小T导读:在 "双碳" 目标推动下,水泥行业需同时破解高能耗精细化管控与环保数据长期合规存储难题,海螺信息作为海螺水泥集团核心信息化主体,承担着全国 100 余家工厂的能源与环保数据管理职责,却面临异构设备数据治理难、存储成本高企、能耗异常响应慢等痛点。通过 TDengine 时序数据库(Time Series Database)分库架构、多级存储(0 级 SSD/1 级 HDD/S3)及时序 SQL 函数提供解决方案,不仅实现存储成本降低 70%、能源监控大屏实时查询延迟<500ms,还将能耗异常检测响应时间压缩至<2 秒,报表生成效率提升 90%,为水泥行业时序数据管理提供高效可落地的实践路径。
背景和痛点
水泥生产以 "连续运行、高能耗、强合规" 为核心特性,覆盖 "生料制备→熟料煅烧→水泥制成→环保处理" 全流程,各环节数据管理需求明确:生料需精准管控配比与能耗以筑牢质量基础,熟料要稳定温度并优化燃料消耗、余热回收效率,水泥制成需平衡成品质量与能耗成本,环保处理需长期留存数据以满足合规审计。
但数据管理存在核心痛点:
-
环保数据管理难:环保数据需保存 5 年,保存所有数据存储成本高;调取历史数据需扫描大量数据文件,查询耗时过长,且人工备份存在数据丢失风险。
-
存储成本过高:热冷数据混存浪费 SSD 资源,且数据增量快、扩容频繁,整体存储成本高。
-
数据割裂与协同难:各环节数据分散存储,无法联动分析(如煅烧温度与余热发电的关联);不同工厂数据标签不统一(如 "研磨能耗" 记为 "粉碎能耗"),跨厂统计需手动匹配,效率极低。
-
核算与报表效率低:单厂日能耗报表及多厂月度汇总耗时长,核算与报表效率难以满足业务时效要求。
TDengine 整体解决方案
针对上述痛点,结合 TDengine TSDB 特性,我们决定从 "分库设计、多级存储与 S3 归档、超级表优化、核心 SQL 应用" 四大维度构建全链路解决方案,且与海螺信息业务流程深度适配:
分库设计:全量 - 分库的精细化管控
基于生产运行、能源管理、环保合规场景特性,明确 TDengine TSDB 中三库分工,解决数据混存问题,每库的参数均对应具体业务需求:
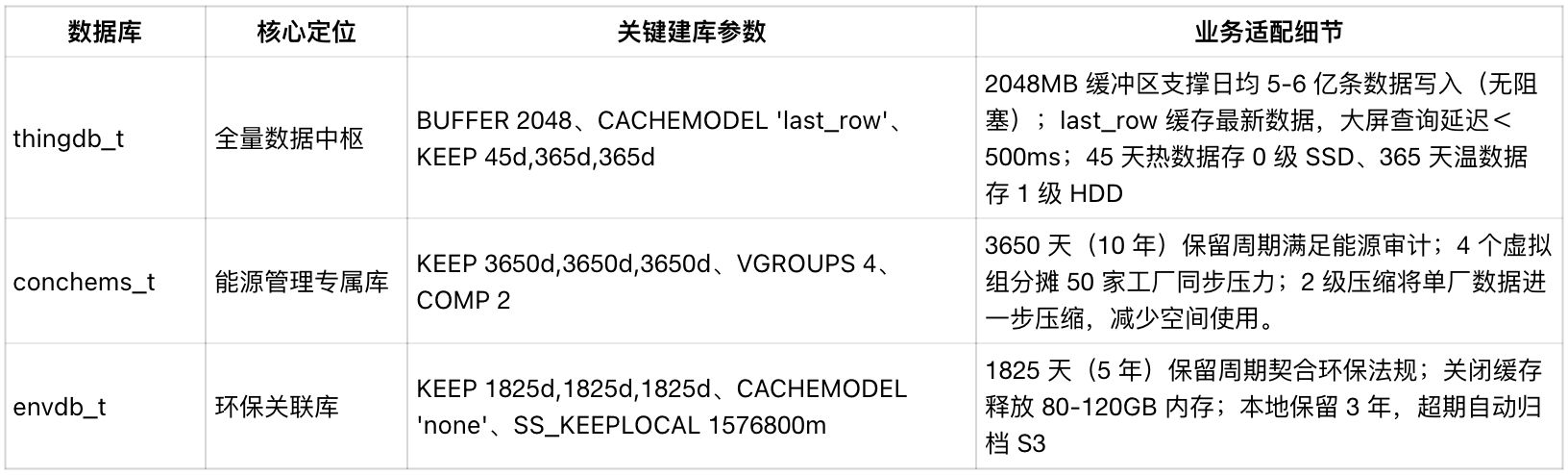
多级存储 + S3 归档:平衡效率与成本
我们通过 TDengine TSDB 多级存储及对象存储功能,实现数据 "热→温→冷" 自动分层,且冷数据超期后归档至 S3,解决存储成本与归档难题:
多级存储分层逻辑(对应现场数据特性)
-
0 级存储(热数据,45 天) :介质为 SSD,对应
thingdb_t.KEEP 45d,存储水泥磨实时电流、余热功率等高频访问数据,CACHEMODEL 'last_row'确保大屏 5 秒轮询时响应时间<500ms;优化效果:单厂大屏查询延迟从 1.2-1.8 秒降至 300-500ms,运维人员盯屏无卡顿,后续未再错过预警。 -
1 级存储(温数据,45 天-1 年) :介质为 HDD,对应
thingdb_t.KEEP 365d,存储周 / 月报表数据,COMP 2压缩后数据压缩率可达到10%,节省大量 HDD 磁盘存储成本。 -
共享存储(冷数据,3年以上) :介质为 HDD+S3,
