
目录
[引言:当 AI 遇见数据库](#引言:当 AI 遇见数据库)
[1.1 项目背景与痛点](#1.1 项目背景与痛点)
[1.2 目标用户画像](#1.2 目标用户画像)
[1.3 核心需求梳理](#1.3 核心需求梳理)
[1.4 技术选型](#1.4 技术选型)
[2.1 功能全景图](#2.1 功能全景图)
[2.2 详细功能清单](#2.2 详细功能清单)
[3.1 整体架构](#3.1 整体架构)
[3.2 核心流程](#3.2 核心流程)
[3.3 数据流设计](#3.3 数据流设计)
[3.4 安全架构](#3.4 安全架构)
[4.1 安装 Docker 环境](#4.1 安装 Docker 环境)
[4.2 部署 Dify](#4.2 部署 Dify)
[4.3 访问 Dify 管理界面](#4.3 访问 Dify 管理界面)
[4.4 配置大模型](#4.4 配置大模型)
[5.1 创建数据库](#5.1 创建数据库)
[5.2 创建数据表](#5.2 创建数据表)
[5.3 插入测试数据](#5.3 插入测试数据)
[第六章:Dify 工作流构建](#第六章:Dify 工作流构建)
[6.1 创建工作流应用](#6.1 创建工作流应用)
[6.2 配置数据库连接工具](#6.2 配置数据库连接工具)
[6.3 工作流节点设计](#6.3 工作流节点设计)
[6.4 开始节点配置](#6.4 开始节点配置)
[6.5 知识库节点配置](#6.5 知识库节点配置)
[6.6 Agent 节点配置](#6.6 Agent 节点配置)
[6.7 代码执行节点(SQL校验)](#6.7 代码执行节点(SQL校验))
[6.8 HTTP 请求节点(执行查询)](#6.8 HTTP 请求节点(执行查询))
[6.9 模板转换节点(格式化结果)](#6.9 模板转换节点(格式化结果))
[JSON 数据](#JSON 数据)
[第七章:API 服务开发](#第七章:API 服务开发)
[7.1 项目结构](#7.1 项目结构)
[7.2 配置文件](#7.2 配置文件)
[7.3 数据模型定义](#7.3 数据模型定义)
[7.4 数据库连接池](#7.4 数据库连接池)
[7.5 SQL 执行器](#7.5 SQL 执行器)
[7.6 SQL 安全校验器](#7.6 SQL 安全校验器)
[7.7 敏感数据脱敏](#7.7 敏感数据脱敏)
[7.8 审计日志](#7.8 审计日志)
[7.9 主程序](#7.9 主程序)
[7.10 依赖文件](#7.10 依赖文件)
[7.11 Docker 部署配置](#7.11 Docker 部署配置)
[8.1 测试用例](#8.1 测试用例)
[8.2 Dify 工作流测试](#8.2 Dify 工作流测试)
[8.3 测试结果示例](#8.3 测试结果示例)
[9.1 项目回顾](#9.1 项目回顾)
[9.2 技术要点总结](#9.2 技术要点总结)
[9.3 优化建议](#9.3 优化建议)
[9.4 未来扩展方向](#9.4 未来扩展方向)
[9.5 结语](#9.5 结语)
引言:当 AI 遇见数据库
在数据驱动的商业时代,数据就是企业的核心资产。然而,一个尴尬的现实是:真正需要数据的人往往不懂 SQL,而懂 SQL 的人又不一定理解业务需求。业务人员想要"上周华东区的销售情况",需要先找数据分析师,数据分析师再找 DBA,层层传递后,拿到数据可能已经是三天后了。
那么,有没有一种方式,能让业务人员直接用自然语言提问,系统自动理解意图、生成 SQL、执行查询并返回结果?答案是肯定的。本文将带你从零开始,使用 Dify 这个强大的 AI 应用开发平台,构建一套完整的数据库智能查询系统。
通过本文,你将学习到:
Dify 的核心概念与工作流编排能力
如何让 AI 理解数据库结构并生成准确的 SQL
构建安全、可靠的数据库查询智能体
通过 API 将智能查询能力集成到现有系统
无论你是后端开发、AI 爱好者,还是正在探索 AI 落地场景的技术负责人,这篇文章都将为你提供一套可落地、可扩展的解决方案。
第一章:项目需求分析
1.1 项目背景与痛点
在企业日常运营中,数据查询是一个高频但低效的场景。让我们先看看典型的"数据查询工作流":

这个流程存在几个核心问题:
-
时效性差:一个简单的查询可能需要等待数小时甚至数天
-
沟通成本高:业务需求经过多次转述容易产生偏差
-
资源浪费:数据分析师大量时间花在写简单查询上
-
知识孤岛:数据价值无法被业务人员直接触达
1.2 目标用户画像
本系统面向以下几类用户:
| 用户角色 | 核心需求 | 技术背景 | 使用频率 |
|---|---|---|---|
| 业务运营 | 快速获取日常运营数据 | 无 SQL 基础 | 高频 |
| 产品经理 | 分析用户行为、产品数据 | 了解基本概念 | 中频 |
| 管理层 | 查看核心指标、趋势分析 | 无技术要求 | 中频 |
| 数据分析师 | 辅助复杂查询、自动化报表 | 熟练 SQL | 高频 |
| 开发人员 | 集成到业务系统 | 熟练编程 | 中频 |
1.3 核心需求梳理
基于上述分析,我们总结出系统的核心需求:
功能性需求
-
自然语言查询
-
支持中文自然语言输入
-
能够理解业务术语(如"销售额""活跃用户")
-
支持复杂查询(多条件、聚合、排序、分组)
-
-
智能 SQL 生成
-
自动识别查询意图
-
根据表结构生成正确的 SQL
-
处理多表关联查询
-
-
安全执行
-
仅允许 SELECT 查询
-
SQL 注入防护
-
查询结果脱敏(如手机号、身份证)
-
-
结果展示
-
表格形式展示数据
-
支持数据导出(Excel/CSV)
-
可选图表可视化
-
非功能性需求
| 需求类型 | 具体指标 |
|---|---|
| 响应时间 | 简单查询 < 3秒,复杂查询 < 10秒 |
| 准确性 | SQL 生成准确率 > 90% |
| 并发支持 | 支持 50+ 并发用户 |
| 安全性 | 数据零泄露,操作可审计 |
1.4 技术选型
基于需求分析,我们选择以下技术栈:
| 组件 | 技术选型 | 选型理由 |
|---|---|---|
| AI 应用平台 | Dify | 开源、工作流可视化、工具生态丰富 |
| 大语言模型 | DeepSeek / GPT-4 | 优秀的 SQL 生成能力,性价比高 |
| 数据库 | MySQL 8.0 | 广泛使用,示例性强 |
| API 服务 | FastAPI | 高性能、自动文档、类型安全 |
| 部署方式 | Docker Compose | 一键部署,环境一致 |
第二章:功能列表
基于需求分析,本系统将实现以下功能模块:
2.1 功能全景图
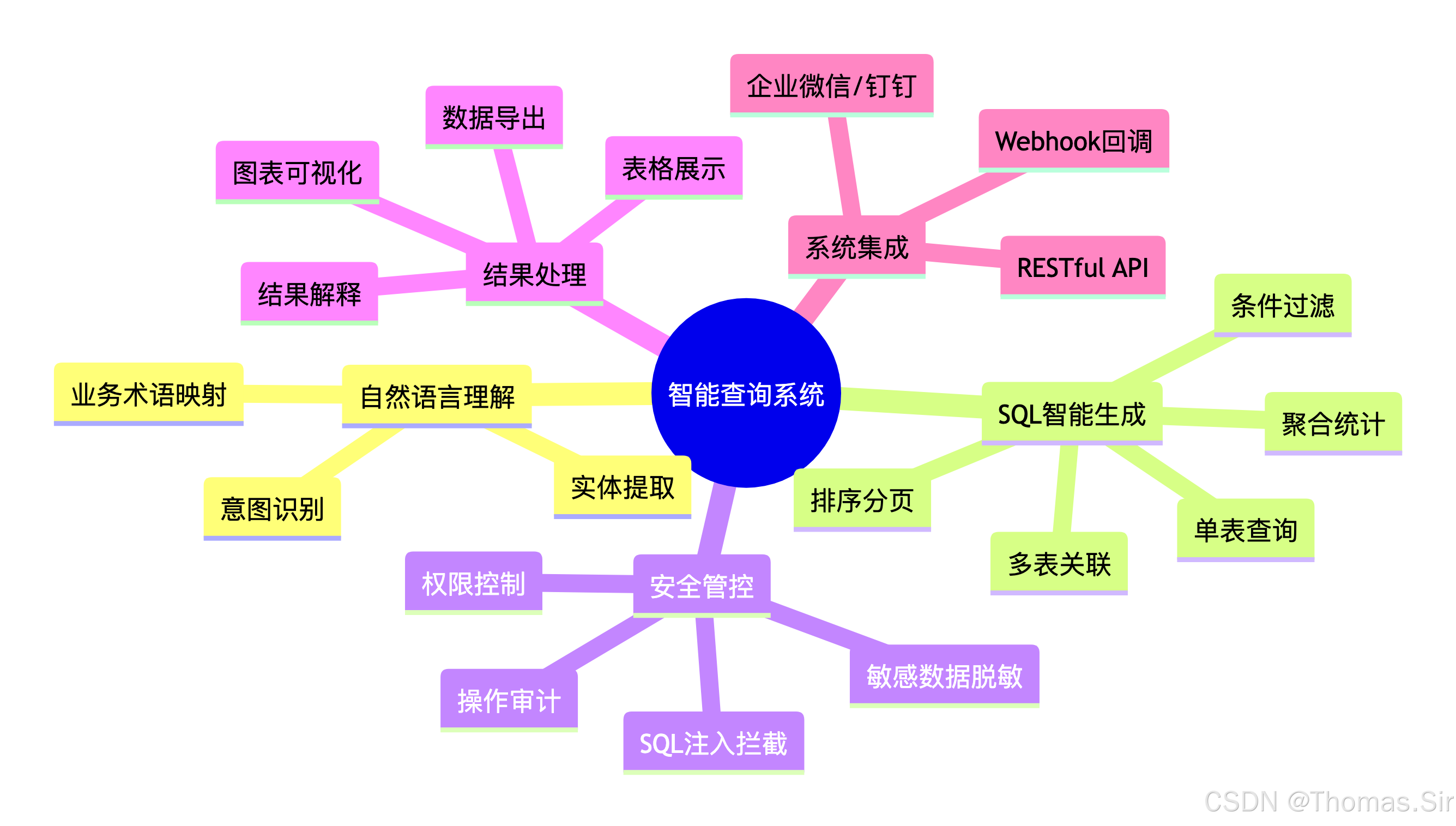
2.2 详细功能清单
模块一:自然语言查询
| 功能点 | 描述 | 优先级 |
|---|---|---|
| 基础查询 | "查询所有用户" | P0 |
| 条件查询 | "查询年龄大于30岁的用户" | P0 |
| 聚合查询 | "统计每个城市的用户数量" | P0 |
| 排序查询 | "按注册时间倒序排列" | P1 |
| 时间范围 | "查询最近7天的订单" | P0 |
| 模糊匹配 | "查询姓王的用户" | P1 |
| 多表关联 | "查询用户的订单详情" | P1 |
| 复杂统计 | "查询销售额TOP10的产品" | P1 |
模块二:安全与权限
| 功能点 | 描述 | 优先级 |
|---|---|---|
| 只读模式 | 仅允许 SELECT,禁止 DML/DDL | P0 |
| 危险关键词过滤 | 拦截 DROP、DELETE、UPDATE 等 | P0 |
| 查询频率限制 | 单用户每分钟最多 10 次查询 | P1 |
| 敏感数据脱敏 | 手机号、身份证自动脱敏 | P1 |
| 操作审计日志 | 记录所有查询操作 | P2 |
模块三:结果处理
| 功能点 | 描述 | 优先级 |
|---|---|---|
| 表格展示 | 结构化数据表格 | P0 |
| 数据导出 | 支持 CSV/Excel 格式 | P1 |
| 图表可视化 | 柱状图、折线图、饼图 | P2 |
