文章目录
前言
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
一、什么是神经网络?
人工神经网络( Artificial Neural Network, 简写为ANN)也简称为神经网络(NN),是一种模仿生物神经网络结
构和功能的计算模型。人脑可以看做是一个生物神经网络,由众多的神经元连接而成。各个神经元传递复杂的电信号
,树突接收到输入信号,然后对信号进行处理,通过轴突输出信号
二、什么是激活函数?
激活函数用于对每层的输出数据进行变换, 进而为整个网络注入了非线性因素。此时, 神经网络就可以
拟合各种曲线。
简言之:
没有激活函数 = 你只能用直尺画图
有激活函数 = 你可以用手随便画波浪、折线、乱七八糟的形状
激活函数就是那个让直线变弯的开关。




通俗易懂的讲故事版本:
咱们今天要干一件事:造一台能帮人干活的人造大脑机器,从拆零件到组装,再到调试,最后拿它去帮小明解决他的手机定价难题,一步一步来,多一句没有,少一句不行。
第一步:先搞懂最小的零件------人造神经元
首先,这台机器最小的零件,就是模仿人脑造的人造神经元 。
人脑的神经元咋干活?树突收一堆信号,加吧加吧凑够了电位,就激活了,给下一个神经元发信号。
咱人造的也一样:把一堆输入信息,每个信息给个权重(就是这个信息重不重要),加起来,然后过个"激活开关"------还记得咱们之前说的不?没有这个开关,所有的计算都是直的,只能画直线,啥复杂活都干不了;有了这个开关,就能给结果"掰弯",啥乱七八糟的曲线都能拟合。
