在过去几年中,大语言模型(LLM)的训练范式几乎是一成不变的:在海量的自然语言网络语料(Web-scale corpora)上进行下一个词预测(Next-token prediction)。Scaling Law(缩放定律)被视为不可挑战的真理,仿佛只要给模型喂入更多的人类文本、投入更多的算力,通用人工智能(AGI)就会自动涌现。然而,这种依赖于"大力出奇迹"的路径正面临空前严峻的挑战:
- 数据枯竭墙(The Data Wall):据多家研究机构(如 Epoch AI)预测,人类在互联网上产生的高质量文本即将在未来几年内被彻底耗尽。我们即将面临"无米之炊"的窘境。
- 人类偏见与噪声的继承:自然语言中充斥着人类偏见、逻辑谬误和低质量的冗余信息。模型在学习语言的同时,也全盘吸收了这些思维杂质。
- 知识与推理的深度纠缠(Knowledge-Reasoning Entanglement):当前的大模型往往只是通过海量统计记住了某些事实的"共现概率"(Knowledge),却并没有真正掌握推导这些事实的底层逻辑(Reasoning)。这导致模型极易产生幻觉,或者在遇到需要严密逻辑的数学和代码任务时,仅仅依赖于表面启发式模式(surface-level heuristics)来伪装出推理的假象,而非进行真正的系统性思考。
正如 Neural Cellular Automata 一文在摘要中提出的:Natural language pre-training has problems: high-quality text is finite, it contains human biases, and it entangles knowledge with reasoning. This raises a fundamental question: is natural language the only path to intelligence?
自然语言预训练存在诸多问题:高质量文本有限、包含人类偏见,且将知识与推理纠缠在一起。
这引发了一个根本问题:自然语言是通往智能的唯一路径吗?
近期出现了一种极具启发性的新范式:预先预训练(Pre-pre-training)。即在让模型接触任何自然语言语义之前,先用"非语言"的纯抽象合成数据对其进行"热身",以此在底层纯净的环境中构建起逻辑推理和计算能力。这里将对比两篇探讨这一方向的最新论文:
- Procedural Pretraining: Warming Up Language Models with Abstract Data(EPFL、阿德莱德大学等)
- Training Language Models via Neural Cellular Automata(MIT、Improbable AI Lab 等)
它们证明了"无字天书"可以教大模型做阅读理解,还向我们前所未有地揭示了神经网络内部知识迁移的奇妙机制。
预先预训练 (Pre-pre-training)?
无论是使用经典算法还是动态系统生成抽象数据,这两篇论文都采用了一个极其相似、且层次分明的三阶段训练架构:
- 预先预训练(Pre-pre-training):使用纯抽象、无语义的合成的强规则数据(如排序序列、括号匹配、元胞自动机演化轨迹)进行数十万步的早期训练。在这个阶段,模型完全不知道什么是"苹果"、什么是"重力",它的世界里只有纯粹的符号和抽象的转移规律。
- 标准预训练(Pre-training):将第一阶段训练好的模型权重(通常会重置词表嵌入层 Embedding)保留,接入真实的自然语言、代码或数学语料(如 C4, CodeParrot)上进行标准的自回归预训练,为其注入真实世界的知识。
- 微调(Fine-tuning):进行针对具体任务的指令微调,例如在逻辑测试集 GSM8K 或代码测试集 HumanEval 上进行强化。
我们可以用人类的认知发展规律来做一个生动的类比。发展心理学表明,婴儿在掌握复杂的语法和语义之前,会先通过物理世界中的基本互动(如堆叠积木、辨别形状)来建立空间、因果和逻辑概念。如果把大模型比作一个婴儿,传统的训练方法是直接把他扔进一个装满百科全书和网络论坛帖子的房间,期望他通过"疯狂阅读"自己顿悟出因果逻辑。这就好比让一个从未见过积木的孩子,直接通过阅读教材来学习盖房子。而"预先预训练"则是先让他玩积木、做拼图、推演简单的数独。正如 Procedural Pretraining 中所指出的:We study an alternative setting where the model is initially exposed to abstract structured data, as a means to ease the subsequent acquisition of rich semantic knowledge, much like humans learn simple logic and mathematics before higher reasoning.
