博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈:Python、Django、snowNLP情感分析、基于矩阵分解的协同过滤推荐系统、requests爬虫
功能模块:
- 数据采集与预处理模块
- 协同过滤推荐模块
- 情感与舆情分析模块
- 多维度数据分析模块
- 系统管控模块
项目介绍:本项目基于Python和Django框架构建新能源汽车数据分析与个性化推荐系统。通过requests爬虫采集汽车评分、价格、性能参数及舆情等多维度数据,完成数据清洗与整合。系统采用基于矩阵分解的协同过滤算法,结合snowNLP情感分析技术,实现车型个性化推荐与舆情倾向挖掘。同时提供价格分析、车型占比、百公里加速等多维度可视化分析面板,并集成注册登录与后台管理功能,保障系统安全运维。
2、项目界面
1数据统计面板
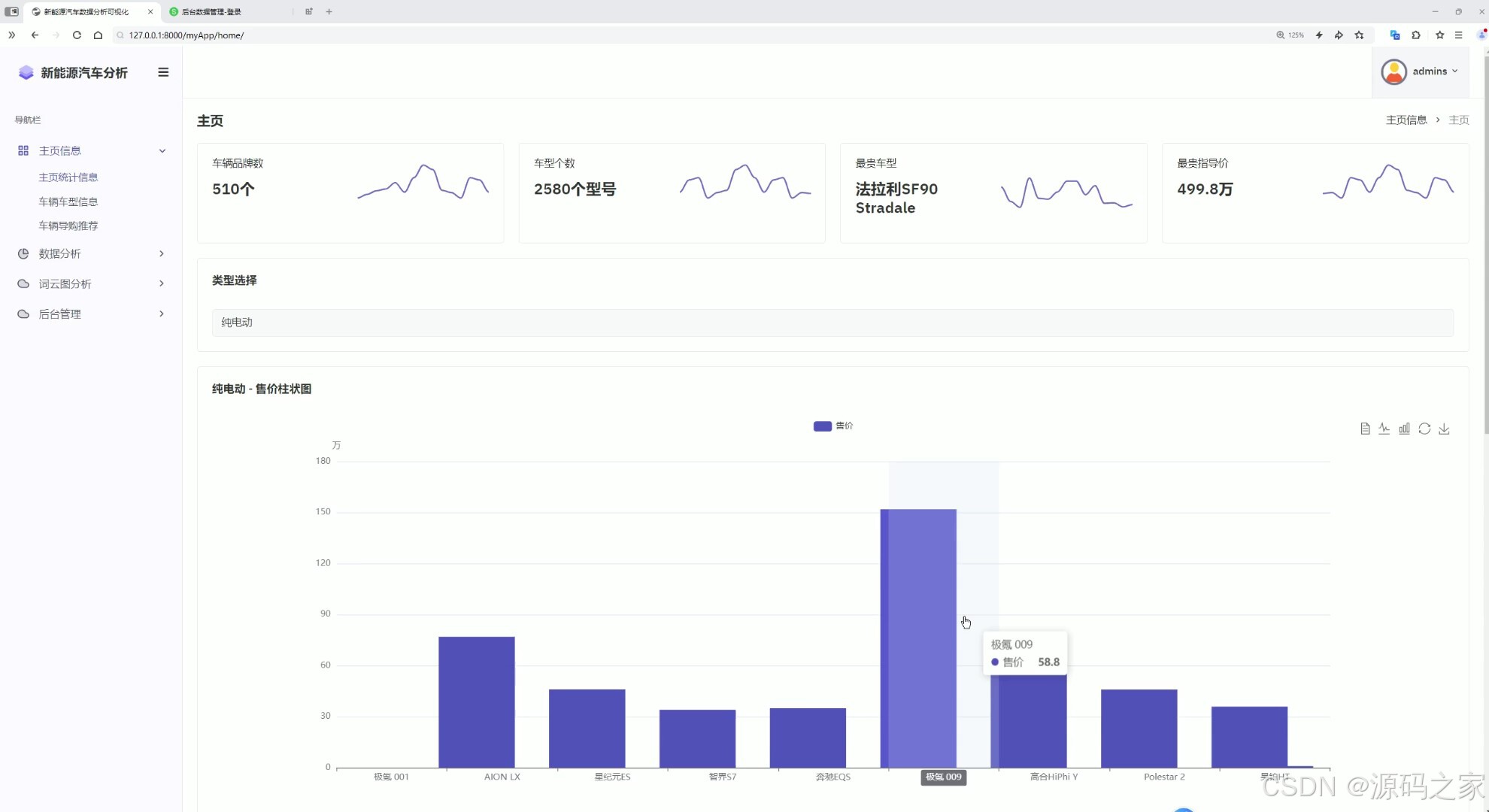
这是新能源汽车数据分析可视化系统的主页,左侧为导航栏,包含主页信息、数据分析、词云图分析、后台管理等功能入口,页面上方展示车辆相关统计信息,支持车辆类型选择,下方呈现对应类型车辆的售价柱状图,可直观查看不同车型的售价情况。
2数据表格
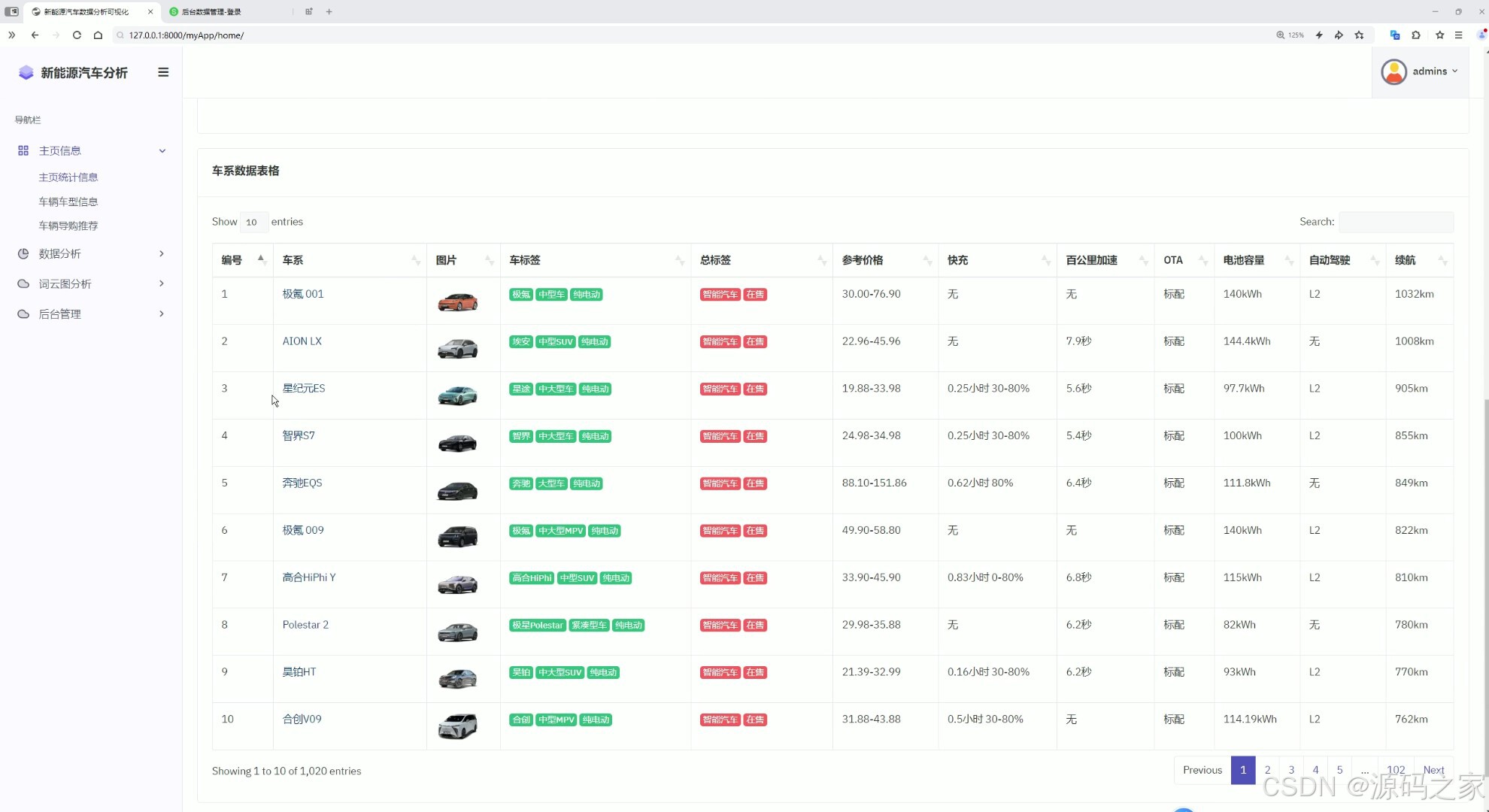
这是新能源汽车数据分析可视化系统的车辆车型信息页面,左侧为包含主页信息、数据分析等模块的导航栏,主区域展示车系数据表格,呈现各车型的详细参数信息,支持搜索、分页查看与条目数量调整,方便用户查询和管理车辆数据。
3车型详细页 车辆推荐
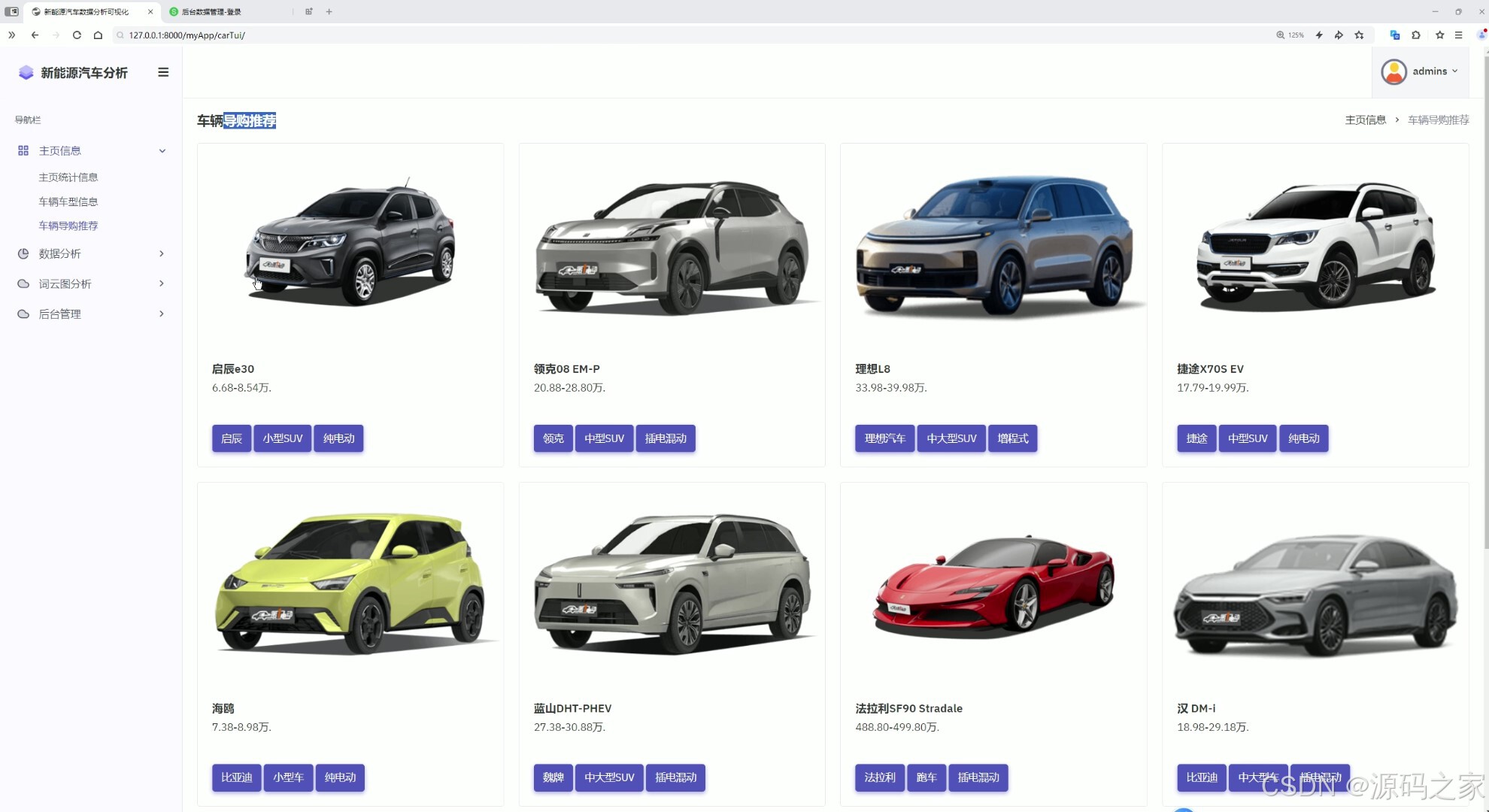
