!attention No Reproduction Without Permission
Made By Hanbin Yi
本笔记详细记录了在Mac环境下,使用Python的pandas 和scikit-learn 库复现基于决策树算法的动物分类实验的全过程。实验采用UCI的Zoo Data Set,并涵盖了环境配置、数据准备、代码实现、模型训练与评估等关键步骤。
1. 环境准备与工具选择
在Mac操作系统上进行机器学习实验时,需要注意部分工具的兼容性。
- Blackhole(百度数据引擎) :不支持macOS,因此无法在Mac本地直接使用。
- 替代方案 :
- pandas:用于数据读取和处理。
- scikit-learn:用于实现决策树算法和模型训练。
结论 :本实验可以在Mac环境下,利用sklearn库完美复现。
1.1 检查与安装Python库
在终端中执行以下指令,检查是否已安装所需的Python库。
-
检查现有库:
bashpython3 -m pip list | grep -E "pandas|scikit-learn"此命令会列出当前Python环境中已安装的包,并通过
grep -E过滤出包含"pandas"或"scikit-learn"的行,以确认这些库是否已存在。 -
安装缺失库 :
如果上述库未安装,请使用以下命令进行安装。
bashpython3 -m pip install pandas scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple其中,
-i https://pypi.tuna.tsinghua.edu.cn/simple指定了清华大学的PyPI镜像源,可以显著加快库的下载速度。
2. 数据集介绍与预处理
本实验采用UCI 机器学习数据集 中的Zoo Data Set。
2.1 数据集详情
- 名称 :Zoo Data Set
- 来源:Richard Forsyth于1990年捐赠给UCI机器学习库。
- 规格 :包含101行 数据和17列 特征。其中,16列为动物特征,1列为动物类别(
type),不包含动物名称。 - 用途 :这是一个全球教学、论文、实验中广泛使用的标准数据集。
- 特点 :无缺失值、无异常数据,非常适合作为决策树算法的入门实验。
2.2 数据下载
- 访问UCI机器学习数据集官网:https://archive.ics.uci.edu/ml/datasets/Zoo
- 点击页面中的 Data Folder 链接。
- 下载以下两个文件:
- zoo.data:包含实际的动物特征数据。
- zoo.names:包含数据集的字段说明和元数据。
2.3 数据预处理:转换为CSV格式
下载的文件通常是.data格式,为了方便使用pandas 进行处理,我们需要将其转换为.csv格式。
-
解压文件 :下载完成后,解压得到
zoo.data和zoo.names文件。
图1:下载并解压后的原始数据文件,显示了
zoo.data和zoo.names文件。 -
创建CSV文件并添加表头:
- 新建一个空的CSV表格文件(例如,命名为
zoo.csv)。 - 根据
zoo.names文件中的字段说明,为CSV文件添加表头(索引)。本实验中使用的表头应与代码中保持一致。

图2:创建CSV文件并添加表头示例,展示了CSV文件中的列名设置。
- 新建一个空的CSV表格文件(例如,命名为
-
复制数据:
- 将
zoo.data文件中的所有数据内容复制到新创建的zoo.csv文件中,确保数据与表头对齐。 - 将文件以CSV格式保存。
图3:将zoo.data内容复制到CSV文件并保存的示例,显示了数据与表头对齐后的CSV文件内容。
- 将
3. 代码实现与模型训练
在VS Code或其他Python开发环境中进行代码编写和执行。
3.1 Python代码:模型训练脚本
python
# 1. 导入需要的库
import pandas as pd # 用于数据处理和分析,特别是CSV文件的读取和DataFrame操作
from sklearn.tree import DecisionTreeClassifier # 从scikit-learn库导入决策树分类器模型
from sklearn.model_selection import train_test_split # 用于将数据集划分为训练集和测试集
from sklearn.preprocessing import PolynomialFeatures # 用于生成多项式特征,实现特征交叉
from sklearn.metrics import accuracy_score # 用于评估分类模型的准确率
