什么是远程监督?怎么自动生成训练数据?
🚀 本文收录于Github:AI-From-Zero 项目 ------ 一个从零开始系统学习 AI 的知识库。如果觉得有帮助,欢迎 ⭐ Star 支持!
by @Laizhuocheng
一、简介
想象一下,你要训练一个 AI 来识别"谁创立了哪家公司"。传统方法是找一群人,逐句阅读成千上万的新闻,手动标注"乔布斯创立了苹果公司"这样的句子。这不仅费时费力,成本也高得惊人。
有没有办法让机器自己找到这些训练样本呢?
远程监督(Distant Supervision)就是解决这个问题的利器。它的核心思想很简单:如果我们已经知道"乔布斯是苹果公司的创始人",那么所有同时提到"乔布斯"和"苹果公司"的句子,很可能都在描述这种创始人关系。
这就像你听说某个朋友结婚了,后来在任何场合看到他和配偶同时出现,你都会默认他们是夫妻关系------虽然偶尔也可能是"前妻"或"商业伙伴",但大多数情况下这个假设是成立的。
二、什么是远程监督
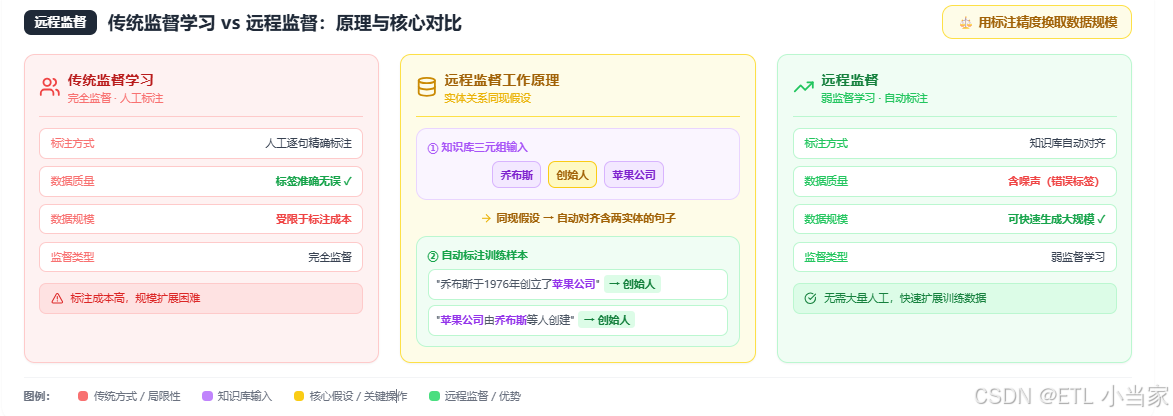
远程监督是一种利用已有知识库自动生成标注数据的方法,主要用于关系抽取任务。
核心假设
远程监督的理论基础是实体关系的同现假设:如果知识库中存在两个实体的某种关系,那么包含这两个实体的句子很可能表达了这种关系。
举个具体例子:
- 知识库中有三元组:(乔布斯, 创始人, 苹果公司)
- 远程监督会自动将所有同时包含"乔布斯"和"苹果公司"的句子标注为"创始人"关系的训练样本
与传统监督学习的区别
| 特点 | 传统监督学习 | 远程监督 |
|---|---|---|
| 标注方式 | 人工逐句精确标注 | 基于知识库自动对齐 |
| 数据质量 | 标签准确无误 | 存在噪声(错误标签) |
| 数据规模 | 受限于标注成本 | 可快速生成大规模数据 |
| 监督类型 | 完全监督 | 弱监督学习的一种 |
远程监督本质上是用标注精度换取数据规模,适合需要大量训练数据但标注资源有限的场景。
三、远程监督如何工作
3.1 自动生成训练数据的三步骤
整个自动标注流程可以分为三个关键环节:
第一步:从知识库提取三元组
从 Freebase、Wikidata 或企业内部知识图谱中获取结构化数据,格式为 (实体1, 关系类型, 实体2)。
第二步:实体对齐与句子检索
在大规模文本语料库中检索同时包含这两个实体的句子。这里有个技术细节:实体匹配不是简单的字符串匹配,需要处理别名和指代消解------"Jobs"和"乔布斯"其实是同一个人。
第三步:自动标签分配
将检索到的所有句子都打上对应的关系标签,这些句子和标签的组合就构成了训练样本。

3.2 具体示例
假设知识库里有 (iPhone, 制造商, 苹果公司) 这条记录,系统会在新闻语料库中找到:
- "苹果公司发布了新款 iPhone"
- "iPhone 是苹果公司的旗舰产品"
- "分析师认为 iPhone 将帮助苹果公司提升市场份额"
然后统统标注为"制造商"关系的正样本。瞬间就能生成几百上千个训练样本!
