文章目录
-
- 前言
- 一、前置准备(环境+工具)
- 二、压测方案设计:梯度加压+平滑压测
-
- [2.1 核心接口梳理](#2.1 核心接口梳理)
- [2.2 梯度线程加压方案](#2.2 梯度线程加压方案)
- [2.3 平滑压测关键配置](#2.3 平滑压测关键配置)
- 三、编写测试计划
-
- [3.1 测试计划结构](#3.1 测试计划结构)
- [3.2 核心组件详解](#3.2 核心组件详解)
- 四、压测结果与核心指标分析
-
- [4.1 整体压测表现](#4.1 整体压测表现)
- [4.2 关键图表分析](#4.2 关键图表分析)
-
- [> 响应时间曲线(Response Times Over Time)](#> 响应时间曲线(Response Times Over Time))
- [> 吞吐量曲线(Transactions per Second)](#> 吞吐量曲线(Transactions per Second))
- 五、核心问题复盘与优化落地
- 六、系统并发能力评估
- 七、压测总结与后续优化方向
-
- [7.1 核心结论](#7.1 核心结论)
- [7.2 压测避坑经验](#7.2 压测避坑经验)
- [7.3 后续优化方向](#7.3 后续优化方向)

前言
抽奖系统作为高并发场景下的典型应用,其性能表现直接影响用户体验与系统稳定性。本文基于实际压测场景,详细记录抽奖系统的性能压测全过程,包括压测环境搭建、核心指标分析、性能瓶颈定位及优化方案。
一、前置准备(环境+工具)
测试环境说明
本次压测基于真实业务部署环境,具体环境如下:
- 操作系统:Windows 11(生产环境可对应Linux服务器)
- 压测工具:JMeter 5.6(开源、易用,适配各类高并发压测场景)
