【前言】
你是否好奇过,为什么 ChatGPT 能跟你流畅对话?为什么搜索引擎能自动补全你的问题?这背后都离不开一个关键技术------语言模型。本文将从基础概念出发,带你回顾语言模型从简单统计到万亿参数的进化历程,并了解如何评估它们的好坏。
一、什么是语言模型 (LM)?
通俗地说,语言模型就是用来判断一句话是不是"人话" 的模型。它会计算一个句子(词语序列)出现的概率。
-
核心任务 :给定一个词语序列
S = {W1, W2, ..., Wn},计算P(S)。序列越符合语言习惯,概率越高。 -
难点 :理论上,
P(S)可以用链式法则分解为一系列条件概率的乘积。但"参数空间过大"和"数据稀疏"使得直接计算不现实。
二、语言模型的进化四阶段
python
"""
1.基于统计的N-gram
2.神经网络模型(CNN/RNN/LSTM/GRU)
3.Transformer预训练➕微调(Pre-training ➕Fine-tuning) BERT GPT T5
4.LLM大语言模型 参数突破千亿,大力出奇迹
"""语言模型的发展可以清晰地划分为四个阶段,这是一个从"机械"到"智能"的跃迁。
1. 基于统计的N-gram模型 (萌芽期)
为了解决计算难题,马尔科夫假设被引入:一个词出现的概率只与它前面的有限个词有关。
-
Unigram (一元模型) :所有词独立。
P(S) = P(W1)*P(W2)*...*P(Wn) -
Bigram (二元模型) :只依赖前一个词。
P(S) = P(W1)*P(W2|W1)*...*P(Wn|Wn-1) -
Trigram (三元模型):依赖前两个词。
优点 :简单、易训练、可解释。缺点:缺乏长期记忆、参数空间爆炸、无法处理未登录词、泛化能力差。
2. 神经网络语言模型 (进化期)
利用神经网络(如Word2Vec + 全连接层**CNN/RNN/LSTM/GRU** )来建模词与词之间的关系。通过将词映射为低维、稠密的词向量 ,模型具备了更强的泛化能力,能理解词之间的相似性,缓解了数据稀疏问题。但依然受限于固定长度的上下文和梯度消失/爆炸问题。
3. 基于Transformer的预训练语言模型 (爆发期)
Transformer架构 的诞生是里程碑事件。它通过自注意力机制,让模型能直接捕捉长距离的词语依赖关系,解决了RNN的遗忘问题。
-
范式:"Pre-training + Fine-tuning"(预训练 + 微调)。先在海量文本上预训练一个"通才"模型,再针对特定任务(如情感分类、问答)进行微调。
-
代表模型:BERT、GPT、T5。
4. 大语言模型 (LLM) (涌现期)
随着模型参数规模突破千亿(如GPT-3的1750亿参数),研究人员发现了标度定律 (Scaling Law) :模型越大,性能越好。更重要的是,LLM涌现出小模型不具备的"智能"能力,如上下文学习 和思维链推理,无需微调即可完成复杂任务。
-
代表模型:GPT-4、PaLM、LLaMA、文心一言、ChatGLM。
-
特点:真正实现了与人类对话、生成创造性内容,但也带来了对算力、偏见和安全性的新挑战。
三、如何评估语言模型的好坏?