这是新能源汽车数据分析可视化系统的车辆导购推荐页面,左侧为包含主页信息、数据分析等模块的导航栏,主区域以卡片形式展示多款车型,呈现车辆外观、名称、价格及品牌、车型、动力类型等标签信息,为用户提供购车参考。
4 数据分析
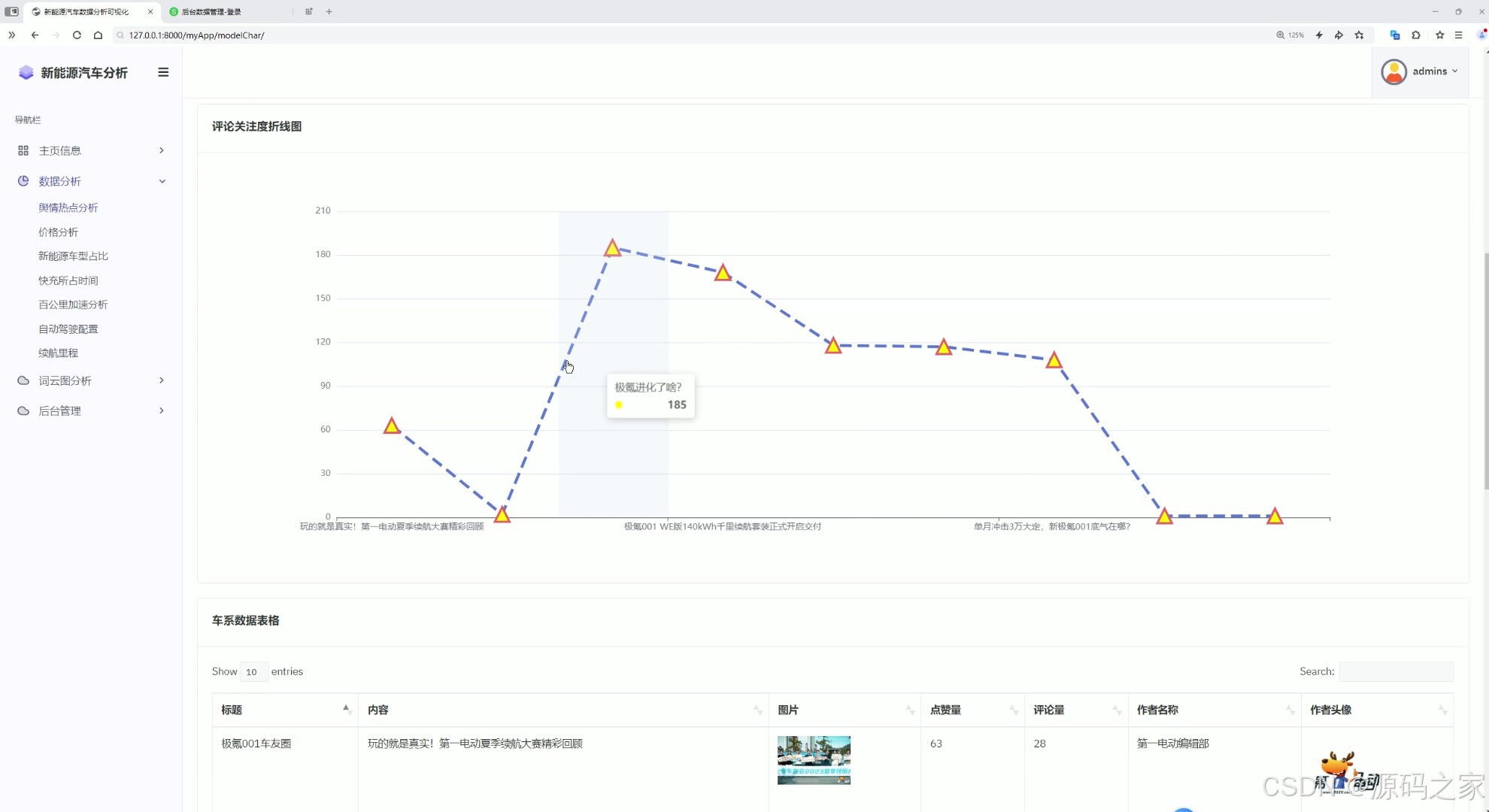
这是新能源汽车数据分析可视化系统的数据分析页面,左侧为包含主页信息、数据分析、词云图分析、后台管理等模块的导航栏,主区域上方展示评论关注度折线图,呈现相关话题热度变化,下方为车系数据表格,展示相关内容的互动数据,支持搜索与分页查看。
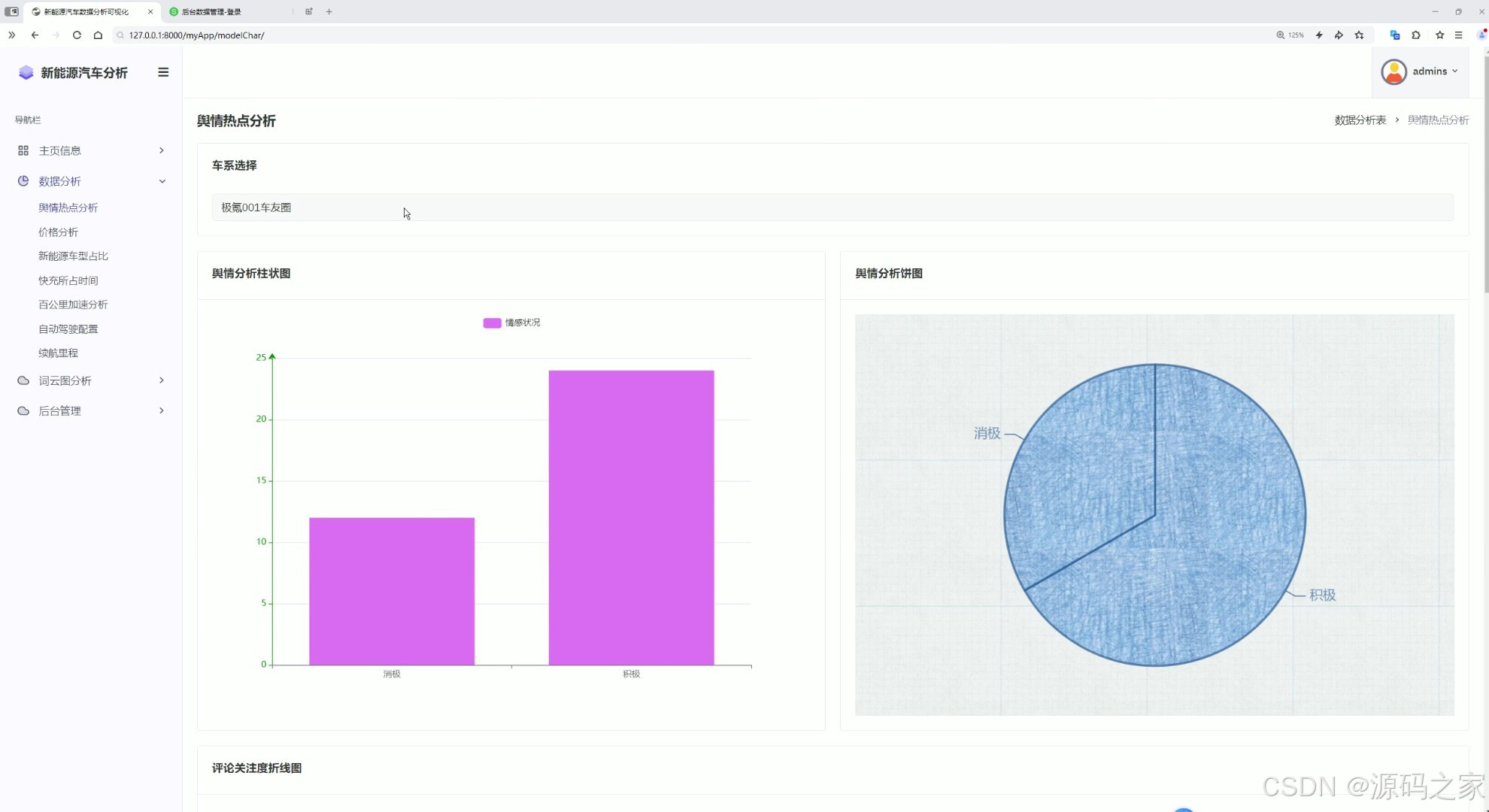
6舆情热点分析
这是新能源汽车数据分析可视化系统的舆情热点分析页面,左侧为包含主页信息、数据分析等模块的导航栏,主区域支持车系选择,通过舆情分析柱状图和饼图展示对应车系的情感状况分布,直观呈现用户对车型的舆情反馈。
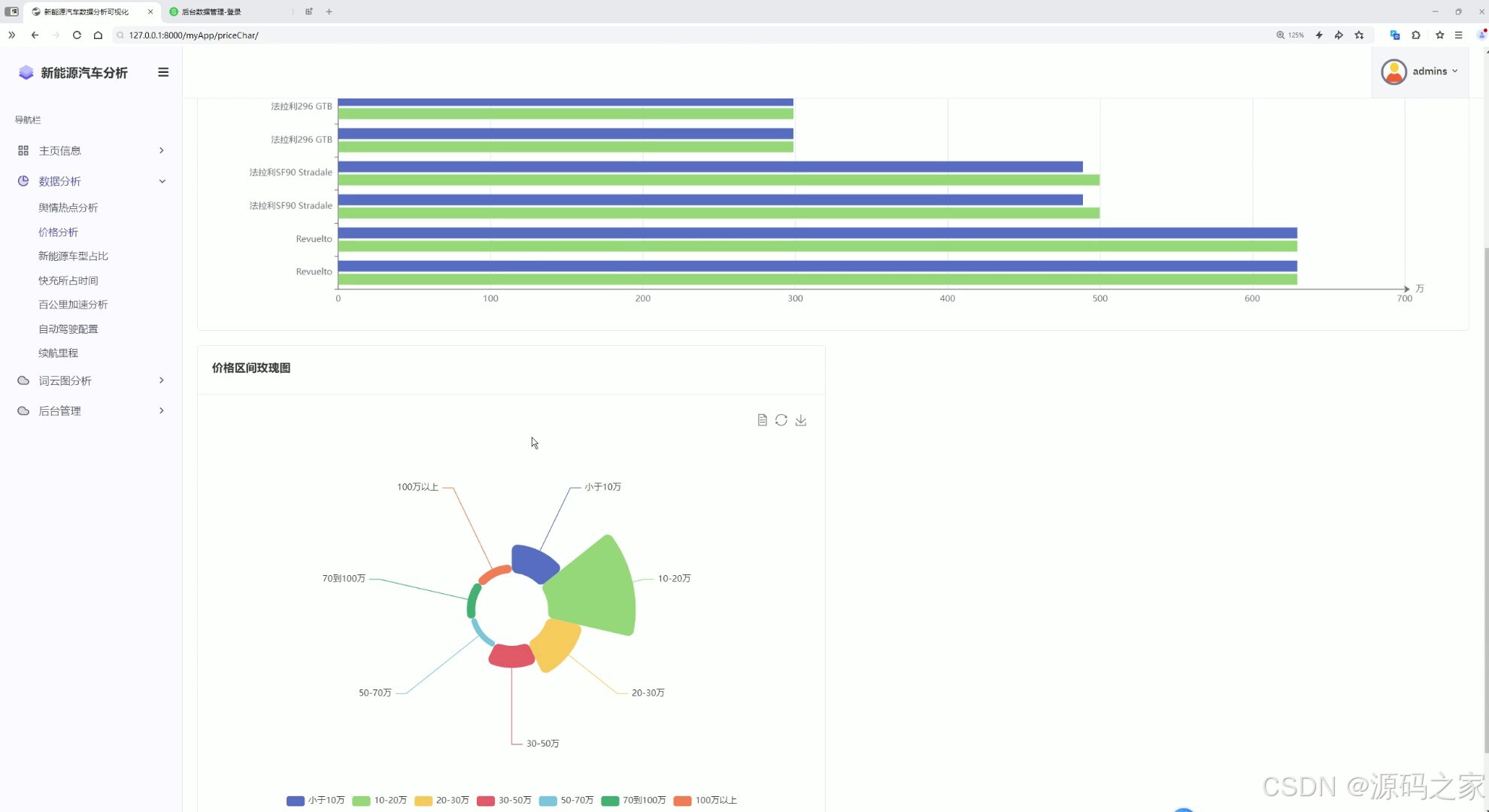
7价格分析
这是新能源汽车数据分析可视化系统的价格分析页面,左侧为包含主页信息、数据分析等模块的导航栏,主区域上方通过条形图展示不同车型的价格情况,下方以玫瑰图呈现各价格区间的车型分布,直观呈现新能源汽车的价格维度数据。
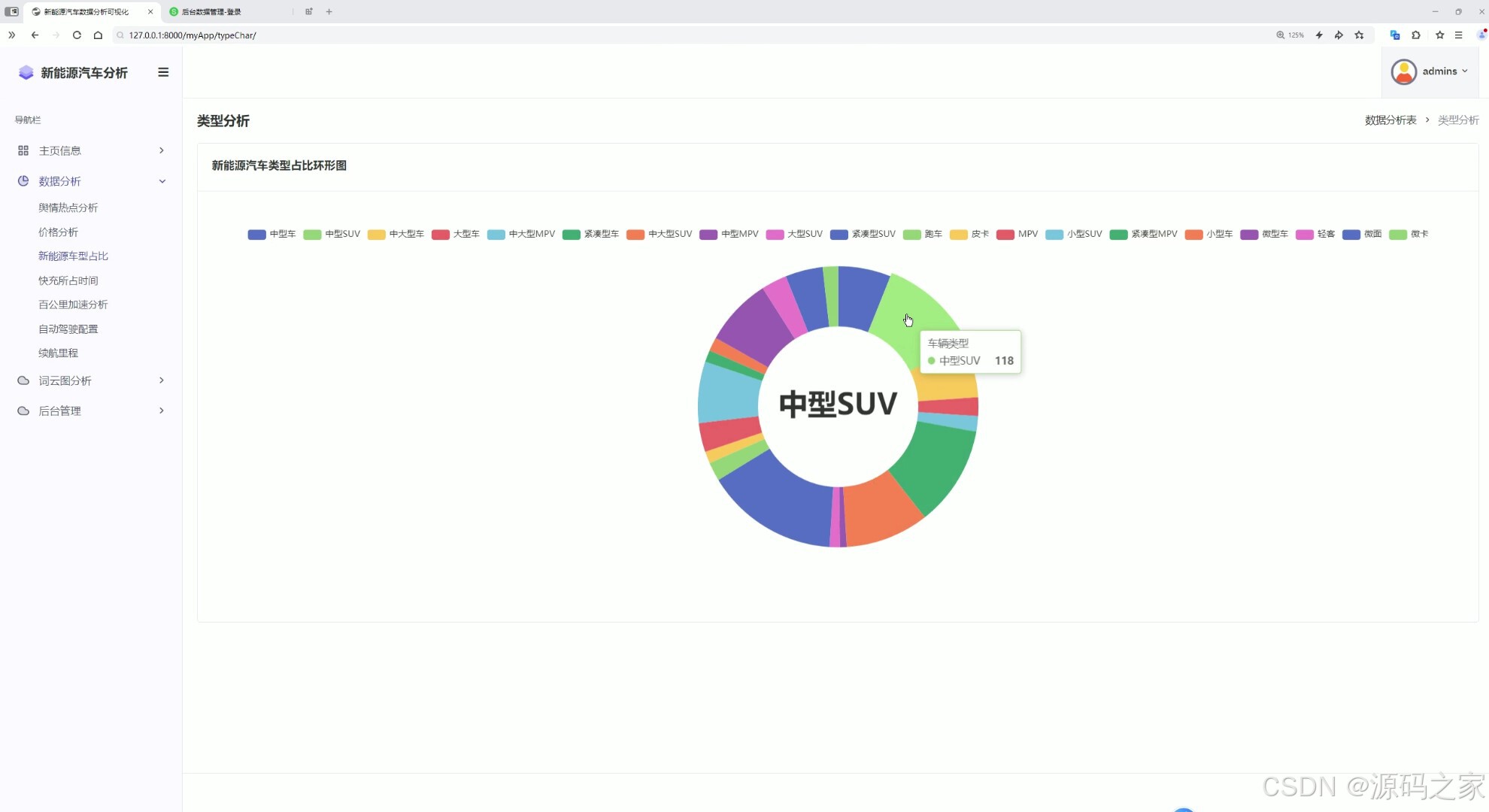
8车型占比
这是新能源汽车数据分析可视化系统的类型分析页面,左侧为包含主页信息、数据分析、词云图分析、后台管理等模块的导航栏,主区域展示新能源汽车类型占比环形图,直观呈现不同类型新能源汽车的分布占比情况,清晰展示各类车型的占比差异。
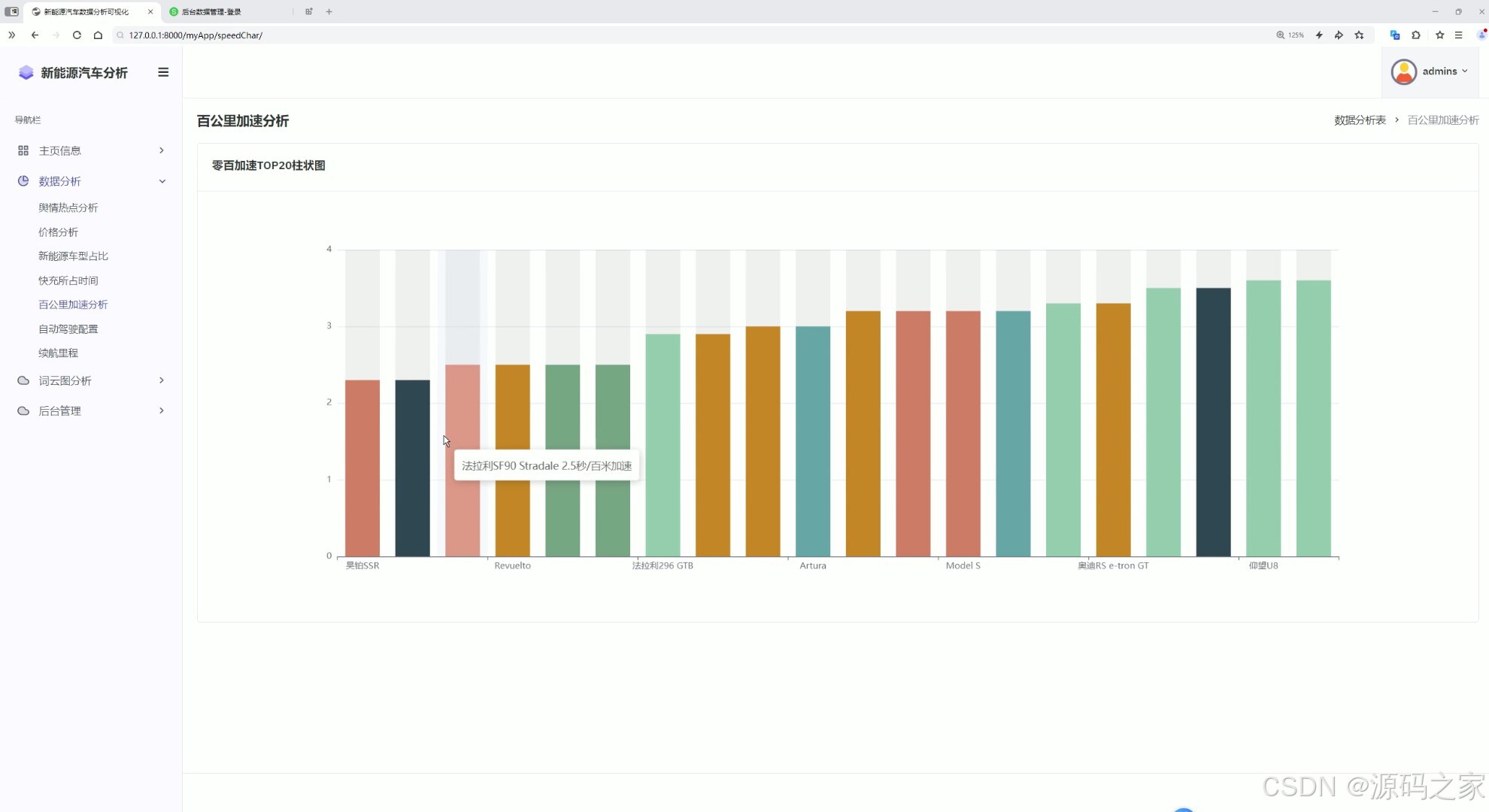
10百公里加速分析
