
目录
[一、LangChain 概述与核心架构](#一、LangChain 概述与核心架构)
[1.1 什么是 LangChain?](#1.1 什么是 LangChain?)
[1.2 六大核心模块](#1.2 六大核心模块)
[1.3 为什么需要 LangChain?](#1.3 为什么需要 LangChain?)
[2.1 安装与环境配置](#2.1 安装与环境配置)
[2.2 第一个 LangChain 程序:基础问答](#2.2 第一个 LangChain 程序:基础问答)
[2.3 理解 LCEL:LangChain 的新一代语法](#2.3 理解 LCEL:LangChain 的新一代语法)
[2.4 流式输出实现](#2.4 流式输出实现)
[2.5 结构化输出解析](#2.5 结构化输出解析)
[3.1 提示词模板(Prompts)](#3.1 提示词模板(Prompts))
[3.2 记忆组件(Memory)](#3.2 记忆组件(Memory))
[3.3 文档加载与处理(RAG 基础)](#3.3 文档加载与处理(RAG 基础))
[3.4 链(Chains)的进阶用法](#3.4 链(Chains)的进阶用法)
[3.5 智能体(Agents)](#3.5 智能体(Agents))
[3.6 回调系统(Callbacks)](#3.6 回调系统(Callbacks))
前言
你是否曾想过,将大语言模型(LLM)的强大能力集成到自己的应用中,却不知从何下手?你是否在尝试调用各种 AI 接口时,被繁琐的提示词管理、上下文记忆和工具调用问题困扰?LangChain 正是为解决这些痛点而生的框架。
作为 2024-2025 年最热门的大模型应用开发框架,LangChain 已成为 AI 工程师的必备技能。它不是一个独立的模型服务,而是一个编排框架------就像乐高积木的说明书,帮你把各种"AI 积木"(模型、数据、工具)巧妙地组合起来,构建复杂的智能应用。
本文将带你从零开始,系统学习 LangChain 的核心概念与实战技巧。无论你是后端、前端还是运维工程师,只要对 AI 应用开发感兴趣,这篇文章都适合你。我们会通过大量可运行的代码示例,让你在实践中掌握这一强大工具。
一、LangChain 概述与核心架构
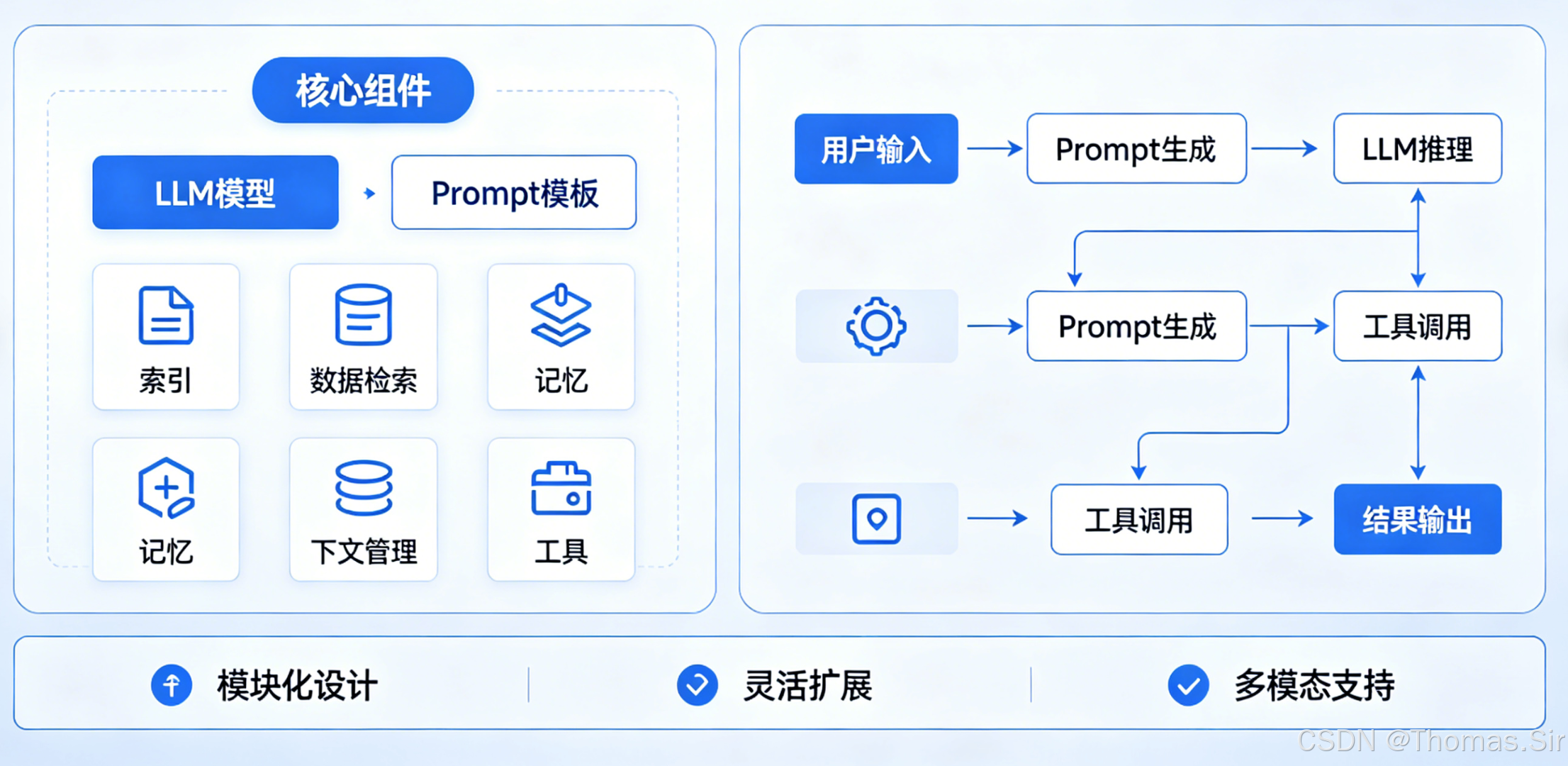
1.1 什么是 LangChain?