3.3 代码示例
下面是一个简化的远程监督标注器实现:
python
class DistantSupervisionLabeler:
def __init__(self, knowledge_base, corpus):
self.kb = knowledge_base # {(实体1, 实体2): 关系类型}
self.corpus = corpus # 文本语料列表
self.entity_aliases = {
"微软": ["Microsoft", "微软", "MSFT", "微软公司"],
"领英": ["LinkedIn", "领英", "Linkedin"]
}
def generate_training_data(self):
training_samples = []
for (entity1, entity2), relation in self.kb.items():
# 检索包含两个实体的句子
candidate_sentences = self._find_sentences(entity1, entity2)
for sentence in candidate_sentences:
sample = {
'text': sentence,
'entity1': entity1,
'entity2': entity2,
'relation': relation,
'confidence': self._calculate_confidence(sentence, entity1, entity2)
}
training_samples.append(sample)
return training_samples
def _find_sentences(self, entity1, entity2):
matched = []
for sentence in self.corpus:
if self._contains_entity(sentence, entity1) and \
self._contains_entity(sentence, entity2):
matched.append(sentence)
return matched
def _contains_entity(self, text, entity):
# 检查实体的所有别名是否出现在文本中
for alias in self.entity_aliases.get(entity, [entity]):
if alias.lower() in text.lower():
return True
return False3.4 噪声问题与降噪方法
远程监督最大的挑战是噪声。同现假设并不总是成立:
- "乔布斯在 1985 年被苹果公司解雇" ------ 同时包含两个实体,但表达的不是创始人关系
- "很多人把雷军称为中国的乔布斯" ------ 只是类比,没有描述乔布斯和苹果公司的关系
噪声的两个特征:
- 假阳性:把不表达目标关系的句子错误标注成正样本
- 标签不完整:知识库本身不完备,导致一些真正表达关系的句子无法被识别
主要降噪方法:
| 方法 | 原理 |
|---|---|
| 多实例学习 | 把同一实体对的所有句子看作一个"包",只要包里至少有一个句子表达目标关系,整个包就是正样本 |
| 注意力机制 | 让模型自动学习哪些句子更可靠,给高置信度句子更高权重 |
| 启发式过滤 | 用规则筛掉明显错误的样本(如出现"离开"、"解雇"等负面词) |
四、远程监督的优缺点
| 优势 | 劣势 |
|---|---|
| 快速生成大规模训练数据 ------ 无需人工逐句标注,大幅降低标注成本 | 数据存在噪声 ------ 自动标注的标签不完全准确,影响模型训练 |
| 利用已有知识资产 ------ 充分发挥知识库的价值,实现知识到数据的转化 | 依赖知识库质量 ------ 知识库覆盖不全或错误会直接传导到训练数据 |
| 可扩展性强 ------ 知识库更新后,可快速重新生成训练数据 | 实体对齐复杂 ------ 需要处理别名、指代消解、实体消歧等问题 |
| 启动成本低 ------ 适合冷启动场景,快速验证想法 | 类别不平衡 ------ 知识库中某些关系的三元组远多于其他关系 |
五、远程监督的实际应用与发展趋势
5.1 实际应用场景
1. 知识库补全
从非结构化文本中抽取新的实体关系,补充和扩展已有知识库。例如从新闻中自动发现"某公司收购了某公司"的新事实,添加到企业知识图谱中。
2. 关系抽取模型训练
为金融、医疗、法律等垂直领域的关系抽取任务快速生成训练数据。比如在医疗领域,利用 UMLS 医学知识图谱自动生成"疾病-药物"关系的训练样本。
3. 搜索引擎优化
通过抽取网页中的实体关系,构建更丰富的语义索引,提升搜索结果的相关性。例如识别"iPhone"和"苹果公司"的关系,帮助理解用户搜索意图。
5.2 局限性与改进方向
当前局限:
- 噪声问题难以完全消除
- 对知识库质量和覆盖度高度依赖
- 实体对齐和消歧仍是技术难点
优化方案:
- 结合预训练语言模型:BERT 等模型本身具有噪声鲁棒性,用远程监督数据微调效果较好
- 提示学习(Prompt Learning):设计提示模板,让大模型直接做关系抽取,减少标注依赖
- 多源知识融合:结合多个知识库,提高覆盖率和准确性
5.3 未来发展趋势
远程监督代表的是一种工程哲学------在资源受限的情况下,如何用自动化手段撬动已有的知识资产。
未来发展方向包括:
- 与主动学习结合:先用远程监督快速启动,再用主动学习精准标注高价值样本
- 联合建模:让实体识别和关系抽取互相增强,减少错误传导
- 跨语言扩展:利用多语言知识库,生成多语言训练数据
六、总结与思考
远程监督是弱监督学习的经典范式,它用同现假设这把钥匙,打开了知识库与文本数据之间的通道,让机器能够自动将结构化知识转化为训练数据。
它的价值不仅在于降低标注成本,更在于提供了一种快速启动的范式------当你面对一个全新的关系抽取任务,没有现成标注数据时,远程监督能让你在一周内训练出可用的模型,而不是等待数月的人工标注。
思考:远程监督的本质是"用精度换规模"。在实际项目中,关键不是消除所有噪声,而是找到"可接受的噪声水平"------当标注成本降低 90%,而模型性能只下降 5% 时,这笔交易往往是值得的。毕竟,完美的数据是不存在的,能解决问题的模型才是好模型。