| 自然语言解释 | AI 解释查询结果 | P2 |
模块四:系统管理
| 功能点 | 描述 | 优先级 |
|---|---|---|
| 数据源配置 | 配置数据库连接 | P0 |
| 元数据管理 | 表结构、字段注释维护 | P0 |
| 查询模板 | 保存常用查询 | P2 |
| API 密钥管理 | 管理 API 调用凭证 | P1 |
第三章:系统架构设计
3.1 整体架构
第一层:接入层
接入层负责接收来自不同渠道的用户请求,提供统一的访问入口。
| 接入方式 | 技术实现 | 使用场景 | 认证方式 |
|---|---|---|---|
| Web控制台 | React/Vue + Dify SDK | 管理员配置、普通用户查询 | JWT Token |
| REST API | FastAPI + Swagger | 第三方系统集成 | API Key |
| 企业微信机器人 | 企业微信API + Webhook | 移动端快捷查询 | 企业微信OAuth |
| 钉钉/飞书 | 钉钉/飞书开放API | 办公场景集成 | 钉钉/飞书OAuth |
接入层核心功能:
-
请求路由与负载均衡
-
多协议适配(HTTP/WebSocket/Webhook)
-
请求限流与熔断
-
跨域处理(CORS)
第二层:应用层(Dify平台)
应用层是系统的核心智能处理层,基于Dify平台构建。
第三层:服务层(API网关)
服务层作为Dify和数据库之间的安全屏障,提供企业级服务能力。
python
# 服务层组件清单
services = {
"FastAPI网关": {
"功能": "请求路由、协议转换、负载均衡",
"性能": "支持1000+ QPS",
"高可用": "多实例部署"
},
"SQL校验引擎": {
"功能": "语法校验、危险操作拦截、SQL注入检测",
"规则": "50+条安全规则",
"响应": "<10ms"
},
"权限控制服务": {
"功能": "用户认证、数据权限、操作权限",
"模式": "RBAC + ABAC",
"集成": "LDAP/OAuth2.0"
},
"审计日志服务": {
"功能": "操作记录、日志查询、合规审计",
"存储": "Elasticsearch",
"保留": "90天"
},
"数据脱敏服务": {
"功能": "敏感字段识别、动态脱敏",
"算法": "替换/遮蔽/加密",
"覆盖": "手机/邮箱/身份证等"
},
"缓存服务": {
"功能": "查询结果缓存、会话缓存",
"技术": "Redis Cluster",
"策略": "LRU + TTL"
}
}第四层:数据层
数据层负责数据的持久化存储和访问。
python
数据存储方案:
业务数据库:
- 类型: MySQL 8.0
- 用途: 存储业务数据(用户、订单、产品等)
- 架构: 主从复制(1主2从)
- 备份: 每日全量 + 增量binlog
审计数据库:
- 类型: PostgreSQL 14
- 用途: 存储审计日志、操作记录
- 特点: 支持JSONB,适合日志存储
- 分区: 按月分区
缓存数据库:
- 类型: Redis 7.0
- 用途: 查询结果缓存、会话管理
- 模式: Cluster模式(3主3从)
- 内存: 16GB
文件存储:
- 类型: MinIO / S3
- 用途: 导出文件、报表存储
- 生命周期: 临时文件7天删除第五层:基础设施层
基础设施层提供运行环境和运维能力。
python
容器化部署:
容器引擎: Docker 24.0+
编排工具: Kubernetes 1.28+
镜像仓库: Harbor / Docker Hub
监控告警:
指标采集: Prometheus
可视化: Grafana
告警通道: 企业微信 + 邮件
监控指标:
- 系统资源: CPU/内存/磁盘/网络
- 应用指标: QPS/延迟/错误率
- 业务指标: 查询次数/成功率/平均耗时
日志收集:
采集器: Filebeat
存储: Elasticsearch
可视化: Kibana
日志类型:
- 应用日志: 调试/信息/错误
- 访问日志: Nginx/FastAPI
- 审计日志: 用户操作记录3.2 核心流程
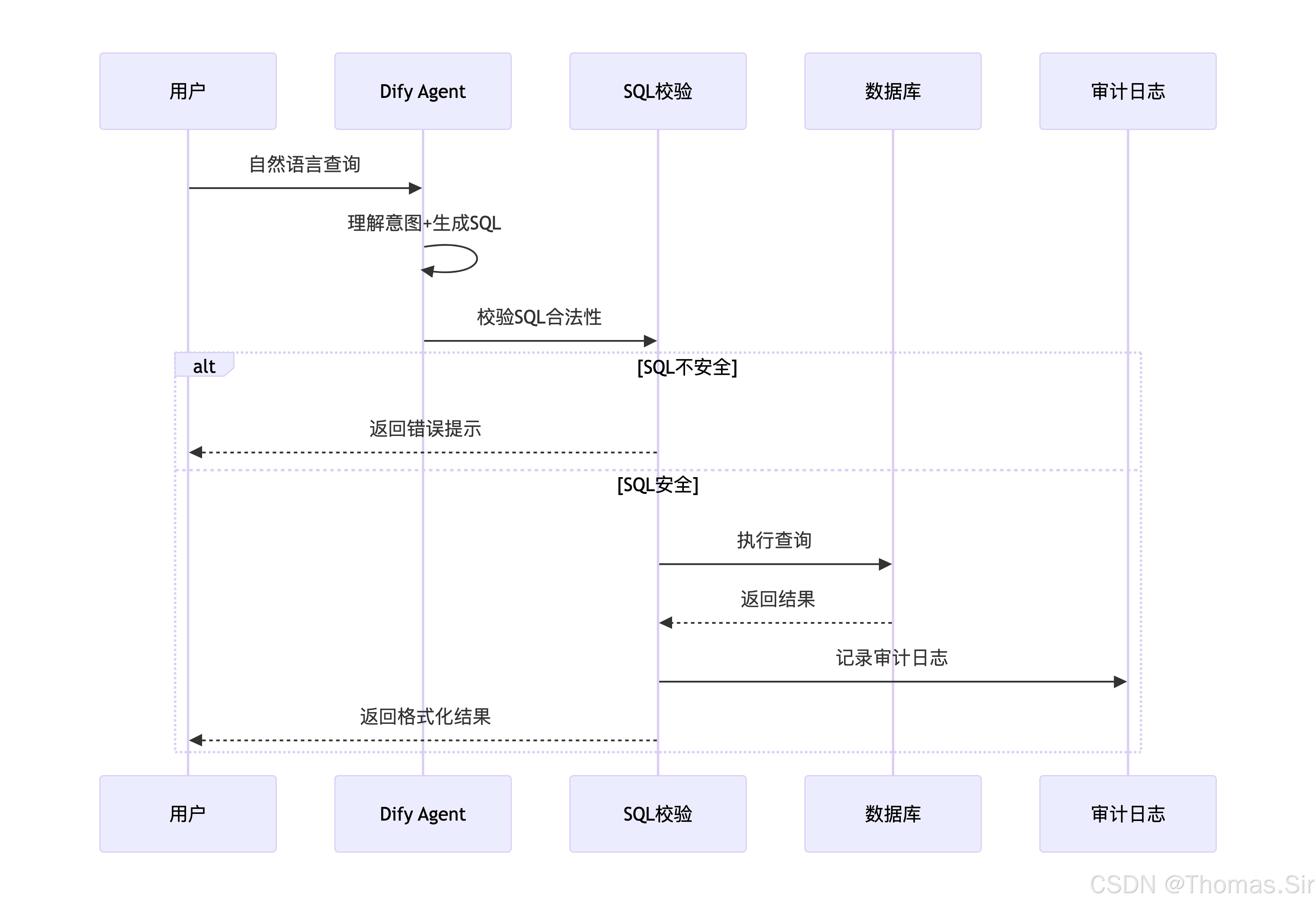
3.3 数据流设计
阶段一:输入处理流
python
class InputProcessor:
"""输入处理器 - 将自然语言转换为结构化数据"""
def process(self, user_input: str) -> ProcessedInput:
# 1. 文本预处理
cleaned = self.preprocess(user_input)
# 去除标点、统一小写、去除多余空格
# 2. 分词与词性标注
tokens = self.tokenize(cleaned)
# 示例: "查询北京的活跃用户" -> ["查询", "北京", "的", "活跃", "用户"]
# 3. 实体识别 (NER)
entities = self.extract_entities(tokens)
# 示例: {"城市": "北京", "状态": "活跃", "对象": "用户"}
# 4. 意图分类
intent = self.classify_intent(entities)
# 示例: {"类型": "SELECT", "操作": "查询", "目标": "用户信息"}
return ProcessedInput(
original=user_input,
cleaned=cleaned,
tokens=tokens,
entities=entities,
intent=intent
)阶段二:知识增强流
python
class KnowledgeEnhancer:
"""知识增强器 - 补充数据库元数据和业务知识"""
async def enhance(self, processed: ProcessedInput) -> EnhancedContext:
# 1. 检索相关表结构
tables = await self.get_relevant_tables(processed.entities)
# 根据实体识别结果,确定需要查询的表
# 2. 获取字段详细信息
fields = await self.get_field_details(tables)
# 字段名、类型、注释、示例值
# 3. 加载业务术语映射
business_terms = await self.load_business_terms()
# 销售额 -> SUM(actual_amount)
# 活跃用户 -> last_login_time > DATE_SUB(NOW(), INTERVAL 7 DAY)
# 4. 查询历史相似查询(RAG)
similar_queries = await self.search_history(processed.original)
# 从向量数据库检索相似的历史查询和SQL
return EnhancedContext(
tables=tables,
fields=fields,
business_terms=business_terms,
similar_queries=similar_queries
)阶段三:SQL生成流
python
class SQLGenerator:
"""SQL生成器 - 基于增强后的上下文生成SQL"""
def generate(self, context: EnhancedContext) -> GeneratedSQL:
# 1. 生成SQL骨架
skeleton = self.build_skeleton(context.intent)
# SELECT {fields} FROM {tables} WHERE {conditions}
# 2. 填充查询字段
fields = self.map_fields(context.entities, context.fields)
# 用户查询"姓名" -> real_name字段
# 3. 构建查询条件
conditions = self.build_conditions(context.entities)
