original transformer
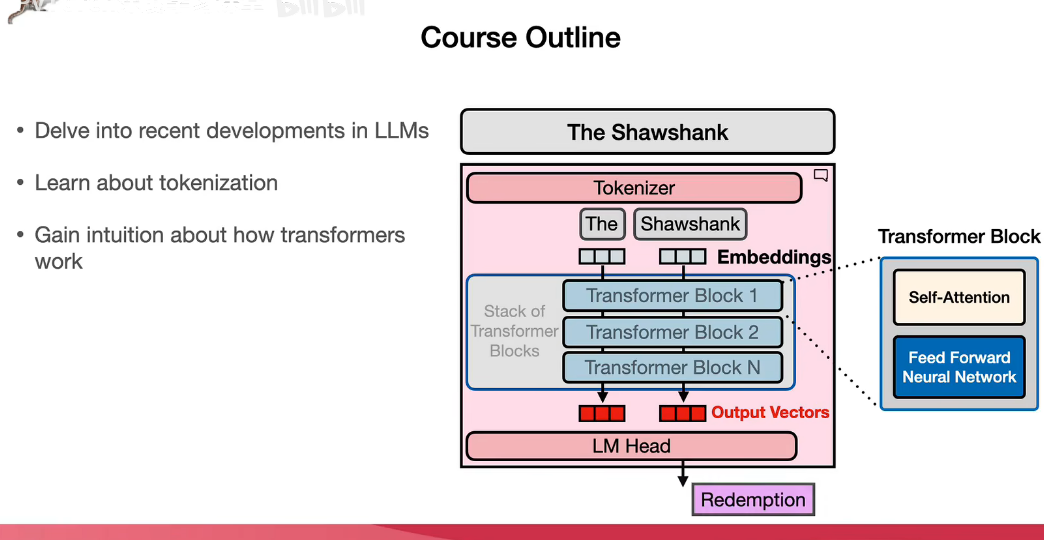
模型首先将每个输入标记映射为表征语义的嵌入向量,随后,讲这些向量输入多层transformer块进行处理,每个块都是专为高效数据学习设计的神经网络架构,并具备良好的jpu扩展性。每个transformer块由注意力层和前馈网络组成, 模型将transformer块的输出向量,,传递给最终组件,语言模型头,由其生成输出标记。
LLM的魅力来自两个要素:transformer架构本身,模型训练所使用的海量优质数据
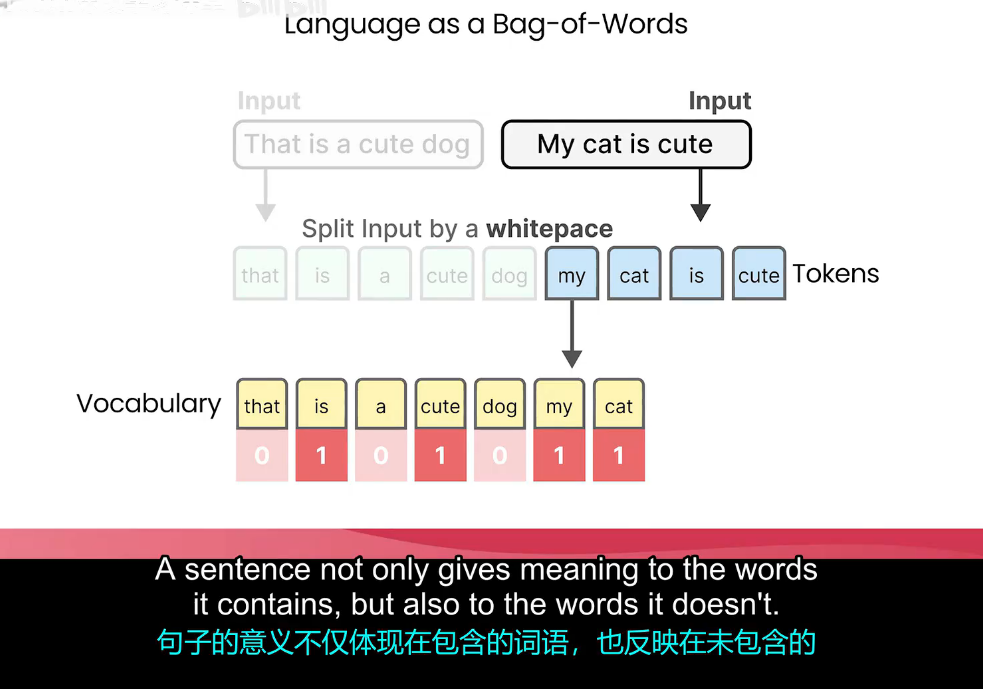
1. 词袋模型
**引言:**词袋是最基础的文本表示方法,理解它才能明白,为啥要用更复杂的模型,transformer解决了啥问题,选学习词袋的"笨",才能体会到transformer的"聪明"; transformer的注意力机制,可以看做是"智能版词袋",不是简单计数,而是根据重要性加权
原始文本 → 分词(Tokenization) → 词元(Token) → 词汇表(Vocabulary)
↓
词元ID(数值化)
↓
词嵌入(Token Embedding)
↓
输入 Transformer
1. 分词:把句子拆成最小单元(词元 Token)
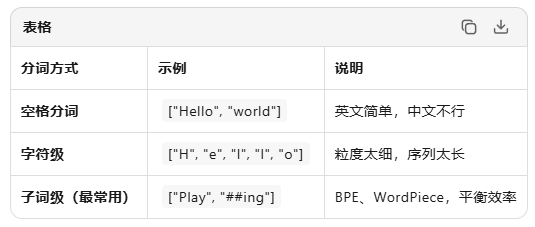
# 示例
"Playing basketball" → ["Play", "##ing", "basket", "##ball"]2. 词元 :分词后的每个小单元就是token

3.词汇表:所有可能出现的token的集合
4. 数值化表示: 把token映射成整数 ID
词汇表:
"Play" → 1024
"##ing" → 2056
"basket" → 3421
"##ball" → 1890
"[CLS]" → 101
"[SEP]" → 102
"Playing basketball" → [101, 1024, 2056, 3421, 1890, 102]这里就是模型实际接受的输入:一串整数
5. 词袋模型 vs transformer 表示
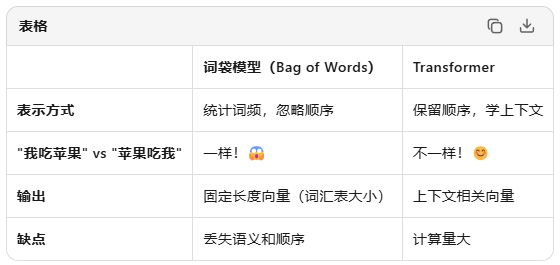
词袋示例:
"猫 喜欢 鱼" → 1, 1, 1, 0, 0... # 每个维度代表一个词是否出现
transformer示例
"猫 喜欢 鱼" → 每个词根据上下文有不同的向量表示
"猫"在"猫吃鱼"和"猫喜欢鱼"中含义不同
6. 词嵌入
把token ID变成稠密向量
Token ID: 1024
↓
Embedding 层(查表)
↓
向量: 0.2, -0.5, 1.1, ..., 0.8 # 768维或更多
- 维度:BETR-base 是768维
- 这些向量是课学习的,训练时候不断更新
注意:为啥表是不固定的?
