
🔥承渊政道: 个人主页
❄️个人专栏: 《C语言基础语法知识》 《数据结构与算法》 《C++知识内容》 《Linux系统知识》 《算法刷题指南》 《测评文章活动推广》 《大模型语言路线学习》
✨逆境不吐心中苦,顺境不忘来时路!✨ 🎬 博主简介:

在算法面试与刷题实战中,栈、队列及优先级队列是三大基础且高频的数据结构,它们看似简单,却贯穿了从基础入门到进阶难题的各类考点,是解锁数组、字符串、树、图等复杂算法题的"钥匙".无论是字节、阿里等大厂面试中的经典追问,还是LeetCode中占比极高的基础应用题,几乎都能看到这三种结构的身影------栈的"先进后出"适配括号匹配、单调栈求解最值,队列的"先进先出"支撑滑动窗口、层次遍历,优先级队列(堆)则是TopK、贪心算法的核心载体.很多学习者在掌握了三种结构的基本原理后,仍会陷入"懂原理、不会做题"的困境.本文聚焦"实战通关"核心,摒弃冗余的理论堆砌,直击栈、队列、优先级队列的高频考点与经典考题.我们将从考点拆解、解题模板、真题精讲三个维度,逐一剖析每种结构的核心应用场景,拆解常见考题的解题思路,总结易错点与避坑技巧,帮助学习者快速掌握解题规律,吃透高频考点,摆脱"刷题低效"的困境,顺利通关算法面试与笔试中的相关考题,夯实算法基础,为进阶学习筑牢根基.废话不多说,下面跟着小编的节奏🎵一起去疯狂的学习吧!
目录
- 1.栈和队列以及优先级队列思想背景
- 2.删除字符串中的所有相邻重复项---栈(OJ题)
- 3.比较含退格的字符串---栈(OJ题)
- 4.基本计算器--栈(OJ题)
- 5.字符串解码--栈(OJ题)
- 6.验证栈序列--栈(OJ题)
- 7.N叉树的层序遍历--队列+宽搜(BFS)(OJ题)
- 8.二叉树的锯齿形层序遍历--队列+宽搜(BFS)(OJ题)
- 9.二叉树最大宽度--队列+宽搜(BFS)(OJ题)
- 10.在每个树行中找最大值--队列+宽搜(BFS)(OJ题)
- 11.最后一块石头的重量--优先级队列(OJ题)
- 12.数据流中的第k大元素--优先级队列(OJ题)
- 13.前k个高频单词--优先级队列(OJ题)
- 14.数据流的中位数--优先级队列(OJ题)
1.栈和队列以及优先级队列思想背景
栈和队列以及优先级队列思想背景,源于对"数据有序操作"的实际需求,是计算机科学中最基础且应用广泛的线性数据结构思想,其设计逻辑贴合现实场景,核心是通过规范数据的"进出顺序",解决不同场景下的高效处理问题.
栈的核心思想是"先进后出"(LIFO),源于现实中"堆叠"场景的抽象------如同叠盘子,先放入的盘子在最底层,最后放入的最先取出,这种思想最初用于解决函数调用、表达式求值、括号匹配等"后进先处理"的问题,是算法中"回溯、单调操作"的核心支撑.
队列的核心思想是"先进先出"(FIFO),对应现实中的"排队"场景,比如超市结账、任务调度,先进入队列的元素先被处理,其思想主要用于解决"顺序处理、缓冲"类问题,例如滑动窗口、广度优先搜索(BFS)、消息队列等,确保数据处理的有序性和公平性.
优先级队列则是在队列"先进先出"思想的基础上,增加了"优先级排序"逻辑------不再遵循严格的进出顺序,而是始终优先处理优先级最高的元素,其思想源于现实中"按重要性处理任务"的场景,比如急诊病人优先救治、操作系统的进程调度,核心依赖堆结构实现高效排序,是贪心算法、TopK问题的核心载体.
2.删除字符串中的所有相邻重复项---栈(OJ题)

算法思路:解法(栈):
本题极像我们玩过的开⼼消消乐游戏,仔细观察消除过程,可以发现本题与我们之前做过的括号匹配问题是类似的.当前元素是否被消除,需要知道上⼀个元素的信息,因此可以⽤栈来保存信息.
但是,如果使⽤stack来保存的话,最后还需要把结果从栈中取出来.不如直接⽤数组模拟⼀个栈结构:在数组的尾部尾插尾删,实现栈的进栈和出栈.那么最后数组存留的内容,就是最后的结果.
核心代码
cpp
class Solution
{
public:
string removeDuplicates(string s)
{
string ret; //搞⼀个数组,模拟栈结构即可
for (auto ch : s)
{
if (ret.size() && ch == ret.back())
ret.pop_back(); //出栈
else
ret += ch; //⼊栈
}
return ret;
}
};完整测试代码
cpp
#include <iostream>
#include <string>
using namespace std;
//字符串模拟栈,删除相邻重复项)
class Solution
{
public:
string removeDuplicates(string s)
{
string ret; // 用字符串模拟栈:back()=栈顶,push_back=入栈,pop_back=出栈
for (auto ch : s) // 遍历字符串的每一个字符
{
// 栈不为空 + 当前字符 == 栈顶字符 → 相邻重复,删除栈顶(消除重复)
if (ret.size() && ch == ret.back())
ret.pop_back();
// 不重复 → 字符入栈
else
ret += ch;
}
return ret; // 栈中剩余字符就是最终结果
}
};
int main() {
Solution sol;
string s1 = "abbaca";
cout << "输入: " << s1 << " → 输出: " << sol.removeDuplicates(s1) << endl;
string s2 = "aabb";
cout << "输入: " << s2 << " → 输出: " << sol.removeDuplicates(s2) << endl;
string s3 = "aaaaa";
cout << "输入: " << s3 << " → 输出: " << sol.removeDuplicates(s3) << endl;
string s4 = "abba";
cout << "输入: " << s4 << " → 输出: " << sol.removeDuplicates(s4) << endl;
string s5 = "x";
cout << "输入: " << s5 << " → 输出: " << sol.removeDuplicates(s5) << endl;
string s6 = "";
cout << "输入: 空字符串 → 输出: " << sol.removeDuplicates(s6) << endl;
return 0;
}
3.比较含退格的字符串---栈(OJ题)

算法思路:解法(⽤数组模拟栈):
由于退格的时候需要知道前⾯元素的信息,⽽且退格也符合后进先出的特性.因此我们可以使⽤栈结构来模拟退格的过程.
- 当遇到⾮#字符的时候,直接进栈;
- 当遇到#的时候,栈顶元素出栈.
为了⽅便统计结果,我们使⽤数组来模拟实现栈结构.
核心代码
cpp
class Solution
{
public:
bool backspaceCompare(string s, string t)
{
return changeStr(s) == changeStr(t);
}
string changeStr(string& s)
{
string ret; //⽤数组模拟栈结构
for (char ch : s)
{
if (ch != '#')
ret += ch;
else {
if (ret.size())
ret.pop_back();
}
}
return ret;
}
};完整测试代码
cpp
#include <iostream>
#include <string>
using namespace std;
//(栈思想解决退格字符串比较)
class Solution
{
public:
//处理两个字符串后比较是否相等
bool backspaceCompare(string s, string t)
{
return changeStr(s) == changeStr(t);
}
//用字符串模拟栈,处理#退格字符
string changeStr(string& s)
{
string ret; // 用string模拟栈:back()栈顶,push_back入栈,pop_back出栈
for (char ch : s)
{
// 字符不是#,直接入栈
if (ch != '#')
ret += ch;
// 字符是#,执行退格:栈不为空则弹出栈顶(删除前一个字符)
else {
if (ret.size())
ret.pop_back();
}
}
return ret; // 返回处理后的最终字符串
}
};
int main() {
Solution sol;
string s1 = "ab#c", t1 = "ad#c";
cout << boolalpha; // 让cout输出true/false,而不是1/0
cout << "测试1:s=\"" << s1 << "\", t=\"" << t1 << "\" → "
<< sol.backspaceCompare(s1, t1) << endl;
string s2 = "a##c", t2 = "#a#c";
cout << "测试2:s=\"" << s2 << "\", t=\"" << t2 << "\" → "
<< sol.backspaceCompare(s2, t2) << endl;
string s3 = "a#c", t3 = "b";
cout << "测试3:s=\"" << s3 << "\", t=\"" << t3 << "\" → "
<< sol.backspaceCompare(s3, t3) << endl;
string s4 = "###", t4 = "#";
cout << "测试4:s=\"" << s4 << "\", t=\"" << t4 << "\" → "
<< sol.backspaceCompare(s4, t4) << endl;
string s5 = "", t5 = "";
cout << "测试5:空字符串对比 → "
<< sol.backspaceCompare(s5, t5) << endl;
return 0;
}
4.基本计算器--栈(OJ题)

算法思路:解法(栈):
由于表达式⾥⾯没有括号,因此我们只⽤处理加减乘除混合运算即可.根据四则运算的顺序,我们可以先计算乘除法,然后再计算加减法.由此,我们可以得出下⾯的结论:
- 当⼀个数前⾯是 '+' 号的时候,这⼀个数是否会被⽴即计算是不确定的,因此我们可以先压⼊栈中;
- 当⼀个数前⾯是 '-' 号的时候,这⼀个数是否被⽴即计算也是不确定的,但是这个数已经和前⾯ 的 '-' 号绑定了,因此我们可以将这个数的相反数压⼊栈中;
- 当⼀个数前⾯是 '*' 号的时候,这⼀个数可以⽴即与前⾯的⼀个数相乘,此时我们让将栈顶的元素乘上这个数;
- 当⼀个数前⾯是 '/' 号的时候,这⼀个数也是可以⽴即被计算的,因此我们让栈顶元素除以这个数.
