数据结构(七)
参考资料:
目录
[3.1 排序](#3.1 排序)
[3.1.1 排序的定义和稳定性](#3.1.1 排序的定义和稳定性)
[3.1.2 插入排序](#3.1.2 插入排序)
[1. 直接插入排序](#1. 直接插入排序)
[2. 希尔排序](#2. 希尔排序)
[3.1.3 选择排序](#3.1.3 选择排序)
[1. 直接选择排序](#1. 直接选择排序)
[2. 堆排序](#2. 堆排序)
[3.1.4 交换排序](#3.1.4 交换排序)
[1. 冒泡排序](#1. 冒泡排序)
[2. 快速排序](#2. 快速排序)
[3.1.6 归并排序](#3.1.6 归并排序)
[3.1.7 基数排序](#3.1.7 基数排序)
[3.1.8 算法复杂性比较(必背核心表)](#3.1.8 算法复杂性比较(必背核心表))
[3.2 查找](#3.2 查找)
[3.2.1 查找的定义和平均查找长度 (ASL)](#3.2.1 查找的定义和平均查找长度 (ASL))
[3.2.2 顺序查找](#3.2.2 顺序查找)
[ASL 计算(默认等概率)](#ASL 计算(默认等概率))
[3.2.3 二分法查找 / 折半查找](#3.2.3 二分法查找 / 折半查找)
[ASL 计算](#ASL 计算)
[3.2.4 分块查找 / 索引顺序查找](#3.2.4 分块查找 / 索引顺序查找)
[ASL 计算(设 n 个元素分 b 块,每块 s 个元素,n = b * s)](#ASL 计算(设 n 个元素分 b 块,每块 s 个元素,n = b * s))
[3.2.5 散列表](#3.2.5 散列表)
[1. 定义](#1. 定义)
[2. 散列函数(构造方法)](#2. 散列函数(构造方法))
[3. 冲突处理](#3. 冲突处理)
[① 开放定址法](#① 开放定址法)
[② 拉链法 / 链地址法](#② 拉链法 / 链地址法)
[4. 探查方式](#4. 探查方式)
[散列表的 ASL 计算题模板](#散列表的 ASL 计算题模板)
[3.2.6 总结对比表](#3.2.6 总结对比表)
3.1 排序
3.1.1 排序的定义和稳定性
排序
将一组数据按关键字递增(或递减)重新排列。
稳定性
若待排序序列中存在多个关键字相同的记录,排序后这些记录的相对次序保持不变,则称该排序方法是稳定的;否则称为不稳定的。
口诀:"不稳定的大神(快、希、选、堆)"
- -稳定的:冒泡、直接插入、归并、基数
- -不稳定的:快速、希尔、选择、堆
3.1.2 插入排序
1. 直接插入排序
原理:
将待排记录按关键字大小插入到前面已排好序的子序列的适当位置。
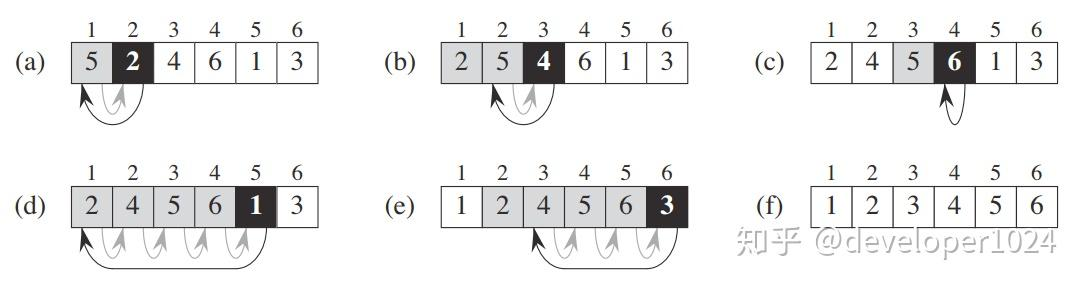
过程:
默认第一个元素有序,从第二个开始,从后往前比较,找到位置后整体后移插入。
性能:
- 时间复杂度:O(n^2) (最好 O(n),数组已有序时)
- 空间复杂度:O(1)
稳定性:稳定
适用:基本有序、数据量小的场景。
2. 希尔排序
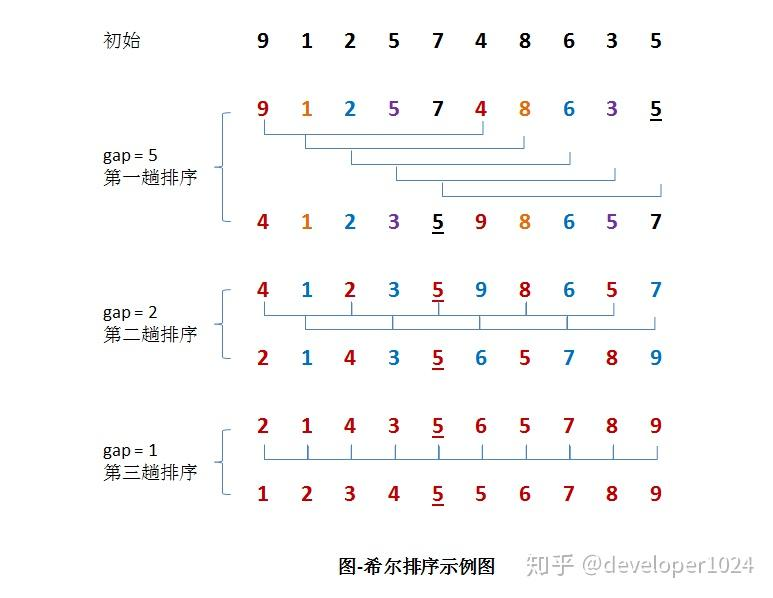
原理:
又称"缩小增量排序"。
按一定增量分组,组内进行直接插入排序,不断缩小增量直到为1。
本质:跳跃式的直接插入排序。
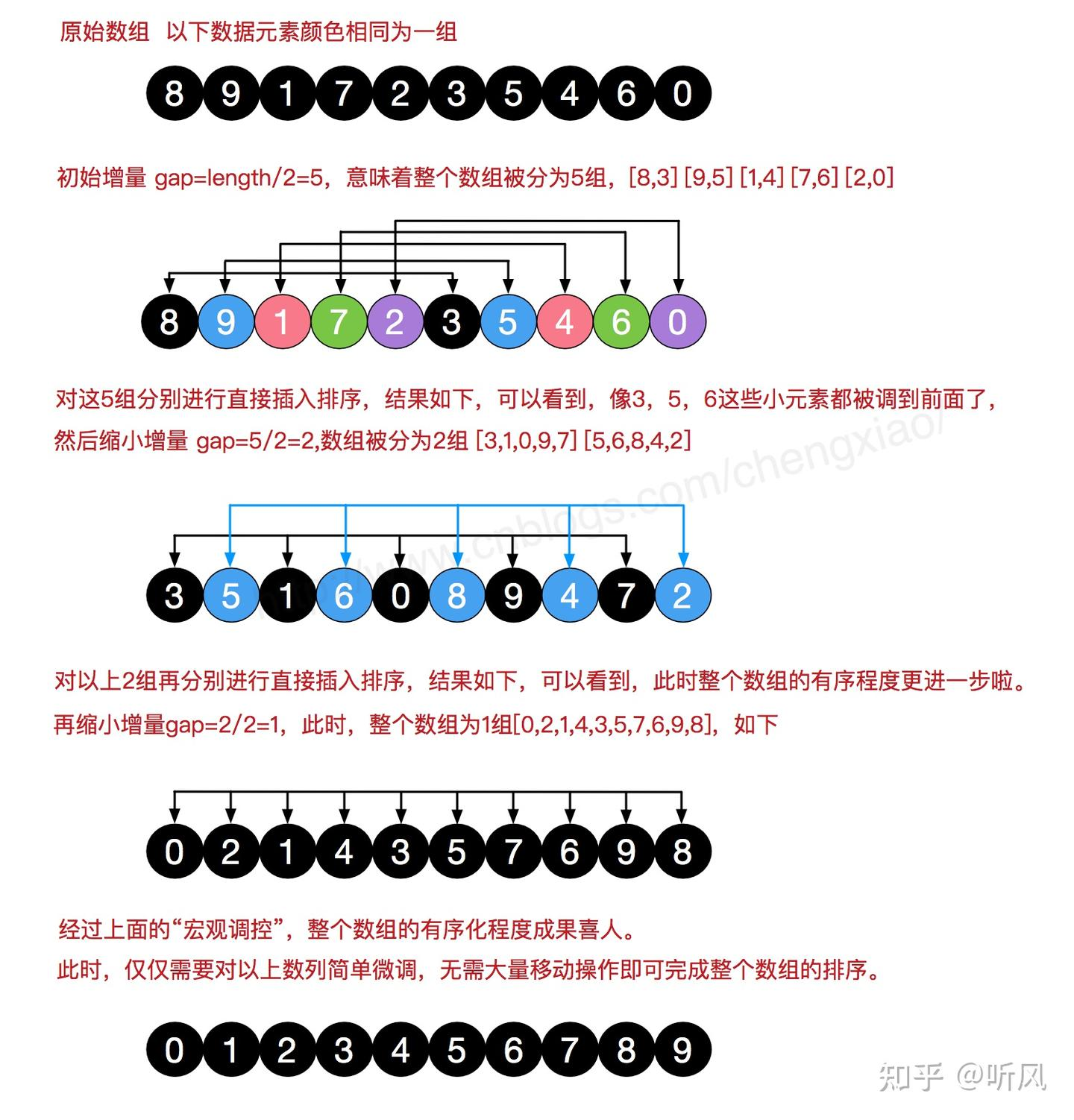
性能:
- 时间复杂度:约 O(n^{1.3}) (与增量序列有关,最坏 O(n^2))
- 空间复杂度:O(1)
稳定性:不稳定(相同元素可能被分到不同组中)
适用:中等规模数据,是对直接插入排序的优化。
3.1.3 选择排序
1. 直接选择排序
原理:
每趟从待排序列中选出最小(或最大)的元素,放在已排序列的末尾。
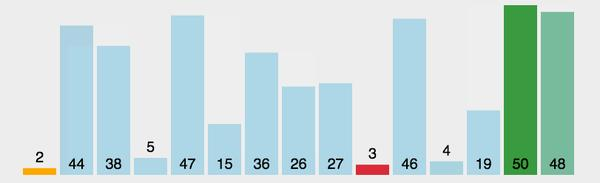

性能:
- 时间复杂度:O(n^2) (无论初始状态如何,比较次数都是 n(n-1)/2)
- 空间复杂度:O(1)
稳定性:不稳定(如 5, 5, 2,选2和第一个5交换,两个5的相对顺序破坏)
特点:移动次数少,最多 3(n-1) 次。
2. 堆排序
原理:
将数组看作完全二叉树,构建大根堆(或小根堆),堆顶为最大值(或最小值)。
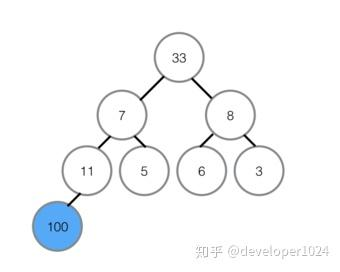
将堆顶与末尾交换,剩下的元素重新调整堆,反复执行。
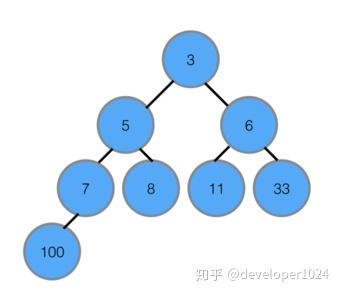
关键操作:
建堆:从最后一个非叶子节点 n/2 - 1 向上调整,O(n)。
调整堆:向下调整,O(\log n)。
性能:
- 时间复杂度:O(n \log n) (最好、最坏、平均都是)