单个神经元不够用啊,咱得把一堆神经元凑起来,拼成一个完整的网络:
- 最前面的是输入层:就相当于工厂的收货口,把原始数据(比如手机的内存、像素这些)收进来,每个特征对应一个收货窗口。
- 中间的是隐藏层:这就是工厂的加工车间,一层一层的工人,上一层的工人把加工完的货传给下一层,每个工人拿到货,先把所有输入加吧加吧算出个内部值(就是z),然后用激活开关掰弯一下,得到输出值(就是a),传给下一波工人。
- 最后面的是输出层:就是打包发货的,给你最终的结果------比如这个手机属于哪个价格档。
第二步:掰弯的花样------激活函数选哪个?
说到这个"掰弯"的激活开关,花样可多了,不是随便掰的,不同的掰法效果天差地别:
- Sigmoid:最早的掰法,把所有数都压到0到1之间,但是它有毛病:太极端的数,比如输入100和10000,压完之后都差不多是1,信息直接丢了;而且它的梯度太小了,网络超过5层,后面的参数就改不动了,传话传着传着就没声了,这叫"梯度消失"。所以现在基本不用它,除非是二分类的最后输出层,刚好要0到1的概率。
- Tanh:比Sigmoid好点,把数压到-1到1之间,以0为中心,梯度也大一点,但是还是没解决梯度消失的毛病,两边极端值还是传不动信号。