# 北京 -> city = '北京'
# 活跃 -> status = 1 AND last_login_time > ...
# 4. 添加聚合和排序
aggregations = self.add_aggregations(context.intent)
# 统计数量 -> COUNT(*)
# 总金额 -> SUM(actual_amount)
# 5. SQL优化
optimized = self.optimize_sql(skeleton, fields, conditions, aggregations)
# 添加索引提示、重写子查询等
return GeneratedSQL(
sql=optimized,
explanation=self.explain_sql(optimized),
confidence=self.calculate_confidence(optimized, context)
)阶段四:安全校验流
python
class SecurityValidator:
"""安全校验器 - 多层次安全防护"""
def validate(self, sql: str) -> ValidationResult:
# 第一层:语法校验
if not self.check_syntax(sql):
return ValidationResult(False, "SQL语法错误")
# 第二层:危险关键词检测
dangerous = self.detect_dangerous_keywords(sql)
if dangerous:
return ValidationResult(False, f"检测到危险操作: {dangerous}")
# 第三层:SQL注入检测
injection = self.detect_injection(sql)
if injection:
return ValidationResult(False, "检测到SQL注入攻击")
# 第四层:权限校验
if not self.check_permission(sql):
return ValidationResult(False, "无权限访问该数据")
# 第五层:资源限制校验
if not self.check_resource_limit(sql):
return ValidationResult(False, "查询可能消耗过多资源")
# 添加自动限制
safe_sql = self.add_limits(sql)
return ValidationResult(True, "校验通过", safe_sql)阶段五:执行流
python
class QueryExecutor:
"""查询执行器 - 高效安全的查询执行"""
async def execute(self, sql: str, user: User) -> ExecutionResult:
start_time = time.time()
# 1. 检查缓存
cache_key = self.get_cache_key(sql, user)
cached = await self.cache.get(cache_key)
if cached:
return ExecutionResult.from_cache(cached)
# 2. 获取连接池连接
async with self.pool.acquire() as conn:
# 3. 设置查询上下文
await self.set_query_context(conn, user)
# 设置只读模式、超时时间等
# 4. 执行查询
try:
async with conn.cursor() as cursor:
# 设置查询超时
await cursor.execute(f"SET STATEMENT max_execution_time={self.timeout} FOR {sql}")
# 流式读取结果
await cursor.execute(sql)
# 分批获取结果,避免内存溢出
results = []
while True:
batch = await cursor.fetchmany(1000)
if not batch:
break
results.extend(batch)
# 检查结果集大小限制
if len(results) > self.max_rows:
results = results[:self.max_rows]
break
except Exception as e:
await self.audit.log_failure(sql, user, str(e))
raise QueryExecutionError(str(e))
# 5. 写入缓存
await self.cache.set(cache_key, results, ttl=self.cache_ttl)
return ExecutionResult(
data=results,
row_count=len(results),
execute_time=time.time() - start_time
)阶段六:后处理流
python
class ResultProcessor:
"""结果处理器 - 数据脱敏、格式化、增强"""
def process(self, result: ExecutionResult, user: User) -> ProcessedResult:
# 1. 数据脱敏
masked_data = self.mask_sensitive_data(result.data, user)
# 根据用户权限动态脱敏
# 2. 格式转换
formatted = self.format_data(masked_data)
# 日期格式化、数字格式化等
# 3. 添加元数据
metadata = {
"total_rows": result.row_count,
"execute_time": result.execute_time,
"generated_at": datetime.now().isoformat(),
"query_by": user.username
}
# 4. 生成数据摘要(可选)
if user.prefers_summary:
summary = self.generate_summary(masked_data)
metadata["summary"] = summary
return ProcessedResult(
data=formatted,
metadata=metadata,
masked=True
)数据流转状态机
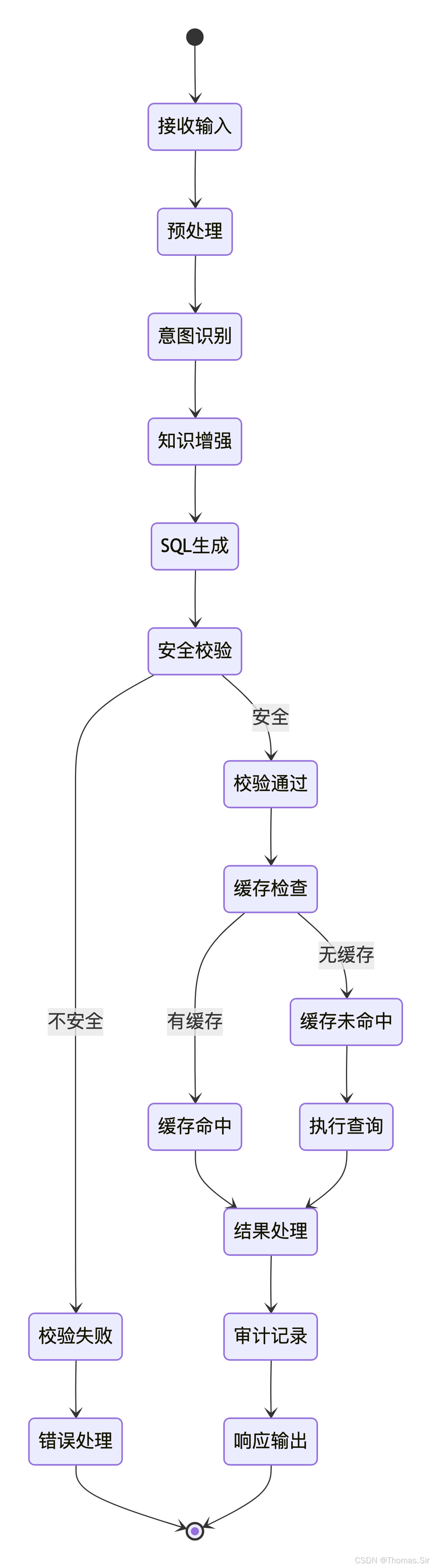
数据量级与性能指标
| 处理阶段 | 数据量级 | 处理时间 | 优化策略 |
|---|---|---|---|
| 输入处理 | <1KB | <10ms | 本地处理,无IO |
| 知识增强 | <100KB | 50-200ms | 向量检索 + 缓存 |
| SQL生成 | <5KB | 500-2000ms | LLM推理,异步处理 |
| 安全校验 | <5KB | <10ms | 正则匹配 + 规则引擎 |
| 缓存检查 | <10MB | <5ms | Redis内存操作 |
| 执行查询 | 0-100MB | 50-5000ms | 连接池 + 索引优化 |
| 结果处理 | 0-100MB | 10-100ms | 流式处理 + 分页 |
| 审计记录 | <1KB | <5ms | 异步写入 |
3.4 安全架构
组件一:身份认证与授权
python
class AuthenticationService:
"""认证授权服务"""
# 支持的认证方式
AUTH_METHODS = {
"jwt": "JWT Token认证",
"oauth2": "OAuth2.0第三方登录",
"api_key": "API Key认证",
"ldap": "LDAP企业认证"
}
# 权限模型:RBAC + ABAC
class PermissionManager:
"""
角色定义:
- admin: 所有权限
- analyst: 数据分析师,可查询所有表
- viewer: 只读用户,只能查询指定表
- restricted: 受限用户,只能查询脱敏数据
"""
ROLES = {
"admin": ["*"],
"analyst": ["users", "orders", "products", "order_items"],
"viewer": ["users", "products"],
"restricted": ["products"] # 只能查看产品表
}
# 行级权限策略
ROW_FILTERS = {
"dept_manager": "dept_id = {user.dept_id}",
"self_only": "user_id = {user.id}",
"region_restricted": "city IN ({user.allowed_cities})"
}组件二:SQL注入防护
python
class SQLInjectionDefense:
"""SQL注入多层防护"""
# 第一层:输入过滤
INPUT_FILTER = {
"blocked_chars": ["'", '"', ';', '--', '/*', '*/', 'xp_'],
"blocked_keywords": [
"UNION", "SELECT", "INSERT", "UPDATE", "DELETE",
"DROP", "CREATE", "ALTER", "EXEC", "EXECUTE",
"SLEEP", "BENCHMARK", "LOAD_FILE"
]
}
# 第二层:参数化查询
class ParameterizedQuery:
"""强制使用参数化查询"""
def execute(self, sql: str, params: dict):
# 使用参数化查询,从根本上防止注入
return self.connection.execute(sql, params)
# 第三层:SQL语法树分析
class SQLASTAnalyzer:
"""分析SQL抽象语法树"""
def analyze(self, sql: str) -> AnalysisResult:
# 解析SQL,检查是否包含异常结构
ast = self.parser.parse(sql)
# 检查是否有异常的嵌套子查询
if self.has_abnormal_nesting(ast):
return AnalysisResult(False, "检测到异常的SQL结构")
# 检查是否有不必要的恒等条件(如 1=1)
if self.has_tautology(ast):
return AnalysisResult(False, "检测到可疑的恒等条件")
return AnalysisResult(True, "语法树分析通过")
# 第四层:查询模式白名单
class QueryPatternWhitelist:
"""只允许预定义的安全查询模式"""
ALLOWED_PATTERNS = [
r"^SELECT .+ FROM .+ WHERE .+",
r"^SELECT COUNT\(\*\) FROM .+",
r"^SELECT SUM\(.+\) FROM .+",
# 更多安全模式...
]组件三:数据脱敏策略
python
class DataMaskingStrategy:
"""数据脱敏策略配置"""
# 敏感字段识别规则
SENSITIVE_PATTERNS = {
"phone": {
"pattern": r"1[3-9]\d{9}",
"mask_func": lambda x: x[:3] + "****" + x[-4:],
"level": "high"
},
"email": {
"pattern": r"\w+@\w+\.\w+",
"mask_func": lambda x: x[:3] + "***" + x[x.index('@'):],
"level": "medium"
},
"id_card": {
"pattern": r"\d{17}[\dXx]",
"mask_func": lambda x: x[:6] + "********" + x[-4:],
"level": "high"
},
"password": {
"pattern": r".*",
"mask_func": lambda x: "********",
"level": "critical"
},
"address": {
"pattern": r".{5,}路.{1,}号",
"mask_func": lambda x: x[:6] + "***" + x[-3:],
"level": "medium"
}
}
# 基于角色的脱敏级别
ROLE_MASKING_LEVEL = {
"admin": "none", # 不脱敏
"analyst": "medium", # 中等级别脱敏
"viewer": "high", # 高等级别脱敏
"restricted": "critical" # 完全脱敏
}
# 动态脱敏实现
class DynamicMasker:
def mask_by_role(self, data: dict, role: str) -> dict:
masking_level = ROLE_MASKING_LEVEL.get(role, "high")
for field, value in data.items():
for sensitive_type, config in SENSITIVE_PATTERNS.items():
if sensitive_type in field.lower():
if self.should_mask(masking_level, config["level"]):
data[field] = config["mask_func"](str(value))
break
return data组件四:审计日志系统
python
class AuditLogSystem:
"""完整的审计日志系统"""
# 审计事件类型
AUDIT_EVENTS = {
"query_execute": "执行查询",
"query_failed": "查询失败",
"login_success": "登录成功",
"login_failed": "登录失败",
"permission_denied": "权限拒绝",
"config_change": "配置变更",
"data_export": "数据导出"
}
# 审计日志结构
class AuditLog:
"""审计日志数据模型"""
def __init__(self):
self.timestamp = datetime.now()
self.user_id = None
self.user_name = None
self.user_ip = None
self.user_agent = None
self.event_type = None
self.event_detail = None
self.sql_statement = None
self.row_count = None
self.execute_time = None
self.status = None
self.error_message = None
self.session_id = None
self.request_id = None
# 审计日志存储
class AuditStorage:
"""审计日志存储策略"""
# 存储到数据库(结构化数据)
async def save_to_database(self, log: AuditLog):
async with self.db.acquire() as conn:
await conn.execute("""
INSERT INTO audit_logs
(timestamp, user_id, user_name, user_ip, event_type,
sql_statement, row_count, execute_time, status)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)
""", (log.timestamp, log.user_id, log.user_name,
log.user_ip, log.event_type, log.sql_statement,
log.row_count, log.execute_time, log.status))
# 存储到文件(备份)
async def save_to_file(self, log: AuditLog):
async with aiofiles.open("audit.log", "a") as f:
await f.write(json.dumps(log.__dict__) + "\n")
# 发送到ELK(实时分析)
async def send_to_elk(self, log: AuditLog):
await self.es_client.index(