当遍历完全部的表达式的时候,栈中剩余的元素之和就是最终结果.
核心代码
cpp
class Solution
{
public:
int calculate(string s)
{
vector<int> st; //⽤数组来模拟栈结构
int i = 0, n = s.size();
char op = '+';
while (i < n) {
if (s[i] == ' ')
i++;
else if (s[i] >= '0' && s[i] <= '9')
{
//先把这个数字给提取出来
int tmp = 0;
while (i < n && s[i] >= '0' && s[i] <= '9')
tmp = tmp * 10 + (s[i++] - '0');
if (op == '+')
st.push_back(tmp);
else if (op == '-')
st.push_back(-tmp);
else if (op == '*')
st.back() *= tmp;
else
st.back() /= tmp;
} else
{
op = s[i];
i++;
}
}
int ret = 0;
for (auto x : st)
ret += x;
return ret;
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
#include <string>
using namespace std;
class Solution
{
public:
int calculate(string s)
{
vector<int> st; //用数组模拟栈
int i = 0, n = s.size();
char op = '+'; //初始运算符为+,处理第一个数字
while (i < n) {
//跳过空格
if (s[i] == ' ')
i++;
//提取连续数字
else if (s[i] >= '0' && s[i] <= '9')
{
int tmp = 0;
while (i < n && s[i] >= '0' && s[i] <= '9')
tmp = tmp * 10 + (s[i++] - '0');
//根据运算符处理数字:加减入栈,乘除直接计算栈顶
if (op == '+')
st.push_back(tmp);
else if (op == '-')
st.push_back(-tmp);
else if (op == '*')
st.back() *= tmp;
else
st.back() /= tmp;
}
//记录当前运算符
else
{
op = s[i];
i++;
}
}
//栈中所有元素求和即为最终结果
int ret = 0;
for (auto x : st)
ret += x;
return ret;
}
};
int main() {
//创建Solution对象
Solution sol;
vector<string> testCases = {
"3+2*2", //基础混合运算 → 7
" 3/2 ", //带空格+除法 → 1
" 3+5 / 2 ", //带空格+混合运算 →5
"10-3*2", //减法+乘法 →4
"14-3/2", //减法+除法(取整)→13
"2*3*4", //连续乘法 →24
"100-20*3+16/4", //复杂混合运算 →44
"0" //单个数字 →0
};
for (string& expr : testCases) {
int res = sol.calculate(expr);
cout << "表达式: \"" << expr << "\"\t计算结果: " << res << endl;
}
return 0;
}
5.字符串解码--栈(OJ题)

算法思路:解法(两个栈):
对于3ab2\[cd] ,我们需要先解码内部的,再解码外部(为了⽅便区分,使⽤了空格):
3ab2\[cd] -> 3abcd cd -> abcdcd abcdcd abcdcd;在解码 cd 的时候,我们需要保存 3 ab 2 这些元素的信息,并且这些信息使⽤的顺序是从后往前,正好符合栈的结构,因此我们可以定义两个栈结构,⼀个⽤来保存解码前的重复次数k(左括号前的数字),⼀个⽤来保存解码之前字符串的信息(左括号前的字符串信息).
细节:字符串这个栈中,先放入一个空串
分情况讨论:
- 遇到数字:提取出这个数字,放入"数字栈"中;
- 遇到 '[':把后面的字符串提取出来,放入"字符串栈"中;
- 遇到 ']':解析,然后放到"字符串栈"栈顶的字符串后面;
- 遇到单独的字符:提取出来这个字符串,直接放在"字符串栈"栈顶的字符串后面.
核心代码
cpp
class Solution
{
public:
string decodeString(string s)
{
stack<int> nums;
stack<string> st;
st.push("");
int i = 0, n = s.size();
while (i < n) {
if (s[i] >= '0' && s[i] <= '9')
{
int tmp = 0;
while (s[i] >= '0' && s[i] <= '9')
{
tmp = tmp * 10 + (s[i] - '0');
i++;
}
nums.push(tmp);
} else if (s[i] == '[')
{
i++; // 把括号后⾯的字符串提取出来
string tmp = "";
while (s[i] >= 'a' && s[i] <= 'z')
{
tmp += s[i];
i++;
}
st.push(tmp);
} else if (s[i] == ']')
{
string tmp = st.top();
st.pop();
int k = nums.top();
nums.pop();
while (k--)
{
st.top() += tmp;
}
i++; // 跳过这个右括号
} else
{
string tmp;
while (i < n && s[i] >= 'a' && s[i] <= 'z')
{
tmp += s[i];
i++;
}
st.top() += tmp;
}
}
return st.top();
}
};完整测试代码
cpp
#include <iostream>
#include <stack>
#include <string>
using namespace std;
class Solution
{
public:
string decodeString(string s)
{
stack<int> nums; //存储重复次数
stack<string> st; //存储字符串片段
st.push(""); //初始化栈,放入空串
int i = 0, n = s.size();
while (i < n) {
//1.处理数字(支持多位数)
if (s[i] >= '0' && s[i] <= '9')
{
int tmp = 0;
while (s[i] >= '0' && s[i] <= '9')
{
tmp = tmp * 10 + (s[i] - '0');
i++;
}
nums.push(tmp);
}
//2.处理左括号 [
else if (s[i] == '[')
{
i++;
string tmp = "";
//提取括号内的字母
while (s[i] >= 'a' && s[i] <= 'z')
{
tmp += s[i];
i++;
}
st.push(tmp);
}
//3.处理右括号 ],执行字符串重复拼接
else if (s[i] == ']')
{
string tmp = st.top();
st.pop();
int k = nums.top();
nums.pop();
//循环拼接k次
while (k--)
{
st.top() += tmp;
}
i++;
}
//4.处理普通字母,直接拼接
else
{
string tmp;
while (i < n && s[i] >= 'a' && s[i] <= 'z')
{
tmp += s[i];
i++;
}
st.top() += tmp;
}
}
return st.top();
}
};
int main() {
Solution sol;
// 经典测试用例(覆盖所有核心场景)
vector<string> testCases = {
"3[a]2[bc]", // 基础用例 → aaabcbc
"3[a2[c]]", // 嵌套用例 → accaccacc
"2[abc]3[cd]ef", // 连续拼接 → abcabccdcdcdef
"abc3[cd]xyz", // 前缀+解码+后缀 → abccdcdcdxyz
"10[a]", // 多位数重复 → aaaaaaaaaa
"2[2[a]b]" // 多层嵌套 → aabaab
};
for (string& str : testCases) {
string res = sol.decodeString(str);
cout << "编码字符串: \"" << str << "\"" << endl;
cout << "解码结果: \"" << res << "\"" << endl << "-------------------------" << endl;
}
return 0;
}
6.验证栈序列--栈(OJ题)

算法思路:解法(栈):
⽤栈来模拟进出栈的流程.
⼀直让元素进栈,进栈的同时判断是否需要出栈.当所有元素模拟完毕之后,如果栈中还有元素,那么就是⼀个⾮法的序列.否则,就是⼀个合法的序列.