- 系统架构:Spring Boot + Redis(远程部署),核心业务为抽奖接口,包含用户登录、奖品管理、人员管理、中奖记录查询等核心功能
- 测试场景:模拟真实用户访问,覆盖"登录""列表查询""中奖记录查询"三大核心场景
- 压测模式:梯度线程加压(逐步提升并发数),本次压测主要为负载测试。
测试核心目标
- 验证系统在 200 + 并发下的稳定性(零错误、零超时);
- 定位中奖记录查询接口的性能瓶颈,并落地可优化方案;
二、压测方案设计:梯度加压+平滑压测
2.1 核心接口梳理
抽奖系统核心接口均为HTTP接口,采用RESTful风格,本次压测聚焦4个核心接口:
- 抽奖系统登录请求:用户登录鉴权接口,高频访问;
- 奖品列表接口:查询活动奖品信息,读多写少;
- 人员列表接口:查询活动参与人员,读多写少;
- 中奖记录查询接口:核心瓶颈接口,高并发热点场景。
2.2 梯度线程加压方案
采用阶梯式梯度加压,逐步提升线程数,观察系统响应变化。具体线程数梯度:
- 第一阶段:50并发(平稳爬坡,验证基础稳定性);
- 第二阶段:100并发(核心测试阶段,匹配业务峰值预期);
- 第三阶段:150并发(验证系统冗余能力);
- 第四阶段:200并发(极限压测前的过渡,监控资源消耗)。
2.3 平滑压测关键配置
由于本地缓存优化后接口响应速度极快(1ms级),若无延迟压测会瞬间打满本机CPU/网卡,因此在JMeter中配置固定定时器(Constant Timer):
- 定时器延迟:100ms(每个线程请求间隔100ms);
- 作用:控制请求发送频率,避免无阻力流量瞬间打爆系统,同时不改变并发数本质(线程数仍为并发核心);
- 采样间隔:每个接口请求独立采样,保证数据准确性。
三、编写测试计划
3.1 测试计划结构

3.2 核心组件详解
- 公共配置
- HTTP 请求默认值:统一配置目标服务器地址、端口、请求协议等基础参数,减少重复配置,提高测试脚本的可维护性。