LangChain 是一个用于开发由大语言模型驱动的应用程序的开源框架。它由 Harrison Chase 于 2022 年创建,旨在简化 LLM 应用的开发流程。简单来说,LangChain 解决了三个核心问题:
标准化接口:统一调用不同提供商(OpenAI、阿里云、本地模型等)的 LLM
上下文增强:让 LLM 能够访问外部数据源(文档、数据库、API)
任务编排:将多个 LLM 调用和工具使用组合成复杂的工作流
1.2 六大核心模块
LangChain 采用模块化设计,主要包括以下六个组件:
| 模块 | 核心作用 | 典型应用 |
|---|---|---|
| 模型 I/O | 标准化 LLM 交互接口 | 统一调用多模型、提示词模板化 |
| 数据增强 | 提升输入数据质量 | 文档加载、文本分割、RAG |
| 链(Chains) | 构建可复用任务流程 | 多步骤任务组合 |
| 记忆(Memory) | 维护上下文状态 | 多轮对话、历史记录 |
| 智能体(Agents) | 动态决策与工具调度 | 自动选择工具、复杂推理 |
| 回调(Callbacks) | 全链路监控与可观测性 | 日志记录、性能分析 |
1.3 为什么需要 LangChain?
你可能会问:"直接调用 OpenAI API 不就行了吗?"确实,对于简单的问答,几行代码就能搞定。但当你的需求变得复杂时,LangChain 的价值就体现出来了:
多轮对话:需要手动管理消息历史,LangChain 提供了开箱即用的记忆组件
文档问答:需要分割文档、生成嵌入向量、检索相关片段,LangChain 封装了整个流程
工具调用:需要让 LLM 决定调用哪个 API、如何传参,LangChain 的 Agent 能自动处理
二、环境搭建与基础使用
2.1 安装与环境配置
首先,创建一个干净的 Python 环境并安装必要的包:
bash
# 创建虚拟环境(推荐)
python -m venv langchain-env
source langchain-env/bin/activate # Linux/Mac
# langchain-env\Scripts\activate # Windows
# 安装核心依赖
pip install langchain langchain-openai python-dotenv注意 :截至 2025 年底,LangChain 已更新至 0.3+ 版本,旧版的
langchain.llms等模块已移至子包。本文使用最新的 API 写法。
创建 .env 文件存放 API 密钥:
OPENAI_API_KEY=your-api-key-here
# 如果使用国内服务,例如阿里云百炼
DASHSCOPE_API_KEY=your-dashscope-key2.2 第一个 LangChain 程序:基础问答
让我们从一个简单的例子开始,感受 LangChain 的工作方式:
python
# demo_01_basic_chain.py
"""
基础问答链示例
演示如何使用 LangChain 创建最简单的 LLM 调用链
"""
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.schema.runnable import RunnableSequence
# 加载环境变量
load_dotenv()
# 1. 初始化模型
# temperature=0.7 控制输出的随机性,0 最确定,1 最随机
llm = ChatOpenAI(
model="gpt-3.5-turbo", # 使用的模型名称
temperature=0.7, # 创造力程度
api_key=os.getenv("OPENAI_API_KEY")
)
# 2. 定义提示词模板
# 使用 {topic} 作为变量占位符
prompt = PromptTemplate.from_template(
"用一句话解释什么是{topic},要求通俗易懂。"
)
# 3. 构建链(现代写法:使用 | 管道操作符)
# 这是 LCEL (LangChain Expression Language) 的核心语法
chain = prompt | llm
# 4. 执行链
result = chain.invoke({"topic": "机器学习"})
# 输出结果
print("回答:", result.content)
print("---")
print("响应元数据:", result.response_metadata)运行结果示例:
回答: 机器学习就是让电脑通过分析大量数据自动学习规律,不需要人类一步步教它怎么做。
响应元数据: {'token_usage': {...}, 'model_name': 'gpt-3.5-turbo', ...}
2.3 理解 LCEL:LangChain 的新一代语法
2024 年后,LangChain 主推 LCEL(LangChain Expression Language) ,它使用 | 管道操作符组合组件,代码更简洁、更易读:
python
# 旧版写法(已弃用,仅供参考)
# from langchain.chains import LLMChain
# chain = LLMChain(llm=llm, prompt=prompt)
# 新版 LCEL 写法
chain = prompt | llm | output_parser # 可串联多个组件LCEL 的核心优势:
函数式组合 :用
|直观表达数据流自动并行:多个独立分支可自动并行执行
原生流式支持 :
.stream()方法直接可用完美集成 LangSmith:自动记录每一步的执行细节
2.4 流式输出实现
流式输出能显著提升用户体验,让用户感觉模型在"实时思考":
python
# demo_02_streaming.py
"""
流式输出示例
让模型一个字一个字地返回结果,提升交互体验
"""
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate
load_dotenv()
llm = ChatOpenAI(
model="gpt-3.5-turbo",
temperature=0.8,
streaming=True # 开启流式输出
)
prompt = PromptTemplate.from_template("请写一首关于编程的短诗,主题是{topic}")
chain = prompt | llm
print("=== 流式输出效果 ===\n")
# 使用 stream 方法逐块获取输出
for chunk in chain.stream({"topic": "Python"}):
# chunk.content 是每次返回的文本片段
print(chunk.content, end="", flush=True)
print("\n\n=== 输出完成 ===")2.5 结构化输出解析
很多时候,我们希望 LLM 返回格式化的数据(如 JSON),便于程序处理:
python
# demo_03_structured_output.py
"""
结构化输出示例
让 LLM 返回 JSON 格式的数据,便于程序解析
"""
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
load_dotenv()
# 1. 定义期望的输出格式
response_schemas = [
ResponseSchema(name="name", description="菜品的名称"),
ResponseSchema(name="ingredients", description="主要食材列表,用数组表示"),
ResponseSchema(name="cooking_time", description="烹饪时间(分钟)"),
ResponseSchema(name="difficulty", description="难度等级:简单/中等/困难")
]
# 创建输出解析器
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
# 2. 获取格式化指令(会自动生成要求 LLM 输出 JSON 的提示)
format_instructions = output_parser.get_format_instructions()
# 3. 构建包含格式要求的提示词
prompt = PromptTemplate(
template="""请推荐一道{cuisine}菜系的家常菜。
{format_instructions}
请直接返回 JSON,不要有其他内容。""",