这是新能源汽车数据分析可视化系统的百公里加速分析页面,左侧为包含主页信息、数据分析、词云图分析、后台管理等模块的导航栏,主区域展示零百加速TOP20柱状图,直观呈现不同车型的百公里加速性能表现,方便用户对比各车型的动力性能。
13车系词云图
这是新能源汽车数据分析可视化系统的车系词云图页面,左侧为包含主页信息、数据分析、词云图分析、后台管理等模块的导航栏,主区域展示车系词云图,以不同大小和颜色的文字呈现各车系、动力类型等信息,直观展示相关数据的热度与分布情况。

14 注册登录
这是新能源汽车数据分析可视化系统的登录页面,左侧为登录功能区,包含用户名和密码输入框、记住我选项、登录按钮以及注册入口,右侧为装饰性背景,用于验证用户身份,只有成功登录后才能进入系统的数据分析、管理等功能模块。

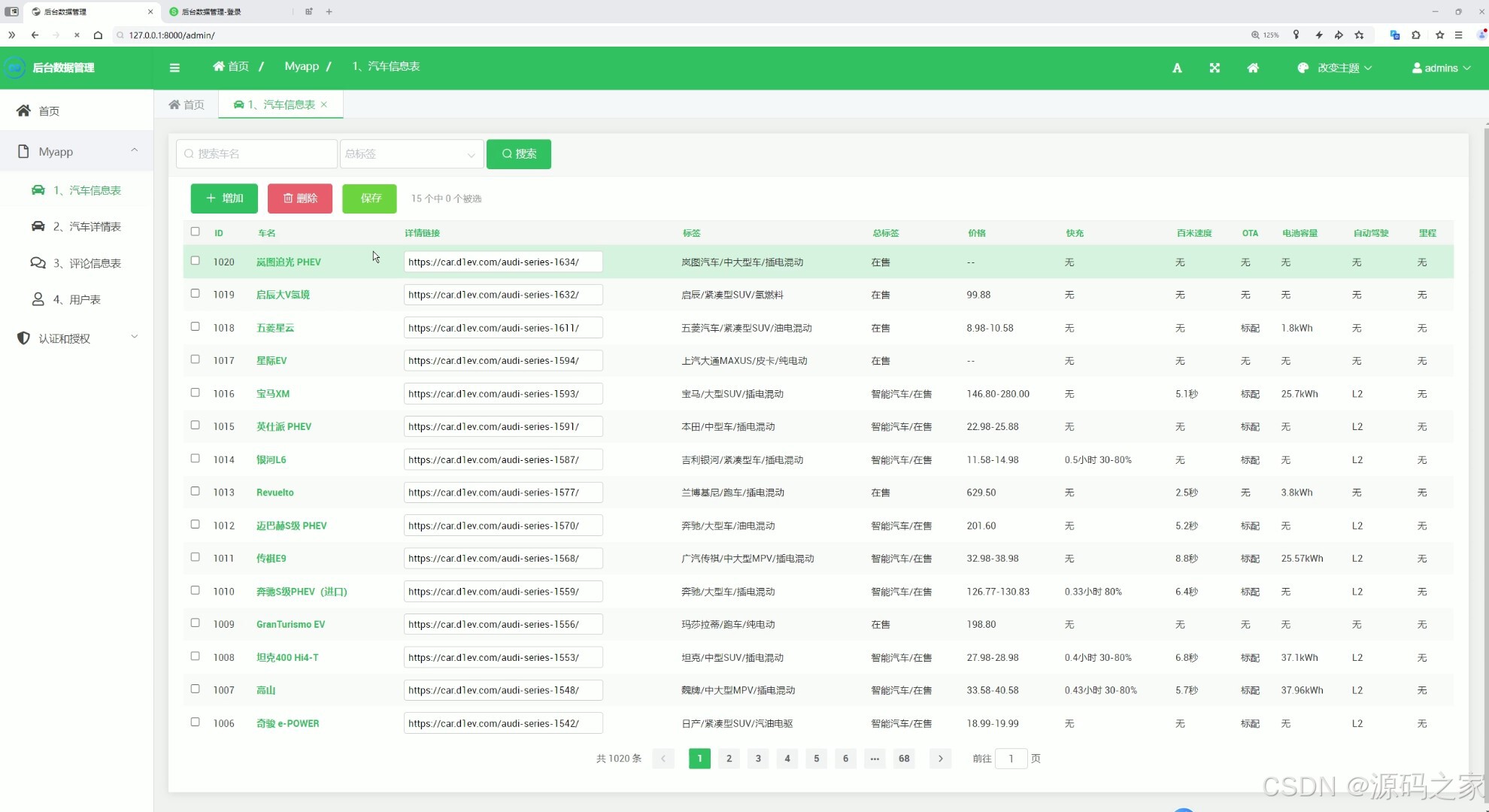
15 后台管理
这是新能源汽车数据分析可视化系统的后台数据管理页面,左侧为包含首页、汽车信息表、评论信息表、用户表等模块的导航栏,主区域展示汽车信息表,支持搜索、增加、删除、保存等操作,可分页查看和管理车辆的详细数据信息。
3、项目说明
一、技术栈简要说明
本系统采用Python作为核心开发语言,基于Django框架构建Web应用后端。数据分析层面使用snowNLP进行舆情情感分析,推荐算法采用基于矩阵分解的协同过滤技术实现个性化车型推荐。数据采集部分借助requests库完成汽车多维度信息的爬取工作。前端展示结合可视化图表库实现各类数据分析图表的动态呈现。
二、功能模块详细介绍
数据采集与预处理模块
该模块通过requests爬虫技术从汽车资讯平台获取车辆评分、价格参数、性能指标及用户舆情等多源数据。采集后的数据经过清洗、去重、格式规整等预处理操作,最终整合存入数据库与CSV文件中,为推荐系统和各分析模块提供标准化数据输入。
