本文分享记录复现 π0.5、π0-FAST、π0的环境搭建、模型推理。
开源地址 :https://github.com/Physical-Intelligence/openpi
开发资源:(需要一块至少满足以下规格的 NVIDIA GPU)
| 模式 | 所需内存 | 示例 GPU |
|---|---|---|
| 推理 | 大于 8 GB | RTX 4090 |
| 微调(LoRA) | > 22.5 GB | RTX 4090 |
| 微调(完整版) | 70 GB | A100 (80GB) / H100 |
1、环境搭建
首先下载 openpi 的开源代码,支持π0.5、π0-FAST、π0等系列,执行命令:
git clone --recurse-submodules https://github.com/Physical-Intelligence/openpi.git
git submodule update --init --recursive我们使用uv来管理 Python 依赖项
如果没有安装uv,先进行安装:
curl -LsSf https://astral.sh/uv/install.sh | sh安装过程,可以默认选择y
安成完成后,打印信息:
(base) lgp@lgp-MS-7E07:~/2026/openpi$ curl -LsSf https://astral.sh/uv/install.sh | sh
downloading uv 0.11.3 x86_64-unknown-linux-gnu
installing to /home/lgp/.local/bin
uv
uvx
everything's installed!
uv安装参考:https://docs.astral.sh/uv/getting-started/installation/
使用命令uv --version,能看到:uv 0.11.3 (x86_64-unknown-linux-gnu)
然后使用uv,来安装开发环境的相关依赖库
GIT_LFS_SKIP_SMUDGE=1 uv sync
安装openpi,执行下面命令:
GIT_LFS_SKIP_SMUDGE=1 uv pip install -e .打印信息:
Resolved 204 packages in 1.56s
Built openpi @ file:///home/lgp/2026/openpi
Prepared 1 package in 147ms
Uninstalled 1 package in 0.34ms
Installed 1 package in 0.30ms
使用下面命令,切换刚才使用uv搭建好的环境
source .venv/bin/activate(base) lgp@lgp-MS-7E07:~/2026/openpi **(base) lgp@lgp-MS-7E07:\~/2026/openpi source .venv/bin/activate**
(openpi) (base) lgp@lgp-MS-7E07:~/2026/openpi$
(openpi) (base) lgp@lgp-MS-7E07:~/2026/openpi$
说明:因为之前安装Conda,会有一个base环境,可以使用conda deactivate命令退出(base)的
(openpi)环境是刚才使用uv搭建好的环境
2、模型权重下载
目前openpi 的开源的模型,如下表格所示:
| 模型 | 用例 | 描述 | 检查点路径 |
|---|---|---|---|
| π0-FAST-DROID | 推理 | π0-基于DROID数据集微调的FAST模型:能够在DROID机器人平台上执行各种简单的桌面操作任务,无需在新场景中进行任何测试。 | gs://openpi-assets/checkpoints/pi0_fast_droid |
| π0-DROID | 微调 | π0在DROID 数据集上微调的模型:推理速度比以往更快π0-FAST-DROID,但可能无法很好地遵循语言命令。 | gs://openpi-assets/checkpoints/pi0_droid |
| π0-ALOHA-towel | 推理 | π0基于ALOHA内部数据微调的模型:可在ALOHA机器人平台上零次折叠各种毛巾 | gs://openpi-assets/checkpoints/pi0_aloha_towel |
| π0-ALOHA-tupperware | 推理 | π0基于ALOHA内部数据微调的模型:可以从特百惠容器中取出食物 | gs://openpi-assets/checkpoints/pi0_aloha_tupperware |
| π0-ALOHA-pen-uncap | 推理 | π0基于公开的ALOHA数据微调的模型:可以打开笔帽 | gs://openpi-assets/checkpoints/pi0_aloha_pen_uncap |
| π0.5-LIBERO | 推理 | π0.5针对LIBERO基准测试进行了微调的模型:获得了最先进的性能(参见LIBERO README) | gs://openpi-assets/checkpoints/pi05_libero |
| π0.5-DROID | 推理/微调 | π0.5在DROID数据集上进行微调并实现知识隔离的模型:推理速度快,语言跟随性能好 | gs://openpi-assets/checkpoints/pi05_droid |
默认情况下,检查点会在需要时自动下载gs://openpi-assets并缓存~/.cache/openpi
但是默认下载,太慢了(即使使用了科学上网),我们可以使用谷歌的 gsutil
# 下载并安装 Google Cloud SDK
curl https://sdk.cloud.google.com | bash
# 设置环境变量
export PATH="$HOME/google-cloud-sdk/bin:$PATH"
# 重启终端或执行
source ~/.bashrc
# 验证
gcloud --version
gsutil --version打印信息:
lgp@lgp-MS-7E07:~/2026/openpi** **export PATH="HOME/google-cloud-sdk/bin:$PATH"
lgp@lgp-MS-7E07:~/2026/openpi **lgp@lgp-MS-7E07:\~/2026/openpi which gsutil**
/home/lgp/google-cloud-sdk/bin/gsutil
lgp@lgp-MS-7E07:~/2026/openpi$ gsutil versionGoogle recommends using Gcloud storage CLI (https://docs.cloud.google.com/storage/docs/discover-object-storage-gcloud) instead of gsutil. Please refer to migration guide (https://docs.cloud.google.com/storage/docs/gsutil-transition-to-gcloud) for assistance.
gsutil version: 5.36lgp@lgp-MS-7E07:~/2026/openpi$
在openpi工程目录下,新建一个文件夹checkpoints,用于存放模型权重
下载"pi0_fast_droid"模型,执行下面命令:
gsutil -m cp -r gs://openpi-assets/checkpoints/pi0_fast_droid ./checkpoints/下载速度还是挺快的,70m/s左右
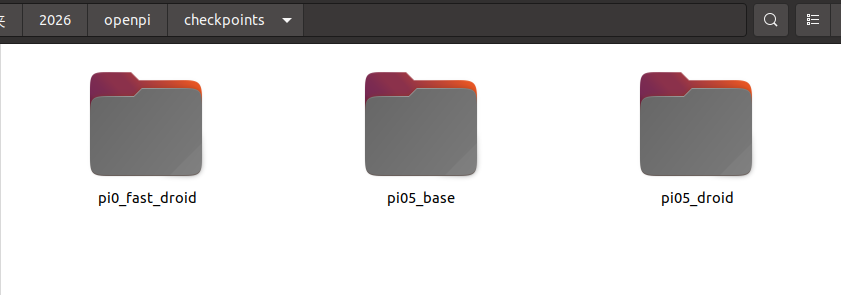
下载其他模型,只需替换 gs://openpi-assets/checkpoints/pi05_droid 链接就可以啦(上面表格有)
比如下载pi05_droid,对应下面的命令
gsutil -m cp -r gs://openpi-assets/checkpoints/pi05_droid ./checkpoints/下载好后的权重路径:
3、模型推理------入门示例
这里功能是加载预训练的机器人VLA模型,并执行推理,具体说明如下:
| 步骤 | 功能说明 |
|---|---|
| 1. 配置加载 | 获取 pi05_droid 模型的配置参数 |
| 2. 加载 Checkpoint | 从本地路径 ./checkpoints/pi05_droid 加载预训练模型权重 |
| 3. 创建策略 | 基于配置和权重实例化一个可执行的策略对象 |
| 4. 运行推理 | 使用虚拟示例数据(dummy example)执行前向推理 |
| 5. 输出结果 | 打印预测动作序列的形状(如 (15, 8) 表示15个时间步,每步8维动作) |
| 6. 释放资源 | 删除策略对象释放 GPU 显存/内存 |
运行代码:
python
import dataclasses
import jax
from pathlib import Path
from openpi.models import model as _model
from openpi.policies import droid_policy
from openpi.policies import policy_config as _policy_config
from openpi.training import config as _config
# 获取模型配置(pi05_droid配置)
config = _config.get_config("pi05_droid")
# ========== 修改:使用本地路径 ==========
# 原始路径:checkpoint_dir = Path("./checkpoints/pi0_fast_droid")
# 修改为本地已下载的checkpoint路径
checkpoint_dir = Path("./checkpoints/pi05_droid")
# 验证checkpoint路径是否存在,不存在则报错
assert checkpoint_dir.exists(), f"Checkpoint not found: {checkpoint_dir}"
print(f"Loading checkpoint from: {checkpoint_dir.absolute()}")
# 创建训练好的策略(加载模型权重和配置)
policy = _policy_config.create_trained_policy(config, checkpoint_dir)
# 使用虚拟示例运行推理(生成动作预测)
example = droid_policy.make_droid_example()
result = policy.infer(example)
# 删除策略对象以释放内存(GPU显存/JAX内存)
del policy
# 输出预测动作的形状(通常格式为 [时间步数, 动作维度])
print("Actions shape:", result["actions"].shape)运行信息:
E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:477] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
E0000 00:00:1775146564.044970 52155 cuda_dnn.cc:8310] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
E0000 00:00:1775146564.047291 52155 cuda_blas.cc:1418] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
Loading checkpoint from: /home/lgp/2026/openpi/checkpoints/pi05_droid
Actions shape: (15, 8)
4、DROID示例数据下载
数据介绍:https://droid-dataset.github.io/
创建一个droid_examples目录,存放droid_100示例数据
然后我们下载droid_100示例数据:
python
gsutil -m cp -r gs://gresearch/robotics/droid_100 ./droid_examples运行信息:
lgp@lgp-MS-7E07:~/2026/openpi$ gsutil -m cp -r gs://gresearch/robotics/droid_100 ./droid_examples
Google recommends using Gcloud storage CLI (https://docs.cloud.google.com/storage/docs/discover-object-storage-gcloud) instead of gsutil. Please refer to migration guide (https://docs.cloud.google.com/storage/docs/gsutil-transition-to-gcloud) for assistance.