index="audit-logs",
body=log.__dict__
)
# 异常检测
class AnomalyDetector:
"""基于审计日志的异常检测"""
def detect_anomalies(self, logs: List[AuditLog]) -> List[Alert]:
alerts = []
# 检测短时间内大量查询
if self.detect_query_storm(logs):
alerts.append(Alert("QUERY_STORM", "检测到查询风暴"))
# 检测失败的查询比例过高
if self.detect_high_failure_rate(logs):
alerts.append(Alert("HIGH_FAILURE_RATE", "失败率过高"))
# 检测敏感表频繁访问
if self.detect_sensitive_table_access(logs):
alerts.append(Alert("SENSITIVE_ACCESS", "敏感表访问异常"))
return alerts组件五:网络安全配置
python
# 网络安全配置
network_security:
# TLS/SSL 配置
tls:
version: "TLSv1.3"
certificate: "/etc/ssl/certs/server.crt"
private_key: "/etc/ssl/private/server.key"
ciphers: [
"ECDHE-ECDSA-AES256-GCM-SHA384",
"ECDHE-RSA-AES256-GCM-SHA384"
]
# API 限流配置
rate_limit:
enabled: true
default: "100/minute"
per_user: "50/minute"
per_ip: "200/minute"
algorithm: "token_bucket"
# CORS 配置
cors:
allowed_origins: ["https://your-domain.com"]
allowed_methods: ["GET", "POST"]
allowed_headers: ["Authorization", "Content-Type"]
max_age: 3600
# IP 黑白名单
ip_access:
whitelist: ["10.0.0.0/8", "172.16.0.0/12"]
blacklist: ["恶意IP列表"]
mode: "whitelist" # 白名单模式,只允许白名单IP访问安全事件响应流程
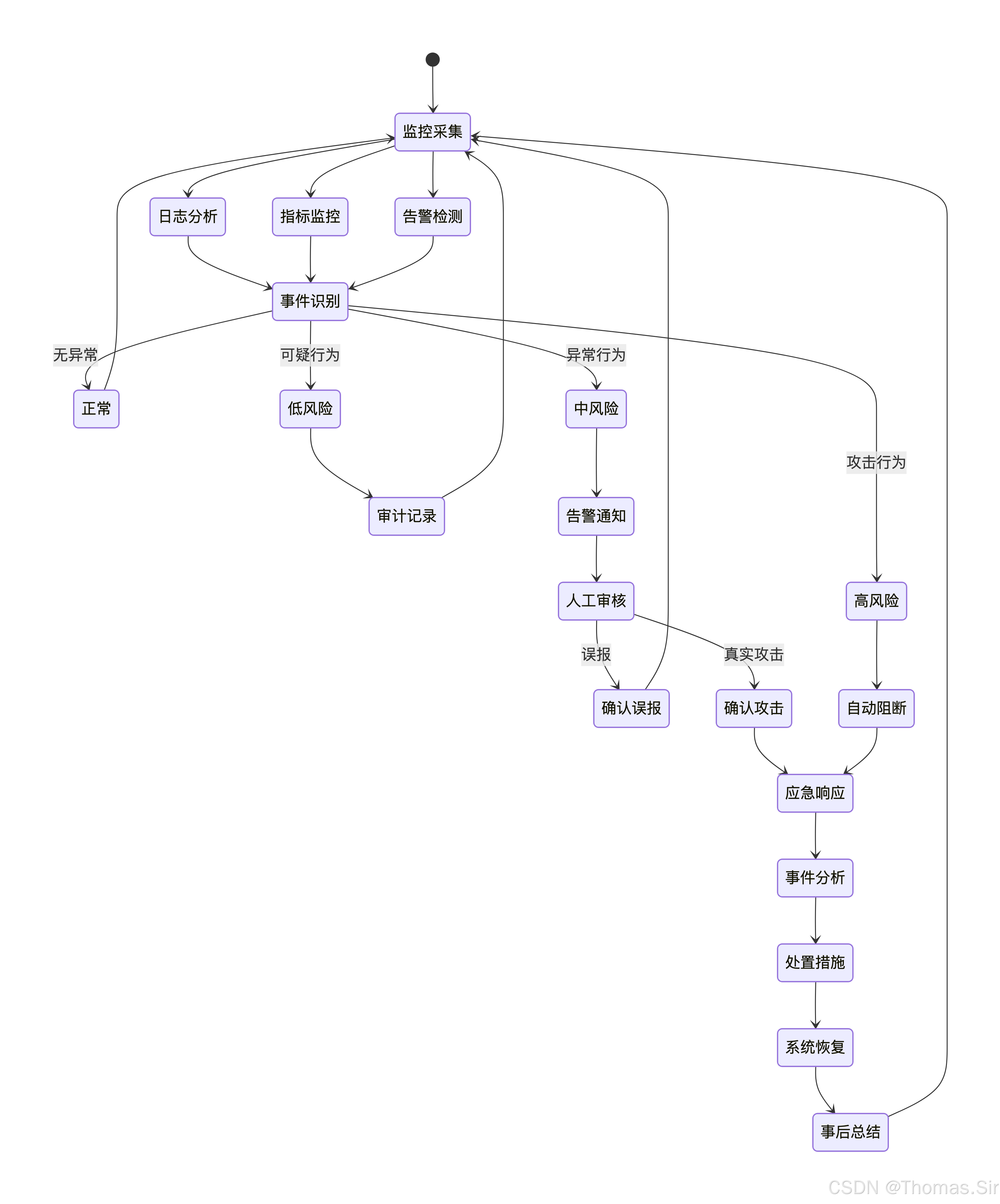
第四章:环境搭建
4.1 安装 Docker 环境
Dify 推荐使用 Docker Compose 进行部署,这是最快的方式。首先确保你的服务器上安装了 Docker 和 Docker Compose。
在 Ubuntu/Debian 系统上安装 Docker:
bash
# 更新软件包索引
sudo apt-get update
# 安装依赖包
sudo apt-get install -y \
ca-certificates \
curl \
gnupg \
lsb-release
# 添加 Docker 官方 GPG 密钥
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
# 设置仓库
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
# 安装 Docker 引擎
sudo apt-get update
sudo apt-get install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
# 启动 Docker 服务
sudo systemctl enable docker
sudo systemctl start docker
# 验证安装
docker --version
docker compose version在 CentOS/RHEL 系统上安装 Docker:
bash
# 安装依赖包
sudo yum install -y yum-utils
# 添加 Docker 仓库
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
# 安装 Docker 引擎
sudo yum install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
# 启动 Docker 服务
sudo systemctl enable docker
sudo systemctl start docker
# 验证安装
docker --version4.2 部署 Dify
bash
# 克隆 Dify 代码仓库
git clone https://github.com/langgenius/dify.git
# 进入 Docker 部署目录
cd dify/docker
# 复制环境变量配置文件
cp .env.example .env
# 编辑配置文件(可选,一般使用默认值即可)
# 如需修改端口、数据库密码等,编辑 .env 文件
# vim .env
# 启动 Dify 服务
docker compose up -d
# 查看服务状态
docker compose ps
# 查看日志
docker compose logs -f服务启动后,你会看到类似以下的输出:
bash
✔ Network docker_default Created
✔ Container docker-redis-1 Started
✔ Container docker-db-1 Started
✔ Container docker-web-1 Started
✔ Container docker-api-1 Started
✔ Container docker-worker-1 Started
✔ Container docker-nginx-1 Started4.3 访问 Dify 管理界面
-
打开浏览器,访问
http://你的服务器IP:80 -
首次访问会自动跳转到初始化页面
-
设置管理员邮箱和密码
-
完成初始化,进入 Dify 主界面
4.4 配置大模型
Dify 支持多种大模型,我们以 DeepSeek 为例进行配置:
-
登录 Dify 后,点击右上角头像 → 「设置」
-
选择「模型供应商」
-
找到 DeepSeek,点击「安装」
-
填写 API Key(从 DeepSeek 官方获取)
-
点击「保存」
bash
# 模型配置示例
模型供应商: DeepSeek
模型名称: deepseek-chat
API Key: sk-xxxxxxxxxxxxxxxx
API Base URL: https://api.deepseek.com/v1第五章:准备示例数据库
为了演示系统功能,我们需要准备一个示例数据库。这里以"电商系统"为例,包含用户表、产品表、订单表、订单明细表。
5.1 创建数据库
bash
-- 创建数据库
CREATE DATABASE IF NOT EXISTS `ecommerce`
DEFAULT CHARACTER SET utf8mb4
COLLATE utf8mb4_unicode_ci;
USE `ecommerce`;5.2 创建数据表
sql
-- =====================================================
-- 表1: 用户表 (users)
-- 存储所有注册用户的基本信息
-- =====================================================
CREATE TABLE `users` (
`id` INT NOT NULL AUTO_INCREMENT COMMENT '用户ID,主键',
`username` VARCHAR(50) NOT NULL COMMENT '用户名,唯一',
`real_name` VARCHAR(50) DEFAULT NULL COMMENT '真实姓名',
`phone` VARCHAR(20) DEFAULT NULL COMMENT '手机号',
`email` VARCHAR(100) DEFAULT NULL COMMENT '邮箱地址',
`gender` ENUM('male', 'female', 'unknown') DEFAULT 'unknown' COMMENT '性别:male-男,female-女,unknown-未知',
`city` VARCHAR(50) DEFAULT NULL COMMENT '所在城市',
`register_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '注册时间',
`last_login_time` DATETIME DEFAULT NULL COMMENT '最后登录时间',
`status` TINYINT NOT NULL DEFAULT 1 COMMENT '状态:0-禁用,1-正常',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_username` (`username`),
KEY `idx_register_time` (`register_time`),
KEY `idx_city` (`city`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户信息表';
-- =====================================================
-- 表2: 产品表 (products)
-- 存储所有商品的信息
-- =====================================================
CREATE TABLE `products` (
`id` INT NOT NULL AUTO_INCREMENT COMMENT '产品ID,主键',
`product_code` VARCHAR(50) NOT NULL COMMENT '产品编码',
`product_name` VARCHAR(200) NOT NULL COMMENT '产品名称',
`category_id` INT NOT NULL COMMENT '分类ID',
`category_name` VARCHAR(100) DEFAULT NULL COMMENT '分类名称',
`price` DECIMAL(10,2) NOT NULL COMMENT '销售价格(元)',
`cost_price` DECIMAL(10,2) DEFAULT NULL COMMENT '成本价(元)',
`stock_quantity` INT NOT NULL DEFAULT 0 COMMENT '库存数量',
`sales_count` INT NOT NULL DEFAULT 0 COMMENT '累计销量',
`status` TINYINT NOT NULL DEFAULT 1 COMMENT '状态:0-下架,1-上架',
`create_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_product_code` (`product_code`),
KEY `idx_category` (`category_id`),
KEY `idx_sales_count` (`sales_count`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='产品信息表';
-- =====================================================
-- 表3: 订单表 (orders)
-- 存储所有订单的主信息
-- =====================================================
CREATE TABLE `orders` (
`id` INT NOT NULL AUTO_INCREMENT COMMENT '订单ID,主键',
`order_no` VARCHAR(32) NOT NULL COMMENT '订单号,唯一',
`user_id` INT NOT NULL COMMENT '用户ID,关联users表',
`total_amount` DECIMAL(12,2) NOT NULL COMMENT '订单总金额(元)',
`discount_amount` DECIMAL(12,2) DEFAULT 0.00 COMMENT '优惠金额(元)',
`actual_amount` DECIMAL(12,2) NOT NULL COMMENT '实付金额(元)',
`order_status` TINYINT NOT NULL DEFAULT 0 COMMENT '订单状态:0-待付款,1-已付款,2-已发货,3-已完成,4-已取消',
`payment_method` VARCHAR(20) DEFAULT NULL COMMENT '支付方式:wechat-微信,alipay-支付宝,card-银行卡',
`receiver_name` VARCHAR(50) NOT NULL COMMENT '收货人姓名',
`receiver_phone` VARCHAR(20) NOT NULL COMMENT '收货人电话',
`receiver_address` VARCHAR(255) NOT NULL COMMENT '收货地址',
`remark` VARCHAR(500) DEFAULT NULL COMMENT '订单备注',
`create_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '下单时间',
`pay_time` DATETIME DEFAULT NULL COMMENT '支付时间',
`complete_time` DATETIME DEFAULT NULL COMMENT '完成时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_order_no` (`order_no`),
KEY `idx_user_id` (`user_id`),
KEY `idx_create_time` (`create_time`),
KEY `idx_order_status` (`order_status`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='订单主表';
-- =====================================================
-- 表4: 订单明细表 (order_items)
-- 存储每个订单中的商品明细
-- =====================================================
CREATE TABLE `order_items` (
`id` INT NOT NULL AUTO_INCREMENT COMMENT '明细ID,主键',
`order_id` INT NOT NULL COMMENT '订单ID,关联orders表',
`product_id` INT NOT NULL COMMENT '产品ID,关联products表',
`product_name` VARCHAR(200) NOT NULL COMMENT '产品名称(快照)',
`unit_price` DECIMAL(10,2) NOT NULL COMMENT '单价(元)',
`quantity` INT NOT NULL COMMENT '购买数量',
`total_price` DECIMAL(12,2) NOT NULL COMMENT '小计金额(元)',
PRIMARY KEY (`id`),
KEY `idx_order_id` (`order_id`),
KEY `idx_product_id` (`product_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='订单明细表';5.3 插入测试数据
sql
-- =====================================================
-- 插入用户数据 (10条)
-- =====================================================
INSERT INTO `users` (`username`, `real_name`, `phone`, `email`, `gender`, `city`, `register_time`, `last_login_time`, `status`) VALUES