当模型在无语义的积木游戏中掌握了"因果"、"包含"、"循环"和"映射"等底层算法原语后,再去读百科全书,它就能迅速理清长篇大论背后的逻辑骨架。
论文概要
程序化预训练(Procedural Pretraining)

使用经典算法数据,让大模型做思维训练,精准靶向提升特定算法技能。
第一篇论文探讨了使用程序化数据(Procedural Data)作为热身材料。这些数据由最基础的经典算法生成,没有任何人类语言的冗余。
例如:
- Dyck 序列:不同类型的多重嵌套括号(如
[ { ( ) } ])。 - Set(集合去重):输入一串带有重复元素的序列,目标输出是去重后的序列。
- Sort(排序):输入乱序数字,输出升序排列。
- Stack(栈操作):模拟压栈和弹栈的后进先出(LIFO)逻辑。
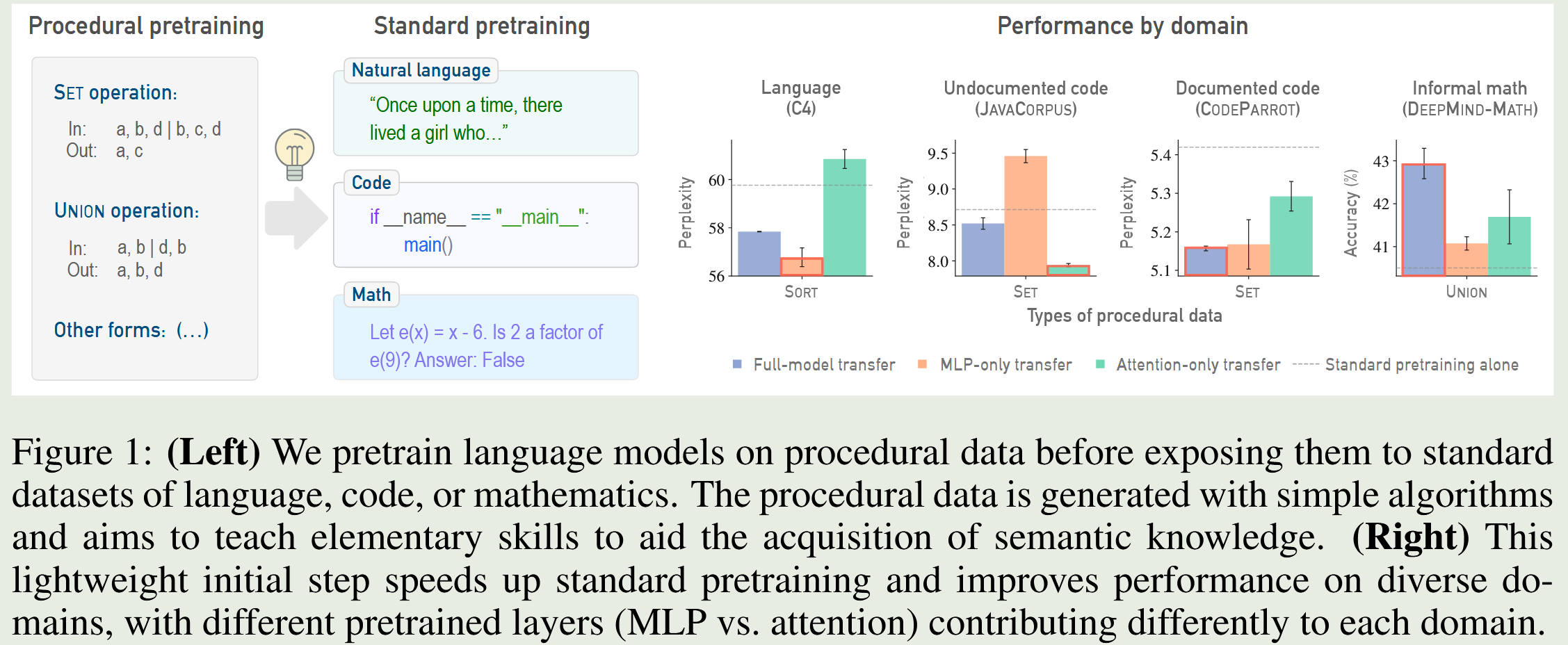
极高的数据杠杆率与暴涨的基准测试分数
研究人员发现,这种预训练不仅能提升模型在下游(语言、代码、数学)的表现,而且数据转化效率很高。最令人震撼的是它对长文本信息检索能力(即著名的"大海捞针"任务,Needle-in-a-haystack,简称 HAYSTACK)的提升。研究指出:For example, on context recall (NEEDLE-IN-A-HAYSTACK), the accuracy jumps from 10 to 98% when pretraining on Dyck sequences (balanced brackets). 在上下文召回"大海捞针"任务中,当在 Dyck 序列(平衡括号)上进行预训练时,准确率从 10% 暴涨到了 98%。
为什么看似无意义的"括号匹配"能解决复杂的"大海捞针"阅读理解?这是因为在处理嵌套括号时,模型必须学会两件事:
- 第一,跨越极长的距离记住左括号的状态;
- 第二,在匹配右括号时,必须无视中间各种局部信息的干扰。
这在计算本质上,与在大段废话(Haystack)中精准定位那一根针(Needle)所需的核心注意力路由(Attention routing)能力完全等价。
此外,在整体的语言预训练加速上,这篇论文得出了惊人的替代率数据:*We find that front-loading as little as 0.1% procedural data significantly outperforms standard pretraining... enables the models to reach the same loss value with only 55/67/86% of the original data.*仅前置加载 0.1% 的程序化数据,就能显著超越标准预训练......使模型分别只需使用原始数据量的 55% C4 自然语言、67% 代码 或 86% 数学,即可达到相同的损失值。这意味着,花极少量的算力让模型跑一点点程序化算法,就能直接为你省下将近一半的真实语料训练成本(计算量和数据收集成本双降)。这无疑是对真实自然语言语料的一种重要的反思。
组件级对口迁移,与反直觉的 MLP 跨域表现
大模型的核心架构由注意力层(Attention)和多层感知机(MLP)交替构成。
当把在抽象数据上"热身"过的权重迁移到真实任务时,研究人员发现了一个特殊的组件归纳偏置(Inductive biases in different components)现象,呈现出明确的"各司其职":
- 在纯代码领域(如 JAVACORPUS):代码是高度结构化且缺乏自然语言的,此时仅迁移注意力层(Attention-only transfer)收益最大。
- 在纯自然语言领域(如 WIKITEXT 和 C4):情况完全反转!仅迁移 MLP 层(MLP-only transfer)最为有效。