Copying gs://gresearch/robotics/droid_100/1.0.0/dataset_info.json...
Copying gs://gresearch/robotics/droid_100/1.0.0/features.json...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00000-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00001-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00002-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00003-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00006-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00008-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00005-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00004-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00009-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00007-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00010-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00011-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00012-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00013-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00015-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00014-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00016-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00017-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00018-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00019-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00020-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00021-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00022-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00023-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00024-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00025-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00028-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00026-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00027-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00029-of-00031...
Copying gs://gresearch/robotics/droid_100/1.0.0/r2d2_faceblur-train.tfrecord-00030-of-00031...
\ 33/33 files 2.0 GiB/ 2.0 GiB 100% Done 63.5 MiB/s ETA 00:00:00
Operation completed over 33 objects/2.0 GiB.
下面好后数据目录:
5、模型推理------进阶(真实数据)
这里功能是加载预训练的机器人策略模型(OpenPI),并在两种数据模式(虚拟示例 + 真实DROID数据)上执行推理,同时保存可视化结果。
| 模块 | 功能说明 |
|---|---|
| 模型加载 | 加载 pi05_droid 配置的预训练 checkpoint |
| 虚拟示例推理 | 使用框架生成的 dummy 数据测试模型能否正常运行 |
| 真实数据推理 | 从本地 DROID 数据集加载真实机器人 episode 进行推理 |
| 结果可视化 | 保存输入图像(原始+调整后)和详细的推理输出信息 |
思路流程:
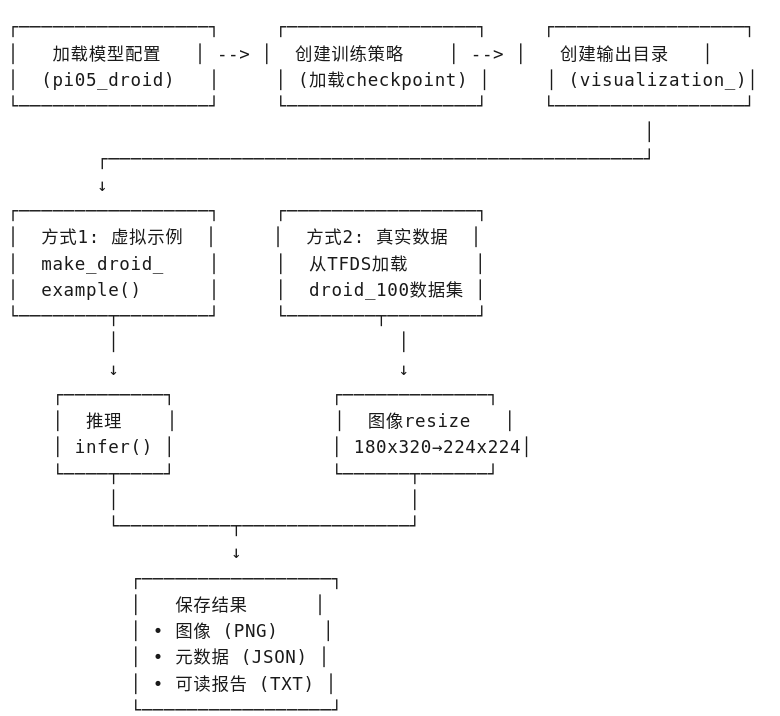
处理数据的维度:
| 数据项 | 处理方式 |
|---|---|
| 图像 | 原始尺寸 180×320 → 调整为模型输入 224×224 |
| 关节位置 | joint_position (7维) |
| 夹爪位置 | gripper_position (标量) |
| 语言指令 | 从 language_instruction 字段解码 |
| 输出动作 | 8维向量 [7关节 + 1夹爪],共15个时间步 |
运行代码:
python
import dataclasses
import jax
import numpy as np
from pathlib import Path
from PIL import Image
import tensorflow as tf
import json
from datetime import datetime
from openpi.models import model as _model
from openpi.policies import droid_policy
from openpi.policies import policy_config as _policy_config
from openpi.training import config as _config
# ========== 配置 ==========
config = _config.get_config("pi05_droid")
checkpoint_dir = Path("./checkpoints/pi05_droid")
assert checkpoint_dir.exists(), f"Checkpoint not found: {checkpoint_dir}"
print(f"Loading checkpoint from: {checkpoint_dir.absolute()}")
# 创建训练好的策略
policy = _policy_config.create_trained_policy(config, checkpoint_dir)
# ========== 创建输出目录 ==========
output_dir = Path("./visualization_output")
output_dir.mkdir(exist_ok=True)
images_dir = output_dir / "images"
images_dir.mkdir(exist_ok=True)
# 生成时间戳
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
# ========== 方式1:虚拟示例 ===========
print("\n=== 方式1:虚拟示例 ===")
dummy_example = droid_policy.make_droid_example()
result_dummy = policy.infer(dummy_example)
# 保存虚拟示例的图像
Image.fromarray(dummy_example['observation/exterior_image_1_left']).save(
images_dir / f"dummy_exterior_{timestamp}.png"
)
Image.fromarray(dummy_example['observation/wrist_image_left']).save(
images_dir / f"dummy_wrist_{timestamp}.png"
)
# 保存虚拟示例的信息
dummy_info = {
"type": "dummy_example",
"timestamp": timestamp,
"actions_shape": result_dummy["actions"].shape,
"actions_dtype": str(result_dummy["actions"].dtype),
"actions_first_5": result_dummy["actions"][:5].tolist(),
"exterior_image_shape": dummy_example['observation/exterior_image_1_left'].shape,
"wrist_image_shape": dummy_example['observation/wrist_image_left'].shape,
"joint_position": dummy_example['observation/joint_position'].tolist(),
"gripper_position": dummy_example['observation/gripper_position'].tolist(),
"prompt": dummy_example['prompt'],
}
with open(output_dir / f"dummy_info_{timestamp}.json", "w") as f:
json.dump(dummy_info, f, indent=2)
print(f"虚拟示例 - Actions shape: {result_dummy['actions'].shape}")
print(f"虚拟示例信息已保存到: {output_dir}/dummy_info_{timestamp}.json")