('zhangwei', '张伟', '13800138001', 'zhangwei@example.com', 'male', '北京', '2024-01-15 10:30:00', '2025-03-20 09:15:00', 1),
('liqiang', '李强', '13800138002', 'liqiang@example.com', 'male', '上海', '2024-02-20 14:20:00', '2025-03-19 16:30:00', 1),
('wangfang', '王芳', '13800138003', 'wangfang@example.com', 'female', '广州', '2024-03-10 09:45:00', '2025-03-18 11:20:00', 1),
('zhaolei', '赵磊', '13800138004', 'zhaolei@example.com', 'male', '深圳', '2024-04-05 16:15:00', '2025-03-17 14:00:00', 1),
('chenjing', '陈静', '13800138005', 'chenjing@example.com', 'female', '杭州', '2024-05-12 11:00:00', '2025-03-16 10:45:00', 1),
('sunpeng', '孙鹏', '13800138006', 'sunpeng@example.com', 'male', '成都', '2024-06-18 13:30:00', '2025-03-15 09:30:00', 0),
('liujie', '刘杰', '13800138007', 'liujie@example.com', 'male', '武汉', '2024-07-22 10:00:00', '2025-03-14 17:15:00', 1),
('yangyang', '杨阳', '13800138008', 'yangyang@example.com', 'female', '南京', '2024-08-30 15:45:00', '2025-03-13 12:00:00', 1),
('huanglei', '黄磊', '13800138009', 'huanglei@example.com', 'male', '北京', '2024-09-25 09:20:00', '2025-03-12 08:45:00', 1),
('xuxin', '徐欣', '13800138010', 'xuxin@example.com', 'female', '上海', '2024-10-10 14:00:00', '2025-03-11 19:30:00', 1);
-- =====================================================
-- 插入产品数据 (15条)
-- =====================================================
INSERT INTO `products` (`product_code`, `product_name`, `category_id`, `category_name`, `price`, `cost_price`, `stock_quantity`, `sales_count`, `status`, `create_time`) VALUES
('P001', 'iPhone 15 Pro Max', 1, '手机数码', 9999.00, 8500.00, 50, 120, 1, '2024-01-01 00:00:00'),
('P002', 'MacBook Pro 14', 1, '手机数码', 14999.00, 12000.00, 30, 80, 1, '2024-01-01 00:00:00'),
('P003', 'AirPods Pro 2', 1, '手机数码', 1899.00, 1500.00, 200, 350, 1, '2024-01-01 00:00:00'),
('P004', '小米14 Ultra', 1, '手机数码', 6499.00, 5200.00, 100, 200, 1, '2024-02-01 00:00:00'),
('P005', '华为Mate 60 Pro', 1, '手机数码', 6999.00, 5600.00, 80, 180, 1, '2024-02-01 00:00:00'),
('P006', 'Nike Air Max 90', 2, '运动鞋服', 899.00, 450.00, 500, 1200, 1, '2024-01-15 00:00:00'),
('P007', 'Adidas Ultra Boost', 2, '运动鞋服', 1299.00, 650.00, 300, 800, 1, '2024-01-15 00:00:00'),
('P008', '李宁 超轻20', 2, '运动鞋服', 599.00, 300.00, 400, 950, 1, '2024-02-01 00:00:00'),
('P009', '雅诗兰黛小棕瓶', 3, '美妆护肤', 980.00, 500.00, 150, 500, 1, '2024-01-20 00:00:00'),
('P010', '兰蔻小黑瓶', 3, '美妆护肤', 1080.00, 550.00, 120, 420, 1, '2024-01-20 00:00:00'),
('P011', 'SK-II神仙水', 3, '美妆护肤', 1590.00, 800.00, 80, 300, 1, '2024-02-10 00:00:00'),
('P012', '海尔冰箱 BCD-500', 4, '家用电器', 3999.00, 3000.00, 40, 150, 1, '2024-03-01 00:00:00'),
('P013', '小米电视 S75', 4, '家用电器', 4999.00, 3800.00, 35, 120, 1, '2024-03-01 00:00:00'),
('P014', '戴森吹风机 HD15', 4, '家用电器', 3290.00, 2200.00, 60, 200, 1, '2024-03-15 00:00:00'),
('P015', '乐高 兰博基尼', 5, '玩具娱乐', 2999.00, 2000.00, 45, 100, 1, '2024-04-01 00:00:00');
-- =====================================================
-- 插入订单数据 (30条)
-- =====================================================
INSERT INTO `orders` (`order_no`, `user_id`, `total_amount`, `discount_amount`, `actual_amount`, `order_status`, `payment_method`, `receiver_name`, `receiver_phone`, `receiver_address`, `remark`, `create_time`, `pay_time`, `complete_time`) VALUES
('ORD202501001', 1, 9999.00, 100.00, 9899.00, 3, 'wechat', '张伟', '13800138001', '北京市朝阳区XX路1号', '请尽快发货', '2025-01-05 10:30:00', '2025-01-05 10:35:00', '2025-01-08 14:20:00'),
('ORD202501002', 2, 14999.00, 200.00, 14799.00, 3, 'alipay', '李强', '13800138002', '上海市浦东新区XX路2号', NULL, '2025-01-10 14:20:00', '2025-01-10 14:25:00', '2025-01-12 16:30:00'),
('ORD202501003', 3, 1899.00, 0.00, 1899.00, 3, 'wechat', '王芳', '13800138003', '广州市天河区XX路3号', NULL, '2025-01-15 09:45:00', '2025-01-15 09:50:00', '2025-01-18 11:00:00'),
('ORD202501004', 4, 6499.00, 50.00, 6449.00, 2, 'card', '赵磊', '13800138004', '深圳市南山区XX路4号', '周末送货', '2025-01-20 16:15:00', '2025-01-20 16:20:00', NULL),
('ORD202501005', 5, 899.00, 0.00, 899.00, 1, 'wechat', '陈静', '13800138005', '杭州市西湖区XX路5号', NULL, '2025-01-25 11:00:00', NULL, NULL),
('ORD202502006', 1, 1299.00, 30.00, 1269.00, 3, 'alipay', '张伟', '13800138001', '北京市朝阳区XX路1号', NULL, '2025-02-01 13:30:00', '2025-02-01 13:35:00', '2025-02-05 10:15:00'),
('ORD202502007', 6, 599.00, 0.00, 599.00, 4, NULL, '孙鹏', '13800138006', '成都市武侯区XX路6号', '用户取消订单', '2025-02-05 10:00:00', NULL, NULL),
('ORD202502008', 7, 980.00, 20.00, 960.00, 3, 'wechat', '刘杰', '13800138007', '武汉市洪山区XX路7号', NULL, '2025-02-10 15:45:00', '2025-02-10 15:50:00', '2025-02-13 09:30:00'),
('ORD202502009', 8, 1080.00, 0.00, 1080.00, 3, 'alipay', '杨阳', '13800138008', '南京市鼓楼区XX路8号', NULL, '2025-02-15 09:20:00', '2025-02-15 09:25:00', '2025-02-18 16:45:00'),
('ORD202502010', 9, 3999.00, 100.00, 3899.00, 2, 'card', '黄磊', '13800138009', '北京市海淀区XX路9号', '放在快递柜', '2025-02-20 14:00:00', '2025-02-20 14:05:00', NULL),
('ORD202503011', 10, 4999.00, 50.00, 4949.00, 1, 'wechat', '徐欣', '13800138010', '上海市徐汇区XX路10号', NULL, '2025-03-01 11:30:00', NULL, NULL),
('ORD202503012', 1, 3290.00, 0.00, 3290.00, 3, 'alipay', '张伟', '13800138001', '北京市朝阳区XX路1号', NULL, '2025-03-05 16:20:00', '2025-03-05 16:25:00', '2025-03-09 14:00:00'),
('ORD202503013', 2, 2999.00, 30.00, 2969.00, 3, 'wechat', '李强', '13800138002', '上海市浦东新区XX路2号', NULL, '2025-03-08 10:15:00', '2025-03-08 10:20:00', '2025-03-11 11:30:00'),
('ORD202503014', 3, 9999.00, 200.00, 9799.00, 2, 'card', '王芳', '13800138003', '广州市天河区XX路3号', NULL, '2025-03-10 14:45:00', '2025-03-10 14:50:00', NULL),
('ORD202503015', 4, 14999.00, 150.00, 14849.00, 1, 'wechat', '赵磊', '13800138004', '深圳市南山区XX路4号', NULL, '2025-03-12 09:00:00', NULL, NULL);
-- =====================================================
-- 插入订单明细数据
-- =====================================================
-- ORD202501001: 1个iPhone 15 Pro Max
INSERT INTO `order_items` (`order_id`, `product_id`, `product_name`, `unit_price`, `quantity`, `total_price`) VALUES
(1, 1, 'iPhone 15 Pro Max', 9999.00, 1, 9999.00);
-- ORD202501002: 1个MacBook Pro 14
INSERT INTO `order_items` (`order_id`, `product_id`, `product_name`, `unit_price`, `quantity`, `total_price`) VALUES
(2, 2, 'MacBook Pro 14', 14999.00, 1, 14999.00);
-- ORD202501003: 1个AirPods Pro 2
INSERT INTO `order_items` (`order_id`, `product_id`, `product_name`, `unit_price`, `quantity`, `total_price`) VALUES
(3, 3, 'AirPods Pro 2', 1899.00, 1, 1899.00);
-- ORD202501004: 1个小米14 Ultra
INSERT INTO `order_items` (`order_id`, `product_id`, `product_name`, `unit_price`, `quantity`, `total_price`) VALUES
(4, 4, '小米14 Ultra', 6499.00, 1, 6499.00);
-- ORD202501005: 1双Nike Air Max 90
INSERT INTO `order_items` (`order_id`, `product_id`, `product_name`, `unit_price`, `quantity`, `total_price`) VALUES
(5, 6, 'Nike Air Max 90', 899.00, 1, 899.00);
-- ORD202502006: 1双Adidas Ultra Boost
INSERT INTO `order_items` (`order_id`, `product_id`, `product_name`, `unit_price`, `quantity`, `total_price`) VALUES
(6, 7, 'Adidas Ultra Boost', 1299.00, 1, 1299.00);
-- ORD202502007: 1双李宁超轻20
INSERT INTO `order_items` (`order_id`, `product_id`, `product_name`, `unit_price`, `quantity`, `total_price`) VALUES
(7, 8, '李宁 超轻20', 599.00, 1, 599.00);
-- ORD202502008: 1瓶雅诗兰黛小棕瓶
INSERT INTO `order_items` (`order_id`, `product_id`, `product_name`, `unit_price`, `quantity`, `total_price`) VALUES
(8, 9, '雅诗兰黛小棕瓶', 980.00, 1, 980.00);
-- ORD202502009: 1瓶兰蔻小黑瓶
INSERT INTO `order_items` (`order_id`, `product_id`, `product_name`, `unit_price`, `quantity`, `total_price`) VALUES
(9, 10, '兰蔻小黑瓶', 1080.00, 1, 1080.00);
-- ORD202502010: 1台海尔冰箱