- 空间复杂度:O(1)
稳定性:不稳定
适用:数据量大、且对内存要求严格(不需要递归栈空间)的场景。
3.1.4 交换排序
1. 冒泡排序
原理:
相邻元素两两比较,如果逆序则交换。每趟将最大(或最小)元素"冒"到末尾。

优化:
加一个标志位 flag,如果某一趟没有发生交换,说明已经有序,直接结束。
性能:
- 时间复杂度:O(n^2) (最好 O(n),优化后数组已有序时)
- 空间复杂度:O(1)
稳定性:稳定(相邻相等时不交换)
2. 快速排序
原理:
分治法。
任取一个元素作为基准,通过一趟排序将序列分为两部分(左边都小于基准,右边都大于基准),然后递归对左右子序列排序。

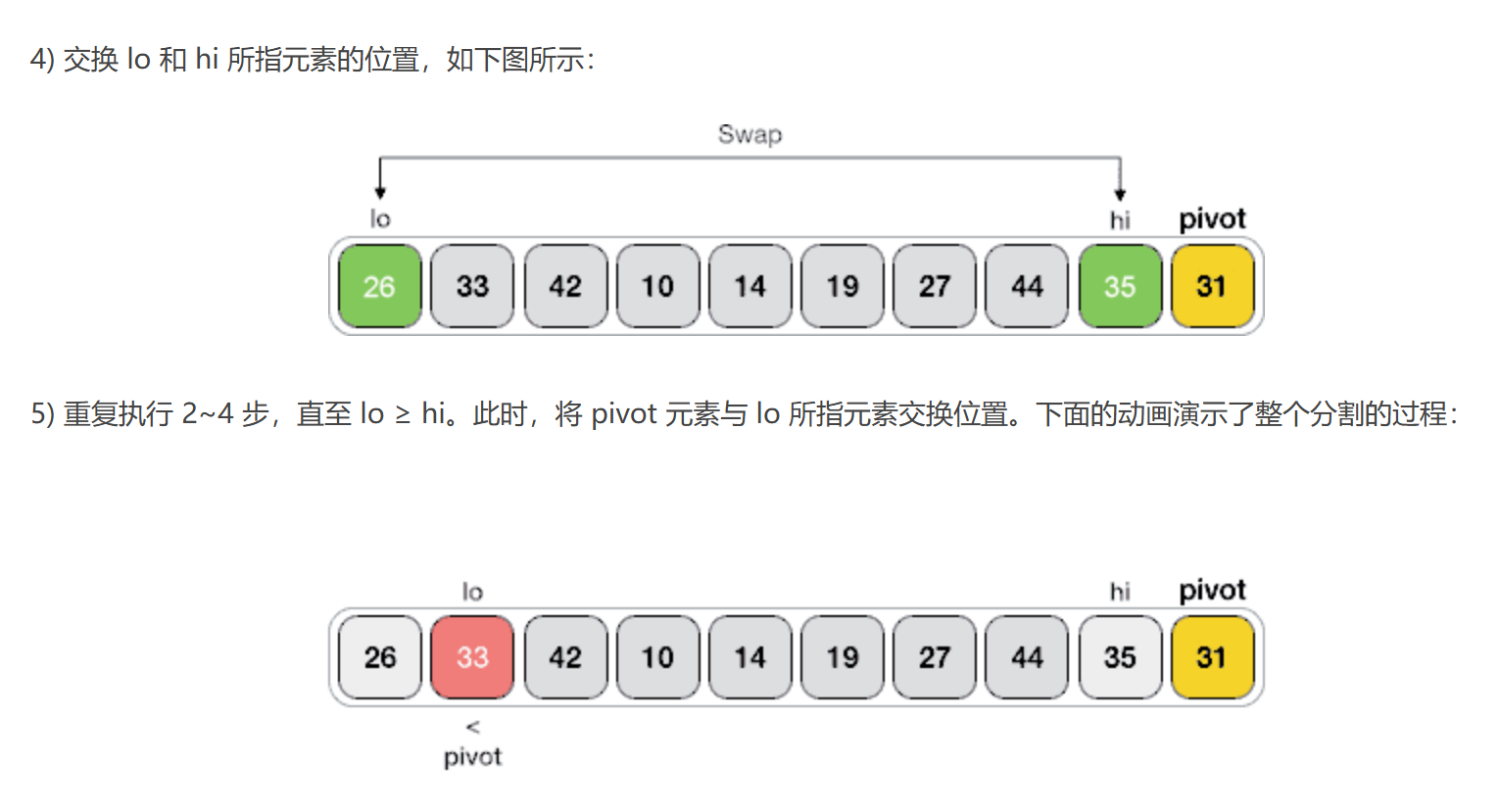
性能:
- 时间复杂度:平均 O(n \log n),最坏 O(n^2)(每次选的基准最大或最小,即数组已有序时)。
- 空间复杂度:O(\log n)(递归调用栈的深度,最坏退化为 O(n))
稳定性:不稳定
适用:目前内部排序中平均性能最高的算法。常考优化方法:随机取基准、三数取中法。
3.1.6 归并排序
原理:
分治法。
将序列递归地分成两半,分别排序,然后将两个有序子序列合并成一个有序序列。
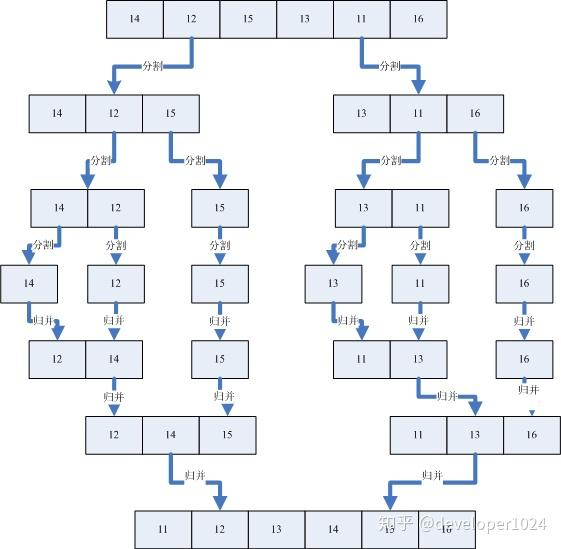
性能:
- 时间复杂度:O(n \log n) (最好、最坏、平均都是,与初始状态无关)
- 空间复杂度:O(n) (需要额外的辅助数组)
稳定性:稳定
适用:数据量大且要求稳定的场景;链表排序的首选(不需要额外空间 O(1))。
3.1.7 基数排序
原理:
非比较排序。
按关键字的各位值,从最低位(LSD)到最高位依次进行"分配"和"收集"。

(类似于扑克牌按花色和面值整理)。
性能:
- 时间复杂度:O(d(n + r)) (d是位数,n是元素个数,r是基数,如十进制 r=10)
- 空间复杂度:O(r) (需要 r 个队列/桶)
稳定性:稳定
适用:适用于字符串排序或位数不多的整数排序。
3.1.8 算法复杂性比较(必背核心表)
这是整个排序章节最重要的总结:
|----------|-----------------------|-----------------------|-----------------------------------|-----------------------------|---------|---------------------|
| 排序算法 | 平均时间 | 最好时间 | 最坏时间 | 空间复杂度 | 稳定性 | 备注 / 特点 |
| 直接插入 | O(n2) | O(n) | O (n 2) | O (1) | 稳定 | 基本有序时极快 |
| 希尔排序 | O(n1.3) | O(n) | O (n 2) | O (1) | 不稳定 | 缩小增量分组插入 |
| 直接选择 | O (n 2) | O(n2) | O (n 2) | O (1) | 不稳定 | 比较次数固定,移动少 |
| 堆排序 | O (n logn ) | O (n logn ) | O (n logn ) | O (1) | 不稳定 | 大根堆/小根堆,无最坏退化 |
| 冒泡排序 | O(n2) | O (n ) | O (n 2) | O (1) | 稳定 | 加标志位可提前结束 |
| 快速排序 | O(nlogn) | O (n logn ) | O ( n 2 ) | O (logn ) | 不稳定 | 平均最快 ,最差退化为有序 |
| 归并排序 | O (n logn ) | O (n logn ) | O (n logn ) | O ( n ) | 稳定 | 需要额外空间,无最坏退化 |
| 基数排序 | O (d (n +r )) | O (d (n +r )) | O (d (n +r )) | O (r ) | 稳定 | 不是比较排序,按位分配收集 |
易错点辨析:
- 问"哪个最快":没加条件选快排(平均 O(n\log n) 且常数小);如果有"最坏情况下也要快",选堆排或归并。
- 问"既快又稳定":选归并排序(只有归并和基数满足 O(n\log n) 且稳定)。
- 问"空间开销最小":选堆排序(同为 O(n\log n) 的快排要 O(\log n) 栈空间,归并要 O(n) 辅助空间)。
判断稳定性记忆法:
- 凡是存在跨越式交换或移动的,都不稳定。
(希尔跨组、选择跨区域、快排基准跨越、堆排父子跨越)。
- 只有相邻比较交换的(冒泡、插入)和合并的(归并、基数)才是稳定的。
python
import random
