Leetcode哈希-day1
记录自己刷力扣备战秋招的刷题笔记❤️
------wosz
今天就是熟悉一下C++然后做一下哈希板块的题目
哈希
哈希我的理解就是通过键去判断值的一种数据结构,比如 key-value对,其中key就是我们存入到哈希表中的下标,然后value就是原本的值,我们可以通过value去定位到原本该值在数组中存在的位置。
- 先遍历原数组将数据放入哈希表中,其中可以存原本的下标和位置等信息
- 存入的过程中需要一个哈希函数,即将我们的value值映射到key去的一个函数,目的就是确定该值应该放到哈希表中什么位置
- 之后就可以使用哈希函数去映射哈希表中下标,看有没有该值进行快速查找
其中哈希函数 主要是利用的取余的形式进行的
cpp
int hash(int value,int size)
{
return (value%size+size)%size
}根据这个就可以获得到该值在哈希表中对应的下标了。
哈希冲突
哈希冲突的意思就是当多个value算出来相同的下标时,我们数组位置发送冲突的情况,解决方法主要有两种
- 采用扩展链表的形式
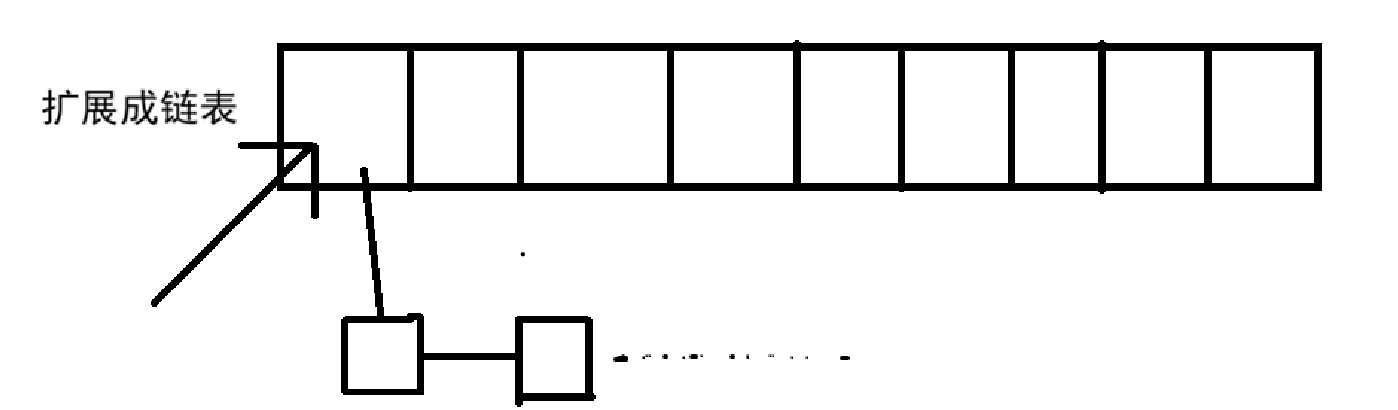
就直接将冲突的点添加入链表即可。
- 直接往后拓展
这种适合在C++、Python等这种已经定义了那个类型的情况下便于拓展的情况
C++中使用哈希
在 C++ 里,我们一般使用标准库中的:
unordered_map<K, V>:存键值对(key -> value)map<K, V>:存键值对(key -> value),会进行排序根据keyunordered_set<T>:只存值(用于快速判断某个值是否出现过)set<T>:只存值(用于快速判断某个值是否出现过)
什么时候选 map / set,取决于目的:如果只需要判断元素是否存在,用 set(或 unordered_set);如果还需要把元素映射到额外信息(如下标、出现次数),用 map(或 unordered_map)。另外,若需要有序遍历就选 map / set,不需要顺序且更追求速度就选 unordered_map / unordered_set。
两数之和
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。你可以假设每种输入只会对应一个答案,并且你不能使用两次相同的元素。
自己的题解:
cpp
#include <unordered_map>
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int,int>hash;
for(auto i=0;i<nums.size();i++) //入hash
{
hash[nums[i]]=i;
}
for(int i=0;i<nums.size();i++) //er:遍历不应该使用hash太小了可能被覆盖
{
if(hash.find(target-nums[i])!=hash.end()) //找到
{
if(i==hash[target-nums[i]]) //er:要排除自己
continue;
vector<int> temp(2);
temp[0]=i;
temp[1]=hash[target-nums[i]];
return temp;
}
}
return {};
}
};本人思路:就是将数组先遍历放入键值对进行存储,存储值(key)和下标(value),然后用目标数减去数组中的数即可获取到差的一个数再去hash键值对中寻找即可。
- 要排除自己和自己组合的情况
- 遍历的时候要排除因为键值对进行覆盖而导致变小的情况,所有应该使用原数组进行遍历
有个疑问就是出现多个数重复导致覆盖或者多个下标都满足的情况?