核心代码
cpp
class Solution
{
public:
bool validateStackSequences(vector<int>& pushed, vector<int>& popped)
{
stack<int> st;
int i = 0, n = popped.size();
for (auto x : pushed)
{
st.push(x);
while (st.size() && st.top() == popped[i])
{
st.pop();
i++;
}
}
return i == n;
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
#include <stack>
using namespace std;
class Solution
{
public:
bool validateStackSequences(vector<int>& pushed, vector<int>& popped)
{
stack<int> st;
int i = 0, n = popped.size();
//遍历所有压入元素
for (auto x : pushed)
{
st.push(x);
//栈顶匹配弹出序列,持续弹出
while (st.size() && st.top() == popped[i])
{
st.pop();
i++;
}
}
//弹出序列全部匹配则合法
return i == n;
}
};
int main() {
Solution sol;
vector<int> pushed1 = {1,2,3,4,5};
vector<int> popped1 = {4,5,3,2,1};
vector<int> pushed2 = {1,2,3,4,5};
vector<int> popped2 = {4,3,5,1,2};
vector<int> pushed3 = {};
vector<int> popped3 = {};
vector<int> pushed4 = {1};
vector<int> popped4 = {1};
vector<int> pushed5 = {1};
vector<int> popped5 = {2};
vector<int> pushed6 = {2,1,0};
vector<int> popped6 = {1,2,0};
cout << "测试用例1:" << (sol.validateStackSequences(pushed1, popped1) ? "合法" : "非法") << endl;
cout << "测试用例2:" << (sol.validateStackSequences(pushed2, popped2) ? "合法" : "非法") << endl;
cout << "测试用例3:" << (sol.validateStackSequences(pushed3, popped3) ? "合法" : "非法") << endl;
cout << "测试用例4:" << (sol.validateStackSequences(pushed4, popped4) ? "合法" : "非法") << endl;
cout << "测试用例5:" << (sol.validateStackSequences(pushed5, popped5) ? "合法" : "非法") << endl;
cout << "测试用例6:" << (sol.validateStackSequences(pushed6, popped6) ? "合法" : "非法") << endl;
return 0;
}
7.N叉树的层序遍历--队列+宽搜(BFS)(OJ题)
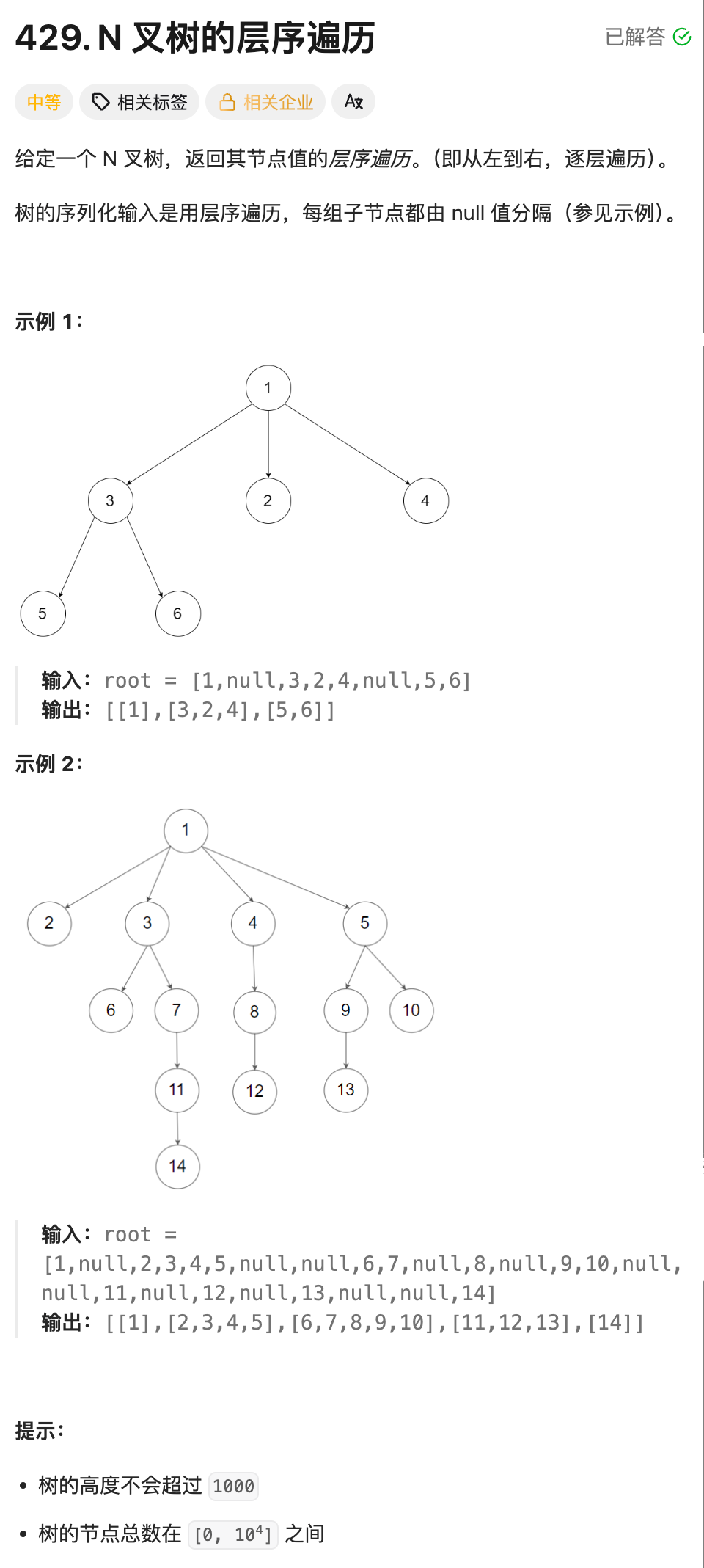
算法思路:解法(队列+宽搜):
层序遍历即可,仅需多加⼀个变量,⽤来记录每⼀层结点的个数就好了.
核心逻辑
- 用队列实现层序遍历 :队列里始终只存放当前待处理层的节点;
- 按层分组 :每次循环先记录当前层的节点数量,保证只处理完本层再处理下一层;
- N叉树适配 :用
for循环遍历节点的所有子节点,统一入队(区别于二叉树的left/right); - 结果存储:每一层的节点值存入一个数组,最终所有层的数组合并为二维数组返回.
执行流程举例
比如一颗简单的N叉树:
1
/|\
2 3 4遍历过程:
- 队列初始:
[1],当前层大小=1 → 处理节点1,值[1],子节点2、3、4入队; - 队列:
[2,3,4],当前层大小=3 → 处理节点2、3、4,值[2,3,4]; - 队列为空,循环结束;
- 最终结果:
[[1], [2,3,4]].
核心代码
cpp
class Solution
{
public:
//函数功能:对N叉树进行层序遍历,返回 二维数组(每一层对应一个一维数组)
//参数:root -> N叉树的根节点
//返回值:vector<vector<int>> -> 外层是层,内层是当前层所有节点的值
vector<vector<int>> levelOrder(Node* root)
{
//1.定义结果容器:存储最终的层序遍历结果
vector<vector<int>> ret;
//2.定义队列:层序遍历的核心工具(BFS用队列,先进先出,保证按层处理)
queue<Node*> q;
//3.边界条件:如果根节点为空(空树),直接返回空结果
if (root == nullptr)
return ret;
//4.初始化队列:将根节点入队,作为第一层的起始节点
q.push(root);
//5.外层循环:遍历每一层(队列不为空,说明还有节点未处理)
while (q.size())
{
//核心步骤:获取当前队列的大小 = 当前层的节点总数
//必须先固定这个值!因为后续子节点入队会改变队列大小
int sz = q.size();
// 定义临时数组:存储当前层所有节点的值
vector<int> tmp;
//6.内层循环:处理当前层的所有 sz 个节点
for (int i = 0; i < sz; i++)
{
//取出队首节点(当前要处理的节点)
Node* t = q.front();
//节点出队(已经取到,不需要留在队列里了)
q.pop();
//把当前节点的值加入临时数组(记录当前层的值)
tmp.push_back(t->val);
//7.遍历当前节点的所有子节点,让下一层节点入队
//范围for:遍历 children 数组里的每一个子节点
for (Node* child : t->children)
{
//安全判断:子节点非空才入队
if (child != nullptr)
q.push(child);
}
}
//8.当前层处理完毕,把临时数组加入最终结果
ret.push_back(tmp);
}
//9.所有层遍历完成,返回结果
return ret;
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
#include <queue>
using namespace std;
//1.定义N叉树节点结构
class Node {
public:
int val;
vector<Node*> children;
//构造函数
Node() {}
Node(int _val) {
val = _val;
}
Node(int _val, vector<Node*> _children) {
val = _val;
children = _children;
}
};
class Solution
{
public:
vector<vector<int>> levelOrder(Node* root)
{
vector<vector<int>> ret;
queue<Node*> q;
if (root == nullptr)
return ret;
q.push(root);
while (q.size())
{
int sz = q.size();
vector<int> tmp;
for (int i = 0; i < sz; i++)
{
Node* t = q.front();
q.pop();
tmp.push_back(t->val);
for (Node* child : t->children)
{
if (child != nullptr)
q.push(child);
}
}
ret.push_back(tmp);
}
return ret;
}
};
void printResult(vector<vector<int>>& res) {
cout << "层序遍历结果:[";
for (int i = 0; i < res.size(); i++) {
cout << "[";
for (int j = 0; j < res[i].size(); j++) {
cout << res[i][j];
if (j != res[i].size() - 1) cout << ",";
}
cout << "]";
if (i != res.size() - 1) cout << ",";
}
cout << "]" << endl << endl;
}
int main() {
Solution sol;
// 树结构:
// 1
// / | \
// 2 3 4
Node* root1 = new Node(1);
Node* node2 = new Node(2);
Node* node3 = new Node(3);
