθ(oi∣q)πref(oi∣q)−1
7.2 DAPO(Dynamic Sampling Policy Optimization)
Tongyi DeepResearch系列的WebDancer中使用的是DAPO,考虑的是,如果某次rollout,结果是全对或者全错,那么对于这个样本及其对应的rollout是没有必要放进去训的(全对/全错的基线b=0)。
J DAPO ( θ ) = E ( q , a ) ∼ D , { o i } i = 1 G ∼ π θ old ( ⋅ ∣ context ) 1 ∑ i = 1 G ∣ o i ∣ ∑ i = 1 G ∑ t = 1 ∣ o i ∣ min ( r i , t ( θ ) A \^ i , t , clip ( r i , t ( θ ) , 1 − ε low , 1 + ε high ) A \^ i , t ) \mathcal{J}{\text{DAPO}}(\theta) = \mathbb{E}{(q,a) \sim \mathcal{D},\ \{o_i\}{i=1}^G \sim \pi{\theta_{\text{old}}}(\cdot \mid \text{context})} \left \\frac{1}{\\sum_{i=1}\^G \|o_i\|} \\sum_{i=1}\^G \\sum_{t=1}\^{\|o_i\|} \\min \\left( r_{i,t}(\\theta) \\hat{A}_{i,t},\\ \\text{clip}\\left(r_{i,t}(\\theta),\\ 1 - \\varepsilon_{\\text{low}},\\ 1 + \\varepsilon_{\\text{high}}\\right) \\hat{A}_{i,t} \\right) \\right JDAPO(θ)=E(q,a)∼D, {oi}i=1G∼πθold(⋅∣context) ∑i=1G∣oi∣1i=1∑Gt=1∑∣oi∣min(ri,t(θ)A^i,t, clip(ri,t(θ), 1−εlow, 1+εhigh)A^i,t)
加入了约束条件,去掉全对和全错的这种样本:
s.t. 0 < ∣ { o i ∣ is_equivalent ( y , o i ) } ∣ < G , \text{s.t.} \quad 0 < \left| \left\{ o_i \mid \text{is\_equivalent}(y, o_i) \right\} \right| < G, s.t.0< {oi∣is_equivalent(y,oi)} <G,
7.3 DUPO(Duplicating Sampling Policy Optimization)
DAPO需要丢弃全对全错的样本,然后再用后面的非全对全错的来填充这个batch的空缺,这让训练更慢了。
为了解决这一问题,WebSailor论文中提出,在训练前先过滤掉过于简单的样本(即 8 条 rollout 全部正确的样本)。在训练过程中,不再使用填充(padding)的方法来保证每个batch的batchsize一样大,而是随机复制同一批次内标准差非零的样本到空缺的位置。与 DAPO 的动态采样相比,该方法实现了约 2-3 倍的加速。
具体而言,在一个batch中也是只保留非全对全错的样本,对于全对/全错的产生的空缺,不再用后面的样本rollout来填补,而是在这个batch里面现有能用的样本进行随机复制填充。
7.4 GSPO(Group Sequence Policy Optimization)
在Tongyi DeeoResearch的WebResearcher系列中,使用了GSPO算法。一个智能体ReACT形式解决问题涉及多个round,GRPO是token-level的重要性采样,GSPO则是sentence-level的重要性采样。传统的Agent训练,把一个轮次看成一个样本,WebResearcher把每个round看成一个样本,给出序列级别的奖励。
具体来说:
- 对于第 i i i 个问题 q ( i ) q^{(i)} q(i),从策略 π θ old \pi_{\theta_{\text{old}}} πθold 中采样 G G G 条 rollout 轨迹;
- 第 g g g 条轨迹包含 T g ( i ) T_g^{(i)} Tg(i) 个研究轮次;
- 每个轮次 j j j 产生一个训练三元组:
( s g , j ( i ) , r g , j ( i ) , o g , j ( i ) ) \left( s_{g,j}^{(i)},\ r_{g,j}^{(i)},\ o_{g,j}^{(i)} \right) (sg,j(i), rg,j(i), og,j(i))
其中:- s g , j ( i ) s_{g,j}^{(i)} sg,j(i):状态(state),即当前的研究上下文;
- r g , j ( i ) r_{g,j}^{(i)} rg,j(i):奖励 (reward),衡量该轮回答的质量(注:论文未给出具体计算公式,有可能是直接把整个轮次的reward进行share,或者精细化的打分方式);
- o g , j ( i ) o_{g,j}^{(i)} og,j(i):工具响应(observation),如搜索结果、API 返回等。
由此,每个问题 q ( i ) q^{(i)} q(i) 可构建一个丰富的训练语料库:
C ( i ) = { ( s g , j ( i ) , r g , j ( i ) ) ∣ g ∈ 1 , G , j ∈ 1 , T g ( i ) } \mathcal{C}^{(i)} = \left\{ \left( s_{g,j}^{(i)},\ r_{g,j}^{(i)} \right) \mid g \in 1, G,\ j \in 1, T_g\^{(i)} \right\} C(i)={(sg,j(i), rg,j(i))∣g∈1,G, j∈1,Tg(i)}
共包含 ∑ g = 1 G T g ( i ) \sum_{g=1}^G T_g^{(i)} ∑g=1GTg(i) 个样本。
训练时,使用GSPO的序列级优化目标:
J GSPO ( θ ) = E x ∼ D , { y i } i = 1 G ∼ π θ old ( ⋅ ∣ x ) 1 G ∑ i = 1 G min ( s i ( θ ) A \^ i , clip ( s i ( θ ) , 1 − ε , 1 + ε ) A \^ i ) \mathcal{J}{\text{GSPO}}(\theta) = \mathbb{E}{x \sim \mathcal{D},\ \{y_i\}{i=1}^G \sim \pi{\theta_{\text{old}}}(\cdot \mid x)} \left \\frac{1}{G} \\sum_{i=1}\^G \\min \\left( s_i(\\theta) \\hat{A}_i,\\ \\text{clip}\\left(s_i(\\theta),\\ 1 - \\varepsilon,\\ 1 + \\varepsilon\\right) \\hat{A}_i \\right) \\right JGSPO(θ)=Ex∼D, {yi}i=1G∼πθold(⋅∣x)G1i=1∑Gmin(si(θ)A\^i, clip(si(θ), 1−ε, 1+ε)A\^i)
其中:
- s i ( θ ) s_i(\theta) si(θ) 是第 i i i 个样本的序列级重要性比率;
- A ^ i \hat{A}_i A^i 是基于组内归一化的优势估计
序列级优势估计(Group-based Advantage Estimation)
A ^ i = r ( x , y i ) − mean ( { r ( x , y j ) } j = 1 G ) std ( { r ( x , y j ) } j = 1 G ) \hat{A}i = \frac{r(x, y_i) - \text{mean}\left(\{r(x, y_j)\}{j=1}^G\right)}{\text{std}\left(\{r(x, y_j)\}_{j=1}^G\right)} A^i=std({r(x,yj)}j=1G)r(x,yi)−mean({r(x,yj)}j=1G)
