课程13:编写强化学习环境_哔哩哔哩_bilibili
BL3能为我们解决很多问题,但是其提供的环境确实有限,如果你想训练Agent玩吃豆人,就需要自行配置环境了。
游戏定义
捕食者游戏:
类似吃豆人,有三个对象,玩家、食物、敌人。在网格环境中要求躲避敌人的追捕,吃到食物。
导入依赖库
python
#将学习环境所需要的依赖库导入
import numpy as np
import cv2
from PIL import Image
import time
import pickle #对象到文件的处理
import matplotlib.pyplot as plt
from matplotlib import style
style.use('ggplot')环境参数 训练参数设置
python
#环境参数设定
SIZE=10 #3个对象在10*10的范围内
EPISODES=30000 #智能体玩的游戏轮数
SHOW_EVERY=3000 #每3000局展示一次游玩过程
#奖励与惩罚
FOOD_REWARD=25#吃食物的奖励
ENEMY_PENALITY=300 #被敌人抓住的惩罚
MOVE_PENALITY=1 #移动惩罚
#环境计算参数
epsilon=0.6 #在强化学习时抽取随机动作的概率 40%使用最大价值期望动作
EPS_DECAY=0.9998 #每玩一局游戏就让随机动作概率乘以这个数,到最后基本就定性了
DISCOUNT=0.95 #折扣回报 未来奖励的折扣
LEARNING_RATE=0.1 #学习率 步长
#q_table_file = "q_table_save.pkl"
q_table = None
d = {1:(255,0,0), #蓝色------玩家
2:(0,255,0), #绿色------食物
3:(0,0,255)} #红色------敌人
PLAYER_N=1
FOOD_N=2
ENEMY_N=3对象类的设置
初始化函数与重写函数
首先必要的init函数,初始化对象的位置。
然后编写打印功能函数,输出自身位置。
python
#为三个对象创建类
class Cube:
def __init__(self):#初始位置
self.x=np.random.randint(0,SIZE)
self.y=np.random.randint(0,SIZE)
def __str__(self): #打印当前位置
return f'{self.x},{self.y}'
python
player=Cube()
print(player) #当使用 print() 函数打印一个对象时,Python 会自动调用该对象的 __str__ 方法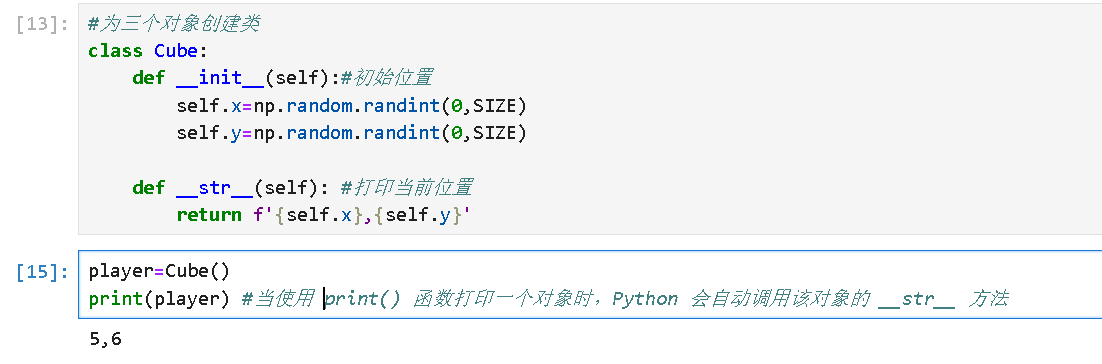
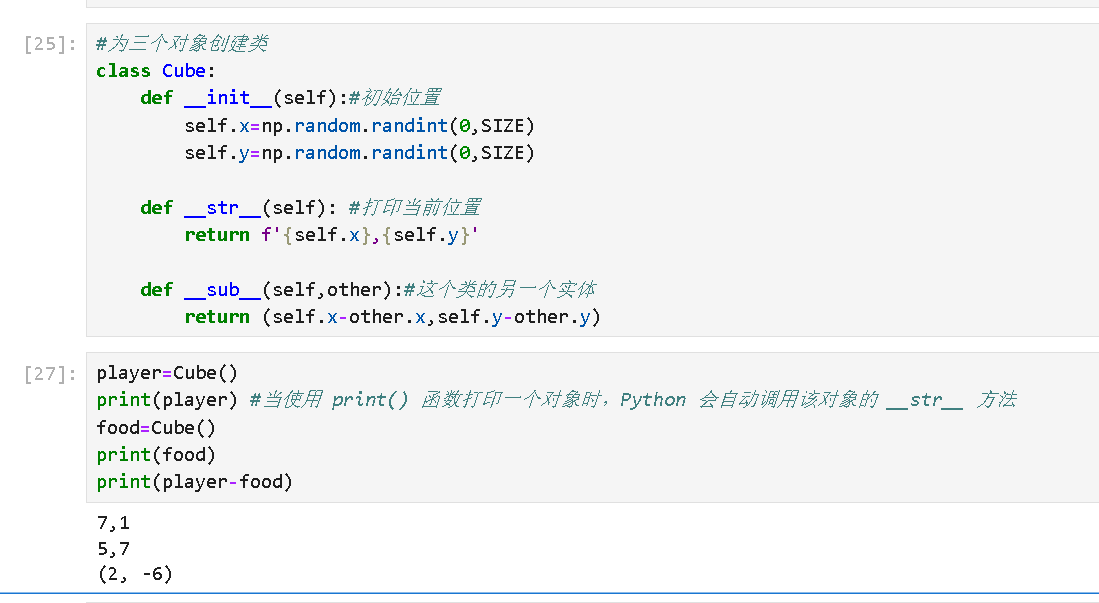
再添加一个__sub__函数,重写减法,标志两个对象的欧氏距离。
python
def __sub__(self,other):#这个类的另一个实体
return (self.x-other.x,self.y-other.y)当你使用 print() 函数打印一个对象时,Python 会自动调用该对象的 __str__ 方法
当你使用A-B时,会自动调用对象的__sub__方法。
编写移动函数
接下来编写移动函数move:
如果没有给定xy的值,就在-1到1之间随机给定一个xy坐标,让对象移动。然后要检查边界,如果超过棋盘SIZE-1,就约束在边界。
python
def move(self,x=False,y=False):
if not x:#如果x没有给值
self.x += np.random.randint(-1,2)
else:
self.x += x
if not y:#如果y没有给值
self.y += np.random.randint(-1,2)
else:
self.y += y
#考虑边界
if self.x<0:
self.x=0
elif self.x>=SIZE:
self.x=SIZE-1
if self.y<0:
self.y=0
elif self.y>=SIZE:
self.y=SIZE-1
编写动作函数(动作函数基于移动):
设定右上 左上 右下 左下四个动作(按理来说应该还要有固定不动)【之后我们会扩展到8个动作】
python
def action(self,choise):
if choise == 0:
self.move(x=1,y=1)
elif choise == 1:
self.move(x=-1,y=1)
elif choise == 2:
self.move(x=1,y=-1)
elif choise == 3:
self.move(x=-1,y=-1)完整的对象类函数
python
# 智能体的类,有其 位置信息 和 动作函数
class Cube:
def __init__(self): # 随机初始化位置坐标
self.x = np.random.randint(0, SIZE-1)
self.y = np.random.randint(0, SIZE-1)
def __str__(self):
return f'{self.x},{self.y}'
def __sub__(self, other):
return (self.x-other.x,self.y- other.y)
def action(self,choise):
if choise == 0:
self.move(x=1,y=1)