协同过滤推荐模块
基于矩阵分解算法构建个性化推荐引擎。模块首先提取用户对汽车的评分数据构建用户-物品评分矩阵,随后通过随机梯度下降优化的矩阵分解模型训练用户与物品的潜在特征向量。模型完成训练后,预测用户对未评分车型的偏好程度,按预测分值从高到低生成推荐列表,并在车型详情页面向用户展示。
情感与舆情分析模块
利用snowNLP情感分析库对汽车舆情文本进行倾向性判断。模块支持按车系筛选,通过柱状图与饼图直观呈现正面、中性、负面情感的比例分布,帮助用户快速把握不同车型的市场口碑趋势,为购车决策提供舆情参考。
多维度数据分析模块
涵盖价格分析、车型占比、百公里加速性能、评论关注度等多个分析维度。价格分析模块通过条形图和玫瑰图展示车型价格分布;车型占比模块使用环形图呈现不同动力类型车辆的结构比例;加速分析模块以TOP20柱状图对比各车型零百加速性能;评论关注度折线图展示话题热度变化趋势;车系词云图则以可视化方式突出高频关键词。
系统管控模块
基于Django框架的用户权限管理功能,包含注册登录验证与后台数据管理两大子模块。登录页面提供身份认证入口,确保只有授权用户可访问系统核心功能。后台管理界面支持汽车信息表、评论信息表、用户表等数据的增删改查操作,并提供搜索、分页、条目筛选等便捷管理工具。
三、项目总结
本系统整合了数据采集、协同过滤推荐、情感分析、多维数据可视化及用户权限管理五大核心功能,形成完整的新能源汽车数据分析与个性化推荐解决方案。系统通过爬虫实现数据自动化采集更新,利用矩阵分解推荐算法提升用户选车效率,借助snowNLP辅助舆情研判,同时提供丰富的可视化分析面板帮助用户直观理解市场特征。后台管理功能保障了数据维护的便捷性与系统运行的安全性,整体实现了从数据获取到分析推荐的全流程闭环。
4、核心代码
python
import os