input_variables=["cuisine"],
partial_variables={"format_instructions": format_instructions}
)
# 4. 执行并解析
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.5)
chain = prompt | llm | output_parser
result = chain.invoke({"cuisine": "川菜"})
print("解析后的结构化数据:")
print(f"菜名: {result['name']}")
print(f"食材: {', '.join(result['ingredients'])}")
print(f"烹饪时间: {result['cooking_time']}分钟")
print(f"难度: {result['difficulty']}")三、核心组件深入
3.1 提示词模板(Prompts)
提示词模板是 LangChain 的基础组件,它帮助我们将用户输入和固定指令组合成完整的提示词。
python
# demo_04_prompt_templates.py
"""
提示词模板的高级用法
演示 Few-shot 学习和动态模板
"""
from langchain.prompts import (
PromptTemplate,
FewShotPromptTemplate,
ChatPromptTemplate,
MessagesPlaceholder
)
from langchain_openai import ChatOpenAI
# 示例 1:Few-shot 学习模板
examples = [
{"question": "什么是 Python?", "answer": "Python 是一种解释型、面向对象的高级编程语言。"},
{"question": "什么是 Django?", "answer": "Django 是 Python 的一个 Web 框架,遵循 MVC 设计模式。"}
]
example_template = """
问题: {question}
回答: {answer}
"""
example_prompt = PromptTemplate(
input_variables=["question", "answer"],
template=example_template
)
few_shot_prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
prefix="你是一个技术专家,请用专业但易懂的方式回答问题。\n\n示例:",
suffix="\n问题: {input}\n回答:",
input_variables=["input"]
)
# 测试 Few-shot 模板
print("=== Few-shot 模板效果 ===")
print(few_shot_prompt.format(input="什么是 FastAPI?"))
# 示例 2:对话式提示词模板(包含历史消息占位符)
chat_prompt = ChatPromptTemplate.from_messages([
("system", "你是一个友好的助手,名字叫{bot_name}。"),
MessagesPlaceholder(variable_name="history"), # 动态插入历史消息
("human", "{input}"),
])
print("\n=== 对话式模板 ===")
print(chat_prompt.format(bot_name="小助手", input="你好"))3.2 记忆组件(Memory)
记忆是构建对话式 AI 的关键。LangChain 提供了多种记忆策略:
python
# demo_05_memory.py
"""
记忆组件完整示例
演示多种记忆策略的使用
"""
from langchain.memory import (
ConversationBufferMemory,
ConversationBufferWindowMemory,
ConversationTokenBufferMemory,
ConversationSummaryMemory
)
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.schema.runnable import RunnableLambda
import os
from dotenv import load_dotenv
load_dotenv()
llm = ChatOpenAI(model="gpt-3.5-turbo")
# ========== 1. 缓冲区记忆(保留全部历史)==========
buffer_memory = ConversationBufferMemory(
return_messages=True,
memory_key="history"
)
# 添加对话示例
buffer_memory.save_context(
{"input": "我叫张三"},
{"output": "你好张三!很高兴认识你。"}
)
buffer_memory.save_context(
{"input": "我喜欢编程"},
{"output": "太棒了!编程是一项很有价值的技能。"}
)
print("=== 缓冲区记忆内容 ===")
print(buffer_memory.load_memory_variables({}))
# ========== 2. 窗口记忆(只保留最近 K 轮)==========
window_memory = ConversationBufferWindowMemory(
k=2, # 只保留最近 2 轮对话
return_messages=True
)
# ========== 3. Token 限制记忆(基于 token 数量截断)==========
# 适用于控制 API 调用成本
token_memory = ConversationTokenBufferMemory(
llm=llm,
max_token_limit=100, # 最多保留 100 个 token
return_messages=True
)
# ========== 4. 摘要记忆(自动生成对话摘要)==========
summary_memory = ConversationSummaryMemory(
llm=llm,
return_messages=True
)
summary_memory.save_context(
{"input": "我想预订一张去北京的机票"},
{"output": "好的,请问您什么时候出发?"}
)
summary_memory.save_context(
{"input": "下周一早上"},
{"output": "已为您查询下周一早上飞往北京的航班。"}
)
print("\n=== 摘要记忆自动生成的摘要 ===")
print(summary_memory.load_memory_variables({}))
# ========== 5. 在链中使用记忆 ==========
# 创建包含记忆的对话链
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个友好的助手。"),
MessagesPlaceholder(variable_name="history"),
("human", "{input}")
])
# 使用 RunnableLambda 包装记忆加载
def load_memory(input_dict):
history = buffer_memory.load_memory_variables({})
return {
"history": history.get("history", []),
"input": input_dict["input"]
}
chain = RunnableLambda(load_memory) | prompt | llm
print("\n=== 使用记忆的对话 ===")
result = chain.invoke({"input": "我叫什么名字?"})
print(result.content)
# 输出会正确回答:张三3.3 文档加载与处理(RAG 基础)
RAG(检索增强生成)是 LangChain 最强大的应用场景之一。它让 LLM 能够基于你自己的文档回答问题。
python
# demo_06_rag_basic.py
"""
RAG 基础示例