from collections import deque
# ============================================================
# 辅助:生成测试数组
# ============================================================
def make_arr(size=10, seed=42):
random.seed(seed)
return [random.randint(1, 99) for _ in range(size)]
def print_step(arr, tag=""):
print(f" {tag:>14}: {arr}")
def swap(arr, i, j):
arr[i], arr[j] = arr[j], arr[i]
# ============================================================
# 1. 直接插入排序
# ============================================================
def insert_sort(arr):
"""
从第2个元素起,将其插入到前方已排好序的子序列的正确位置
时间: O(n²) 空间: O(1) 稳定
"""
a = arr[:]
n = len(a)
for i in range(1, n):
temp = a[i]
j = i - 1
while j >= 0 and a[j] > temp: # 后移腾位
a[j + 1] = a[j]
j -= 1
a[j + 1] = temp
return a
# ============================================================
# 2. 希尔排序(缩小增量排序)
# ============================================================
def shell_sort(arr):
"""
按增量 gap 分组,组内直接插入排序;gap 逐次缩小直到 1
时间: ~O(n^1.3) 空间: O(1) 不稳定
"""
a = arr[:]
n = len(a)
gap = n // 2
while gap > 0:
for i in range(gap, n):
temp = a[i]
j = i - gap
while j >= 0 and a[j] > temp:
a[j + gap] = a[j]
j -= gap
a[j + gap] = temp
gap //= 2
return a
# ============================================================
# 3. 直接选择排序
# ============================================================
def select_sort(arr):
"""
每趟从待排区间选出最小值,放到已排区间末尾
时间: O(n²) 空间: O(1) 不稳定
"""
a = arr[:]
n = len(a)
for i in range(n - 1):
min_idx = i
for j in range(i + 1, n):
if a[j] < a[min_idx]:
min_idx = j
if min_idx != i:
swap(a, i, min_idx)
return a
# ============================================================
# 4. 堆排序
# ============================================================
def heap_sort(arr):
"""
建大根堆 → 堆顶(最大值)与末尾交换 → 调整堆 → 重复
时间: O(n log n) 空间: O(1) 不稳定
"""
a = arr[:]
n = len(a)
def sift_down(size, root):
"""将 root 为根的子树调整为大根堆"""
largest = root
left = 2 * root + 1
right = 2 * root + 2
if left < size and a[left] > a[largest]:
largest = left
if right < size and a[right] > a[largest]:
largest = right
if largest != root:
swap(a, root, largest)
sift_down(size, largest)
# 建堆:从最后一个非叶子节点向上调整
for i in range(n // 2 - 1, -1, -1):
sift_down(n, i)
# 排序:每次把堆顶最大值交换到末尾,缩小堆
for end in range(n - 1, 0, -1):
swap(a, 0, end)
sift_down(end, 0)
return a
# ============================================================
# 5. 冒泡排序
# ============================================================
def bubble_sort(arr):
"""
相邻元素两两比较,逆序则交换,每趟把最大值"冒"到末尾
时间: O(n²) 空间: O(1) 稳定
"""
a = arr[:]
n = len(a)
for i in range(n - 1):
swapped = False
for j in range(0, n - 1 - i):
if a[j] > a[j + 1]:
swap(a, j, j + 1)
swapped = True
if not swapped: # 本趟无交换 → 已有序,提前结束
break
return a
# ============================================================
# 6. 快速排序
# ============================================================
def quick_sort(arr):
"""
取基准 pivot,将序列分为 < pivot 和 > pivot 两部分,递归排序
时间: 平均 O(n log n),最坏 O(n²) 空间: O(log n) 不稳定
"""
a = arr[:]
def _quick(lo, hi):
if lo >= hi:
return
pivot = a[hi] # 选最右为基准
i = lo # i 指向"小于区"的下一个位置
for j in range(lo, hi):
if a[j] < pivot:
swap(a, i, j)
i += 1
swap(a, i, hi) # 基准归位
_quick(lo, i - 1)
_quick(i + 1, hi)
_quick(0, len(a) - 1)
return a
# ============================================================
# 7. 归并排序
# ============================================================
def merge_sort(arr):
"""
递归拆分为两半 → 分别排序 → 合并两个有序子序列
时间: O(n log n) 空间: O(n) 稳定
"""
a = arr[:]
def _merge(left, right):
"""合并两个有序列表"""
res = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]: # <= 保证稳定
res.append(left[i]); i += 1
else:
res.append(right[j]); j += 1
res.extend(left[i:])
res.extend(right[j:])
return res
if len(a) <= 1:
return a
mid = len(a) // 2
return _merge(merge_sort(a[:mid]), merge_sort(a[mid:]))
# ============================================================
# 8. 基数排序(LSD 最低位优先)
# ============================================================
def radix_sort(arr):
"""
按个位、十位、百位...依次进行"分配-收集"
时间: O(d(n+r)) 空间: O(n+r) 稳定
"""
if not arr:
return arr
a = [x for x in arr] # 复制
max_val = max(a)
exp = 1 # 当前位(个位=1, 十位=10, ...)