- HTTP 信息头管理器:全局设置请求头(如 Content-Type、Accept 等),保证所有接口请求格式统一。
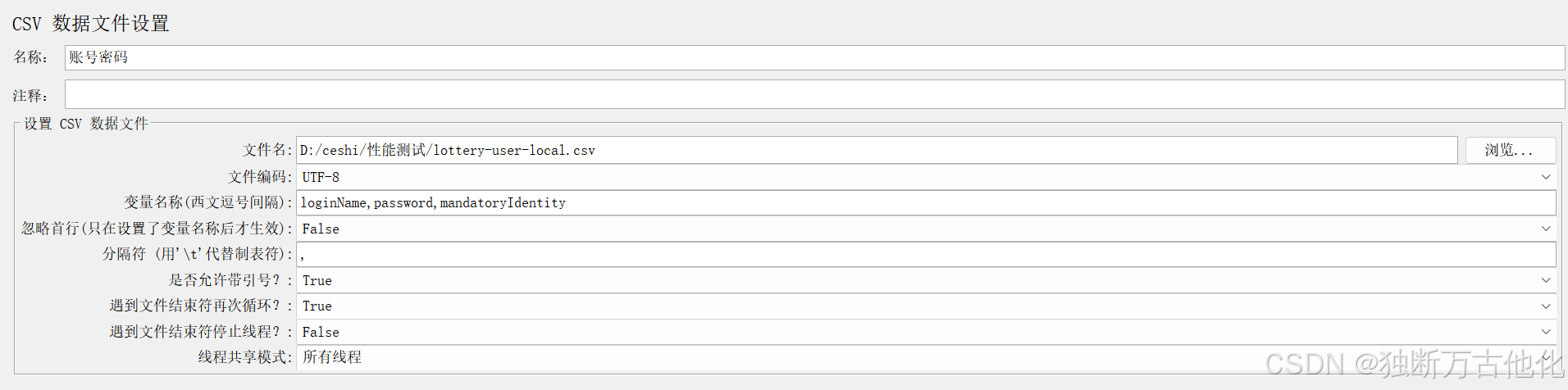
用户参数配置:
账号/密码:存储登录接口的用户凭证,用于登录鉴权请求。
活动ID:存储本次测试对应的活动标识,用于后续接口请求参数的动态传递。 - 定时器:
同步定时器:控制多个请求的并发执行时机,保证请求的同步性。
固定定时器:设置请求间隔时间,避免请求发送过快导致服务器 / 本地压力过大,实现平滑压测。
- 业务请求链路
登录请求(登录接口):
-
作用:完成用户登录鉴权,获取 Token 等身份凭证。
关键组件:
-
JSON 提取器:从登录响应中提取 Token 或用户信息,供后续接口使用。
-
JSON 断言:验证登录响应结果是否符合预期(如成功状态码、响应字段校验)。
业务接口请求:
- 包含 奖品列表、用户列表、活动列表、中奖记录 等核心接口请求,模拟用户在系统中的主要数据查询行为。
- 所有接口共享登录请求提取的用户凭证,保证请求的合法性与连贯性。
- 结果分析组件
- 聚合报告: 展示所有请求的平均响应时间、吞吐量(TPS)、错误率、样本数等关键指标,用于整体性能评估。
- 响应时间曲线(Response Time Over Time):按时间维度展示每个请求的响应时间变化趋势,识别性能瓶颈与波动点。
- 吞吐量曲线(Transactions Per Second):展示系统每秒处理的请求数,反映服务的整体处理能力。
- 活跃线程曲线(Active Threads Over Time):展示测试过程中的并发线程数变化,验证压测过程的稳定性。
四、压测结果与核心指标分析
4.1 整体压测表现