文本分类评估指标: 准确率 f1score
文本生成机器翻译:bleu ppl rouge
光说不练假把式,我们需要一些量化指标来评估模型生成文本(NLG生成式任务)的质量。
-
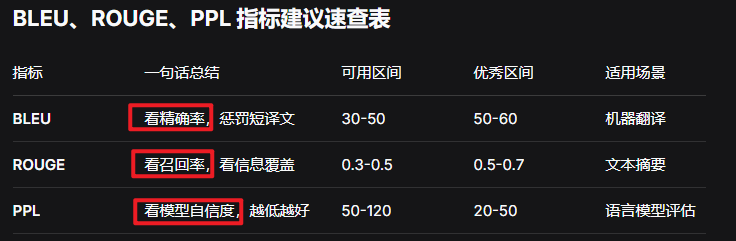
困惑度 (PPL) :衡量模型对句子预测的"不确定度"。PPL越低,模型越好。它是最基础的内部评价指标。
-
loss是多分类交叉熵损失函数
loss = -Σ(ylog(p)) y真实值对应one-hot编码 p对应softmax预测概率值
真实值y=0,0,1 0的部分乘积下消除,log对数会将靠近0的无限变大,靠近1的无限变小,将分类结果特征增强,弱者愈弱,强者愈强
PPL = e^loss 最小值无限接近1,PPL越低,模型越好,loss越高PPL越差


PPL 没有一个固定的"及格线",通常 20-60 是工业级模型的常见区间
-
-
BLEU :基于准确率 。计算模型生成的文本(candidate)与参考文本(reference)在n-gram上的匹配程度。常用于机器翻译任务。分数越高越好。
-
candidate中n-gram个数 C
reference中n-gram个数 R
K = e^(1 - R/C)
BLEU底层理念:漏译比错译更不可接受,不允许偷懒,指数的放大效应 >> 惩罚稀释K
BLEU**= C与R匹配个数➗C * K**
n-gram == 1时:
BLEU = 预测正确的数量/预测的总数量 >> 精确率 * 惩罚系数
 python
python# 第一步安装nltk的包-->pip install nltk from nltk.translate.bleu_score import sentence_bleu # 导入nltk中的BLEU分数计算函数 import warnings warnings.filterwarnings("ignore") # 忽略警告信息,避免输出干扰 def cumulative_bleu(reference, candidate): """ 计算候选句子与参考句子之间的BLEU分数(1-gram, 2-gram, 3-gram, 4-gram) :param reference: 参考文本(list of list of str),如多组参考答案 :param candidate: 生成文本(list of str),如模型生成的答案 :return: 1-gram, 2-gram, 3-gram, 4-gram的BLEU分数 """ # BLEU分数的累积计算示例: # BP * p1^w1 * p2^w2 = 0.6^0.5 * 0.25^0.5 = (0.6*0.25)^0.5 = 0.387 # 也可以写成:math.exp(0.5 * math.log(0.6) + 0.5 * math.log(0.25)) = math.exp(math.log(0.6*0.25)^0.5) = (0.6*0.25)^0.5 = 0.387 # 计算1-gram BLEU分数(只考虑单个词的精确率) bleu_1_gram = sentence_bleu(reference, candidate, weights=(1, 0, 0, 0)) # 计算2-gram BLEU分数(考虑1-gram和2-gram,权重各0.5) bleu_2_gram = sentence_bleu(reference, candidate, weights=(0.5, 0.5, 0, 0)) # 计算3-gram BLEU分数(考虑1-3-gram,权重各1/3) bleu_3_gram = sentence_bleu(reference, candidate, weights=(0.33, 0.33, 0.33, 0)) # 计算4-gram BLEU分数(考虑1-4-gram,权重各1/4) bleu_4_gram = sentence_bleu(reference, candidate, weights=(0.25, 0.25, 0.25, 0.25)) # 可以打印每个BLEU分数,便于调试 print('bleu 1-gram: %f' % bleu_1_gram) print('bleu 2-gram: %f' % bleu_2_gram) print('bleu 3-gram: %f' % bleu_3_gram) print('bleu 4-gram: %f' % bleu_4_gram) # 返回所有n-gram的BLEU分数 return bleu_1_gram, bleu_2_gram, bleu_3_gram, bleu_4_gram if __name__ == '__main__': # 