while max_val // exp > 0:
# 10 个桶 (0~9)
buckets = [[] for _ in range(10)]
# 分配
for num in a:
digit = (num // exp) % 10
buckets[digit].append(num)
# 收集
a = [num for bucket in buckets for num in bucket]
exp *= 10
return a
# ============================================================
# 排序算法汇总测试
# ============================================================
if __name__ == "__main__":
original = make_arr()
print(f"原始数组: {original}\n")
algorithms = [
("直接插入排序", insert_sort),
("希尔排序 ", shell_sort),
("直接选择排序", select_sort),
("堆排序 ", heap_sort),
("冒泡排序 ", bubble_sort),
("快速排序 ", quick_sort),
("归并排序 ", merge_sort),
("基数排序 ", radix_sort),
]
print("=" * 35)
for name, func in algorithms:
result = func(original)
print(f" {name}: {result}")
print("=" * 35)运行结果:
*
原始数组: 82, 15, 4, 95, 36, 2, 69, 32, 54, 85
===================================
直接插入排序: 2, 4, 15, 32, 36, 54, 69, 82, 85, 95
希尔排序 : 2, 4, 15, 32, 36, 54, 69, 82, 85, 95
直接选择排序: 2, 4, 15, 32, 36, 54, 69, 82, 85, 95
堆排序 : 2, 4, 15, 32, 36, 54, 69, 82, 85, 95
冒泡排序 : 2, 4, 15, 32, 36, 54, 69, 82, 85, 95
快速排序 : 2, 4, 15, 32, 36, 54, 69, 82, 85, 95
归并排序 : 2, 4, 15, 32, 36, 54, 69, 82, 85, 95
基数排序 : 2, 4, 15, 32, 36, 54, 69, 82, 85, 95
===================================
3.2 查找
3.2.1 查找的定义和平均查找长度 (ASL)
查找
给定一个值 K,在含有 n 个元素的表中找出关键字等于 K 的记录。
平均查找长度
查找过程中,关键字比较次数的期望值。
公式:

3.2.2 顺序查找
原理
从头到尾(或从尾到头)逐个比较。
一般把哨兵设在下标 0 处,从后往前找,免去每次判断是否越界。
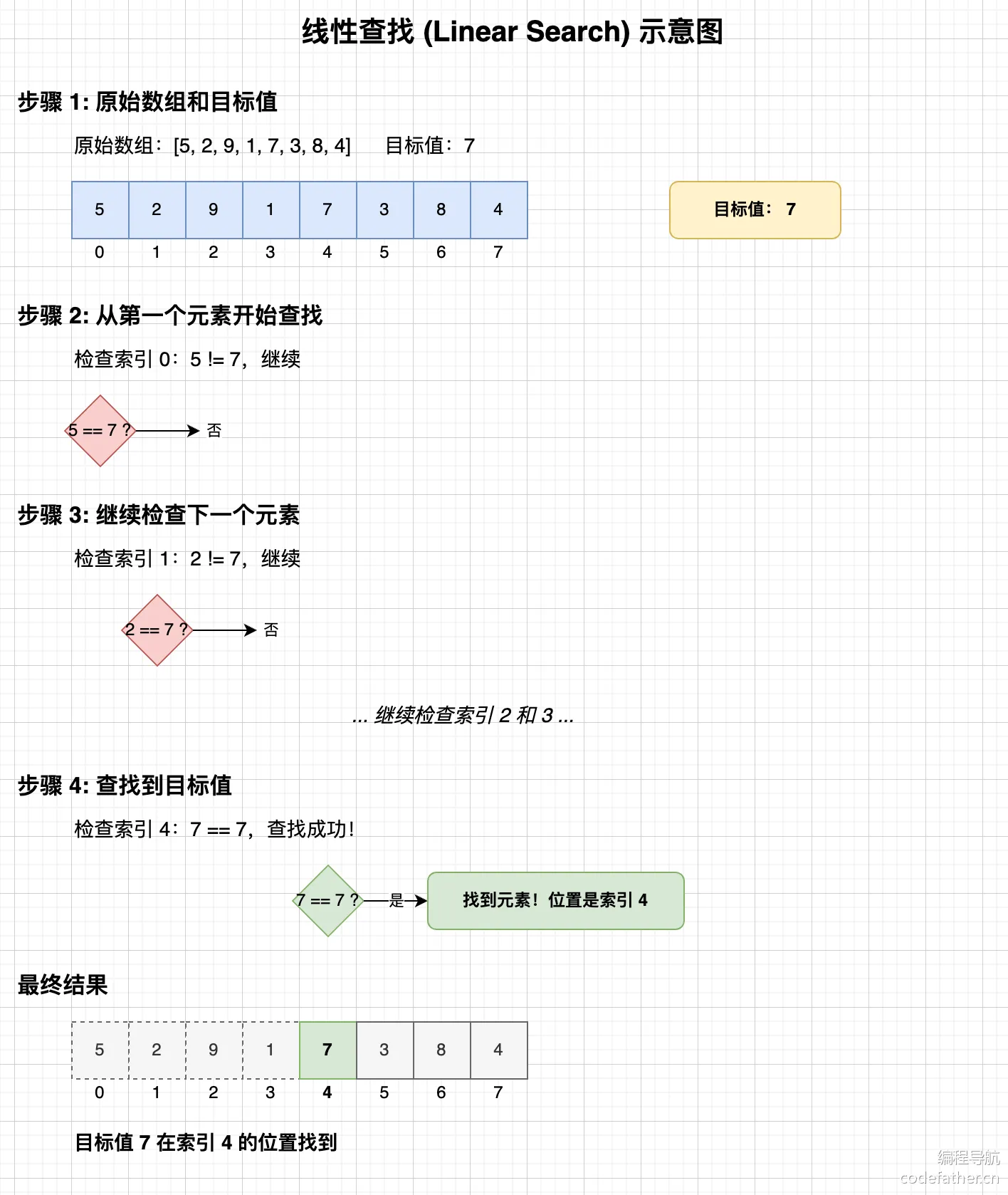
适用
无序表、线性链表。
ASL 计算(默认等概率)

3.2.3 二分法查找 / 折半查找
前提条件
线性表必须有序,且必须是顺序存储结构(数组)。
原理
取中间元素比较,相等则成功;
小于则在左半区查找;
大于则在右半区查找。

判定树
二分查找的过程可以用一棵二叉树(平衡二叉排序树)来描述。
查找成功时的比较次数 = 目标结点在判定树中的层数。
树的形态只与表的长度 n 有关,与表中元素的具体值无关。
ASL 计算

缺点
不适合频繁插入删除的场景
(因为要保持有序和顺序存储,移动元素代价大)。
3.2.4 分块查找 / 索引顺序查找
原理
将 n 个元素分成 b 块。
块内无序,块间有序(例如第2块所有元素都大于第1块)。
建一个索引表,存储每块的最大关键字和起始地址。
过程
先在索引表中二分或顺序查找确定目标在哪一块,然后在该块内顺序查找。
ASL 计算(设 n 个元素分 b 块,每块 s 个元素,n = b * s)

3.2.5 散列表
1. 定义
根据关键字直接计算出存储地址的方法。
记录的存储位置 f(key) 称为散列函数/哈希函数。
冲突:
 ,这两个key称为同义词。
,这两个key称为同义词。
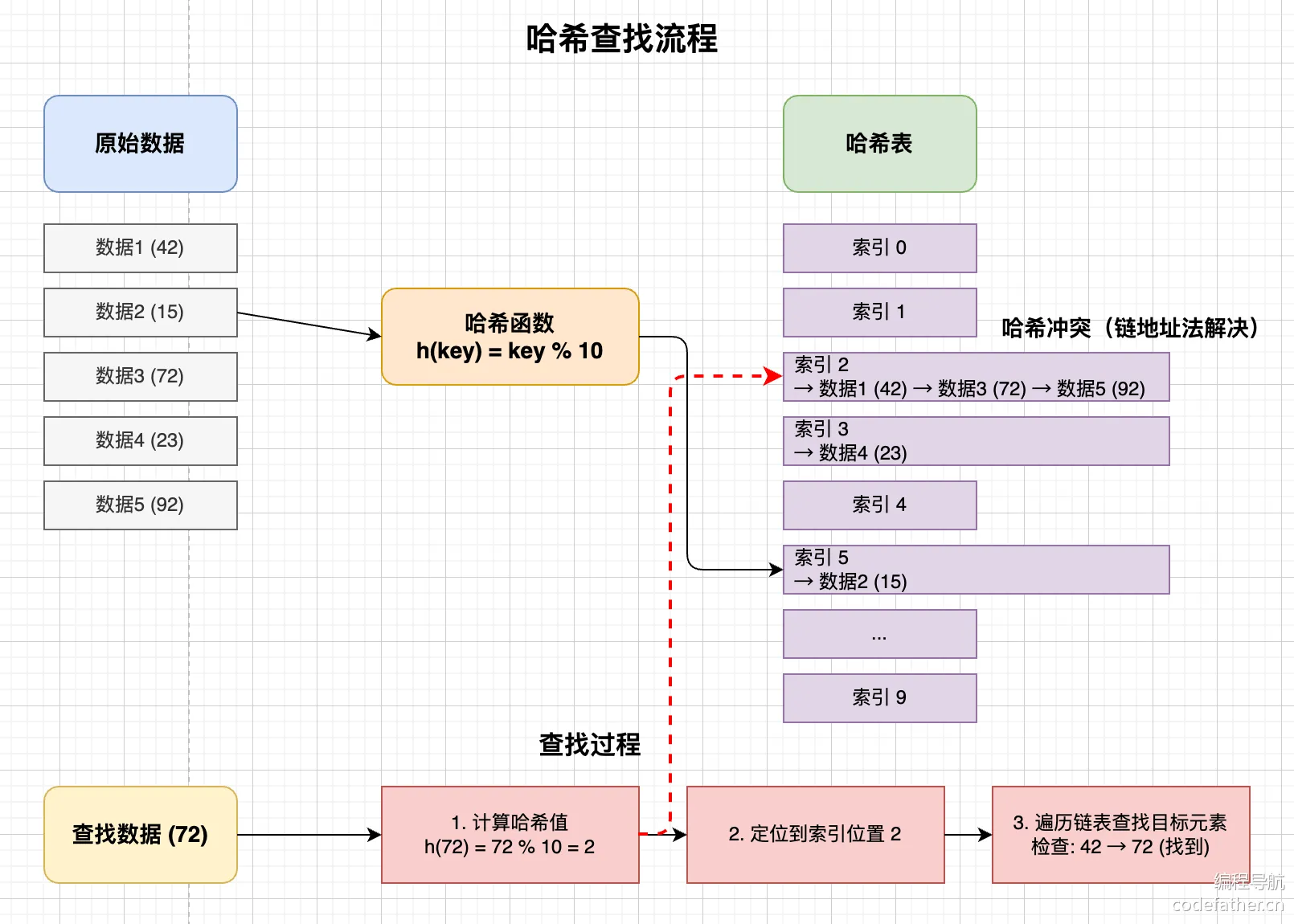
2. 散列函数(构造方法)
直接定址法
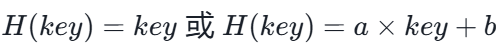
不会发生冲突,适合关键字分布连续。
除留余数法(最常考、最常用)
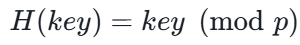
注意:
p 必须是不大于表长 m 的最大素数
(或者最小素数,按教材来,通常是不大于表长的最大素数),这样能最大程度减少冲突。
3. 冲突处理
① 开放定址法
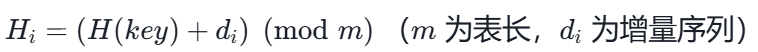
② 拉链法 / 链地址法
所有同义词用一个单链表链接起来。
散列表的每个单元存放链表的头指针。
优点:
处理冲突简单,无堆积现象。
适合经常进行插入删除的场景(不用像开放定址法那样移动元素)。
适用于表长不确定的情况。
缺点:
指针占用额外空间。
4. 探查方式
线性探查法
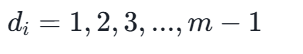
缺点:
容易产生"堆积/聚集"现象
(非同义词抢占了同一个后续地址)。
二次探查法(平方探查法)
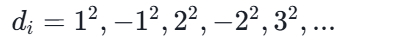
特点:
可以避免堆积,但不能探测到表的所有位置
(至少能探测到一半位置)。
双重散列法
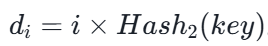
散列表的 ASL 计算题模板
给一组数字、表长 m、散列函数、处理冲突方法,求 ASL_{成功} 和 ASL_{失败}。
第一步:画表填数
严格按照规则填入散列表。如果是线性探查,遇到冲突就往后挪;如果是拉链法,画链表。
第二步:计算 ASL_{成功}
关键点:分母是元素的个数 n(不是表长 m)。
分子是每个元素插入时比较的次数之和。
例如:
某元素算出地址为5,发现被占了,和6比,发现也被占了,和7比,放入7。那么这个元素的比较次数是 3。*
第三步:计算 ASL_{失败}(极易错)
关键点:分母是散列函数的取值种类(即表长 m)。
分子是从第 0 个位置到第 m-1 个位置,假设查找不存在的关键字,分别需要比较几次才能确定失败。
(1)线性探查法中:
如果某个位置为空,则查找该位置失败只需比较 1 次;
如果某个位置及后面连续 3 个位置都有元素,则查找该位置失败需要比较 4 次(直到遇到第一个空隙才算失败)。
(2)拉链法中:
如果某个位置的链表有 3 个结点,查找该位置失败需要比较 3 次(从头比到尾的 NULL);
如果位置为空,比较 0 次。
3.2.6 总结对比表
|----------|-----------|-----------|---------------------------------|-------------------|
| 查找算法 | 前提条件 | 存储结构 | ASL 成功 ASL 成功 | 优缺点 |
| 顺序查找 | 无 | 顺序表/链表 | (n+1)/2 | 最慢,但最通用 |
| 二分查找 | 必须有序 | 仅限顺序表 | ≈log2(n+1)−1 | 最快(静态),但不支持动态增删 |
| 分块查找 | 块间有序,块内无序 | 顺序表+索引表 | 根号下n+1 | 介于顺序和二分之间 |
| 散列查找 | 选好散列函数 | 顺序表/链表 | 接近 O(1) | 极快,但有冲突开销,不支持范围查找 |
python
from collections import deque
# ============================================================
# 1. 顺序查找
# ============================================================
def seq_search(arr, key):
"""
从头到尾逐个比较
时间: O(n) 无需有序 支持任意存储结构
"""
for i, val in enumerate(arr):
if val == key:
return i # 返回下标(从 0 开始,即比较 i+1 次)
return -1 # 未找到
# ============================================================
# 2. 二分法查找 / 折半查找
# ============================================================
def binary_search(arr, key):
"""
前提:数组必须有序(从小到大)
时间: O(log n) 仅限顺序存储
返回: (找到的下标, 比较次数) 未找到时下标为 -1
"""
lo, hi = 0, len(arr) - 1
cnt = 0
while lo <= hi:
cnt += 1
mid = (lo + hi) // 2
if arr[mid] == key:
return mid, cnt
elif arr[mid] > key:
hi = mid - 1
else:
lo = mid + 1
return -1, cnt
# ============================================================
# 3. 分块查找(索引顺序查找)
# ============================================================
def block_search(arr, index, key):
"""
块间有序、块内无序。先在索引表中确定块号,再块内顺序查找
参数:
arr : 原始数组
index : 索引表 [(块内最大值, 块起始下标), ...]
key : 查找关键字
返回: (下标, 索引比较次数, 块内比较次数)
"""
# --- 第一步:在索引表中查找目标块(顺序查找) ---
block_idx = -1
idx_cmp = 0
for i, (max_val, start) in enumerate(index):
idx_cmp += 1
if key <= max_val:
block_idx = i
break
if block_idx == -1:
return -1, idx_cmp, 0 # 超出最大块
# --- 第二步:块内顺序查找 ---
_, blk_start = index[block_idx]
# 确定块结束位置
if block_idx + 1 < len(index):
blk_end = index[block_idx + 1][1]
else:
blk_end = len(arr)
blk_cmp = 0
for j in range(blk_start, blk_end):
blk_cmp += 1
if arr[j] == key:
return j, idx_cmp, blk_cmp
return -1, idx_cmp, blk_cmp
# ============================================================
# 4. 散列表 ------ 开放定址法(线性探查)
# ============================================================
class HashTableOpen:
"""
散列函数: H(key) = key % p (p 为不大于表长的最大素数)
冲突处理: 线性探查法 d_i = 1, 2, 3, ...
"""
def __init__(self, size, p=None):
"""
:param size: 散列表长 m
:param p: 除留余数法的 p(默认取 <= size 的最大素数)
"""
self.m = size
self.p = p or self._max_prime_le(size)
self.table = [None] * size
@staticmethod
def _max_prime_le(n):
"""求不超过 n 的最大素数"""
if n < 2:
return 2
for x in range(n, 1, -1):
if all(x % i != 0 for i in range(2, int(x**0.5) + 1)):
return x
return 2
