博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈
python语言、flask框架、Echarts可视化、Prophet时间序列预测算法、逻辑回归算法、requests爬虫、汽车之家二手车
功能模块
- 数据采集模块
- 可视化分析模块
- 智能分析模块
- 系统管理模块
- 数据可视化分析大屏
- 数据中心
- 汽车口碑分析
- 汽车推荐
- 各品牌销量预测
- 后台管理
- 注册登录
项目介绍
本项目是基于python开发的二手车数据分析可视化系统,以汽车之家二手车数据为核心,搭建了完整的数据分析体系。系统通过爬虫完成原始数据的批量采集,依托Echarts实现多维度数据可视化呈现,结合Prophet时间序列预测算法实现品牌销量趋势预测,通过逻辑回归算法完成个性化汽车推荐,同时配套完善的后台管理与权限管控功能,打通数据采集、分析、预测、管理全流程,为二手车行业的市场分析、购车决策与经营策略制定提供全方位的数据支撑。
2、项目界面
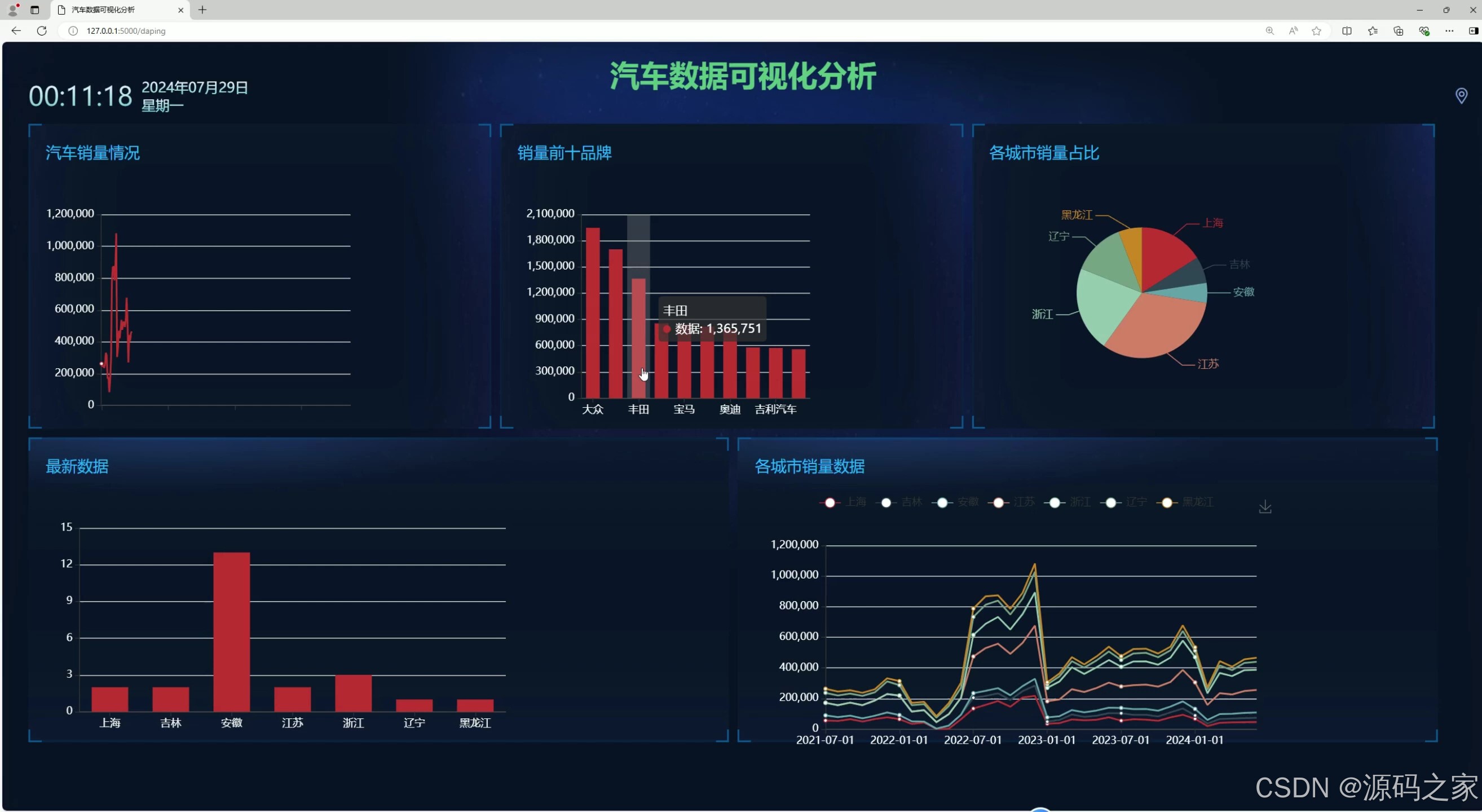
(1)数据可视化分析大屏
该页面为汽车数据可视化分析大屏,包含汽车销量情况折线图、销量前十品牌柱状图、各城市销量占比饼图、最新数据柱状图以及各城市销量数据趋势折线图,可直观展示汽车销量相关的多维度数据信息。
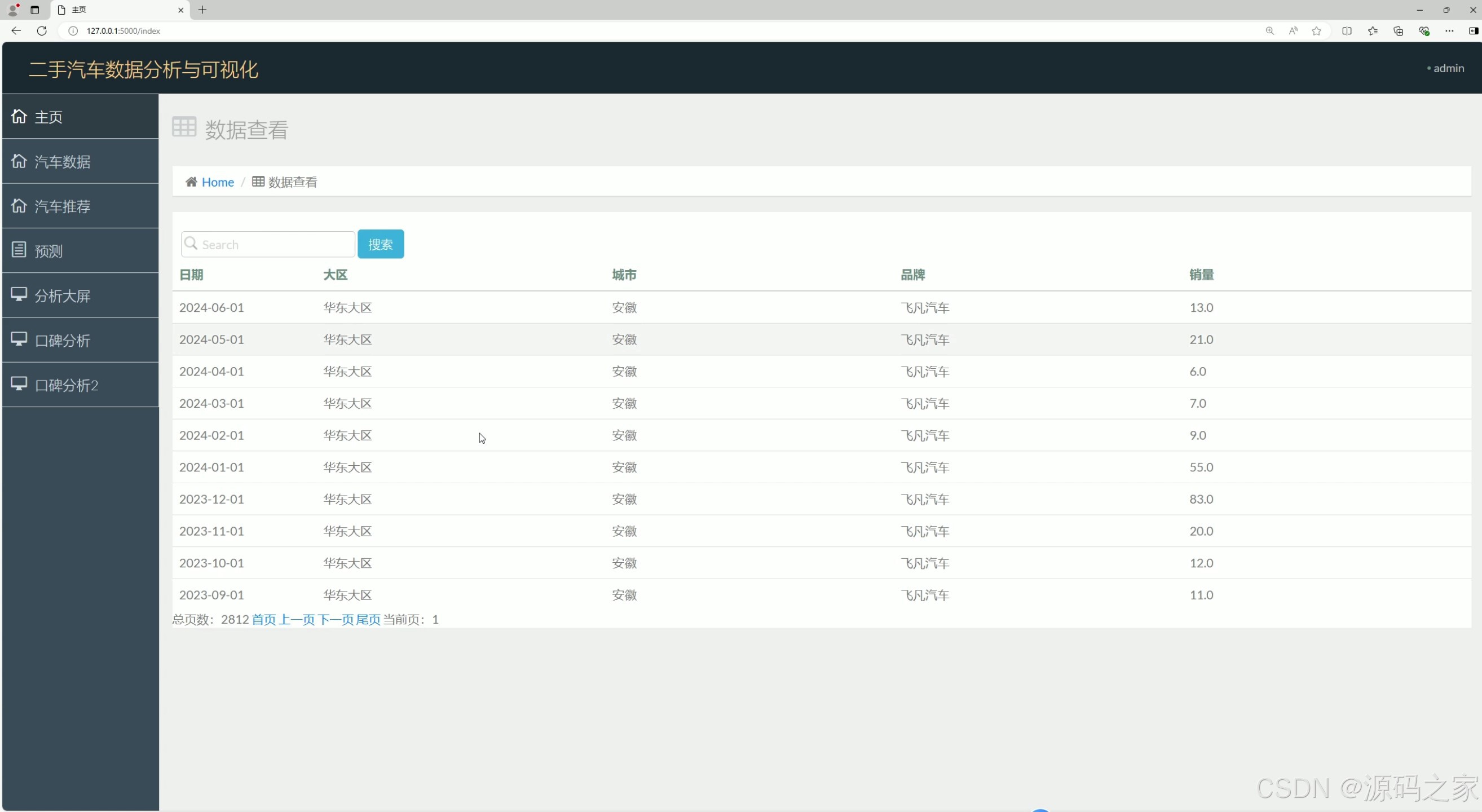
(2)数据中心
该页面是二手汽车数据分析与可视化系统的数据查看页面,左侧设有主页、汽车数据、汽车推荐、预测、分析大屏、口碑分析等功能导航栏,右侧以表格形式展示汽车相关数据,支持搜索查询,可分页浏览数据信息。
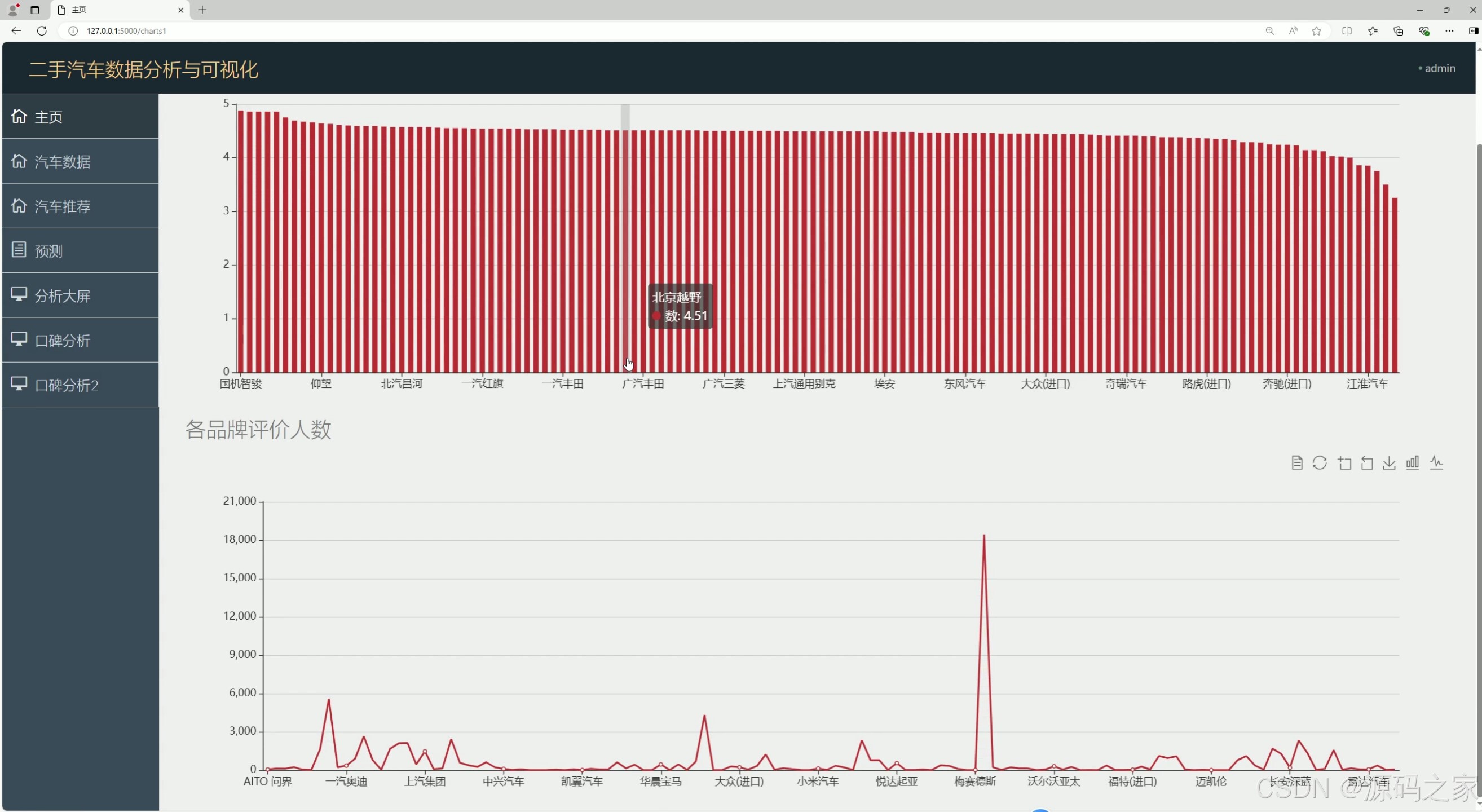
(3)汽车口碑分析1----评分、评价人数
该页面是二手汽车数据分析与可视化系统的图表分析页面,左侧设有主页、汽车数据、汽车推荐等功能导航栏,页面上方展示各汽车品牌相关评分柱状图,下方呈现各品牌评价人数折线图,可直观呈现不同汽车品牌的口碑相关数据情况。