elif choise == 1:
self.move(x=-1, y=1)
elif choise == 2:
self.move(x=1, y=-1)
elif choise == 3:
self.move(x=-1, y=-1)
def move(self,x=False, y=False):
if not x:
self.x += np.random.randint(-1, 2)
else:
self.x += x
if not y:
self.y += np.random.randint(-1, 2)
else:
self.y += y
if self.x< 0:
self.x = 0
if self.x> SIZE -1:
self.x = SIZE-1
if self.y< 0:
self.y = 0
if self.y> SIZE -1:
self.y = SIZE-1初始化Q_table
我们之前定义q_table是None
python
q_table = None第一次训练我们确实没有q_table,但是之后的训练可以居于此前的q_table继续训练,因此这里要做个判断,如果没有q_table就初始化,如果已经有了q_table就加载进来。
加载的代码没什么好说的,就是with open...
我们看一下如何初始化q_table:
python
#q_table初始化 整个状态空间有19^4个状态 存储玩家和食物、玩家和敌人的距离作为状态,二者距离差在-9-9之间,有19*19个状态,三个对象有361*361个对象
#内部存储当前最佳的动作
# 初始化Q表格
if q_table is None: # 如果没有实现提供,就随机初始化一个Q表格
q_table = {}
for x1 in range(-SIZE+1,SIZE):
for y1 in range(-SIZE + 1, SIZE):
for x2 in range(-SIZE + 1, SIZE):
for y2 in range(-SIZE + 1, SIZE):
q_table[((x1,y1),(x2,y2))] = [np.random.randint(-5,0) for i in range(4)]
#这是值,一个包含 4 个元素的列表。
#np.random.uniform(-5,0):给这 4 个动作随机赋一个负数的初始价值(比如 -2.3, -1.5, -4.0, -0.5)。
#注意:这里存的是价值,不是概率。如果想看概率,需要额外的数学运算(如 Softmax),但 Q-Learning 通常直接用 argmax 拿最大值的索引来作为动作。
else: # 提供了,就使用提供的Q表格
with open(q_table,'rb') as f:
q_table= pickle.load(f)
Q_table是存储所有离散状态的表格,在preadtor游戏中:
状态的定义
在强化学习中,状态(State) 是智能体用来做决策的所有信息的集合。
-
相对位置的重要性
在这个迷宫/吃豆人游戏中,智能体(玩家)并不需要知道它在地图上的绝对坐标(比如
x=5, y=5)。- 它真正关心的是 :
- 食物在哪儿?(相对于我,食物在左上、右下还是正前方?)
- 敌人在哪儿?(相对于我,敌人在追我吗?)
- 结论 :状态应该是相对位置,而不是绝对位置。
- 它真正关心的是 :
-
状态向量的构成
代码中定义的状态由两个相对向量组成:
(x1, y1):玩家与食物的相对位置差(player - food)。(x2, y2):玩家与敌人的相对位置差(player - enemy)。
-
状态数量的计算
SIZE = 10,坐标范围是0到9。- 相对位置差的范围:最小是
-9(我在9,目标在0),最大是9(我在0,目标在9)。所以每个坐标轴上有19个可能的值(从 -9 到 9)。 - 总状态数 :
- 玩家-食物:
19(x轴) ×19(y轴) =361种可能。 - 玩家-敌人:
19(x轴) ×19(y轴) =361种可能。 - 总计:361×361=130,321 种状态。
- 玩家-食物:
- 这就是代码中
for循环嵌套 4 层的原因,它在穷举所有可能的相对位置组合。
我们用一个二维数组存储 q_table((x1,y1),(x2,y2)),第一组是玩家与食物的坐标差,第二组是玩家与敌人的坐标差。
然后做初始化:
python
[np.random.randint(-5,0) for i in range(4)]这是值,一个包含 4 个元素的列表。
相对于给这 4 个动作随机赋一个负数的初始价值(比如 -2.3, -1.5, -4.0, -0.5),代表当前状态下,向四个方向走的预估价值。
之后会通过更新q_table更新这些Q值。一般来说,智能体会选择当前收益最高的动作。我们可以用argmax函数获取"最高价值对应的索引"

智能体的动作选择
我们首先捋一下如何写训练过程:
首先明确大架构:一共训练EPISODES个批次,限制每个批次训练200步,是明显的双循环。
然后更新q_table是更新其四个动作的q,计算q需要用到当前的reward和预估的q,因此需要在每步和每批次都设计一个变量存储reward。
python
epidoe_reward=[]
for episode in range(EPISODES):
player=Cube()
food=Cube()
enemy=Cube()
episode_reward=0
for i in range(200):
#TODO 每步的训练流程接下来我们看每一步应该执行什么?