- 在混合领域(如包含注释的代码 CODEPARROT、非正式数学 DEEPMIND-MATH):全模型迁移(Full-model transfer)表现最好,因为它完美结合了"MLP 处理自然语言的优势"与"Attention 处理结构化数据的优势"。
为什么 MLP 在自然语言上的表现颠覆了学术界的认知?
传统大模型研究(如 Transformer feed-forward layers are key-value memories、Attention retrieves, mlp memorizes: Disentangling trainable components in the transformer、Filtering with self-attention and storing with mlp: One-layer transformers can provably acquire and extract knowledge等)普遍认为,MLP 是大模型用来存储"事实记忆"(Factual information)的知识库。
既然如此,在毫无事实概念的"抽象算法"上训练出的 MLP,为何能提升自然语言表现?
研究者通过 BLiMP(语言形态与句法基准,Blimp: The benchmark of linguistic minimal pairs for english)测试揭开了谜底:MLP 从抽象算法中学习到的不是"事实",而是极其强大的句法和形态能力(Syntactic and morphological competence)。这种精准的组件迁移将数据效率推向了极限:在 C4 数据集上,全模型迁移需要原始数据量的 55% 才能达到基线水平,而仅迁移 MLP 竟然只需要 42%!
神经元胞自动机预训练(NCA Pre-pre-training)

论文看点:用涌现的复杂动态系统数据,实现对自然语言的高阶统计学平替。
与第一篇使用人工硬编码(Hard-coded)的离散算法不同,第二篇论文的作者们使用了一种更具生命力、更具混沌特征的生成源,神经元胞自动机(Neural Cellular Automata, NCA)。
研究者构建了一个 12x12 的 2D 离散网格,状态空间为 10(即每个格子有 10 种可能的颜色或状态),并通过局部的多层神经网络规则(3x3 卷积核加 MLP)在网格上进行演化推演。这就像是一个被神经网络驱动的康威生命游戏(Conway's Game of Life)。
当把这种 2D 的时空演化轨迹按行扫描、展平为一维(1D)的 token 序列后,研究人员发现了一个决定性的特征:NCA 生成的数据展现出了与人类自然语言高度相似的长尾(Zipfian)分布 。
这意味着,虽然 NCA 序列满屏都是无意义的乱码,但在底层的统计学特征、信息熵的分布上,它和莎士比亚的十四行诗、维基百科的详尽条目有着极其相似的内在波动规律。

1.6亿抽象涌现数据,超越16亿真实文本
既然统计学特征相似,这种由局部规则涌现(Emergent)出的数据,能代替自然语言培养大模型的底层推理能力吗?实验结果极其震撼,甚至有些反直觉:
We find that pre-pre-training on only 164M NCA tokens improves downstream language modeling by up to 6% and accelerates convergence by up to 1.6x. Surprisingly, this even outperforms pre-pre-training on 1.6B tokens of natural language from Common Crawl with more compute.