- 对每个问题 x x x,采样 G G G 个响应 { y i } \{y_i\} {yi};
- 使用组内均值和标准差对奖励进行标准化;
- 使不同样本间的奖励具有可比性,避免绝对尺度差异影响训练。
序列级重要性比率(Sequence-level Importance Ratio)
定义为:
s i ( θ ) = ( π θ ( y i ∣ x ) π θ old ( y i ∣ x ) ) 1 ∣ y i ∣ = exp ( 1 ∣ y i ∣ ∑ t = 1 ∣ y i ∣ log π θ ( y i , t ∣ x , y i , < t ) π θ old ( y i , t ∣ x , y i , < t ) ) s_i(\theta) = \left( \frac{\pi_\theta(y_i \mid x)}{\pi_{\theta_{\text{old}}}(y_i \mid x)} \right)^{\frac{1}{|y_i|}} = \exp\left( \frac{1}{|y_i|} \sum_{t=1}^{|y_i|} \log \frac{\pi_\theta(y_{i,t} \mid x, y_{i,<t})}{\pi_{\theta_{\text{old}}}(y_{i,t} \mid x, y_{i,<t})} \right) si(θ)=(πθold(yi∣x)πθ(yi∣x))∣yi∣1=exp ∣yi∣1t=1∑∣yi∣logπθold(yi,t∣x,yi,<t)πθ(yi,t∣x,yi,<t)
GSPO相比于GRPO,用序列级重要性权重,避免 token 级权重波动带来的梯度震荡,不再过度拟合局部 token,鼓励生成高质量完整响应。
8 强化学习奖励稀疏的问题
强化学习是奖励稀疏的,例如WebAgent,从开始搜索到最后产生回答,中间可能有十几步甚至上百步,最后有了final answer后和标准答案比较才产生一个0/1的reward。
现有的WebAgent方法没有充分利用实体的信息,《Repurposing Synthetic Data for Fine-grained Search Agent Supervision》这篇论文提出了一种entity-aware的 reward function,把奖励变得密集。
首先,它发现,在搜索到最终的答案前,think/response里面会含有各种实体,如果模型走的这条路是对的,涉及的实体和正确路径的实体交集比例是比较大的,如果走的路是错的,实体的match rate就低,二者正相关,因此从实体匹配率的角度设计了更密集的奖励信号。
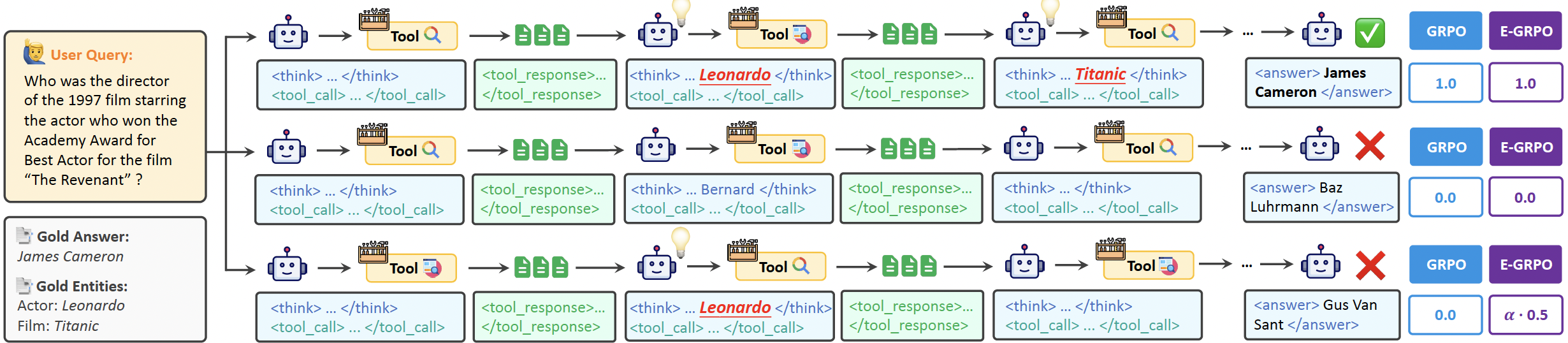
对于一个QA对,如果它里面有 m m m个实体,在 r o l l o u t i rollout_i rollouti,如果提到了其中的 E i E_i Ei个,提及率为 γ i = E i m \gamma_i=\frac{E_i}{m} γi=mEi,在GRPO中使用归一化的 γ i ~ \tilde{\gamma_i} γi~:
γ ^ i = { γ i γ max if γ max > 0 0 otherwise where γ max = max j ∈ { 1 , ... , G } γ j . \hat{\gamma}i = \begin{cases} \dfrac{\gamma_i}{\gamma{\max}} & \text{if } \gamma_{\max} > 0 \\ 0 & \text{otherwise} \end{cases} \quad \text{where} \quad \gamma_{\max} = \max_{j \in \{1, \ldots, G\}} \gamma_j. γ^i=⎩ ⎨ ⎧γmaxγi0if γmax>0otherwisewhereγmax=j∈{1,...,G}maxγj.