初始状态(随机或预训练):
"苹果" → 0.1, -0.3, 0.5, ... ← 随机初始化的向量
训练过程中:
看到 "苹果" 在 "吃苹果" 中
看到 "苹果" 在 "苹果手机" 中模型学习调整:
"苹果"(水果)→ 0.8, 0.2, -0.1, ...
"苹果"(公司)→ 0.1, 0.9, 0.3, ... ← 根据上下文不同!
最终:同一个词在不同句子中有不同表示
具体怎么更新?
# 伪代码
embedding_table = 随机初始化 # 形状:[词汇表大小, 768]
for 每个训练样本:
token_id = [101, 1024, 2056] # "Play", "##ing"
# 查表获取向量
vectors = embedding_table[token_id] # 取出对应行
# 前向传播 → 计算损失 → 反向传播
loss = 模型输出 vs 真实标签的差距
# 关键:更新 embedding_table!
embedding_table[token_id] -= 学习率 * 梯度embedding_table 就是神经网络的参数,和权重 W、b 一样会被梯度下降更新!
Token → ID 是固定的映射,但 ID → 向量是可学习的参数,训练时会不断优化,让语义相似的词拥有相似的向量表示。
2. word2Vec此项两点的生成原理
Word2Vec → 突破!学会"语义"
核心思想: "物以类聚,词以群分"
经常一起出现的词,语义相近
训练任务: 预测"相邻词"(Skip-gram或CBOW)
"猫 ___ 鱼" → 预测中间是"吃"
每次预测错误 → 反向传播 → 调整嵌入向量
让"猫"和"狗"的向量靠近
让"猫"和"苹果"的向量远离
- 嵌入向量可以学习(不是固定)
- 向量维度捕捉语义特征
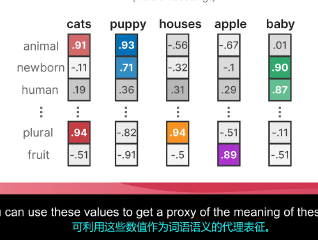
图3解释:
cats = 0.91(animal高), -0.11(newborn低), 0.19(human低), 0.94(plural高)
↑ 这些就是语义维度!每个数字代表该特征的强度
baby = 0.01(animal低), 0.90(newborn高), 0.87(human高), -0.11(plural低)

从"数词频"到"学语义":Word2Vec用神经网络让相似词拥有相似向量,解决了词袋的语义缺失;Transformer在此基础上,用Attention让同一个词在不同上下文中拥有不同向量,解决了多义词和全局依赖问题。
3.利用注意力机制实现上下文的编码和解码(非静态)
word2wec生成的是静态嵌入表示,无论上下文如何变化,单词bank都会生成相同的嵌入。
RNN编码器-解码器架构(基础版)
输入: "I love llamas" (英文)
↓
编码器(RNN): 把整句话压缩成一个"上下文向量"
↓
解码器(RNN): 从这个向量逐词生成 "Ik hou van lama's" (荷兰语)
word2vec是静态的 bank永远是一个向量 rnn编码器是动态的 但是编码器最后只输出一个固定向量承载全部信息,长句子会记不住前面的内容 信息瓶颈
自回归生成(Autoregressive)
这是解码器生成文本的方式:
Step 1: 输入 I, love, llamas → 预测第1个词 "Ik"
Step 2: 输入 I, love, llamas, Ik → 预测第2个词 "hou"
Step 3: 输入 I, love, llamas, Ik, hou → 预测第3个词 "van"
Step 4: 输入 I, love, llamas, Ik, hou, van → 预测第4个词 "lama's"
自回归=自己回归自己,每生成一个词,就把生成的词佳慧输入,继续生成下一个。
attention机制(突破版本)
输入: "I love llamas"
↓
编码器(RNN): 生成每个词的表示(不再压缩成一个向量!)
↓
Attention解码器: 生成"Ik"时 → 重点关注"I"
生成"hou"时 → 重点关注"love"
生成"van"时 → 重点关注"llamas"
attention解决了什么问题》?
- rnn:所有的信息在一个向量里卖弄,长句子会议网
- attention:解码器每步都可以回头看编码器的所有词,选择性关注重要的词
4.注意力机制在transformer模型的具体使用
1.transformer 核心架构
彻底理解"摒弃传统神经网络"
传统的RNN的问题:
RNN: 一个个词顺序处理,像排队过安检,后面的词要等前面的
"我 喜欢 猫" → 处理"猫"时,"我"的信息已经传了3步,可能丢失
Transformer: 所有词同时处理,像所有人同时过安检,互相都能看到
"我 喜欢 猫" → 3个词同时进入,直接计算谁和谁相关
关键创新 :用Self-Attention(自注意力) 代替循环连接
**2.**编码器(Encoder)详解
输入: 我, 喜欢, 猫
↓
词嵌入 + 位置编码(知道词的顺序)
↓
┌─────────────────┐
│ Self-Attention │ ← 核心:每个词都看看其他词,计算关联度
│ (多头注意力) │ "喜欢"看"我"和"猫",决定关注谁
└─────────────────┘
↓
前馈神经网络(FFN)← 对每个词单独做变换
↓
重复N层(如12层)
↓
输出: 上下文相关的向量表示
我', 喜欢', 猫' ← 每个词的向量都融合了整句信息
通过堆叠,编码器解码器的处理能力逐级增强
"逐级增强"是什么意思?
第1层: "喜欢"知道附近有"我"和"猫"
第2层: "喜欢"知道"我"是主语,"猫"是宾语
第3层: "喜欢"知道这是"人对动物的情感"
...
第12层: 深层语义,"喜欢"的情感强度、正式程度等
每层都在细化理解,像从"识字"到"理解含义"到"体会情感"。
核心:每层到底在增强什么?
输入向量 (词向量+位置信息)
↓
┌─────────────────────────────────────┐
│ Multi-Head Self-Attention │ ← 第一层增强:建立词与词的关联
│ (多头自注意力) │
│ │
│ "猫"看"坐""在""垫子""上",计算: │
│ - 我和谁最相关? │
│ - 我和"垫子"关系强(主语-宾语) │
│ - 我和"坐"关系强(主语-动作) │
│ │
│ 输出:关联后的向量 猫', 坐', 在', 垫子', 上' │
│ 每个词向量都"混入"了其他词的信息 │
└─────────────────────────────────────┘
↓
残差连接 + LayerNorm(防止信息丢失,训练稳定)
↓
┌─────────────────────────────────────┐
│ Feed-Forward Network (FFN) │ ← 第二层增强:非线性变换
│ (前馈神经网络) │
│ │
│ 对每个词向量单独做: │
│ 输入: 猫' = 0.2, -0.1, 0.5, ... │
│ 经过: W₂(ReLU(W₁x + b₁)) + b₂ │
│ 输出: 猫'' = 0.8, 0.3, -0.1, ... │
│ │
│ 作用:增加非线性表达能力, │
│ 把"关联信息"进一步加工提炼 │
└─────────────────────────────────────┘
↓
残差连接 + LayerNorm
↓
输出到下一层
逐层增强的含义:
第1层输入: 猫₀ = 只包含"猫"这个词本身的信息
第1层输出: 猫₁ = 猫₀ + 与"坐"的关联(主谓关系初识)
(知道自己是主语,后面有个动作)第2层输入: 猫₁
第2层输出: 猫₂ = 猫₁ + 与"垫子"的关联(语义角色细化)
(知道自己是"坐"的主体,"垫子"是客体)第3层输出: 猫₃ = 加入与整句的情感/语气理解
...
