GitHub链接:http://animatedai.github.io
在识别手写数字的时候不是使用几个全连接层就可以了,为什么在识别猫猫狗狗的时候就要使用到卷积层?卷积有什么作用?
核心作用:在保留与全连接层相同的特征提取功能的前提下,还能够避免参数量爆炸
核心矛盾:参数量爆炸
手写数字(MNIST)用全连接可行
输入:28×28 = 784像素 隐藏层1:256神经元 隐藏层2:128神经元 输出:10类(数字0-9) 总参数量:784×256 + 256×128 + 128×10 ≈ 20万 ✓ 完全可控猫猫狗狗用全连接?
输入:224×224×3 = 150,528像素(是MNIST的192倍!) 如果照搬MNIST架构: 输入层 → 4096 → 4096 → 1000类 参数量 = 150,528×4096 + 4096×4096 + 4096×1000 ≈ 6.3亿 + 1600万 + 400万 ≈ **6.5亿参数**! 问题: ❌ 内存爆炸:仅存储就需要2.6GB(float32) ❌ 计算量巨大:推理一次需要数十亿次乘法 ❌ 严重过拟合:参数比训练图片还多 ❌ 丢失空间信息:由于是全连接,所以就会把224*224*3的图片展平成150528*1的长向量,像素被打乱,不知道"眼睛在脸的上部"
卷积层的三大核心特点
特点1:局部连接(Sparse Connectivity)
全连接层:每个输出连接所有输入 784输入 → 每个神经元需要784个权重 卷积层:每个输出只连接局部区域 3×3卷积核 → 每个神经元只需要9个权重!优势:参数数量与图像尺寸无关,只与卷积核大小有关
特点2:权重共享(Parameter Sharing)
同一个卷积核滑动扫描整张图片: 输入图像:224×224 ↓ 用同一个3×3卷积核(9个参数) 在(0,0)位置检测边缘 在(0,1)位置检测边缘 在(0,2)位置检测边缘 ...遍历所有位置 无论检测哪里,都用同一组权重!对比:
方式 检测100个位置的边缘需要参数 全连接 100 × 9 = 900参数 卷积(权重共享) 9参数 ✓ 本质:平移等变性------猫在图片左上角或右下角,都用同样的"猫眼检测器"
作用3:保留空间结构
全连接层的灾难:打平输入 224×224×3 → 展平为150,528维向量 [红,红,红,红,红,红...] 完全丢失"哪个像素在哪" 原来眼睛在鼻子上方 → 变成第3829和第10584维 网络根本不知道它们的空间关系! 卷积层:保持2D结构 224×224×3 → 卷积 → 224×224×64 每个特征图还是二维的!眼睛的位置信息保留
直观对比:全连接 vs 卷积
特性 全连接层 卷积层 连接方式 全局连接 局部连接(感受野) 参数数量 随输入尺寸爆炸 与输入尺寸无关 空间信息 完全丢失 完整保留 平移不变性 无 天然具备 特征检测 每个位置重新学习 一次学习,到处应用 适合数据 表格数据、特征向量 图像、视频、音频
卷积在猫猫狗狗识别中的具体作用
层级特征学习
第1层(32个3×3卷积核): 检测边缘、颜色、简单纹理 "这是一片橙色"、"这里有条竖线" 第3层(128个卷积核): 组合低级特征 → 检测纹理、形状 "这有条纹"、"这是圆形" 第5层(256个卷积核): 组合中级特征 → 检测部件 "这是猫耳朵"、"这是狗鼻子" 第7层(512个卷积核): 组合高级特征 → 检测对象 "这是猫的脸"、"这是狗的躯干" 全连接层(最后): 综合所有特征 → 分类 "有尖耳朵+胡须+小鼻子 = 猫"可视化:卷积核学到什么