想象你在过马路:
观察环境-看看有没有来车
选择动作-思考如何过马路
执行动作-过马路
计算奖励-刚刚差点被创飞了,给的奖励低一些,刚刚欻的一下过去了,给定奖励高一些
更新策略-根据这次过马路的经验优化下次
观察环境-看看有没有来车
我们定义obs是环境,环境要包括player到food,player到enemy的状态。
python
#拿到环境状态值
obs=(player-food,player-enemy)#obs的状态 类型要和定义的q_table的状态一致这个状态类型要和q_table的状态要一致,因为选择动作要根据q_table的状态选择Q最大的动作。
选择动作-思考如何过马路
我们前面认为直接选择Q最大的动作即可,但如果每次都按照Q最大的动作做,就会进入局部最优解,因此我们设计了ε-greedy算法,也就是(1-ε)%的概率选择Q最大的动作,但有ε的概率选择其他动作。
python
#ε-Greedy
if np.random.random()>epsilon:
#Q-Learning就是在Q表中找到对应状态的最佳动作
action=np.argmax(q_table[obs])#argmax就是取最大值的索引(0-3)
else:
action = np.random.randint(0,4)#左闭右开具体如何选择最大Q的动作呢?其实就是查表,q_table存储了所有的状态,每个状态都有一个四维数组,存储着当前状态下采取各个动作预期的Q值,那么用argmax就能取出最大Q值的动作对应的下标,一会交给player的action函数执行即可。

执行动作-过马路
python
#执行动作
player.action(action)计算奖励-刚刚差点被创飞了,给的奖励低一些,刚刚欻的一下过去了,给定奖励高一些
当player与food重合时,就给FOOD_REWARD的奖励,
当player与enemy重合时,就给-ENEMY_PENALITY的惩罚,
其他情况都是移动,给予-MOVE_PENALITY的惩罚。
python
#计算奖励
if player.x==food.x and player.y==food.y:
reward=FOOD_REWARD
elif player.x==enemy.x and player.y == enemy.y:
reward = -ENEMY_PENALITY
else:
reward= -MOVE_PENALITY
print(f'reward:{reward}')更新策略-根据这次过马路的经验优化下次
我们先考虑如何更新,然后再看需要得到哪些信息:
这是Q-Learning 的更新公式,将其转换为代码如下:
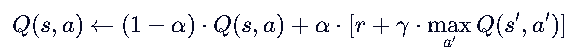
python
new_q=(1-LEARNING_RATE)*current_q + LEARNING_RATE*(reward + DISCOUNT*max_future_q)这个公式本质上是在做一个加权平均:
- (1 - 学习率) * 旧值:保留一部分旧的记忆。
- 学习率 * (即时奖励 + 预估的未来价值):加入新的经验。
我们要做的就是计算出这个new_q,然后把new_q存入到q_table中。
各参数获取
**【LEARNING_RATE】**是在参数设定一节就设好的。
python
LEARNING_RATE=0.1 #学习率 步长**【current_q】**是执行当前动作前的q值,可以根据当前的状态和选择的动作通过查表q_table获取。
python
#得到当前的q值
current_q=q_table[obs][action]#从 Q 表中取出:在当前状态 obs 下,执行动作 action 对应的 Q 值【reward】 上一步得到了。
**【DISCOUNT】**也是在参数设定一节就设好的。
python
DISCOUNT=0.95 #折扣回报 未来奖励的折扣**【max_future_q】**就比较麻烦了,要计算q就需要查表,但是这是执行完当前动作后的q表,因此要获取执行完当前动作后的状态new_obs才能查表获取(这里不用new_obsnew_action是因为我们直接取最大Q值)。
那么我们先获取new_obs,状态的定义是什么?是不是还是player与food和enemy的坐标差。
那么执行完当前动作后,他们的坐标差是什么?
是不是直接获取就好了,因为我们已经执行了动作,那当前的状态就是new_obs:
python
#更新表格需要 新obs和权衡后的q值
#得到新的状态
new_obs=(player-food,player-enemy)然后直接找这个状态下最大的Q即可:
python
max_future_q=np.max(q_table[new_obs])现在就能用这些参数更新出new_q了!
python
#更新q_table
#得到当前的q值
current_q=q_table[obs][action]#从 Q 表中取出:在当前状态 obs 下,执行动作 action 对应的 Q 值
print(f'current_q:{current_q}')
#更新表格需要 新obs和权衡后的q值
#得到新的状态
new_obs=(player-food,player-enemy)
print(f'new_obs{new_obs}')
max_future_q=np.max(q_table[new_obs])
print(f'max_future_q:{max_future_q}')
new_q=(1-LEARNING_RATE)*current_q + LEARNING_RATE*(reward + DISCOUNT*max_future_q)