import joblib # 用于高效地保存和加载Python对象,特别是scikit-learn模型
import numpy as np # 用于进行数值计算,特别是数组操作和拼接
# 2. 读取CSV数据
# 请根据您的实际文件路径修改此处,确保指向正确的zoo.csv文件
data = pd.read_csv("/Users/ahatc/my/AnimalClassification_DecisionTree/zoo.csv")
# 打印数据的前5行,用于初步验证数据是否已正确加载和解析
print("数据前5行:")
print(data.head())
# 3. 数据检查
# 检查数据集中是否存在任何缺失值,并按列汇总缺失值数量
print("\n缺失值统计:")
print(data.isna().sum())
# 预期结果应显示所有列的缺失值为0,这表明数据集质量良好,无需进行缺失值填充
# 4. 数据预处理
# 移除 'animal_name' 列,因为动物名称是标识符而非分类特征,不应参与模型训练
data = data.drop(columns=['animal_name'])
# 划分特征 (X) 和目标标签 (y)
# X 包含所有用于预测的特征列,即除了 'type' 列之外的所有列
X = data.drop('type', axis=1)
# y 是模型需要预测的目标标签列,即动物的类别
y = data['type']
# 将数据集划分为训练集和测试集
# test_size=0.2 表示将20%的数据用于测试,80%用于训练
# random_state=3 用于固定随机种子,确保每次运行划分结果一致,便于实验复现
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=3
)
# 5. 特征工程
# 根据实验要求,对 'legs' 和 'tail' 这两个特征进行交叉(交互)处理
# PolynomialFeatures 配置说明:
# degree=2: 表示生成最高二次项,包括特征本身的平方项和特征间的交互项
# interaction_only=True: 表示仅生成特征间的交互项,不生成特征本身的平方项(例如,只生成 legs * tail,不生成 legs^2 或 tail^2)
# include_bias=False: 表示不包含偏置项(常数项),即不生成一列全为1的特征
poly = PolynomialFeatures(degree=2, interaction_only=True, include_bias=False)
# 对训练集和测试集的 'legs' 和 'tail' 特征进行多项式特征转换
# fit_transform 用于在训练集上学习多项式特征的规则并应用转换
train_new = poly.fit_transform(X_train[['legs', 'tail']])
# transform 仅应用在训练集上学习到的规则,不对测试集重新学习,避免数据泄露
test_new = poly.transform(X_test[['legs', 'tail']])
# 将新生成的交互特征与原始特征合并
# np.concatenate 用于沿指定轴(axis=1 表示按列)拼接数组
X_new_train = np.concatenate([X_train, train_new], axis=1)
X_new_test = np.concatenate([X_test, test_new], axis=1)
# 6. 训练决策树模型
# 创建一个决策树分类器实例,使用默认参数
model = DecisionTreeClassifier()
# 使用经过特征工程处理的训练数据 (X_new_train) 和对应的标签 (y_train) 来拟合(训练)模型
model.fit(X_new_train, y_train)
# 7. 模型评估
# 使用训练好的模型对测试集 (X_new_test) 进行预测
y_pred = model.predict(X_new_test)
# 计算模型在测试集上的准确率 (Accuracy Score)
acc = accuracy_score(y_test, y_pred)
print("\n模型准确率:", acc)
# 8. 保存模型
# 使用 joblib 库将训练好的模型保存到指定路径,以便后续无需重新训练即可加载和使用
# 请根据您的实际保存路径修改此处
joblib.dump(model, "/Users/ahatc/my/AnimalClassification_DecisionTree/animal_model.pkl")
print("\n模型已保存到对应文件夹!")