第1层卷积核(直接可视化): ┌───┬───┬───┐ │-1 │ 0 │+1 │ ← 垂直边缘检测器 ├───┼───┼───┤ │-1 │ 0 │+1 │ ├───┼───┼───┤ │-1 │ 0 │+1 │ └───┴───┴───┘ 第3层卷积核(可视化为偏好): → 对"条纹"模式响应强烈 → 对"圆形斑点"响应强烈 第5层卷积核: → 看到特定部位激活(如猫眼检测器)
一句话总结
全连接层把图像当"一串数字"处理,卷积层把图像当"一幅画"处理------保留空间结构、共享局部特征、大幅减少参数。
任务 为什么可行 手写数字 28×28=784维,全连接20万参数可控,且数字结构简单(笔画位置相对固定) 猫猫狗狗 224×224=5万像素,全连接6亿参数爆炸;且猫姿态多变,需要平移不变的特征检测
卷积核的常见维度:
维度 名称 使用场景 2维 2D Kernel 单通道图像处理(如灰度图)、传统图像滤波 3维 3D Kernel 标准CNN(RGB图像、多通道特征图) 4维+ 3D Conv、视频处理 医学3D图像、视频时序
可视化理解卷积过程:
b站:eve的科学频道 搜索"卷积"相关视频
理解:
- 卷积解决的核心痛点是避免使用全连接层提取特征而导致的参数爆炸问题,在能够提取特征图的情况下,还能大幅度减少参数的需求量
2.卷积核也叫做滤波器,也叫做特征提取器,卷积的过程就是一个提取特征的过程,每一个卷积核上面的参数决定了这个卷积核的功能(具体能够提取出来什么特征,如垂直纹理,横线纹理),每一个卷积核对输入做一次卷积就会得到一张特征图
如这张图,输入是6*6*8,卷积层由8个卷积核组成,每一个卷积核都是3*3*8,红色卷积核对原始图像做一次卷积得到红色的2维特征图
所以:
卷积核的通道数一定等于输入的通道数
卷积核的个数是自由的
卷积层的输出的通道数等于卷积层中卷积核的个数
3.一个卷积层其实就是由很多很多个卷积核的集合。第一层卷积层的输入就是原始RGB图像,输出就是每一个卷积核对原始图像卷积后得到的特征图的集合,有多少个卷积核,就有多少个特征图。卷积层的输入就是特征图的集合。



卷积的相关概念
1. Padding(填充)
定义:在输入数据的边缘补充额外的像素(通常是0)
作用:
问题 解决方案 卷积后特征图(卷积后的输出的某一个单层)尺寸缩小 保持空间维度不变 边缘信息丢失 让边缘像素被充分计算 常见模式:
Padding一般在pytorch或者tensorflow中都可以直接选择一下三种模式(开关)
Valid:不填充,输出尺寸减小
Same:填充使输出尺寸与输入相同
Full:充分填充,输出尺寸增大
示例:3×3卷积核,Same填充时四周各加1圈0
2. Stride(步长)
定义:卷积核每次移动的像素距离
影响:
Stride = 1:精细扫描,保留更多细节
Stride = 2:下采样,输出尺寸减半,计算量减少
输出尺寸公式: Output=⌊StrideInput−Kernel+2×Padding⌋+1
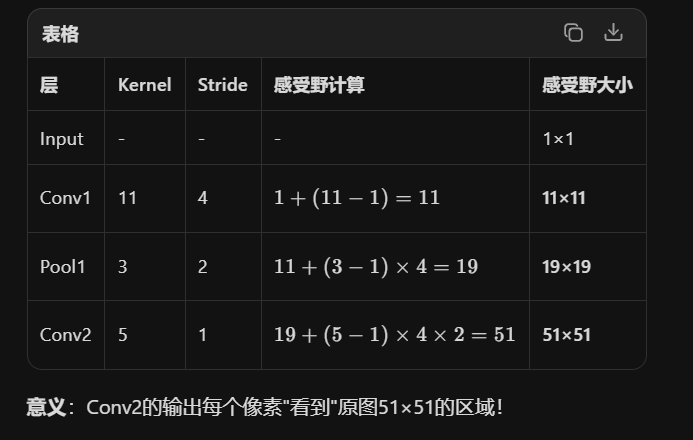
3. Receptive Field(感受野)
定义 :输出特征图中一个像素对应原始输入图像的区域大小
关键特性:
越深层的网络,感受野越大
大感受野能捕捉全局上下文信息
小感受野专注于局部细节
感受野的迭代公式:
4. 分辨率
定义:特征图的尺寸(例如128*128,256*256)
5. 编码器
编码器(Encoder)= 将输入数据压缩/转换成低维、有意义的特征表示(向量)的网络模块

卷积核的尺寸:
核心原因:奇数尺寸的优势
1. 存在中心点(Central Pixel)