仅在 1.64 亿 NCA 代币上进行预先预训练,就能将下游语言建模能力提升高达 6%,并使收敛速度加快高达 1.6 倍。
令人惊讶的是,这甚至优于使用 16 亿个来自 Common Crawl 的自然语言代币进行的、消耗更多算力的预先预训练。
并且,这种优势直接转化为了下游推理榜单的成绩提升:经过 NCA 预先预训练的模型,在数学题(GSM8K)、代码编写(HumanEval)和综合逻辑(BigBench-Lite)上的通过率均稳定超越了基线模型。
为什么 1.64 亿的无意义元胞轨迹,能打败十倍体积的真实人类网页文本?
论文作者深入剖析了这一点:在极其有限的早期训练规模(Early training regime)下,大模型如果看人类真实文本,往往只会把有限的参数容量浪费在记忆浅层的语法结构和高频词汇搭配上(比如记住"因为"后面要接"所以","is"后面接名词)。
但如果看 NCA 数据,情况完全不同。NCA 序列是由一个隐藏的神经网络规则生成的,由于没有任何外部语义(如常识、语境)可以依靠,大模型为了预测下一个 Token,被逼迫着必须在上下文中动态地推断出隐藏的演化规则。这种强制的"上下文潜规则推断(In-context rule inference)",极大地锻炼了模型的核心推理引擎,让它早早摆脱了"随机复读机(Stochastic Parrot)"的命运。
寻找复杂度的门当户对
NCA 论文揭示了另一个对行业具有极高指导价值的规律------抽象数据并非越复杂越好,也并非越简单越好。下游真实任务的类型,决定了你该用多复杂的抽象数据来"热身"。为了量化复杂度,研究人员巧妙地使用了序列的 Gzip 压缩率。压缩率越高,说明数据越混乱、不可预测(复杂度高);压缩率越低,说明数据越有规律、冗余度高(复杂度低)。
论文得出结论:Optimal NCA complexity varies by domain: code benefits from simpler dynamics, while math and web text favor more complex ones. 最佳的 NCA 复杂度因领域而异:代码得益于较简单的动态特性,而数学和网页文本则偏好更复杂的特性。
- 代码(Code)领域:代码具有极其严谨的抽象语法树(AST),容错率极低,整体信息熵较低(真实的 CodeParrot 数据集 Gzip 压缩率约为 32%)。因此,使用中低复杂度(Gzip压缩率 30-40%)的 NCA 数据为其"热身"效果最好。
- 网页文本与数学(Web text & Math)领域:人类自然语言包含隐喻、多重指代和跳跃性思维,而数学包含极其复杂的抽象组合与假设,两者的内在随机性和信息熵极高(真实文本的 Gzip 压缩率往往在 60%-70% 之间)。因此,必须使用高复杂度(Gzip压缩率 50%+)的 NCA 数据来进行匹配预训练,才能让模型适应这种错综复杂的信息流。
这种将复杂动态系统转化为"连续调节数据复杂度的旋钮"的能力,为未来根据垂直领域精准定制大模型提供了一种新颖的方案。
共性与分歧中的奇妙火花
将这两篇同期的顶尖研究放在一起审视,我们不仅能看到大模型底层训练机制的清晰图景,更能看到二者在探索前沿时的碰撞。
共性(Commonalities)
- 破除自然语言迷信:两者共同且强有力地证明了,缺乏人类语义内涵的纯抽象数据,不仅能教会模型规则,更能为其注入极其强大的上下文学习(In-context Learning)能力和推理先验。大模型真正通往智能的钥匙,源于其内部对动态规律的压缩能力,而不在于它背诵了多少人类的维基百科。
- 极高的训练数据杠杆率:不管是仅仅 0.1% 的经典程序数据,还是 1.6 亿 token 的 NCA 轨迹,都证明了:提纯后的、密度极高的"逻辑提炼",比充满人类废话的海量自然水文要高效得多。这对于算力、数据双重受限的 AI 研究无疑是一种利好。
- 注意力机制的通用王者地位:两篇论文一致认同并用实验证明了,注意力机制(Attention layers)是承载上下文学习、长期依赖和规则推断等通用计算原语的绝对核心。NCA 论文明确总结道:The attention layers capture the most useful computational primitives, accounting for the majority of the transfer gains. 注意力机制捕获了最具可迁移性的原语,在迁移收益中占据主导地位。这侧面印证了 Anthropic 等机构提出的"归纳头(Induction heads)"理论,只要是具备复杂隐式规则的序列,就能在早期迅速催生出注意力网络中负责复制、匹配和推理的通用子电路。