Node* node4 = new Node(4);
root1->children = {node2, node3, node4};
cout << "测试用例1:";
vector<vector<int>> res1 = sol.levelOrder(root1);
printResult(res1);
// 树结构:
// 1
// / | \
// 3 2 4
// / \
// 5 6
Node* root2 = new Node(1);
Node* node3_2 = new Node(3);
Node* node2_2 = new Node(2);
Node* node4_2 = new Node(4);
Node* node5 = new Node(5);
Node* node6 = new Node(6);
node3_2->children = {node5, node6};
root2->children = {node3_2, node2_2, node4_2};
cout << "测试用例2:";
vector<vector<int>> res2 = sol.levelOrder(root2);
printResult(res2);
Node* root3 = nullptr;
cout << "测试用例3:";
vector<vector<int>> res3 = sol.levelOrder(root3);
printResult(res3);
return 0;
}
8.二叉树的锯齿形层序遍历--队列+宽搜(BFS)(OJ题)
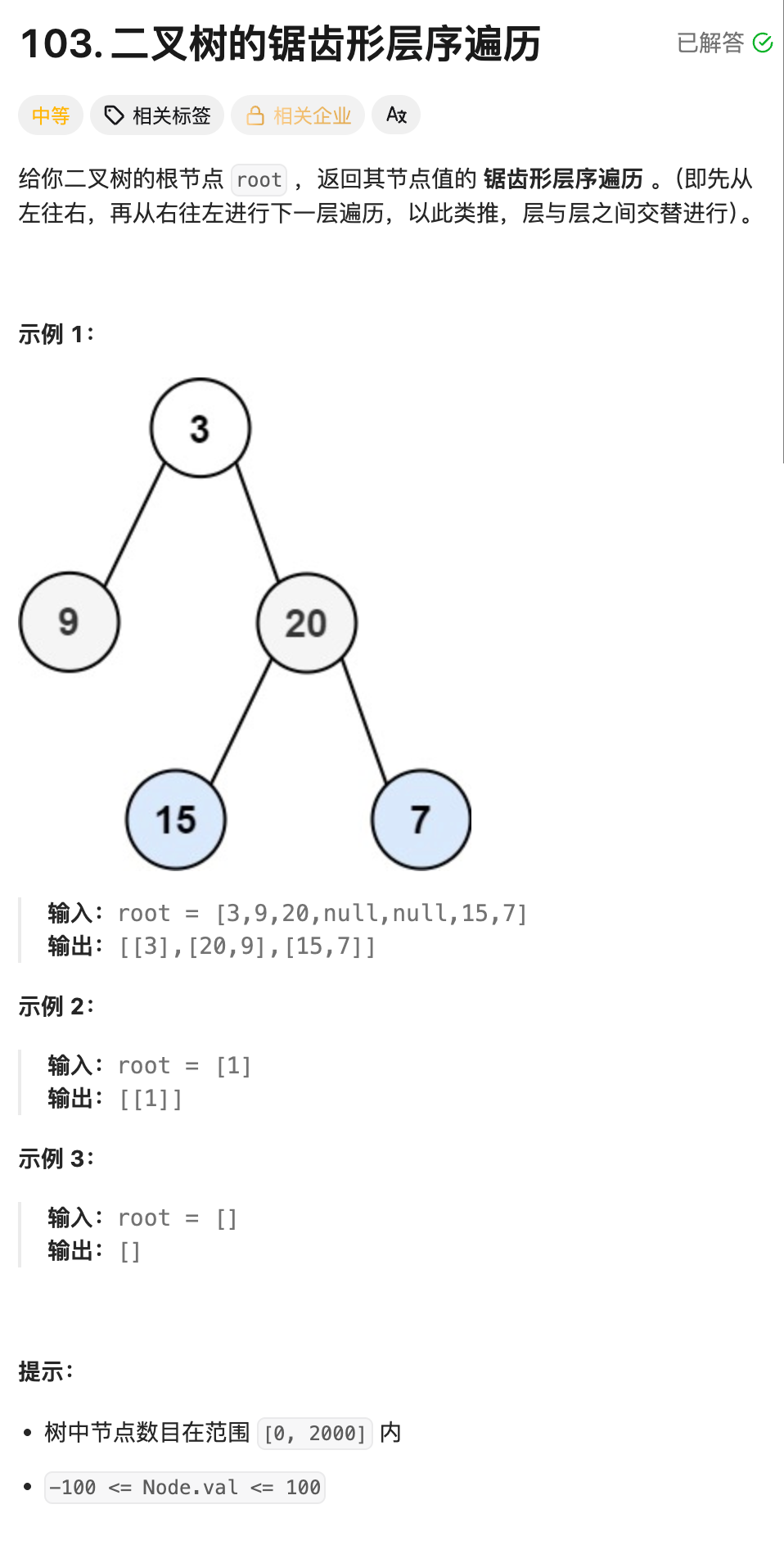
算法思路:解法(层序遍历):
在正常的层序遍历过程中,我们是可以把⼀层的结点放在⼀个数组中去的.既然我们有这个数组,在合适的层数逆序就可以得到锯⻮形层序遍历的结果.
核心功能
对二叉树进行锯齿形层序遍历:
- 奇数层:从左到右输出
- 偶数层:从右到左输出
- 最终返回二维数组(每一层对应一个一维数组)
核心逻辑
- 基础框架 :用队列实现标准的二叉树层序遍历(BFS);
- 按层处理 :每次循环先记录当前层节点数量,保证只处理完本层再处理下一层;
- 锯齿效果 :用
level标记层数,偶数层反转数组,奇数层保持正序; - 结果存储:每层的节点值存入一个数组,最终合并为二维数组返回.
执行流程举例
给一个二叉树:
3
/ \
9 20
/ \
15 7遍历过程:
- 第1层(奇数,正序) :节点
3→ 数组[3] - 第2层(偶数,逆序) :节点
9,20→ 反转成[20,9] - 第3层(奇数,正序) :节点
15,7→ 数组[15,7]
最终结果:
[[3], [20,9], [15,7]]
核心代码
cpp
class Solution
{
public:
//函数功能:锯齿形层序遍历二叉树,返回二维数组
//参数:root 二叉树根节点
vector<vector<int>> zigzagLevelOrder(TreeNode* root)
{
vector<vector<int>> ret; //存储最终结果(二维数组:每层一个数组)
if (root == nullptr) //边界条件:空树直接返回空结果
return ret;
queue<TreeNode*> q; //队列:BFS核心工具,存储待遍历的节点
q.push(root); //根节点入队,开始遍历
int level = 1; //标记当前层数:初始为第1层(奇数层,正序)
//外层循环:遍历每一层(队列不为空 = 还有节点未处理)
while (q.size())
{
int sz = q.size(); //固定当前层的节点总数
//必须先存下来!子节点入队会改变队列大小
vector<int> tmp; //临时数组:存储当前层的节点值
//内层循环:处理当前层的所有 sz 个节点
for (int i = 0; i < sz; i++)
{
auto t = q.front();//取出队首节点(当前要处理的节点)
q.pop(); //节点出队
tmp.push_back(t->val); //把节点值加入临时数组
//子节点入队(先左后右,保证层序顺序)
if (t->left)
q.push(t->left);
if (t->right)
q.push(t->right);
}
//核心逻辑:偶数层反转数组,实现锯齿形
if (level % 2 == 0)
reverse(tmp.begin(), tmp.end()); //反转临时数组
ret.push_back(tmp); //当前层处理完成,加入最终结果
level++; //层数+1,处理下一层
}
return ret; //返回最终结果
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
#include <queue>
#include <algorithm>
using namespace std;
//1.定义二叉树节点结构
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode() : val(0), left(nullptr), right(nullptr) {}
TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
};
class Solution
{
public:
vector<vector<int>> zigzagLevelOrder(TreeNode* root)
{
vector<vector<int>> ret;
if (root == nullptr)
return ret;
queue<TreeNode*> q;
q.push(root);
int level = 1;
while (q.size())
{
int sz = q.size();
vector<int> tmp;
for (int i = 0; i < sz; i++)
{
auto t = q.front();
q.pop();
tmp.push_back(t->val);
if (t->left)
q.push(t->left);
if (t->right)
q.push(t->right);
}
//偶数层反转,实现锯齿效果
if (level % 2 == 0)
reverse(tmp.begin(), tmp.end());
ret.push_back(tmp);
level++;
}
return ret;
}
};
void printResult(vector<vector<int>>& res) {
cout << "锯齿形层序遍历结果:[";
for (int i = 0; i < res.size(); ++i) {
cout << "[";
for (int j = 0; j < res[i].size(); ++j) {
cout << res[i][j];
if (j != res[i].size() - 1) cout << ",";
}
cout << "]";
if (i != res.size() - 1) cout << ",";
}
cout << "]" << endl << endl;
}
int main() {
Solution sol;
// 树结构:
// 3
// / \
// 9 20
// / \
// 15 7
TreeNode* root1 = new TreeNode(3);
root1->left = new TreeNode(9);
root1->right = new TreeNode(20);
root1->right->left = new TreeNode(15);
root1->right->right = new TreeNode(7);
cout << "测试用例1:";
vector<vector<int>> res1 = sol.zigzagLevelOrder(root1);
printResult(res1);
TreeNode* root2 = nullptr;
cout << "测试用例2:";
vector<vector<int>> res2 = sol.zigzagLevelOrder(root2);
printResult(res2);
TreeNode* root3 = new TreeNode(1);
cout << "测试用例3:";
vector<vector<int>> res3 = sol.zigzagLevelOrder(root3);
printResult(res3);
// 树结构:
// 1
// / \
// 2 3
TreeNode* root4 = new TreeNode(1);
root4->left = new TreeNode(2);
root4->right = new TreeNode(3);
cout << "测试用例4:";
vector<vector<int>> res4 = sol.zigzagLevelOrder(root4);
printResult(res4);
return 0;
}
9.二叉树最大宽度--队列+宽搜(BFS)(OJ题)
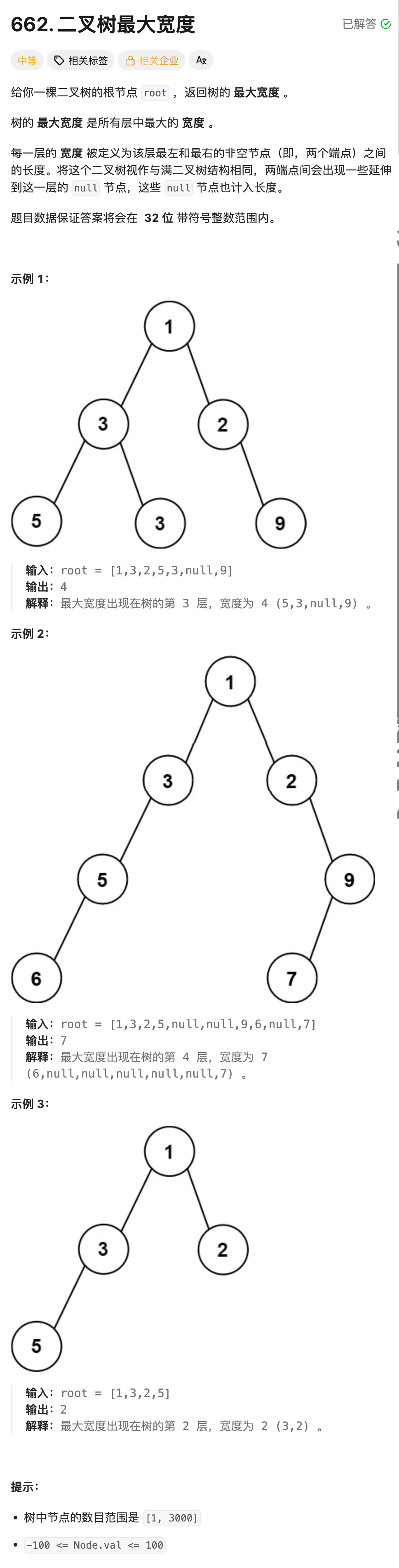
算法思路:解法(层序遍历):
- 第一种思路(会超过内存限制):
既然统计每一层的最大宽度,我们优先想到的就是利用层序遍历,把当前层的结点全部存在队列里面,利用队列的长度来计算每一层的宽度,统计出最大的宽度.