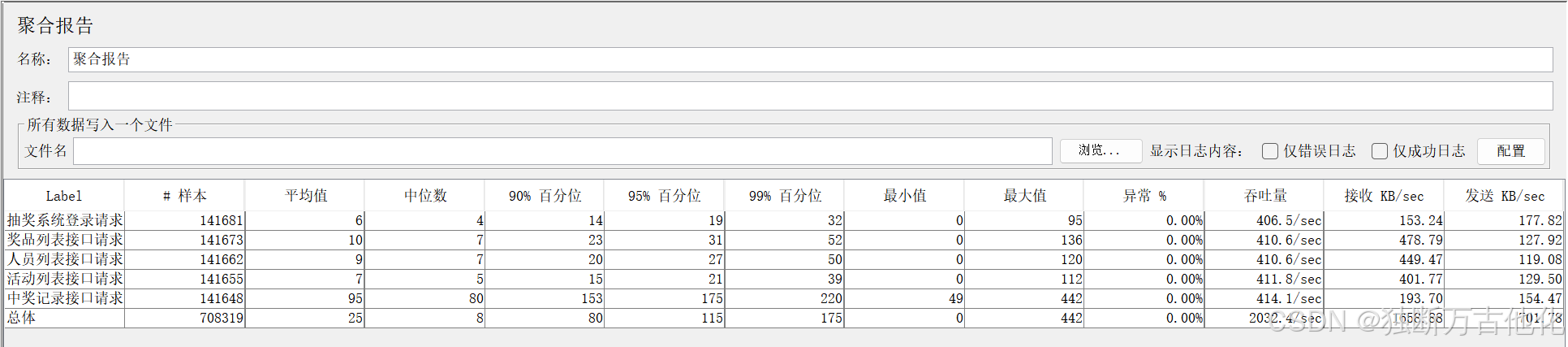
100并发 阶段(系统稳定且资源可控),核心指标如下:
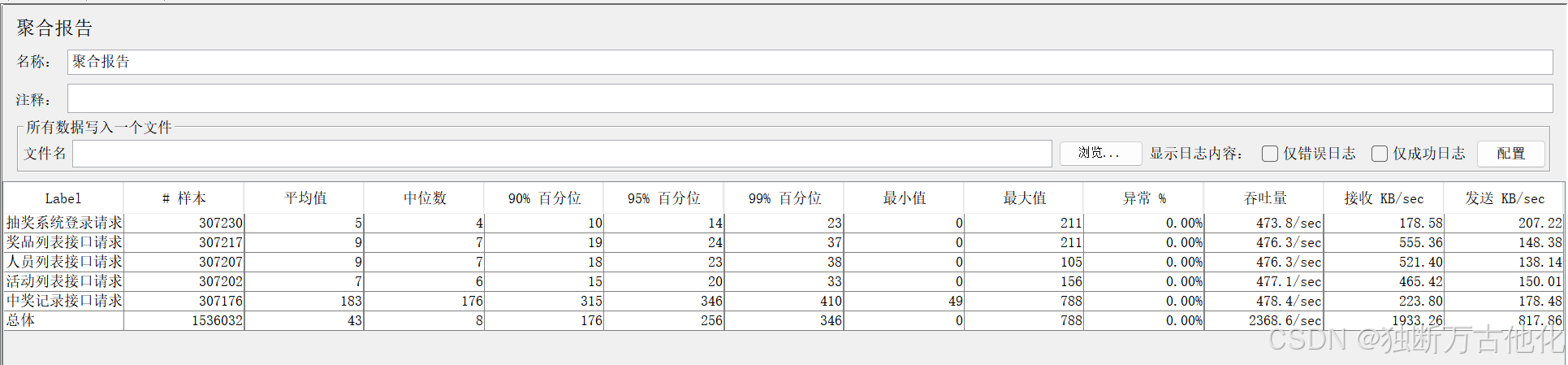
200并发 阶段(系统稳定,响应比100并发略慢),核心指标如下:
4.2 关键图表分析
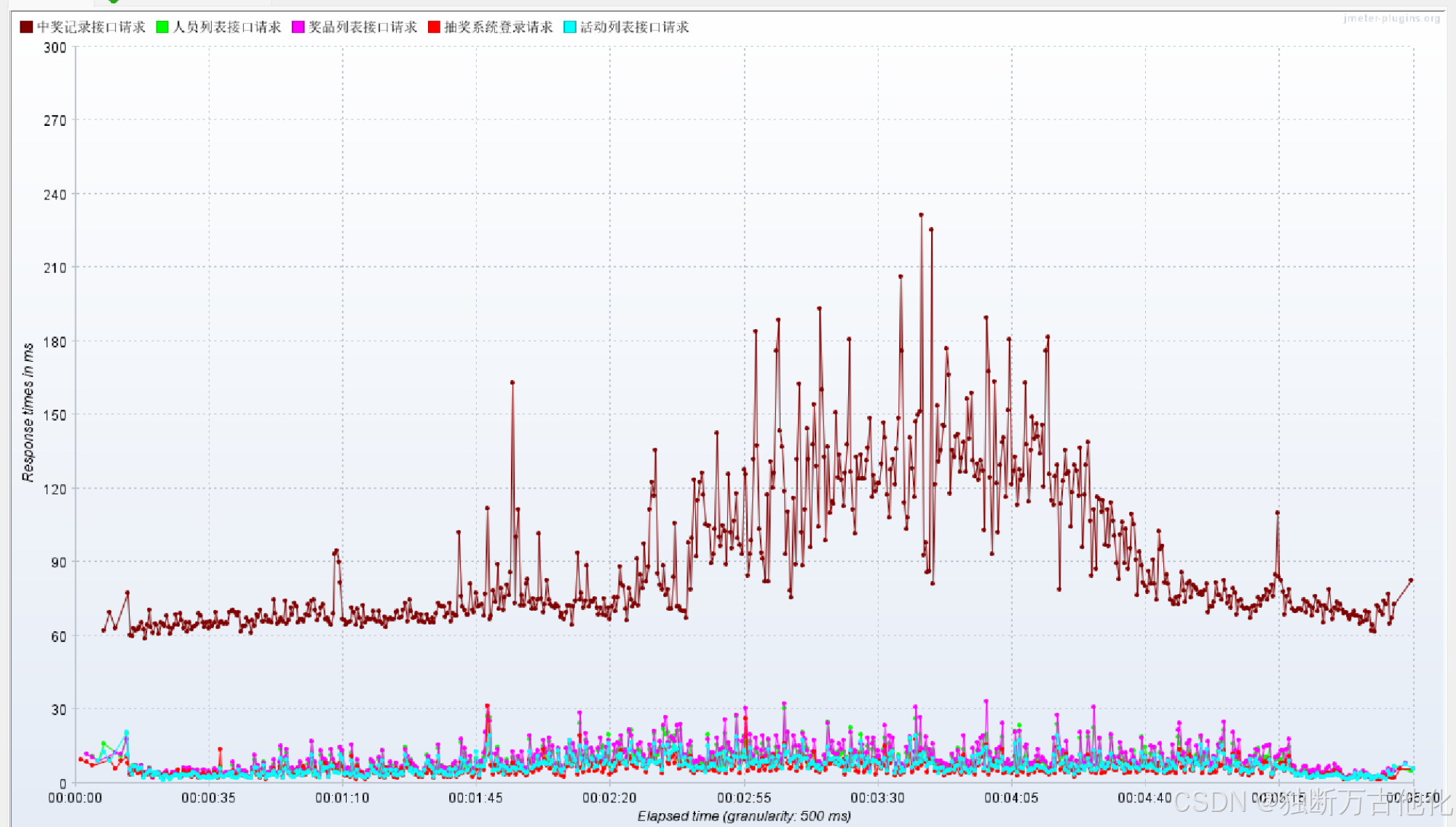
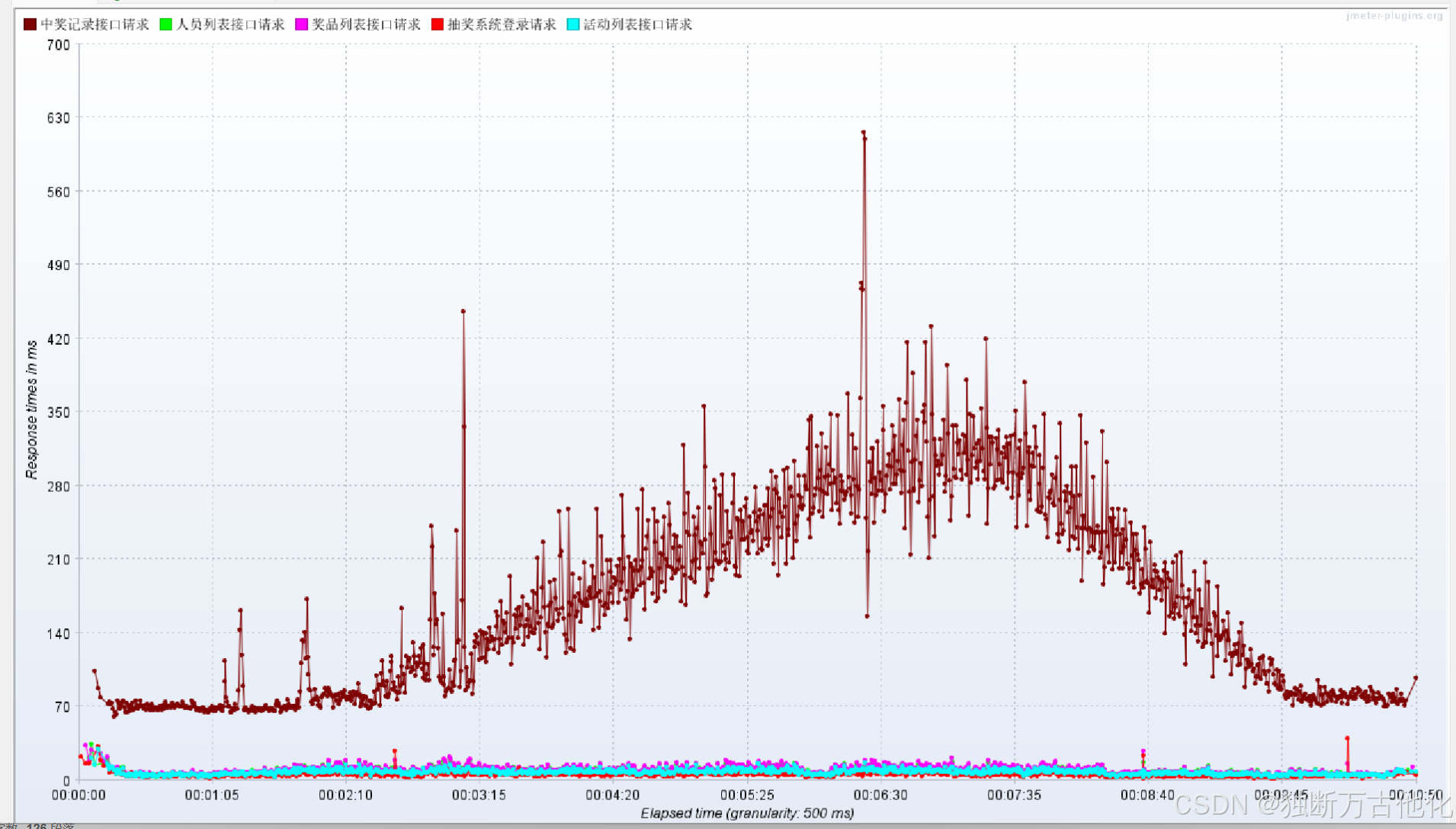
> 响应时间曲线(Response Times Over Time)
100 并发下:
- 核心趋势:列表接口响应时间整体平稳,无剧烈波动;
- 差异点:中奖记录接口响应时间略高于其他接口,但仍处于合理范围,99分位仅220ms,无长尾响应,最大值为 440ms;
- 异常点:仅出现少量瞬时尖峰,为网络波动导致,不影响整体稳定性。
200 并发下:
- 中奖记录接口响应时间变的更长,但仍可以接受,最大值为 790ms;
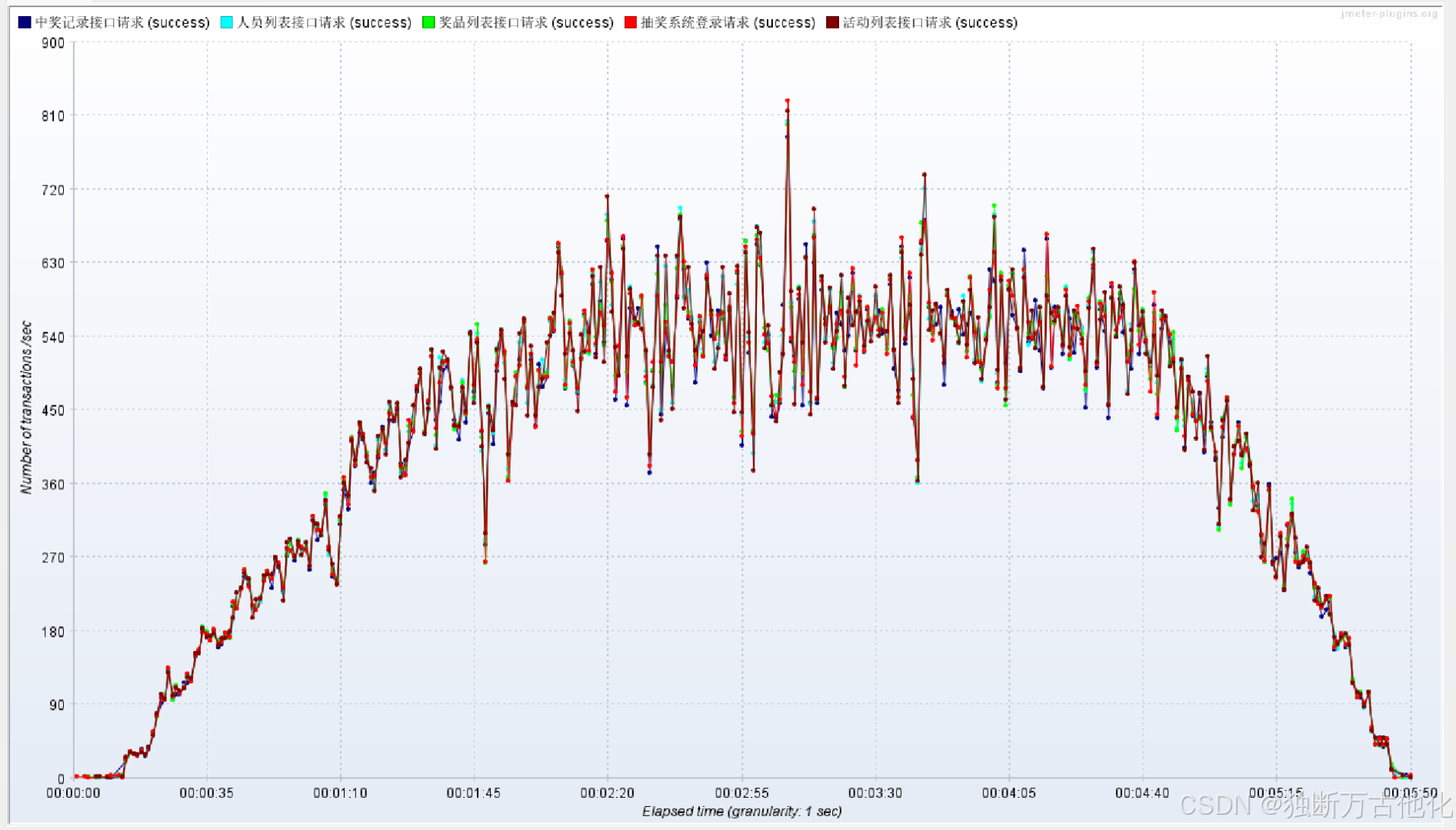
> 吞吐量曲线(Transactions per Second)
100 并发下:
- 上升阶段:随线程数梯度增加,TPS从0逐步攀升至474.7/sec,增长趋势平滑,无突发暴涨;
- 稳定阶段:100并发阶段TPS保持平稳,说明系统处理能力与请求量匹配,无积压;
- 下降阶段:压测收尾阶段TPS缓慢下降,为JMeter线程逐步停止导致,非系统性能问题。
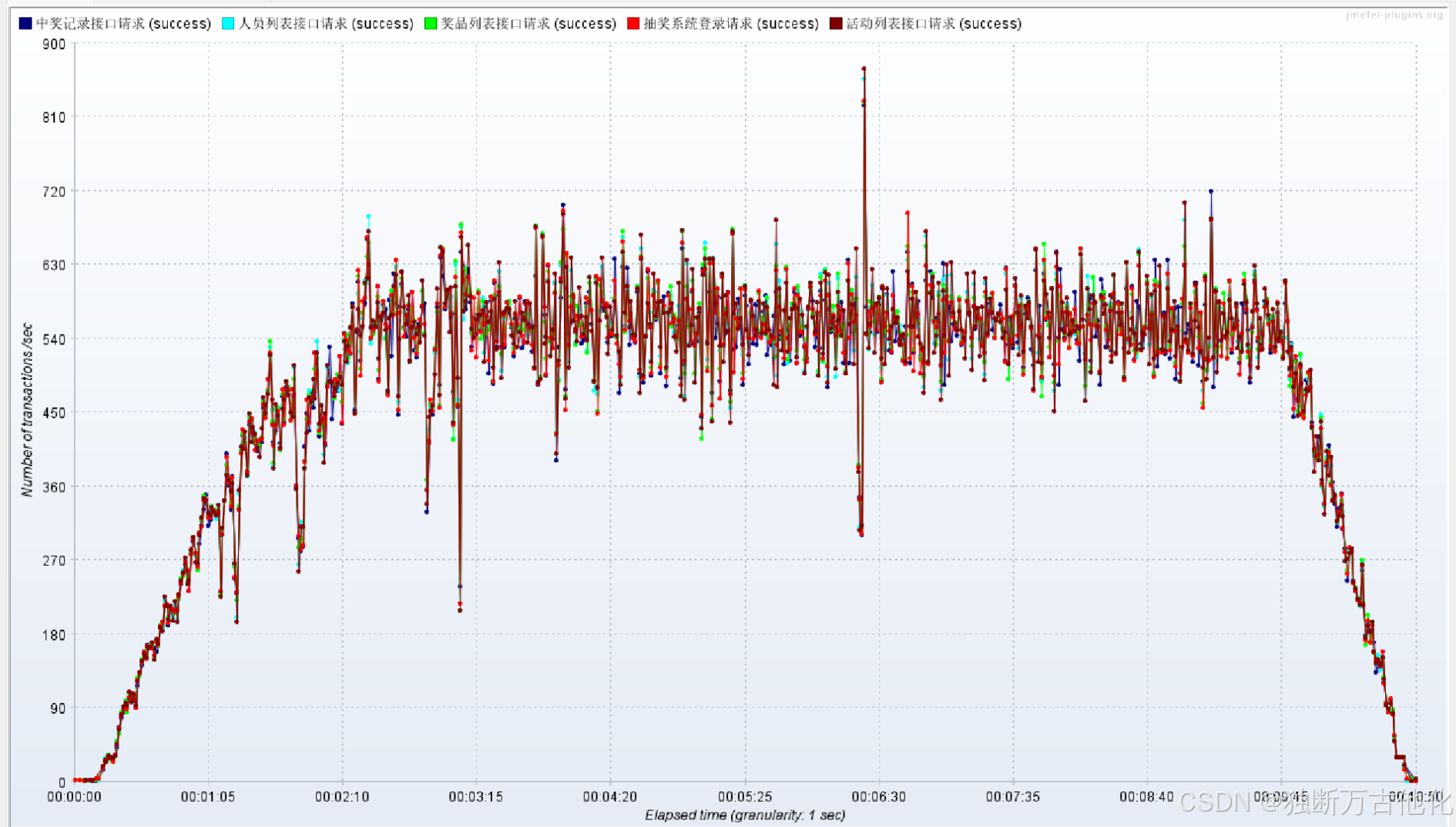
200 并发下:
- TPS 有所增长但是趋近于 570 左右不再增长,说明出现了明显的性能拐点。
五、核心问题复盘与优化落地
通过上面的图表分析等等,以下是问题定位与优化全流程:
问题1: 中奖记录接口Redis远程延迟高
- 现象:压测初期未加本地缓存,中奖记录接口平均响应时间远高于其他接口。
- 定位:通过代码埋点精准拆分耗时:
redisUtil.get()缓存获取值的耗时占比99%,序列化耗时<1ms,确认瓶颈为 远程Redis网络IO延迟 (非序列化、非连接池等问题)。
优化方案: 引入本地缓存
- 核心逻辑:在JVM内存中缓存中奖记录数据,首次请求访问Redis,后续请求直接读取本地内存;
- 实现方式:基于
Caffeine实现线程安全本地缓存,设置5分钟过期时间,避免数据过期; - 优化效果:接口响应耗时从67ms降至1ms,性能得到大幅度提升。
示例代码:
java
@Component
public class LocalCacheUtil {
private static final Logger logger = LoggerFactory.getLogger(LocalCacheUtil.class);
private final Cache<String, String> localCache = Caffeine.newBuilder()
.maximumSize(1000)
.expireAfterWrite(5, TimeUnit.MINUTES)
.build();
public void set(String key, String value) {
try {
localCache.put(key, value);
} catch (Exception e) {
logger.error("LocalCacheUtil error, set({}, {})", key, value, e);
}
}
public String get(String key) {
try {
return localCache.getIfPresent(key);