envdb_t的 共享存储存 3 年以上数据。通过对象存储周期参数SS_KEEPLOCAL 1576800m(3 年)设置本地保留周期,超过 3 年自动归档至对象存储,本地仅保留索引。对象存储的使用,使环保合规数据归档耗时从原来的 150-250 小时 / 月降至 0,无数据丢失风险。
S3 归档的实操配置与查询优化
TDengine TSDB 启动对象存储非常便捷,只需配置对象存储路径,以及存储参数,即可实现指定周期数据文件自动迁移,无需人工操作。
且 TDengine TSDB 通过本地索引可以快速定位 S3 文件,响应时间优化了 5 倍,满足环保审计需求。
- /etc/taos/taos.cfg 中添加 S3 对接配置如下:

- 数据库参数调整如下:
SQL
ALTER DATABASE envdb_t
SS_CHUNKPAGES 131072 -- 按131072页打包,提升传输效率
SS_KEEPLOCAL 1576800m; -- 本地保留3年超级表与标签体系:解决编码混乱与统计效率
通过超级表的设计,构建标准化标签体系,提升数据治理与统计效率:
超级表设计与场景适配
-
生产运行库(thingdb_t)、能源管理库(conchems_t)及环保合规库(envdb_t)超级表均采用简捷的单列模型,包括
ts(时间戳)、point_value(数据值)、quality(数据质量状态) -
通过 TAG 标签来区分关键业务要素,各库超级表仅保留个性业务标签,适配各自业务场景,设计如下:

标签标准化治理的实操步骤
-
制定标签规则:明确
point_id格式为 "业务类型_工厂编码_设备类型_序号"(如EMS_F001_CEMENTMILL_01),point_name统一为中文业务名,新接入设备严格按规则配置; -
存量数据补录:通过批量 SQL 补录老数据标签,示例如下:
SQL
ALTER TABLE thingdb_t.tbname
tag point_name = '某电力室_某库某区尾部***收尘风机_C相电流',
point_id = 'DG_SNKD_***_Ic' - 补录后跨 20-30 家工厂统计时间从 1-2 天缩短至 1 小时以内,每月节省运维工时 15-20 小时。
核心 SQL 应用示例:支撑能源管理关键场景
我们通过 TDengine TSDB 时序函数(diff、spread、last_row等)编写核心 SQL,覆盖 "能耗差异分析、异常检测、波动统计、实时监控" 四大关键场景,以下为整理后的完整 SQL 及业务意义:
- 能耗波动范围统计 :
spread(point_value)计算指定时段内能耗的波动范围,用于设备能耗稳定性分析(如判断脱硫风机的电流波动是否正常),波动超阈值时触发维护提醒。
SQL
SELECT
spread(point_value) AS energy_spread, -- 计算数值极差(最大值-最小值)
quality,
oa_code,
point_name,
point_id
FROM conchems_t.conchems_base
WHERE
1 = 1
AND point_id IN ('DG_YL5_SCRKYJ1_Ea', 'DG_YL5_SCRKYJ1_Eb',......)