但是,由于空节点也是需要计算在内的.因此,我们可以选择将空节点也存在队列里面.
这个思路是我们正常会想到的思路,但是极端境况下,最左边一条长链,最右边一条长链,我们需要存几亿个空节点,会超过最大内存限制.
- 第二种思路(利用二叉树的顺序存储 - 通过根节点的下标,计算左右孩子的下标):
依旧是利用层序遍历,但是这一次队列里面不单单存结点信息,并且还存储当前结点如果在数组中存储所对应的下标(学习数据结构 - 堆的时候,计算左右孩子的方式).
这样我们计算每一层宽度的时候,无需考虑空节点,只需将当层结点的左右结点的下标相减再加1即可.
但是,这里有个细节问题:如果二叉树的层数非常恐怖的话,我们任何一种数据类型都不能存下下标的值.但是没有问题,因为
- 我们数据的存储是一个环形的结构;
- 并且题目说明,数据的范围在
int这个类型的最大值的范围之内,因此不会超出一圈; - 因此,如果是求差值的话,我们无需考虑溢出的情况.
·核心功能·
计算二叉树的最大宽度 :
二叉树每一层的宽度 = 该层最左侧非空节点 到 最右侧非空节点 之间的节点数量(包含中间的空节点);代码返回所有层中最大的宽度值.
完全二叉树编号规则(关键!)
根节点编号 = 1
任意节点编号 = y
→ 左孩子编号 = y * 2
→ 右孩子编号 = y * 2 + 1
宽度计算公式
当前层宽度 = 最右节点编号 - 最左节点编号 + 1
极简执行流程
测试用例二叉树:
1(1)
/ \
3(2) 2(3)
/ \ \
5(4) 3(5) 9(7)编号规则:根1,左2,右3 → 孙节点4、5、6、7
- 第一层:节点
1(1)→ 宽度1-1+1=1 - 第二层:节点
3(2)、2(3)→ 宽度3-2+1=2 - 第三层:节点
5(4)、3(5)、9(7)→ 宽度7-4+1=4 - 最大宽度 =
4
核心代码
cpp
class Solution
{
public:
//函数功能:计算二叉树最大宽度
//参数:root 二叉树根节点
//返回值:最大宽度值
int widthOfBinaryTree(TreeNode* root)
{
//1.定义队列:用vector模拟队列
//存储 节点指针 + 节点编号(unsigned int 防止编号溢出)
vector<pair<TreeNode*, unsigned int>> q;
//初始化队列:根节点入队,编号为1
q.push_back({root, 1});
//2.记录最终结果:最大宽度
unsigned int ret = 0;
//3.层序遍历循环:队列不为空,说明还有节点未处理
while (q.size())
{
//步骤1:计算当前层的宽度
//结构化绑定(C++17):取出当前层 第一个节点(最左) 和 最后一个节点(最右)
auto& [x1, y1] = q[0]; // x1=节点,y1=最左节点编号
auto& [x2, y2] = q.back();// x2=节点,y2=最右节点编号
//更新最大宽度:用当前层宽度 和 历史最大值比较
ret = max(ret, y2 - y1 + 1);
//步骤2:构建下一层节点队列
//临时队列:存储下一层的 节点+编号
vector<pair<TreeNode*, unsigned int>> tmp;
//遍历当前层所有节点
for (auto& [x, y] : q)
{
//如果左孩子非空,入队,编号=2*y
if (x->left)
tmp.push_back({x->left, y * 2});
//如果右孩子非空,入队,编号=2*y+1
if (x->right)
tmp.push_back({x->right, y * 2 + 1});
}
//队列更新为下一层,继续循环
q = tmp;
}
//遍历完成,返回最大宽度
return ret;
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
//定义二叉树节点结构
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode() : val(0), left(nullptr), right(nullptr) {}
TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
};
class Solution
{
public:
int widthOfBinaryTree(TreeNode* root)
{
//数组模拟队列:存储节点 + 节点编号(无符号整型防止溢出)
vector<pair<TreeNode*, unsigned int>> q;
q.push_back({root, 1});
unsigned int ret = 0;
while (q.size())
{
//结构化绑定:获取当前层最左、最右节点的编号
auto& [x1, y1] = q[0];
auto& [x2, y2] = q.back();
// 更新最大宽度:最右编号 - 最左编号 + 1
ret = max(ret, y2 - y1 + 1);
//构建下一层节点队列
vector<pair<TreeNode*, unsigned int>> tmp;
for (auto& [x, y] : q)
{
//左孩子编号:2*y
if (x->left)
tmp.push_back({x->left, y * 2});
//右孩子编号:2*y+1
if (x->right)
tmp.push_back({x->right, y * 2 + 1});
}
//迭代到下一层
q = tmp;
}
return ret;
}
};
int main() {
Solution sol;
// 树结构:
// 1
// / \
// 3 2
// / \ \
// 5 3 9
//最大宽度:4
TreeNode* root1 = new TreeNode(1);
root1->left = new TreeNode(3);
root1->right = new TreeNode(2);
root1->left->left = new TreeNode(5);
root1->left->right = new TreeNode(3);
root1->right->right = new TreeNode(9);
cout << "测试用例1 最大宽度:" << sol.widthOfBinaryTree(root1) << endl;
// 树结构:
// 1
// /
// 3
// / \
// 5 3
// 最大宽度:2
TreeNode* root2 = new TreeNode(1);
root2->left = new TreeNode(3);
root2->left->left = new TreeNode(5);
root2->left->right = new TreeNode(3);
cout << "测试用例2 最大宽度:" << sol.widthOfBinaryTree(root2) << endl;
TreeNode* root3 = new TreeNode(1);
cout << "测试用例3 最大宽度:" << sol.widthOfBinaryTree(root3) << endl;
return 0;
}
10.在每个树行中找最大值--队列+宽搜(BFS)(OJ题)
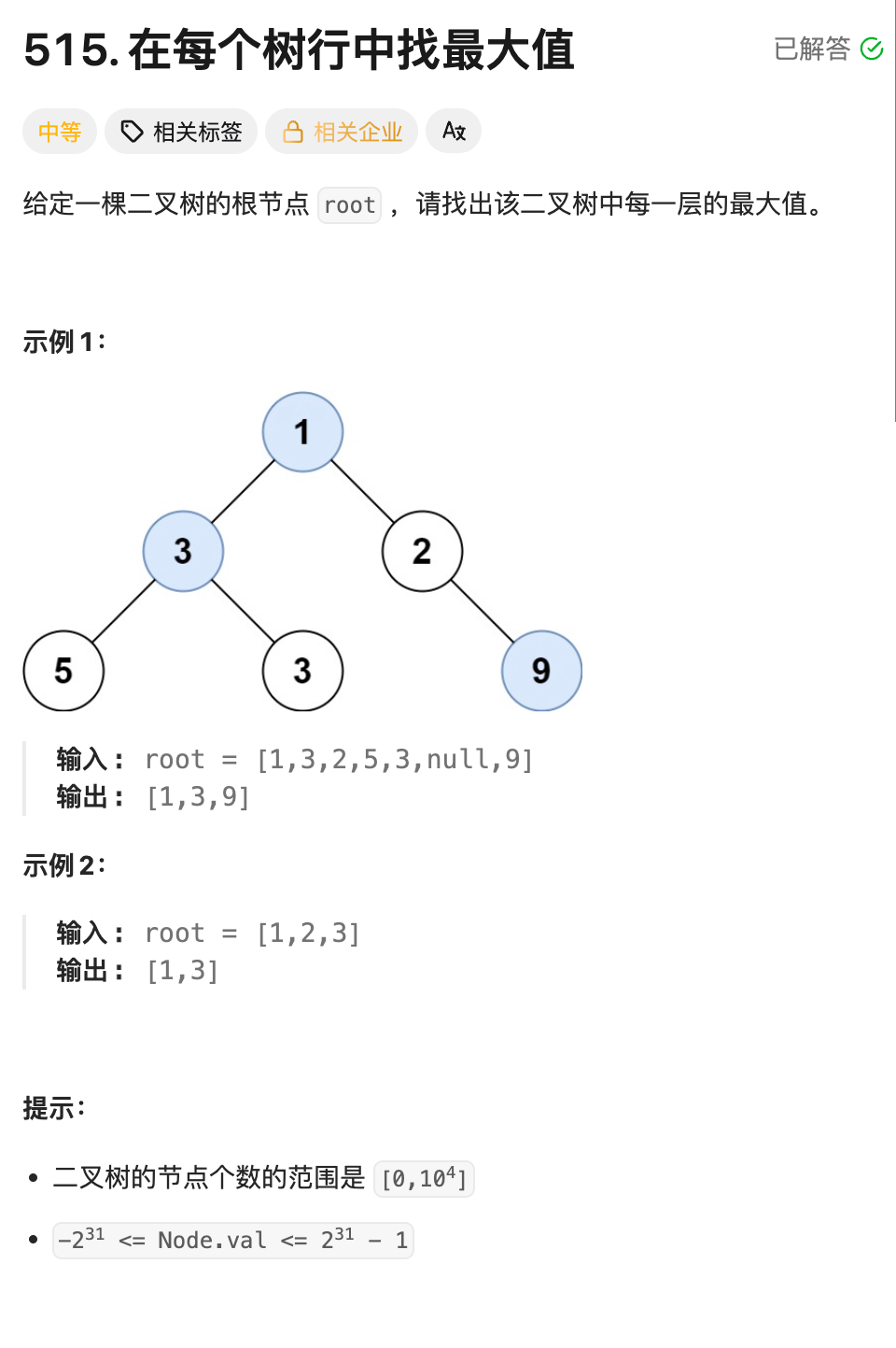
算法思路:解法(bfs):
层序遍历过程中,在执⾏让下⼀层节点⼊队的时候,我们是可以在循环中统计出当前层结点的最⼤值
的.因此,可以在bfs的过程中,统计出每⼀层结点的最⼤值.