print(f'new_q:{new_q}')再考虑一下边界,如果吃到食物时,是不是就是真实的奖励Q,无需预估,直接给FOOD_REAWRD即可。
python
if reward==FOOD_REWARD:#如果吃到了食物,就用实际奖励更新
new_q=FOOD_REWARD
else:
new_q=(1-LEARNING_RATE)*current_q + LEARNING_RATE*(reward + DISCOUNT*max_future_q)
print(f'new_q:{new_q}')最后把new_q存进q_table:
python
q_table[obs][action]=new_q然后别忘了把单步奖励reward加到单轮总奖励episode_reward中
python
#加上这一步的奖励
episode_reward+=reward最后再考虑一下退出本批的情况,一种是吃到食物,一种是被enemy击杀,因此要加一句
python
if reward==FOOD_REWARD or reward==-ENEMY_PENALITY:
break #如果吃到食物或被杀死就结束这一轮在内层循环外部,别忘了把每一轮的奖励append进各批次列表中,方便展示。
然后减小随机率,保证后期收敛。
python
#轮批次处理
episode_rewards.append(episode_reward)
epsilon*=EPS_DECAY完整代码:
python
#建立实例-设计超时步数-初始化环境-得到环境状态-选择动作(e-greedy)-执行动作-计算奖励-
#得到new_q(计算当前q值、计算新状态、计算未来最大q)【用q new_obs max_future_q reward】更新-
#更新q_table[obs][action]=new_q(这里是当前obs,new_obs是为了估计max_future_q)的
episode_rewards=[]
for episode in range(EPISODES):
player=Cube()
food=Cube()
enemy=Cube()
episode_reward=0
for i in range(200):#超过200步结束
#拿到环境状态值
obs=(player-food,player-enemy)#obs的状态 类型要和定义的q_table的状态一致
#ε-Greedy
if np.random.random()>epsilon:
#Q-Learning就是在Q表中找到对应状态的最佳动作
action=np.argmax(q_table[obs])#argmax就是取最大值的索引(0-3)
else:
action = np.random.randint(0,4)#左闭右开
#执行动作
player.action(action)
#计算奖励
if player.x==food.x and player.y==food.y:
reward=FOOD_REWARD
elif player.x==enemy.x and player.y == enemy.y:
reward = -ENEMY_PENALITY
else:
reward= -MOVE_PENALITY
#print(f'reward:{reward}')
#更新q_table
#得到当前的q值
current_q=q_table[obs][action]#从 Q 表中取出:在当前状态 obs 下,执行动作 action 对应的 Q 值
#print(f'current_q:{current_q}')
#更新表格需要 新obs和权衡后的q值
#得到新的状态
new_obs=(player-food,player-enemy)
#print(f'new_obs{new_obs}')
max_future_q=np.max(q_table[new_obs])
#print(f'max_future_q:{max_future_q}')
if reward==FOOD_REWARD:#如果吃到了食物,就用实际奖励更新
new_q=FOOD_REWARD
else:
new_q=(1-LEARNING_RATE)*current_q + LEARNING_RATE*(reward + DISCOUNT*max_future_q)
#print(f'new_q:{new_q}')
q_table[obs][action]=new_q
#加上这一步的奖励
episode_reward+=reward
if reward==FOOD_REWARD or reward==-ENEMY_PENALITY:
break #如果吃到食物或被杀死就结束这一轮
#轮批次处理
episode_rewards.append(episode_reward)
epsilon*=EPS_DECAY训练展示
python
# 图像显示
if show:
env = np.zeros((SIZE,SIZE,3),dtype= np.uint8)
env[food.x][food.y] = d[FOOD_N]
env[player.x][player.y] = d[PLAYER_N]
env[enemy.x][enemy.y] = d[ENEMY_N]
img = Image.fromarray(env,'RGB')
img = img.resize((800,800))
cv2.imshow('',np.array(img))
if reward == FOOD_REWARD or reward == -ENEMY_PENALITY:
if cv2.waitKey(500) & 0xFF == ord('q'):
break
else:
if cv2.waitKey(1) & 0xFF == ord('q'):