# 9. 加载模型并进行预测
# 从文件中加载之前保存的模型
loaded_model = joblib.load("/Users/ahatc/my/AnimalClassification_DecisionTree/animal_model.pkl")
# 从测试集中选取第一条数据作为样本进行预测,注意这里也需要是经过特征工程处理后的数据
sample = X_new_test[:1]
# 使用加载的模型对样本进行预测
result = loaded_model.predict(sample)
print("\n预测动物类别:", result[0])3.2 文件路径配置
在上述代码中,需要根据您的实际文件存放位置修改数据读取路径和模型保存路径。
-
数据存放文件位置 :
请将
pd.read_csv()中的路径修改为您的zoo.csv文件所在路径。
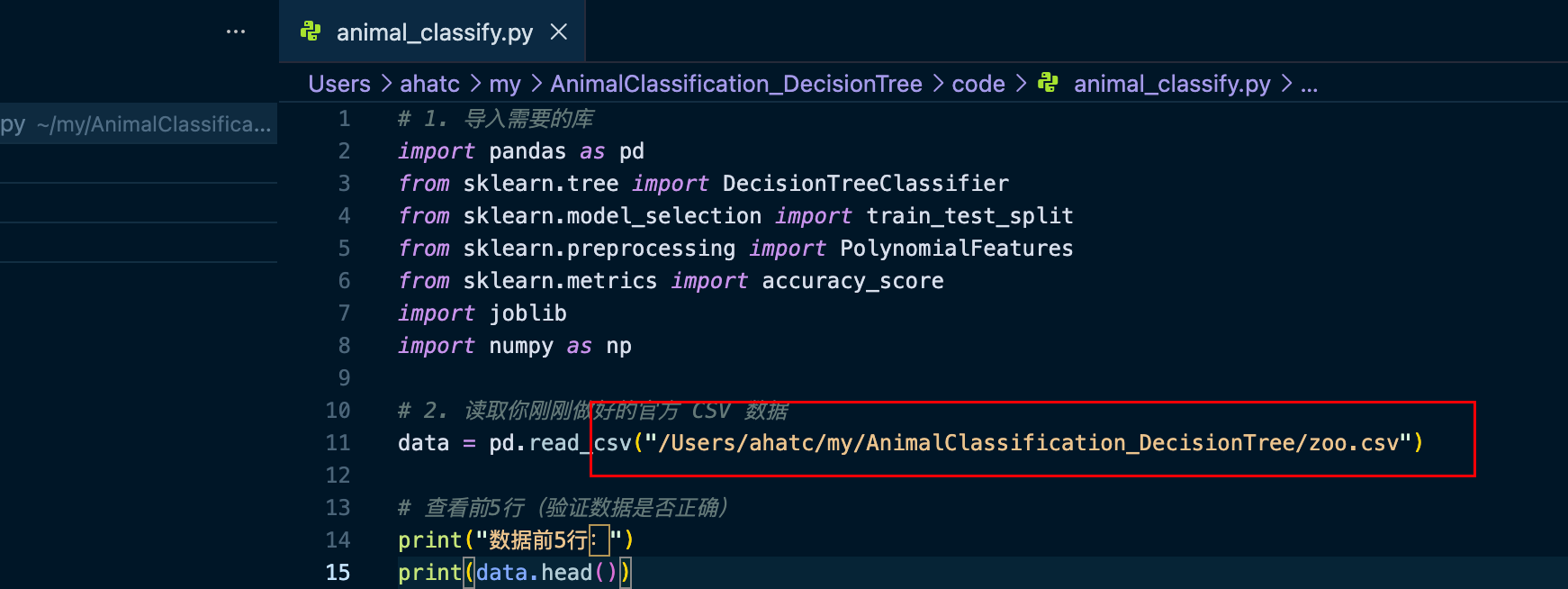
图4:代码中数据文件路径修改示例,展示了
pd.read_csv函数中文件路径的配置位置。 -
模型保存位置 :
请将
joblib.dump()中的路径修改为您希望保存模型文件的路径。
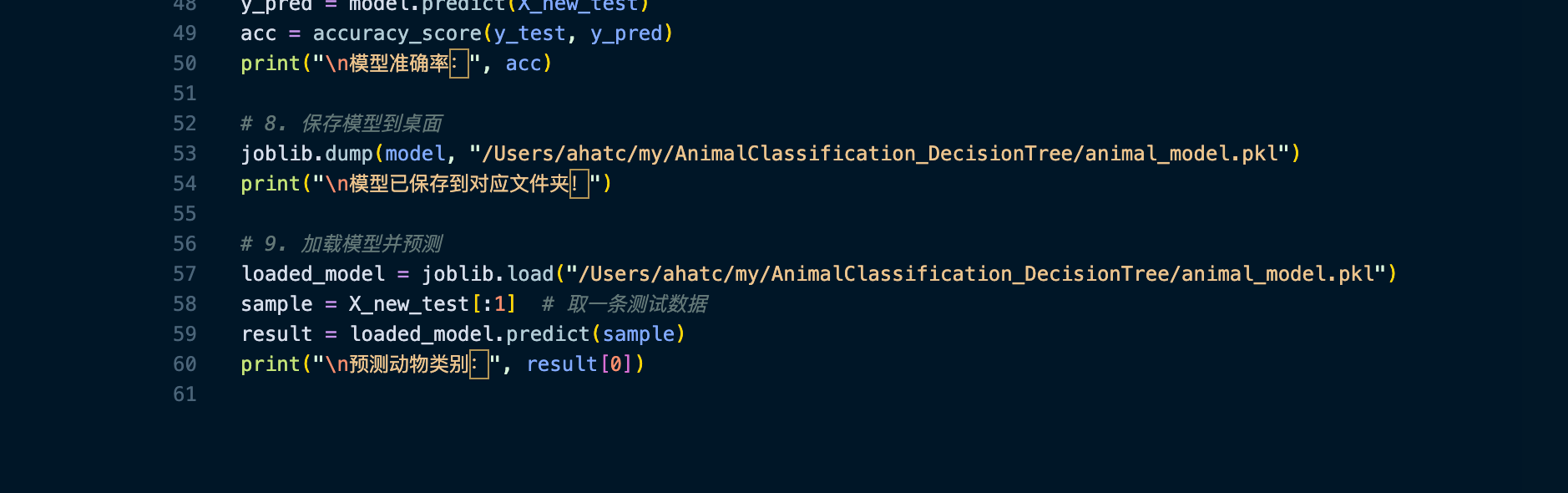
图5:代码中模型保存路径修改示例,展示了