3×3 卷积核 2×2 卷积核(无中心) ┌───┬───┬───┐ ┌───┬───┐ │ a │ b │ c │ │ a │ b │ ├───┼───┼───┤ ├───┼───┤ │ d │ e │ f │ ← e是中心 │ c │ d │ ← 没有明确中心 ├───┼───┼───┤ └───┴───┘ │ g │ h │ i │ └───┴───┴───┘中心点的重要性:
可以对应输入的特定位置 ,实现对称填充(Same Padding)
便于确定卷积核的锚点位置,特征图定位更精确
2×2卷积核无法对称填充,会导致特征偏移
没有论文主动承认过偶数尺寸卷积核的尺寸,所以我们大家都不认为他是好的,自然也就不会去使用他了
2. 参数效率与感受野的平衡
用多个小卷积核替代大卷积核
方案 参数量 感受野 非线性次数 一个 5×5 25 5×5 1次 两个 3×3 叠加 9+9=18 5×5 2次 三个 3×3 叠加 27 7×7 3次 VGG网络的核心发现:两层3×3 = 一层5×5的感受野,三层3×3 = 一层7×7。的感受野但参数更少、非线性更强!所以我们基本都只用3*3的卷积核,因为本来就能够等效替代5*5,并且参数更少,那就没有理由拒绝了。
3. 1×1 卷积核的特殊作用
虽然看似奇怪,但1×1极其重要:
输入: 32通道 × H × W ↓ 1×1 卷积(输出16通道) 输出: 16通道 × H × W ← 空间尺寸不变!功能:
降维/升维:如果某一层全都是1*1的卷积核,padding=0,stride=1,那么输出的尺寸就等于输入的尺寸,然而,卷积核的数量又等于输出的通道数。所以可以控制卷积核的数量来改变通道数,进行升维或者降维,以减少计算量
跨通道信息融合 :降维其实就是在做一个跨通道信息融合,比如把32通道,压缩融合成16个通道特征。
32个输入通道可以看作32种"特征描述" ↓ 1×1卷积学习:哪些特征组合更重要? ↓ 16个输出通道 = 16种新的"混合特征" 例如: - 输入通道1-10:各种边缘方向 - 输入通道11-20:各种纹理模式 - 输入通道21-32:颜色信息 1×1卷积可能学到: 输出通道1 = 0.5×(边缘) + 0.3×(纹理) + 0.2×(颜色) = "带颜色的边缘纹理" 输出通道2 = 0.1×(边缘) + 0.8×(纹理) + 0.1×(颜色) = "纯纹理特征" ...
4. 为什么不用更大的(7×7, 9×9)?
问题 说明 参数量爆炸 7×7 = 49参数,是3×3的5.4倍 计算成本高 大卷积核在GPU上效率低 过拟合风险 参数多,需要更多数据 已可被堆叠替代 三个3×3 = 7×7感受野,但更好 例外情况:
第一层有时用7×7(如ResNet、AlexNet),因为原始图像信息丰富
但现代网络(ResNet-50+)连第一层也倾向于用多个3×3堆叠
5. 现代网络的演进趋势
LeNet (1998) → 5×5 混合 AlexNet (2012) → 11×11, 5×5, 3×3 混用 VGG (2014) → 统一 3×3 堆叠 ⭐ ResNet (2015) → 3×3 + 1×1 瓶颈 MobileNet → 3×3 深度可分离卷积 EfficientNet → 5×5 深度可分离(偶尔用)趋势:小卷积核(3×3)+ 网络加深,取代大卷积核
总结
尺寸 存在理由 典型场景 1×1 通道变换,不降维 瓶颈层、特征融合 3×3 效率最优的基本单元 几乎所有卷积层 5×5 早期网络或特定需求 较少见,可被3×3替代 偶数尺寸 ❌ 基本不用 定位偏移问题 黄金法则:用多个3×3堆叠,而不是单个大卷积核!