第12层输出: 猫₁₂ = 包含全句深层语义(谁在什么上对什么做了什么)
词向量的语义表达能力,从孤立词义 → 句法关系 → 语义角色 → 语用理解
3.解码器(Decoder)详解
编码器和解码器很相似,但是有两个关键区别
解码器输入: I, love(已生成的词)
↓
┌─────────────────────┐
│ Masked Self-Attention│ ← 带掩码!只能看左边,不能偷看右边
│ (自回归特性) │ 生成"llamas"时,只能看I, love,不能看答案
└─────────────────────┘
↓
┌─────────────────────┐
│ Cross-Attention │ ← 关键!看编码器的输出(源语言信息)
│ (编码器-解码器注意力)│ 生成荷兰语时,回头参考英语原句
└─────────────────────┘
↓
前馈神经网络
↓
输出: "llamas"(下一个词)
4.BERT:双向编码器
4.1 啥叫双向?
GPT(生成式): 只能从左看到右
"我 喜欢 ___" → 猜"猫"
不知道后面有什么!
BERT(双向): 左右都能看到
"我 ___ 猫" → 猜"喜欢"
看全文猜中间!
- Gpt:自回归,适合生成
- BERT:双向,适合理解
4.2 CLS标记详解(全局表征?)(摘要员)
输入: CLS 我 喜欢 猫
↑
特殊标记,初始无意义,专门训练用来"总结"经过12层后:
CLS' = 整句话的压缩表示
(不是我+喜欢+猫的简单相加,
而是学会了"这句话是正面情感")用途:
- 情感分类: CLS' → 全连接层 → "正面"
- 文本相似: 比较两句的CLS'向量距离
关键 : CLS的向量是通过注意力机制,主动学习如何总结全文,不是被动装东西。
输入: CLS 我 喜欢 猫
↑
特殊标记,无实际语义
经过12层Transformer后:
CLS' = 整句话的"摘要向量"
包含了"我"、"喜欢"、"猫"的全部信息
用途:
分类任务: CLS' → 全连接层 → 情感分类(正面/负面)
句子关系: CLS' → 判断两句是否相关
为什么用CLS而不是取平均?
取平均: 我+喜欢+猫/3 → 模糊,重点不突出
CLS: 经过专门训练,学会"总结全文"
就像专门培养了一个"摘要员"
单向vs双向(对比理解)
句子: "我___今天很开心"
BERT(双向):
左边: "我"
右边: "今天很开心"
两边一起看 → 猜"今天"(知道是时间词)
优势: 理解完整语境,适合填空、分类
GPT(单向):
只能看: "我"
预测下一个词 → "今天"
再看: "我今天" → 预测"很"
优势: 适合续写、生成,和人类写作一样逐字产出
5. 掩码语言建模训练(MLM)
原始句: 我 喜欢 在 阳光 下 睡觉
掩码后: 我 MASK 在 阳光 下 MASK
↑ ↑
预测"喜欢" 预测"睡觉"
训练目标: 让模型根据上下文猜被遮住的词
迫使模型真正理解语义,而不是死记硬背
原始句: 猫 MASK 在垫子上 ("坐"被遮住)↓
BERT编码器处理(双向,能看到"猫""在垫子上")
↓
输出: MASK位置的向量 → 预测"坐"的概率最高
↓
训练目标: 让预测接近真实词"坐"
和Transformer的关系:
- MLM是BETR的训练方法,不是transformer原始论文的,
- 原始transformer用自回归(预测下一个词)
- BETR改成MLM,强迫模型双向理解
5.1 两阶段训练

- 预训练:学会通用的语言理解诶能力(义务教育)
- 微调:学会特定任务的技能(进厂了,该专业培训了)
6. GPT vs BETR 生成式vs表征式
架构对比:
┌─────────────────┐ ┌─────────────────┐
│ GPT(生成式) │ │ BERT(表征式) │
├─────────────────┤ ├─────────────────┤
│ Transformer │ │ Transformer │
│ Decoder × 12 │ │ Encoder × 12 │
│ (只有解码器) │ │ (只有编码器) │
├─────────────────┤ ├─────────────────┤
│ Masked Self- │ │ Full Self- │
│ Attention │ │ Attention │
│ (只能看左边) │ │ (左右都能看) │
├─────────────────┤ ├─────────────────┤
│ 输出: 下一个词 │ │ 输出: 语义向量 │
│ "llamas" │ │ 我',喜欢',猫' │
└─────────────────┘ └─────────────────┘
7. 关注!! 知识点串联?
词袋模型(BoW) ──→ 没语义,淘汰
↓
Word2Vec ───────→ 静态向量,"bank"歧义
↓
RNN ────────────→ 有序列但慢,长句遗忘
↓
RNN + Attention ─→ 翻译时动态看源语言(图7)
↓
Transformer ────→ 完全基于注意力,编码器+解码器(图8)
↓
├────────────→ BERT: 只用编码器,双向理解(图9)
│ CLS分类,MLM训练,适合理解任务
│
└────────────→ GPT: 只用解码器,单向生成(图10)
自回归生成,适合对话/写作
↓
ChatGPT = GPT + 人类反馈训练
GPT,BETR 和 transformer的关系(核心)##!!