print(f"虚拟示例图像已保存到: {images_dir}/")
# ========== 方式2:真实DROID数据 ===========
print("\n=== 方式2:真实DROID数据 ===")
import tensorflow_datasets as tfds
droid_data_path = "./droid_examples"
builder_dir = Path(droid_data_path) / "droid_100" / "1.0.0"
# 加载数据集
builder = tfds.builder_from_directory(str(builder_dir))
ds = builder.as_dataset(split='all')
# 获取第一个episode
episodes = list(ds.take(1))
episode = episodes[0]
steps = list(episode['steps'])
# 获取第一个step
step = steps[0]
# 提取数据
exterior_img = step['observation']['exterior_image_1_left'].numpy()
wrist_img = step['observation']['wrist_image_left'].numpy()
# 调整图像大小到224x224
exterior_img_resized = np.array(Image.fromarray(exterior_img).resize((224, 224)))
wrist_img_resized = np.array(Image.fromarray(wrist_img).resize((224, 224)))
# 提取其他数据
joint_pos = step['observation']['joint_position'].numpy()
gripper_pos = step['observation']['gripper_position'].numpy()
instruction = step['language_instruction'].numpy().decode('utf-8')
# 创建example
real_example = {
"observation/exterior_image_1_left": exterior_img_resized,
"observation/wrist_image_left": wrist_img_resized,
"observation/joint_position": joint_pos.astype(np.float32),
"observation/gripper_position": gripper_pos.astype(np.float32),
"prompt": instruction,
}
# 运行推理
result_real = policy.infer(real_example)
# 保存原始图像(180x320)
Image.fromarray(exterior_img).save(
images_dir / f"real_exterior_original_{timestamp}.png"
)
Image.fromarray(wrist_img).save(
images_dir / f"real_wrist_original_{timestamp}.png"
)
# 保存调整后图像(224x224)
Image.fromarray(exterior_img_resized).save(
images_dir / f"real_exterior_resized_{timestamp}.png"
)
Image.fromarray(wrist_img_resized).save(
images_dir / f"real_wrist_resized_{timestamp}.png"
)
# 保存真实数据的信息
real_info = {
"type": "real_droid_example",
"timestamp": timestamp,
"dataset_name": builder.info.name,
"dataset_version": str(builder.info.version),
"total_episodes": builder.info.splits['all'].num_examples,
"current_episode": 0,
"total_steps_in_episode": len(steps),
"current_step": 0,
"actions_shape": result_real["actions"].shape,
"actions_dtype": str(result_real["actions"].dtype),
"actions_all": result_real["actions"].tolist(),
"original_image_shape": list(exterior_img.shape),
"resized_image_shape": list(exterior_img_resized.shape),
"joint_position": joint_pos.tolist(),
"gripper_position": gripper_pos.tolist(),
"prompt": instruction,
}
with open(output_dir / f"real_info_{timestamp}.json", "w") as f:
json.dump(real_info, f, indent=2)
# 同时保存一个可读的txt文件
txt_content = f"""
========================================
DROID真实数据推理结果
========================================
时间戳: {timestamp}
数据集: {builder.info.name} v{builder.info.version}
总样本数: {builder.info.splits['all'].num_examples}
当前Episode: 0 (共{len(steps)}个steps)
当前Step: 0
----------------------------------------
输入信息
----------------------------------------
原始图像尺寸: {exterior_img.shape}
调整后图像尺寸: {exterior_img_resized.shape}
关节位置: {joint_pos.tolist()}
夹爪位置: {gripper_pos.tolist()}
语言指令: "{instruction}"
----------------------------------------
输出动作
----------------------------------------
Actions Shape: {result_real["actions"].shape}
Actions Dtype: {result_real["actions"].dtype}
完整动作序列 (共{result_real["actions"].shape[0]}个动作):
说明: 每个动作是8维向量 [7个关节 + 1个夹爪]
"""
for i in range(result_real["actions"].shape[0]):
action = result_real["actions"][i]
joints = action[:7]
gripper = action[7]
txt_content += f"动作 {i:2d}: 关节=[{', '.join([f'{j:8.5f}' for j in joints])}], 夹爪={gripper:.5f}\n"
txt_content += f"""
----------------------------------------
保存文件
----------------------------------------
原始外部图像: real_exterior_original_{timestamp}.png ({exterior_img.shape})
原始腕部图像: real_wrist_original_{timestamp}.png ({wrist_img.shape})
调整后外部图像: real_exterior_resized_{timestamp}.png (224, 224, 3)
调整后腕部图像: real_wrist_resized_{timestamp}.png (224, 224, 3)
JSON信息: real_info_{timestamp}.json
========================================
"""
with open(output_dir / f"real_info_{timestamp}.txt", "w") as f:
f.write(txt_content)
print(f"\n真实数据信息已保存到:")
print(f" - JSON: {output_dir}/real_info_{timestamp}.json")
print(f" - TXT: {output_dir}/real_info_{timestamp}.txt")
print(f"\n真实数据图像已保存到: {images_dir}/")
print(f" - 原始尺寸 (180x320): real_exterior_original_{timestamp}.png, real_wrist_original_{timestamp}.png")
print(f" - 调整后尺寸 (224x224): real_exterior_resized_{timestamp}.png, real_wrist_resized_{timestamp}.png")
# 释放内存
del policy
print(f"\n✓ 所有结果已保存到: {output_dir.absolute()}/")
print(f" - 图像文件夹: {images_dir.absolute()}/")输出目录结构:
visualization_output/
├── images/
│ ├── dummy_exterior_{timestamp}.png # 虚拟示例外部视角
│ ├── dummy_wrist_{timestamp}.png # 虚拟示例腕部视角
│ ├── real_exterior_original_{timestamp}.png # 真实数据原始尺寸
│ ├── real_wrist_original_{timestamp}.png
│ ├── real_exterior_resized_{timestamp}.png # 真实数据调整后
│ └── real_wrist_resized_{timestamp}.png