从本地文档构建知识库,实现文档问答
需要先安装: pip install langchain-community chromadb pypdf
"""
import os
from dotenv import load_dotenv
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_community.document_loaders import TextLoader, PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain.chains import RetrievalQA
load_dotenv()
# 1. 加载文档(支持多种格式)
# 示例:加载文本文件
loader = TextLoader("knowledge.txt", encoding="utf-8")
# 如果是 PDF: loader = PyPDFLoader("document.pdf")
documents = loader.load()
print(f"加载了 {len(documents)} 个文档片段")
# 2. 文本分割
# 由于 LLM 有上下文长度限制,需要将长文档切分成小块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 每个块的最大字符数
chunk_overlap=50, # 块之间的重叠字符数(保持上下文连贯)
separators=["\n\n", "\n", "。", "!", "?", ";", " ", ""]
)
chunks = text_splitter.split_documents(documents)
print(f"文档被分割成 {len(chunks)} 个块")
# 3. 创建向量嵌入
# 将文本转换为向量,便于语义检索
embeddings = OpenAIEmbeddings()
# 4. 创建向量数据库(使用 Chroma)
# 向量数据库会存储文本块及其对应的向量表示
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="./chroma_db" # 持久化存储路径
)
print("向量数据库创建完成")
# 5. 创建检索器
retriever = vectorstore.as_retriever(
search_kwargs={"k": 3} # 每次检索返回最相关的 3 个块
)
# 6. 构建检索问答链
qa_chain = RetrievalQA.from_chain_type(
llm=ChatOpenAI(model="gpt-3.5-turbo", temperature=0),
chain_type="stuff", # stuff: 将所有检索结果放入上下文
retriever=retriever,
return_source_documents=True, # 返回引用的文档片段
verbose=True
)
# 7. 提问
question = "文档中提到了哪些关键技术?"
result = qa_chain.invoke({"query": question})
print(f"\n问题: {question}")
print(f"回答: {result['result']}")
print(f"\n引用来源: {len(result['source_documents'])} 个片段")知识库文件示例(knowledge.txt):
LangChain 是一个用于开发大语言模型应用的框架,于 2022 年发布。
它的核心组件包括模型 I/O、检索、链、记忆和智能体。
RAG(检索增强生成)是 LangChain 的重要功能,它允许 LLM 访问外部知识库。
RAG 的流程包括:文档加载、文本分割、向量化、检索和生成。
LCEL(LangChain 表达式语言)是 2024 年推出的新语法,使用管道操作符组合组件。
3.4 链(Chains)的进阶用法
链可以将多个步骤组合成一个可复用的工作流:
python
# demo_07_chains_advanced.py
"""
链的高级用法
演示顺序链、条件链和自定义链
"""
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.schema.runnable import RunnableLambda, RunnableBranch
from langchain_core.output_parsers import StrOutputParser
import os
from dotenv import load_dotenv
load_dotenv()
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.5)
parser = StrOutputParser()
# ========== 1. 顺序链:多步骤处理 ==========
# 场景:用户评价 → 情感分析 → 生成回复
# 步骤1:情感分析
sentiment_prompt = PromptTemplate.from_template(
"分析以下用户评价的情感是正面、负面还是中性:\n'{review}'\n只输出:正面/负面/中性"
)
sentiment_chain = sentiment_prompt | llm | parser
# 步骤2:根据情感生成回复
reply_prompt = PromptTemplate.from_template(
"""用户评价的情感是:{sentiment}
请根据情感生成一个合适的客服回复。
原评价:{review}
回复:"""
)
def prepare_reply_input(review):
sentiment = sentiment_chain.invoke({"review": review})
return {"sentiment": sentiment, "review": review}
reply_chain = (
RunnableLambda(prepare_reply_input)
| reply_prompt
| llm
| parser
)
# 测试
review_text = "产品质量很好,但发货速度太慢了!"
print("=== 顺序链处理结果 ===")
print(f"原始评价: {review_text}")
print(f"客服回复: {reply_chain.invoke(review_text)}")
# ========== 2. 条件分支链 ==========
# 根据问题的类型路由到不同的处理流程
# 定义不同场景的处理函数
def handle_math(question):
prompt = PromptTemplate.from_template("解决这个数学问题:{question}")
chain = prompt | llm | parser
return chain.invoke({"question": question})
def handle_general(question):
prompt = PromptTemplate.from_template("回答这个问题:{question}")
chain = prompt | llm | parser
return chain.invoke({"question": question})
# 分类器:判断问题类型
classifier_prompt = PromptTemplate.from_template(
"判断以下问题属于 'math' 还是 'general':\n'{question}'\n只输出一个词:"
)
classifier_chain = classifier_prompt | llm | parser
# 构建条件路由
def route_question(question):
category = classifier_chain.invoke({"question": question}).strip().lower()
if "math" in category:
return handle_math(question)
else:
return handle_general(question)
print("\n=== 条件分支链示例 ===")
print("数学问题:", route_question("一个苹果5元,买3个需要多少钱?"))
print("通用问题:", route_question("什么是人工智能?"))