核心功能
对二叉树进行层序遍历 ,找到每一层的最大节点值,最终返回一个数组,数组中的每个元素对应二叉树每一层的最大值.
极简执行流程
二叉树结构:
1
/ \
3 2
/ \ \
5 3 9遍历过程:
- 第一层 :节点
1→ 最大值1 - 第二层 :节点
3、2→ 最大值3 - 第三层 :节点
5、3、9→ 最大值9
最终结果:[1, 3, 9]
核心代码
cpp
class Solution
{
public:
//函数功能:找到二叉树每一层的最大值
//参数:root -> 二叉树根节点
//返回值:vector<int> -> 存储每一层最大值的数组
vector<int> largestValues(TreeNode* root)
{
vector<int> ret; //1.定义结果数组,存储每一层的最大值
if (root == nullptr) //2.边界条件:空树直接返回空数组
return ret;
queue<TreeNode*> q; //3.定义队列,层序遍历核心工具(先进先出)
q.push(root); //4.根节点入队,开始遍历
//5.外层循环:遍历每一层(队列不为空 = 还有节点未处理)
while (q.size())
{
int sz = q.size(); //6.关键:固定当前层的节点总数
//必须先保存,子节点入队会改变队列大小
int tmp = INT_MIN; //7.初始化当前层最大值为【整数最小值】
//保证任何节点值都能比它大
//8.内层循环:处理当前层的所有sz个节点
for (int i = 0; i < sz; i++)
{
auto t = q.front();//取出队首节点(当前要处理的节点)
q.pop(); //节点出队
//9.更新当前层最大值:比较已有最大值和当前节点值
tmp = max(tmp, t->val);
//10.子节点入队(为下一层遍历做准备)
if (t->left)
q.push(t->left);
if (t->right)
q.push(t->right);
}
//11.当前层遍历完成,把最大值加入结果数组
ret.push_back(tmp);
}
//12.所有层处理完毕,返回结果
return ret;
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
#include <queue>
#include <algorithm>
using namespace std;
//定义二叉树节点结构体
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode() : val(0), left(nullptr), right(nullptr) {}
TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
};
class Solution
{
public:
vector<int> largestValues(TreeNode* root)
{
vector<int> ret;
if (root == nullptr)
return ret;
queue<TreeNode*> q;
q.push(root);
while (q.size())
{
int sz = q.size();
int tmp = INT_MIN;
for (int i = 0; i < sz; i++)
{
auto t = q.front();
q.pop();
tmp = max(tmp, t->val);
if (t->left)
q.push(t->left);
if (t->right)
q.push(t->right);
}
ret.push_back(tmp);
}
return ret;
}
};
void printResult(vector<int>& res) {
cout << "二叉树每层最大值:[";
for (int i = 0; i < res.size(); ++i) {
cout << res[i];
if (i != res.size() - 1) cout << ", ";
}
cout << "]" << endl << endl;
}
int main() {
Solution sol;
// 树结构:
// 1
// / \
// 3 2
// / \ \
// 5 3 9
// 预期结果:[1, 3, 9]
TreeNode* root1 = new TreeNode(1);
root1->left = new TreeNode(3);
root1->right = new TreeNode(2);
root1->left->left = new TreeNode(5);
root1->left->right = new TreeNode(3);
root1->right->right = new TreeNode(9);
cout << "测试用例1:";
vector<int> res1 = sol.largestValues(root1);
printResult(res1);
TreeNode* root2 = nullptr;
cout << "测试用例2:";
vector<int> res2 = sol.largestValues(root2);
printResult(res2);
TreeNode* root3 = new TreeNode(10);
cout << "测试用例3:";
vector<int> res3 = sol.largestValues(root3);
printResult(res3);
// 树结构:1 -> 2 -> 3
// 预期结果:[1, 2, 3]
TreeNode* root4 = new TreeNode(1);
root4->left = new TreeNode(2);
root4->left->left = new TreeNode(3);
cout << "测试用例4:";
vector<int> res4 = sol.largestValues(root4);
printResult(res4);
return 0;
}
11.最后一块石头的重量--优先级队列(OJ题)

算法思路:解法(利用堆):
其实就是一个模拟的过程:
- 每次从石堆中拿出最大的元素以及次大的元素,然后将它们粉碎;
- 如果还有剩余,就将剩余的石头继续放在原始的石堆里面
重复上面的操作,直到石堆里面只剩下一个元素,或者没有元素(因为所有的石头可能全部抵消了)
那么主要的问题就是解决:
- 如何顺利的拿出最大的石头以及次大的石头;
- 并且将粉碎后的石头放入石堆中之后,也能快速找到下一轮粉碎的最大石头和次大石头;
这不正好可以利用堆的特性来实现嘛?
- 我们可以创建一个大根堆;
- 然后将所有的石头放入大根堆中;
- 每次拿出前两个堆顶元素粉碎一下,如果还有剩余,就将剩余的石头继续放入堆中;
这样就能快速的模拟出这个过程.
核心代码
cpp
class Solution
{
public:
int lastStoneWeight(vector<int>& stones)
{
//1.创建⼀个⼤根堆
priority_queue<int> heap;
//2.将所有元素丢进这个堆⾥⾯
for (auto x : stones)
heap.push(x);
//3.模拟这个过程
while (heap.size() > 1)
{
int a = heap.top();
heap.pop();
int b = heap.top();
heap.pop();
if (a > b)
heap.push(a - b);
}
return heap.size() ? heap.top() : 0;
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
#include <queue>
using namespace std;
class Solution
{
public:
int lastStoneWeight(vector<int>& stones)
{
//1.创建⼀个⼤根堆(C++默认priority_queue就是大根堆)
priority_queue<int> heap;
//2.将所有元素丢进这个堆⾥⾯
for (auto x : stones)
heap.push(x);
//3.模拟粉碎过程
while (heap.size() > 1)
{
//取出最重的两块石头
int a = heap.top();
heap.pop();
int b = heap.top();
heap.pop();
//重量不等,将剩余重量放回堆中
if (a > b)
heap.push(a - b);
}
//剩余石头重量,无剩余返回0
return heap.size() ? heap.top() : 0;
}
};
int main() {
Solution sol;
vector<int> stones1 = {2,7,4,1,8,1};
cout << "测试用例1 结果:" << sol.lastStoneWeight(stones1) << endl;
vector<int> stones2 = {2,2};
cout << "测试用例2 结果:" << sol.lastStoneWeight(stones2) << endl;
vector<int> stones3 = {5};
cout << "测试用例3 结果:" << sol.lastStoneWeight(stones3) << endl;
return 0;
}
12.数据流中的第k大元素--优先级队列(OJ题)

算法思路:解法(优先级队列):
我相信,看到 TopK 问题的时候,大家应该能⽴⻢想到堆,这应该是刻在⻣⼦⾥的记忆.
📌Top-K问题全面解析
Top-K问题是算法面试、数据处理中的经典高频题 ,核心需求是:从N个元素中,找出最大/最小的K个元素,或第K大/第K小的元素 .
核心解法1:堆(优先队列)法(面试首选,通用场景)
🔍 原理
- 找前K大元素 :用大小为K的小根堆
- 遍历所有N个元素,依次入堆;
- 堆大小超过K时,弹出堆顶(当前堆中最小的元素);
- 最终堆中剩余的K个元素,就是全局最大的K个元素,堆顶为第K大元素.
- 找前K小元素 :用大小为K的大根堆,逻辑完全对称.