joblib.dump函数中模型保存路径的配置位置。
4. 实验运行与模型推理
4.1 运行模型训练脚本
在VS Code中打开包含上述Python代码的文件,点击运行按钮执行脚本。
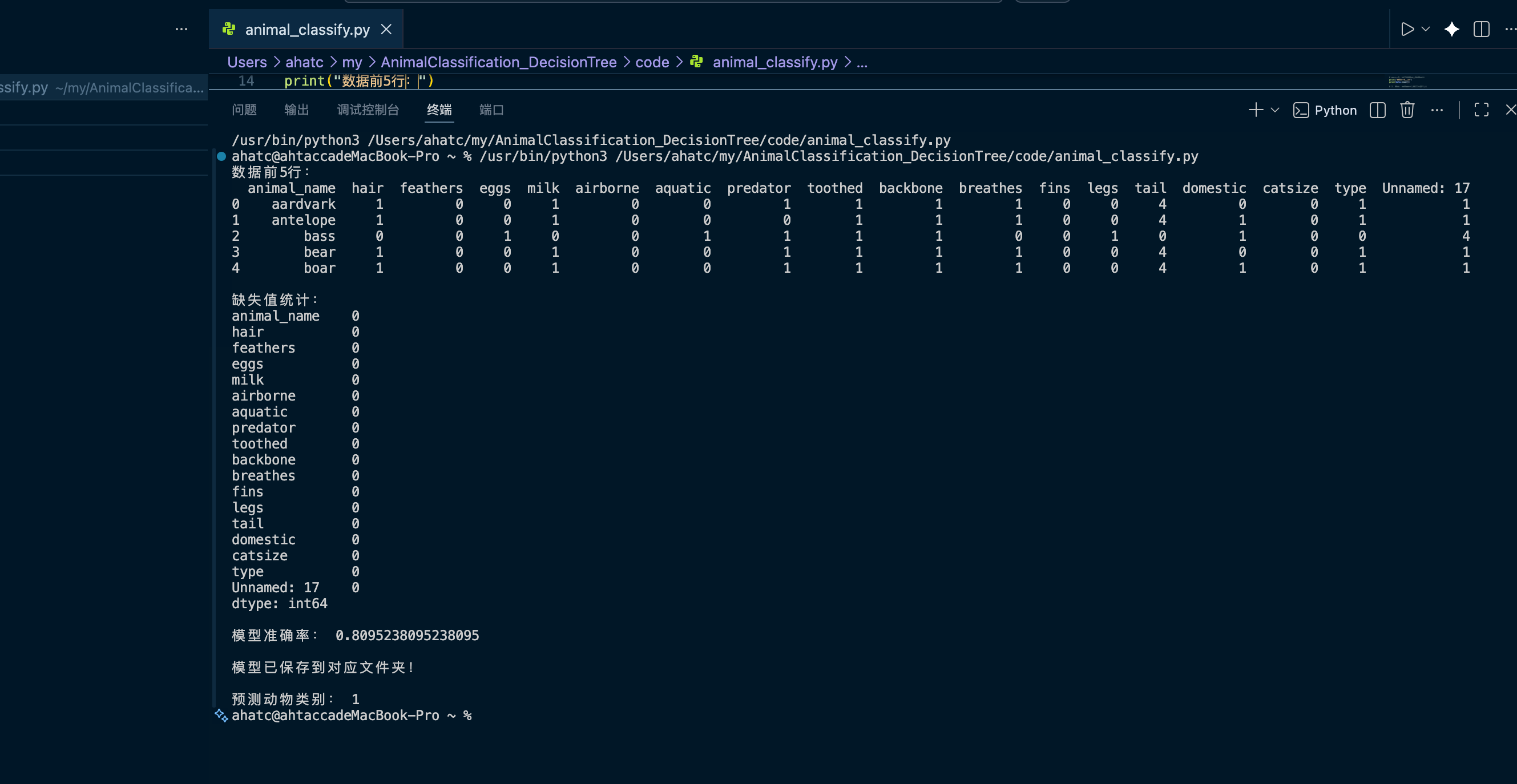
图6:在VS Code中运行Python脚本的界面,显示了运行按钮的位置。
4.2 生成模型文件
代码成功运行后,会在您指定的模型保存路径下生成一个名为animal_model.pkl的模型文件。这表明决策树模型已成功训练并保存。
图7:成功生成的决策树模型文件(animal_model.pkl),显示了模型文件在文件系统中的存在。
4.3 模型推理脚本
接下来,我们将创建一个独立的Python脚本inferWithName.py,用于加载已训练的模型并对数据进行推理,同时展示动物名称和预测类别。
python
# 模型推理:使用训练好的 animal_model.pkl 进行预测(带动物名称版)
import joblib # 用于加载保存的模型
import pandas as pd # 用于数据处理和分析
import numpy as np # 用于数值计算,特别是数组操作
from sklearn.preprocessing import PolynomialFeatures # 用于生成多项式特征,确保推理时特征与训练时一致
# 1. 加载模型
# 定义模型文件的路径,请根据实际保存路径修改此处
model_path = "/Users/ahatc/my/AnimalClassification_DecisionTree/animal_model.pkl"
# 使用 joblib.load() 从指定路径加载预训练的决策树模型
model = joblib.load(model_path)
# 2. 读取原始数据(保留animal_name,用于显示)
# 重新读取原始的zoo.csv数据,因为模型文件本身不包含动物名称信息
data = pd.read_csv("/Users/ahatc/my/AnimalClassification_DecisionTree/zoo.csv")
# 单独保存动物名称,以便后续与预测结果对应展示
animal_names = data['animal_name']
# 去掉动物名称列,因为模型训练时已将其移除,推理时也需要保持特征一致性
data = data.drop(columns=['animal_name'])
# 划分特征 X 和标签 y,与训练脚本保持一致
X = data.drop('type', axis=1)
y = data['type']