├── dummy_info_{timestamp}.json # 虚拟示例元数据
├── real_info_{timestamp}.json # 真实数据元数据
└── real_info_{timestamp}.txt # 可读的动作序列报告
运行信息:
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
E0000 00:00:1775146899.467644 53171 cuda_dnn.cc:8310] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
E0000 00:00:1775146899.469954 53171 cuda_blas.cc:1418] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
Loading checkpoint from: /home/lgp/2026/openpi/checkpoints/pi05_droid
=== 方式1:虚拟示例 ===
虚拟示例 - Actions shape: (15, 8)
虚拟示例信息已保存到: visualization_output/dummy_info_20260403_002149.json
虚拟示例图像已保存到: visualization_output/images/
=== 方式2:真实DROID数据 ===
I0000 00:00:1775146920.356610 53171 gpu_device.cc:2022] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 1428 MB memory: -> device: 0, name: NVIDIA GeForce RTX 4070 Ti SUPER, pci bus id: 0000:01:00.0, compute capability: 8.9
真实数据信息已保存到:
JSON: visualization_output/real_info_20260403_002149.json
TXT: visualization_output/real_info_20260403_002149.txt
真实数据图像已保存到: visualization_output/images/
原始尺寸 (180x320): real_exterior_original_20260403_002149.png, real_wrist_original_20260403_002149.png
调整后尺寸 (224x224): real_exterior_resized_20260403_002149.png, real_wrist_resized_20260403_002149.png
✓ 所有结果已保存到: /home/lgp/2026/openpi/visualization_output/
- 图像文件夹: /home/lgp/2026/openpi/visualization_output/images/
看一下保存的图片:
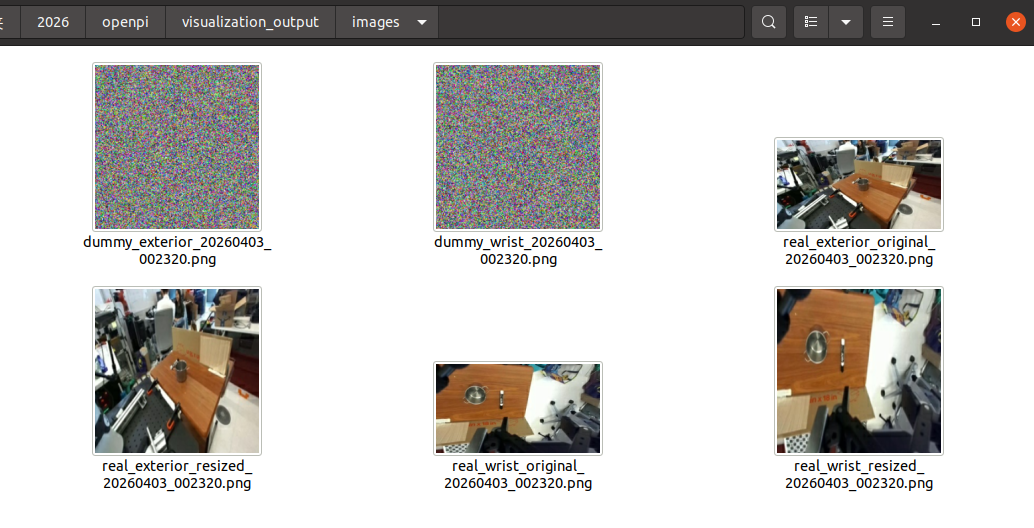
看一下real_info_20260403_002320.txt文件:
========================================
DROID真实数据推理结果
========================================
时间戳: 20260403_002320
数据集: r2d2_faceblur v1.0.0
总样本数: 100
当前Episode: 0 (共166个steps)
当前Step: 0
输入信息
原始图像尺寸: (180, 320, 3)
调整后图像尺寸: (224, 224, 3)
关节位置: 0.15790215134620667, -0.5977073907852173, -0.008947020396590233, -2.3909943103790283, 0.2606939375400543, 1.981839656829834, -0.08346986770629883
夹爪位置: 0.0
语言指令: "Put the marker in the pot"
输出动作
Actions Shape: (15, 8)
Actions Dtype: float64
完整动作序列 (共15个动作):
说明: 每个动作是8维向量 7个关节 + 1个夹爪
动作 0: 关节=-0.08155, 0.40714, 0.10694, 0.26895, 0.01408, 0.05039, 0.13597, 夹爪=0.01158
动作 1: 关节=-0.08323, 0.45226, 0.11254, 0.30192, 0.01623, 0.05179, 0.15427, 夹爪=0.01267
动作 2: 关节=-0.08228, 0.49628, 0.11671, 0.33716, 0.01276, 0.05131, 0.16763, 夹爪=0.01288
动作 3: 关节=-0.07642, 0.53242, 0.11993, 0.36973, 0.00674, 0.04856, 0.18521, 夹爪=0.01249
动作 4: 关节=-0.07413, 0.55684, 0.12037, 0.39758, 0.00134, 0.03617, 0.19904, 夹爪=0.01609
动作 5: 关节=-0.07270, 0.57619, 0.11928, 0.42014, -0.00526, 0.01403, 0.20281, 夹爪=0.01568
动作 6: 关节=-0.06476, 0.57428, 0.11467, 0.44271, -0.02360, 0.00090, 0.20300, 夹爪=0.01551
动作 7: 关节=-0.06027, 0.57023, 0.10646, 0.44668, -0.03227, -0.01800, 0.20377, 夹爪=0.01763
动作 8: 关节=-0.05676, 0.54565, 0.09740, 0.45021, -0.04065, -0.03304, 0.19663, 夹爪=0.01483
动作 9: 关节=-0.05695, 0.51878, 0.09090, 0.42629, -0.04678, -0.04827, 0.18961, 夹爪=0.01768
动作 10: 关节=-0.04734, 0.49214, 0.08056, 0.41056, -0.04698, -0.05808, 0.18070, 夹爪=0.01546
动作 11: 关节=-0.04544, 0.45429, 0.07805, 0.37726, -0.04018, -0.05751, 0.16421, 夹爪=0.01711
动作 12: 关节=-0.04162, 0.41011, 0.06779, 0.33338, -0.04858, -0.05420, 0.13991, 夹爪=0.01548
动作 13: 关节=-0.03275, 0.36016, 0.06674, 0.29094, -0.03779, -0.04125, 0.12957, 夹爪=0.01269
动作 14: 关节=-0.03289, 0.31541, 0.06642, 0.24203, -0.03581, -0.01586, 0.11779, 夹爪=0.01217
保存文件
原始外部图像: real_exterior_original_20260403_002320.png ((180, 320, 3))
原始腕部图像: real_wrist_original_20260403_002320.png ((180, 320, 3))
调整后外部图像: real_exterior_resized_20260403_002320.png (224, 224, 3)
调整后腕部图像: real_wrist_resized_20260403_002320.png (224, 224, 3)
JSON信息: real_info_20260403_002320.json
========================================
看一下real_info_20260403_002320.json:
{
"type": "real_droid_example",
"timestamp": "20260403_002320",
"dataset_name": "r2d2_faceblur",
"dataset_version": "1.0.0",
"total_episodes": 100,
"current_episode": 0,
"total_steps_in_episode": 166,
"current_step": 0,
"actions_shape": [
15,
8
],
"actions_dtype": "float64",
"actions_all": [
-0.08154634371984004, 0.4071407799335717, 0.10693605120307226, 0.26894644938743106, 0.01407702680611611, 0.0503900275505782, 0.13597406342220308, 0.011579890901863576 \], \[ -0.08323099790859217, 0.4522623475474118, 0.11253950938206925, 0.3019174320928454, 0.01623307605493074, 0.05179187836837773, 0.15427342353189, 0.012668025331288578 \], \[ -0.08227704425662752, 0.4962844592009782, 0.11670720679432167, 0.33715753523623937, 0.012758746997833303, 0.05131390730768448, 0.16762633343952893, 0.0128830658903718 \], \[ -0.0764195108186006, 0.5324210117179154, 0.11993307971966283, 0.36972994967591755, 0.006742186442911691, 0.04856379896712304, 0.18520654872417452, 0.012487995532482863 \], \[ -0.07412768480536336, 0.5568433147099613, 0.12037184368520992, 0.3975815102375747, 0.0013360591633617691, 0.03617196820998192, 0.19903552983093264, 0.016088144562721254 \], \[ -0.07270279986631867, 