⏱️ 复杂度
- 时间复杂度:
O(N log K)(每次堆操作O(log K),共N次) - 空间复杂度:
O(K)(仅存K个元素,适合大数据量/流式数据)
核心解法2:快速选择(QuickSelect)法(静态数组最优,平均O(N))
🔍 原理
基于快速排序的分治思想,通过基准划分快速定位第K大元素:
- 随机选择基准
pivot,将数组划分为大于pivot 等于pivot 小于pivot三部分; - 根据大于pivot的元素个数
cnt,递归缩小搜索范围:cnt >= k:第K大在大于pivot区间;cnt + 等于pivot的个数 >= k:pivot就是第K大;- 否则:在小于pivot区间搜索,更新
k = k - cnt - 等于pivot的个数.
⏱️ 复杂度
- 平均时间复杂度:
O(N)(总操作≈2N) - 最坏时间复杂度:
O(N²)(可通过随机基准优化) - 空间复杂度:
O(log N)(递归栈)
其他解法(适合特定场景)
- 全排序法(极简,小数据量)
- 原理:对数组全排序后取前K个
- 时间复杂度:
O(N log N),仅适合N极小的场景
- 桶排序/计数排序(数据范围小的整数)
- 原理:用桶统计每个值的出现次数,从大到小遍历桶,累计到K个元素
- 时间复杂度:
O(N + M)(M为数据范围) - 适用场景:数据范围小,如年龄、分数等
解法对比表
| 解法 | 时间复杂度 | 空间复杂度 | 适用场景 | 核心优势 | 局限性 |
|---|---|---|---|---|---|
| 小根堆法 | O(N log K) | O(K) | 大数据量、流式数据、动态数据 | 内存占用小、支持实时更新 | 略慢于快速选择的平均时间 |
| 快速选择法 | 平均O(N) | O(log N) | 静态数组、找第K大 | 平均时间最优 | 最坏O(N²)、不支持流式数据 |
| 全排序法 | O(N log N) | O(1) | 小数据量 | 代码极简 | 大数据量效率极低 |
| 桶排序法 | O(N + M) | O(M) | 数据范围小的整数 | 线性时间 | 数据范围大时不可用 |
核心代码
cpp
class KthLargest
{
//创建⼀个⼤⼩为 k 的⼩跟堆
priority_queue<int, vector<int>, greater<int>> heap;
int _k;
public:
KthLargest(int k, vector<int>& nums)
{
_k = k;
for (auto x : nums)
{
heap.push(x);
if (heap.size() > _k)
heap.pop();
}
}
int add(int val)
{
heap.push(val);
if (heap.size() > _k)
heap.pop();
return heap.top();
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
#include <queue>
using namespace std;
class KthLargest
{
//创建⼀个⼤⼩为 k 的小根堆
priority_queue<int, vector<int>, greater<int>> heap;
int _k; // 保存k值
public:
//构造函数:初始化堆
KthLargest(int k, vector<int>& nums)
{
_k = k;
for (auto x : nums)
{
heap.push(x);
//堆大小超过k,弹出堆顶(最小元素)
if (heap.size() > _k)
heap.pop();
}
}
//添加新元素,并返回当前第K大元素
int add(int val)
{
heap.push(val);
if (heap.size() > _k)
heap.pop();
// 堆顶即为第K大元素
return heap.top();
}
};
int main() {
vector<int> nums = {4,5,8,2};
KthLargest obj(3, nums);
cout << "添加元素3,第3大元素:" << obj.add(3) << endl; // 预期:4
cout << "添加元素5,第3大元素:" << obj.add(5) << endl; // 预期:5
cout << "添加元素10,第3大元素:" << obj.add(10) << endl; // 预期:5
cout << "添加元素9,第3大元素:" << obj.add(9) << endl; // 预期:8
cout << "添加元素8,第3大元素:" << obj.add(8) << endl; // 预期:8
return 0;
}
13.前k个高频单词--优先级队列(OJ题)

算法思路:解法(堆):
-
稍微处理一下原数组:
(1)我们需要知道每一个单词出现的频次,因此可以先使用哈希表,统计出每一个单词出现的频次;
(2)然后在哈希表中,选出前 k 大的单词(为什么不在原数组中选呢?因为原数组中存在重复的单词,哈希表里面没有重复单词,并且还有每一个单词出现的频次)
-
如何使用堆,拿出前 k 大元素:
(1)先定义一个自定义排序,我们需要的是前 k 大,因此需要一个小根堆.但是当两个字符串的频次相同的时候,我们需要的是字典序较小的,此时是一个大根堆的属性,在定义比较器的时候需要注意!当两个字符串出现的频次不同的时候:需要的是基于频次比较的小根堆;当两个字符串出现的频次相同的时候:需要的是基于字典序比较的大根堆
(2)定义好比较器之后,依次将哈希表中的字符串插入到堆中,维持堆中的元素不超过 k 个;
(3)遍历完整个哈希表后,堆中的剩余元素就是前 k 大的元素
代码核心功能
给定一个单词数组,返回出现频率前 K 高的单词:
- 频率越高,排名越靠前;
- 若频率相同 ,按字典序从小到大排列;
- 最终按要求返回前 K 个单词.
执行流程举例
输入:words = ["i","love","leetcode","i","love","coding"], k = 2
- 哈希统计频次:
i:2, love:2, leetcode:1, coding:1 - 入堆,维护大小为2:
堆中保留:love(2), i(2) - 逆序取出:
["i", "love"]
核心代码
cpp
class Solution
{
//1.类型别名:简化 pair<string, int> 为 PSI
//表示:<单词字符串, 出现频次>
typedef pair<string, int> PSI;
//2.自定义堆的比较规则
struct cmp {
//重载小括号运算符,给优先队列指定排序规则
bool operator()(const PSI& a, const PSI& b)
{
if (a.second == b.second)
{
//情况1:频次相同 → 字典序**大**的排前面(大根堆)
//保证最终输出时,字典序小的在结果数组前面
return a.first < b.first;
}
//情况2:频次不同 → 频次**小**的排前面(小根堆)
return a.second > b.second;
}
};
public:
vector<string> topKFrequent(vector<string>& words, int k)
{
//3.哈希表:统计每个单词出现的频次(去重+计数)
unordered_map<string, int> hash;
for (auto& s : words)
hash[s]++; //单词 s 出现次数 +1
//4.创建优先队列(堆)
//模板参数:元素类型PSI + 底层容器vector + 自定义比较器cmp
priority_queue<PSI, vector<PSI>, cmp> heap;
//5.Top-K 核心逻辑:维护大小为 k 的小根堆
for (auto& psi : hash)
{
heap.push(psi); //元素入堆
if (heap.size() > k) //堆大小超过 k,弹出堆顶(最小的元素)
heap.pop();
}
//6.提取结果:堆顶是第K大元素,需要逆序存入结果数组
vector<string> ret(k);
for (int i = k - 1; i >= 0; i--)
{
ret[i] = heap.top().first; //取出单词
heap.pop(); //弹出堆顶
}
return ret; //返回最终结果
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
#include <unordered_map>
#include <queue>
#include <string>
using namespace std;
class Solution
{
typedef pair<string, int> PSI;
//自定义堆的比较规则
struct cmp {
bool operator()(const PSI& a, const PSI& b)
{
if (a.second == b.second) //频次相同,字典序大的优先(大根堆)
{
return a.first < b.first;
}
return a.second > b.second; //频次不同,频次小的优先(小根堆)
}
};
public:
vector<string> topKFrequent(vector<string>& words, int k)
{
//1.哈希表统计单词频次
unordered_map<string, int> hash;
for (auto& s : words)
hash[s]++;
//2.创建自定义规则的小根堆
priority_queue<PSI, vector<PSI>, cmp> heap;
//3.Top-K核心逻辑:维护堆大小为k
for (auto& psi : hash)
{
heap.push(psi);
if (heap.size() > k)
heap.pop();
}
//4.逆序提取结果
vector<string> ret(k);
for (int i = k - 1; i >= 0; i--)
{
ret[i] = heap.top().first;
heap.pop();
}
return ret;
}
};
void printResult(const vector<string>& res) {
cout << "前K个高频单词:[";
for (int i = 0; i < res.size(); ++i) {
cout << "\"" << res[i] << "\"";
if (i != res.size() - 1) cout << ", ";
}
cout << "]" << endl << endl;
}
int main() {
Solution sol;
// 输入:words = ["i","love","leetcode","i","love","coding"], k = 2
// 输出:["i","love"]
vector<string> words1 = {"i","love","leetcode","i","love","coding"};
int k1 = 2;
cout << "测试用例1:";
vector<string> res1 = sol.topKFrequent(words1, k1);
printResult(res1);
// 输入:words = ["the","day","is","sunny","the","the","the","sunny","is","is"], k = 4
// 输出:["the","is","sunny","day"]
vector<string> words2 = {"the","day","is","sunny","the","the","the","sunny","is","is"};
int k2 = 4;
cout << "测试用例2:";
vector<string> res2 = sol.topKFrequent(words2, k2);
printResult(res2);
vector<string> words3 = {"hello"};
int k3 = 1;
cout << "测试用例3:";
vector<string> res3 = sol.topKFrequent(words3, k3);
printResult(res3);
vector<string> words4 = {"a","b","c","a","b","c"};
int k4 = 2;
cout << "测试用例4:";
vector<string> res4 = sol.topKFrequent(words4, k4);
printResult(res4);
return 0;
}
14.数据流的中位数--优先级队列(OJ题)

算法思路:解法(利用两个堆):
这是一道关于堆这种数据结构的一个经典应用.