差异(Differences)
- 数据生成路线:
- Procedural Pretraining:经典且离散。通过规则完全确定的经典算法(如排序、去重、栈操作)生成,逻辑指向性明确,人类可解释性极强。
- Neural Cellular Automata:参数化且动态连续。通过局部神经网络演化生成,具有自然界的混沌与分形特征(涌现复杂性 Emergent complexity),人类难以直观阅读其内在规则。
- 对控制域的理解:
- Procedural Pretraining:离散的分类控制。认为不同的经典算法可以像RPG游戏里的"技能点"一样,针对性强化大模型不同的下游特长(例如用 Dyck 练长距匹配,用排序练逻辑顺序)。
- Neural Cellular Automata:连续的统计学控制。利用字母表大小(Alphabet size)和 Gzip 压缩率作为连续旋钮,系统调节数据整体的混乱度,追求与目标领域的"宏观复杂度对齐"。
- 目标域的适配性:
- Procedural Pretraining:组件级解耦与混合。揭示了不同模态对组件的特定依赖:代码靠 Attention,纯自然语言靠 MLP,混合领域靠全模型迁移。
- Neural Cellular Automata:全局复杂度匹配。并未在组件级做过多拆分组合,而是主张数据宏观统计学(Gzip压缩率)上的门当户对。下游领域越复杂,越需要高 Gzip 复杂度的抽象数据;下游规则越严谨,越需要中低复杂度数据。这是一种偏向宏观信息论视角的迁移。
- MLP 层的角色:
- Procedural Pretraining:抽象语法提取器。发现 MLP 并没有死板地记忆事实,而是内化了抽象算法的结构,转化为极其强大的自然语言"句法和形态能力"。
- Neural Cellular Automata:产生负迁移的领域干扰源。认为 MLP 容易过度记忆合成数据的特定规则,在迁移时不匹配会产生严重副作用。
第一篇论文在经典的 1D(一维)离散算法特征中,发现 MLP 对 1D 的自然语言具有极高的泛化和迁移能力。
而第二篇基于参数化的 NCA 动态系统,其数据本质上是 2D 空间(12x12 网格)演化被强行展平为 1D 序列,因此它的 MLP 层可能在预先预训练阶段深度过拟合了这种独特的 2D 空间转移规则。
当模型后续被用来阅读真实的 1D 线性自然语言文本时,这部分被"空间逻辑污染"的 MLP 权重反而产生了强烈的排异反应。
这一现象为未来的机械可解释性研究(Mechanistic Interpretability)和跨模态迁移学习留下了探索空间。
什么才是更好的训练方案
这两篇前沿论文带来的启示是极具启发性的。
它们不仅为解决数据墙(Data Wall)问题提供了一条切实可行的退路,更重要的是,它们为大模型演进指出了一条更特别的范式:不必只让大模型来死记硬背进行填鸭式教育,而可以先锻炼其思维逻辑强化规则学习。
这对时下火热的小语言模型(SLM, Small Language Models)的发展也具有重要意义。当前要想让小模型变聪明,通常需要用大模型生成成千上万的高质量语料进行"知识蒸馏"。但如果换个思路,在仅拥有 1B 甚至 500M 参数的微型模型中,先用合成的抽象算法数据极致地压榨出它的逻辑推理潜力,然后再用极少量但最高质量、人工精标的专业语料为其注入业务知识。完全有可能在端侧训练出体积极小、但推理极其严密、且幻觉极低的掌上专家。
正如 Procedural Pretraining 的总结:This ultimately suggests the promise of disentangling knowledge acquisition from reasoning in LLMs. 这最终暗示了在大型语言模型中将知识获取与推理能力彻底解耦的广阔前景。用干净、低成本、可无限生成、可精准调控的合成抽象数据构建模型的"逻辑骨架",再用高质量的人类语料为其注入"事实血肉"。
这种分离"推理(Reasoning)"与"知识(Knowledge)"的探索,为未来构造推理能力更强、体量更灵巧、训练更高效的模型提供了一种新的方案。