- 力扣是保证唯一解的,所有可以不用担心
官方题解:
cpp
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int, int> hashtable;
for (int i = 0; i < nums.size(); ++i) {
auto it = hashtable.find(target - nums[i]);
if (it != hashtable.end()) {
return {it->second, i};
}
hashtable[nums[i]] = i;
}
return {};
}
};官方的题解的思路和我的思路不一样,我是先存再找 ,官方是边找边存(就可以避免掉自己和自己组合以及多个值相同进行覆盖的问题)
字母异位词分组
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
输入: strs = "eat", "tea", "tan", "ate", "nat", "bat"
输出: \["bat","nat","tan","ate","eat","tea"]
自己的题解:
cpp
#include <unordered_map>
#include <algorithm>
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
vector<vector<string>> result;
unordered_map<string,int>hash; //存原下标(下标好像没用)
int index=0;
unordered_map<string,int>tabel; //用于存排序后的下标
for(int i=0;i<strs.size();i++)
{
string temp = strs[i]; //先拷贝,再排序
sort(temp.begin(), temp.end()); //er:无返回值
if(hash.find(temp)!=hash.end()) //找到了
{
result[tabel[temp]].push_back(strs[i]); //放入结果
}else //新字符
{
tabel[temp] = index; // 记录新分组下标
result.push_back({}); // er:先创建一个空的 vector<string>
result[tabel[temp]].push_back(strs[i]); // 再放当前字符串
hash[temp] = i;
index++;
}
}
return result;
}
};本人思路:就是先拷贝字符串进行排序,然后我参考了一下两数之和官方的解法边查边存 ,首先开一个哈希表用于存我们当前已经遍历过并且进行排序后的结果,其实这里我用的是map键值对,但是对于原始组的下标其实没用使用,因为我们是边查边存只需要判断有无即可,然后引入一个新的桶键值对来存我们的排序后字符存储在result中的一个下标便于存时方便。
- 错误的地点1:在排序的时候误认为排序sort返回值的
- 错误的地点2:只是声明了二维动态数组,没用去创建空空间
ai优化简化之后的题解
cpp
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
unordered_map<string, vector<string>> mp;
for (auto &s : strs) {
string key = s; //拷贝
sort(key.begin(), key.end()); //排序
mp[key].push_back(s); //入hash表,值是字符串数组
}
vector<vector<string>> result;
result.reserve(mp.size()); //开容量保证有这个多空间
for (auto &kv : mp) {
result.push_back(move(kv.second)); //直接将一整组 vector<string> 放进 result
}
return result;
}
};这个优化之后的内容很巧妙,主要是采用的哈希表键值对的方法直接采用的是 unordered_map<string, vector<string>> mp 类型,可以直接通过排序之后将原字符串直接放入值中去,然后返回的时候也很巧妙,直接采用了整组拷贝的方法不是像原来我自己那个一样一个元素移动。
官方题解:
cpp
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
// 自定义对 array<int, 26> 类型的哈希函数
auto arrayHash = [fn = hash<int>{}] (const array<int, 26>& arr) -> size_t {
return accumulate(arr.begin(), arr.end(), 0u, [&](size_t acc, int num) {
return (acc << 1) ^ fn(num);
});
};