我们可以将整个数组按照大小平分成两部分(如果不能平分,那就让较小部分的元素多一个),较小的部分称为左侧部分,较大的部分称为右侧部分:
- 将左侧部分放入大根堆 中,然后将右侧元素放入小根堆中;
- 这样就能在O(1) 的时间内拿到中间的一个数或者两个数,进而求得平均数.
如下图所示:
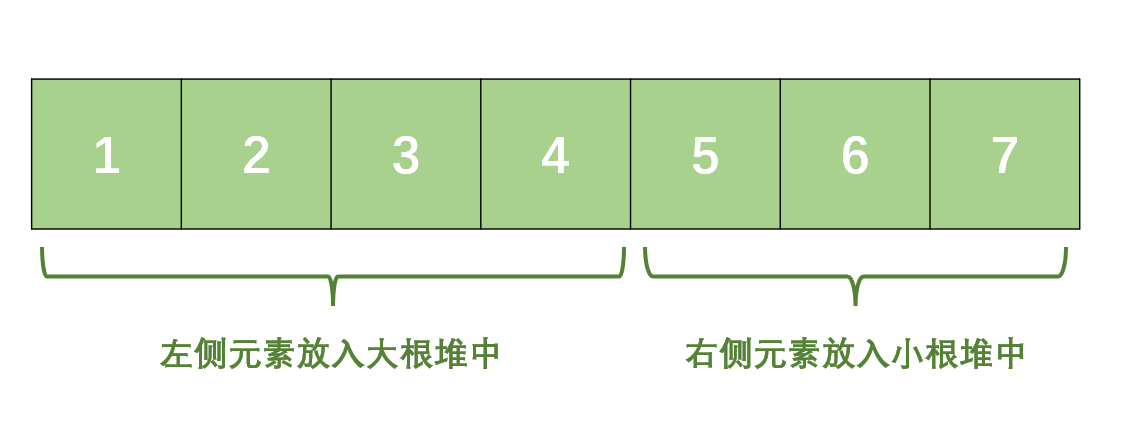
于是问题变成了如何将一个从数据流中过来的数据,动态调整到大根堆或者小根堆中,并且保证两个堆的元素一致,或者左侧堆的元素比右侧堆的元素多一个 .
为了方便叙述,将左侧的大根堆记为 left,右侧的小根堆记为 right,数据流中来的数据记为 x.
其实就是一个分类讨论的过程:
-
如果左右堆的数量相同,即
left.size() == right.size():- 如果两个堆都是空的,直接将数据
x放入到left中; - 如果两个堆非空:
- 如果元素要放入左侧,也就是
x <= left.top():那就直接放,因为不会影响我们制定的规则; - 如果要放入右侧:
- 可以先将
x放入right中, - 然后把
right的堆顶元素放入left中;
- 可以先将
- 如果元素要放入左侧,也就是
- 如果两个堆都是空的,直接将数据
-
如果左右堆的数量不相同,即
left.size() > right.size():- 这个时候我们关心的是
x是否会放入left中,导致left变得过多:- 如果
x放入right中,也就是x >= right.top(),直接放; - 反之,就是需要放入
left中:- 可以先将
x放入left中, - 然后把
left的堆顶元素放入right中;
- 可以先将
- 如果
- 这个时候我们关心的是
只要每一个新来的元素按照上述规则 执行,就能保证 left 中放着整个数组排序后的左半部分,right 中放着整个数组排序后的右半部分,就能在O(1) 的时间内求出平均数.
核心代码
cpp
class MedianFinder {
// 成员变量:两个堆
priority_queue<int> left; //大根堆(默认):存较小的一半数
priority_queue<int, vector<int>, greater<int>> right; //小根堆:存较大的一半数
public:
//构造函数:初始化对象,无需额外操作
MedianFinder() {}
//核心函数:添加数据流中的数字
void addNum(int num) {
//分类讨论:根据两个堆的大小关系,决定数字放哪里
if (left.size() == right.size()) //情况1:左右堆元素个数相同
{
//堆为空 或 新数字 ≤ 左堆最大值 → 直接放左堆
if (left.empty() || num <= left.top())
{
left.push(num);
}
else //新数字更大,应该放右堆,但要保证左堆多1个
{
right.push(num); //先放右堆
left.push(right.top()); //把右堆最小值挪到左堆
right.pop(); //右堆删除该元素
}
}
else //情况2:左堆比右堆多1个元素(唯一的不等情况)
{
if (num <= left.top()) // 新数字要放左堆,会导致失衡
{
left.push(num); //先放左堆
right.push(left.top());//把左堆最大值挪到右堆
left.pop(); //左堆删除该元素
}
else //新数字直接放右堆,保持平衡
{
right.push(num);
}
}
}
//获取中位数
double findMedian() {
if (left.size() == right.size()) //总元素个数:偶数
return (left.top() + right.top()) / 2.0 ; //两个堆顶取平均
else // 总元素个数:奇数,左堆多一个,堆顶就是中位数
return left.top();
}
};完整测试代码
cpp
#include <iostream>
#include <queue>
using namespace std;
class MedianFinder {
priority_queue<int> left; //大根堆:存储较小的一半数据
priority_queue<int, vector<int>, greater<int>> right; //小根堆:存储较大的一半数据
public:
MedianFinder() {}
void addNum(int num) {
//分类讨论维护两个堆的平衡
if (left.size() == right.size()) //左右堆元素个数相同
{
if (left.empty() || num <= left.top()) //直接放入左堆
{
left.push(num);
} else { //先放右堆,再将右堆堆顶移到左堆
right.push(num);
left.push(right.top());
right.pop();
}
} else { //左堆元素比右堆多1个
if (num <= left.top()) { //先放左堆,再将左堆堆顶移到右堆
left.push(num);
right.push(left.top());
left.pop();
} else { //直接放入右堆
right.push(num);
}
}
}
double findMedian() {
//元素总数为偶数:两个堆顶取平均
if (left.size() == right.size())
return (left.top() + right.top()) / 2.0;
//元素总数为奇数:左堆堆顶就是中位数
else
return left.top();
}
};
int main() {
cout << "===== 测试用例1 =====" << endl;
MedianFinder mf1;
mf1.addNum(1);
cout << "添加元素1,当前中位数:" << mf1.findMedian() << endl;
mf1.addNum(2);
cout << "添加元素2,当前中位数:" << mf1.findMedian() << endl;
mf1.addNum(3);
cout << "添加元素3,当前中位数:" << mf1.findMedian() << endl;
cout << endl;
cout << "===== 测试用例2 =====" << endl;
MedianFinder mf2;
mf2.addNum(5);
mf2.addNum(1);
mf2.addNum(3);
mf2.addNum(7);
cout << "元素:5,1,3,7,中位数:" << mf2.findMedian() << endl;
cout << endl;
cout << "===== 测试用例3 =====" << endl;
MedianFinder mf3;
mf3.addNum(10);
cout << "单个元素10,中位数:" << mf3.findMedian() << endl;
cout << endl;
cout << "===== 测试用例4 =====" << endl;
MedianFinder mf4;
mf4.addNum(0);
mf4.addNum(1);
mf4.addNum(2);
mf4.addNum(4);
mf4.addNum(5);
cout << "元素:0,1,2,4,5,中位数:" << mf4.findMedian() << endl;
return 0;
}

🚀真正的勇者不是流泪的人,而是含泪奔跑的人!
敬请期待下一篇文章内容:【优选算法】(实战攻坚BFS之FloodFill、最短路径问题、多源BFS以及解决拓扑排序)
每日心灵鸡汤:相遇的意义在于彼此照亮,而不是"物是人非事事休,欲语泪先流!"
我们总以为相识一个人,就必须要有一个结果.直到后来才明白,有些人光是遇见,就已经是上上签.朋友也好,爱人也罢,他们都是上天赋予我们生命的珍贵礼物,陪伴一程,温暖一段,拥有过便已值得感念.所以,不必纠结他能否陪你走到最后.这世间,有些人的出现,本就是为了陪你走过一段短暂却美好的时光.即便日后形同陌路,也无需正式告别,更不必遗憾.因为"前世不欠,今生不见",我大大方方地为自己的选择买单,也要我的人生始终热烈,真诚而坦荡.山鸟与鱼不同路,从此山水不相逢,这才是常态.重要的不是结局,而是那些熠熠生辉的瞬间------那些被你改变的部分的我,将代替你,永远留在我生命里.不是每件事都要有结果,不是每段路都必须同行.只要在相遇时,我们曾真心相待,彼此照亮,那段回忆就足以在往后的黯淡时刻,兀自闪耀,成为前行的光.愿你相信:总有一场相遇,是隔着茫茫人海,为奔赴彼此而来,它不一定有结局,但一定有意义.物是人非事事休,欲语泪先流.我时常想,人与人的羁绊为何如此短暂,明明昨天还分享琐碎的日常,今天却默契的不说话,这或许就是人们常说的阶段性陪伴,我常常羡慕那些以年为单位的陪伴,每当有断联的旧人再次联系上我时,我总是庆幸,终于能够说话的人但在互不联系的日子里,或许对方已经忘记了过去的太多过往,长达一年甚至两年的断联重新呈现,人和人真是奇怪,明明那么多个夜晚,聊到凌晨时彼此袒露心迹但在某一天突然变成了不会联系的陌生人,抱怨人生路上不应该遇见的人,下雨坐在窗边回忆过去,其实好坏我都舍不得.所以珍惜眼前人,走好每一段旅途!