break这段代码的主要功能是将当前的游戏状态(数据)渲染成一张可视化的图片并显示出来,用于让你直观地看到智能体(Player)是如何在环境中移动的。
🎨 1. 创建画布
env = np.zeros((SIZE,SIZE,3), dtype=np.uint8)- 含义:创建一个全黑的背景图(画布)。
- 细节 :
(SIZE, SIZE, 3):表示图像的高、宽和颜色通道(RGB)。SIZE是游戏地图的大小(比如 10x10)。np.uint8:数据类型是 0-255 的整数,这是图像的标准格式。- 初始全是 0,代表黑色背景。
🖌️ 2. 绘制角色(上色)
env[food.x][food.y] = d[FOOD_N]
env[player.x][player.y] = d[PLAYER_N]
env[enemy.x][enemy.y] = d[ENEMY_N]- 含义:在画布的特定坐标点上涂上特定的颜色。
- 细节 :
d是一个字典,里面存储了定义好的颜色(RGB 元组)。例如:FOOD_N可能对应绿色,PLAYER_N对应蓝色。- 这里直接把对应坐标的像素值改成了定义好的颜色。
- 注意:这里有一个潜在的索引顺序问题,通常 numpy 数组是
[行, 列]即[y, x],但代码写的是[x][y]。如果画面显示方向不对,可能需要调整这里。
🖼️ 3. 转换与放大图像
img = Image.fromarray(env, 'RGB')
img = img.resize((800, 800))- 含义:将 numpy 数组转换为图片对象,并放大以便人眼观察。
- 细节 :
Image.fromarray:把数字矩阵变成图片。resize((800, 800)):因为原始地图可能很小(比如 10x10 像素),在屏幕上根本看不清。这里把它强行放大到 800x800 像素,每个格子会变得很大,方便调试和观看。
🖥️ 4. 显示图像
cv2.imshow('', np.array(img))- 含义:弹出一个窗口显示这张处理好的图片。
- 细节:OpenCV 需要 numpy 数组格式,所以又把 PIL 图片转回了 numpy 数组。
⏯️ 5. 控制播放速度(关键逻辑)
if reward == FOOD_REWARD or reward == -ENEMY_PENALITY:
if cv2.waitKey(500) & 0xFF == ord('q'):
break
else:
if cv2.waitKey(1) & 0xFF == ord('q'):
break这段逻辑控制动画的流畅度和暂停:
-
cv2.waitKey(毫秒数):- 这是程序的"暂停"指令。它会让程序停下来等待键盘输入,单位是毫秒。
- 正常移动时 (
else) :waitKey(1)表示只暂停 1 毫秒。这意味着动画会跑得飞快,像看视频一样。 - 游戏结束时 (
if) :waitKey(500)表示暂停 500 毫秒(0.5秒)。这是为了让你能看清最后的结果(是吃到了食物,还是撞到了敌人),否则画面一闪而过,你根本不知道发生了什么。
-
& 0xFF == ord('q'):- 这是一个检测按键的操作。
- 意思是:如果在等待期间,你按下了键盘上的 'q' 键,就执行
break,跳出循环,关闭程序。
但是每一轮都看就看不完了,有30000轮呢,于是我们考虑一开始设定的SHOW_EVERY参数,只展示每SHOW_EVERY的训练过程:
python
# 每隔一段时间设定show为True,显示图像
if episode % SHOW_EVERY == 0:
print('episode ',episode,' epsilon:',epsilon)
print('mean_reward:',np.mean(episode_rewards[-SHOW_EVERY:]))
show = True
else:
show = False完整代码:
python
#建立实例-设计超时步数-初始化环境-得到环境状态-选择动作(e-greedy)-执行动作-计算奖励-
#得到new_q(计算当前q值、计算新状态、计算未来最大q)【用q new_obs max_future_q reward】更新-
#更新q_table[obs][action]=new_q(这里是当前obs,new_obs是为了估计max_future_q)的
episode_rewards=[]
for episode in range(EPISODES):
player=Cube()
food=Cube()
enemy=Cube()
# 每隔一段时间设定show为True,显示图像
if episode % SHOW_EVERY == 0:
print('episode ',episode,' epsilon:',epsilon)
print('mean_reward:',np.mean(episode_rewards[-SHOW_EVERY:]))
show = True
else:
show = False
episode_reward=0
for i in range(200):#超过200步结束
#拿到环境状态值
obs=(player-food,player-enemy)#obs的状态 类型要和定义的q_table的状态一致
#ε-Greedy
if np.random.random()>epsilon:
#Q-Learning就是在Q表中找到对应状态的最佳动作
action=np.argmax(q_table[obs])#argmax就是取最大值的索引(0-3)
else:
action = np.random.randint(0,4)#左闭右开
#print(player)
#print(obs)
#print(action)