# ========== 3. 并行执行 ==========
# 同时执行多个独立任务,提升效率
from langchain.schema.runnable import RunnableParallel
# 定义多个并行的处理分支
parallel_chain = RunnableParallel(
summary=(
PromptTemplate.from_template("用一句话总结:{text}")
| llm | parser
),
keywords=(
PromptTemplate.from_template("提取3个关键词:{text},用逗号分隔")
| llm | parser
),
sentiment=(
PromptTemplate.from_template("判断情感极性(正面/负面/中性):{text}")
| llm | parser
)
)
text = "LangChain框架非常好用,它大大简化了LLM应用的开发流程,强烈推荐!"
print("\n=== 并行处理结果 ===")
results = parallel_chain.invoke({"text": text})
for key, value in results.items():
print(f"{key}: {value}")3.5 智能体(Agents)
智能体是 LangChain 最强大的特性------它让 LLM 能够自主决定调用哪些工具、以什么顺序执行:
python
# demo_08_agent_basic.py
"""
智能体基础示例
让 LLM 自主选择和使用工具
需要安装: pip install langchain-community wikipedia
"""
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain.agents import create_react_agent, AgentExecutor
from langchain.tools import Tool
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
from langchain.prompts import PromptTemplate
import math
load_dotenv()
# 1. 定义工具
# 工具1:计算器
def calculator(expression: str) -> str:
"""执行数学计算,输入应为数学表达式"""
try:
# 安全地评估数学表达式
result = eval(expression, {"__builtins__": {}}, {"math": math})
return f"计算结果: {result}"
except Exception as e:
return f"计算错误: {e}"
# 工具2:维基百科查询
wikipedia = WikipediaQueryRun(
api_wrapper=WikipediaAPIWrapper(top_k_results=1, lang="zh")
)
# 工具3:自定义 API 模拟
def get_current_time(query: str) -> str:
"""获取当前时间"""
from datetime import datetime
return f"当前时间是: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}"
# 将函数包装成 Tool 对象
tools = [
Tool(
name="Calculator",
func=calculator,
description="执行数学计算。输入应为数学表达式,如 '2+3*4'"
),
Tool(
name="Wikipedia",
func=wikipedia.run,
description="查询维基百科获取知识"
),
Tool(
name="GetTime",
func=get_current_time,
description="获取当前日期和时间"
)
]
# 2. 创建智能体
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
# ReAct 提示词模板
agent_prompt = PromptTemplate.from_template("""
你是一个智能助手,可以调用工具来回答问题。
你有以下工具可用:
{tools}
工具名称:{tool_names}
回复格式(必须严格遵守):
Question: 用户的问题
Thought: 思考是否需要使用工具
Action: 要使用的工具名称(必须是 [{tool_names}] 之一)
Action Input: 工具的输入参数
Observation: 工具返回的结果
...(可以重复 Thought/Action/Action Input/Observation 多次)
Thought: 我现在知道答案了
Final Answer: 最终回答
开始!
Question: {input}
Thought: {agent_scratchpad}
""")
agent = create_react_agent(
llm=llm,
tools=tools,
prompt=agent_prompt
)
# 创建执行器
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True, # 打印执行过程
max_iterations=5, # 最多执行5步
handle_parsing_errors=True
)
# 3. 测试智能体
print("=== 智能体测试 ===\n")
queries = [
"请帮我计算 123 * 456 等于多少?",
"现在几点了?",
"请介绍一下 Python 编程语言,然后计算 100 除以 3 等于多少",
]
for query in queries:
print(f"\n用户: {query}")
print("智能体执行过程:")
result = agent_executor.invoke({"input": query})
print(f"\n最终回答: {result['output']}")
print("-" * 50)3.6 回调系统(Callbacks)
回调系统让你能够监控 LLM 应用的运行状态:
python
# demo_09_callbacks.py
"""
回调系统示例
用于监控、日志记录和调试
"""
from langchain.callbacks.base import BaseCallbackHandler
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.schema.runnable import RunnableSequence
from typing import Dict, Any, List
import time
class CustomCallbackHandler(BaseCallbackHandler):
"""自定义回调处理器"""
def __init__(self):
self.step_times = []
self.current_step_start = None
def on_llm_start(self, serialized: Dict[str, Any], prompts: List[str], **kwargs):
"""LLM 开始调用时触发"""
self.current_step_start = time.time()
print(f"\n[LLM 开始] 提示词长度: {len(prompts[0])} 字符")
def on_llm_end(self, response, **kwargs):
"""LLM 调用结束时触发"""
elapsed = time.time() - self.current_step_start
self.step_times.append(elapsed)
print(f"[LLM 结束] 耗时: {elapsed:.2f} 秒")
# 输出 token 使用情况
if hasattr(response, 'llm_output') and response.llm_output:
token_usage = response.llm_output.get('token_usage', {})
print(f"[Token 统计] 输入: {token_usage.get('prompt_tokens', 0)}, "
f"输出: {token_usage.get('completion_tokens', 0)}")
def on_chain_start(self, serialized: Dict[str, Any], inputs: Dict[str, Any], **kwargs):
"""链开始执行时触发"""
print(f"\n[链开始] 输入: {inputs}")
def on_chain_end(self, outputs: Dict[str, Any], **kwargs):
"""链执行结束时触发"""
print(f"[链结束] 输出: {outputs}")
def on_llm_error(self, error: Exception, **kwargs):
"""LLM 调用出错时触发"""
print(f"[错误] LLM 调用失败: {error}")
# 使用回调
callback = CustomCallbackHandler()
llm = ChatOpenAI(
model="gpt-3.5-turbo",