AND oa_code = 'F003'AND ts <= '2025-10-30 00:00:00'
AND ts >= '2025-10-01 00:00:00' GROUP BY quality, oa_code, point_name, point_id;- 能耗累计差异统计 :
diff(point_value, 3)按步长 3 计算能耗差异,SUM累计后得到指定时段内的总能耗变化,用于能耗总量核算(如每日水泥磨总耗电量统计),支撑成本分摊。
SQL
SELECT
SUM(diff) AS total_energy_diff,
point_id,
point_name,
oa_code
FROM (SELECT
diff(point_value, 3) AS diff,
oa_code,
point_name,
point_id,
ts
FROM conchems_t.conchems_base
WHERE
1 = 1 AND point_id IN ('DG_95_0005_Er', 'DG_95_0005_Ia', ...... ) -- 补充完整测点)AND oa_code = 'F004'AND ts BETWEEN '2025-10-01 00:00:00' AND '2025-10-31 00:00:00'PARTITION BY tbname
AND oa_code = 'F004' AND ts BETWEEN '2025-10-30 00:00:00' AND '2025-10-31 00:00:00'
) AS sub_query
GROUP BY point_id, point_name, oa_code;- 时间窗口能耗累计修正 :按时间窗口(如 1 小时)计算能耗累计差异,通过
CASE修正窗口起始与查询起始不一致的情况,用于精准能耗统计(如小时级余热发电量修正),避免统计偏差。
SQL
SELECT
CASE
WHEN _wstart > _qstart THEN SUM(step_diff) - FIRST(step_diff)
else sum(diff) end as spreadvalue ,
_wstart AS wstart,
_wend AS wend,
point_id
FROM (SELECT
diff(point_value, 3) AS step_diff,
point_value,
oa_code,
point_name,
point_id,
ts
WHERE
1 = 1 AND point_id IN ('DG_YL12_YLB1_E', 'DG_YT45_3BYQ_E', 'DG_YL4_13092_E',......)
AND oa_code = 'F005'AND ts BETWEEN '2025-10-01 00:00:00' AND '2025-10-31 00:00:00' )
partition by point_id INTERVAL(1h) ;- 设备最新能耗值查询 :
LAST_ROW函数快速获取设备最新能耗数据,用于监控大屏实时展示(如水泥磨当前电流、余热发电当前功率),运维人员可直观掌握设备运行状态。
SQL
SELECT
LAST_ROW(*),
point_name,
point_id
FROM conchems_t.conchems_base
WHERE
oa_code = '01030206' AND point_id IN ('DG_MTHF_0109_E', 'DG_YM3_0110_E'......);未来规划
为进一步提升数据利用价值,我们已在验证使用 TDengine IDMP 工业数据管理平台:
-
组态可视化功能:IDMP 支持植入水泥行业专用矢量图(如电机、仪表图标),可直接读取 TDengine 时序数据库中存储的生产、环保、能源数据,生成 B/S 端可视化组态界面,替代传统 C/S 架构的组态软件,降低跨终端访问门槛;
-
智能分析扩展:IDMP 支持配置大模型接口(如 DeepSeek),未来可基于 TDengine 时序数据库中存储的历史数据,训练设备故障预测模型、能耗优化模型,推动集团从 "被动监控" 向 "主动预警" 升级。
关于海螺信息
安徽海螺信息技术工程有限责任公司成立于 2008 年 6 月,是安徽海螺水泥股份有限公司全资子公司,位于安徽省芜湖市,是海螺集团国家级企业技术中心、"绿色建材与高端制造安徽省技术中心"骨干成员单位。先后获得国家高新技术企业及安徽省软件企业,入选国家级"专精特新"小巨人企业、安徽省"专精特新"冠军企业、安徽省制造业与互联网融合发展试点企业、安徽省服务型制造示范平台、安徽省企业技术中心以及安徽省工业互联网"十大服务商"、安徽省制造业数字化转型服务商名单等称号,取得多项发明专利、计算机软件著作权、软件产品注册认证,在工业互联网、智能工厂、企业信息化等方面构建起管理咨询、解决方案与产品、数据运维服务、数据监理服务的全流程全周期的服务体系。
关于作者
海螺信息研发团队,深耕水泥行业信息化领域,专注于通过技术创新解决生产全流程数据管理难题,助力行业数字化转型。