Transformer原始论文(2017):
├─ 编码器(6层)→ 理解输入
└─ 解码器(6层)→ 生成输出
(用于机器翻译:英文→法文)后续发展:
├─ BERT(2018): 把编码器拿出来,堆到12层,加MLM训练
│ → 只做理解,不做生成
│
└─ GPT(2018): 把解码器拿出来,堆到12层,保持自回归
→ 只做生成,不做理解(单向)ChatGPT(2022): GPT-3.5/4,解码器堆到96层+,加人类反馈训练
关系 : GPT和BERT都是Transformer的"零部件"单独放大版,不是完整Transformer。
知识脉络图
文本表示演进:
BoW(词袋) → Word2Vec(静态向量) → RNN(有序列) → Transformer(全并行)
↓
┌─────────┴─────────┐
↓ ↓
编码器(理解) 解码器(生成)
↓ ↓
BERT(双向) GPT(单向)
MLM训练 自回归训练
CLS分类 续写生成
5.分词和嵌入技术
5.1 分词和嵌入技术
完整流程概览
输入句子: "unhappiness"
↓
┌─────────────────────────────────────────┐
│ 第一步: 分解更小单元 │
│ │
│ 检查词表: "unhappiness"在不在? │
│ 结果: 不在(词表只有3万-5万常用词) │
│ │
│ 策略: 拆成子词(Subword) │
│ "unhappiness" → "un" + "happiness" │
│ 或 → "un" + "happy" + "ness" │
│ │
│ 词表检查: │
│ - "un": ✓ 在词表(前缀) │
│ - "happy": ✓ 在词表(词根) │
│ - "ness": ✓ 在词表(后缀) │
│ │
│ 最终分解: "un", "happy", "ness" │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 第二步: 词完整或片段的判断 │
│ │
│ 规则: │
│ - 完整词: 直接保留 │
│ - 片段: 标记为子词(通常加##表示) │
│ │
│ 例子: "un" + "##happy" + "##ness" │
│ ##表示这是词的中间/结尾部分,不是独立词 │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 第三步: 组合还原(模型内部完成) │
│ │
│ 模型看到: "un", "##happy", "##ness" │
│ │
│ Self-Attention计算: │
│ - "un"看"##happy": 发现"un"+"happy"="unhappy"(否定+形容词)
│ - "##happy"看"##ness": 发现形容词+后缀=名词
│ - 三层关联: 理解这是"不幸福"的名词形式 │
│ │
│ 嵌入向量融合: │
│ un的向量 + happy的向量 + ness的向量 │
│ → 通过注意力加权,组合成"unhappiness"的语义表示 │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 第四步: 分词器词表有限 → ID映射 │
│ │
│ 词表大小: 如BERT是30522,GPT是50257 │
│ 映射: │
│ "un" → 1024 │
│ "##happy" → 8876 │
│ "##ness" → 4521 │
│ │
│ 输入模型: 1024, 8876, 4521 │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 第五步: 模型内部生成词元嵌入 │
│ │
│ 嵌入层查表: │
│ ID 1024 → 向量 0.2, -0.1, 0.5, ... │
│ ID 8876 → 向量 0.1, 0.3, -0.2, ... │
│ ID 4521 → 向量 -0.3, 0.7, 0.1, ... │
│ │
│ 注意: 这是静态嵌入,每个子词有自己的向量 │
│ 但"##happy"的向量包含了"happy"的语义信息 │
│ (训练时学到的) │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 第六步: 生成式模型生产新词元 │
│ │
│ 上下文嵌入经过Transformer后: │
│ "unhappiness"的表示 = 三个子词向量的融合 │
│ │
│ 解码器预测下一个词: │
│ 根据"unhappiness"的语义,预测可能的后续 │
│ 如"causes"、"is"、"makes"等 │
└─────────────────────────────────────────┘
5.2 三种分词粒度对比
词语级分词:
例子: "I love natural language processing"
分词: "I", "love", "natural", "language", "processing"
↓
问题1: 词表爆炸
英语: 17万+单词
加上专业术语、新词、拼写变体 → 无限增长
问题2: 未登录词(OOV)
"Transformerization"不在词表 → UNK
信息完全丢失!
问题3: 形态学信息丢失
"processing", "processes", "processed"
是同一个词根的不同形式,但被当成完全不同的词
子句级分词--现代标准
初始: 词表 = 所有单个字符
"T", "r", "a", "n", "s", "f", "o", "r", "m", "e", "r"
训练数据中出现频率:
"Th"出现1000次 → 合并加入词表
"he"出现950次 → 合并加入词表
"er"出现900次 → 合并加入词表
"Trans"出现800次 → 合并
...
最终词表: "T", "h", "e", "Trans", "form", "##er", "##s", "##ing", ...
编码"Transformers":
贪心匹配最长子词:
"Trans" + "form" + "##er" + "##s" → 287, 892, 1024, 56
1. wordpiece(BERT使用)
与BPE区别: 不是看频率,而是看概率
选择合并: 使训练数据似然(likelihood)最大的子词对
例子:
"un" + "happy"的联合概率 > 单独概率
→ 合并成"unhappy"
BERT词表特点:
30522个token
常见词完整保留: "the", "and", "cat"
罕见词拆分子词: "hypersensitivity" → "hyper", "##sensit", "##ivity"
2.BPE(Byte Pair Encoding)算法
初始: 词表 = 所有单个字符
"T", "r", "a", "n", "s", "f", "o", "r", "m", "e", "r"
训练数据中出现频率:
"Th"出现1000次 → 合并加入词表
"he"出现950次 → 合并加入词表
"er"出现900次 → 合并加入词表
"Trans"出现800次 → 合并
...
最终词表: "T", "h", "e", "Trans", "form", "##er", "##s", "##ing", ...
编码"Transformers":
贪心匹配最长子词:
"Trans" + "form" + "##er" + "##s" → 287, 892, 1024, 56
字符级分词:
例子: "cat"
分词: "c", "a", "t"
↓
优点:
词表极小: 26个字母 + 标点 + 数字 ≈ 100个token
无OOV问题: 任何词都能拼出来
缺点:
序列极长: "unhappiness" → 13个字符
语义粒度太细: 模型需要学"c"+"a"+"t"=猫,而不是直接知道"cat"
计算成本高: 注意力复杂度O(n²),长序列平方增长
5.3 BETR的特殊处理:没收入的词咋办啊
wordPiece策略