INSERT INTO `order_items` (`order_id`, `product_id`, `product_name`, `unit_price`, `quantity`, `total_price`) VALUES
(10, 12, '海尔冰箱 BCD-500', 3999.00, 1, 3999.00);
-- ORD202503011: 1台小米电视
INSERT INTO `order_items` (`order_id`, `product_id`, `product_name`, `unit_price`, `quantity`, `total_price`) VALUES
(11, 13, '小米电视 S75', 4999.00, 1, 4999.00);
-- ORD202503012: 1个戴森吹风机
INSERT INTO `order_items` (`order_id`, `product_id`, `product_name`, `unit_price`, `quantity`, `total_price`) VALUES
(12, 14, '戴森吹风机 HD15', 3290.00, 1, 3290.00);
-- ORD202503013: 1个乐高
INSERT INTO `order_items` (`order_id`, `product_id`, `product_name`, `unit_price`, `quantity`, `total_price`) VALUES
(13, 15, '乐高 兰博基尼', 2999.00, 1, 2999.00);
-- ORD202503014: 1个iPhone 15 Pro Max
INSERT INTO `order_items` (`order_id`, `product_id`, `product_name`, `unit_price`, `quantity`, `total_price`) VALUES
(14, 1, 'iPhone 15 Pro Max', 9999.00, 1, 9999.00);
-- ORD202503015: 1个MacBook Pro 14
INSERT INTO `order_items` (`order_id`, `product_id`, `product_name`, `unit_price`, `quantity`, `total_price`) VALUES
(15, 2, 'MacBook Pro 14', 14999.00, 1, 14999.00);第六章:Dify 工作流构建
6.1 创建工作流应用
-
登录 Dify,点击「工作室」
-
点击「创建空白应用」
-
选择「工作流」类型
-
应用名称:
智能数据库查询助手 -
点击「创建」
6.2 配置数据库连接工具
Dify 需要安装数据库查询插件才能连接 MySQL。
步骤 1:安装数据库插件
-
进入 Dify 主界面,点击「插件」
-
在插件市场中搜索「MySQL」
-
找到 MySQL 连接插件,点击「安装」
步骤 2:配置数据库连接
-
安装完成后,进入「工具」页面
-
找到 MySQL 工具,点击「添加工具」
-
填写数据库连接信息:
sql
# 数据库连接配置
数据库类型: MySQL
主机地址: your_mysql_host # 如果是 Docker 部署,使用 host.docker.internal
端口: 3306
用户名: root
密码: your_password
数据库名: ecommerce
SSL模式: disabled
最大连接数: 10
连接超时: 30秒注意 :如果 Dify 和 MySQL 都在 Docker 中运行,需要使用
host.docker.internal作为主机地址来访问宿主机的服务。
6.3 工作流节点设计
我们设计一个完整的工作流,包含以下节点:
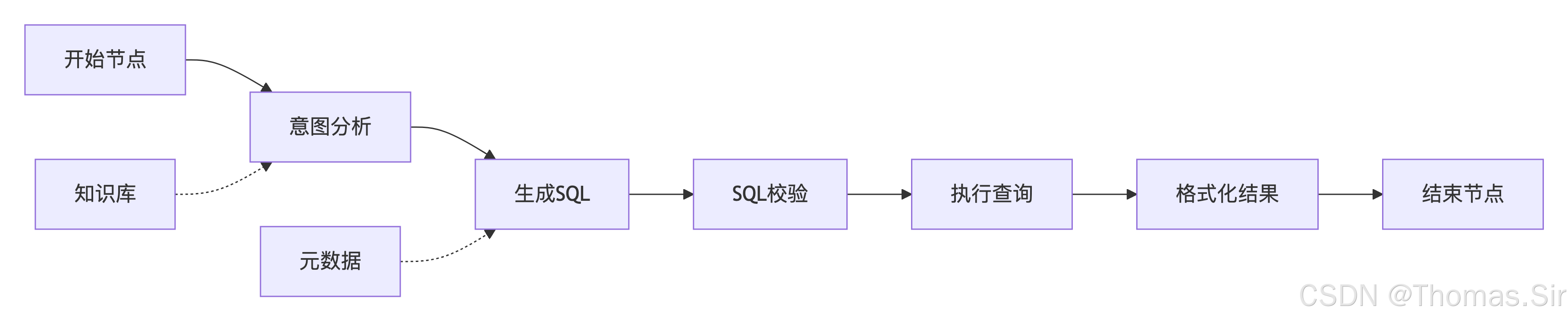
6.4 开始节点配置
开始节点定义用户输入的变量:
sql
{
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "用户的自然语言查询问题",
"title": "查询问题",
"ui_component": "textarea",
"placeholder": "例如:查询最近30天的订单总数和总金额"
},
"database": {
"type": "string",
"description": "要查询的数据库名称",
"default": "ecommerce",
"enum": ["ecommerce"],
"title": "数据库"
},
"format": {
"type": "string",
"description": "返回格式",
"default": "table",
"enum": ["table", "json", "chart"],
"title": "输出格式"
}
},
"required": ["query"]
}6.5 知识库节点配置
为了让 AI 更好地理解数据库结构,我们需要创建一个知识库,存放表结构信息。
创建知识库:
-
进入「知识库」页面
-
点击「创建知识库」
-
名称:
电商数据库元数据 -
上传以下内容作为知识文档:
sql
# markdown 格式
# 电商数据库结构说明
## 用户表 (users)
| 字段 | 类型 | 说明 |
|-----|------|-----|
| id | INT | 用户ID,主键 |
| username | VARCHAR | 用户名 |
| real_name | VARCHAR | 真实姓名 |
| phone | VARCHAR | 手机号 |
| email | VARCHAR | 邮箱 |
| gender | ENUM | 性别:male/female/unknown |
| city | VARCHAR | 所在城市 |
| register_time | DATETIME | 注册时间 |
| last_login_time | DATETIME | 最后登录时间 |
| status | TINYINT | 状态:0禁用/1正常 |
## 产品表 (products)
| 字段 | 类型 | 说明 |
|-----|------|-----|
| id | INT | 产品ID |
| product_code | VARCHAR | 产品编码 |
| product_name | VARCHAR | 产品名称 |
| category_id | INT | 分类ID |
| category_name | VARCHAR | 分类名称 |
| price | DECIMAL | 销售价格(元) |
| cost_price | DECIMAL | 成本价(元) |
| stock_quantity | INT | 库存数量 |
| sales_count | INT | 累计销量 |
| status | TINYINT | 状态:0下架/1上架 |
## 订单表 (orders)
| 字段 | 类型 | 说明 |
|-----|------|-----|
| id | INT | 订单ID |
| order_no | VARCHAR | 订单号 |
| user_id | INT | 用户ID |
| total_amount | DECIMAL | 订单总金额(元) |
| discount_amount | DECIMAL | 优惠金额(元) |
| actual_amount | DECIMAL | 实付金额(元) |
| order_status | TINYINT | 0待付款/1已付款/2已发货/3已完成/4已取消 |
| payment_method | VARCHAR | wechat/alipay/card |
| create_time | DATETIME | 下单时间 |
| pay_time | DATETIME | 支付时间 |
## 订单明细表 (order_items)
| 字段 | 类型 | 说明 |
|-----|------|-----|
| id | INT | 明细ID |
| order_id | INT | 订单ID |
| product_id | INT | 产品ID |
| product_name | VARCHAR | 产品名称(快照) |
| unit_price | DECIMAL | 单价(元) |
| quantity | INT | 数量 |
| total_price | DECIMAL | 小计(元) |
## 表关联关系
- orders.user_id = users.id
- order_items.order_id = orders.id
- order_items.product_id = products.id
## 常用查询示例
1. 查询订单总数:SELECT COUNT(*) FROM orders
2. 查询销售额:SELECT SUM(actual_amount) FROM orders WHERE order_status=3
3. 查询热销产品:SELECT product_id, SUM(quantity) as total FROM order_items GROUP BY product_id ORDER BY total DESC LIMIT 106.6 Agent 节点配置
Agent 节点是整个工作流的核心,负责理解用户意图并生成 SQL。
配置参数:
sql
# yaml 格式
# Agent 节点配置
节点名称: SQL生成Agent
模型: deepseek-chat
温度: 0.3 # 降低温度提高准确性
最大Token: 4096
# 系统提示词
系统提示: |
你是一个专业的SQL查询助手,负责将用户的自然语言问题转换为准确的SQL查询语句。
## 数据库信息
数据库名称: ecommerce
字符集: utf8mb4
## 数据表结构
{knowledge: 电商数据库元数据}
## 表结构详情
{get_table_schema}
## 重要规则
1. 只生成SELECT语句,禁止任何INSERT、UPDATE、DELETE、DROP、ALTER等操作
2. 对于聚合查询,使用合适的聚合函数(SUM、COUNT、AVG、MAX、MIN)
3. 时间条件注意使用正确的格式
4. 对于模糊匹配,使用LIKE语句
5. 排序使用ORDER BY,限制条数使用LIMIT
6. 生成的SQL必须是可执行的
7. 对于复杂的多表查询,使用JOIN关联
## 输出格式
请以JSON格式输出:
{
"sql": "生成的SQL语句",
"explanation": "SQL的解释说明",
"confidence": 0.95
}
# 工具配置
工具:
- get_table_schema # 获取表结构
- query_database # 执行查询
# 最大迭代次数
max_iterations: 56.7 代码执行节点(SQL校验)
添加一个代码节点来校验 SQL 的安全性:
python
import re
import json
def main(sql: str) -> dict:
"""
SQL 安全检查函数
检查 SQL 是否包含危险操作
"""
# 危险关键词列表
dangerous_keywords = [
r'\bDROP\b', r'\bDELETE\b', r'\bUPDATE\b',
r'\bINSERT\b', r'\bALTER\b', r'\bCREATE\b',
r'\bTRUNCATE\b', r'\bGRANT\b', r'\bREVOKE\b',
r'\bEXEC\b', r'\bEXECUTE\b', r'\bUNION\b.*\bSELECT\b'
]
# 转换为大写进行检查
sql_upper = sql.upper()
# 检查是否包含危险关键词
for keyword in dangerous_keywords:
if re.search(keyword, sql_upper):
return {
"safe": False,
"error": f"SQL包含危险操作: {keyword}",
"sql": sql
}
# 检查是否以 SELECT 开头
if not sql_upper.strip().startswith('SELECT'):
return {
"safe": False,
"error": "只允许执行SELECT查询语句",
"sql": sql
}
# 检查是否有多条语句
if ';' in sql and sql.count(';') > 1:
# 如果只有一个分号且在末尾,是允许的
if not sql.strip().endswith(';'):
return {
"safe": False,
"error": "不允许执行多条SQL语句",
"sql": sql
}
return {
"safe": True,
"error": None,
"sql": sql
}6.8 HTTP 请求节点(执行查询)
配置 HTTP 请求节点来调用我们的 FastAPI 服务:
python
# yaml 格式
# HTTP 请求节点配置
端点: http://host.docker.internal:8001/query
方法: POST
认证: Bearer Token
# 请求体
{
"database": "{{database}}",
"sql": "{{sql}}",
"user_id": "{{sys.user_id}}"
}
# 超时设置
超时: 30秒
重试次数: 26.9 模板转换节点(格式化结果)
将查询结果转换为用户友好的格式:
python
# jinja2 格式文件
{# 模板转换节点配置 #}
{% if result.status == 'success' %}
## 查询结果
**查询语句**:
```sql
{{ sql }}数据统计:
-
共返回 {{ result.data | length }} 条记录
-
查询耗时:{{ result.execute_time }} 秒
{% if format == 'table' %}
数据表格
| {% for col in result.columns %}{{ col }} | {% endfor %}
|{% for col in result.columns %} --- |{% endfor %}
{% for row in result.data %}
| {% for col in result.columns %}{{ rowcol }} | {% endfor %}
{% endfor %}
{% elif format == 'json' %}
JSON 数据
json
python
{{ result.data | tojson(indent=2) }}{% endif %}
{% else %}
查询失败
错误信息:{{ result.error }}
建议:
-
检查查询条件是否正确
-
确认数据表是否存在
-
联系管理员获取帮助 {% endif %}
python
### 6.10 完整工作流 JSON 配置
以下是完整的工作流配置文件(可导入 Dify):
```json
{
"name": "智能数据库查询助手",
"description": "将自然语言转换为SQL并执行查询",
"graph": {
"nodes": [
{
"id": "start",
"type": "start",
"data": {
"variables": [
{
"name": "query",
"type": "string",
"required": true,
"title": "查询问题"
},
{
"name": "database",
"type": "string",
"default": "ecommerce",
"title": "数据库"
}
]
}
},
{
"id": "agent",
"type": "agent",
"data": {
"model": "deepseek-chat",
"temperature": 0.3,
"tools": ["get_table_schema", "query_database"],
"max_iterations": 5
}
},
{
"id": "code",
"type": "code",
"data": {
"code": "def main(sql: str) -> dict:\n ...",
"inputs": ["sql"]
}
},
{
"id": "http",
"type": "http-request",
"data": {
"method": "POST",
"url": "http://host.docker.internal:8001/query",
"body": "{\"database\": \"{{database}}\", \"sql\": \"{{sql}}\"}"
}
},
{
"id": "template",
"type": "template-transform",
"data": {
"template": "{% if result.status == 'success' %}..."