import django
import pandas as pd
import numpy as np
from tqdm import tqdm
os.environ.setdefault('DJANGO_SETTINGS_MODULE','project.settings')
django.setup()
from myApp.models import *
def getAllCars():
carInfoList = list(carInfo.objects.all())
df = pd.read_csv('./commentNew.csv').values
dataList = []
for i in df:
if type(i[0]) == str:
title = i[0][0:2]
for j in carInfoList:
if j.carName.find(title) != -1:
dataList.append([
i[7], # userid
j.id,#itemid
i[3]
])
print(dataList)
return dataList
def getUIMat(data):
user_list = [i[0] for i in data]
item_list = [i[1] for i in data]
UI_matrix = np.zeros((max(user_list) +1,max(item_list) +1))
for eache_interation in tqdm(data,total = len(data)):
UI_matrix[eache_interation[0]][eache_interation[1]] = eache_interation[2]
return UI_matrix
class MF():
def __init__(self,R,K,alpha,beta,iterations):
self.R = R
self.num_users,self.num_items = R.shape
self.K = K
self.alpha = alpha
self.beta = beta
self.iterations = iterations
def train(self):
self.P = np.random.normal(scale=1./self.K, size=(self.num_users, self.K))
self.Q = np.random.normal(scale=1./self.K, size=(self.num_items, self.K))
self.b_u = np.zeros(self.num_users)
self.b_i = np.zeros(self.num_items)
self.b = np.mean(self.R[np.where(self.R != 0)])
self.samples = [
(i, j, self.R[i, j])
for i in range(self.num_users)
for j in range(self.num_items)
if self.R[i, j] > 0
]
training_process = []
for i in tqdm(range(self.iterations), total=self.iterations):
np.random.shuffle(self.samples)
self.sgd()
mse = self.mse()
training_process.append((i, mse))