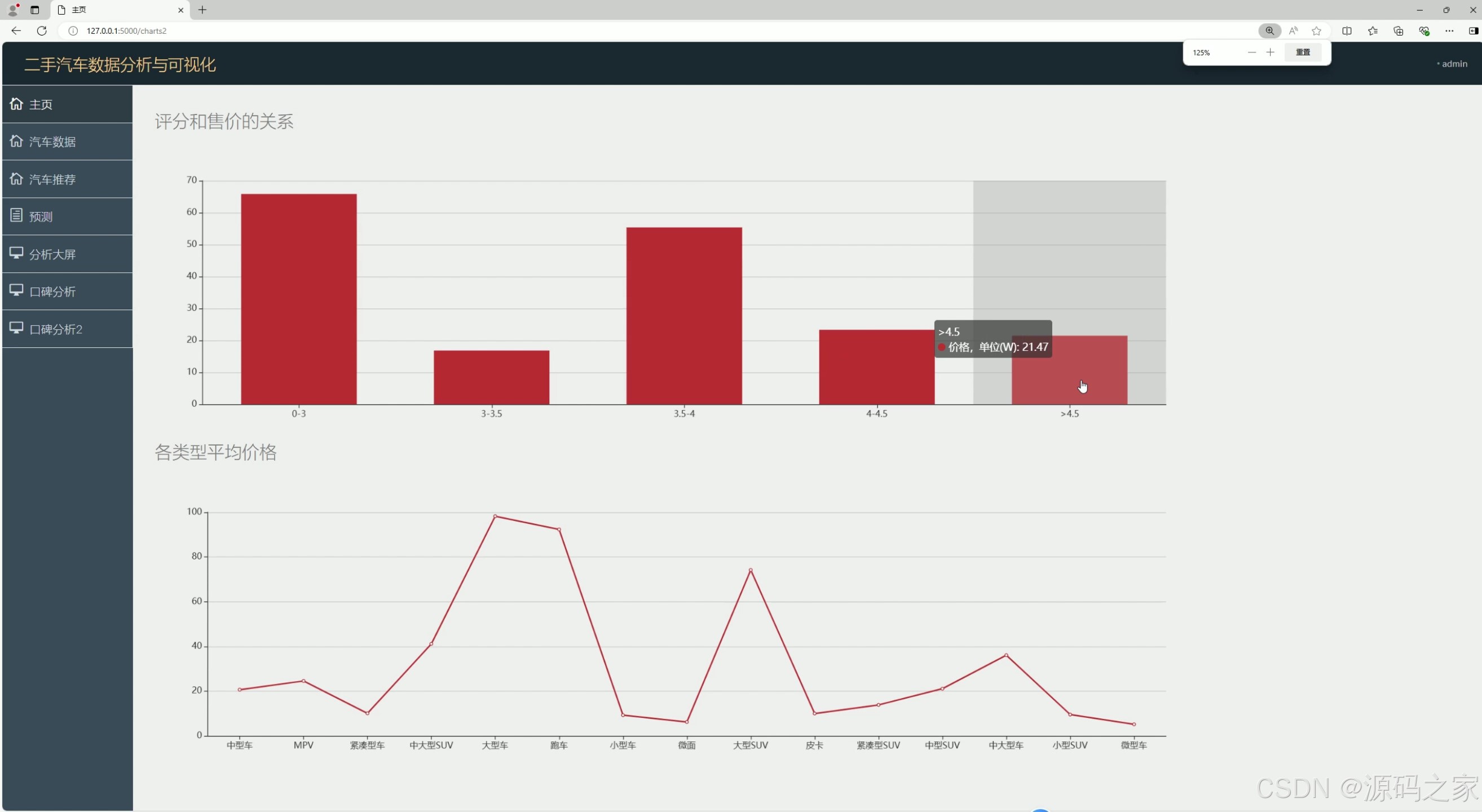
(4)汽车口碑分析2----评分与售价关系、各类型均价分析
该页面是二手汽车数据分析与可视化系统的图表分析页面,左侧设有主页、汽车数据、汽车推荐等功能导航栏,页面上方展示评分和售价关系的柱状图,下方呈现各类型汽车平均价格的折线图,可直观呈现汽车评分、售价与车型相关的数据分析结果。
(5)汽车推荐
该页面是二手汽车数据分析与可视化系统的汽车数据页面,左侧设有主页、汽车数据、汽车推荐等功能导航栏,右侧以表格形式展示各汽车品牌、子品牌、价格、评分、类型、评价人数等详细信息,支持分页浏览数据。
(6)各品牌销量预测
该页面是二手汽车数据分析与可视化系统的汽车品牌销量预测页面,左侧设有主页、汽车数据、汽车推荐等功能导航栏,页面上方提供各汽车品牌的切换入口,下方以表格形式展示对应品牌不同日期的销量预测数据,支持分页浏览。
(7)后台管理
该页面是二手汽车数据分析与可视化系统的后台管理系统中的汽车口碑管理页面,左侧设有数据管理、汽车数据管理、汽车口碑管理、用户管理、权限管理等导航栏,右侧以表格形式展示各汽车口碑内容、热度及关联车辆信息,支持编辑、删除、创建、分页浏览等操作。
(8)注册登录
该页面是二手汽车数据分析与可视化系统的登录页面,以暖棕色渐变背景呈现,中间设有登录账号和密码的输入框,搭配绿色登录按钮,还提供点击切换功能,用于用户身份验证,验证通过后可进入系统后台。
(9)数据采集
该页面是PyCharm开发环境中的Python爬虫代码编辑界面,代码通过requests库发送网络请求,结合BeautifulSoup解析网页内容,按地区、品牌维度循环爬取汽车相关数据,将结果写入csv文件,控制台同步输出爬取日志,用于采集二手汽车数据分析所需的原始数据。
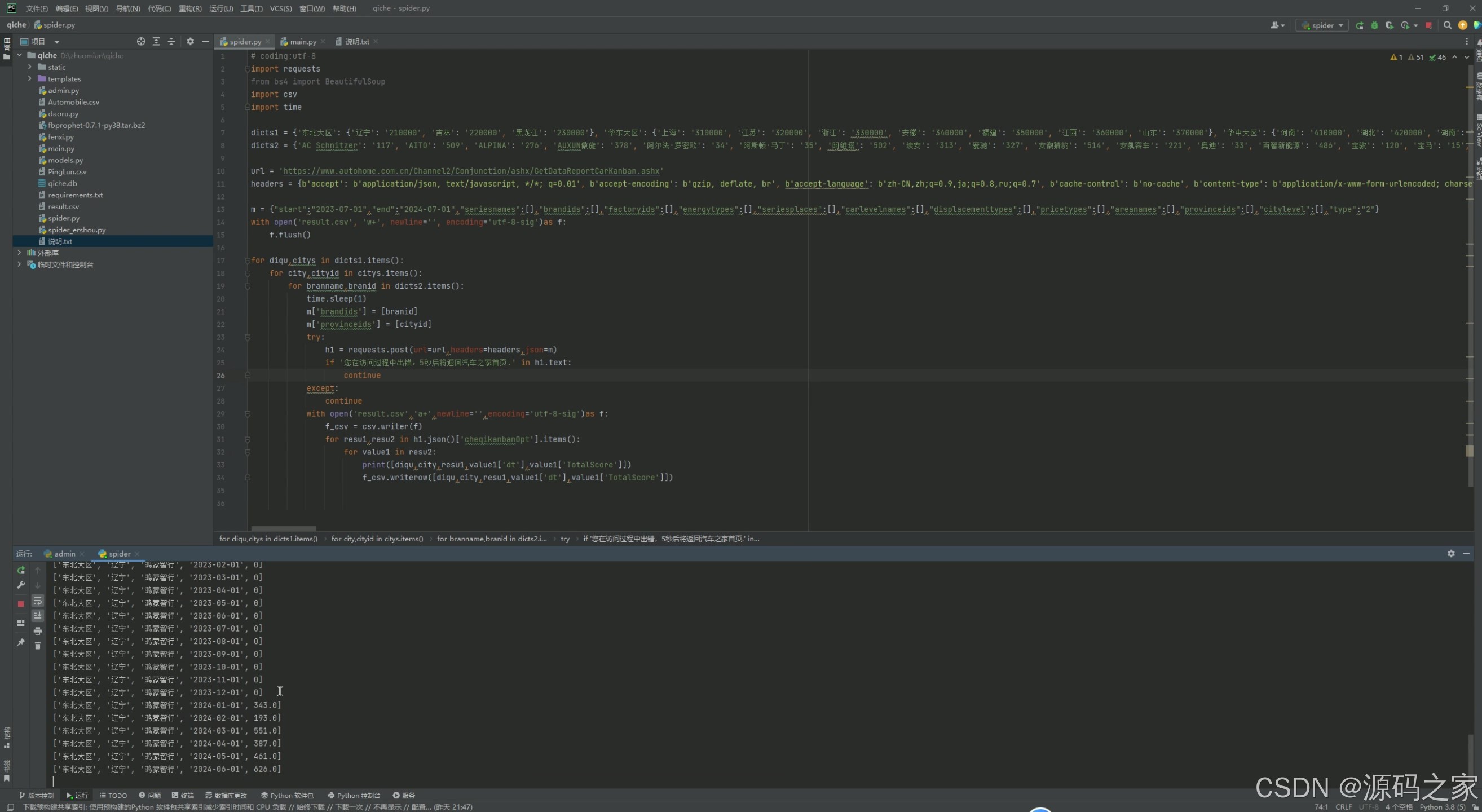
3、项目说明
一、技术栈简要说明