temperature=0,
callbacks=[callback] # 注册回调
)
prompt = PromptTemplate.from_template("用一句话解释什么是{concept}")
chain = prompt | llm
print("=== 带监控的链执行 ===")
result = chain.invoke({"concept": "区块链"})
print(f"\n回答: {result.content}")
print(f"\n=== 执行统计 ===")
print(f"总 LLM 调用次数: {len(callback.step_times)}")
print(f"平均耗时: {sum(callback.step_times)/len(callback.step_times):.2f} 秒")
四、实战项目:智能客服机器人
结合所学知识,让我们构建一个完整的智能客服机器人:
python
# demo_10_customer_service_bot.py
"""
完整实战项目:智能客服机器人
整合了记忆、RAG、工具调用等核心功能
"""
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.memory import ConversationBufferMemory
from langchain.vectorstores import Chroma
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import TextLoader
from langchain.tools import Tool
from langchain.agents import create_react_agent, AgentExecutor
from langchain.schema.runnable import RunnableWithMessageHistory
import json
from datetime import datetime
load_dotenv()
class CustomerServiceBot:
"""智能客服机器人"""
def __init__(self, knowledge_base_path: str = None):
self.llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.3)
self.memory = ConversationBufferMemory(
return_messages=True,
memory_key="chat_history"
)
# 初始化知识库(如果提供)
self.retriever = None
if knowledge_base_path and os.path.exists(knowledge_base_path):
self._init_knowledge_base(knowledge_base_path)
# 定义工具
self.tools = self._create_tools()
# 创建智能体
self.agent = self._create_agent()
def _init_knowledge_base(self, path: str):
"""初始化知识库"""
# 加载文档
loader = TextLoader(path, encoding="utf-8")
documents = loader.load()
# 文本分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50
)
chunks = text_splitter.split_documents(documents)
# 创建向量数据库
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="./customer_service_db"
)
self.retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
print(f"[初始化] 知识库已加载,包含 {len(chunks)} 个文档块")
def _create_tools(self):
"""创建客服工具"""
def check_order_status(order_id: str) -> str:
"""查询订单状态"""
# 模拟订单查询
orders = {
"12345": "已发货,预计3天内送达",
"67890": "已签收",
"11111": "处理中"
}
status = orders.get(order_id.strip(), "未找到该订单,请确认订单号")
return f"订单 {order_id} 状态: {status}"
def calculate_refund(amount: str) -> str:
"""计算退款金额"""
try:
refund = float(amount) * 0.9 # 假设90%退款
return f"预计退款金额: {refund:.2f} 元"
except:
return "金额格式错误,请输入数字"
def get_support_hours(query: str) -> str:
"""获取客服工作时间"""
return "客服工作时间:周一至周日 9:00-21:00(节假日照常服务)"
tools = [
Tool(
name="CheckOrder",
func=check_order_status,
description="查询订单状态。输入订单号,如 '12345'"
),
Tool(
name="CalculateRefund",
func=calculate_refund,
description="计算退款金额。输入原支付金额"
),
Tool(
name="GetSupportHours",
func=get_support_hours,
description="获取客服工作时间"
)
]
# 如果知识库可用,添加知识库检索工具
if self.retriever:
def search_knowledge(query: str) -> str:
docs = self.retriever.get_relevant_documents(query)
if docs:
return "\n".join([doc.page_content for doc in docs[:2]])
return "未找到相关信息"
tools.append(Tool(
name="SearchKnowledgeBase",
func=search_knowledge,
description="搜索产品知识库,回答产品相关问题"
))
return tools
def _create_agent(self):
"""创建智能体"""
agent_prompt = PromptTemplate.from_template("""
你是一个专业的客服机器人,名字叫"小智"。
你的职责:
1. 友好、耐心地回答用户问题
2. 使用工具查询订单、计算退款、获取工作时间
3. 对于不确定的问题,诚实地说"我需要转接人工客服"
可用工具:
{tools}
工具名称:{tool_names}
回复格式:
Question: 用户问题
Thought: 分析需要什么信息
Action: 工具名称(如果需要)
Action Input: 工具参数
Observation: 工具返回
(可以重复上述步骤)
Thought: 我已经有足够信息了
Final Answer: 最终回复
开始对话!
Previous conversation:
{chat_history}
Question: {input}
Thought: {agent_scratchpad}
""")
agent = create_react_agent(
llm=self.llm,
tools=self.tools,
prompt=agent_prompt
)
return AgentExecutor(
agent=agent,
tools=self.tools,
verbose=False,
max_iterations=3,
handle_parsing_errors=True
)
def chat(self, user_input: str) -> str:
"""处理用户消息"""
# 保存用户输入到记忆
self.memory.save_context({"input": user_input}, {"output": ""})
# 获取历史记录
history = self.memory.load_memory_variables({})
# 调用智能体
result = self.agent.invoke({
"input": user_input,
"chat_history": history.get("chat_history", "")
})
response = result["output"]
# 保存回复到记忆
self.memory.save_context({"input": user_input}, {"output": response})
return response
def clear_memory(self):
"""清空对话历史"""
self.memory.clear()
print("[系统] 对话历史已清空")
# 测试客服机器人
def main():
# 创建知识库文件(示例)
knowledge_content = """
产品特性:
1. 7天无理由退货
2. 1年质保服务
3. 全国联保,支持上门维修
常见问题:
Q: 如何申请退货?