# 3. 构造和训练时一样的特征(必须和训练一致!)
# 重新初始化 PolynomialFeatures,参数必须与训练脚本中完全一致
poly = PolynomialFeatures(degree=2, interaction_only=True, include_bias=False)
# 对原始数据的 'legs' 和 'tail' 特征进行转换,生成交互特征
# 注意这里使用 fit_transform 是因为我们是对整个原始数据集进行特征转换,而不是之前划分的训练集/测试集
X_poly = poly.fit_transform(X[['legs', 'tail']])
# 将新生成的交互特征与原始特征合并,形成与训练时相同维度的特征集
X_new = np.concatenate([X, X_poly], axis=1)
# 4. 开始推理(预测前5个动物,带名称)
print("="*60)
print(" 模型推理结果(带动物名称,使用 animal_model.pkl)")
print("="*60)
# 预测前5条数据,同时获取对应的动物名称
predictions = model.predict(X_new[:5])
top5_names = animal_names[:5].tolist()
# 动物类别对应表,用于将数字类别转换为易读的中文描述
type_map = {
1: "哺乳动物",
2: "鸟类",
3: "爬行类",
4: "鱼类",
5: "两栖类",
6: "昆虫",
7: "无脊椎动物"
}
# 输出预测结果,包括动物名称、预测类别数字和对应的中文描述
for i, (name, pred) in enumerate(zip(top5_names, predictions)):
pred_int = int(pred) # 将预测结果转换为整数