完整的reward function定义如下,相比于通常的GRPO,对于回答错误的 R i R_i Ri并不是直接定义为0,而是 α ⋅ γ i ~ \alpha \cdot \tilde{\gamma_i} α⋅γi~,只有格式错误的才是打出reward=0,这样的方式区分了准确、部分准确和错误,更好的利用样本:
R i = { 1 if H ( i ) is correct α ⋅ γ ^ i if H ( i ) is wrong 0 if error 1 occurs in H ( i ) R_i = \begin{cases} 1 & \text{if } \mathcal{H}^{(i)} \text{ is correct} \\ \alpha \cdot \hat{\gamma}_i & \text{if } \mathcal{H}^{(i)} \text{ is wrong} \\ 0 & \text{if error\^1 occurs in } \mathcal{H}^{(i)} \end{cases} Ri=⎩ ⎨ ⎧1α⋅γ^i0if H(i) is correctif H(i) is wrongif error1 occurs in H(i)
9 LLM的不确定性对RL的影响
在《【大模型LLM学习】推理阶段同一样本LLM输出结果不同的原因》里面有提到,温度为0时,同一个样本的结果不一样对RL会有一定的影响,如果准确的进行重要性采样设置或者使用确定性的kernel(对性能损害较大),能避免RL一言不合就崩了。这种现象可能对于dense小模型训练不是大问题,但是对于MoE模型还有DSA等机制会产生大问题。
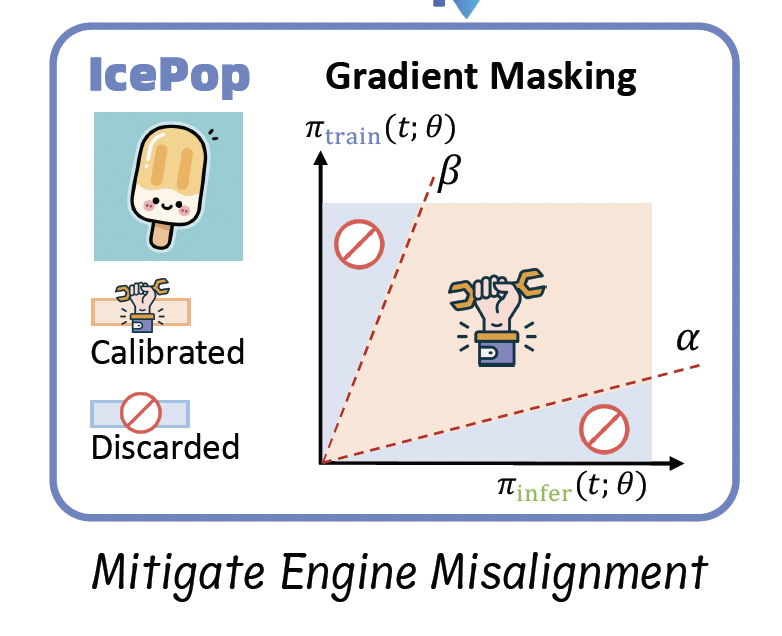
9.1 处理RL中训推的"不确定性"------蚂蚁百灵IcePop算法
核心问题: 模型在训练初期会尝试多种解法(高多样性),但一旦发现某条路径能获得奖励,便会"路径依赖",不断重复,导致生成的解法越来越单一,最终多样性丧失,模型"死机"