#执行动作
player.action(action)
#food.action
#print('after action:')
#print(player)
#计算奖励
if player.x==food.x and player.y==food.y:
reward=FOOD_REWARD
elif player.x==enemy.x and player.y == enemy.y:
reward = -ENEMY_PENALITY
else:
reward= -MOVE_PENALITY
#print(f'reward:{reward}')
#更新q_table
#得到当前的q值
current_q=q_table[obs][action]#从 Q 表中取出:在当前状态 obs 下,执行动作 action 对应的 Q 值
#print(f'current_q:{current_q}')
#更新表格需要 新obs和权衡后的q值
#得到新的状态
new_obs=(player-food,player-enemy)
#print(f'new_obs{new_obs}')
max_future_q=np.max(q_table[new_obs])
#print(f'max_future_q:{max_future_q}')
#逻辑:智能体当前可能因为 ϵ -greedy 探索策略而做了一个"傻事"(比如撞墙),或者做了一个次优动作。
#目标:但我们更新 Q 值时,不应该参考那个"傻事",而是要参考如果我们在那个新位置(s')重新开始,最聪明的做法能拿多少分。
#结果:这使得 Q-Learning 的更新目标(Target)总是朝着"最好"的方向修正,最终收敛到最优解。
if reward==FOOD_REWARD:#如果吃到了食物,就用实际奖励更新
new_q=FOOD_REWARD
else:
new_q=(1-LEARNING_RATE)*current_q + LEARNING_RATE*(reward + DISCOUNT*max_future_q)
#print(f'new_q:{new_q}')
q_table[obs][action]=new_q
# 图像显示
if show:
env = np.zeros((SIZE,SIZE,3),dtype= np.uint8)
env[food.x][food.y] = d[FOOD_N]
env[player.x][player.y] = d[PLAYER_N]
env[enemy.x][enemy.y] = d[ENEMY_N]
img = Image.fromarray(env,'RGB')
img = img.resize((800,800))
cv2.imshow('',np.array(img))
if reward == FOOD_REWARD or reward == -ENEMY_PENALITY:
if cv2.waitKey(500) & 0xFF == ord('q'):
break
else:
if cv2.waitKey(1) & 0xFF == ord('q'):
break
#加上这一步的奖励
episode_reward+=reward
if reward==FOOD_REWARD or reward==-ENEMY_PENALITY:
break #如果吃到食物或被杀死就结束这一轮
#轮批次处理
episode_rewards.append(episode_reward)
epsilon*=EPS_DECAY
训练结果解析
从头执行到这里,可以看到如下输出:
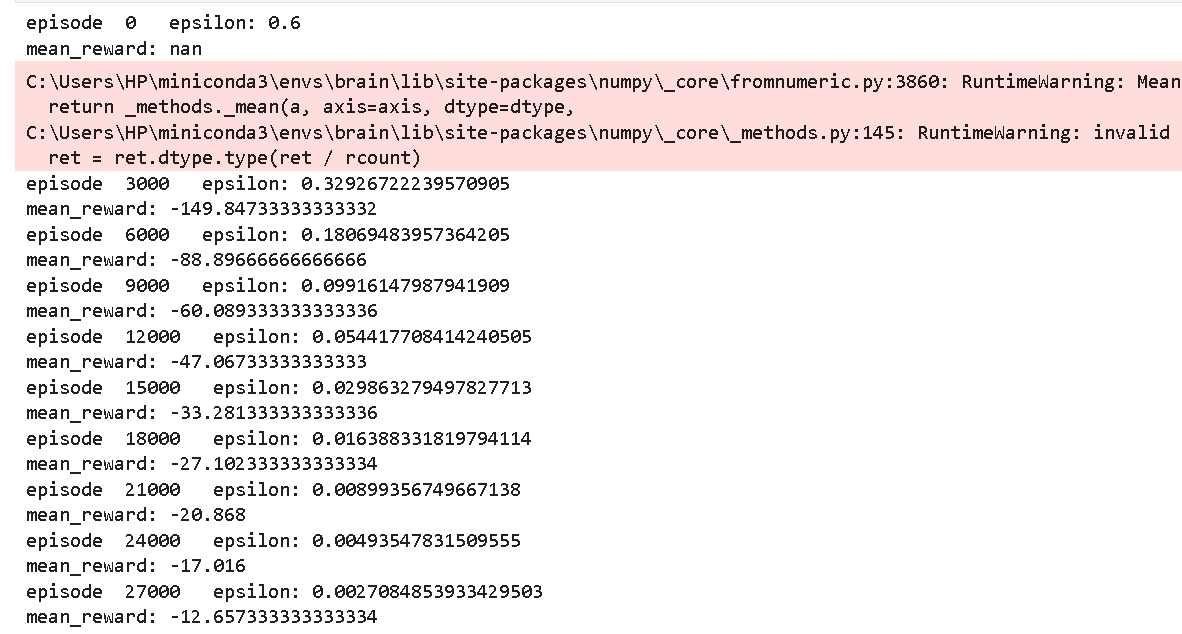
可以发现,收敛非常快,从-150到-12,在动绘中也能看出后期几乎是瞬间就吃到了绿点(FOOD)
统计量输出
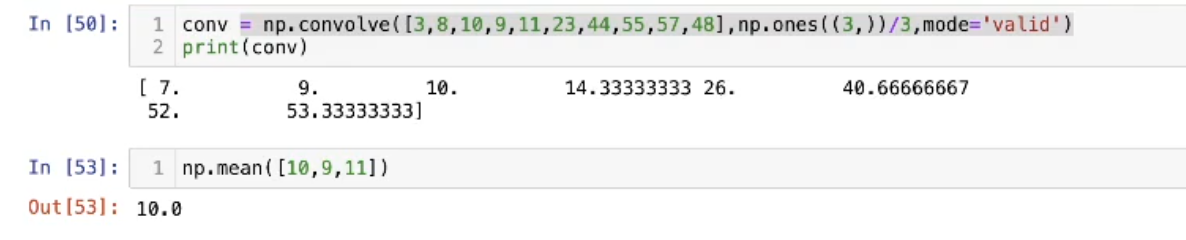
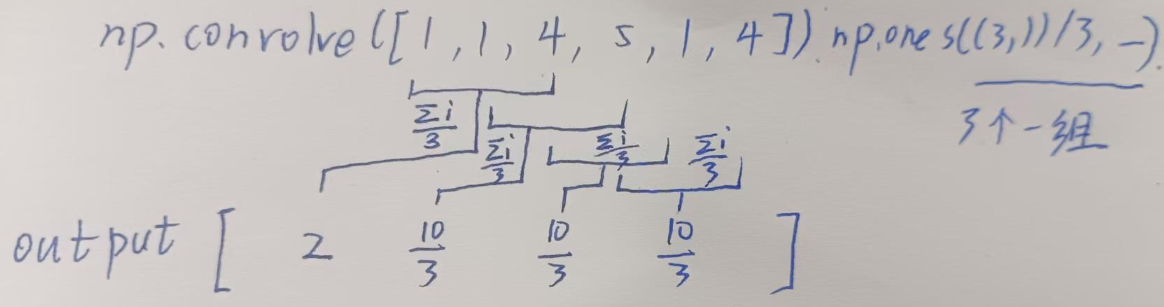
我们希望得到各个批次的奖励是如何变化的,我们不希望每一个批次都单独输出,而是平滑一些,取相邻几次和自己的平均一起输出,我们可以用卷积函数:
卷积就是对每k个数取mean:
python
moving_avg = np.convolve(episode_rewards, np.ones((SHOW_EVERY,))/SHOW_EVERY,mode='valid')
plt.plot([i for i in range(len(moving_avg))], moving_avg)
plt.xlabel('episode #')
plt.ylabel(f'mean{SHOW_EVERY} reward')
plt.show()-
原理:
np.ones((SHOW_EVERY,))/SHOW_EVERY创建了一个长度为SHOW_EVERY的窗口,里面每个值都是 1/N 。- 当这个窗口在数据上"滑过"时,每滑一步,它就会把覆盖住的那几个数加起来乘以 1/N 。
- 这本质上就是在算平均值。
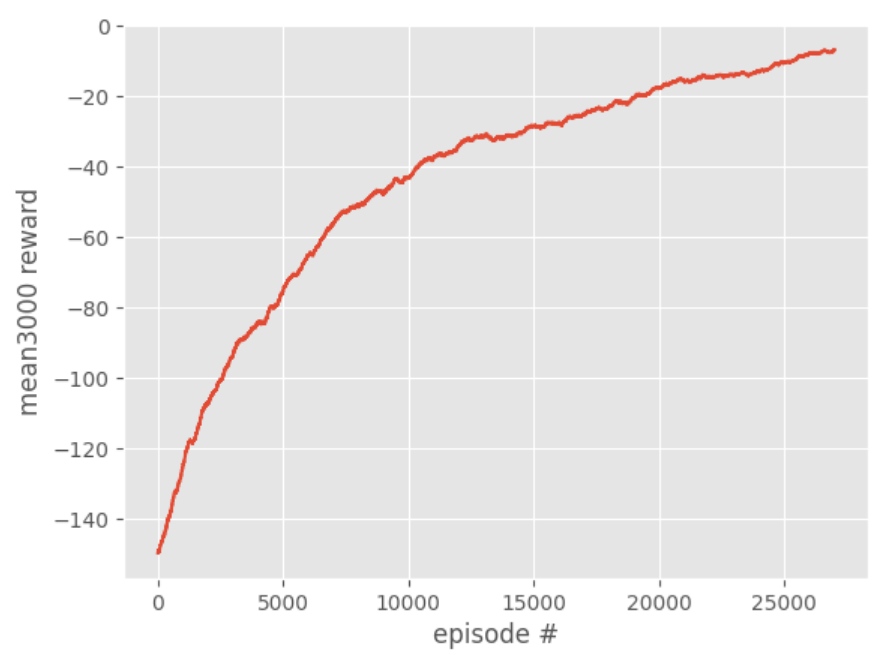
可以看出,整个过程非常稳定!
保存q_table
最后的最后,把训练的参数q_table存入文件中,用时间命名。
with open(f'qtable_{int(time.time())}.pickle','wb') as f:
pickle.dump(q_table,f)这样,我们下一次就可以调用上一次的训练模型继续优化
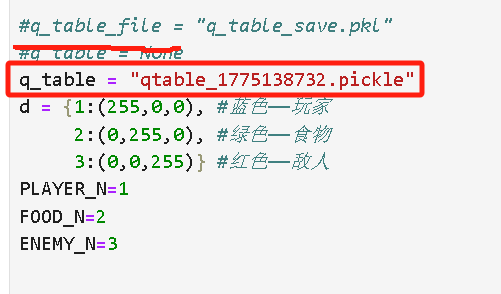
找到保存的文件名:
在第一部分原本填None的地方填上面的pickle文件,然后从头执行一遍即可。(因为到q_table初始化一段有自动判断,如果有历史训练数据就会自动调用,不再触发初始化)
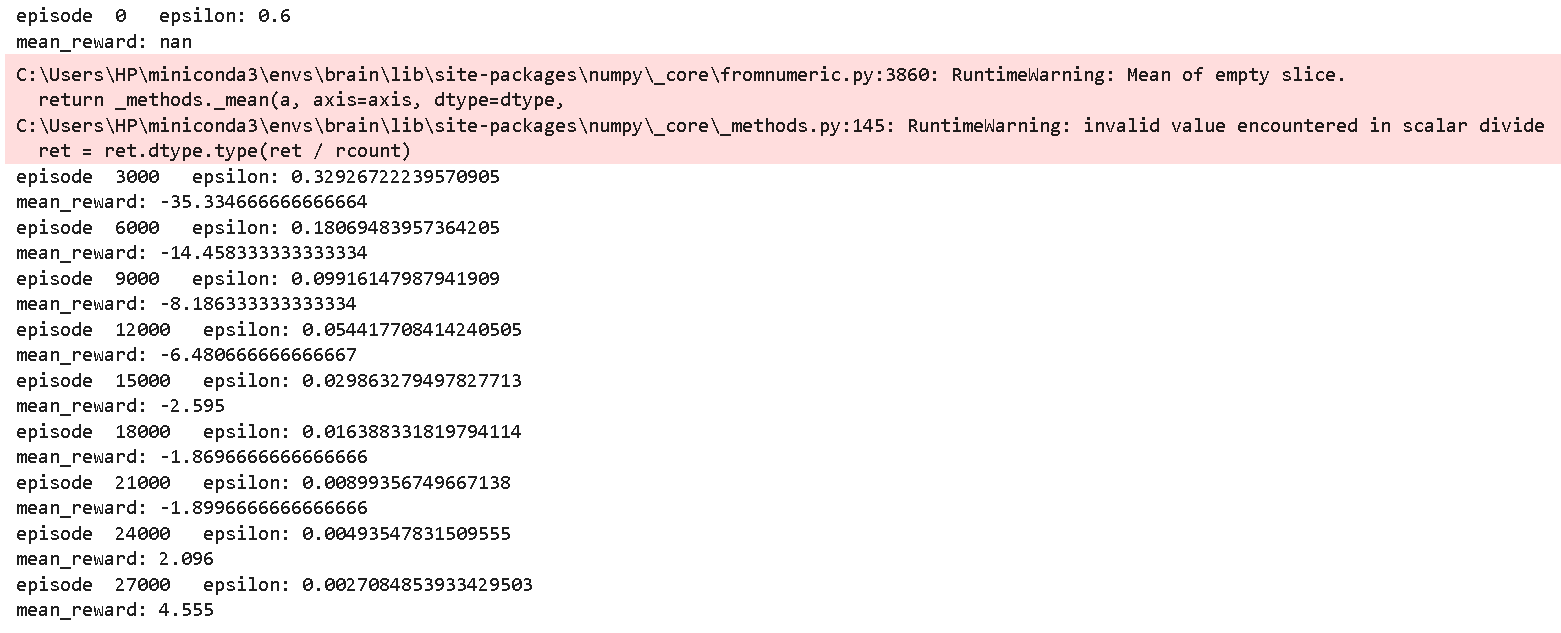
可以发现,这次直接从-35而不是-150开始训练,直接站在巨人的肩膀上,这次奖励甚至为正数了!
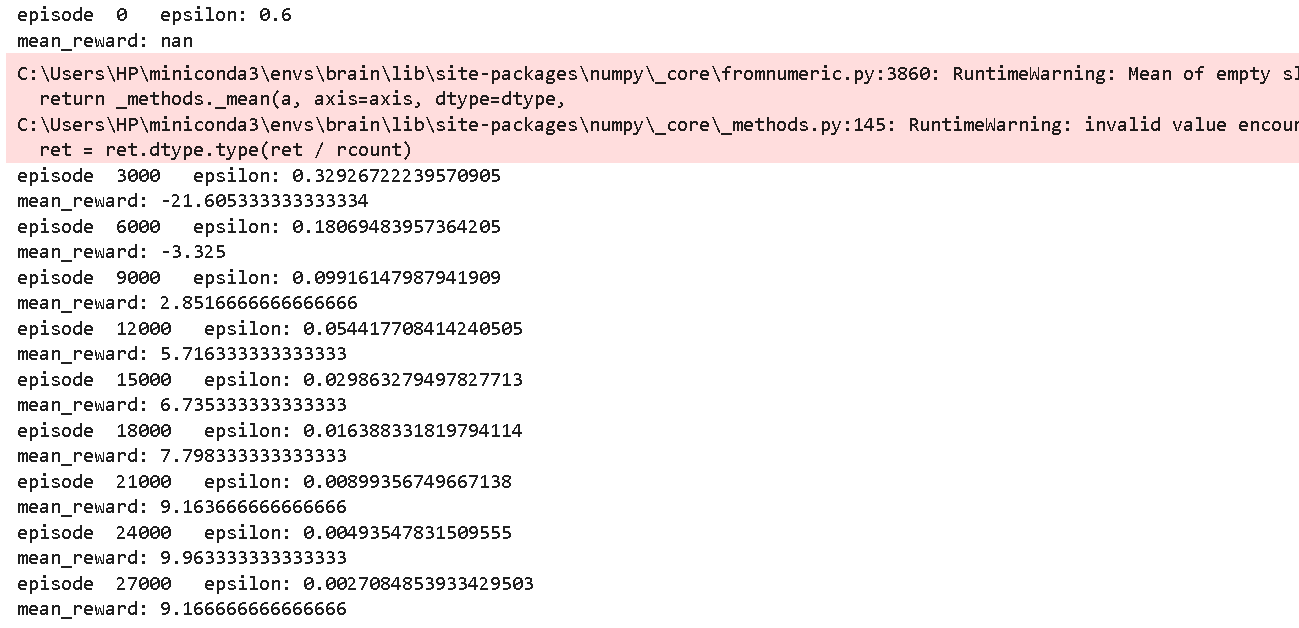
再迭代一轮,奖励就接近10了,非常好。
完整代码
导入依赖库
python
#将学习环境所需要的依赖库导入
import numpy as np
import cv2
from PIL import Image
import time
import pickle #对象到文件的处理
import matplotlib.pyplot as plt
from matplotlib import style
style.use('ggplot')填写参数
python
#环境参数设定
SIZE=10 #3个对象在10*10的范围内
EPISODES=30000 #智能体玩的游戏轮数
SHOW_EVERY=3000 #每3000局展示一次游玩过程
#奖励与惩罚
FOOD_REWARD=25#吃食物的奖励
ENEMY_PENALITY=300 #被敌人抓住的惩罚
MOVE_PENALITY=1 #移动惩罚
#环境计算参数
epsilon=0.6 #在强化学习时抽取随机动作的概率 40%使用最大价值期望动作
EPS_DECAY=0.9998 #每玩一局游戏就让随机动作概率乘以这个数,到最后基本就定性了
DISCOUNT=0.95 #折扣回报 未来奖励的折扣
LEARNING_RATE=0.1 #学习率 步长
#q_table_file = "q_table_save.pkl"
#q_table = None
q_table = "qtable_1775139173.pickle"
d = {1:(255,0,0), #蓝色------玩家
2:(0,255,0), #绿色------食物
3:(0,0,255)} #红色------敌人
PLAYER_N=1
FOOD_N=2
ENEMY_N=3创建对象类
python
#为三个对象创建类
class Cube:
def __init__(self):#初始位置
self.x=np.random.randint(0,SIZE-1)
self.y=np.random.randint(0,SIZE-1)
def __str__(self): #打印当前位置
return f'{self.x},{self.y}'
def __sub__(self,other):#这个类的另一个实体
return (self.x-other.x,self.y-other.y)
def action(self,choise):
if choise == 0:
self.move(x=1,y=1)
elif choise == 1:
self.move(x=-1,y=1)
elif choise == 2:
self.move(x=1,y=-1)
elif choise == 3:
self.move(x=-1,y=-1)
def move(self,x=False,y=False):
if not x:#如果x没有给值
self.x += np.random.randint(-1,2)
else:
self.x += x
if not y:#如果y没有给值
self.y += np.random.randint(-1,2)
else:
self.y += y
#考虑边界
if self.x<0:
self.x=0
elif self.x>=SIZE:
self.x=SIZE-1
if self.y<0:
self.y=0
elif self.y>=SIZE:
self.y=SIZE-1
初始化q_table
python
#q_table初始化 整个状态空间有19^4个状态 存储玩家和食物、玩家和敌人的距离作为状态,二者距离差在-9-9之间,有19*19个状态,三个对象有361*361个对象
#内部存储当前最佳的动作
# 初始化Q表格
if q_table is None: # 如果没有实现提供,就随机初始化一个Q表格
q_table = {}
for x1 in range(-SIZE+1,SIZE):
for y1 in range(-SIZE + 1, SIZE):
for x2 in range(-SIZE + 1, SIZE):
for y2 in range(-SIZE + 1, SIZE):
q_table[((x1,y1),(x2,y2))] = [np.random.randint(-5,0) for i in range(4)]
#这是值,一个包含 4 个元素的列表。
#np.random.uniform(-5,0):给这 4 个动作随机赋一个负数的初始价值(比如 -2.3, -1.5, -4.0, -0.5)。
#注意:这里存的是价值,不是概率。如果想看概率,需要额外的数学运算(如 Softmax),但 Q-Learning 通常直接用 argmax 拿最大值的索引来作为动作。
else: # 提供了,就使用提供的Q表格
with open(q_table,'rb') as f:
q_table= pickle.load(f)
智能体动作选择
python
#建立实例-设计超时步数-初始化环境-得到环境状态-选择动作(e-greedy)-执行动作-计算奖励-
#得到new_q(计算当前q值、计算新状态、计算未来最大q)【用q new_obs max_future_q reward】更新-
#更新q_table[obs][action]=new_q(这里是当前obs,new_obs是为了估计max_future_q)的