0.576187946092844, 0.11927597425502556, 0.4201438596001864, -0.005255378442287406, 0.014026859851539175, 0.20280522191071515, 0.01568222831824422 \], \[ -0.06475917766082284, 0.5742832098888159, 0.11466919272840037, 0.44270990225946905, -0.023600539275407728, 0.0008984528327584673, 0.2029997878137827, 0.015509498635411264 \], \[ -0.06027209232270714, 0.5702343095712662, 0.10646345817828196, 0.44667896508181093, -0.032272555922031376, -0.01799958053877948, 0.20377252297234538, 0.017627455955654382 \], \[ -0.05676330472624297, 0.5456450445170401, 0.09739705686855327, 0.4502055504446626, -0.04064893914335965, -0.03304482547461984, 0.1966259265318513, 0.01483079642468691 \], \[ -0.0569504465420842, 0.5187844016949533, 0.09089520772665749, 0.4262850938228965, -0.046781732302486834, -0.04826922179627413, 0.18961014043957003, 0.017684605434983968 \], \[ -0.047341791160255664, 0.49213562538635724, 0.08055872266745578, 0.4105610884296299, -0.04698091657611725, -0.05807523457580799, 0.18070460403394706, 0.015458070063292981 \], \[ -0.04544006434029335, 0.4542919537496567, 0.07805430512070666, 0.3772551442344786, -0.04017776132047168, -0.05750677119743819, 0.1642111757459045, 0.017109862834990025 \], \[ -0.041615532281249756, 0.41011272338962546, 0.06778617183578028, 0.33337939533346905, -0.04858052247852085, -0.0541958835244476, 0.1399113924853802, 0.015477854867398739 \], \[ -0.03274896679967637, 0.3601619117156266, 0.06674291352927697, 0.2909389025554062, -0.03778739577996726, -0.04125325879406927, 0.12956694224941734, 0.012686350112199783 \], \[ -0.03289208953538536, 0.3154100792917013, 0.06641892291772378, 0.24203298618018632, -0.035814912289619416, -0.015863922836303668, 0.11778866079378125, 0.012167684321433307
],
"original_image_shape": [
180,
320,
3
],
"resized_image_shape": [
224,
224,
3
],
"joint_position": [
0.15790215134620667,
-0.5977073907852173,
-0.008947020396590233,
-2.3909943103790283,
0.2606939375400543,
1.981839656829834,
-0.08346986770629883
],
"gripper_position": [
0.0
],
"prompt": "Put the marker in the pot"
}
6、模型推理------进阶(真实数据,连续推理)
这里功能是加载预训练的机器人策略模型(OpenPI),对真实DROID数据集的一个完整Episode进行逐帧推理,并结构化保存所有可视化结果。
| 模块 | 说明 |
|---|---|
| 模型加载 | 加载 pi05_droid checkpoint,创建可推理策略 |
| 数据读取 | 通过 TFDS 从本地加载 DROID 数据集 Episode 0 |
| 逐帧推理 | 遍历 Episode 的所有时间步(steps),每帧执行一次模型推理 |
| 结果保存 | 每帧保存 4 张图像 + JSON 元数据 + TXT 可读报告 |
思路流程:
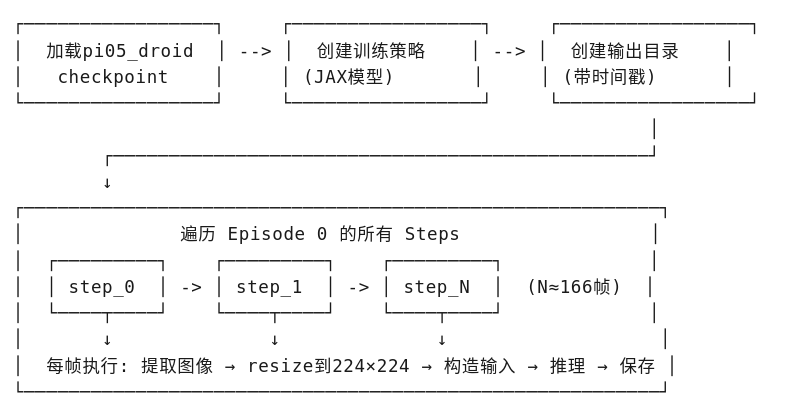
输入与输出数据:
| 数据项 | 来源 | 处理方式 |
|---|---|---|
| 外部图像 | exterior_image_1_left |
180×320 → 224×224 |
| 腕部图像 | wrist_image_left |
180×320 → 224×224 |
| 关节位置 | joint_position |
7维数组,直接输入 |
| 夹爪位置 | gripper_position |
标量,直接输入 |
| 语言指令 | language_instruction |
解码为字符串 |
| 输出动作 | 模型预测 | 15×8 数组(15个未来动作,每动作7关节+1夹爪) |
运行代码:
python
import dataclasses
import jax
import numpy as np
from pathlib import Path
from PIL import Image
import tensorflow as tf
import json
from datetime import datetime
from openpi.models import model as _model
from openpi.policies import droid_policy
from openpi.policies import policy_config as _policy_config
from openpi.training import config as _config
# ========== 配置 ==========
# 获取pi05_droid模型配置
config = _config.get_config("pi05_droid")
# 指定本地checkpoint路径
checkpoint_dir = Path("./checkpoints/pi05_droid")
# 验证checkpoint路径是否存在
assert checkpoint_dir.exists(), f"Checkpoint not found: {checkpoint_dir}"
print(f"Loading checkpoint from: {checkpoint_dir.absolute()}")
# 创建训练好的策略
policy = _policy_config.create_trained_policy(config, checkpoint_dir)
# ========== 创建输出目录 ==========
# 创建可视化输出根目录
output_dir = Path("./visualization_output_sequence")
output_dir.mkdir(exist_ok=True)
# 生成时间戳用于文件夹命名
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
# ========== 真实DROID数据 - 遍历所有steps ===========
print("\n=== 真实DROID数据 - 遍历所有steps ===")
import tensorflow_datasets as tfds
# DROID数据集本地路径
droid_data_path = "./droid_examples"
builder_dir = Path(droid_data_path) / "droid_100" / "1.0.0"
# 从本地目录加载TFDS数据集
builder = tfds.builder_from_directory(str(builder_dir))
ds = builder.as_dataset(split='all')
# 获取第一个Episode (Episode 0)
episodes = list(ds.take(1))
episode = episodes[0]
steps = list(episode['steps'])
total_steps = len(steps)
print(f"Episode 0 共有 {total_steps} 个steps")
print(f"开始遍历所有steps并保存结果...\n")
# 创建episode目录
episode_dir = output_dir / f"episode_0_{timestamp}"
episode_dir.mkdir(exist_ok=True)
# 保存episode元信息
episode_summary = {
"type": "droid_episode",
"timestamp": timestamp,
"dataset_name": builder.info.name,
"dataset_version": str(builder.info.version),
"total_episodes": builder.info.splits['all'].num_examples,
"current_episode": 0,
"total_steps": total_steps,
}
with open(episode_dir / "episode_summary.json", "w") as f:
json.dump(episode_summary, f, indent=2)
# 遍历所有steps
for step_idx in range(total_steps):
print(f"处理 Step {step_idx}/{total_steps-1} ...", end=" ")