} catch (Exception e) {
logger.error("LocalCacheUtil error, get({})", key, e);
return null;
}
}
}
java
public List<WinningRecordDTO> getRecords(ShowWinningRecordsParam param) {
String key = null == param.getPrizeId()
? String.valueOf(param.getActivityId())
: param.getActivityId() + "_" + param.getPrizeId();
String cacheKey = WINNING_RECORDS_PREFIX + key;
long startTime = System.currentTimeMillis();
String localCacheValue = localCacheUtil.get(cacheKey);
if (StringUtils.hasText(localCacheValue)) {
log.info("本地缓存获取中奖记录!耗时: {}ms", System.currentTimeMillis() - startTime);
return convetToWinningRecordDTOList(JacksonUtil.readListValue(localCacheValue, WinningRecordDO.class));
}
List<WinningRecordDO> winningRecordDOList = getWinningRecords(key);
}问题2: 本地缓存过快导致本机请求打满
- 现象:本地缓存优化后,接口响应时间仅1ms(无阻力处理),若直接压测,100+ 并发会瞬间打满本机CPU,导致压测数据失真。
- 根因:本地缓存消除了Redis网络延迟,请求处理速度远超系统资源承载上限,无限制请求直接耗尽本机资源。
解决方案: 固定定时器+平滑压测
- 配置:在JMeter中添加固定定时器(100ms),控制每个线程的请求间隔;
- 核心逻辑:并发数不变(仍为100线程),仅控制QPS,避免流量瞬间爆发;
- 效果:压测过程平稳,本机CPU占用率稳定在8%以内,压测数据真实有效。
问题3: 高并发下的流量管控(补充优化)
为进一步保障系统不被超量流量冲击,在业务层新增QPS限流:
- 技术选型:Guava RateLimiter(秒级QPS控制,非阻塞快速失败);
- 配置:每秒限制100个请求进入中奖记录接口,超过阈值直接返回空数据,不排队、不阻塞;
- 效果:避免了本地缓存被无限请求打满,同时保证系统高可用。
六、系统并发能力评估
优化后 ,基于本次200并发梯度加压测试结果,系统在优化后的性能表现如下:
| 核心指标 | 结果 | 说明 |
|---|---|---|
| 最大并发数 | 200(稳定运行) | 200并发下无报错、无超时,系统无雪崩风险 |
| 峰值吞吐量 | 约910 / sec(整体) | 单接口最高可达183+ /sec |
| 平均响应时间 | 9ms(整体) | 核心接口平均响应时间仅5-18ms,用户体验极佳 |
| 响应时间99分位 | ≤32ms | 无长尾延迟,服务稳定性极高 |
| 错误率 | 0% | 全程无接口异常、无超时,服务健壮 |
结论: 优化后,系统在200并发压力下表现稳定,核心接口的响应时间和吞吐量均达到了生产级高并发系统的标准,能够轻松支撑业务高峰期的流量需求。
-