本项目采用Python作为核心开发语言,搭配Flask框架搭建后端服务与系统架构,通过Echarts实现数据可视化呈现,运用Prophet时间序列预测算法完成品牌销量预测,借助逻辑回归算法实现汽车个性化推荐,依托requests爬虫技术抓取汽车之家二手车相关数据,各技术协同配合,构建完整的二手车数据分析可视化体系。
二、功能模块详细介绍
- 数据采集模块:基于requests库开发爬虫脚本,定向抓取汽车之家二手车平台的全维度数据,涵盖品牌、子品牌、价格、评分、销量、评价人数、口碑内容等信息,按地区、品牌维度循环爬取,结合解析工具处理网页内容,将采集到的原始数据写入csv文件,控制台同步输出爬取日志,确保数据批量获取的准确性和完整性,为后续分析工作奠定坚实的数据基础。
- 可视化分析模块:借助Echarts工具实现多维度数据可视化展示,包含数据可视化分析大屏、汽车口碑分析两大核心部分。其中,数据可视化分析大屏整合汽车销量情况折线图、销量前十品牌柱状图、各城市销量占比饼图等,全景呈现销量相关数据;汽车口碑分析分为两部分,分别展示各品牌评分、评价人数,以及评分与售价关系、各类型汽车平均价格,直观呈现车型口碑特征与价格关联。
- 智能分析模块:融合两种核心算法,一是Prophet时间序列预测算法,构建各汽车品牌销量预测模型,可切换不同品牌,输出对应品牌未来不同日期的销量预测数据,支持分页浏览;二是逻辑回归算法,支撑汽车推荐模块,结合车型价格、评分、类型等特征,为用户提供个性化汽车推荐,呈现详细的车型信息。
- 系统管理模块:包含注册登录与后台管理两大功能。注册登录页面采用暖棕色渐变背景,设置账号、密码输入框及登录按钮,支持切换功能,实现用户身份验证,保障系统访问安全;后台管理聚焦汽车口碑管理,左侧设有完善的导航栏,右侧以表格形式展示口碑内容、热度及关联车辆信息,支持口碑数据的创建、编辑、删除及分页浏览,同时管控用户权限、清洗异常数据,确保系统稳定运行。
- 数据中心:作为系统的数据汇总页面,左侧设有主页、汽车数据、汽车推荐等功能导航栏,右侧以表格形式展示全量二手车数据,包含品牌、子品牌、价格、评分、类型、评价人数等详细信息,支持搜索查询和分页浏览,方便用户快速获取所需数据。