A: 在订单页面点击申请售后,填写退货原因即可。
Q: 质保期内维修需要费用吗?
A: 非人为损坏的故障,质保期内免费维修。
"""
with open("knowledge_base.txt", "w", encoding="utf-8") as f:
f.write(knowledge_content)
# 初始化机器人
bot = CustomerServiceBot(knowledge_base_path="knowledge_base.txt")
print("=" * 50)
print("智能客服机器人已启动")
print("输入 'quit' 退出,输入 'clear' 清空对话")
print("=" * 50)
while True:
user_input = input("\n用户: ").strip()
if user_input.lower() == 'quit':
print("客服机器人: 感谢您的咨询,再见!")
break
elif user_input.lower() == 'clear':
bot.clear_memory()
print("客服机器人: 对话历史已清空")
continue
elif not user_input:
continue
response = bot.chat(user_input)
print(f"客服机器人: {response}")
if __name__ == "__main__":
main()本章练习题及答案
一、选择题(每题4分,共20分)
1. LangChain 中 LCEL 的核心语法是什么?
-
A.
chain = chain1 + chain2 -
B.
chain = chain1 >> chain2 -
C.
chain = prompt | model | parser -
D.
chain = chain1.and_then(chain2)
答案:C
解析:LCEL(LangChain Expression Language)使用管道操作符
|来组合组件,这是现代 LangChain 的标准写法。
2. 以下哪个记忆组件会自动生成对话摘要来减少 token 消耗?
-
A. ConversationBufferMemory
-
B. ConversationBufferWindowMemory
-
C. ConversationTokenBufferMemory
-
D. ConversationSummaryMemory
答案:D
解析:ConversationSummaryMemory 会使用 LLM 自动生成对话摘要,用摘要替代完整历史,适合长对话场景。
3. 在 RAG 流程中,文本分割的 chunk_overlap 参数作用是什么?
-
A. 控制分割块的数量
-
B. 控制块之间的重叠字符数,保持上下文连贯
-
C. 控制块的最大长度
-
D. 控制向量维度
答案:B
解析:chunk_overlap 让相邻文本块之间有重叠内容,避免在分割边界处丢失关键上下文。
4. 以下哪种 Chain 类型最适合让 LLM 自主决定调用哪个工具?
-
A. SequentialChain
-
B. Agent
-
C. LLMChain
-
D. SimpleSequentialChain
答案:B
解析:Agent(智能体)可以动态决策,根据用户输入选择使用哪些工具、按什么顺序执行。
5. 关于 LangChain 回调系统,下列说法正确的是?
-
A. 只能用于错误处理
-
B. 可以监控 LLM 调用、链执行的各个阶段
-
C. 只能在同步模式下使用
-
D. 需要付费才能使用
答案:B
解析:回调系统提供 on_llm_start、on_llm_end、on_chain_start 等多个钩子,可以全方位监控执行过程。
二、填空题(每空3分,共15分)
-
LangChain 的六大核心模块包括:模型 I/O、数据增强、++链 、记忆++、智能体和回调处理器。
-
在 LCEL 中,使用
|操作符连接组件,最后调用 ++invoke++ 方法执行链。 -
对话式提示词模板中,使用 ++
MessagesPlaceholder++ 作为历史消息的动态占位符。 -
向量数据库中,用于衡量文本语义相似度的技术称为 ++
embedding++(嵌入/向量化)。 -
智能体的 ReAct 模式中,"Re" 代表推理(Reasoning),"Act" 代表 ++行动(Acting)++。
三、简答题(每题10分,共30分)
1. 请简述 RAG(检索增强生成)的工作流程及其解决了 LLM 的什么问题?
参考答案:
RAG 的工作流程包括 5 个步骤:
文档加载:从 PDF、TXT 等源加载文档
文本分割:将长文档切分成适当大小的块
向量化:使用嵌入模型将文本块转换为向量
检索:根据用户问题,从向量库中检索最相关的文本块
生成:将检索结果作为上下文,连同用户问题一起提交给 LLM 生成回答
RAG 解决了 LLM 的三个核心问题:
知识时效性:LLM 训练数据有截止日期,RAG 可接入实时数据
幻觉问题:通过提供真实上下文,减少模型捏造信息
私有数据访问:让 LLM 能够基于企业内部文档回答问题,而不需要重新训练
2. 请对比 ConversationBufferMemory 和 ConversationBufferWindowMemory 的区别及适用场景。
参考答案:
特性 BufferMemory WindowMemory 存储策略 保存全部对话历史 只保留最近 K 轮 Token 消耗 随时间线性增长 恒定(受 K 控制) 长期记忆 保留所有信息 会遗忘早期对话 适用场景 短对话、需要完整上下文 长对话、控制成本 适用场景:
BufferMemory:适合客服诊断、技术支持等需要完整上下文的场景
WindowMemory:适合日常闲聊、信息查询等早期对话相关性低的场景
3. 解释 Agent 中的 ReAct 模式及其工作流程。
参考答案:
ReAct 模式结合了推理 (Reasoning)和行动(Acting),让 LLM 能够交替进行思考和执行操作。
工作流程:
pythonQuestion → Thought → Action → Observation → Thought → ... → Final Answer
Thought:LLM 分析当前状态,决定下一步做什么
Action:选择一个工具并给出输入参数
Observation:执行工具并返回结果
重复:根据观察结果继续思考,直到获得足够信息
Final Answer:给出最终回答
例如用户问"今天北京天气如何",Agent 会:思考需要查询天气 → 执行搜索工具 → 观察结果 → 整理回答。
四、实操题(35分)
题目:构建一个多轮对话的 RAG 问答系统
要求:
-
使用 LangChain 构建一个支持多轮对话的问答系统
-
系统需包含:文档加载、向量存储、对话记忆
-
实现一个自定义的对话检索链(ConversationalRetrievalChain)
-