优化效果显著,性能提升明显,通过引入本地缓存替代远程Redis调用,核心接口的响应时间从优化前的60ms+降至1ms以内,性能提升超过5倍,解决了原系统的关键瓶颈。
-
200并发下服务稳定,满足业务需求,在200并发梯度加压场景下,系统全程无报错、无超时,响应时间波动极小,无性能拐点,证明优化后的系统完全具备支撑业务高峰期流量的能力。
-
系统具备一定的性能冗余空间,从测试曲线来看,系统在200并发下的CPU、内存资源占用率仍有冗余,响应时间和吞吐量曲线平滑,未出现明显拐点,具备支撑更高并发压力的潜力。
七、压测总结与后续优化方向
7.1 核心结论
本次抽奖系统压测完整验证了"梯度加压+平滑压测"方案的有效性,最终达成以下成果:
- 系统稳定支撑200并发,异常率0%,响应时间控制在合理范围;
- 定位并解决中奖记录接口Redis远程延迟瓶颈,性能得到大幅提升;
- 掌握了"本地缓存过快打满本机"的解决方案:固定定时器+QPS限流;
7.2 压测避坑经验
- ❌ 拒绝暴力压测:无定时器、无梯度的瞬间高并发压测,会导致压测数据失真,无法反映系统真实性能;
- ❌ 避免盲目限流:阻塞式限流(如Semaphore.acquire())会导致请求堆积,应采用非阻塞快速失败限流;
- ✅ 梯度加压是核心:逐步提升并发数,才能精准定位系统性能拐点;
- ✅ 本地缓存需配套限流:接口速度越快,越需要控制请求频率,避免打满本机/服务器。
7.3 后续优化方向
- 进一步提升并发至500,验证系统极限性能;
- 引入多级缓存(本地缓存+Redis集群),提升热点数据访问效率;
- 增加限流熔断机制,应对大促突发流量。
结尾
本次抽奖系统压测全程基于真实场景,从问题定位到优化落地,再到压测方案迭代,完整还原了高并发应用压测的全流程。所有压测数据均可复现,优化方案具备强落地性,希望能为各位开发者在高并发系统性能测试中提供参考。后续将持续跟进系统性能优化,输出更多实战干货!