词表构成:
┌─────────────────────────────────────┐
│ 完整词(常用词): 占大部分 │
│ the, and, cat, dog, happy, ... │
│ 约2万个 │
├─────────────────────────────────────┤
│ 子词(前缀/后缀/词根): │
│ un, re, pre, ##ing, ##ed, ##ly, │
│ ##tion, ##ness, ... │
│ 约1万个 │
├─────────────────────────────────────┤
│ 特殊标记: │
│ CLS, SEP, PAD, UNK, MASK │
│ 约100个 │
└─────────────────────────────────────┘
比如:
输入: "unhappiness"
↓
WordPiece分词:
查"unhappiness" → 不在词表
查"unhappy" → 不在词表
查"un" → ✓ 在词表(ID: 4891)
剩余"happiness"
查"happiness" → ✓ 在词表(ID: 9832)
结果: "un", "happiness"
↓
模型输入: 4891, 9832
↓
嵌入层:
"un" → 向量表示"否定前缀"
"happiness" → 向量表示"幸福"
↓
Self-Attention:
"un"看"happiness": 发现否定关系
组合语义: "不幸福"
BERT通过子词组合,用有限的词表表达无限的词汇。
5.4 知识串联一下
┌──────────────────────────────────────────────────────┐
│ 前面学的: Transformer架构(编码器-解码器,Self-Attention)│
│ ↓ 需要输入 │
│ 问题: 文本怎么变成Transformer能处理的格式? │
│ ↓ │
│ 本章答案: 分词 + 嵌入 │
│ ↓ │
│ 分词解决: 无限文本 → 有限词表 → 序列ID │
│ (词语级/子词级/字符级的权衡) │
│ ↓ │
│ 嵌入解决: 离散ID → 连续向量 → 语义空间 │
│ (静态嵌入 → 上下文嵌入) │
│ ↓ │
│ 最终输入: Transformer处理,生成理解或生成结果 │
└──────────────────────────────────────────────────────┘
关系链:
分词粒度选择 → 影响序列长度和语义表达 → 影响Transformer效率和理解能力
↑ ↓
└──────────────── 共同决定模型性能 ← 嵌入质量(随机→预训练→微调)
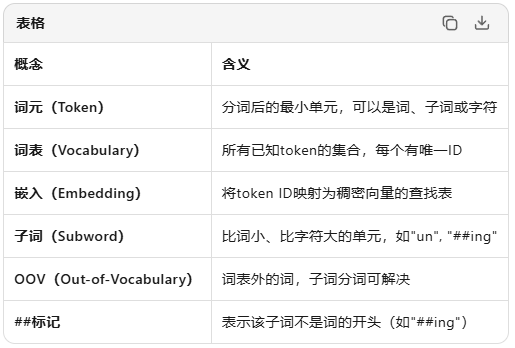
6.大型语言模型如何处理标记以生成文本
至此,我们已经了解语言如何被数值化表示,词语如何转化为令牌,并通过密集嵌入向量表征。接下来探究transformer架构细节。
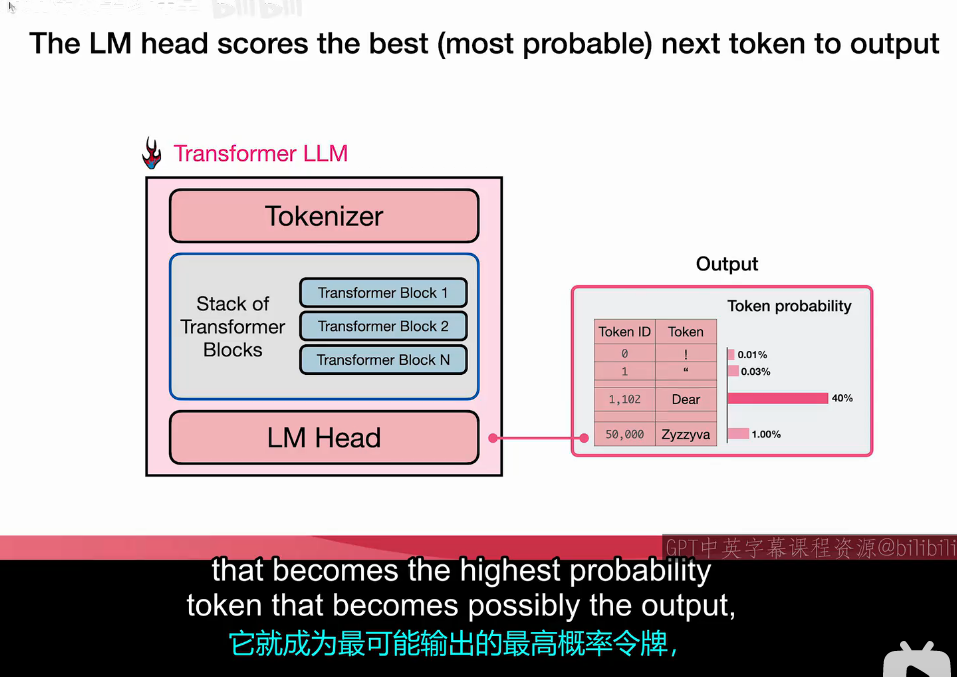
6.1 三大核心部件拆解


6.2 解码策略详解
6.2.1 贪心解码--最简单()
原理: 每次选择概率最高的token
例子:
当前序列: "Write an email"
模型输出概率:
"to": 0.35 ← 最高,选这个
"for": 0.25
"about": 0.20
...
结果: "Write an email to..."
下一步: 基于"Write an email to"继续预测...
问题: 局部最优 ≠ 全局最优
可能陷入重复或平庸表达
"the the the..."或"I think I think..."
6.2.2 束搜索 --平衡质量
原理: 保留top-k个候选序列,同时探索
例子: beam_size=2
步骤1: "Write"
候选: "Write to"(0.3), "Write for"(0.25)
步骤2: 扩展两个候选
"Write to" → "Write to Sarah"(0.12), "Write to you"(0.10)
"Write for" → "Write for Sarah"(0.15), "Write for you"(0.08)
保留top2: "Write for Sarah"(0.15), "Write to Sarah"(0.12)
步骤3: 继续扩展...
最终选整体概率最高的完整序列
优点: 比贪心搜索质量好
缺点: 计算量大,可能生成"安全但无聊"的文本
6.3 并行处理和上下文长度
1.为啥能并行?
RNN(不能并行):
"Write" → 处理完 → "an" → 处理完 → "email" → ...
必须顺序,像排队
Transformer(可以并行):
"Write" ──┐
"an" ──┼→ 同时进入Self-Attention,同时计算
"email"──┘
Self-Attention公式: Attention(Q,K,V) = softmax(QK^T/√d)V
矩阵运算,GPU可以并行加速
2. 上下文长度是啥
上下文长度 = 模型能"看到"的最大token数
GPT-3: 2048 tokens
GPT-4: 8192 / 32768 tokens
Claude: 100K+ tokens
例子:
提示: "Write an email..."(50 tokens)
生成: 已经写了1000 tokens
如果上下文长度=2048:
当总token达到2048时,最前面的token被"遗忘"
可能丢失关键指令!
如果上下文长度=100K:
可以处理整本书,保持长期一致性
3. 多个处理通道的理解
Transformer Block内部:
┌─────────────────────────────────────────┐
│ 输入: 8个token "Write", "an", ... │
│ │
│ 不是: 一个token一个token处理 │
│ 而是: 8个token同时进入,8个通道并行 │
│ │
│ Self-Attention: │
│ 每个token都计算与其他7个token的关系 │
│ 8×8的注意力矩阵,一次算完 │
│ │
│ FFN: 8个token各自独立通过同一网络 │
│ 批处理,GPU并行加速 │
└─────────────────────────────────────────┘

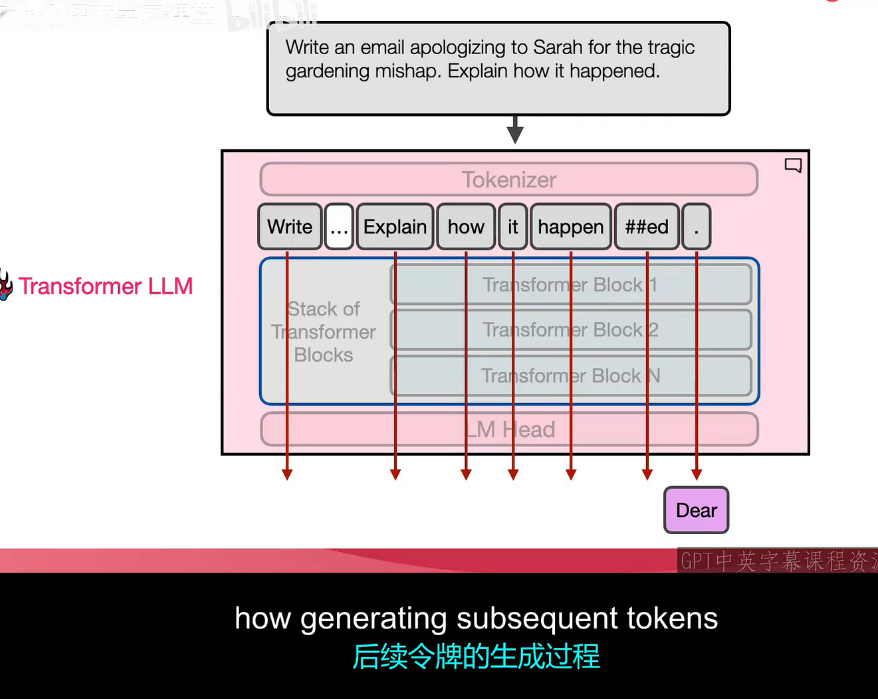
6.4 串联一下知识点
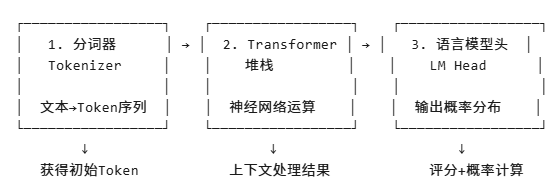
6.4.1 分词器工作
输入句子 → 分解更小单元(词或子词片段)→ 组合还原语义
↓
分词器词表有限 → 未收入词拆成子词(如happened→happen+##ed)
↓
每个Token分配唯一ID → 输入语言模型
6.4.2 transformer堆栈处理
获得所有初始Token(ID序列)→ 嵌入层转成向量
↓
┌─────────────────┐
│ 关键特性:并行处理 │
│ 所有Token同时进入 │
│ 多个处理通道同时流经 │
└─────────────────┘
↓
堆叠的神经网络运算(多层Self-Attention+FFN)
↓
基于上下文处理结果:每个Token向量融合全局信息
↓
生成上下文嵌入(动态语义表示,区别于静态嵌入)
6.3.3 生成下一个token
堆栈输出 → 语言模型头(LM Head)→ 对词表中所有Token评分
↓
Softmax转为概率分布
↓
解码策略选择(不是简单选最高分!):
• 贪心:直接选最高
• 采样:按概率随机选(Temperature控制)
• 束搜索:保留多个候选
↓
生成下一个响应Token
分词器把文本拆成Token ID → Transformer堆栈并行处理所有Token,逐层增强语义理解,生成上下文相关嵌入 → LM头评分算概率 → 解码策略选下一个Token → 自回归循环生成,KV缓存避免重复计算加速推理。
7.