三、项目总结
本项目是一款功能完善、实用性强的二手车数据分析可视化系统,以汽车之家二手车数据为核心,打通"数据采集-可视化分析-智能预测-系统管理"的全流程。通过多种技术协同,实现了二手车数据的批量采集、多维度可视化呈现、精准销量预测及个性化推荐,同时配套完善的后台管理与权限管控功能,解决了二手车市场分析、购车决策及经营策略制定中数据杂乱、分析不便的问题。整体系统操作便捷、数据直观,可为二手车行业从业者、购车用户提供全方位的数据支撑,具有较强的实际应用价值和推广意义。
4、核心代码
python
import re
import time
import traceback
import requests
from bs4 import BeautifulSoup
import models
from sqlalchemy import and_
session = requests.session()
url = 'https://k.autohome.com.cn/'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36",
"Referer": "https://k.autohome.com.cn/"
}
session.get(url=url,headers=headers,verify=False)
dicts_item = {
'小型SUV': 'https://k.autohome.com.cn/suva01/',
'紧凑型SUV': 'https://k.autohome.com.cn/suva1/',
'中型SUV': 'https://k.autohome.com.cn/suvb1/',
'中大型SUV': 'https://k.autohome.com.cn/suvc1/',
'大型SUV': 'https://k.autohome.com.cn/suvd1/',
'微型车': 'https://k.autohome.com.cn/a001/',