if (i == 0) or ((i+1) % (self.iterations / 10) == 0):
pass
return training_process
def mse(self):
xs, ys = self.R.nonzero()
predicted = self.full_matrix()
error = 0
for x, y in zip(xs, ys):
error += pow(self.R[x, y] - predicted[x, y], 2)
return np.sqrt(error)
def sgd(self):
for i, j, r in self.samples:
prediction = self.get_rating(i, j)
e = (r - prediction)
self.b_u[i] += self.alpha * (e - self.beta * self.b_u[i])
self.b_i[j] += self.alpha * (e - self.beta * self.b_i[j])
self.P[i, :] += self.alpha * (e * self.Q[j, :] - self.beta * self.P[i,:])
self.Q[j, :] += self.alpha * (e * self.P[i, :] - self.beta * self.Q[j,:])
# 数值检查和处理
if np.isnan(self.P[i, :]).any() or np.isnan(self.Q[j, :]).any():
self.P[i, :] = np.nan_to_num(self.P[i, :])
self.Q[j, :] = np.nan_to_num(self.Q[j, :])
def get_rating(self, i, j):
prediction = self.b + self.b_u[i] + self.b_i[j] + self.P[i, :].dot(self.Q[j, :].T)
if np.isnan(prediction) or np.isinf(prediction):
prediction = 0
return prediction
def full_matrix(self):
return self.b + self.b_u[:,np.newaxis] + self.b_i[np.newaxis:,] + self.P.dot(self.Q.T)
def modelFn(each_user):
startList = getAllCars()
obs_dataset = []
for i in startList:
obs_dataset.append([i[0],i[1],i[2]])
R = getUIMat(obs_dataset)
mf = MF(R,K=2,alpha=0.1,beta=0.8,iterations=3)
mf.train()
user_rating = mf.full_matrix()[each_user].tolist()
topN = [(i,user_rating.index(i)) for i in user_rating]
topN = [i[1] for i in sorted(topN,key=lambda x:x[0],reverse=True)]
return topN
if __name__ == '__main__':
# getAllCars()
getAllCars()
print(modelFn(3))