- ReLU:现在最常用的!太简单了,负的输入直接扔了,变成0,正的输入原封不动给你。算的贼快,而且正的地方梯度永远是1,不会消失,深网络也能训。但是它也有毛病:有的输入一直是负的,这个神经元从此以后就再也不输出东西了,相当于废了,这叫"神经元死亡"。
- Softmax:这个是专门给多分类用的,比如你要分4个价格档,它能把网络输出的一堆数,变成加起来等于1的概率,谁的概率大,就选谁当结果。
最后给你个口诀,别瞎选:
- 隐藏层:优先用ReLU,不行再试别的,少用Sigmoid
- 输出层:二分类用Sigmoid,多分类用Softmax,回归预测数就直接输出
第三步:零件刚买来,怎么摆?------参数初始化
零件都齐了,刚组装机器的时候,这些权重参数不能瞎放,也不能全放0------全放0的话,所有神经元都长的一模一样,白搭,等于一个神经元用了一万遍。
所以就有了各种摆法:
- 简单的:均匀随便摆、正态随机摆,浅层网络够用了
- 深层的:得匹配激活函数来:
- 如果你用Sigmoid、Tanh,就用Xavier初始化,保证数据传的时候方差不变,不会越传越炸或者越传越小
- 如果你用ReLU,就用Kaiming初始化,专门给ReLU量身定做的,刚好匹配它的特性
第四步:攒成完整的机器------搭网络
零件摆好了,就可以把这些层攒成一个完整的网络了,用PyTorch的话贼简单:
继承个父类,在初始化里把你要的层都定义好------比如第一层接输入,第二层接第一层的输出,最后输出层出结果;然后写个forward函数,告诉数据:你进来之后,先走第一层,过ReLU,再走第二层,再过ReLU,最后走输出层,就完事了。