在transformer架构概览中,我们了解经过分词处理之后,词嵌入向量会通过堆叠的transformer块进行传递现在深入解析这些处理块的细节
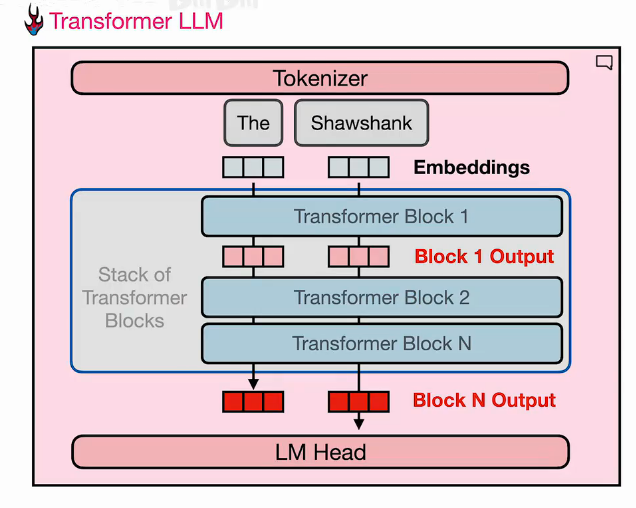
7.1 双轨处理机制(起点)
1.分词器输入提示,分解为词元
用户提示: "The cat sat"
↓
分词器处理:
"The" → Token ID: 101
"cat" → Token ID: 5432
"sat" → Token ID: 8765
序列: 101, 5432, 8765
2.每个词元有对应嵌入向量(替换)
嵌入层查表(替换过程):
101 → 0.2, -0.1, 0.5, ..., 0.3 (768维)
5432 → 0.1, 0.4, -0.2, ..., 0.8
8765 → -0.3, 0.2, 0.7, ..., -0.1
语言 → 数字(完成转换)
3.这是起点
此时状态:
• 每个词元有独立向量
• 向量之间还没有交互
• 等待进入Transformer块进行处理
7.2 流向第一块,进行处理
1.transformer内部组件运算(重点)
第一块输入: The向量, cat向量, sat向量
↓
┌─────────────────────────────────────────┐
│ 组件1: 自注意力层(Self-Attention) │
│ │
│ 运算过程: │
│ The向量 ──┐ │
│ cat向量 ──┼→ 互相计算注意力分数 │
│ sat向量 ──┘ │
│ │
│ 结果: │
│ The' = The + 0.3×cat + 0.2×sat │
│ cat' = cat + 0.5×The + 0.4×sat │
│ sat' = sat + 0.2×The + 0.6×cat │
│ │
│ 含义: 每个词元向量融入了其他词元的信息 │
└─────────────────────────────────────────┘
↓
残差连接 + LayerNorm(稳定训练)
↓
┌─────────────────────────────────────────┐
│ 组件2: 前馈神经网络层(FFN) │
│ │
│ 结构: 先扩散(升维)→ 再收缩(降维) │
│ │
│ 输入: 768维 │
│ ↓ │
│ Linear1: 768 → 3072(扩散4倍) │
│ ↓ │
│ ReLU激活(非线性变换) │
│ ↓ │
│ Linear2: 3072 → 768(收缩回原维) │
│ ↓ │
│ 输出: 768维 │
│ │
│ 作用: │
│ • 扩散: 增加表达能力,探索更多特征组合 │
│ • 收缩: 筛选重要信息,压缩回标准维度 │
│ • 非线性: 让模型学习复杂模式 │
└─────────────────────────────────────────┘
↓
残差连接 + LayerNorm
↓
第一块输出: The'', cat'', sat''
7.3第二层回合第一层相同方式处理他的输出
第一块输出 → 作为第二块输入
↓
第二块内部:
自注意力层: The''看cat''和sat'',进一步细化关系
FFN层: 再次扩散→收缩,提炼更抽象特征
↓
输出: The''', cat''', sat'''
相同方式: 每层都是 Self-Attention + FFN 的结构不变
不同: 输入已经融合了更丰富的上下文,处理的是更高层次的抽象
7.4 各处理轨道保持并行(啥意思)
并行含义:
┌─────────────────────────────────────────┐
│ 不是: The处理完 → cat处理完 → sat处理完 │
│ (串行,慢) │
│ │
│ 而是: │
│ The ──┐ │
│ cat ──┼→ 同时进入Self-Attention │
│ sat ──┘ 同时计算 │
│ │
│ 矩阵运算: 3×768 × 768×3 = 3×3 │
│ 一次完成所有词元之间的注意力计算 │
│ │
│ 3个处理轨道(3个词元)同时流经网络 │
│ GPU并行加速 │
└─────────────────────────────────────────┘
7.5 这样逐层处理
Layer 1: 基础语法关系(The是冠词,cat是名词)
↓
Layer 2: 短语结构(The cat是名词短语)
↓
Layer 3: 谓语关系(cat是sat的主语)
↓
...
Layer 12: 深层语义(理解整句描述的场景)
每层都在前一层基础上,提取更抽象的特征
7.6 最后一层之后
最后一层输出: The_final, cat_final, sat_final
↓
语言模型头(LM Head):
Linear: 768维 → 词汇表大小(如50257维)
↓
Softmax: 转为概率分布
↓
预测下一个词元:
"on": 0.15
"there": 0.10
"down": 0.35 ← 最高概率
"quietly": 0.20
...