unordered_map<array<int, 26>, vector<string>, decltype(arrayHash)> mp(0, arrayHash);
for (string& str: strs) {
array<int, 26> counts{};
int length = str.length();
for (int i = 0; i < length; ++i) {
counts[str[i] - 'a'] ++;
}
mp[counts].emplace_back(str);
}
vector<vector<string>> ans;
for (auto it = mp.begin(); it != mp.end(); ++it) {
ans.emplace_back(it->second);
}
return ans;
}
};官方的题解思路是通过对字符进行记录频次,通过字符频次确定一样的内容。(但是我感觉语法好复制,主要是对于像我这种C转C++的来说语法太复杂了🤣,算了就掌握自己的排序方法好了)。
最长连续序列
给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
**输入:**nums = 100,4,200,1,3,2
**输出:**4
解释:最长数字连续序列是 1, 2, 3, 4。它的长度为 4。
自己的题解:
cpp
#include<unordered_set>
class Solution {
public:
int longestConsecutive(vector<int>& nums) {
unordered_set<int>hash;
int count=0;
for(int i=0;i<nums.size();i++) //放入hash
{
hash.insert(nums[i]);
}
for(auto x : hash) //er:set的遍历
{
int temp=1; //er:头元素本身算1个
if(hash.find(x-1)!=hash.end()) //不是头
{
continue;
}else //是头
{
int j=1;
while(hash.find(x+j)!=hash.end()) //寻找
{
temp++;
j+=1;
}
}
if(temp>count)
{
count=temp;
}
}
return count;
}
};我的解题思路:虽然但是这个版本的代码没用问题,但是会超时过不了,这个题目我最初的想法就是肯定需要一个去遍历判断这个下一个值,最主要的问题其实就是找连续串中的头,首先判断头 就通过在集合中查看有无该数减1即可判断这个元素是不是头。(但是超时了)。
后续发现只要先对集合进行容量的分配,就可以通过了
cpp
#include<unordered_set>
class Solution {
public:
int longestConsecutive(vector<int>& nums) {
unordered_set<int>hash;
hash.reserve(nums.size()); //添加这个就可以过
int count=0;
for(int i=0;i<nums.size();i++) //放入hash
{
hash.insert(nums[i]);
}
for(auto x : hash) //er:set的遍历
{
int temp=1; //er:头元素本身算1个
if(hash.find(x-1)!=hash.end()) //不是头
{
continue;
}else //是头
{
int j=1;
while(hash.find(x+j)!=hash.end()) //寻找
{
temp++;
j+=1;
}
}
if(temp>count)
{
count=temp;
}
}
return count;
}
};- 原来如果没有提前进行容量分配,会每次都从最小桶开始进行多次扩容耗费时间
- 如果一开始就预留了足够容量,则插入阶段大幅减少(甚至避免)多次 rehash;
官方题解:
cpp
class Solution {
public:
int longestConsecutive(vector<int>& nums) {
unordered_set<int> num_set;
for (const int& num : nums) {
num_set.insert(num);
}
int longestStreak = 0;
for (const int& num : num_set) {
if (!num_set.count(num - 1)) {
int currentNum = num;
int currentStreak = 1;
while (num_set.count(currentNum + 1)) {
currentNum += 1;
currentStreak += 1;
}
longestStreak = max(longestStreak, currentStreak);
}
}
return longestStreak;
}
};官方的解题思路和我们的解题思路是一致的,都是利用哈希表进行判断元素是否存在,同时进行遍历查找,最主要的还是那个寻找序列头的元素。