搭完还能算一下,你这台机器有多少参数------就是每个神经元的w和b加起来,比如3个输入3个输出的层,就有3*3+3=12个参数,这就是你机器的大小。
第五步:怎么知道机器干的好不好?------损失函数
机器造好了,怎么知道它干活准不准?得有个打分的,就是损失函数,预测错了,就扣你分,错的越多扣的越多。
不同的活,打分的方式不一样:
- 分类活:比如分价格档,多分类就用交叉熵损失,二分类就用二分类的交叉熵,就是看你预测的概率和真实的差多少。
- 回归活:比如预测具体的价格,就看你预测和真实差多少:MAE是差多少算多少,MSE是差的平方,大错罚的更狠,Smooth L1是把俩结合起来,解决了MAE不平滑、MSE容易梯度爆炸的毛病。
第六步:错了怎么改?------优化算法
知道错了,就得改参数,让损失越来越小,这就是优化,核心就是梯度下降:往损失变小最快的方向走,就像下山,找最陡的路往下走。
这里先给你讲三个基础概念:
- Epoch:所有训练数据完整过一遍,叫一轮,相当于你把所有题做了一遍
- Batch:一次拿多少题来做,一次做一批,改一次参数
- Iter:每做一批题,改一次参数,这就叫一次迭代
然后改的时候,是从后往前改的,这叫反向传播:先算最后输出错了多少,然后往前推,每个参数错了多少,挨个改,就像你考试完了,从最后一道题往前改错题。
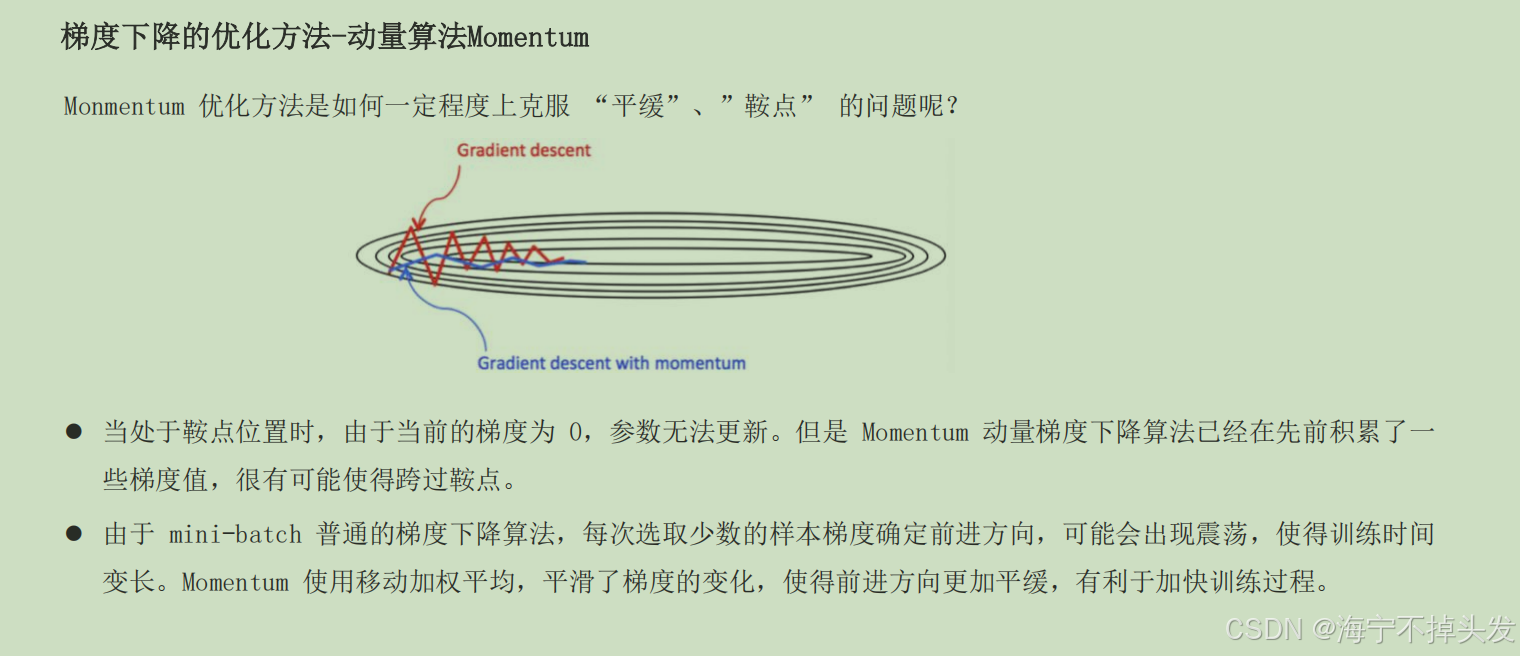