def hash(self, key):
return key % self.p
def insert(self, key):
"""插入,返回插入时的比较次数(即探查次数)"""
addr = self.hash(key)
cmp_cnt = 1 # 第一次探查
# 逐步向后线性探查
while self.table[addr] is not None and self.table[addr] != -1:
if self.table[addr] == key: # 已存在,不重复插入
return cmp_cnt
addr = (addr + 1) % self.m
cmp_cnt += 1
self.table[addr] = key
return cmp_cnt
def search(self, key):
"""查找,返回 (找到的下标, 比较次数)"""
addr = self.hash(key)
cmp_cnt = 1
first_deleted = None
start = addr
while self.table[addr] is not None:
if self.table[addr] == key:
return addr, cmp_cnt
if self.table[addr] == -1 and first_deleted is None:
first_deleted = addr
addr = (addr + 1) % self.m
cmp_cnt += 1
if addr == start: # 绕了一圈,表满
break
return -1, cmp_cnt
def asl_success(self, keys):
"""计算查找成功的 ASL(keys 为实际插入的关键字列表)"""
total = 0
for k in keys:
_, cnt = self.search(k)
total += cnt
return round(total / len(keys), 2)
def asl_failure(self):
"""计算查找失败的 ASL(对每个散列地址 0~m-1 计算探查到空位的次数)"""
total = 0
for i in range(self.m):
addr = i
cnt = 1
while self.table[addr] is not None:
addr = (addr + 1) % self.m
cnt += 1
total += cnt
return round(total / self.m, 2)
def __repr__(self):
return str(self.table)
# ============================================================
# 5. 散列表 ------ 拉链法(链地址法)
# ============================================================
class HashTableChain:
"""
散列函数: H(key) = key % p
冲突处理: 拉链法(同义词链在同一槽位的单链表中)
"""
def __init__(self, size, p=None):
self.m = size
self.p = p or self._max_prime_le(size)
self.table = [[] for _ in range(size)] # 每个槽位一个链表
@staticmethod
def _max_prime_le(n):
if n < 2: return 2
for x in range(n, 1, -1):
if all(x % i != 0 for i in range(2, int(x**0.5) + 1)):
return x
return 2
def hash(self, key):
return key % self.p
def insert(self, key):
addr = self.hash(key)
if key not in self.table[addr]: # 去重
self.table[addr].append(key)
def search(self, key):
"""返回 (是否找到, 比较次数)"""
addr = self.hash(key)
for i, k in enumerate(self.table[addr]):
if k == key:
return True, i + 1 # 第 i+1 次比较命中
return False, len(self.table[addr]) # 比较了链表全部元素
def asl_success(self, keys):
total = 0
for k in keys:
_, cnt = self.search(k)
total += cnt
return round(total / len(keys), 2)
def asl_failure(self):
"""
查找失败:对每个散列地址,探查次数 = 该槽位链表长度
(空链表探查 0 次即可确定失败)
"""
total = sum(len(chain) for chain in self.table)
return round(total / self.m, 2)
def __repr__(self):
lines = []
for i, chain in enumerate(self.table):
lines.append(f" [{i:>2}]: {chain}")
return "\n".join(lines)
# ============================================================
# 查找算法汇总测试
# ============================================================
if __name__ == "__main__":
# ---------- 1. 顺序查找 ----------
print("=" * 50)
print("1. 顺序查找")
arr1 = [3, 9, 1, 7, 5, 2, 8, 4, 6]
key = 5
idx = seq_search(arr1, key)
print(f" 数组: {arr1}")
print(f" 查找 {key}: 下标={idx}, 比较次数={idx + 1}")