episode_rewards=[]
for episode in range(EPISODES):
player=Cube()
food=Cube()
enemy=Cube()
# 每隔一段时间设定show为True,显示图像
if episode % SHOW_EVERY == 0:
print('episode ',episode,' epsilon:',epsilon)
print('mean_reward:',np.mean(episode_rewards[-SHOW_EVERY:]))
show = True
else:
show = False
episode_reward=0
for i in range(200):#超过200步结束
#拿到环境状态值
obs=(player-food,player-enemy)#obs的状态 类型要和定义的q_table的状态一致
#ε-Greedy
if np.random.random()>epsilon:
#Q-Learning就是在Q表中找到对应状态的最佳动作
action=np.argmax(q_table[obs])#argmax就是取最大值的索引(0-3)
else:
action = np.random.randint(0,4)#左闭右开
#print(player)
#print(obs)
#print(action)
#执行动作
player.action(action)
#food.action
#print('after action:')
#print(player)
#计算奖励
if player.x==food.x and player.y==food.y:
reward=FOOD_REWARD
elif player.x==enemy.x and player.y == enemy.y:
reward = -ENEMY_PENALITY
else:
reward= -MOVE_PENALITY
#print(f'reward:{reward}')
#更新q_table
#得到当前的q值
current_q=q_table[obs][action]#从 Q 表中取出:在当前状态 obs 下,执行动作 action 对应的 Q 值
#print(f'current_q:{current_q}')
#更新表格需要 新obs和权衡后的q值
#得到新的状态
new_obs=(player-food,player-enemy)
#print(f'new_obs{new_obs}')
max_future_q=np.max(q_table[new_obs])
#print(f'max_future_q:{max_future_q}')
#逻辑:智能体当前可能因为 ϵ -greedy 探索策略而做了一个"傻事"(比如撞墙),或者做了一个次优动作。
#目标:但我们更新 Q 值时,不应该参考那个"傻事",而是要参考如果我们在那个新位置(s')重新开始,最聪明的做法能拿多少分。
#结果:这使得 Q-Learning 的更新目标(Target)总是朝着"最好"的方向修正,最终收敛到最优解。
if reward==FOOD_REWARD:#如果吃到了食物,就用实际奖励更新
new_q=FOOD_REWARD
else:
new_q=(1-LEARNING_RATE)*current_q + LEARNING_RATE*(reward + DISCOUNT*max_future_q)
#print(f'new_q:{new_q}')
q_table[obs][action]=new_q
# 图像显示
if show:
env = np.zeros((SIZE,SIZE,3),dtype= np.uint8)
env[food.x][food.y] = d[FOOD_N]
env[player.x][player.y] = d[PLAYER_N]
env[enemy.x][enemy.y] = d[ENEMY_N]
img = Image.fromarray(env,'RGB')
img = img.resize((800,800))
cv2.imshow('',np.array(img))
if reward == FOOD_REWARD or reward == -ENEMY_PENALITY:
if cv2.waitKey(500) & 0xFF == ord('q'):
break
else:
if cv2.waitKey(1) & 0xFF == ord('q'):
break
#加上这一步的奖励
episode_reward+=reward
if reward==FOOD_REWARD or reward==-ENEMY_PENALITY:
break #如果吃到食物或被杀死就结束这一轮
#轮批次处理
episode_rewards.append(episode_reward)
epsilon*=EPS_DECAY
刻画统计量曲线
python
moving_avg = np.convolve(episode_rewards, np.ones((SHOW_EVERY,))/SHOW_EVERY,mode='valid')
plt.plot([i for i in range(len(moving_avg))], moving_avg)
plt.xlabel('episode #')
plt.ylabel(f'mean{SHOW_EVERY} reward')
plt.show()保存q_table
python
with open(f'qtable_{int(time.time())}.pickle','wb') as f:
pickle.dump(q_table,f)