# 创建当前step的独立目录
step_dir = episode_dir / f"step_{step_idx:04d}"
step_dir.mkdir(exist_ok=True)
# 获取当前step数据
step = steps[step_idx]
# 提取原始图像数据
exterior_img = step['observation']['exterior_image_1_left'].numpy()
wrist_img = step['observation']['wrist_image_left'].numpy()
# 调整图像大小到模型输入尺寸224x224
exterior_img_resized = np.array(Image.fromarray(exterior_img).resize((224, 224)))
wrist_img_resized = np.array(Image.fromarray(wrist_img).resize((224, 224)))
# 提取机器人状态数据
joint_pos = step['observation']['joint_position'].numpy()
gripper_pos = step['observation']['gripper_position'].numpy()
# 解码语言指令
instruction = step['language_instruction'].numpy().decode('utf-8')
# 构造模型输入示例
real_example = {
"observation/exterior_image_1_left": exterior_img_resized,
"observation/wrist_image_left": wrist_img_resized,
"observation/joint_position": joint_pos.astype(np.float32),
"observation/gripper_position": gripper_pos.astype(np.float32),
"prompt": instruction,
}
# 执行推理获取动作预测
result_real = policy.infer(real_example)
# 保存原始尺寸图像(180x320)
Image.fromarray(exterior_img).save(step_dir / "exterior_original.png")
Image.fromarray(wrist_img).save(step_dir / "wrist_original.png")
# 保存调整后尺寸图像(224x224)
Image.fromarray(exterior_img_resized).save(step_dir / "exterior_resized.png")
Image.fromarray(wrist_img_resized).save(step_dir / "wrist_resized.png")
# 保存JSON格式的结构化信息
step_info = {
"type": "droid_step",
"timestamp": timestamp,
"episode": 0,
"step": step_idx,
"total_steps_in_episode": total_steps,
"dataset_name": builder.info.name,
"dataset_version": str(builder.info.version),
"actions_shape": result_real["actions"].shape,
"actions_dtype": str(result_real["actions"].dtype),
"actions": result_real["actions"].tolist(),
"original_image_shape": list(exterior_img.shape),
"resized_image_shape": list(exterior_img_resized.shape),
"joint_position": joint_pos.tolist(),
"gripper_position": gripper_pos.tolist(),
"prompt": instruction,
}
with open(step_dir / "info.json", "w") as f:
json.dump(step_info, f, indent=2)
# 保存人类可读的TXT报告
txt_content = f"""
========================================
DROID Step {step_idx}/{total_steps-1} 推理结果
========================================
时间戳: {timestamp}
数据集: {builder.info.name} v{builder.info.version}
Episode: 0 / {builder.info.splits['all'].num_examples}
Step: {step_idx} / {total_steps-1}
----------------------------------------
输入信息
----------------------------------------
原始图像尺寸: {exterior_img.shape}
调整后图像尺寸: {exterior_img_resized.shape}
关节位置: {joint_pos.tolist()}
夹爪位置: {gripper_pos.tolist()}
语言指令: "{instruction}"
----------------------------------------
输出动作
----------------------------------------
Actions Shape: {result_real["actions"].shape}
Actions Dtype: {result_real["actions"].dtype}
完整动作序列 (共{result_real["actions"].shape[0]}个动作):
说明: 每个动作是8维向量 [7个关节 + 1个夹爪]
"""
# 逐帧写入动作详情
for i in range(result_real["actions"].shape[0]):
action = result_real["actions"][i]
joints = action[:7]
gripper = action[7]
txt_content += f"动作 {i:2d}: 关节=[{', '.join([f'{j:8.5f}' for j in joints])}], 夹爪={gripper:.5f}\n"
txt_content += f"""
----------------------------------------
保存文件
----------------------------------------
exterior_original.png - 外部相机原始图像 ({exterior_img.shape})
wrist_original.png - 腕部相机原始图像 ({wrist_img.shape})
exterior_resized.png - 外部相机调整后图像 (224, 224, 3)
wrist_resized.png - 腕部相机调整后图像 (224, 224, 3)
info.json - 完整信息(JSON格式)
info.txt - 本文件
========================================
"""
with open(step_dir / "info.txt", "w") as f:
f.write(txt_content)
print(f"✓ 已保存到: {step_dir}/")
# 释放策略对象内存
del policy
print(f"\n========================================")
print(f"✓ 全部完成!")
print(f"========================================")
print(f"输出目录: {output_dir.absolute()}/")
print(f"\n文件结构:")
print(f" {output_dir}/")
print(f" └── episode_0_{timestamp}/")
print(f" ├── episode_summary.json")
print(f" ├── step_0000/")
print(f" │ ├── exterior_original.png")
print(f" │ ├── wrist_original.png")
print(f" │ ├── exterior_resized.png")
print(f" │ ├── wrist_resized.png")
print(f" │ ├── info.json")
print(f" │ └── info.txt")
print(f" ├── step_0001/")
print(f" │ └── ...")
print(f" └── ... (共{total_steps}个steps)")运行信息:
输出目录:
保存的信息:
输出内容:
| 文件 | 说明 |
|---|---|
exterior_original.png |
外部相机原始图像(180×320) |
wrist_original.png |
腕部相机原始图像(180×320) |
exterior_resized.png |
外部相机调整后(224×224,模型输入) |
wrist_resized.png |
腕部相机调整后(224×224,模型输入) |
info.json |
结构化数据(动作数组、关节位置、指令等) |
info.txt |
人类可读报告(含15个未来动作的详细数值) |
info.txt的信息:
========================================
DROID Step 83/165 推理结果
========================================
时间戳: 20260403_003011
数据集: r2d2_faceblur v1.0.0
Episode: 0 / 100
Step: 83 / 165
输入信息
原始图像尺寸: (180, 320, 3)
调整后图像尺寸: (224, 224, 3)
关节位置: 0.25488361716270447, 0.5500816106796265, -0.027102891355752945, -1.8354902267456055, -0.11073070764541626, 2.426971197128296, 0.381460577249527
夹爪位置: 0.8061674237251282