print(f" ASL_成功 = ({len(arr1)}+1)/2 = {(len(arr1)+1)/2}")
# ---------- 2. 二分查找 ----------
print("\n" + "=" * 50)
print("2. 二分查找")
arr2 = [2, 4, 7, 11, 15, 19, 23, 28, 33, 40]
key = 23
idx, cnt = binary_search(arr2, key)
print(f" 有序数组: {arr2}")
print(f" 查找 {key}: 下标={idx}, 比较次数={cnt}")
# ASL 计算(验证)
total_cmp = sum(binary_search(arr2, x)[1] for x in arr2)
print(f" ASL_成功 = {total_cmp}/{len(arr2)} = {round(total_cmp/len(arr2), 2)}")
# ---------- 3. 分块查找 ----------
print("\n" + "=" * 50)
print("3. 分块查找")
arr3 = [22, 12, 13, 9, 8, 33, 42, 44, 38, 45, 60, 58, 73, 77, 71]
# 分 3 块,每块 5 个,块间有序
index3 = [(22, 0), (45, 5), (77, 10)] # (块内最大值, 起始下标)
print(f" 原始数组: {arr3}")
print(f" 索引表: {index3}")
for k in [42, 71, 50]:
idx, ic, bc = block_search(arr3, index3, k)
status = f"下标={idx}" if idx != -1 else "未找到"
print(f" 查找 {k}: {status}, 索引比较={ic}次, 块内比较={bc}次")
# ---------- 4. 散列表 - 开放定址法 ----------
print("\n" + "=" * 50)
print("4. 散列表 ------ 开放定址法(线性探查)")
keys4 = [19, 14, 23, 1, 68, 20, 84, 27, 55, 11, 10, 79]
ht_open = HashTableOpen(size=13, p=13)
print(f" 关键字: {keys4}")
print(f" 表长 m=13, p=13, H(key) = key % 13\n")
for k in keys4:
ht_open.insert(k)
print(f" 散列表: {ht_open.table}")
print(f" ASL_成功 = {ht_open.asl_success(keys4)}")
print(f" ASL_失败 = {ht_open.asl_failure()}")
# ---------- 5. 散列表 - 拉链法 ----------
print("\n" + "=" * 50)
print("5. 散列表 ------ 拉链法(链地址法)")
keys5 = [19, 14, 23, 1, 68, 20, 84, 27, 55, 11, 10, 79]
ht_chain = HashTableChain(size=13, p=13)
print(f" 关键字: {keys5}")
print(f" 表长 m=13, p=13, H(key) = key % 13\n")
for k in keys5:
ht_chain.insert(k)
print(f" 散列表:")
print(ht_chain)
print(f"\n ASL_成功 = {ht_chain.asl_success(keys5)}")
print(f" ASL_失败 = {ht_chain.asl_failure()}")运行结果:
==================================================
- 顺序查找
数组: 3, 9, 1, 7, 5, 2, 8, 4, 6
查找 5: 下标=4, 比较次数=5
ASL_成功 = (9+1)/2 = 5.0
==================================================
- 二分查找
有序数组: 2, 4, 7, 11, 15, 19, 23, 28, 33, 40
查找 23: 下标=6, 比较次数=2
ASL_成功 = 29/10 = 2.9
==================================================
- 分块查找
原始数组: 22, 12, 13, 9, 8, 33, 42, 44, 38, 45, 60, 58, 73, 77, 71
索引表: (22, 0), (45, 5), (77, 10)
查找 42: 下标=6, 索引比较=2次, 块内比较=2次
查找 71: 下标=14, 索引比较=3次, 块内比较=5次
查找 50: 未找到, 索引比较=3次, 块内比较=5次
==================================================
- 散列表 ------ 开放定址法(线性探查)
关键字: 19, 14, 23, 1, 68, 20, 84, 27, 55, 11, 10, 79
表长 m=13, p=13, H(key) = key % 13
散列表: 1, 14, 68, 55, 84, 19, 20, 79, 33, 23, 11, 10, 27
ASL_成功 = 2.0
ASL_失败 = 6.62
==================================================
- 散列表 ------ 拉链法(链地址法)
关键字: 19, 14, 23, 1, 68, 20, 84, 27, 55, 11, 10, 79
表长 m=13, p=13, H(key) = key % 13
散列表:
0\]: \[
1\]: \[1, 14, 27
2\]: \[68
3\]: \[55
4\]: \[84
5\]: \[19
6\]: \[20
7\]: \[79
8\]: \[33
9\]: \[23
10\]: \[10, 23
11\]: \[11
12\]: \[
ASL_成功 = 1.33
ASL_失败 = 1.08