7 !.2 每个transformer块的两个核心组件详解
1.自注意力机制:关注之前的标记
核心能力: 将上下文信息融入当前处理标记
处理"sat"时:
sat向量 ← 看The向量(0.2权重)
← 看cat向量(0.6权重)
← 看自己(0.2权重)
sat' = 0.2×The + 0.6×cat + 0.2×sat
结果: sat的新向量融入了"The cat"的信息
理解自己是"猫发出的坐的动作"
7.2 前馈神经网络层:扩散再收缩
结构细节:
输入向量 ──→ Linear(768→3072) ──→ ReLU ──→ Linear(3072→768) ──→ 输出
扩散: 拓宽特征空间\] \[非线性\] \[收缩: 筛选压缩
为什么需要扩散?
• 768维可能不足以表达复杂特征组合
• 3072维提供更多"思考空间"
• 类似人脑: 先发散联想,再收敛结论
为什么需要收缩?
• 保持维度一致,才能堆叠多层
• 筛选掉噪声,保留核心信息
要理解transformer的工作原理,需要关注在transformer块堆栈中流动的双轨处理机制;
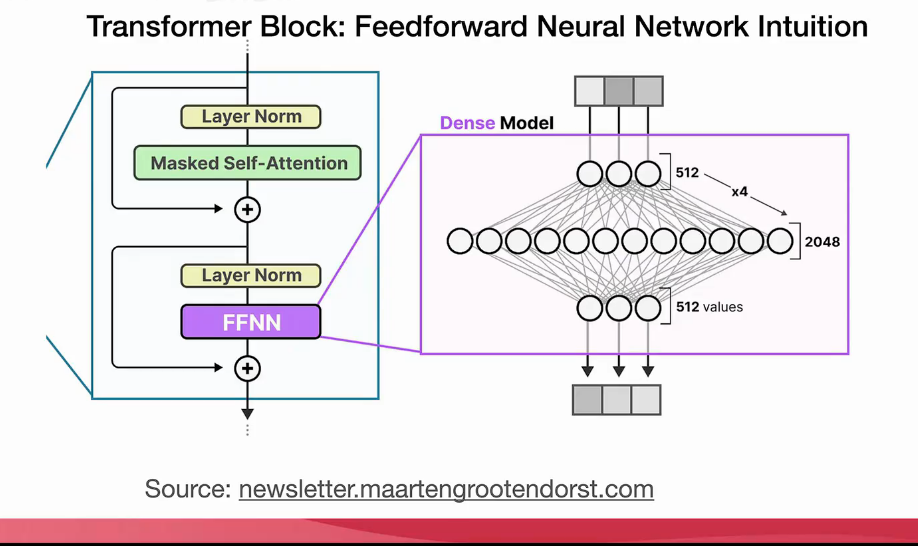
补充前馈神经网络FFN部分
1. FFN在transformer中的位置和作用
整体结构中的位置
Transformer Block内部:
┌─────────────────────────────────────────┐
│ 输入: 自注意力层输出(已融入上下文信息) │
│ ↓ │
│ ┌─────────────────────────────────┐ │
│ │ Add & Norm(残差+归一化) │ │
│ └─────────────────────────────────┘ │
│ ↓ │
│ ┌─────────────────────────────────┐ │
│ │ 前馈神经网络层(FFN) │ ← 重点 │
│ │ Feed-Forward Network │ │
│ └─────────────────────────────────┘ │
│ ↓ │
│ ┌─────────────────────────────────┐ │
│ │ Add & Norm(残差+归一化) │ │
│ └─────────────────────────────────┘ │
│ ↓ │
│ 输出: 到下一层或最终输出 │
└─────────────────────────────────────────┘
为啥需要FFN?
自注意力已经融合了上下文,为啥还要FFN?
自注意力做的事情: 信息混合(谁该关注谁)
"cat"看了"The"和"at",知道自己是主语
FFN做的事情: 特征转换(深度加工)
把"我是主语"这个信息,转换成更高维度的抽象特征
比如: 主语+动物+单数+第三人称...
类比:
自注意力 = 开会讨论,大家交换意见
FFN = 每个人回去独自思考,把讨论结果内化
2.FFN的具体结构详解
2.1 数学公式
FFN(x) = W₂ · ReLU(W₁ · x + b₁) + b₂
其中:
• x: 输入向量(768维)
• W₁: 768 × 3072 的权重矩阵(扩散)
• b₁: 3072维的偏置
• ReLU: 激活函数(非线性)
• W₂: 3072 × 768 的权重矩阵(收缩)
• b₂: 768维的偏置
2.2 分布拆解
输入向量 x: 0.2, -0.1, 0.5, ..., 0.3 ← 768个数
↓
第一步: 线性扩散(Linear1)
W₁ · x + b₁
768维 → 3072维(扩大4倍)
为什么扩散?
• 768维空间可能不够用
• 3072维提供更多"思考维度"
• 类似: 草稿纸比大脑内存大,可以展开计算结果: 1.2, -0.5, 0.8, ..., 2.1 ← 3072个数
↓
第二步: 非线性激活(ReLU)
ReLU(x) = max(0, x)
作用: 引入非线性,让模型能学习复杂模式
例子:
输入: 1.2, -0.5, 0.8, -2.0, 0.0
输出: 1.2, 0.0, 0.8, 0.0, 0.0 ← 负数变0
为什么需要非线性?
• 如果没有激活,两层线性 = 一层线性
• 非线性让网络可以拟合任意复杂函数↓
第三步: 线性收缩(Linear2)
W₂ · ReLU输出 + b₂
3072维 → 768维(压缩回原维度)
为什么收缩?
• 保持维度一致,才能堆叠多层
• 筛选重要信息,去除噪声
• 类似: 草稿纸写满后,总结成一段话结果: 0.4, 0.1, -0.3, ..., 0.7 ← 768个数
↓
输出: 与输入同维度,但内容已深度加工
3. 扩散--》收缩的直观理解
3.1 为啥是先扩散后收缩?
场景类比: 解决一个复杂问题
狭窄空间(768维):
问题: "cat"在句中是什么角色?
只能想: 是名词(太简单)宽敞空间(3072维):
可以展开思考:
- 是主语还是宾语?
- 是动物还是植物?
- 是单数还是复数?
- 和动词"sat"什么关系?
- 情感色彩是正面还是负面?
每个维度探索一个方面
总结压缩(回到768维):
把3072个维度的探索结果,提炼成精华:
"cat" = 主语, 动物, 单数, 第三人称, 中性情感, ...
3.2 可视化示意
输入(768维): 一个点
↓
扩散(3072维): 展开成一个面/空间
• 维度1-500: 句法角色探索
• 维度501-1000: 语义类别探索
• 维度1001-1500: 情感色彩探索
• 维度1501-3072: 其他特征探索
↓
ReLU激活: 筛选有效探索,关闭无效方向
↓
收缩(768维): 把探索结果压缩成精炼特征向量
↓
输出(768维): 一个更"有内涵"的点
4. FFN和Self-Attention的对比
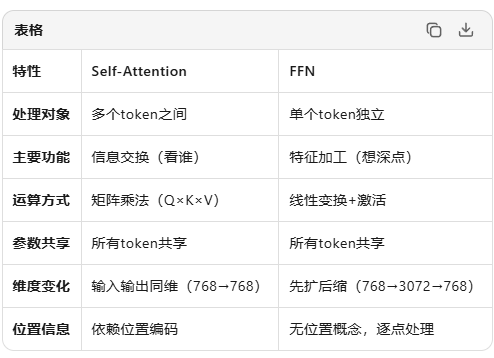
两者互补:
- self-attention 横向联系,token之间交互
- FFN纵向深挖,单个token内部特征提炼
5.FFN的训练和学习
5.1 学啥?