语言指令: "Put the marker in the pot"
输出动作
Actions Shape: (15, 8)
Actions Dtype: float64
完整动作序列 (共15个动作):
说明: 每个动作是8维向量 7个关节 + 1个夹爪
动作 0: 关节= 0.08289, -0.42710, -0.15341, -0.59056, -0.37139, 0.51136, 0.12834, 夹爪=0.92603
动作 1: 关节= 0.09103, -0.42177, -0.16479, -0.62005, -0.40236, 0.53954, 0.14552, 夹爪=0.92743
动作 2: 关节= 0.10111, -0.41300, -0.18139, -0.61333, -0.43276, 0.55179, 0.17491, 夹爪=0.93010
动作 3: 关节= 0.10687, -0.39263, -0.21084, -0.59955, -0.46382, 0.57584, 0.20874, 夹爪=0.93285
动作 4: 关节= 0.13734, -0.37710, -0.24512, -0.58587, -0.50373, 0.57991, 0.25223, 夹爪=0.93016
动作 5: 关节= 0.16136, -0.34897, -0.27556, -0.55771, -0.54405, 0.56529, 0.29577, 夹爪=0.93242
动作 6: 关节= 0.19797, -0.32064, -0.32201, -0.51746, -0.57308, 0.52830, 0.35085, 夹爪=0.92891
动作 7: 关节= 0.22830, -0.29898, -0.35062, -0.47077, -0.60272, 0.47910, 0.38348, 夹爪=0.92936
动作 8: 关节= 0.23826, -0.27714, -0.36575, -0.43120, -0.60011, 0.40866, 0.40944, 夹爪=0.93204
动作 9: 关节= 0.24720, -0.26355, -0.36627, -0.37909, -0.61040, 0.34990, 0.43303, 夹爪=0.93079
动作 10: 关节= 0.23378, -0.25260, -0.35108, -0.35318, -0.59584, 0.30822, 0.43031, 夹爪=0.93105
动作 11: 关节= 0.21736, -0.24919, -0.32812, -0.32396, -0.57746, 0.26323, 0.43888, 夹爪=0.93284
动作 12: 关节= 0.20957, -0.25011, -0.30294, -0.30799, -0.56352, 0.24089, 0.43479, 夹爪=0.93105
动作 13: 关节= 0.18627, -0.25308, -0.27335, -0.29918, -0.53940, 0.22156, 0.42672, 夹爪=0.93244
动作 14: 关节= 0.17291, -0.24034, -0.24758, -0.29516, -0.50966, 0.19955, 0.42131, 夹爪=0.93299
保存文件
exterior_original.png - 外部相机原始图像 ((180, 320, 3))
wrist_original.png - 腕部相机原始图像 ((180, 320, 3))
exterior_resized.png - 外部相机调整后图像 (224, 224, 3)
wrist_resized.png - 腕部相机调整后图像 (224, 224, 3)
info.json - 完整信息(JSON格式)
info.txt - 本文件
========================================
7、模型推理------输入自定义真实数据
在网上随机找一张图像,然后保存,作为输入:
使用 OpenPI π0.5 模型的单图像推理,用于机器人VLA任务
| 功能模块 | 说明 |
|---|---|
| 模型加载 | 加载 π0.5 DROID 预训练检查点 |
| 单图推理 | 仅需1张RGB图像 + 语言指令即可预测机器人动作 |
| 数据预处理 | 自动调整图像尺寸为 224×224,填充缺失的关节状态 |
| 结果保存 | 输出JSON数据 + 可读文本报告 + 输入图像备份 |
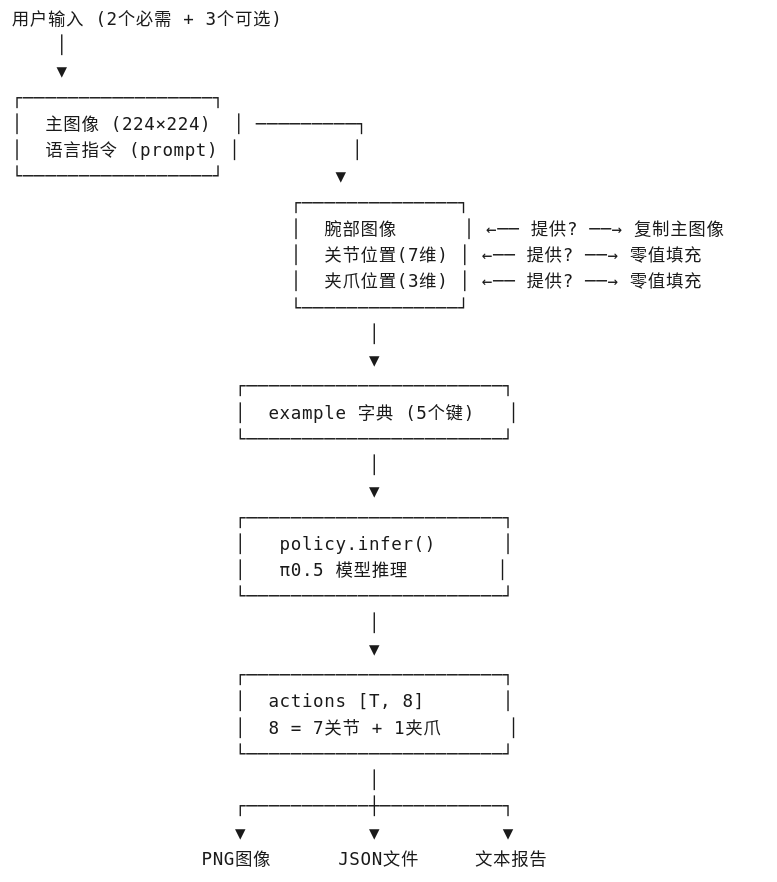
输入(5个):
-
image_path: 主视角图像(必需) -
prompt: 语言指令(必需,如"pick up the cup") -
wrist_image_path: 腕部视角(可选,默认复制主图) -
joint_position: 7维关节角度(可选,默认零值) -
gripper_position: 3维夹爪位置(可选,默认零值)
输出:
-
actions: 形状为[time_steps, 8]的动作序列- 每步8维:7个关节角度 + 1个夹爪开合度
思路流程:
运行代码:
python
import dataclasses
import jax
import numpy as np
from pathlib import Path
from PIL import Image
import json
from datetime import datetime
from openpi.models import model as _model
from openpi.policies import droid_policy
from openpi.policies import policy_config as _policy_config
from openpi.training import config as _config
def infer_single_image(
image_path: str,
prompt: str,
wrist_image_path: str = None,
joint_position: np.ndarray = None,
gripper_position: np.ndarray = None,
checkpoint_dir: str = "./checkpoints/pi05_droid",
output_dir: str = "./inference_output"
):
"""
使用单张图片进行模型推理
Args:
image_path: 主视角图像路径 (外部相机视角)
prompt: 语言指令,如 "pick up the red cup"
wrist_image_path: 腕部视角图像路径(可选,不提供则使用主图像)
joint_position: 7维关节位置(可选,默认零值)
gripper_position: 3维夹爪位置(可选,默认零值)
checkpoint_dir: 模型检查点路径
output_dir: 输出目录
"""
# ========== 配置与加载模型 ==========
config = _config.get_config("pi05_droid")
checkpoint_dir = Path(checkpoint_dir)
assert checkpoint_dir.exists(), f"检查点不存在: {checkpoint_dir}"
print(f"加载模型: {checkpoint_dir.absolute()}")
policy = _policy_config.create_trained_policy(config, checkpoint_dir)
# ========== 准备输入数据 ==========
# 1. 加载并预处理主图像 (外部视角)
exterior_img = Image.open(image_path).convert('RGB')
exterior_img = exterior_img.resize((224, 224))
exterior_array = np.array(exterior_img).astype(np.uint8)
# 2. 处理腕部图像(如未提供,复制主图像)
if wrist_image_path and Path(wrist_image_path).exists():
wrist_img = Image.open(wrist_image_path).convert('RGB')
wrist_img = wrist_img.resize((224, 224))
wrist_array = np.array(wrist_img).astype(np.uint8)
else:
# 使用主图像作为腕部图像(或可用黑色图像)
wrist_array = exterior_array.copy()
print("警告: 未提供腕部图像,使用主图像替代")
# 3. 设置默认值(如果未提供关节状态)
if joint_position is None:
joint_position = np.zeros(7, dtype=np.float32)
print("警告: 使用默认关节位置 (全零)")
else:
joint_position = np.array(joint_position, dtype=np.float32)
if gripper_position is None:
gripper_position = np.zeros(3, dtype=np.float32)
print("警告: 使用默认夹爪位置 (全零)")
else:
gripper_position = np.array(gripper_position, dtype=np.float32)
# ========== 构建输入示例 ==========
example = {
"observation/exterior_image_1_left": exterior_array,
"observation/wrist_image_left": wrist_array,
"observation/joint_position": joint_position,
"observation/gripper_position": gripper_position,
"prompt": prompt,
}
print(f"\n输入信息:")
print(f" 图像尺寸: {exterior_array.shape}")
print(f" 语言指令: '{prompt}'")
print(f" 关节位置: {joint_position}")
print(f" 夹爪位置: {gripper_position}")
# ========== 执行推理 ==========
print("\n执行推理...")
result = policy.infer(example)
actions = result["actions"]
print(f"推理完成!")