观察到的现象: 在训练后期,模型开始生成大量乱码,训练过程彻底崩溃
根本原因: 经过深入分析,发现崩溃的根源并非模型"学坏了",而是存在一个微妙但致命的"训推不一致"问题
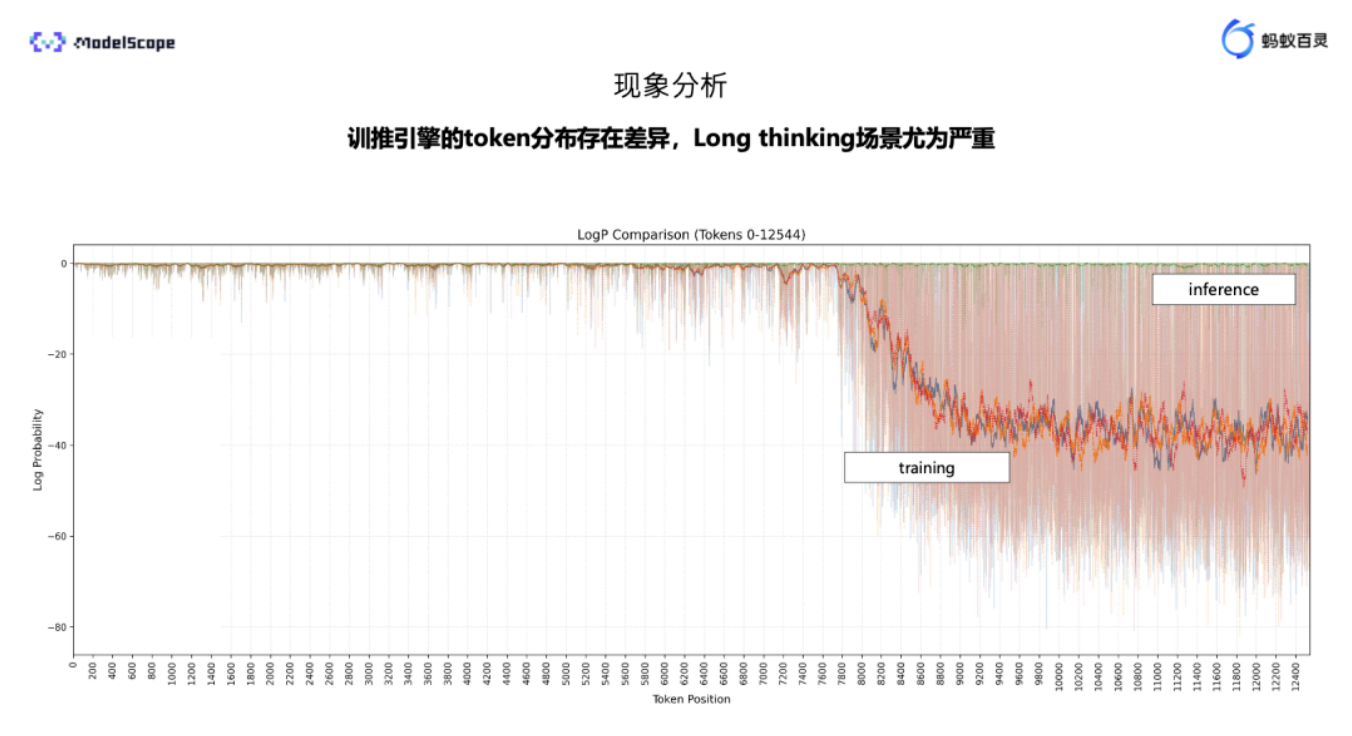
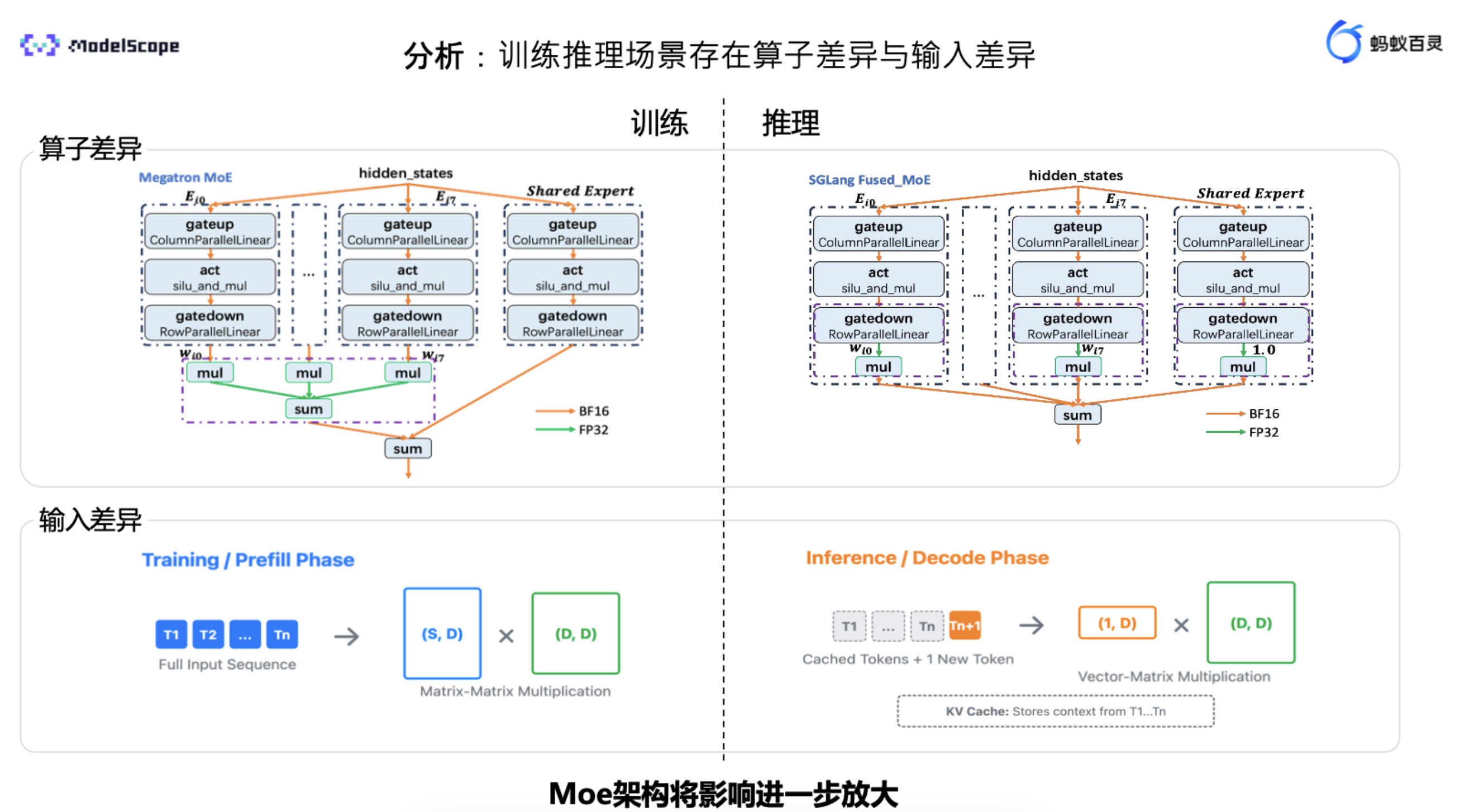
如上图所示,在长序列生成(Long thinking)场景下,模型在推理时对自身生成的 token 非常自信(对数概率较高),但当相同的序列被送回进行训练计算时,模型却认为这些 token 的概率极低(对数概率急剧下降,为负值)。这种矛盾导致了巨大的梯度波动,最终引发梯度爆炸和训练崩溃。更致命的是,对于采用MoE架构的万亿模型,路由决策对精度极其敏感。一个微小的计算误差,可能导致路由选择完全错误,而这一错误会在后续的每一层中被指数级放大,最终导致灾难性后果。
Icepop算法
核心思想是承认并控制差异,而非彻底消除差异,在GRPO的clip的基础上再引入了一个掩码函数
- 重要性采样: 通过比较训练策略 π t r a i n \pi_{train} πtrain 推理策略 π i n f e r \pi_{infer} πinfer 生成token的概率比,对梯度进行修正。
- 异常Token剔除: 引入一个掩码函数 M(⋅) ,根据训推比例的大小去动态识别那些因分布偏移导致的、重要性权重异常的Token,并将其反向梯度进行裁剪或屏蔽。其核心公式为:
J IcePop ( θ ) = E x ∼ D , { y i } i = 1 G ∼ π infer ( ⋅ ∣ x ; θ old ) 1 G ∑ i = 1 G 1 ∣ y i ∣ ∑ t = 1 ∣ y i ∣ \[ M ( π train ( y i , t ∣ x , y i , \< t ; θ old ) π infer ( y i , t ∣ x , y i , \< t ; θ old ) ; α , β ) ⋅ min ( r i , t A \^ i , t , clip ( r i , t , 1 − ε , 1 + ε ) A \^ i , t ) − γ D KL ( π θ ∥ π ref ) ] \mathcal{J}{\text{IcePop}}(\theta) = \mathbb{E}{x \sim \mathcal{D},\ \{y_i\}{i=1}^G \sim \pi{\text{infer}}(\cdot \mid x; \theta_{\text{old}})} \left \\frac{1}{G} \\sum_{i=1}\^G \\frac{1}{\|y_i\|} \\sum_{t=1}\^{\|y_i\|} \\left\[ \\mathcal{M}\\left( \\frac{\\pi_{\\text{train}}(y_{i,t} \\mid x, y_{i,\
其中:
- π infer \pi_{\text{infer}} πinfer:rollout的模型;
- π train \pi_{\text{train}} πtrain:训练的模型;
- r i , t = π train ( y i , t ∣ x , y i , < t ; θ ) π train ( y i , t ∣ x , y i , < t ; θ old ) r_{i,t} = \dfrac{\pi_{\text{train}}(y_{i,t} \mid x, y_{i,<t}; \theta)}{\pi_{\text{train}}(y_{i,t} \mid x, y_{i,<t}; \theta_{\text{old}})} ri,t=πtrain(yi,t∣x,yi,<t;θold)πtrain(yi,t∣x,yi,<t;θ) 是 token 级的重要性权重;
- A ^ i , t \hat{A}_{i,t} A^i,t 是优势估计;
- M ( k ) \mathcal{M}(k) M(k) 是掩码函数,定义如下:
M ( k ) = { k if k ∈ α , β , 0 otherwise \mathcal{M}(k) = \begin{cases} k & \text{if } k \in \\alpha, \\beta, \\ 0 & \text{otherwise} \end{cases} M(k)={k0if k∈α,β,otherwise
9.2 处理RL中DSA的"不确定性"------GLM 5
在GLM 5中,引入了DSA,DSA需要选top-k。DSA 引入了一个额外的Indexer,用于检索前 k 个最相关的 KV 条目,并对检索到的子集进行稀疏注意力计算。检索到的前 k 个结果对 RL 稳定性至关重要。这类似于 MoE 模型使用路由回放来保留激活的前 k 个专家,以确保训练与推理的一致性。然而,在每个 token 位置存储索引器的前 k 个索引显然是不切实际的,因为索引器使用的 k = 2048 远大于 MoE 中通常使用的 k 值,存储所有这些索引将带来巨大的存储开销,以及训练引擎与推理引擎之间显著的通信开销。
采用确定性 top-k 算子能有效解决这一问题,与 SGLang 的 DSA Indexer 中使用的基于 CUDA 的非确定性 top-k 实现相比,直接使用原生的 torch.topk 速度稍慢,但具有确定性。它能产生更一致的输出,并带来显著的 RL 增益。相比之下,其他非确定性 top-k 算子(如 CUDA 或 TileLang 实现)在 RL 仅几步后就导致性能急剧下降,并伴随熵值骤降。因此,在所有的 RL 阶段中,在训练引擎的 DSA Indexer 中默认使用 torch.topk 作为 top-k 算子,在 RL 过程中默认冻结索引器参数,从而加速训练并防止索引器出现不稳定的学习行为。
10 参考资料
- 蘑菇书《Easy RL》
- 智谱的《GLM-5技术报告:技术细节全公开》
- 蚂蚁的《演讲实录 | 万亿参数 RLVR 中的关键技术挑战》
- Tongyi DeepResearch系列论文
- Qwen的《Group Sequence Policy Optimization》