但是普通的梯度下降太慢了,还容易卡在半路上,比如走到一个平缓的地方,或者一个假的最低点(鞍点),就走不动了,所以就有了各种优化的黑科技:
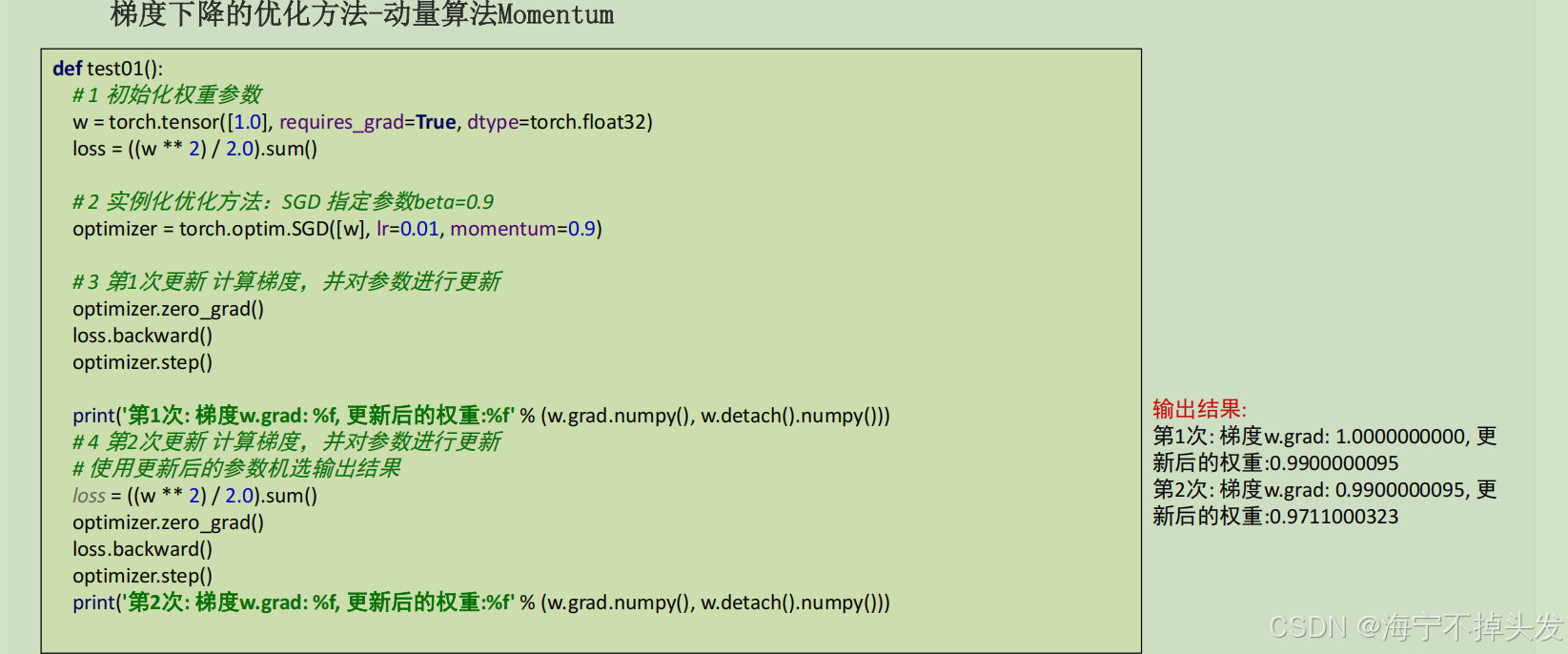
- Momentum动量:给你加个惯性,之前走的方向带着你,就算当前梯度为0,也能靠着惯性冲过去,跨过鞍点,还能减少震荡。
- AdaGrad:给不同的参数用不同的学习率,但是它有毛病,越训学习率越小,最后就不动了。
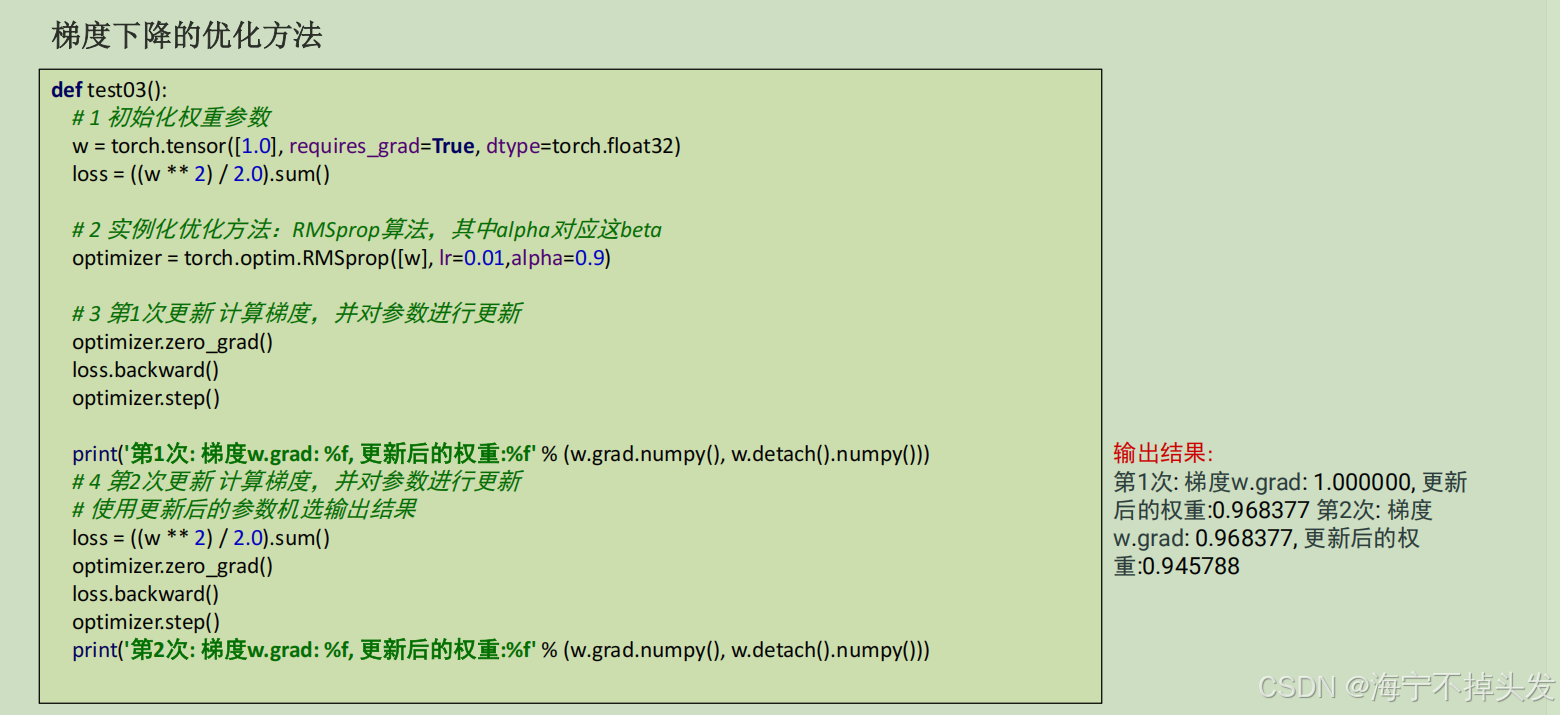
- RMSProp:把AdaGrad改了,用指数加权平均,不会让学习率降的太快。
- Adam:现在最常用的!把动量和RMSProp的优点合一块了,又有惯性,又能自适应调学习率,大部分情况用它就对了。
而且学习率也不能一直不变,一开始步幅大一点,快点走,快到山脚了,步幅就得小一点,别跨过了,这就是学习率衰减:有每隔多少轮降一次的,有到指定轮次降的,有指数慢慢降的,都是为了让你能稳稳的走到最低点。
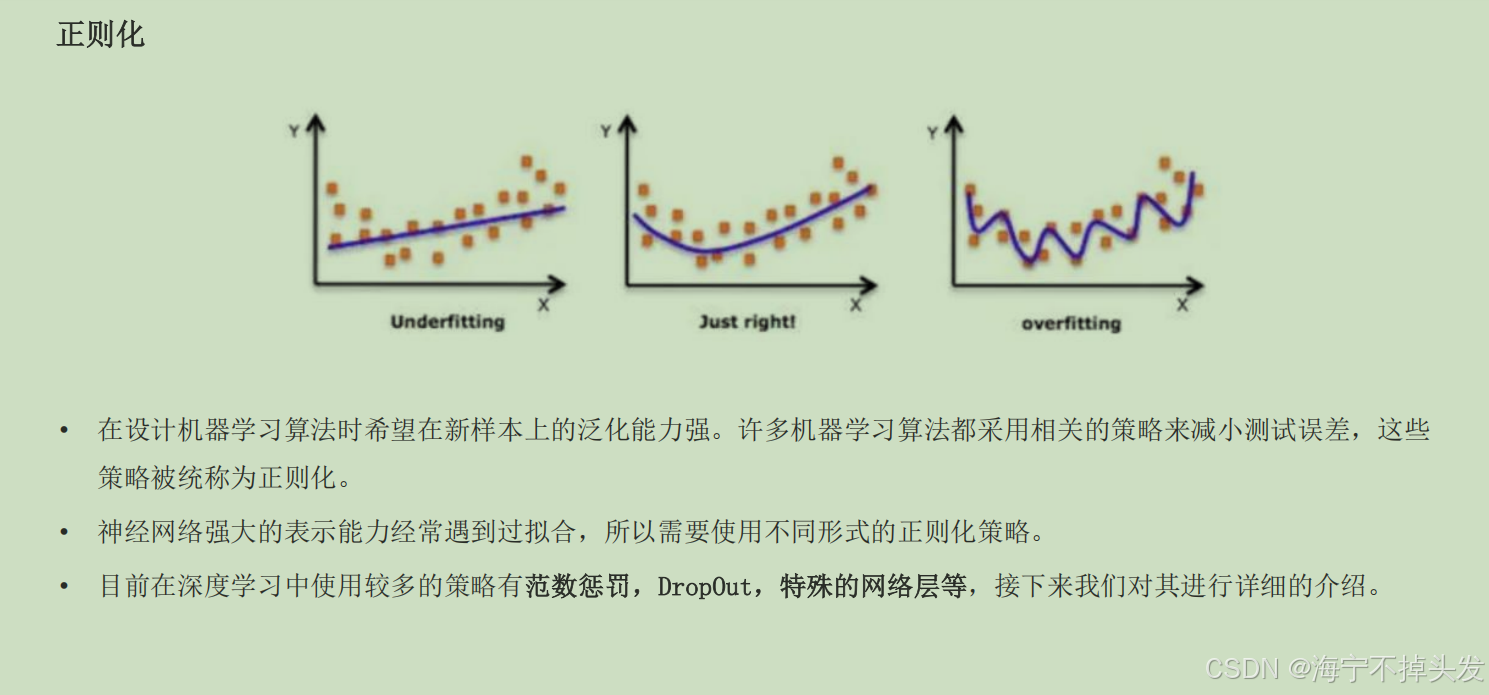
第七步:防止机器背题------正则化
训着训着你会发现,机器在训练题上背的滚瓜烂熟,考试换了新题,就不会了,这叫过拟合。
怎么治?正则化,就是防作弊:
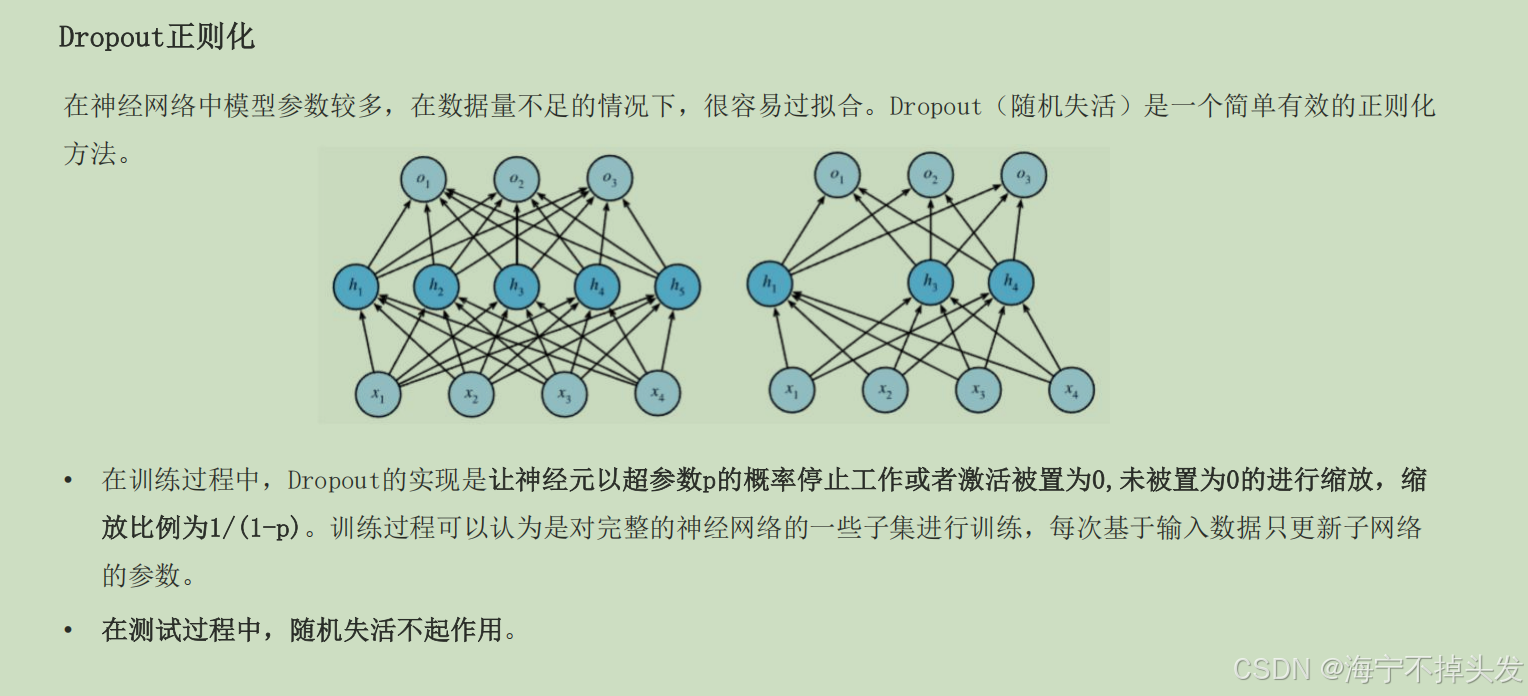