print(f" 输出动作形状: {actions.shape}")
print(f" 动作序列长度: {actions.shape[0]} 步")
print(f" 每步动作维度: {actions.shape[1]} (7关节 + 1夹爪)")
# ========== 保存结果 ==========
output_path = Path(output_dir)
output_path.mkdir(exist_ok=True)
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
# 保存输入图像
exterior_img.save(output_path / f"input_exterior_{timestamp}.png")
# 保存详细结果
result_data = {
"timestamp": timestamp,
"input": {
"image_path": str(image_path),
"prompt": prompt,
"wrist_image_provided": wrist_image_path is not None,
"joint_position": joint_position.tolist(),
"gripper_position": gripper_position.tolist(),
},
"output": {
"actions_shape": list(actions.shape),
"actions": actions.tolist(), # [time_steps, 8]
}
}
with open(output_path / f"result_{timestamp}.json", "w") as f:
json.dump(result_data, f, indent=2)
# 保存可读文本报告
report = f"""
========================================
OpenPI π0.5 推理结果
========================================
时间: {timestamp}
图像: {image_path}
指令: "{prompt}"
输入状态:
关节位置: [{', '.join([f'{x:.3f}' for x in joint_position])}]
夹爪位置: [{', '.join([f'{x:.3f}' for x in gripper_position])}]
输出动作序列 (共{actions.shape[0]}步):
格式: [关节1, 关节2, ..., 关节7, 夹爪]
"""
for i, action in enumerate(actions):
joints = action[:7]
gripper = action[7]
report += f"Step {i:2d}: [{', '.join([f'{x:7.4f}' for x in joints])}, {gripper:7.4f}]\n"
report += f"""
========================================
结果已保存:
- JSON: result_{timestamp}.json
- 图像: input_exterior_{timestamp}.png
========================================
"""
with open(output_path / f"report_{timestamp}.txt", "w") as f:
f.write(report)
print(f"\n结果已保存到: {output_path.absolute()}")
# 释放资源
del policy
return actions, result_data
# ========== 使用示例 ==========
if __name__ == "__main__":
# 示例1: 最简单用法(仅需图片路径和指令)
actions, info = infer_single_image(
image_path="./data_test/demo1.png", # ← 替换为你的图片路径
prompt="Pick up the water bottle on the table", # ← 替换为你的指令
)
# 示例2: 完整用法(提供所有信息)
# actions, info = infer_single_image(
# image_path="./test_scene.jpg",
# prompt="move the bottle to the left",
# wrist_image_path="./wrist_view.jpg", # 可选
# joint_position=[0.1, -0.5, 0.3, 0.0, 0.2, -0.1, 0.0], # 7维,可选
# gripper_position=[0.05, 0.02, 0.1], # 3维,可选
# )输入图片:

运行信息:
加载模型: /home/lgp/2026/openpi/checkpoints/pi05_droid
警告: 未提供腕部图像,使用主图像替代
警告: 使用默认关节位置 (全零)
警告: 使用默认夹爪位置 (全零)
输入信息:
图像尺寸: (224, 224, 3)
语言指令: 'Pick up the water bottle on the table'
关节位置: 0. 0. 0. 0. 0. 0. 0.
夹爪位置: 0. 0. 0.
执行推理...
推理完成!
输出动作形状: (15, 8)
动作序列长度: 15 步
每步动作维度: 8 (7关节 + 1夹爪)
结果已保存到: /home/lgp/2026/openpi/inference_output
保存的report_20260403_005932.txt:
图像: ./data_test/demo1.png
指令: "Pick up the water bottle on the table"
输入状态:
关节位置: 0.000, 0.000, 0.000, 0.000, 0.000, 0.000, 0.000
夹爪位置: 0.000, 0.000, 0.000
输出动作序列 (共15步):
格式: 关节1, 关节2, ..., 关节7, 夹爪
Step 0: -0.1401, 0.1888, -0.1612, 0.3800, -0.0551, -0.3900, -0.3138, 0.6063
Step 1: -0.1431, 0.1956, -0.1646, 0.4225, -0.0486, -0.3730, -0.3359, 0.6531
Step 2: -0.1470, 0.1930, -0.1690, 0.3938, -0.0678, -0.3493, -0.3201, 0.7195
Step 3: -0.1422, 0.2130, -0.1687, 0.4174, -0.0657, -0.3270, -0.3374, 0.7994
Step 4: -0.1380, 0.2151, -0.1638, 0.4011, -0.0558, -0.2951, -0.3458, 0.8760
Step 5: -0.1205, 0.2032, -0.1448, 0.3595, -0.0667, -0.2446, -0.3041, 0.9020
Step 6: -0.1024, 0.1657, -0.1210, 0.2574, -0.0603, -0.1726, -0.2524, 0.8922
Step 7: -0.0813, 0.1435, -0.0943, 0.1926, -0.0436, -0.1267, -0.1916, 0.9046
Step 8: -0.0547, 0.0941, -0.0789, 0.1084, -0.0387, -0.0730, -0.1069, 0.8827
Step 9: -0.0417, 0.0798, -0.0622, 0.0773, -0.0242, -0.0570, -0.0702, 0.8874
Step 10: -0.0295, 0.0507, -0.0509, 0.0552, -0.0198, -0.0536, -0.0305, 0.8953
Step 11: -0.0248, 0.0477, -0.0399, 0.0310, -0.0161, -0.0492, 0.0097, 0.8980
Step 12: -0.0159, 0.0337, -0.0291, 0.0137, -0.0115, -0.0566, 0.0184, 0.9020
Step 13: -0.0023, 0.0106, -0.0242, 0.0057, -0.0197, -0.0677, 0.0329, 0.9142
Step 14: -0.0013, 0.0103, -0.0250, -0.0091, -0.0244, -0.0732, 0.0270, 0.9314
========================================
结果已保存:
JSON: result_20260403_005932.json
图像: input_exterior_20260403_005932.png
========================================
输入图像:

保存的report_20260403_005932.txt:
图像: ./data_test/demo2.png
指令: "Pick up the wooden cube"
输入状态:
关节位置: 0.000, 0.000, 0.000, 0.000, 0.000, 0.000, 0.000
夹爪位置: 0.000, 0.000, 0.000
输出动作序列 (共15步):
格式: 关节1, 关节2, ..., 关节7, 夹爪
Step 0: -0.1383, 0.0644, -0.1574, 0.1863, 0.0587, -0.1821, -0.1998, 0.6047
Step 1: -0.1501, 0.0599, -0.1639, 0.2094, 0.0791, -0.1637, -0.2152, 0.6473
Step 2: -0.1695, 0.0691, -0.1887, 0.2106, 0.0755, -0.1583, -0.2054, 0.7177
Step 3: -0.1753, 0.0804, -0.1954, 0.2090, 0.0891, -0.1363, -0.2195, 0.7990
Step 4: -0.1854, 0.0831, -0.1993, 0.1922, 0.0996, -0.1198, -0.2233, 0.8790
Step 5: -0.1789, 0.0760, -0.1869, 0.1565, 0.0761, -0.0865, -0.1938, 0.9168
Step 6: -0.1692, 0.0686, -0.1695, 0.1091, 0.0641, -0.0449, -0.1791, 0.9107
Step 7: -0.1463, 0.0662, -0.1380, 0.0641, 0.0651, -0.0014, -0.1401, 0.9258
Step 8: -0.1195, 0.0504, -0.1185, 0.0303, 0.0527, 0.0379, -0.0852, 0.9027
Step 9: -0.0925, 0.0521, -0.0883, 0.0151, 0.0554, 0.0577, -0.0496, 0.8938
Step 10: -0.0641, 0.0345, -0.0620, 0.0160, 0.0485, 0.0614, -0.0113, 0.8524
Step 11: -0.0442, 0.0300, -0.0370, 0.0181, 0.0339, 0.0459, 0.0206, 0.8186
Step 12: -0.0239, 0.0176, -0.0204, 0.0053, 0.0116, 0.0163, 0.0038, 0.8404
Step 13: -0.0072, -0.0012, -0.0097, 0.0066, -0.0014, -0.0058, -0.0014, 0.8538
Step 14: -0.0078, -0.0019, -0.0069, 0.0006, -0.0108, -0.0156, -0.0166, 0.9287
========================================
结果已保存:
JSON: result_20260403_011902.json
图像: input_exterior_20260403_011902.png
========================================
上面这些代码,如果需要替换模型,比如:pi0_fast_droid,
只需修改:模型配置 和 模型路径
python
# ========== 配置 ==========
config = _config.get_config("pi0_fast_droid")
checkpoint_dir = Path("./checkpoints/pi0_fast_droid")代码是通用适配π0.5、π0-FAST、π0系列的模型~
分享完成~