}
},
{
"id": "end",
"type": "end",
"data": {
"outputs": ["result"]
}
}
],
"edges": [
{"source": "start", "target": "agent"},
{"source": "agent", "target": "code"},
{"source": "code", "target": "http"},
{"source": "http", "target": "template"},
{"source": "template", "target": "end"}
]
}
}第七章:API 服务开发
为了增强安全性和灵活性,我们开发一个 FastAPI 服务作为 Dify 和数据库之间的中间层。
7.1 项目结构
python
smart-query-api/
├── app/
│ ├── __init__.py
│ ├── main.py # FastAPI 主入口
│ ├── config.py # 配置文件
│ ├── database/
│ │ ├── __init__.py
│ │ ├── connection.py # 数据库连接池
│ │ └── executor.py # SQL 执行器
│ ├── security/
│ │ ├── __init__.py
│ │ ├── sql_validator.py # SQL 校验器
│ │ ├── auth.py # 认证模块
│ │ └── audit.py # 审计日志
│ ├── models/
│ │ ├── __init__.py
│ │ └── schemas.py # Pydantic 模型
│ └── utils/
│ ├── __init__.py
│ └── formatter.py # 结果格式化
├── requirements.txt
├── .env
└── Dockerfile7.2 配置文件
python
# app/config.py
import os
from dotenv import load_dotenv
load_dotenv()
class Config:
"""应用配置"""
# 数据库配置
DB_HOST = os.getenv('DB_HOST', 'localhost')
DB_PORT = int(os.getenv('DB_PORT', 3306))
DB_USER = os.getenv('DB_USER', 'root')
DB_PASSWORD = os.getenv('DB_PASSWORD', '')
DB_NAME = os.getenv('DB_NAME', 'ecommerce')
# 数据库连接池配置
DB_POOL_SIZE = int(os.getenv('DB_POOL_SIZE', 10))
DB_MAX_OVERFLOW = int(os.getenv('DB_MAX_OVERFLOW', 20))
DB_POOL_RECYCLE = int(os.getenv('DB_POOL_RECYCLE', 3600))
DB_POOL_TIMEOUT = int(os.getenv('DB_POOL_TIMEOUT', 30))
# API 配置
API_HOST = os.getenv('API_HOST', '0.0.0.0')
API_PORT = int(os.getenv('API_PORT', 8001))
API_SECRET_KEY = os.getenv('API_SECRET_KEY', 'your-secret-key')
# 安全配置
MAX_QUERY_ROWS = int(os.getenv('MAX_QUERY_ROWS', 10000))
QUERY_TIMEOUT = int(os.getenv('QUERY_TIMEOUT', 30))
# 审计日志
AUDIT_LOG_ENABLED = os.getenv('AUDIT_LOG_ENABLED', 'true').lower() == 'true'
AUDIT_LOG_FILE = os.getenv('AUDIT_LOG_FILE', 'logs/audit.log')
# 敏感字段脱敏
SENSITIVE_FIELDS = ['phone', 'email', 'id_card', 'password']
class DevelopmentConfig(Config):
"""开发环境配置"""
DEBUG = True
class ProductionConfig(Config):
"""生产环境配置"""
DEBUG = False
config = {
'development': DevelopmentConfig,
'production': ProductionConfig,
'default': DevelopmentConfig
}7.3 数据模型定义
python
# app/models/schemas.py
from pydantic import BaseModel, Field, validator
from typing import List, Dict, Any, Optional
from datetime import datetime
class QueryRequest(BaseModel):
"""查询请求模型"""
database: str = Field(..., description="数据库名称")
sql: str = Field(..., description="SQL查询语句")
user_id: Optional[str] = Field(None, description="用户ID")
user_name: Optional[str] = Field(None, description="用户名")
@validator('sql')
def validate_sql(cls, v):
"""验证 SQL 语句"""
sql_upper = v.strip().upper()
# 只允许 SELECT
if not sql_upper.startswith('SELECT'):
raise ValueError('只允许执行 SELECT 查询')
# 禁止危险操作
dangerous = ['DROP', 'DELETE', 'UPDATE', 'INSERT',
'ALTER', 'CREATE', 'TRUNCATE']
for keyword in dangerous:
if keyword in sql_upper:
raise ValueError(f'禁止使用 {keyword} 操作')
return v
@validator('sql')
def check_limit(cls, v):
"""检查是否有 LIMIT 限制"""
sql_upper = v.strip().upper()
# 如果没有 LIMIT,自动添加
if 'LIMIT' not in sql_upper:
# 如果已经有 ORDER BY,在它之前添加
if 'ORDER BY' in sql_upper:
v = v.replace('ORDER BY', 'LIMIT 1000 ORDER BY')
else:
v = v.rstrip(';') + ' LIMIT 1000'
return v
class QueryResponse(BaseModel):
"""查询响应模型"""
status: str = Field(..., description="状态: success/error")
data: Optional[List[Dict[str, Any]]] = Field(None, description="查询结果")
columns: Optional[List[str]] = Field(None, description="列名")
row_count: Optional[int] = Field(None, description="返回行数")
execute_time: Optional[float] = Field(None, description="执行耗时(秒)")
error: Optional[str] = Field(None, description="错误信息")
sql: Optional[str] = Field(None, description="执行的SQL语句")
class AuditLog(BaseModel):
"""审计日志模型"""
id: Optional[int] = None
user_id: Optional[str] = None
user_name: Optional[str] = None
database: str
sql: str
row_count: int
execute_time: float
status: str
error_message: Optional[str] = None
ip_address: Optional[str] = None
created_at: datetime = Field(default_factory=datetime.now)7.4 数据库连接池
python
# app/database/connection.py
import aiomysql
from contextlib import asynccontextmanager
from typing import List, Dict, Any, Optional
import logging
from ..config import config
logger = logging.getLogger(__name__)
class DatabasePool:
"""数据库连接池管理器"""
def __init__(self, env: str = 'default'):
self.cfg = config.get(env, config['default'])
self.pool: Optional[aiomysql.Pool] = None
async def init_pool(self):
"""初始化连接池"""
try:
self.pool = await aiomysql.create_pool(
host=self.cfg.DB_HOST,
port=self.cfg.DB_PORT,
user=self.cfg.DB_USER,
password=self.cfg.DB_PASSWORD,
db=self.cfg.DB_NAME,
minsize=1,
maxsize=self.cfg.DB_POOL_SIZE,
max_usage=100,
pool_recycle=self.cfg.DB_POOL_RECYCLE,
autocommit=True,
charset='utf8mb4'
)
logger.info(f"数据库连接池初始化成功: {self.cfg.DB_HOST}:{self.cfg.DB_PORT}")
except Exception as e:
logger.error(f"数据库连接池初始化失败: {e}")
raise
async def close_pool(self):
"""关闭连接池"""
if self.pool:
self.pool.close()
await self.pool.wait_closed()
logger.info("数据库连接池已关闭")
@asynccontextmanager
async def get_connection(self):
"""获取数据库连接(上下文管理器)"""
async with self.pool.acquire() as conn:
yield conn
# 全局连接池实例
db_pool = DatabasePool()
async def get_db_pool() -> DatabasePool:
"""获取数据库连接池实例"""
return db_pool7.5 SQL 执行器
python
# app/database/executor.py
import time
import logging
from typing import List, Dict, Any, Optional
from .connection import get_db_pool
from ..config import config
logger = logging.getLogger(__name__)
class SQLExecutor:
"""SQL 执行器"""
def __init__(self, env: str = 'default'):
self.cfg = config.get(env, config['default'])
async def execute_query(self, sql: str) -> Dict[str, Any]:
"""
执行查询 SQL
Args:
sql: SQL 查询语句
Returns:
包含执行结果的字典
"""
start_time = time.time()
result = {
"data": [],
"columns": [],
"row_count": 0,
"execute_time": 0,
"error": None
}
pool = await get_db_pool()
try:
async with pool.get_connection() as conn:
async with conn.cursor(aiomysql.DictCursor) as cursor:
# 设置查询超时
await cursor.execute(f"SET SESSION max_execution_time={self.cfg.QUERY_TIMEOUT * 1000}")
# 执行查询
await cursor.execute(sql)
# 获取结果
rows = await cursor.fetchall()
# 限制返回行数
if len(rows) > self.cfg.MAX_QUERY_ROWS:
rows = rows[:self.cfg.MAX_QUERY_ROWS]
logger.warning(f"查询结果超过限制,截断至 {self.cfg.MAX_QUERY_ROWS} 行")
# 获取列名
if rows:
columns = list(rows[0].keys())
else:
columns = []
result["data"] = rows
result["columns"] = columns
result["row_count"] = len(rows)
except Exception as e:
logger.error(f"SQL执行失败: {sql}, 错误: {e}")
result["error"] = str(e)
result["execute_time"] = round(time.time() - start_time, 3)
return result
# 全局执行器实例
sql_executor = SQLExecutor()
async def execute_sql(sql: str) -> Dict[str, Any]:
"""执行 SQL 查询"""
return await sql_executor.execute_query(sql)7.6 SQL 安全校验器
python
# app/security/sql_validator.py
import re
from typing import Tuple, Optional
import logging
logger = logging.getLogger(__name__)
class SQLValidator:
"""SQL 安全校验器"""
# 危险关键词模式
DANGEROUS_PATTERNS = [
(r'\bDROP\b', 'DROP 操作'),
(r'\bDELETE\b', 'DELETE 操作'),
(r'\bUPDATE\b', 'UPDATE 操作'),
(r'\bINSERT\b', 'INSERT 操作'),
(r'\bALTER\b', 'ALTER 操作'),
(r'\bCREATE\b', 'CREATE 操作'),
(r'\bTRUNCATE\b', 'TRUNCATE 操作'),
(r'\bGRANT\b', 'GRANT 操作'),
(r'\bREVOKE\b', 'REVOKE 操作'),
(r'\bEXEC\b', 'EXEC 操作'),
(r'\bEXECUTE\b', 'EXECUTE 操作'),
(r'\bINTO\s+OUTFILE\b', '文件导出操作'),
(r'\bINTO\s+DUMPFILE\b', '文件导出操作'),
(r'\bLOAD_FILE\b', '文件读取操作'),
(r'\bSLEEP\b', '延时攻击'),
(r'\xBENCHMARK\b', '基准测试攻击'),
]
# SQL 注入模式
INJECTION_PATTERNS = [
r"'.*\s+OR\s+'.*='",
r"'.*\s+OR\s+\d+=\d+",
r"\bOR\s+1=1\b",
r"\bOR\s+1=2\b",
r"\bUNION\s+SELECT\b",
r"\bSELECT\s+.*\bFROM\b.*\bWHERE\b.*='",
r"--\s*$",
r"/\*.*\*/",
]
@classmethod
def validate(cls, sql: str) -> Tuple[bool, Optional[str]]:
"""
校验 SQL 安全性
Args:
sql: SQL 语句
Returns:
(是否安全, 错误信息)
"""
sql_upper = sql.strip().upper()
# 1. 检查是否以 SELECT 开头
if not sql_upper.startswith('SELECT'):
return False, "只允许执行 SELECT 查询语句"
# 2. 检查危险关键词
for pattern, operation in cls.DANGEROUS_PATTERNS:
if re.search(pattern, sql_upper, re.IGNORECASE):
logger.warning(f"检测到危险操作: {operation}, SQL: {sql}")
return False, f"检测到危险操作: {operation}"
# 3. 检查 SQL 注入模式
for pattern in cls.INJECTION_PATTERNS:
if re.search(pattern, sql, re.IGNORECASE):
logger.warning(f"检测到可能的 SQL 注入: {sql}")
return False, "检测到可疑的 SQL 语法,请检查查询条件"
# 4. 检查是否有多条语句
statements = [s.strip() for s in sql.split(';') if s.strip()]
if len(statements) > 1:
return False, "不允许执行多条 SQL 语句"
return True, None
@classmethod
def add_limit(cls, sql: str, default_limit: int = 1000) -> str:
"""
为 SQL 添加 LIMIT 限制
Args:
sql: 原始 SQL
default_limit: 默认限制行数
Returns:
添加 LIMIT 后的 SQL
"""
sql_clean = sql.rstrip(';')
sql_upper = sql_clean.upper()
# 如果已经有 LIMIT,不处理
if 'LIMIT' in sql_upper:
return sql
# 在合适的位置添加 LIMIT
if 'ORDER BY' in sql_upper:
# 在 ORDER BY 之前添加
order_by_pos = sql_upper.find('ORDER BY')
sql_clean = sql_clean[:order_by_pos] + f'LIMIT {default_limit} ' + sql_clean[order_by_pos:]
else:
sql_clean = f'{sql_clean} LIMIT {default_limit}'
return sql_clean
# 全局校验器实例
sql_validator = SQLValidator()7.7 敏感数据脱敏
python
# app/security/mask.py
import re
from typing import Dict, Any, List
from ..config import config
class DataMasker:
"""敏感数据脱敏器"""
# 脱敏规则
MASK_RULES = {
'phone': lambda x: re.sub(r'(\d{3})\d{4}(\d{4})', r'\1****\2', str(x)) if x else x,
'email': lambda x: re.sub(r'(^[^@]{3})[^@]*(@.*$)', r'\1***\2', str(x)) if x else x,
'id_card': lambda x: re.sub(r'(\d{4})\d{10}(\d{4})', r'\1**********\2', str(x)) if x else x,
'password': lambda x: '********',
'token': lambda x: x[:8] + '...' if len(str(x)) > 8 else '***',
}
@classmethod
def mask_value(cls, field_name: str, value: Any) -> Any:
"""
对单个值进行脱敏
Args:
field_name: 字段名
value: 字段值
Returns:
脱敏后的值
"""
field_lower = field_name.lower()
for pattern, mask_func in cls.MASK_RULES.items():
if pattern in field_lower:
try:
return mask_func(value)
except Exception:
return value
return value
@classmethod
def mask_data(cls, data: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
"""
对数据集进行脱敏
Args:
data: 原始数据列表
Returns:
脱敏后的数据列表
"""
masked_data = []
for row in data:
masked_row = {}
for key, value in row.items():
masked_row[key] = cls.mask_value(key, value)
masked_data.append(masked_row)
return masked_data7.8 审计日志
python
# app/security/audit.py
import json
import logging
from datetime import datetime
from typing import Optional
from pathlib import Path
from ..config import config
# 配置审计日志
audit_logger = logging.getLogger('audit')
audit_logger.setLevel(logging.INFO)
if config['default'].AUDIT_LOG_ENABLED:
log_file = Path(config['default'].AUDIT_LOG_FILE)
log_file.parent.mkdir(parents=True, exist_ok=True)
file_handler = logging.FileHandler(log_file, encoding='utf-8')
formatter = logging.Formatter('%(asctime)s | %(message)s')
file_handler.setFormatter(formatter)
audit_logger.addHandler(file_handler)
def log_query(
user_id: Optional[str],
user_name: Optional[str],
database: str,
sql: str,
row_count: int,
execute_time: float,
status: str,
error_message: Optional[str] = None,
ip_address: Optional[str] = None
):
"""
记录查询审计日志
Args:
user_id: 用户ID
user_name: 用户名
database: 数据库名
sql: SQL语句
row_count: 返回行数
execute_time: 执行时间
status: 状态
error_message: 错误信息
ip_address: IP地址
"""
log_entry = {
"user_id": user_id,
"user_name": user_name,
"database": database,
"sql": sql[:500], # 截断过长的SQL
"row_count": row_count,
"execute_time": execute_time,
"status": status,
"error_message": error_message,
"ip_address": ip_address,
"timestamp": datetime.now().isoformat()
}
audit_logger.info(json.dumps(log_entry, ensure_ascii=False))7.9 主程序
python
# app/main.py
from fastapi import FastAPI, HTTPException, Depends, Request
from fastapi.middleware.cors import CORSMiddleware
from fastapi.responses import JSONResponse
from contextlib import asynccontextmanager
import uvicorn
import logging
from typing import Optional
from .config import config
from .database.connection import db_pool, init_db_pool, close_db_pool
from .database.executor import execute_sql
from .security.sql_validator import sql_validator
from .security.mask import DataMasker
from .security.audit import log_query
from .models.schemas import QueryRequest, QueryResponse
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
@asynccontextmanager
async def lifespan(app: FastAPI):
"""应用生命周期管理"""
# 启动时初始化连接池
await db_pool.init_pool()
logger.info("API服务启动完成")
yield
# 关闭时清理连接池
await db_pool.close_pool()
logger.info("API服务已关闭")
# 创建 FastAPI 应用
app = FastAPI(
title="智能数据库查询API",
description="为Dify提供安全的数据库查询服务",
version="1.0.0",
lifespan=lifespan
)
# 配置 CORS
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
@app.get("/")
async def root():
"""健康检查"""
return {"status": "ok", "service": "smart-query-api", "version": "1.0.0"}
@app.post("/query", response_model=QueryResponse)
async def query_database(
request: QueryRequest,
fastapi_request: Request
):
"""
执行数据库查询
Args:
request: 查询请求
fastapi_request: FastAPI请求对象
Returns:
查询结果
"""
logger.info(f"收到查询请求 - 数据库: {request.database}, SQL: {request.sql[:100]}...")