卷积核上面的数字是什么:
1. 数字的本质:可学习的权重
输入图像区域 卷积核权重 输出特征 ┌───┬───┬───┐ ┌───┬───┬───┐ │ 1 │ 2 │ 3 │ │w₁ │w₂ │w₃ │ 3 │ 4 │ 5 │ 6 │ ⊛ │w₄ │w₅ │w₆ │ = 单个数值(特征响应) │ 7 │ 8 │ 9 │ │w₇ │w₈ │w₉ │ └───┴───┴───┘ └───┴───┴───┘ 计算:1×w₁ + 2×w₂ + 3×w₃ + 4×w₄ + 5×w₅ + 6×w₆ + 7×w₇ + 8×w₈ + 9×w₉这些权重不是人工设计的,而是通过反向传播自动学习得到的!
2. 数字代表什么?------ 特征检测模板
训练完成后,不同的数字组合会形成特定的特征检测器:
权重模式 检测的特征 直观理解 水平边缘权重 水平线/边缘 上负下正或反之 垂直边缘权重 垂直线/边缘 左负右正或反之 对角线权重 45°或135°边缘 对角分布的强弱对比 中心强四周弱 斑点/中心特征 类似高斯分布 棋盘状权重 纹理/高频细节 正负交替
3. 可视化:真实的卷积核权重
浅层卷积核(第1层,直接看像素)
学习到的边缘检测器示例: 垂直边缘检测 水平边缘检测 45°边缘检测 ┌────┬────┬────┐ ┌────┬────┬────┐ ┌────┬────┬────┐ │-0.5│ 0 │+0.5│ │-0.3│-0.3│-0.3│ │+0.4│ 0 │-0.4│ ├────┼────┼────┤ ├────┼────┼────┤ ├────┼────┼────┤ │-0.8│ 0 │+0.8│ │ 0 │ 0 │ 0 │ │ 0 │ 0 │ 0 │ ├────┼────┼────┤ ├────┼────┼────┤ ├────┼────┼────┤ │-0.5│ 0 │+0.5│ │+0.3│+0.3│+0.3│ │-0.4│ 0 │+0.4│ └────┴────┴────┘ └────┴────┴────┘ └────┴────┴────┘ 左暗右亮 上暗下亮 对角变化深层卷积核(抽象特征)
越深层的权重越难直接解释,它们检测的是低级特征的组合:
第1层:边缘、颜色 → 第3层:纹理、角点 → 第5层:眼睛、轮胎 → 第7层:人脸、汽车
一般常见网络有多少多少卷积层,每层多少卷积核?
1. 典型网络的卷积核数量
网络 各层卷积核数量 总卷积层数 特点 LeNet-5 (1998) 6 → 16 2层 奠基之作,数量少 AlexNet (2012) 96 → 256 → 384 → 384 → 256 5层 引爆深度学习 VGG-16 (2014) 64→64→128→128→256→256→256→512×6 13层 统一用3×3,深度突破 ResNet-50 (2015) 64→64→128→256→512 ( Bottleneck结构) 53层 残差连接,可极深 MobileNet (2017) 32→64→128→256→512→1024 28层 轻量化,通道可分离 EfficientNet-B0 (2019) 32→16→24→40→80→112→192→320→1280 23层 复合缩放,效率最优 趋势:从浅层少通道 → 深层多通道,但每层具体数量差异很大
2. 卷积核数量的决定因素
因素1:输入复杂度(Input Complexity)
简单任务(MNIST手写数字): 输入:28×28 灰度图 第1层:6-32个卷积核足够 复杂任务(ImageNet 1000类): 输入:224×224 RGB图 第1层:64个卷积核起步 深层:512-2048个卷积核原则:任务越复杂、类别越多,需要学习的特征越丰富 → 更多卷积核
因素2:网络深度(Depth)
浅层(第1-3层):检测边缘、纹理、颜色 → 通道数少(32-64),因为基础特征种类有限 中层(第4-8层):检测部件、形状、模式 → 通道数中等(128-512) 深层(第9层+):检测对象、语义概念 → 通道数多(512-2048),组合可能性爆炸增长为什么 深层需要更多通道**?**
深层每个位置对应原始图像更大区域(感受野大)
需要编码的组合特征数量指数增长