预测文本(模型生成的文本,已分词) candidate_text = ["This", "is", "some", "generated", "text"] # 目标文本列表(参考答案,可以有多个,每个也是分词后的列表) # 以最大匹配长度作为参考长度 reference_texts = [ ["This", "is", "a", "reference", "text"], ["This", "is", "another", "reference", "text"] ] # 计算 Bleu 指标,返回1-gram到4-gram的BLEU分数 c_bleu = cumulative_bleu(reference_texts, candidate_text) # 打印结果,显示各个n-gram的BLEU分数 print("The Bleu score is:", c_bleu)
-
-
ROUGE :基于召回率 。计算参考文本中的n-gram有多少出现在了生成文本中。更关注生成内容是否完整覆盖 了参考答案的核心信息。常用于自动摘要 和问答任务。
-
ROUGE是将BLEU的惩罚系数去掉,然后分母换成R
candidate中n-gram个数 C
reference中n-gram个数 R
ROUGE = C与R匹配个数➗R >> 召回率
ROUGE的精确率就是BLEU的1-gram忽略惩罚稀释K的结果
ROUGE一般情况只统计rouge-1,也就是直接算精确率、召回率和F1得分
精确率 >> scores0"rouge-1""p"
召回率 >> scores0"rouge-1""r"
F1分数 >> scores0"rouge-1""f"
0.5可用,0.3-0.5还行,0.7-0.9优质
python# 第一步:安装rouge库,可以使用命令:pip install rouge from rouge import Rouge # 导入ROUGE指标的计算库 # 预测文本(模型生成的文本) generated_text = ["This is some generated text."] # 目标文本列表(人工标注的参考答案,可以有多个参考答案) reference_texts = [ ["This is a reference text."], # 第一个参考文本 ["This is another generated reference text."], # 第二个参考文本 ] # 创建Rouge对象,用于后续计算ROUGE分数 rouge = Rouge() # 计算生成文本与第二个参考文本之间的ROUGE分数 # get_scores方法的第一个参数是待评估的生成文本,第二个参数是参考文本 # 返回值是一个包含各类ROUGE分数的字典列表 print('reference_texts[1]--->', reference_texts[1]) scores = rouge.get_scores(generated_text, reference_texts[1]) # 打印完整的ROUGE分数字典列表 print("scores:", scores) # 打印ROUGE-1的precision(精确率) print("ROUGE-1 precision:", scores[0]["rouge-1"]["p"]) # 打印ROUGE-1的recall(召回率) print("ROUGE-1 recall:", scores[0]["rouge-1"]["r"]) # 打印ROUGE-1的F1分数 print("ROUGE-1 F1 score:", scores[0]["rouge-1"]["f"]) print("ROUGE-l F1 score:", scores[0]["rouge-l"]["f"])
-
四、BERT>>GPT>>T5(LLM三大架构流派)
1. 三大架构总览
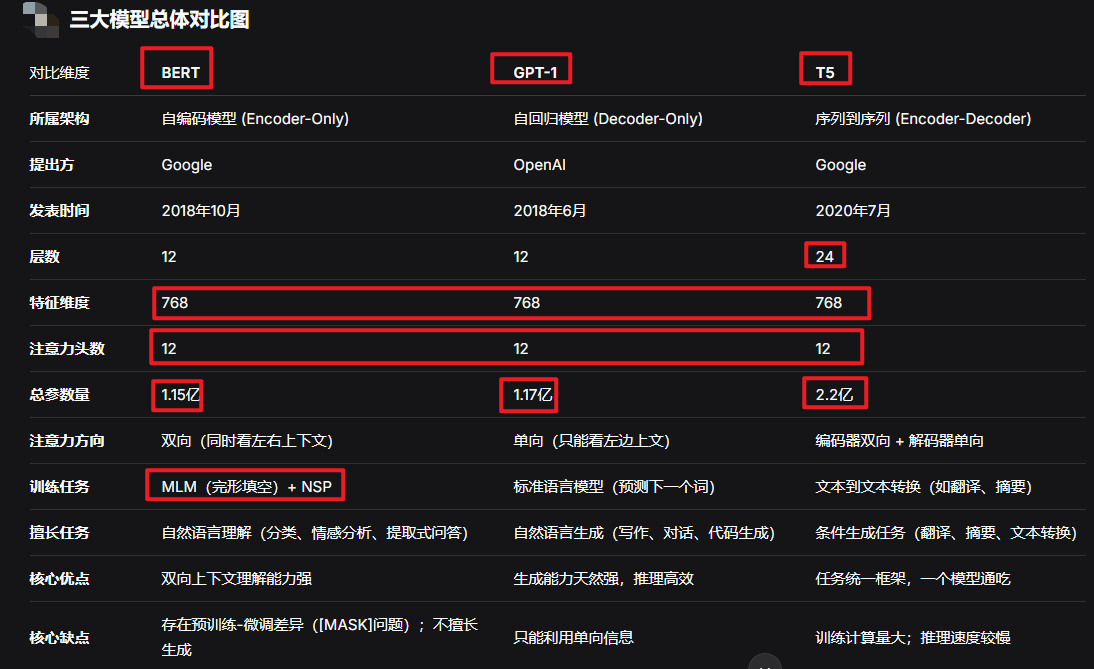
所有LLM都根植于2017年提出的Transformer架构,但不同的模型对其进行了不同的"剪裁"和改造,形成了三类主要流派:
| 架构类型 | 常见称呼 | 代表模型 | 核心特点 | 擅长任务 |
|---|---|---|---|---|
| 自编码模型 | Encoder-Only | BERT | 双向注意力,随机MASK预测 | 自然语言理解(分类、情感分析、提取式问答) |
| 自回归模型 | Decoder-Only | GPT系列 | 单向注意力,从左到右预测下一个词 | 自然语言生成(写作、对话、代码生成) |
| 序列到序列 | Encoder-Decoder | T5、BART | 编码器理解输入,解码器生成输出 | 条件生成任务(翻译 、摘要、文本转换) |
