目录
[3.1 为什么需要初始化](#3.1 为什么需要初始化)
[3.2 常见初始化方法](#3.2 常见初始化方法)
[4.1 Sigmoid](#4.1 Sigmoid)
[4.2 Tanh](#4.2 Tanh)
[4.3 ReLU(最重要)](#4.3 ReLU(最重要))
[4.4 Leaky ReLU](#4.4 Leaky ReLU)
[4.5 Softmax](#4.5 Softmax)
[5.1 为什么需要标准化](#5.1 为什么需要标准化)
[5.2 Z-score标准化](#5.2 Z-score标准化)
[5.3 Min-Max归一化](#5.3 Min-Max归一化)
[5.4 Batch Normalization(BN)](#5.4 Batch Normalization(BN))
[5.5 Layer Norm](#5.5 Layer Norm)
[6.1 为什么需要正则化](#6.1 为什么需要正则化)
[6.2 L1正则化](#6.2 L1正则化)
[6.3 L2正则化(权重衰减)](#6.3 L2正则化(权重衰减))
[6.4 Dropout](#6.4 Dropout)
[6.5 Early Stopping](#6.5 Early Stopping)
[7.1 固定学习率](#7.1 固定学习率)
[7.2 Step Decay](#7.2 Step Decay)
[7.3 Exponential Decay](#7.3 Exponential Decay)
[7.4 Cosine Annealing](#7.4 Cosine Annealing)
[7.5 Warmup策略](#7.5 Warmup策略)
[8.1 SGD(随机梯度下降)](#8.1 SGD(随机梯度下降))
[8.2 Momentum](#8.2 Momentum)
[8.3 AdaGrad](#8.3 AdaGrad)
[8.4 RMSProp](#8.4 RMSProp)
[8.5 Adam(最常用)](#8.5 Adam(最常用))
一、前言
当我们从感知器一路学习到 CNN、RNN、Transformer,会发现一个核心问题始终存在:
模型越深 → 越难训练
模型越复杂 → 越容易不稳定深度学习真正的难点并不是"搭网络",而是:
如何让深层网络稳定收敛
如何避免梯度消失/爆炸
如何提升泛化能力
如何让模型真正学到有效特征因此,现代深度学习系统的核心不只是网络结构,还包括一整套"优化体系"。
本文将系统讲解六大核心优化技术:
参数初始化
激活函数
标准化方法
正则化方法
学习率策略
优化算法二、深度学习优化的整体框架
一个完整训练流程:
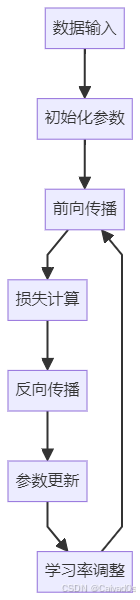
优化的目标是:
让损失函数更快下降
让模型更稳定收敛
让泛化能力更强三、掌握常见的参数初始化方法
3.1 为什么需要初始化
如果参数初始化不合理:
梯度消失
梯度爆炸
模型不收敛例如:
全部初始化为0 → 所有神经元学习相同特征(错误)3.2 常见初始化方法
(1)零初始化(错误示例)
W = 0问题:
所有神经元完全对称
无法学习不同特征(2)随机初始化
W ~ N(0, 0.01)优点:
打破对称性缺点:
深层网络可能梯度不稳定(3)Xavier初始化(Glorot)
适用于:
Sigmoid / Tanh公式:
Var(W) = 2 / (fan_in + fan_out)特点:
保持方差稳定(4)He初始化
适用于:
ReLU / LeakyReLU公式:
Var(W) = 2 / fan_in特点:
适合深层ReLU网络四、掌握常见激活函数
4.1 Sigmoid
σ(x) = 1 / (1 + e^-x)特点:
输出0~1问题:
梯度消失4.2 Tanh
tanh(x)特点:
输出 -1 ~ 1优点:
比Sigmoid更居中4.3 ReLU(最重要)
f(x) = max(0, x)优点:
计算简单
梯度传播稳定
收敛快缺点:
死亡ReLU问题4.4 Leaky ReLU
f(x) = x (x>0)
f(x) = 0.01x (x<0)解决:
ReLU死亡问题4.5 Softmax
用于:
多分类输出公式:
Softmax(xi) = exp(xi) / Σ exp(xj)五、掌握常见标准化方法
5.1 为什么需要标准化