提供完整的代码和注释
参考答案:
python
"""
实操题参考答案:多轮对话 RAG 系统
"""
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain
from langchain.prompts import PromptTemplate
load_dotenv()
# 1. 准备知识库数据
knowledge = """
LangChain 是一个用于开发大语言模型应用的框架,于 2022 年发布。
它的主要组件包括:模型 I/O、检索、链、记忆和智能体。
RAG 是检索增强生成的缩写,它通过检索外部知识来增强 LLM 的回答质量。
RAG 特别适合构建基于私有文档的问答系统。
LCEL 是 LangChain Expression Language 的缩写,它使用 | 管道操作符来组合组件。
LCEL 支持并行执行、流式输出和自动追踪等特性。
Memory 模块用于在对话之间维护状态。
常用的记忆类型包括:BufferMemory、WindowMemory、SummaryMemory 和 VectorStoreMemory。
"""
with open("qa_knowledge.txt", "w", encoding="utf-8") as f:
f.write(knowledge)
# 2. 构建 RAG 组件
def build_rag_system():
# 加载文档
loader = TextLoader("qa_knowledge.txt", encoding="utf-8")
documents = loader.load()
# 文本分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=300,
chunk_overlap=50
)
chunks = text_splitter.split_documents(documents)
print(f"文档已分割为 {len(chunks)} 个块")
# 创建向量存储
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="./chat_qa_db"
)
# 创建记忆(返回消息格式)
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True,
output_key="answer" # 指定输出键
)
# 自定义提示词模板
custom_prompt = PromptTemplate.from_template("""
你是一个知识库助手。请基于以下上下文回答用户问题。
对话历史:
{chat_history}
上下文:
{context}
用户问题:{question}
回答要求:
1. 如果上下文中没有相关信息,请诚实地说"我不知道"
2. 回答要简洁、准确
3. 可以引用对话历史中的信息
回答:
""")
# 创建对话检索链
qa_chain = ConversationalRetrievalChain.from_llm(
llm=ChatOpenAI(model="gpt-3.5-turbo", temperature=0),
retriever=vectorstore.as_retriever(search_kwargs={"k": 2}),
memory=memory,
combine_docs_chain_kwargs={"prompt": custom_prompt},
verbose=True
)
return qa_chain
# 3. 交互式对话
def main():
print("=" * 50)
print("多轮对话 RAG 问答系统")
print("知识库内容:LangChain、RAG、LCEL、Memory")
print("输入 'quit' 退出,输入 'clear' 清空记忆")
print("=" * 50)
chain = build_rag_system()
while True:
question = input("\n用户: ").strip()
if question.lower() == 'quit':
print("再见!")
break
elif question.lower() == 'clear':
chain.memory.clear()
print("对话记忆已清空")
continue
elif not question:
continue
# 调用链
result = chain.invoke({"question": question})
print(f"助手: {result['answer']}")
# 可选:显示检索到的来源
if 'source_documents' in result:
print(f"\n(参考了 {len(result['source_documents'])} 个文档片段)")
if __name__ == "__main__":
main()预期交互示例:
用户: LangChain 是什么?
助手: LangChain 是一个用于开发大语言模型应用的框架,于 2022 年发布。
用户: 它的主要组件有哪些?
助手: LangChain 的主要组件包括:模型 I/O、检索、链、记忆和智能体。
用户: 那 RAG 呢?
助手: RAG 是检索增强生成的缩写,它通过检索外部知识来增强 LLM 的回答质量,特别适合构建基于私有文档的问答系统。
总结
本文系统介绍了 LangChain 框架的核心概念与实践技巧。从环境搭建到 RAG 应用,从记忆管理到智能体构建,我们通过大量可运行的代码示例,展示了这一强大框架的使用方法。
关键收获:
-
模块化思维:LangChain 将复杂的 LLM 应用拆解为可组合的组件,理解每个组件的职责是高效开发的基础
-
LCEL 为核心 :掌握
|管道语法是使用现代 LangChain 的必备技能 -
RAG 是标配:让 LLM 访问外部知识是解决幻觉和时效性问题的关键
-
记忆需谨慎:不同场景选择合适的记忆策略,平衡上下文完整性和成本
-
智能体是未来:赋予 LLM 使用工具的能力,开启了自动化任务的新可能
进阶学习路径:
-
深入 LangGraph:学习基于图的工作流编排
-
掌握 LangSmith:生产级应用的调试与监控
-
探索多模态:结合图像、音频等多模态输入
-
优化性能:缓存、流式输出、异步调用
随着大模型技术的持续演进,LangChain 也在快速迭代。建议读者多关注官方文档和社区动态,保持学习的热情。AI 应用开发的门槛从未如此之低,希望本文能帮助你迈出坚实的第一步!
🌟 感谢您耐心阅读到这里!
🚀 技术成长没有捷径,但每一次的阅读、思考和实践,都在默默缩短您与成功的距离。
💡 如果本文对您有所启发,欢迎点赞👍、收藏📌、分享📤给更多需要的伙伴!
🗣️ 期待在评论区看到您的想法、疑问或建议,我会认真回复,让我们共同探讨、一起进步~
🔔 关注我,持续获取更多干货内容!
🤗 我们下篇文章见!