- Dropout:训练的时候,随机让一半的工人放假,不让他们太依赖彼此,不能几个工人偷偷串通好背答案,这样测试的时候所有工人都回来,泛化能力就强了。
- BN层:把每一层的数据都标准化一下,让数据不要太偏,别有的太大有的太小,这样训练的更快更稳,还能缓解过拟合。
第八步:拿这台机器去干活------帮小明定手机价
好了,所有零件、调试方法都齐了,咱们拿这台机器去帮小明解决问题!
小明开了个二手手机店,不知道该给手机定啥价,他收集了2000条手机数据,每个手机有20个特征(比如内存、像素、电池啥的),要把手机分成4个价格档,这就是个分类问题。
咱们就用前面学的所有东西,走一遍流程:
- 准备数据:把2000条数据,1600条拿来当训练题,400条拿来当考试题,转成PyTorch能用的格式。
- 搭模型:造个3层的全连接网络,输入20个特征,第一层128个神经元,第二层256个,最后输出4个价格档,都用ReLU激活。
- 训练:用交叉熵损失,SGD优化器,训了50轮,把模型存起来。
- 测试:拿考试题测了一下,准确率0.64,也就是100个手机能猜对64个。
当然,这只是个基础版,还有很大的调优空间,比如把SGD换成Adam,调小学习率,给数据做标准化,把网络搭的更深一点,还能把准确率提的更高。
你看,就这么回事,从最小的神经元零件,到攒成机器,到调试,最后拿去干活,整个一套下来,就是神经网络的全部基础了,多一句没有,少一句不行,全是最实用的东西。