问题:
不同特征尺度差异过大
导致训练困难例如:
年龄:0~100
收入:0~1,000,0005.2 Z-score标准化
x' = (x - μ) / σ特点:
均值=0
方差=15.3 Min-Max归一化
x' = (x - min) / (max - min)范围:
0 ~ 15.4 Batch Normalization(BN)
核心思想:
在神经网络内部进行标准化公式:
BN(x) = (x - μbatch) / sqrt(σ² + ε)优点:
加速收敛
稳定训练
允许更大学习率5.5 Layer Norm
用于:
Transformer / NLP区别:
BN:按batch
LN:按特征维度六、掌握常见正则化方法
6.1 为什么需要正则化
问题:
模型过拟合训练数据表现:
训练准确率高
测试效果差6.2 L1正则化
Loss + λ|W|特点:
产生稀疏模型6.3 L2正则化(权重衰减)
Loss + λW²特点:
防止权重过大6.4 Dropout
思想:
随机丢弃神经元公式:
y = mask * x作用:
防止过拟合6.5 Early Stopping
策略:
验证集不再提升 → 停止训练七、掌握学习率迭代策略
学习率是:
最重要的超参数之一7.1 固定学习率
lr = 0.01问题:
可能震荡或收敛慢7.2 Step Decay
每N轮下降一次公式:
lr = lr * 0.17.3 Exponential Decay
lr = lr0 * exp(-kt)特点:
平滑下降7.4 Cosine Annealing
学习率余弦下降特点:
训练更稳定7.5 Warmup策略
思想:
前期小学习率 → 后期变大学习率适用于:
Transformer模型八、掌握常见最优化方法
8.1 SGD(随机梯度下降)
W = W - η∇L特点:
简单
稳定性一般8.2 Momentum
思想:
引入"惯性"公式:
v = βv + (1-β)∇L
W = W - ηv优点:
加速收敛8.3 AdaGrad
特点:
自适应学习率问题:
学习率衰减过快8.4 RMSProp
改进AdaGrad:
解决学习率过早下降问题8.5 Adam(最常用)
结合:
Momentum + RMSProp公式:
m = β1m + (1-β1)g
v = β2v + (1-β2)g²更新:
W = W - η * m / (sqrt(v) + ε)优点:
收敛快
稳定性强
默认首选九、深度学习优化整体流程
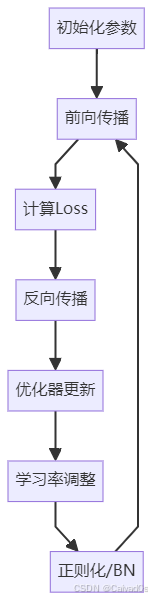
十、PyTorch综合示例
python
import torch
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(100, 64)
self.bn1 = nn.BatchNorm1d(64)
self.dropout = nn.Dropout(0.5)
self.fc2 = nn.Linear(64, 10)
nn.init.kaiming_normal_(self.fc1.weight)
def forward(self, x):
x = torch.relu(self.bn1(self.fc1(x)))
x = self.dropout(x)
x = self.fc2(x)
return x优化器:
python
optimizer = torch.optim.Adam(
model.parameters(),
lr=0.001,
weight_decay=1e-4
)十一、六大优化技术总结
| 模块 | 核心作用 |
|---|---|
| 初始化 | 稳定训练起点 |
| 激活函数 | 提供非线性能力 |
| 标准化 | 加速收敛 |
| 正则化 | 防止过拟合 |
| 学习率策略 | 控制训练节奏 |
| 优化算法 | 提升收敛效率 |
十二、总结
深度学习的核心不是单一模型,而是:
模型结构 + 优化体系六大优化技术共同作用:
初始化 → 决定起点
激活函数 → 决定表达能力
标准化 → 决定稳定性
正则化 → 决定泛化能力
学习率 → 决定收敛速度
优化器 → 决定下降路径最终形成完整训练闭环。
可以说:
深度学习模型之所以能够解决复杂任务,不仅因为网络更深,更因为背后有一整套成熟的优化体系在支撑训练过程。