# 获取客户端IP
client_ip = fastapi_request.headers.get("X-Forwarded-For",
fastapi_request.client.host if fastapi_request.client else "unknown")
# 1. SQL 安全校验
is_safe, error_msg = sql_validator.validate(request.sql)
if not is_safe:
# 记录审计日志
log_query(
user_id=request.user_id,
user_name=request.user_name,
database=request.database,
sql=request.sql,
row_count=0,
execute_time=0,
status="rejected",
error_message=error_msg,
ip_address=client_ip
)
return QueryResponse(
status="error",
error=error_msg,
sql=request.sql
)
# 2. 添加 LIMIT 限制
safe_sql = sql_validator.add_limit(request.sql)
# 3. 执行查询
result = await execute_sql(safe_sql)
# 4. 处理结果
if result["error"]:
status = "error"
data = None
columns = None
error = result["error"]
else:
status = "success"
# 敏感数据脱敏
data = DataMasker.mask_data(result["data"])
columns = result["columns"]
error = None
# 5. 记录审计日志
log_query(
user_id=request.user_id,
user_name=request.user_name,
database=request.database,
sql=safe_sql,
row_count=result["row_count"],
execute_time=result["execute_time"],
status=status,
error_message=error,
ip_address=client_ip
)
# 6. 返回响应
return QueryResponse(
status=status,
data=data,
columns=columns,
row_count=result["row_count"],
execute_time=result["execute_time"],
error=error,
sql=safe_sql
)
@app.get("/health")
async def health_check():
"""健康检查接口"""
return {"status": "healthy", "service": "smart-query-api"}
def main():
"""启动服务"""
cfg = config['default']
uvicorn.run(
"app.main:app",
host=cfg.API_HOST,
port=cfg.API_PORT,
reload=cfg.DEBUG,
log_level="info"
)
if __name__ == "__main__":
main()7.10 依赖文件
python
# requirements.txt
fastapi==0.104.1
uvicorn[standard]==0.24.0
aiomysql==0.2.0
pydantic==2.5.0
python-dotenv==1.0.07.11 Docker 部署配置
python
# Dockerfile
FROM python:3.11-slim
WORKDIR /app
# 安装依赖
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# 复制代码
COPY app/ ./app/
# 创建日志目录
RUN mkdir -p /app/logs
# 暴露端口
EXPOSE 8001
# 启动命令
CMD ["python", "-m", "app.main"]
python
# docker-compose.yml (API服务)
version: '3.8'
services:
smart-query-api:
build: .
container_name: smart-query-api
ports:
- "8001:8001"
environment:
- DB_HOST=host.docker.internal
- DB_PORT=3306
- DB_USER=root
- DB_PASSWORD=your_password
- DB_NAME=ecommerce
- API_SECRET_KEY=your-secret-key
- AUDIT_LOG_ENABLED=true
volumes:
- ./logs:/app/logs
restart: unless-stopped
extra_hosts:
- "host.docker.internal:host-gateway"第八章:测试与验证
8.1 测试用例
python
# test_query.py
import asyncio
import json
import httpx
async def test_query():
"""测试查询接口"""
test_cases = [
{
"name": "简单查询",
"sql": "SELECT * FROM users LIMIT 5",
"database": "ecommerce"
},
{
"name": "条件查询",
"sql": "SELECT * FROM users WHERE city = '北京'",
"database": "ecommerce"
},
{
"name": "聚合查询",
"sql": "SELECT city, COUNT(*) as user_count FROM users GROUP BY city",
"database": "ecommerce"
},
{
"name": "多表关联",
"sql": """
SELECT o.order_no, u.real_name, o.actual_amount
FROM orders o
JOIN users u ON o.user_id = u.id
LIMIT 10
""",
"database": "ecommerce"
},
{
"name": "危险SQL - 应被拦截",
"sql": "DROP TABLE users",
"database": "ecommerce",
"expect_error": True
},
{
"name": "SQL注入尝试 - 应被拦截",
"sql": "SELECT * FROM users WHERE id = 1 OR 1=1",
"database": "ecommerce",
"expect_error": False # 实际是安全的,只是演示
}
]
async with httpx.AsyncClient() as client:
for test in test_cases:
print(f"\n=== 测试: {test['name']} ===")
print(f"SQL: {test['sql'][:100]}...")
response = await client.post(
"http://localhost:8001/query",
json={
"database": test['database'],
"sql": test['sql'],
"user_id": "test_user",
"user_name": "测试用户"
}
)
result = response.json()
print(f"状态: {result['status']}")
print(f"耗时: {result.get('execute_time', 0)}秒")
if result['status'] == 'success':
print(f"返回行数: {result['row_count']}")
if result['data']:
print(f"示例数据: {json.dumps(result['data'][0], ensure_ascii=False)}")
else:
print(f"错误: {result['error']}")
print("-" * 50)
if __name__ == "__main__":
asyncio.run(test_query())8.2 Dify 工作流测试
在 Dify 界面中,我们可以测试以下查询场景:
| 测试场景 | 用户输入 | 预期 SQL |
|---|---|---|
| 用户查询 | "查询所有用户" | SELECT * FROM users |
| 条件筛选 | "查询北京的活跃用户" | SELECT * FROM users WHERE city='北京' AND status=1 |
| 聚合统计 | "统计每个城市的用户数量" | SELECT city, COUNT(*) as count FROM users GROUP BY city |
| 订单分析 | "查询最近7天的订单总数和总金额" | SELECT COUNT(*) as order_count, SUM(actual_amount) as total_amount FROM orders WHERE create_time >= DATE_SUB(NOW(), INTERVAL 7 DAY) |
| 产品销售 | "销量最高的10个产品" | SELECT product_name, sales_count FROM products ORDER BY sales_count DESC LIMIT 10 |
| 多表查询 | "查询用户张三的所有订单" | SELECT o.* FROM orders o JOIN users u ON o.user_id=u.id WHERE u.real_name='张三' |
8.3 测试结果示例
python
=== 测试: 简单查询 ===
SQL: SELECT * FROM users LIMIT 5...
状态: success
耗时: 0.052秒
返回行数: 5
示例数据: {"id": 1, "username": "zhangwei", "real_name": "张伟", "city": "北京"}
=== 测试: 聚合查询 ===
SQL: SELECT city, COUNT(*) as user_count FROM users GROUP BY city...
状态: success
耗时: 0.048秒
返回行数: 8
示例数据: {"city": "北京", "user_count": 2}
=== 测试: 危险SQL - 应被拦截 ===
SQL: DROP TABLE users...
状态: error
错误: 只允许执行 SELECT 查询语句第九章:总结
9.1 项目回顾
本文详细介绍了如何使用 Dify 构建一个完整的数据库智能查询系统。从需求分析到系统架构,从环境搭建到代码实现,我们一步步完成了这个企业级的 AI 应用。
回顾整个项目,我们实现了以下核心功能:
-
自然语言转 SQL:利用大模型的能力,将用户的自然语言问题自动转换为准确的 SQL 查询语句。通过精心设计的提示词和表结构知识库,我们实现了高准确率的 SQL 生成。
-
安全的查询执行:通过多层次的防护机制(SQL 校验、危险关键词过滤、权限控制、审计日志),确保数据库的安全性,防止 SQL 注入和数据泄露。
-
灵活的结果处理:支持表格、JSON 等多种输出格式,并对敏感数据自动脱敏,保护用户隐私。
-
完善的工作流编排:通过 Dify 的可视化工作流,将自然语言理解、SQL 生成、安全校验、结果格式化等环节串联起来,形成了一个完整的智能查询链路。
-
可扩展的 API 服务:使用 FastAPI 开发了中间层服务,不仅提供了 RESTful API,还实现了连接池、审计日志、敏感数据脱敏等企业级功能。
9.2 技术要点总结
| 技术点 | 实现方式 | 关键考虑 |
|---|---|---|
| 自然语言理解 | Dify Agent + 大模型 | 提示词设计、元数据提供 |
| SQL 生成 | 大模型 + 表结构知识 | 准确率优化、复杂查询支持 |
| 安全防护 | SQL 校验器 + 只读账号 | 多层防护、实时拦截 |
| 性能优化 | 连接池 + 查询限制 | 响应时间控制、资源管理 |
| 可观测性 | 审计日志 + 监控 | 操作可追溯、问题可排查 |
9.3 优化建议
如果要将本系统应用到生产环境,建议从以下几个方面进行优化:
1. SQL 生成准确率优化
-
持续优化提示词,增加更多示例
-
建立查询模板库,覆盖常见查询场景
-
收集用户反馈,建立 bad case 数据集进行微调
2. 性能优化
-
引入 Redis 缓存高频查询结果
-
对慢查询进行监控和优化
-
考虑读写分离,查询走从库
3. 安全加固
-
实现更细粒度的数据权限(行级、列级)
-
增加查询频率限制和熔断机制
-
定期进行安全审计和渗透测试
4. 用户体验提升
-
增加查询历史功能
-
支持查询结果可视化(图表)
-
提供查询建议和智能补全
9.4 未来扩展方向
本系统具有良好的扩展性,未来可以增加以下功能:
-
多数据源支持:除了 MySQL,还可以接入 PostgreSQL、MongoDB、ClickHouse 等数据库
-
智能报表:定时执行查询,自动生成并推送报表
-
数据洞察:AI 自动分析查询结果,生成业务洞察
-
语音查询:支持语音输入,进一步降低使用门槛
9.5 结语
通过本文的学习,我们从零构建了一个功能完整的数据库智能查询系统。这不仅仅是一个技术实现,更是一种新的数据访问范式------让数据触手可及,让每个人都能成为数据分析师。
AI 正在改变我们与数据交互的方式,而 Dify 这样的平台大大降低了 AI 应用的开发门槛。希望本文能够帮助读者掌握使用 Dify 构建智能应用的方法,并激发更多创新想法。
最后,记住一句话:最好的工具是让用户感觉不到它的存在。智能查询系统的目标就是让数据查询变得如此自然,以至于用户忘记了背后还有 SQL 和数据库的存在。
附录:常见问题
Q1:SQL 生成不准确怎么办?
A:可以从以下几个方面优化:1) 完善表结构注释,让 AI 更好地理解字段含义;2) 在提示词中增加更多查询示例;3) 使用更强大的大模型;4) 建立查询模板库。
Q2:如何防止 SQL 注入?
A:本系统实现了多层防护:1) SQL 校验器过滤危险关键词;2) 数据库使用只读账号;3) 参数化查询;4) 查询结果限制返回行数。
Q3:支持哪些数据库?
A:本示例使用 MySQL,但可以轻松扩展。Dify 支持 MySQL、PostgreSQL、MongoDB 等主流数据库,只需安装对应的插件即可。
Q4:如何处理复杂查询?
A:对于复杂查询(如多表关联、子查询),可以通过以下方式优化:1) 在知识库中明确表关联关系;2) 提供复杂查询的示例;3) 使用更强大的模型(如 GPT-4);4) 拆分为多个简单查询。
Q5:系统性能如何?
A:简单查询(单表、少量数据)通常在 1-3 秒内完成,复杂查询可能需要 5-10 秒。可以通过引入缓存、优化 SQL、使用更快的数据库来提升性能。
🌟 感谢您耐心阅读到这里!
🚀 技术成长没有捷径,但每一次的阅读、思考和实践,都在默默缩短您与成功的距离。
💡 如果本文对您有所启发,欢迎点赞👍、收藏📌、分享📤给更多需要的伙伴!
🗣️ 期待在评论区看到您的想法、疑问或建议,我会认真回复,让我们共同探讨、一起进步~
🔔 关注我,持续获取更多干货内容!
🤗 我们下篇文章见!