'小型车': 'https://k.autohome.com.cn/a01/',
'紧凑型车': 'https://k.autohome.com.cn/a1/',
'中型车': 'https://k.autohome.com.cn/b1/',
'中大型车': 'https://k.autohome.com.cn/c1/',
'大型车': 'https://k.autohome.com.cn/d1/',
'MPV': 'https://k.autohome.com.cn/mpv1/',
'跑车': 'https://k.autohome.com.cn/s1/',
'皮卡': 'https://k.autohome.com.cn/p1/',
'微面': 'https://k.autohome.com.cn/mb1/'}
for _key,_url in dicts_item.items():
time.sleep(3)
headers = {
}
print(_url)
h1 = session.get(url=_url + '#pvareaid=2099126',headers=headers,verify=False)
print(h1.request.url)
if h1.request.url == 'https://k.autohome.com.cn':
print(1111)
h1 = session.get(url=_url, headers=headers, verify=False)
soup = BeautifulSoup(h1.text,'html.parser')
lis = soup.select('ul.list-cont > li')
# print(lis)
for li in lis:
time.sleep(1)
try:
img_url = li.select('img')[0].attrs.get('src')
title = li.select('a.font-14-b')[0].text.strip()
fenshu = li.select('span.red')[0].text.strip()
renshu = li.select('a')[-1].text.strip()
lianjie = li.select('a.font-14-b')[0].attrs.get('href')
if not str(lianjie).startswith('http'):
lianjie = 'https://k.autohome.com.cn' + lianjie + '#pvareaid=102519'
print(img_url,title,fenshu,renshu,lianjie)
print(lianjie)
h2 = session.get(url=lianjie, headers=headers, verify=False)
soup2 = BeautifulSoup(h2.text, 'html.parser')
# print(soup2)
subnav_name = soup2.select('div.header_toolbar__car__name__5SxJb a')[0].text
brand = subnav_name.split('-')[0]
Sub_brand = subnav_name.split('-')[1:]
if len(Sub_brand) == 1:
Sub_brand = Sub_brand[0]
else:
Sub_brand = '-'.join(Sub_brand)
price = re.findall('seriesMinPrice":{"title":"(.*?)万',h2.text)[0]
pingjias = soup2.select('ul.score_tag__Wq2Z4 > li')
if not models.Automobile.query.filter(models.Automobile.url==lianjie).all():
models.db.session.add(
models.Automobile(
title=title,
brand=brand,
Sub_brand=Sub_brand,
price=price,
pingfen=fenshu,
renshu=renshu,
img_url=img_url,
url=lianjie,
type=_key
)
)
models.db.session.commit()
for pingjia in pingjias:
print(pingjia)
try:
text1 = pingjia.select("div")[0].text.strip()
renshu2 = re.findall('(\d+)',text1)
if renshu2:
renshu2 = renshu2[0]
else:
renshu2 = '0'
content = text1.replace(renshu2,'')
datas1 = models.Automobile.query.filter(models.Automobile.url==lianjie).all()[0]
print(content,renshu2)
if not models.PingLun.query.filter(
and_(models.PingLun.automobile_id == datas1.id, models.PingLun.content == content)).all():
print('插入数据',content,renshu2)
models.db.session.add(
models.PingLun(
content=content,
renshu = renshu2,
automobile_id = datas1.id
)
)
models.db.session.commit()
except:
print(traceback.format_exc())
continue
except:
print(traceback.format_exc())
continue