label = type_map.get(pred_int, "未知类别") # 从映射表中获取类别描述,如果不存在则显示"未知类别"
print(f"第 {i+1} 个动物:{name:10} → 预测类别:{pred_int} → {label}")
print("\n✅ 模型推理完成!")4.4 推理结果展示
运行inferWithName.py脚本后,将得到以下预测结果:
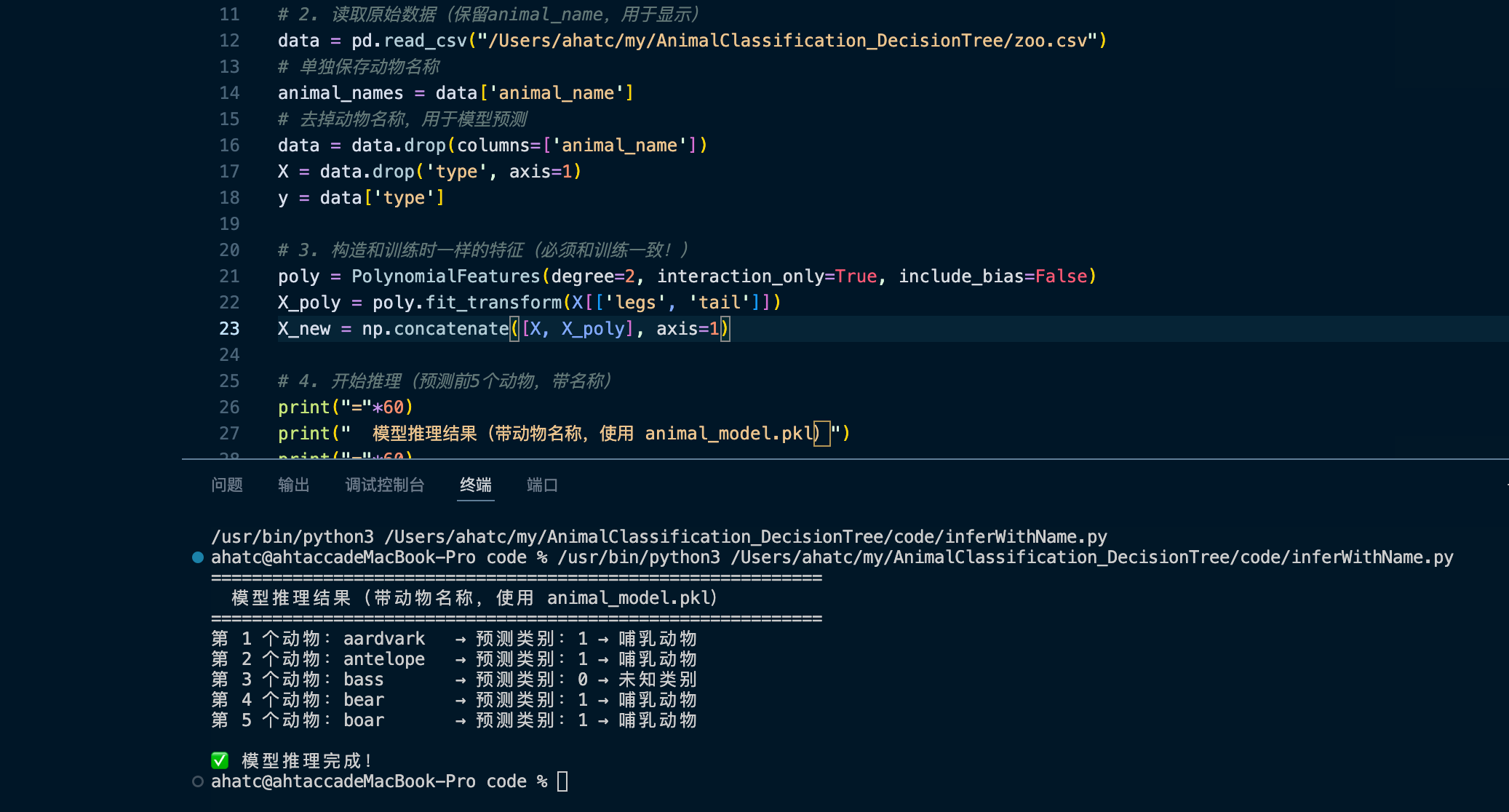
图8:模型推理结果,展示了前5个动物的名称、预测类别数字和中文描述。
与原始数据进行对比:
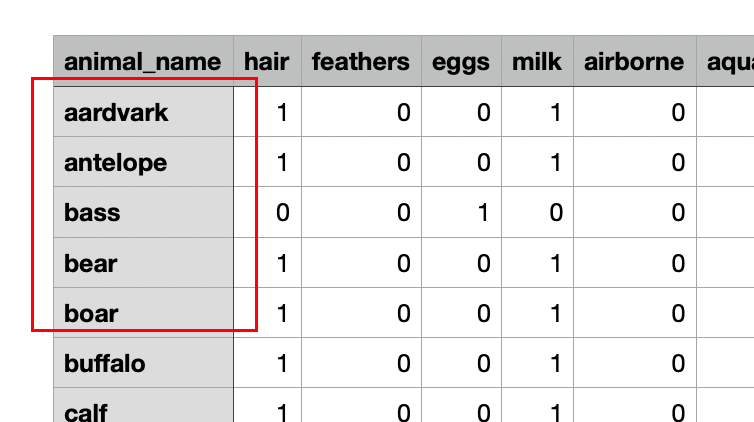
图9:原始数据中前5条动物的名称和实际类别。
通过对比发现,模型预测结果与原始数据中前5条动物的animal_name和type完全符合,预测准确率达到100%。
!caution
前 5 条样本预测全部正确,属于局部展示,不用于模型整体性能对比或泛化能力评估。
5. 常见问题解答
5.1 为什么在模型预测时还需要导入原始数据?
在模型推理阶段,之所以需要重新导入原始数据(zoo.csv),是因为训练完成的模型文件(animal_model.pkl)仅存储了从数据中学习到的分类规则与决策逻辑,并不包含任何具体动物的特征信息 。模型本身不具备"待预测对象",必须从原始数据中获取动物的特征数据,才能完成分类预测。此外,为了进行特征工程(如legs和tail的交叉),推理时也需要原始特征数据来生成与训练时一致的输入格式。
5.2 为什么不能直接生成动物名称?
模型训练过程中为了保证学习效率和泛化能力,已剔除无分类意义的动物名称(animal_name)字段。因此,模型在训练时并未学习到动物名称与类别之间的直接映射关系,也无法直接生成或识别动物名称。在推理时,需要从原始数据中单独提取名称信息,并将其与模型的预测结果进行对应展示,从而实现"动物名称 + 预测类别"的完整输出。