W₁(768×3072): 学习如何把768维特征展开到3072维空间
每个输出维度 = 输入768维的加权组合
W₂(3072×768): 学习如何从3072维空间提炼回768维
筛选哪些维度重要,哪些可以丢弃
b₁, b₂: 偏置项,调整激活阈值
5.2 训练过程
前向传播:
输入 → FFN计算 → 输出 → 计算损失
反向传播:
损失 → 梯度 → 更新W₁, W₂, b₁, b₂
学习结果:
W₁学会: 哪些原始特征组合有意义(如"主语+动物")
W₂学会: 如何把这些组合压缩成高效表示
FFN = 先扩散(768→3072)给模型足够空间探索特征,再收缩(3072→768)提炼精华,配合ReLU非线性,让每个token的表示从"知道上下文"升级为"深度理解上下文"。
Self-Attention横向看关系,FFN纵深挖潜质------完全正确!
这就是Transformer设计的精妙之处:先横向打通信息,再纵向深化理解,层层堆叠,从表面语义到深层理解。
总结
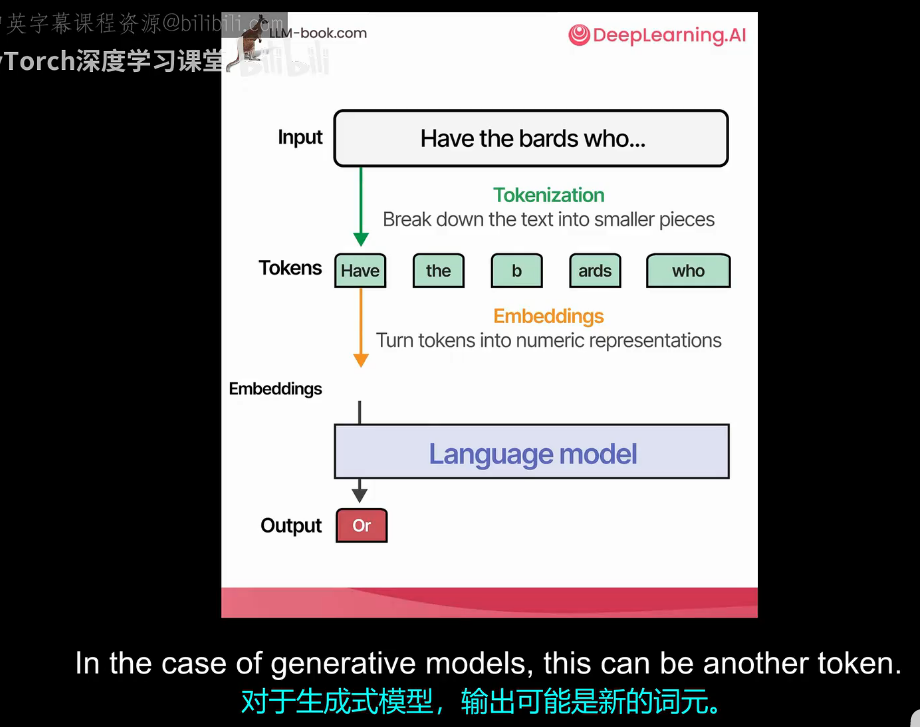
Transformer是一种完全基于注意力机制的神经网络架构,它摒弃了传统的循环结构,通过堆叠编码器和解码器来处理序列数据。理解Transformer需要从最基础的分词开始,文本首先经过分词器被拆解成更小的单元,这些单元可以是完整的词,也可以是子词片段,比如"happened"会被拆成"happen"和"##ed",这样做的原因是分词器的词表有限,无法收录所有词汇,通过子词组合可以表达无限的新词。每个词元会被映射为唯一的ID,再经过嵌入层转换成稠密的向量表示,至此语言被转化为了数字,这是整个流程的起点。
这些向量进入Transformer块堆栈后,会经历双轨处理机制。首先是自注意力层,它的作用是横向建立词与词之间的关系,每个词元都会计算与其他所有词元的关联程度,比如"cat"会关注"The"和"sat",通过加权求和将上下文信息融入自身的表示中,此时词元向量已经完成了信息交换和融合。接下来是前馈神经网络层,它的作用是纵向深度加工,先将768维的向量扩散到3072维的高维空间,在这个宽敞的空间中探索各种潜在特征,比如句法角色、语义类别、情感色彩等,然后通过非线性激活函数ReLU筛选有效信息,最后收缩回768维,提炼出更丰富的内在表示。这种先扩散后收缩的结构让模型能够挖掘词元的深层潜质,将表面的上下文关联升华为抽象的特征理解。
堆栈中的每一层都采用相同的处理路线,但语义表示逐级增强。第一层可能只识别出基本的词性和短语结构,到了更高层则能理解复杂的句法关系和语义角色,最深层甚至可以把握整个句子的意图和情感。各处理轨道保持并行,所有词元同时流经网络,这是Transformer计算效率高的关键。最后一层的输出会进入语言模型头,通过线性变换和Softmax生成词汇表上的概率分布,解码策略可以选择贪心搜索直接取最高概率,也可以采用温度采样引入多样性,或者使用束搜索保留多个候选。
在生成式模型中,这个过程是自回归的,首个词元生成后会与完整提示一起重新输入模型,循环往复直到生成结束符。为了加速推理,KV缓存技术被广泛应用,它存储了之前词元的键和值,避免重复计算,使生成速度从平方级降为线性级。双向编码器如BERT能够从左右两个方向同时理解上下文,适合表征任务,它使用掩码语言建模进行训练,通过预测被遮蔽的词来强迫模型深度理解语义,特殊的CLS标记作为全局表征用于分类任务。而生成式模型如GPT只使用解码器,单向生成,适合续写和对话,经过人类反馈强化学习后成为ChatGPT这样的对话系统。无论是BERT还是GPT,它们都只是Transformer架构的零部件单独放大版,前者放大编码器用于理解,后者放大解码器用于生成,两者共同构成了现代自然语言处理的技术基石。
随着Transformer架构在自然语言处理领域的巨大成功,其"注意力机制"和"编码器-解码器"结构展现出强大的序列建模能力。然而,计算机视觉领域长期以来依赖卷积神经网络作为主干,目标检测任务更是需要复杂的锚框设计和后处理步骤。2020年,Facebook AI提出的DETR(DEtection TRansformer)首次将Transformer完整引入目标检测领域,摒弃了传统的锚框生成和非极大值抑制等手工设计组件,实现了端到端的检测范式。DETR直接采用Transformer的编码器-解码器结构,将图像特征视为序列数据,通过自注意力机制建模全局关系,借助交叉注意力实现目标查询与图像特征的交互,最终并行输出预测结果。这一工作不仅验证了Transformer在视觉任务中的通用性,更开创了视觉Transformer的新纪元,为后续ViT、Swin Transformer等研究奠定了基础。理解DETR,本质上是在理解如何将NLP领域的Transformer思想迁移并适配到计算机视觉的目标检测任务中。