📌 架构图速记:BERT只看左边+右边 → GPT只从左看到右 → T5先看完整输入再生成输出
2. 自编码模型(AE):BERT------双向理解的王者
BERT(Bidirectional Encoder Representation from Transformers)是2018年Google提出的里程碑式模型,在SQuAD阅读理解测试中首次超越人类水平。
核心原理 :在输入中随机MASK掉15%的词汇,让模型根据上下文(左+右) 来预测被遮住的词。这种"完形填空"式的训练方式,使BERT获得了对语言的深层理解能力。
架构组成:
-
Embedding模块:Token Embedding + Segment Embedding(区分句子)+ Position Embedding(可学习位置编码)三者加和
-
Transformer模块:仅使用Encoder部分,通常12层、768维、12个注意力头(Base版)
优点 :双向上下文建模,NLU任务表现极佳。缺点 :预训练中的MASK符号在下游任务中不存在,存在"预训练-微调差异";不擅长生成任务(训练与微调/推理有差异)。
3. 自回归模型(AR):GPT------生成的王者
GPT(Generative Pre-training)是2018年OpenAI推出的模型,开创了"生成式预训练"范式,也是ChatGPT的底层架构。
核心原理 :传统的语言模型训练方式------给定前面的词,预测下一个词。这种单向(从左到右) 的建模方式天然适合生成任务。GPT预测Wi时,只能看到W1...W(i-1),不能看到后面的词。
架构特点 :仅使用Transformer的Decoder部分,且进一步简化------去掉了经典Decoder中的Encoder-Decoder Attention层(去除交叉注意力层),只保留Masked Self-Attention和Feed Forward层。
BERT vs GPT 核心区别:
-
BERT看双向上下文(像阅读理解)
-
GPT看单向上文(像续写)
优点 :生成能力天然强,适合NLG任务;预训练数据获取容易(直接拿语料库预测下一个词即可)。缺点:只能利用单向信息,无法像BERT那样捕捉完整的双向依赖。
4. 序列到序列模型(Seq2Seq):T5------一切皆为文本转换
T5(Text-to-Text Transfer Transformer)是2020年Google提出的统一框架模型。
核心思想:将所有NLP任务都转化为"文本到文本"的转换问题。无论是翻译、分类、摘要还是相似度计算,输入和输出都是文本字符串。
统一框架示例:
-
翻译:输入
translate English to German: That is good→ 输出Das ist gut -
分类:输入
cola sentence: The cat is on the mat→ 输出acceptable或unacceptable
架构特点:完整保留了Transformer的Encoder-Decoder结构,但做了几处优化:简化版LayerNorm(去除bias)、使用相对位置编码(学习32个Embedding,覆盖长度128以内的位置差)。
优点 :任务统一,一个模型通吃所有NLP任务;参数效率相对较高(T5-Base约2.2亿参数)。缺点:训练计算量大;可解释性不足。
5. 为什么现在的LLM都选择Decoder-Only?
你可能会问:既然三大架构各有千秋,为什么GPT系列、LLaMA、Claude等主流大模型都采用了Decoder-Only架构?
核心原因有三:
-
训练效率高:AR模型只需做"预测下一个词"这一个任务,数据获取简单,训练稳定。
-
工程实现友好:单向注意力在推理时可以使用KV Cache技术大幅加速生成,而双向注意力在生成长文本时需要重复计算。
-
理论上有优势:研究表明,Encoder的双向注意力会带来"低秩问题",可能削弱模型的表达能力。而Decoder-Only在同等参数量下,表达能力更强。
💡 通俗理解:在同等参数量和推理成本下,Decoder-Only就是"性价比最高"的选择。
chatGPT的大参数量,用超大参数量大力出奇迹,可以弥补其文本理解的短板.
【写在最后】
理解BERT、GPT、T5这三种架构,就是理解了现代NLP的半壁江山:
-
BERT教我们如何让机器"读懂"语言(Encoder-Only)
-
GPT教我们如何让机器"写出"语言(Decoder-Only)
-
T5教我们如何用一个框架统一所有任务(Encoder-Decoder)
而今天的LLM浪潮最终选择了Decoder-Only,也提醒我们:在学术探索中百花齐放很重要,但在工程落地中,"简单有效"往往是最终的答案。
希望这篇总结能帮你建立起LLM架构的系统认知!🚀